
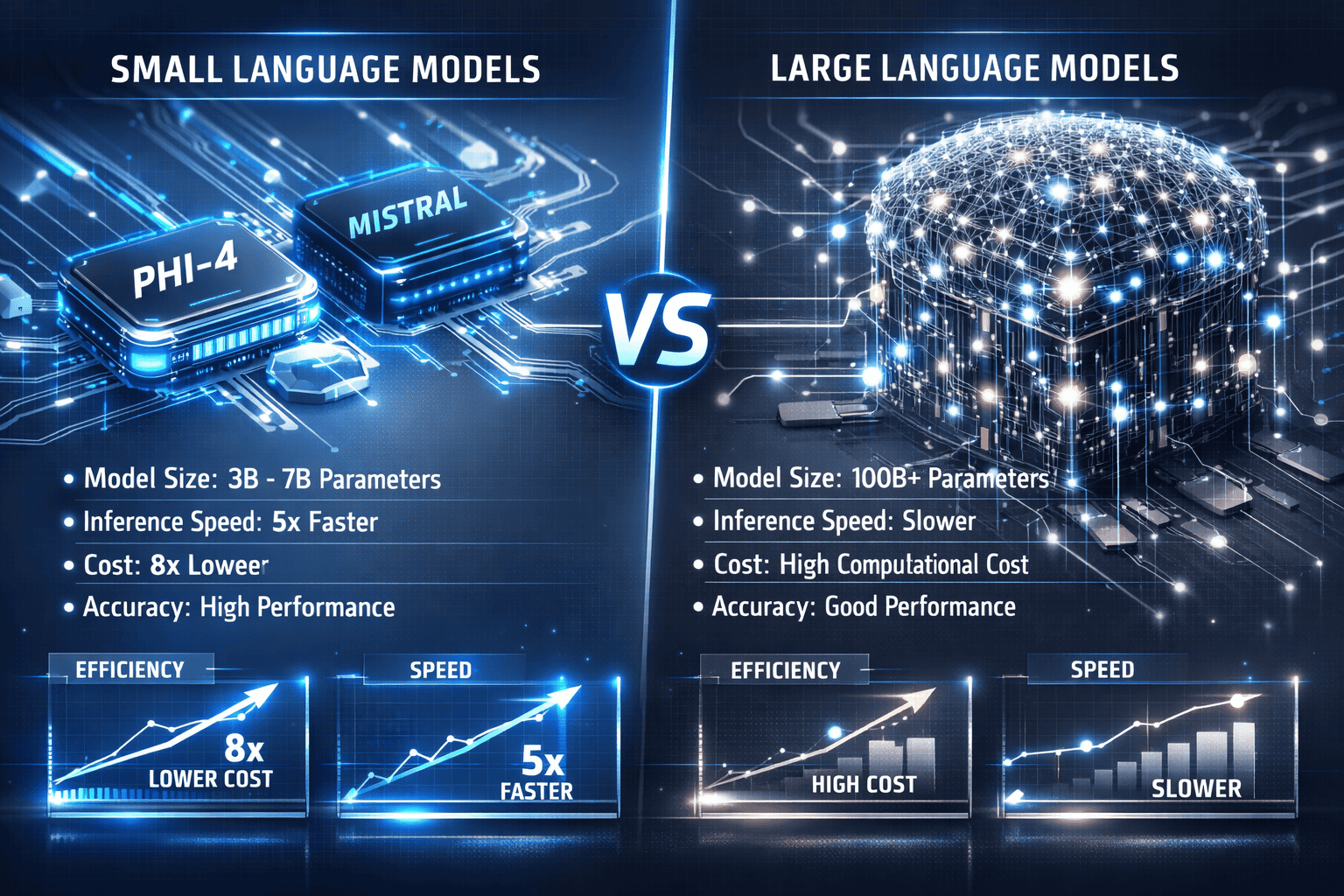
Enterprise organizations are abandoning the “bigger is better” mentality that dominated AI strategy for years. The small model revolution: why Phi-4, Mistral, and lightweight LLMs are winning in 2026 comes down to a simple truth—most business use cases don’t need 175 billion parameters when 14 billion can deliver the same results at a fraction of the cost. Microsoft’s Phi-4, with just 14.7 billion parameters, now outperforms models five times its size on key benchmarks, while Mistral Small 3 delivers 70B-class performance in 24B parameters and executes over 3× faster on identical hardware[1][3].
This shift represents more than incremental improvement. Industry analysts project that small language models (SLMs) will see 300% greater adoption than traditional large models by 2027, fundamentally reshaping how companies deploy AI[8]. The economics are compelling: Mistral’s API pricing sits at approximately $0.30 per million tokens—roughly half the cost of comparable services—while enabling deployment on hardware as modest as gaming laptops[1].
- Key Takeaways
- Quick Answer
- What Makes Small Language Models Different from Traditional LLMs?
- Why Are Phi-4 and Mistral Small 3 Outperforming Larger Models?
- How Do Deployment Costs Compare Between Small and Large Models?
- What Use Cases Are Best Suited for Lightweight LLMs?
- How Does the Small Model Revolution Impact Enterprise AI Strategy?
- What Are the Technical Limitations of Small Models in 2026?
- How Will Small Model Development Evolve Through 2026 and Beyond?
- What Should Teams Consider When Migrating to Small Models?
- FAQ
- Conclusion
- References
Key Takeaways
- The small model revolution: why Phi-4, Mistral, and lightweight LLMs are winning in 2026 centers on performance-per-dollar optimization, with small models delivering 70B-class results at half the cost and 3× the speed[1][3]
- Phi-4’s 14.7B parameters outperform much larger models on reasoning and code generation through optimized training data and architectural efficiency, proving parameter count no longer determines capability[3][4]
- Mistral Small 3 covers 80% of enterprise use cases including customer service, content generation, and document processing while running on gaming laptop hardware (8-12 GB VRAM)[1]
- API costs dropped by half with Mistral charging approximately $0.30 per million tokens, saving organizations $100,000+ annually on typical production workloads[1]
- Gartner projects 3× greater SLM adoption than LLMs by 2027, signaling an industry-wide shift toward right-sized model deployment[8]
- Deployment flexibility enables on-premise processing for regulated industries, solving data privacy and compliance challenges that cloud-dependent large models can’t address[1]
- Hybrid architectures become standard, routing common tasks to small models while reserving large models for truly complex reasoning and specialized domains
- Small models require higher-quality fine-tuning data but deliver better ROI when optimized for specific use cases with 1,000-5,000 curated examples
- Migration should start with high-volume, well-defined tasks where cost and latency matter most, then expand based on measured results
- The future favors multi-model strategies where organizations deploy portfolios of right-sized models rather than forcing all use cases through a single expensive LLM
Quick Answer

The small model revolution: why Phi-4, Mistral, and lightweight LLMs are winning in 2026 centers on performance-per-dollar optimization. Phi-4 (14.7B parameters) and Mistral Small 3 (24B parameters) deliver results comparable to models with 70B+ parameters while running faster, costing less, and deploying on accessible hardware. For most teams, these models cover 80% of use cases—customer service, real-time assistants, document processing—without the infrastructure overhead of massive models. Choose small models when speed, cost, and deployment flexibility matter more than pushing absolute performance limits on specialized research tasks.
What Makes Small Language Models Different from Traditional LLMs?
Small language models (SLMs) are purpose-built AI systems with parameter counts typically ranging from 3.8 billion to 24 billion, compared to 70 billion or more in traditional large language models. The key difference is architectural efficiency rather than raw scale.
Parameter efficiency defines the category. Microsoft’s Phi family spans from Phi-3 Mini (3.8B) through Phi-4 (14.7B), with each model engineered to outperform larger competitors on specific tasks[3]. Mistral Small 3, at 24B parameters, was deliberately optimized to cover 80% of common generative tasks—customer service, real-time assistants, mobile deployments—with dramatically reduced computational requirements[1].
The architectural innovations that enable this efficiency include:
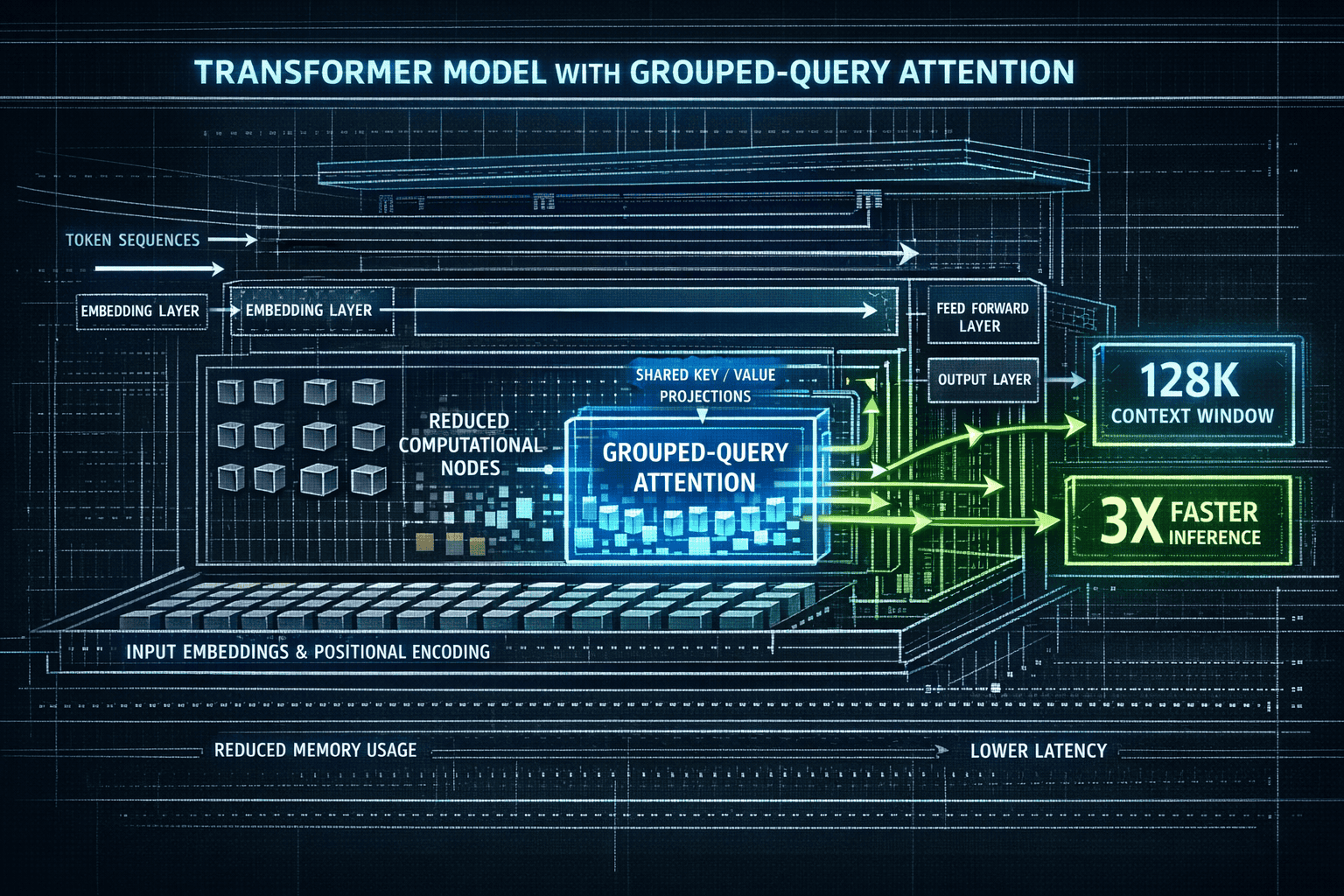
- Grouped-query attention mechanisms that reduce computational load without sacrificing output quality[1]
- Optimized training data curation focusing on high-quality, task-relevant examples rather than maximum dataset size
- Latency-optimized transformer architectures that prioritize inference speed over parameter count
- Extended context windows (up to 128k tokens) matching or exceeding larger model capabilities[1][3]
In practice, this means a 4-bit quantized version of Mistral Small 3 runs on a single GPU with approximately 8-12 GB VRAM—hardware found in gaming laptops and modest servers[1]. Traditional LLMs with 70B+ parameters require multi-GPU clusters costing tens of thousands of dollars.
Choose small models when:
- Your use case falls within common generative tasks (content generation, summarization, basic reasoning)
- Deployment budget or infrastructure limits GPU availability
- Latency matters (real-time applications, user-facing chatbots)
- You need local deployment for data privacy or compliance
Stick with larger models when:
- Tasks require cutting-edge reasoning on novel problems
- Specialized domain knowledge beyond common training data is essential
- Absolute performance matters more than cost or speed
The economics shift dramatically at scale. For organizations processing millions of API calls monthly, the difference between $0.30 and $0.60 per million tokens compounds into six-figure annual savings[1].
Why Are Phi-4 and Mistral Small 3 Outperforming Larger Models?
Phi-4 and Mistral Small 3 outperform larger models because they prioritize training data quality and architectural efficiency over parameter count. Microsoft’s Phi-4, with 14.7 billion parameters, beats much larger models on reasoning benchmarks by using carefully curated training data and optimized attention mechanisms[3][4].
The performance advantage comes from three core strategies:
1. Synthetic data generation for reasoning tasks
Microsoft trained Phi-4 using high-quality synthetic data specifically designed to teach reasoning patterns. This targeted approach produces better results on logic and math problems than training on massive but noisy web-scraped datasets. Phi-4-mini-instruct, with only 3.8B parameters, demonstrates reasoning and multilingual performance comparable to 7B-9B range models like Llama-3.1-8B-Instruct[5].
2. Task-specific optimization
Mistral engineered Small 3 to excel at the 80% of use cases most organizations actually deploy: customer service automation, document summarization, code assistance, and conversational interfaces[1]. By optimizing for common tasks rather than trying to be universal, the model achieves 70B-class performance on these workloads while running 3× faster.
3. Architectural efficiency improvements
Both model families employ grouped-query attention and other transformer optimizations that reduce computational requirements without quality loss[1]. This isn’t just about speed—it fundamentally changes what hardware can run production workloads.
The benchmark results tell the story. Mistral Small 3.1 (released March 2026) outperforms Gemma 3 27B on several standardized tests while maintaining faster inference speeds[2]. Phi-4 beats models with 5× more parameters on mathematical reasoning and code generation tasks[3].
Common mistake: Assuming larger models are always better for production deployments. In practice, most enterprise use cases don’t require the absolute ceiling of model capability—they need reliable, fast, cost-effective performance on well-defined tasks.
For teams evaluating models, the decision framework is straightforward:
- Run benchmark tests on your actual use case data, not general leaderboards
- Measure total cost of ownership including API fees, infrastructure, and latency impact on user experience
- Start with the smallest model that meets quality thresholds, then scale up only if necessary
The performance-per-dollar equation has shifted dramatically. What once required a 70B model and expensive GPU infrastructure now runs on hardware accessible to mid-market companies. For organizations exploring how to leverage multiple AI models effectively, understanding these efficiency gains is critical to building sustainable AI strategies. Learn more about choosing the right AI for specific tasks.
How Do Deployment Costs Compare Between Small and Large Models?

Small models cost 50-70% less to deploy and operate than large models when accounting for infrastructure, API fees, and latency requirements. A quantized Mistral Small 3 runs on a single GPU with 8-12 GB VRAM, while comparable large models require multi-GPU clusters costing $50,000-$100,000 in hardware alone[1].
Infrastructure Cost Breakdown
| Model Type | Parameters | GPU Requirement | Hardware Cost | Monthly API Cost (1M tokens/day) |
|---|---|---|---|---|
| Mistral Small 3 | 24B | 1× GPU (12GB) | $1,500-$3,000 | ~$9,000 |
| Phi-4 | 14.7B | 1× GPU (8GB) | $800-$1,500 | Variable (open source) |
| Traditional LLM | 70B+ | 4-8× GPU (80GB each) | $50,000-$100,000 | ~$18,000 |
API pricing differences compound quickly at scale. Mistral’s API costs approximately $0.30 per million tokens generated—roughly half the cost of OpenAI’s GPT-4 API and comparable services[1]. For an organization processing 30 million tokens monthly (typical for a mid-sized customer service operation), this translates to $9,000 versus $18,000 monthly—a $108,000 annual difference.
Self-hosting economics favor small models even more dramatically. A Phi-4 deployment on a single NVIDIA RTX 4090 (consumer gaming GPU) can handle production workloads that would require a cluster of A100s for a 70B model. The difference:
- Small model setup: $1,500 GPU + $2,000 server = $3,500 one-time
- Large model setup: $80,000 in GPUs + $15,000 server infrastructure = $95,000 one-time
Latency costs matter for user-facing applications. Mistral Small 3 executes over 3× faster than 70B alternatives on identical hardware[1]. For real-time chatbots or interactive assistants, this speed difference directly impacts user experience and retention. Every 100ms of latency can reduce conversion rates by 1-2% in e-commerce applications.
Edge case: Highly specialized domains (medical diagnosis, legal analysis, advanced research) may still justify large model costs when accuracy requirements outweigh economic considerations. But for the 80% of use cases Mistral Small 3 targets—customer service, content generation, basic coding assistance—the cost difference is impossible to justify[1].
Common mistake: Comparing only API pricing without factoring in latency, context window costs, and fine-tuning expenses. Small models often support longer context windows (128k tokens) at base pricing, while large models charge premium rates for extended context[1][3].
For teams building AI-powered products, the deployment cost advantage of small models fundamentally changes what’s economically viable. Features that were too expensive to offer at scale with large models become profitable with Phi-4 or Mistral Small 3.
What Use Cases Are Best Suited for Lightweight LLMs?
Lightweight LLMs excel at high-volume, well-defined tasks where speed and cost matter more than pushing absolute performance boundaries. Mistral Small 3 was engineered specifically to cover 80% of enterprise use cases with dramatically reduced computational requirements[1].
The ideal use cases fall into four categories:
1. Customer Service and Support Automation
Real-time chatbots, ticket classification, and response generation benefit from small models’ low latency and cost efficiency. A customer service operation processing 10,000 conversations daily needs fast response times (under 500ms) and reasonable per-interaction costs. Phi-4 and Mistral Small 3 deliver both while maintaining quality comparable to larger models on these structured tasks.
Choose small models for:
- FAQ responses and common troubleshooting
- Ticket routing and priority classification
- Initial response drafting for human review
- Sentiment analysis and escalation detection
2. Content Generation and Summarization
Blog posts, product descriptions, email drafts, and document summaries represent straightforward language tasks where small models perform at parity with larger alternatives. Phi-4-mini-instruct, with only 3.8B parameters, demonstrates multilingual performance across 20+ languages—making it viable for global content operations without infrastructure overhead[5].
Specific applications:
- Marketing copy generation for A/B testing
- Meeting notes and transcript summarization
- Product description scaling across catalogs
- Email response suggestions
3. Code Assistance and Documentation
Code completion, bug detection, and documentation generation fall within Phi-4’s optimization targets. The model outperforms larger competitors on code generation benchmarks despite its 14.7B parameter count[3]. For development teams, this means faster IDE integrations and lower costs for features like GitHub Copilot alternatives.
Development use cases:
- Autocomplete and code suggestion
- Unit test generation
- API documentation writing
- Code review and basic bug detection
4. Mobile and Edge Deployments
On-device AI for privacy-sensitive applications becomes viable with models that run on 8-12 GB VRAM. Healthcare apps, financial tools, and enterprise software requiring local processing can deploy Phi-4 or quantized Mistral Small 3 without cloud dependencies[1].
Edge deployment scenarios:
- Medical transcription on local devices
- Financial document analysis without data transmission
- Manufacturing quality control with on-premise processing
- Retail point-of-sale intelligent assistants
Decision framework:
Use small models when:
- Task patterns are well-defined and repeatable
- Volume is high (thousands to millions of requests)
- Latency requirements are strict (under 1 second)
- Budget constraints limit infrastructure spending
- Data privacy requires local deployment
Use large models when:
- Tasks require novel reasoning on unfamiliar problems
- Specialized domain knowledge is critical
- Volume is low enough that cost differences are negligible
- Absolute accuracy matters more than speed or price
Common mistake: Defaulting to the largest available model without testing whether a small model meets quality thresholds. In practice, running comparative evaluations on actual use case data often reveals that Phi-4 or Mistral Small 3 perform identically to 70B models for specific tasks—at a fraction of the cost.
For organizations managing multiple AI models across different use cases, understanding these distinctions is essential for optimizing both performance and budget. Explore how MULTIBLY’s platform helps teams choose the right model for each specific task.
How Does the Small Model Revolution Impact Enterprise AI Strategy?
The small model revolution forces enterprises to rethink AI architecture from “one large model for everything” to “right-sized models for specific tasks.” This shift reduces infrastructure costs by 50-70% while improving latency and deployment flexibility[1].
Strategic implications for 2026:
1. Multi-Model Architectures Become Standard
Instead of routing all requests through a single expensive LLM, leading organizations now deploy model portfolios matched to use case requirements. Customer service queries route to Mistral Small 3, code assistance uses Phi-4, and only complex reasoning tasks hit larger models. This approach optimizes the performance-per-dollar equation across the entire AI stack.
2. Infrastructure Costs Shift from Barrier to Competitive Advantage
When AI deployment required $100,000+ GPU clusters, only large enterprises could compete. Now, mid-market companies deploy production-grade AI on hardware costing $3,000-$5,000[1]. This democratization accelerates AI adoption across industries previously priced out of the market.
Budget reallocation opportunity: The $100,000 saved on infrastructure can fund data quality improvements, fine-tuning, and specialized model development—investments that deliver better results than simply buying larger models.
3. Data Privacy and Compliance Become Easier
Small models that run on single GPUs enable true on-premise deployment for regulated industries. Healthcare organizations can process patient data without cloud transmission. Financial services can analyze sensitive documents locally. This wasn’t economically viable when models required multi-GPU clusters[1].
4. Speed Becomes a Differentiator
Mistral Small 3’s 3× faster inference speed compared to 70B models transforms user experience in customer-facing applications[1]. The difference between 300ms and 900ms response time directly impacts conversion rates, user satisfaction, and competitive positioning.
Practical example: An e-commerce company using AI-powered product recommendations can test more variations, personalize faster, and serve more customers concurrently when switching from a large model to Phi-4 or Mistral Small 3.
5. Vendor Lock-In Risks Decrease
Open-source small models (Phi-4, Mistral Small 3) reduce dependency on proprietary API providers. Organizations can self-host, fine-tune, and modify models without vendor permission or pricing changes. This flexibility matters for long-term strategic planning.
Implementation framework for enterprises:
Phase 1: Audit current AI use cases
- Map which tasks actually require large model capabilities
- Identify high-volume, well-defined workloads suitable for small models
- Calculate current costs (API fees, infrastructure, latency impact)
Phase 2: Run comparative benchmarks
- Test Phi-4 and Mistral Small 3 on actual production data
- Measure quality differences (if any) against current large models
- Calculate total cost of ownership for each scenario
Phase 3: Implement hybrid architecture
- Route appropriate tasks to small models
- Reserve large models for complex reasoning and specialized domains
- Monitor performance and cost metrics continuously
Phase 4: Optimize and scale
- Fine-tune small models on proprietary data
- Expand use cases as confidence grows
- Reinvest savings into data quality and model improvements
Common mistake: Treating this as a pure technology decision rather than a strategic business initiative. The small model revolution impacts budgets, team structure, vendor relationships, and competitive positioning. Successful implementations require buy-in from finance, legal, and business units—not just engineering.
For organizations navigating this transition, understanding how to effectively manage multiple AI models becomes a core competency. Learn more about MULTIBLY’s approach to multi-model AI management.
What Are the Technical Limitations of Small Models in 2026?
Small models face three primary limitations: specialized domain knowledge, novel reasoning tasks, and extreme context requirements. Understanding these boundaries helps teams deploy the right model for each use case rather than forcing small models into scenarios where they underperform.
1. Specialized Domain Knowledge Gaps
Small models trained on general datasets lack the depth of knowledge in highly specialized fields that larger models acquire through massive parameter counts. A 14.7B model like Phi-4 won’t match a 70B model trained extensively on medical literature when diagnosing rare conditions or interpreting complex research papers[3].
Specific limitations:
- Advanced medical diagnosis requiring rare disease knowledge
- Legal analysis of obscure precedents and complex case law
- Scientific research requiring deep domain expertise
- Highly technical engineering problems in niche fields
Workaround: Fine-tuning small models on domain-specific datasets can close this gap for well-defined specializations, but it requires quality training data and expertise.
2. Novel Reasoning and Abstract Problem-Solving
While Phi-4 outperforms larger models on many reasoning benchmarks, it still struggles with truly novel problems requiring multi-step abstract reasoning outside its training distribution. Large models with more parameters can sometimes generalize better to completely unfamiliar scenarios[3][4].
Where small models struggle:
- Complex mathematical proofs requiring novel approaches
- Multi-step strategic planning in unfamiliar domains
- Creative problem-solving with minimal context
- Reasoning about entirely new concepts or frameworks
Decision rule: If your use case involves repetitive reasoning patterns (customer service logic, common coding problems, standard document analysis), small models perform excellently. If it requires inventing new approaches to unfamiliar problems, larger models may justify their cost.
3. Extreme Context and Memory Requirements
Although Mistral Small 3 supports up to 128k token context windows[1], some applications require even longer memory or more sophisticated context management than current small models provide efficiently.
Context limitations:
- Multi-document analysis spanning hundreds of pages
- Long-running conversations requiring perfect memory of all details
- Complex codebase analysis across dozens of interconnected files
- Legal document review requiring cross-referencing hundreds of sources
4. Multilingual Performance Gaps
Phi-4-mini-instruct supports 20+ languages[5], but performance quality varies significantly across languages. English and major European languages perform well, while less-common languages show noticeable quality degradation compared to larger multilingual models.
Language considerations:
- Strong performance: English, Spanish, French, German, Chinese
- Moderate performance: Portuguese, Italian, Japanese, Korean
- Weaker performance: Less-common languages, regional dialects, code-switching scenarios
5. Fine-Tuning Data Requirements
Small models require higher-quality fine-tuning data to match large model performance on specialized tasks. While this is technically achievable, it demands more careful data curation and expertise than simply throwing data at a large model.
Practical constraint: Organizations without strong ML engineering teams may find it harder to optimize small models for niche use cases, even though the raw capability exists.
Edge cases where large models still win:
- Cutting-edge research applications where absolute performance ceiling matters more than cost
- Low-volume, high-stakes decisions (major legal filings, critical medical diagnoses) where the cost difference is negligible compared to error risk
- Truly novel product categories where training data doesn’t exist and generalization capability is paramount
Common mistake: Assuming small models can’t handle complex tasks. In practice, 80% of “complex” enterprise use cases involve well-defined patterns that small models handle excellently[1]. The limitation is truly novel reasoning, not routine complexity.
For teams building AI strategies, the key is matching model capabilities to actual requirements rather than defaulting to the largest available option. Understanding these limitations helps optimize the performance-per-dollar equation across your entire AI portfolio. Explore MULTIBLY’s features for managing multiple models effectively.
How Will Small Model Development Evolve Through 2026 and Beyond?
Small model development will focus on three key areas: architectural efficiency gains, specialized fine-tuning frameworks, and hybrid model systems that combine small models for common tasks with selective large model access for complex reasoning.
Near-Term Evolution (2026-2027)
1. Sub-10B models reaching current 14B performance
The efficiency improvements that enabled Phi-4 (14.7B) to outperform 70B models will continue down the parameter scale. Expect models with 7-9B parameters to match current Phi-4 performance by late 2026, making deployment on even more modest hardware viable[3][5].
2. Task-specific model families
Rather than general-purpose small models, vendors will release specialized variants optimized for specific use cases: customer service models, coding assistants, document processors, and conversational agents. Each variant will outperform general models on its target task while using fewer parameters.
Mistral’s approach of engineering Small 3 to cover 80% of use cases represents the beginning of this trend[1]. Future iterations will offer 90%+ coverage for specific verticals (healthcare, finance, legal) with even better efficiency.
3. Improved quantization and compression
Current 4-bit quantization enables Mistral Small 3 to run on 8-12 GB VRAM[1]. Next-generation compression techniques will push this further, enabling production deployments on smartphones and IoT devices without quality loss.
Medium-Term Trends (2027-2028)
4. Hybrid inference systems
Production systems will automatically route requests to appropriately-sized models based on complexity detection. Simple queries hit 3-7B models, moderate complexity uses 14-24B models, and only truly difficult problems route to large models. This optimization happens transparently to end users.
Technical implementation: Request classifiers analyze query complexity and route to the smallest model likely to succeed. If confidence is low, the system escalates to larger models. This approach minimizes cost while maintaining quality.
5. Federated and edge-first architectures
As small models become efficient enough for edge deployment, privacy-first architectures will process sensitive data locally and only send anonymized or aggregated results to cloud services. Healthcare, finance, and enterprise applications will adopt this pattern as standard.
6. Continuous learning and adaptation
Small models will incorporate lightweight fine-tuning mechanisms that adapt to user feedback and domain-specific data without full retraining. This enables personalization and specialization at scale without the computational overhead of traditional fine-tuning.
Strategic Implications
Industry consolidation around efficiency metrics
Benchmarks will shift from raw performance to performance-per-dollar and performance-per-watt measurements. Vendors will compete on efficiency rather than parameter count, accelerating the small model revolution.
Democratization of AI development
When production AI runs on $3,000 hardware instead of $100,000 clusters[1], the barrier to entry drops dramatically. Expect an explosion of specialized AI applications from smaller companies and individual developers.
Regulatory and compliance advantages
As governments implement AI regulations requiring transparency and data localization, small models that run on-premise will have compliance advantages over cloud-dependent large models. This regulatory tailwind will accelerate enterprise adoption.
Common misconception: That large models will disappear. In reality, large models will remain essential for research, cutting-edge applications, and truly novel reasoning tasks. The shift is toward right-sized deployment rather than abandoning large models entirely.
For organizations planning AI strategies beyond 2026, the trend is clear: invest in multi-model architectures, develop expertise in model selection and optimization, and build systems that can adapt as small models continue improving. Understanding how to navigate this landscape effectively becomes a competitive advantage. Learn more about MULTIBLY’s approach to multi-model AI.
What Should Teams Consider When Migrating to Small Models?
Teams migrating to small models should start with high-volume, well-defined use cases where cost and latency matter most, then expand based on measured results. The migration process requires technical evaluation, cost analysis, and change management—not just a simple model swap.
Phase 1: Identify Migration Candidates
Audit current AI use cases and prioritize based on:
- Request volume: High-volume tasks (thousands to millions of requests) show the largest cost savings
- Task definition: Well-defined, repetitive tasks (customer service, summarization, code completion) migrate most successfully
- Latency sensitivity: User-facing applications benefit most from small models’ 3× faster inference[1]
- Current costs: Calculate monthly API fees and infrastructure expenses to quantify potential savings
Best first candidates:
- Customer service chatbots handling common questions
- Content generation for marketing or product descriptions
- Document summarization and classification
- Code completion and basic assistance
Avoid starting with:
- Novel reasoning tasks requiring cutting-edge capabilities
- Low-volume, high-stakes decisions where cost differences are negligible
- Highly specialized domains without fine-tuning resources
Phase 2: Run Comparative Benchmarks
Test small models against current solutions using actual production data:
- Collect representative samples (500-1,000 examples) from production workloads
- Run identical prompts through current large model and small model candidates (Phi-4, Mistral Small 3)
- Measure quality differences using both automated metrics and human evaluation
- Calculate cost and latency for each scenario
- Determine quality threshold: Is small model performance acceptable for the use case?
Key metrics to track:
- Response quality (accuracy, relevance, coherence)
- Latency (average, p95, p99)
- Cost per request
- Error rates and edge case handling
Common mistake: Testing only on cherry-picked examples rather than representative production data. Real-world performance often differs from curated test sets.
Phase 3: Implement Hybrid Architecture
Don’t migrate everything at once. Deploy a routing layer that sends appropriate requests to small models while keeping large models available for complex cases.
Implementation approach:
<code>Request → Complexity Classifier → Route to:
- Simple/Common → Small Model (Phi-4, Mistral Small 3)
- Complex/Novel → Large Model
- Uncertain → Small Model with Large Model fallback
</code>Gradual rollout strategy:
- Start with 10% of traffic to small models
- Monitor quality metrics and user feedback
- Increase to 50% if metrics hold
- Scale to 80-90% for appropriate use cases
- Keep large models for remaining complex cases
Phase 4: Optimize and Fine-Tune
Once base migration succeeds, optimize for your specific use case:
- Fine-tune small models on proprietary data to close any quality gaps
- Adjust prompting strategies (small models may respond better to different prompt formats)
- Optimize infrastructure (quantization, batching, caching)
- Monitor and iterate based on production metrics
Fine-tuning considerations:
Small models require higher-quality training data than large models to achieve comparable results. Invest in data curation and cleaning before fine-tuning. For most teams, 1,000-5,000 high-quality examples produce better results than 50,000 noisy examples.
Phase 5: Measure and Communicate Results
Track and report on:
- Cost savings: Monthly API fees or infrastructure costs before and after
- Performance metrics: Latency improvements, throughput increases
- Quality maintenance: Demonstrate that user experience hasn’t degraded
- Business impact: Faster features, new capabilities enabled by cost savings
Example metrics report:
| Metric | Before (Large Model) | After (Small Model) | Improvement |
|---|---|---|---|
| Monthly Cost | $18,000 | $9,000 | 50% reduction |
| Average Latency | 850ms | 280ms | 67% faster |
| User Satisfaction | 4.2/5 | 4.3/5 | Maintained/improved |
| Requests/Second | 50 | 150 | 3× throughput |
Change Management Considerations
Address stakeholder concerns proactively:
- Engineering teams: Provide clear migration documentation and support
- Product teams: Demonstrate quality maintenance through A/B testing
- Finance teams: Quantify cost savings and ROI
- Leadership: Frame as strategic positioning for the small model revolution
Common objection: “Why risk changing something that works?”
Response: Run parallel deployments showing identical quality at half the cost. Let data drive the decision.
For organizations navigating this transition, having the right tools to manage multiple models effectively becomes critical. Explore how MULTIBLY’s pricing makes multi-model management accessible.
FAQ
What is the main advantage of small models like Phi-4 over larger LLMs?
Small models like Phi-4 deliver comparable performance to much larger models (70B+ parameters) while running 3× faster, costing 50% less, and deploying on accessible hardware like gaming laptops with 8-12 GB VRAM[1][3]. For 80% of enterprise use cases, this efficiency advantage outweighs any marginal quality differences.
Can Phi-4 really outperform models with 70B parameters?
Yes, on specific tasks. Phi-4’s 14.7B parameters outperform many 70B models on reasoning, mathematics, and code generation benchmarks through optimized training data and architectural efficiency[3][4]. However, large models still excel at truly novel reasoning and specialized domain knowledge.
How much does it cost to run Mistral Small 3 compared to GPT-4?
Mistral Small 3 API pricing sits at approximately $0.30 per million tokens—roughly half the cost of GPT-4 API[1]. For self-hosting, a quantized version runs on a single GPU costing $1,500-$3,000, while comparable large models require $50,000-$100,000 in GPU clusters.
What hardware do I need to run small models locally?
A gaming laptop or server with a single GPU and 8-12 GB VRAM can run quantized versions of Mistral Small 3 or Phi-4[1]. For example, an NVIDIA RTX 4090 or RTX 3090 provides sufficient capacity for production deployments of these models.
Are small models suitable for customer service applications?
Yes, customer service is an ideal use case. Small models handle common queries, ticket classification, and response generation with quality matching larger models while delivering faster responses (under 500ms) and lower per-interaction costs[1]. Mistral Small 3 was specifically optimized for this use case.
Do small models support multiple languages?
Phi-4-mini-instruct supports 20+ languages[5], though performance varies by language. English and major European languages perform best, while less-common languages show quality gaps compared to larger multilingual models. For most business applications in major languages, small models perform adequately.
How do I choose between Phi-4 and Mistral Small 3?
Choose Phi-4 (14.7B) for code generation, mathematical reasoning, and scenarios requiring the smallest possible model. Choose Mistral Small 3 (24B) for broader generative tasks, longer context windows (128k tokens), and applications where the extra parameters provide quality improvements[1][3]. Test both on your specific use case to determine which performs better.
Can small models be fine-tuned for specialized domains?
Yes, both Phi-4 and Mistral Small 3 support fine-tuning. Small models require higher-quality training data than large models to achieve comparable specialized performance, but 1,000-5,000 well-curated examples typically produce excellent results for defined domains.
What are the main limitations of small models?
Small models struggle with truly novel reasoning outside training distribution, specialized domain knowledge in niche fields (rare medical conditions, obscure legal precedents), and some extreme context requirements[3]. For 80% of enterprise use cases, these limitations don’t apply[1].
Will small models replace large models entirely?
No, the trend is toward right-sized deployment rather than replacement. Small models will handle 80% of common tasks while large models remain essential for cutting-edge research, truly novel reasoning, and specialized applications where absolute performance matters more than cost[1].
How quickly can a team migrate from large to small models?
A phased migration typically takes 2-4 months: 2-3 weeks for benchmarking and evaluation, 3-4 weeks for initial deployment and testing, then gradual rollout to full production. Teams with strong ML engineering can move faster, while those requiring extensive fine-tuning may need additional time.
What cost savings should I expect from switching to small models?
Most organizations see 50-70% reduction in AI infrastructure and API costs when migrating appropriate use cases to small models[1]. A typical mid-market company processing 30 million tokens monthly saves approximately $100,000 annually by switching from large model APIs to Mistral Small 3.
Conclusion
The small model revolution: why Phi-4, Mistral, and lightweight LLMs are winning in 2026 represents a fundamental shift in how organizations deploy AI. The economics are undeniable: 50-70% cost reduction, 3× faster inference, and deployment on accessible hardware—all while maintaining quality for 80% of use cases[1].
For most teams, the question is no longer whether to adopt small models, but how quickly to migrate appropriate workloads. The organizations winning in 2026 aren’t those with the largest models, but those with the smartest model selection strategies—routing each task to the right-sized model for optimal performance-per-dollar.
Next Steps
1. Audit your current AI use cases
- Identify high-volume, well-defined tasks suitable for small models
- Calculate current costs (API fees, infrastructure, latency impact)
- Prioritize migration candidates based on potential savings
2. Run comparative benchmarks
- Test Phi-4 and Mistral Small 3 on actual production data
- Measure quality, latency, and cost differences
- Determine which use cases can migrate without quality loss
3. Implement a hybrid architecture
- Deploy routing layer to send appropriate requests to small models
- Start with 10% of traffic, scale based on metrics
- Keep large models available for complex cases
4. Optimize and scale
- Fine-tune small models on proprietary data
- Monitor performance continuously
- Reinvest savings into data quality and model improvements
The shift toward lightweight LLMs isn’t a temporary trend—it’s the new standard for production AI deployment. Organizations that adapt quickly gain competitive advantages in cost structure, deployment flexibility, and speed to market.
For teams looking to navigate this transition effectively, understanding how to manage multiple AI models becomes a core competency. Explore how MULTIBLY helps organizations choose the right AI for each specific task, optimize costs, and build sustainable AI strategies. Contact us to learn how your team can benefit from the small model revolution.
References
[1] Top 10 Open Source Llms The Deepseek Revolution 2026 – https://o-mega.ai/articles/top-10-open-source-llms-the-deepseek-revolution-2026
[2] The Big Llm Architecture Comparison – https://magazine.sebastianraschka.com/p/the-big-llm-architecture-comparison
[3] Best Llm – https://zapier.com/blog/best-llm/
[4] Top Llm Models And Applications – https://www.wpwebelite.com/blog/top-llm-models-and-applications/
[5] The Best Open Source Small Language Models – https://www.bentoml.com/blog/the-best-open-source-small-language-models
[8] Slm Vs Llm Why Bigger Is Better Is Dead In 2026 Ab5f7d6b4f45 – https://ai.gopubby.com/slm-vs-llm-why-bigger-is-better-is-dead-in-2026-ab5f7d6b4f45



