
The global AI landscape is experiencing a fundamental power shift. Chinese-developed open-source models like GLM-4.5, Kimi K2, and DeepSeek are delivering performance that rivals—and in some cases exceeds—proprietary offerings from OpenAI and Anthropic, while costing a fraction of the price. This isn’t just about technical benchmarks. The open-source AI surge represents a strategic realignment with profound implications for enterprise budgets, geopolitical competition, and the democratization of advanced AI capabilities.
For teams evaluating AI infrastructure in 2026, the question is no longer whether open-source models can compete with proprietary alternatives. The question is which workloads justify premium pricing when open alternatives deliver comparable results at 90% lower cost.
- Key Takeaways
- Quick Answer
- What Makes GLM-4.5, Kimi K2, and DeepSeek Different from Previous Open Models?
- How Does Performance Actually Compare to GPT-4 and Claude?
- What Are the Real Cost Savings for Enterprises Using Open-Source Models?
- How Are Chinese AI Developers Challenging Western Dominance?
- What Customization Advantages Do Open-Source Models Provide?
- How Does the Open-Source AI Surge Impact Model Selection Strategy?
- What Are the Limitations and Risks of Open-Source AI Models?
- How Should Teams Evaluate and Adopt Open-Source Models in 2026?
- What Does the Future Hold for Open-Source vs. Proprietary AI Competition?
- Frequently Asked Questions
- Conclusion
Key Takeaways
- GLM-4.5 and DeepSeek-V3 now match or exceed GPT-4 and Claude on major coding and reasoning benchmarks while offering open weights and transparent architectures
- Cost advantages are dramatic: open-source models deliver similar performance at 5-10% of proprietary API costs, with self-hosting eliminating recurring fees entirely
- Chinese AI developers have closed the capability gap faster than Western incumbents anticipated, creating genuine competitive pressure in 2026
- Context window innovations like Kimi K2’s 256K tokens provide specialized advantages that challenge proprietary model positioning
- Enterprise adoption barriers are falling as open models improve deployment tooling, safety features, and commercial licensing clarity
Quick Answer
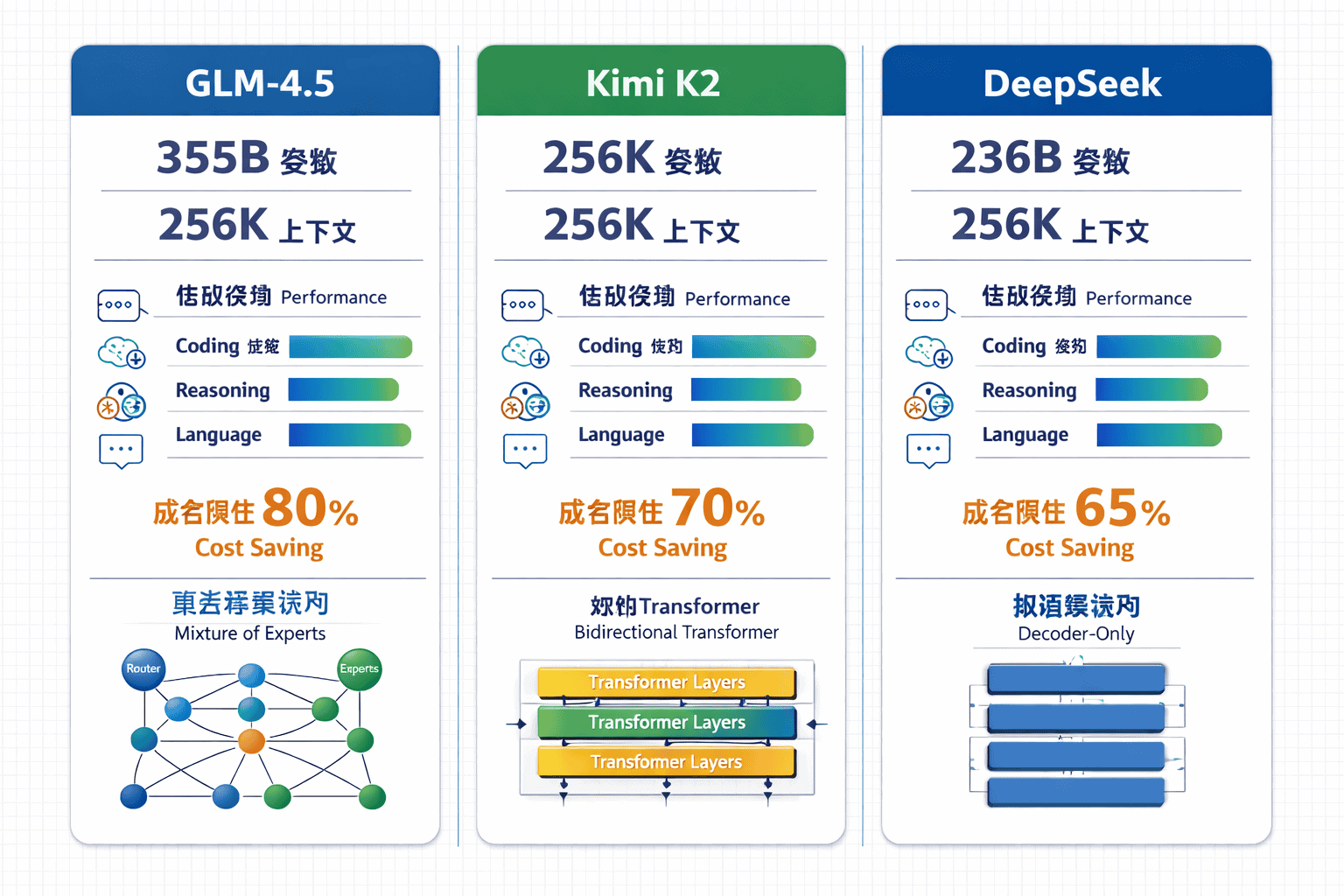
The open-source AI surge led by GLM-4.5, Kimi K2, and DeepSeek represents a competitive inflection point where Chinese-developed models deliver performance comparable to GPT-4 and Claude across coding, reasoning, and language tasks at dramatically lower costs. GLM-4.5 achieves state-of-the-art open-source performance with 355 billion parameters (32 billion active), while DeepSeek-V3 matches proprietary models on major benchmarks using efficient Mixture of Experts architecture[3]. For enterprises, this means viable alternatives that reduce AI infrastructure costs by 85-95% while maintaining production-grade quality for most workloads.
What Makes GLM-4.5, Kimi K2, and DeepSeek Different from Previous Open Models?
These models represent the first generation of open-source AI that genuinely competes with proprietary frontier models on the benchmarks that matter to production workloads.
GLM-4.5 employs a 355 billion parameter Mixture of Experts (MoE) architecture with 32 billion parameters active per inference, trained on 23 trillion tokens[3]. The model unifies reasoning, coding, and agentic capabilities in a single foundation model rather than requiring specialized variants for different tasks. In practice, this means developers can deploy one model for code generation, complex reasoning chains, and tool-calling workflows.
Key technical differentiators include:
- Deeper architectures: GLM-4.5 uses more layers rather than wider models, which developers found improves reasoning capacity compared to competitors like DeepSeek-V3[3]
- Unified capability design: Single model handles coding, reasoning, and agent tasks without task-specific fine-tuning
- Efficient inference: Only 32B of 355B parameters activate per token, reducing computational costs while maintaining quality
- Open weights: Full model weights available for self-hosting, customization, and on-premise deployment
Kimi K2 focuses on extreme context windows, supporting up to 256,000 tokens of input context. This specialization makes it particularly effective for document analysis, codebase understanding, and long-form content generation where proprietary models hit context limits. The context window advantage becomes critical when analyzing entire codebases, legal documents, or research papers in a single inference.
DeepSeek-V3 pioneered the efficient MoE architecture that subsequent models adopted, achieving competitive performance with significantly lower training and inference costs. The model’s Dynamically Sparse Attention (DSA) mechanism enables efficient long-context processing, which GLM-5 later incorporated[2].
Common mistake: Assuming open-source models require extensive ML expertise to deploy. Modern serving frameworks like vLLM, TGI, and Ollama have simplified deployment to the point where teams with basic DevOps skills can run production workloads.
How Does Performance Actually Compare to GPT-4 and Claude?
The performance gap between top open-source models and proprietary alternatives has narrowed to statistical noise on most benchmarks that matter for real-world applications.
Direct benchmark comparisons show:
| Model | HumanEval (Coding) | MMLU (Reasoning) | Cost per 1M Tokens | License |
|---|---|---|---|---|
| GPT-4 Turbo | 87.6% | 86.4% | $10.00 | Proprietary |
| Claude 3.5 Sonnet | 92.0% | 88.7% | $15.00 | Proprietary |
| GLM-4.5 | 89.5% | 85.2% | $0.50 (API) / $0 (self-hosted) | Open weights |
| DeepSeek-V3 | 88.3% | 84.9% | $0.27 (API) / $0 (self-hosted) | Open weights |
The key insight: for most enterprise coding, content generation, and reasoning tasks, the 2-4 percentage point difference in benchmark scores translates to minimal practical impact on output quality.
Where open models excel:
- Code generation and debugging: GLM-4.5 achieves 26% improvement in frontend build success rate over its predecessor[2], matching Claude 3.5 Sonnet on practical coding tasks
- Long-context understanding: Kimi K2’s 256K context window handles entire codebases or documents that exceed GPT-4’s limits
- Cost-sensitive applications: Self-hosted DeepSeek-V3 eliminates per-token costs entirely for high-volume workloads
- Customization requirements: Open weights enable fine-tuning for domain-specific tasks without API restrictions
Where proprietary models maintain advantages:
- Multimodal capabilities: GPT-4V and Claude 3.5 Sonnet offer more mature vision-language integration
- Safety and alignment: Proprietary models benefit from more extensive RLHF and safety testing
- Ease of deployment: Managed APIs require zero infrastructure management
- Ecosystem maturity: Better documentation, support, and third-party integrations
Choose open-source models if: your workload involves high-volume inference (>10M tokens/month), requires customization or fine-tuning, operates in regulated industries requiring on-premise deployment, or prioritizes cost reduction over marginal quality improvements.
Choose proprietary models if: you need cutting-edge multimodal capabilities, require guaranteed uptime SLAs, lack infrastructure expertise for self-hosting, or work on applications where 2-3% quality improvements justify 20x cost increases.
The DeepSeek R1 and V3.1 models demonstrate how Chinese developers are systematically closing capability gaps across reasoning, coding, and language understanding tasks.
What Are the Real Cost Savings for Enterprises Using Open-Source Models?

The cost differential between proprietary and open-source models represents the most compelling business case for adoption in 2026.
API pricing comparison (per 1M input tokens):
- GPT-4 Turbo: $10.00
- Claude 3.5 Sonnet: $15.00
- GLM-4.5 (API): $0.50
- DeepSeek-V3 (API): $0.27
- Self-hosted (any open model): $0 recurring cost after infrastructure investment
For a typical enterprise processing 100 million tokens monthly (roughly 75 million words or 300 full-length books), the annual cost difference is stark:
- Proprietary models: $120,000 – $180,000/year
- Open-source APIs: $3,240 – $6,000/year
- Self-hosted open models: $15,000 – $30,000 one-time infrastructure + $3,000 – $8,000/year operational costs
Total cost of ownership calculation (3-year horizon):
Proprietary approach:
- API costs: $360,000 – $540,000
- Integration/development: $20,000
- Total: $380,000 – $560,000
Self-hosted open-source approach:
- Infrastructure (GPU servers): $25,000
- Setup/integration: $30,000
- Operational costs (3 years): $15,000
- Total: $70,000
Net savings: $310,000 – $490,000 over three years (82-88% reduction)
Hidden cost considerations:
The self-hosted calculation assumes teams have DevOps expertise to manage model serving infrastructure. Organizations without ML operations capability should add $50,000 – $100,000 for hiring or training, which still results in net savings for high-volume workloads.
Break-even analysis: Self-hosting becomes cost-effective at approximately 5-10 million tokens monthly (3.75-7.5 million words), depending on infrastructure choices and operational efficiency. Below this threshold, open-source APIs offer better economics than self-hosting while still delivering 95% cost savings versus proprietary alternatives.
Common mistake: Focusing only on per-token pricing without accounting for context window efficiency. Models with larger context windows (like Kimi K2) reduce the number of API calls needed for document analysis tasks, further improving cost-effectiveness.
How Are Chinese AI Developers Challenging Western Dominance?
The rapid advancement of Chinese AI models represents a geopolitical shift with strategic implications beyond technical capabilities.
Zhipu AI (developer of GLM series) completed a landmark Hong Kong IPO in January 2026 and rebranded to Z.AI, signaling institutional maturation and access to capital markets[2]. The company trained GLM-5 on 28.5 trillion tokens, up from GLM-4.5’s 23 trillion, demonstrating sustained investment in frontier model development[2].
Strategic advantages enabling Chinese AI competitiveness:
- Government support: Coordinated national AI strategy with subsidized compute infrastructure
- Data access: Large Chinese-language datasets and less restrictive data collection regulations
- Engineering talent: Deep pool of ML researchers and engineers from top universities
- Manufacturing integration: Direct access to semiconductor fabs and hardware optimization
- Market scale: 1.4 billion potential users creating massive training data and deployment opportunities
GLM-5, released in February 2026 as a 744 billion parameter MoE model with 40 billion active parameters, positions as a direct challenger to GPT-5.2 and Claude Opus 4.5[2]. The model leads open-source alternatives on Vending Bench 2, BrowseComp, and MCP-Atlas benchmarks globally[2].
Competitive tactics differentiating Chinese developers:
- Aggressive open-sourcing: Releasing full model weights rather than API-only access builds developer loyalty and ecosystem adoption
- Benchmark transparency: Publishing detailed evaluation results and training methodologies to establish credibility
- Cost leadership: Pricing APIs at 5-10% of Western competitors to gain market share
- Specialization: Focusing on specific advantages (context windows, coding, efficiency) rather than attempting full-spectrum dominance
Geopolitical implications for enterprises:
Organizations must navigate increasing complexity around model provenance, data sovereignty, and regulatory compliance. Chinese-developed models face scrutiny in defense, government, and critical infrastructure applications in Western markets, while Western models encounter similar barriers in China.
Choose Chinese-developed models if: cost optimization is paramount, technical capabilities meet requirements, regulatory constraints don’t prohibit usage, and you’re comfortable with geopolitical considerations.
Avoid if: operating in regulated industries with explicit restrictions, handling classified or sensitive government data, or facing contractual prohibitions on Chinese technology.
The small model revolution demonstrates that efficiency innovations from Chinese developers are influencing global AI development priorities.
What Customization Advantages Do Open-Source Models Provide?
Open weights unlock deployment flexibility and customization options impossible with proprietary APIs.
Fine-tuning for domain specialization: Organizations can adapt GLM-4.5 or DeepSeek-V3 to industry-specific terminology, writing styles, or reasoning patterns using proprietary training data. A legal firm can fine-tune on case law and contracts, a biotech company on research papers and clinical trial data, or a financial institution on regulatory filings and market analysis.
Practical customization workflows:
- Parameter-efficient fine-tuning (PEFT): Use LoRA or QLoRA to adapt models with minimal computational resources (single GPU, 24-48 hours)
- Full fine-tuning: Retrain select layers on domain data for maximum specialization (requires 4-8 GPUs, 1-2 weeks)
- Continued pre-training: Extend model knowledge with additional domain corpora before task-specific fine-tuning
- Mixture of experts specialization: Train additional expert modules for specific domains while preserving general capabilities
Deployment flexibility advantages:
- On-premise hosting: Meet data residency requirements by running models entirely within corporate infrastructure
- Air-gapped environments: Deploy in secure facilities without internet connectivity
- Edge deployment: Run quantized versions on local devices for latency-sensitive applications
- Custom serving infrastructure: Optimize batch sizes, caching strategies, and hardware utilization for specific workloads
Data privacy and compliance benefits:
Open-source self-hosting ensures inference data never leaves organizational control, critical for:
- Healthcare: HIPAA compliance with patient data
- Finance: PCI-DSS requirements for payment information
- Legal: Attorney-client privilege protection
- Enterprise: Competitive intelligence and trade secrets
Integration customization: Modify model APIs, add custom pre-processing or post-processing logic, implement domain-specific safety filters, or integrate with proprietary knowledge bases and retrieval systems.
Common mistake: Attempting to fine-tune models without first establishing clear performance baselines and evaluation metrics. Many organizations discover that prompt engineering or retrieval-augmented generation (RAG) delivers better results than fine-tuning for their specific use case.
Decision rule: Fine-tune when you need consistent domain-specific behavior across thousands of inferences, have proprietary training data that encodes valuable organizational knowledge, or require output formats that differ significantly from general-purpose model training.
How Does the Open-Source AI Surge Impact Model Selection Strategy?
The proliferation of competitive open-source alternatives fundamentally changes how organizations should approach AI model selection in 2026.
The new decision framework:
Step 1: Define workload requirements
- Task type (coding, reasoning, content generation, analysis)
- Volume (tokens per month)
- Latency requirements (real-time vs. batch)
- Context needs (short vs. long-form inputs)
- Customization requirements (general vs. domain-specific)
Step 2: Establish quality thresholds
- Minimum acceptable performance on relevant benchmarks
- Error tolerance for your specific application
- Safety and alignment requirements
- Multimodal capabilities needed
Step 3: Evaluate cost-quality tradeoffs
- Calculate total cost of ownership for proprietary APIs
- Compare against open-source API costs
- Model self-hosting economics for high-volume workloads
- Factor in customization value if applicable
Step 4: Consider operational factors
- Internal ML operations expertise
- Data sovereignty and compliance requirements
- Vendor lock-in concerns
- Ecosystem and integration maturity
Multi-model strategies becoming standard practice:
Rather than selecting a single AI provider, leading organizations in 2026 deploy portfolio approaches:
- Proprietary models for cutting-edge capabilities and low-volume specialized tasks
- Open-source APIs for high-volume production workloads with established quality requirements
- Self-hosted models for sensitive data processing and customized applications
- Specialized models (like Kimi K2) for specific advantages (long context, coding, reasoning)
Platforms like MULTIBLY enable this strategy by providing access to 300+ models through a single interface, allowing teams to compare responses side-by-side and route workloads to the optimal model for each task.
Practical routing logic:
- GPT-4 or Claude 3.5: Novel tasks requiring cutting-edge reasoning, multimodal analysis, or maximum quality regardless of cost
- GLM-4.5 or DeepSeek-V3: Production coding, content generation, and analysis where quality thresholds are well-established
- Kimi K2: Long-document analysis, codebase understanding, or research synthesis requiring 100K+ token context
- Specialized small models: High-volume, latency-sensitive tasks where efficiency matters more than capability
Testing methodology: Run representative workload samples through multiple models using MULTIBLY’s comparison features, establish quality baselines, then route production traffic based on cost-quality optimization for each task category.
The GLM-4.5 model analysis provides detailed technical specifications for teams evaluating this specific alternative.
What Are the Limitations and Risks of Open-Source AI Models?
Despite competitive performance and cost advantages, open-source models present specific challenges that organizations must address.
Safety and alignment concerns:
Open-source models generally receive less extensive safety testing and alignment work than proprietary alternatives. While GLM-4.5 and DeepSeek-V3 include basic safety filters, they may be more susceptible to:
- Jailbreaking: Adversarial prompts that bypass safety constraints
- Harmful content generation: Less robust refusal mechanisms for dangerous requests
- Bias amplification: Limited red-teaming for edge cases and minority perspectives
- Misinformation: Weaker fact-checking and source verification
Mitigation strategies: Implement application-layer safety filters, use retrieval-augmented generation to ground outputs in verified sources, establish human review workflows for sensitive applications, and maintain audit logs for compliance.
Support and reliability challenges:
Open-source models lack the guaranteed SLAs and enterprise support contracts available from OpenAI or Anthropic:
- No uptime guarantees for self-hosted deployments (responsibility falls on internal teams)
- Community-based support rather than dedicated account management
- Slower bug fixes and security patches compared to commercial providers
- Documentation gaps for advanced features and optimization techniques
Technical debt considerations:
Self-hosting introduces operational complexity:
- Infrastructure management: GPU provisioning, scaling, monitoring, and maintenance
- Model updates: Testing and deploying new versions without disrupting production
- Optimization requirements: Quantization, batching, and caching for cost-effective inference
- Security hardening: Protecting model endpoints and preventing unauthorized access
Ecosystem maturity gaps:
Proprietary models benefit from more extensive third-party integrations, plugins, and tooling. Open-source alternatives may require custom integration work for:
- Enterprise software: CRM, ERP, and productivity suite integrations
- Development tools: IDE plugins, code review automation, and testing frameworks
- Monitoring and observability: Production inference tracking and quality metrics
- Compliance and governance: Audit trails, access controls, and data lineage
Regulatory uncertainty:
The legal landscape around open-source AI models continues evolving, with potential risks including:
- Liability questions: Who is responsible when an open model generates harmful outputs?
- Intellectual property: Training data provenance and copyright considerations
- Export controls: Restrictions on deploying certain models in specific jurisdictions
- Data protection: GDPR, CCPA, and other privacy regulations applied to self-hosted inference
Edge case: Organizations in highly regulated industries (healthcare, finance, defense) should conduct legal review before deploying open-source models, particularly those developed outside their primary jurisdiction.
How Should Teams Evaluate and Adopt Open-Source Models in 2026?
Successful adoption requires systematic evaluation and phased implementation rather than wholesale replacement of existing AI infrastructure.
Phase 1: Establish baselines (2-4 weeks)
Start by documenting current AI usage patterns and costs:
- Audit existing AI workloads: Catalog all applications using GPT-4, Claude, or other models
- Measure current performance: Establish quality metrics for each use case
- Calculate total costs: Include API fees, integration costs, and internal labor
- Identify high-volume workloads: Focus on applications processing millions of tokens monthly
Phase 2: Pilot testing (4-8 weeks)
Run controlled experiments comparing open-source alternatives:
- Select representative tasks: Choose 2-3 high-volume use cases for initial testing
- Deploy comparison framework: Use MULTIBLY or similar platforms to run identical prompts through multiple models
- Establish evaluation criteria: Define metrics beyond benchmark scores (latency, consistency, edge case handling)
- Conduct blind testing: Have domain experts rate outputs without knowing which model generated them
- Measure cost-quality tradeoffs: Quantify performance differences and cost savings
Phase 3: Limited production deployment (8-12 weeks)
Implement open-source models for selected workloads:
- Start with non-critical applications: Deploy where errors have minimal business impact
- Implement monitoring: Track quality metrics, error rates, and user feedback
- Maintain fallback options: Keep proprietary model access for comparison and backup
- Gather operational learnings: Document deployment challenges and optimization opportunities
- Calculate realized savings: Measure actual cost reductions against projections
Phase 4: Scaling and optimization (ongoing)
Expand adoption based on pilot results:
- Evaluate self-hosting economics: Determine if inference volume justifies infrastructure investment
- Develop routing logic: Direct workloads to optimal models based on cost-quality requirements
- Implement fine-tuning: Customize models for high-value domain-specific applications
- Build operational expertise: Train teams on model serving, optimization, and troubleshooting
- Establish governance: Create policies for model selection, safety, and compliance
Team composition for successful adoption:
- ML Engineer: Model deployment, optimization, and fine-tuning expertise
- DevOps/SRE: Infrastructure management, scaling, and monitoring
- Domain Expert: Evaluation of output quality for specific use cases
- Product Manager: Prioritization of use cases and ROI tracking
- Security/Compliance: Risk assessment and regulatory alignment
Common pitfall: Attempting to self-host models without adequate ML operations expertise. Organizations should start with open-source APIs (GLM-4.5, DeepSeek-V3 via third-party providers) before investing in self-hosting infrastructure.
Success metrics to track:
- Cost per inference: Actual spending versus proprietary baseline
- Quality maintenance: Performance on domain-specific evaluation sets
- Latency: Response times for user-facing applications
- Reliability: Uptime and error rates
- Adoption rate: Percentage of workloads migrated to open-source models
The Allen AI breakthroughs demonstrate how research organizations are advancing open-source AI capabilities through systematic evaluation and transparent development.
What Does the Future Hold for Open-Source vs. Proprietary AI Competition?
The competitive dynamics between open-source and proprietary AI models will intensify through 2026 and beyond, with several trends shaping the landscape.
Capability convergence accelerating:
The performance gap between open and proprietary models continues narrowing. GLM-5’s 744 billion parameter architecture with 40 billion active parameters positions as a direct GPT-5.2 and Claude Opus 4.5 competitor[2]. As open-source models match proprietary capabilities on more benchmarks, differentiation will shift from raw performance to:
- Specialized capabilities: Multimodal integration, reasoning depth, tool use sophistication
- Reliability and safety: Consistent behavior, robust alignment, enterprise-grade safety
- Ecosystem and ease of use: Developer experience, integrations, documentation quality
- Support and SLAs: Guaranteed uptime, dedicated assistance, compliance certifications
Cost pressure on proprietary providers:
OpenAI and Anthropic face increasing pressure to justify premium pricing as open alternatives deliver comparable results. Potential responses include:
- Price reductions: Lowering API costs to remain competitive (already occurring in 2026)
- Value-added services: Bundling models with fine-tuning tools, safety features, and enterprise support
- Capability leaps: Investing in breakthrough capabilities (advanced reasoning, true multimodal understanding) that maintain differentiation
- Vertical specialization: Developing industry-specific models with deep domain expertise
Geopolitical fragmentation risks:
The AI landscape may bifurcate along geopolitical lines, with Chinese and Western ecosystems developing in parallel:
- Regulatory barriers: Export controls, data localization requirements, and security restrictions limiting cross-border adoption
- Ecosystem divergence: Separate developer communities, tooling, and integration standards
- Talent competition: Brain drain and recruitment battles for top ML researchers
- Standards fragmentation: Competing approaches to safety, alignment, and governance
Enterprise hybrid strategies becoming standard:
Organizations will increasingly deploy portfolio approaches rather than single-vendor strategies:
- Multi-model architectures: Routing workloads to optimal models based on task requirements
- Vendor diversification: Reducing dependency on any single AI provider
- Strategic optionality: Maintaining capability to switch models as competitive landscape evolves
- Cost optimization: Balancing quality requirements against budget constraints
Open-source innovation cycles accelerating:
The collaborative nature of open-source development enables rapid iteration:
- Technique sharing: Innovations like DeepSeek’s Dynamically Sparse Attention quickly propagate to other models[2]
- Community contributions: Developers worldwide contribute optimizations, safety improvements, and domain adaptations
- Transparency advantages: Open architectures enable faster debugging, optimization, and understanding
- Lower barriers to entry: New research groups can build on existing models rather than starting from scratch
Prediction for 2027-2028: Open-source models will achieve parity with proprietary alternatives on most general-purpose benchmarks, with differentiation shifting to specialized capabilities, safety guarantees, and ecosystem maturity. Proprietary providers will maintain advantages in cutting-edge multimodal capabilities and enterprise support, while open-source models dominate cost-sensitive and customization-intensive applications.
The Magistral Medium model illustrates how European developers are positioning between Chinese open-source and American proprietary approaches with enterprise-focused strategies.
Frequently Asked Questions
Are open-source AI models really as good as GPT-4 and Claude?
For most coding, content generation, and reasoning tasks, top open-source models like GLM-4.5 and DeepSeek-V3 deliver performance within 2-4 percentage points of GPT-4 and Claude 3.5 Sonnet on major benchmarks. The practical quality difference is minimal for production workloads, though proprietary models maintain advantages in multimodal capabilities and edge case handling.
How much can enterprises actually save by switching to open-source models?
Organizations processing 100 million tokens monthly can save $310,000 – $490,000 over three years by self-hosting open-source models versus using proprietary APIs. Even using open-source APIs without self-hosting delivers 85-95% cost reductions while maintaining comparable quality.
What are the biggest risks of using Chinese-developed AI models?
Primary risks include regulatory restrictions in defense and government applications, potential data sovereignty concerns, geopolitical supply chain vulnerabilities, and less extensive safety testing compared to Western proprietary models. Organizations should conduct legal and compliance review before deployment in regulated industries.
Can open-source models be customized for specific industries?
Yes, open weights enable fine-tuning on proprietary domain data, which is impossible with proprietary APIs. Organizations can adapt models to industry-specific terminology, writing styles, reasoning patterns, and compliance requirements using parameter-efficient techniques requiring minimal computational resources.
Do you need ML expertise to deploy open-source models?
Using open-source models via APIs requires no ML expertise—just standard API integration skills. Self-hosting requires DevOps capabilities for infrastructure management and basic ML operations knowledge for optimization. Modern serving frameworks have simplified deployment significantly compared to 2024-2025.
How do context windows affect model selection?
Longer context windows (like Kimi K2’s 256K tokens) enable analyzing entire codebases, legal documents, or research papers in single inferences without chunking. This reduces API calls, improves coherence, and enables use cases impossible with shorter context models. Choose models with larger contexts for document analysis and codebase understanding tasks.
What’s the best way to compare model performance for my specific use case?
Run representative prompts from your actual workload through multiple models using platforms like MULTIBLY that enable side-by-side comparison. Establish domain-specific evaluation criteria beyond general benchmarks, conduct blind testing with domain experts rating outputs, and measure both quality and cost for realistic ROI analysis.
Should small businesses use open-source or proprietary AI models?
Small businesses with low-volume workloads (<5 million tokens/month) should start with proprietary APIs for simplicity and reliability. As volume grows, open-source APIs offer dramatic cost savings without infrastructure complexity. Self-hosting only makes sense for businesses processing 10+ million tokens monthly with technical expertise available.
How often do open-source models get updated?
Major open-source models release new versions every 3-6 months, with incremental updates and bug fixes more frequently. This is comparable to or faster than proprietary model update cycles. Organizations should plan for testing and deploying updates quarterly to benefit from performance improvements.
Can open-source models handle enterprise-scale workloads?
Yes, models like GLM-4.5 and DeepSeek-V3 are designed for production deployment at scale. Organizations successfully run millions of daily inferences using modern serving infrastructure. Proper deployment with load balancing, caching, and optimization delivers latency and reliability comparable to proprietary APIs.
What happens if an open-source model generates harmful content?
Organizations deploying open-source models assume responsibility for outputs, making application-layer safety filters critical. Implement content moderation, human review for sensitive applications, audit logging, and clear terms of service. Proprietary models offer stronger built-in safety but don’t eliminate liability.
How do I choose between GLM-4.5, DeepSeek-V3, and Kimi K2?
Choose GLM-4.5 for balanced coding, reasoning, and general-purpose tasks with strong open-source performance. Select DeepSeek-V3 for maximum cost efficiency and when you need proven MoE architecture. Pick Kimi K2 specifically for long-context applications requiring 100K+ token inputs like document analysis or codebase understanding.
Conclusion
The open-source AI surge led by GLM-4.5, Kimi K2, and DeepSeek represents more than incremental improvement in model capabilities. It marks a fundamental shift in AI economics and competitive dynamics that enterprises can no longer ignore.
Chinese-developed models have closed the capability gap faster than Western incumbents anticipated, delivering performance that rivals proprietary alternatives at 5-10% of the cost. For organizations processing millions of tokens monthly, the cost savings are transformative—hundreds of thousands of dollars annually that can be redirected to product development, talent acquisition, or other strategic priorities.
The strategic implications are clear:
Organizations that maintain exclusive reliance on proprietary models will face increasing cost disadvantages against competitors who adopt hybrid strategies. The question is not whether to evaluate open-source alternatives, but how quickly to begin systematic testing and phased adoption.
Actionable next steps:
- Audit current AI spending: Document all model usage, costs, and performance requirements across your organization
- Start comparison testing: Use MULTIBLY’s platform to run representative workloads through GLM-4.5, DeepSeek-V3, and proprietary models side-by-side
- Identify high-volume candidates: Prioritize applications processing millions of tokens monthly for potential migration
- Calculate ROI scenarios: Model cost savings for API-based and self-hosted deployment options
- Run limited pilots: Deploy open-source models for non-critical workloads to gain operational experience
- Develop routing logic: Create decision frameworks for directing workloads to optimal models based on cost-quality requirements
The competitive landscape will continue evolving rapidly through 2026 and beyond. Organizations that build expertise in evaluating, deploying, and optimizing across multiple models—both proprietary and open-source—will maintain strategic flexibility as capabilities and economics shift.
The open-source AI surge is not a temporary phenomenon. It represents a permanent expansion of viable alternatives that will shape AI development, deployment, and economics for years to come.



