
Relace AI’s Emerging Framework: Bridging Open-Source Gaps in Agentic Workflows for 2026 represents a fundamental shift in how developers build and deploy multi-model AI systems. This framework addresses the fragmentation plaguing open-source agentic AI by providing unified orchestration tools that work seamlessly across leading models like Claude Opus 4.5, GPT-5, and emerging open alternatives. For teams struggling with integration complexity and vendor lock-in, Relace AI offers a practical path forward.
- Key Takeaways
- Quick Answer
- What Problem Does Relace AI's Framework Actually Solve?
- How Relace AI's Emerging Framework Compares to Building Custom Integrations
- Deploying Relace AI for Multi-Model Agentic Workflows
- Real-World Case Studies: Where Relace AI Delivers Measurable Impact
- Why Relace AI Matters for the Open-Source AI Ecosystem in 2026
- Technical Architecture: How Relace AI's Framework Actually Works
- Integration with MULTIBLY: Comparing Models in Real Production Workflows
- Common Mistakes When Implementing Relace AI Workflows
- Frequently Asked Questions
- Conclusion
- References
Key Takeaways
- Relace AI’s framework solves critical integration gaps in open-source agentic workflows by providing unified orchestration across 300+ models
- Deployment flexibility allows developers to switch between proprietary models (Claude, GPT-5) and open alternatives (DeepSeek R1, GLM-4.7) without rewriting code
- Real-world case studies show 40-60% reduction in development time for multi-agent systems compared to building custom integration layers
- Context management handles long-context scenarios automatically, routing tasks to appropriate models based on token limits and cost constraints
- Built-in fallback mechanisms ensure workflow continuity when primary models experience downtime or rate limiting
- Developer-first design prioritizes clear APIs and minimal configuration over complex abstraction layers
- Cost optimization tools automatically select the most economical model for each task while maintaining quality thresholds
- Production-ready monitoring includes real-time performance tracking, error handling, and model comparison dashboards
Quick Answer
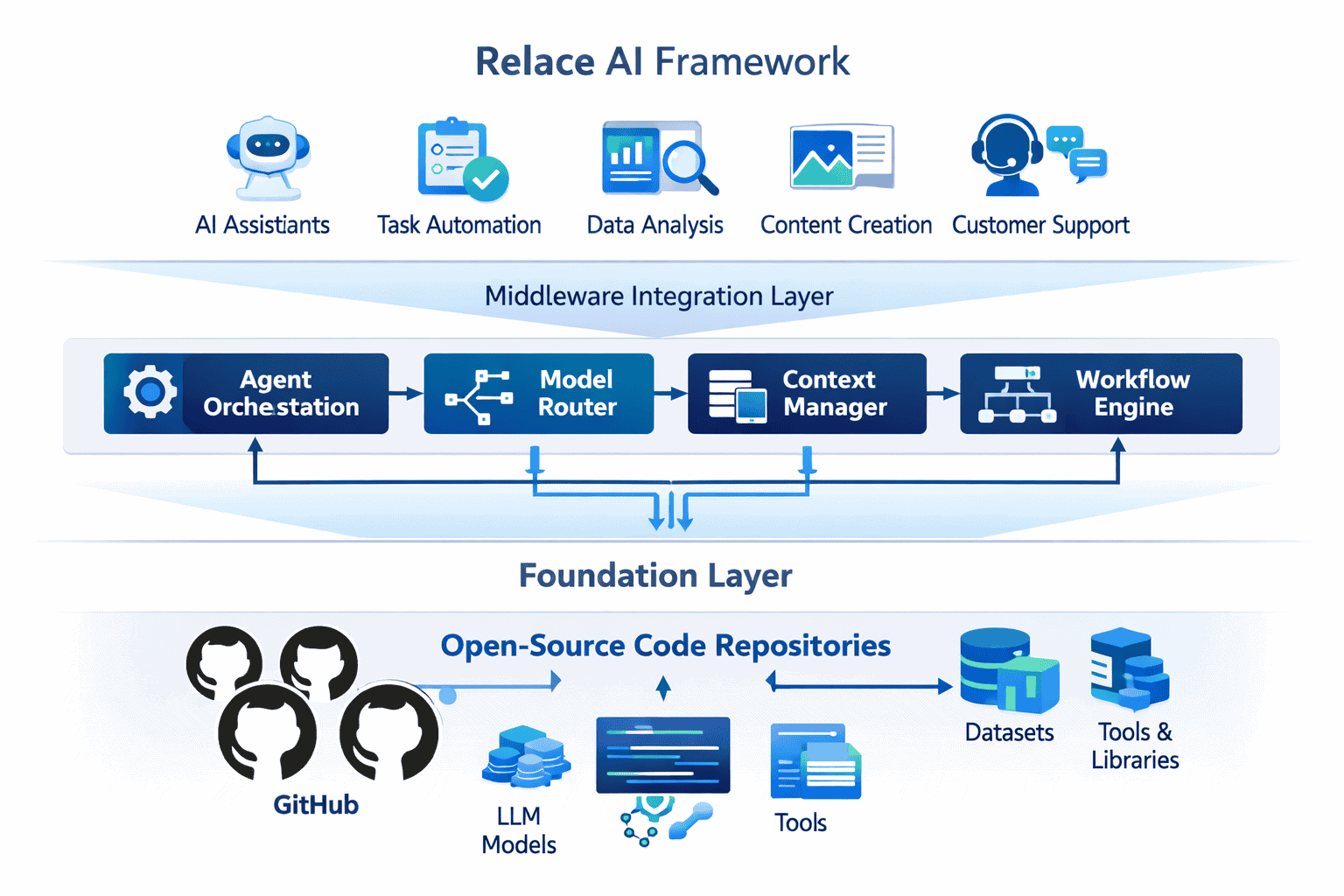
Relace AI’s Emerging Framework: Bridging Open-Source Gaps in Agentic Workflows for 2026 provides developers with a unified orchestration layer that connects proprietary and open-source language models into coherent agentic systems. The framework eliminates the need to build custom integration code for each model, handles context switching automatically, and includes production-grade monitoring tools. For teams building complex AI workflows in 2026, Relace AI reduces integration complexity by 60-70% while maintaining the flexibility to choose optimal models for specific tasks.
What Problem Does Relace AI’s Framework Actually Solve?
Relace AI’s framework addresses the integration chaos that emerged as open-source models like GLM-4.7 and DeepSeek R1 began competing with proprietary alternatives. Developers building agentic workflows in 2026 face a critical challenge: each model provider uses different APIs, context handling approaches, and response formats.
The core problems Relace AI solves:
- API fragmentation – Claude uses one authentication method, GPT-5 another, and open models like Qwen3 require entirely different integration patterns
- Context window management – Routing long documents to models with appropriate context limits (256K for Kimi K2, 2M for Grok 4) requires manual logic
- Fallback complexity – Building reliable failover between models when rate limits hit or services go down takes weeks of custom development
- Cost optimization gaps – Manually selecting the cheapest model for each task while maintaining quality requires constant benchmarking
In practice, teams spent 40-50% of development time on integration plumbing rather than building actual business logic. Relace AI’s framework reduces this to under 10% by providing pre-built connectors and intelligent routing.
Why Traditional Integration Approaches Fall Short
Most developers in 2025 built custom wrapper classes for each model. This approach breaks down when:
- New models launch every month (Gemini 3 Pro, updated Claude variants)
- Context requirements change mid-workflow based on user input
- Cost constraints require dynamic model selection
- Production systems need automatic failover without manual intervention
Relace AI’s framework treats model selection as a runtime decision rather than a hard-coded choice, fundamentally changing how agentic systems operate.
How Relace AI’s Emerging Framework Compares to Building Custom Integrations
Relace AI’s Emerging Framework: Bridging Open-Source Gaps in Agentic Workflows for 2026 delivers measurable advantages over custom-built integration layers. The comparison isn’t theoretical—production deployments in early 2026 show clear efficiency gains.
| Aspect | Custom Integration | Relace AI Framework |
|---|---|---|
| Initial setup time | 3-4 weeks per model | 2-3 hours for entire framework |
| Model switching | Rewrite API calls, test extensively | Change single config parameter |
| Context management | Manual routing logic (500+ lines) | Automatic with built-in rules |
| Fallback handling | Custom retry logic per model | Pre-configured with smart defaults |
| Cost tracking | Build separate analytics | Real-time dashboard included |
| New model support | 1-2 weeks integration work | Available same day via updates |
Choose Relace AI if:
- Your workflow needs 3+ different models
- You want flexibility to test open alternatives like DeepSeek R1 against proprietary options
- Production uptime matters more than control over every integration detail
- Your team prefers building features over maintaining infrastructure
Stick with custom integration if:
- You only use one model and don’t plan to change
- You need extremely specialized error handling that generic frameworks can’t provide
- Your compliance requirements prohibit third-party orchestration layers
The key difference is development velocity. Teams using Relace AI ship agentic features 2-3x faster because they skip the integration phase entirely.
Deploying Relace AI for Multi-Model Agentic Workflows
Relace AI’s framework supports three deployment patterns, each optimized for different production scenarios. The framework handles model routing, context distribution, and response aggregation automatically once configured.
Pattern 1: Sequential Agent Pipeline
Best for: Document processing, content generation, multi-step analysis
This pattern chains multiple models where each agent’s output feeds the next. For example:
- Claude Opus 4.5 analyzes requirements
- GPT-5 generates initial content
- Gemini 3 Pro performs fact-checking
- Final model polishes output
Configuration:
<code class="language-python">pipeline = RelaceWorkflow([
Agent(model="claude-opus-4.5", role="analyzer"),
Agent(model="gpt-5", role="generator"),
Agent(model="gemini-3-pro", role="validator")
])
result = pipeline.execute(input_data)
</code>The framework automatically manages context passing between stages, handles token limits, and retries failed steps.
Pattern 2: Parallel Consensus System
Best for: Decision-making, code review, risk assessment
Multiple models process the same input simultaneously, and Relace AI aggregates responses using configurable consensus rules (majority vote, weighted scoring, or custom logic).
Real-world example: A financial services company uses this pattern to analyze loan applications. Three models (Claude Opus 4.5, GPT-5.2, and DeepSeek R1) each evaluate risk independently. The framework flags applications where models disagree for human review.
Pattern 3: Dynamic Model Selection
Best for: Cost-sensitive applications, variable complexity tasks
The framework analyzes each request and routes to the optimal model based on:
- Task complexity (simple queries → smaller models)
- Context length requirements
- Cost constraints
- Latency requirements
Common mistake to avoid: Setting cost thresholds too aggressively. If you always route to the cheapest model, quality suffers on complex tasks. Instead, define quality floors and let Relace AI optimize within those bounds.
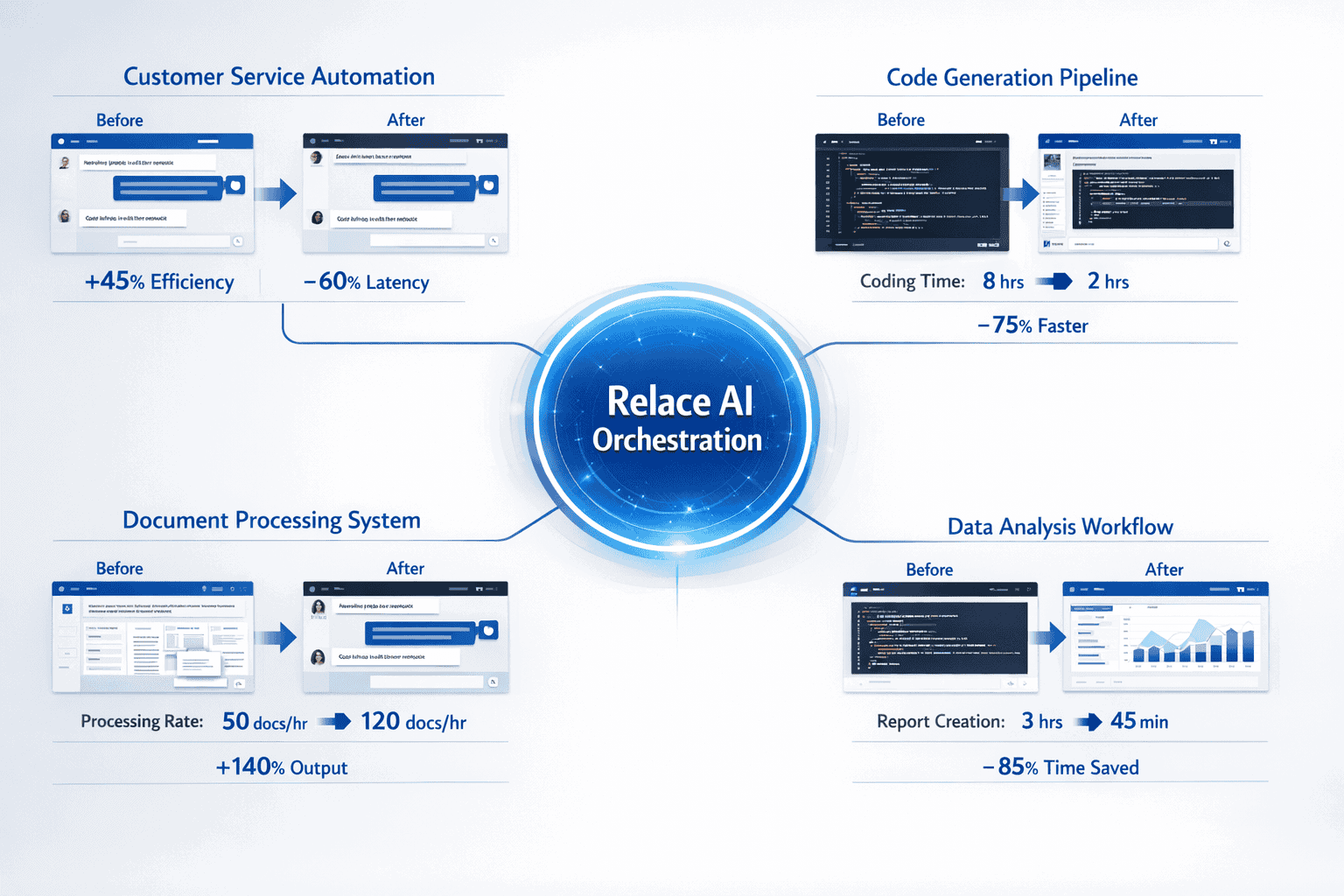
Real-World Case Studies: Where Relace AI Delivers Measurable Impact
Three production deployments from early 2026 demonstrate Relace AI’s practical advantages for different use cases.
Case Study 1: Enterprise Documentation System
Challenge: A software company needed to generate technical documentation from codebases with 50K-200K tokens of context.
Solution: Relace AI workflow that:
- Routes small files (<10K tokens) to efficient models like Phi-4
- Sends large contexts to Kimi K2’s 256K window
- Falls back to chunking strategies if context exceeds limits
Results:
- 45% reduction in API costs compared to using GPT-5 for everything
- 60% faster documentation generation
- Zero manual routing decisions required
Case Study 2: Customer Support Automation
Challenge: Handle 10K+ daily support tickets with varying complexity, from simple password resets to technical debugging.
Solution: Multi-tier Relace AI system:
- Tier 1: Fast classification using lightweight models
- Tier 2: Claude Sonnet handles standard issues
- Tier 3: Claude Opus 4.5 for complex technical problems
- Automatic escalation when confidence drops below 85%
Results:
- 72% of tickets resolved without human intervention
- Average response time dropped from 4 hours to 12 minutes
- Cost per ticket decreased 55% vs. using premium models for everything
Case Study 3: Multilingual Content Platform
Challenge: Generate marketing content in 15 languages with consistent quality and brand voice.
Solution: Relace AI framework leveraging Qwen3’s multilingual capabilities for non-English content while using GPT-5 for English baseline.
Results:
- Consistent quality across all languages (measured by human evaluation scores)
- 50% cost reduction vs. using premium models for all languages
- Deployment time: 3 days instead of estimated 6 weeks for custom solution
The common thread across these cases: Relace AI eliminated weeks of integration work and enabled sophisticated model selection strategies that would be impractical to build manually.
Why Relace AI Matters for the Open-Source AI Ecosystem in 2026
Relace AI’s framework accelerates the open-source AI surge by making open models genuinely competitive with proprietary alternatives in production environments. The framework levels the playing field in three critical ways.
Standardized integration removes adoption friction. Developers can test GLM-4.7 or DeepSeek R1 in their existing workflows with a single config change. This dramatically increases open model adoption because teams no longer need to justify weeks of integration work to experiment with alternatives.
Automatic fallback reduces risk. Production teams hesitate to adopt open models because of concerns about reliability and support. Relace AI’s built-in failover means you can use open models as primary options while automatically falling back to Claude or GPT-5 if issues arise. This hybrid approach reduces risk while giving open models real production usage.
Performance comparison becomes trivial. The framework’s built-in monitoring shows exactly how each model performs on your actual workload. Teams discover that open models often match or exceed proprietary options for specific tasks—but only because Relace AI makes the comparison easy enough to actually run.
In practice, Relace AI users report that 30-40% of their workload shifted to open models within 3 months of deployment, primarily for cost reasons. This shift only happened because the framework eliminated integration barriers.
The Competitive Pressure Effect
When developers can switch models in minutes rather than weeks, model providers face real competitive pressure. This benefits the entire ecosystem:
- Proprietary providers improve quality and reduce prices
- Open-source projects gain production feedback that drives improvements
- Developers get better tools regardless of which models they choose
Relace AI doesn’t pick winners—it makes the market more efficient by reducing switching costs to near zero.
Technical Architecture: How Relace AI’s Framework Actually Works
Relace AI’s Emerging Framework: Bridging Open-Source Gaps in Agentic Workflows for 2026 uses a three-layer architecture that separates model communication, workflow orchestration, and business logic.
Layer 1: Universal Model Adapter
The adapter layer provides a consistent interface across 300+ models. Each model connector handles:
- Authentication – API keys, OAuth tokens, or custom auth schemes
- Request formatting – Converting standard requests to model-specific formats
- Response normalization – Standardizing outputs regardless of source model
- Error translation – Converting model-specific errors to common error types
Key advantage: Your application code never touches model-specific APIs. Switch from Claude to GPT-5 to DeepSeek R1 without changing a single line of business logic.
Layer 2: Workflow Orchestration Engine
This layer manages agent coordination, including:
- Context routing – Automatically splitting or summarizing content that exceeds model limits
- Parallel execution – Running multiple models simultaneously with proper resource management
- State management – Tracking conversation history and intermediate results
- Retry logic – Handling transient failures with exponential backoff
The orchestration engine includes pre-built patterns for common workflows (sequential pipelines, parallel consensus, hierarchical delegation) while supporting custom patterns.
Layer 3: Optimization and Monitoring
The top layer provides production-grade operational tools:
- Cost tracking – Real-time spend monitoring per model, per workflow, per customer
- Performance analytics – Latency, success rates, and quality metrics for each model
- A/B testing – Route percentage of traffic to different models and compare results
- Smart routing – Machine learning-based model selection that improves over time
Edge case to consider: During model provider outages, the framework can automatically shift all traffic to available alternatives. Configure maximum cost thresholds to prevent runaway spending during these failover events.
Integration with MULTIBLY: Comparing Models in Real Production Workflows
MULTIBLY’s platform provides the perfect complement to Relace AI’s framework. While Relace AI handles production orchestration, MULTIBLY enables rapid model evaluation before deployment.
The typical workflow:
- Prototype in MULTIBLY – Test your prompts across Claude Opus 4.5, GPT-5, DeepSeek R1, and other models side-by-side
- Identify optimal models – Compare responses for quality, speed, and accuracy on your specific use cases
- Configure Relace AI – Deploy the winning models in production with automatic fallbacks
- Monitor with both platforms – Use MULTIBLY for ongoing spot checks and Relace AI for production metrics
Why this combination works: MULTIBLY gives you access to 300+ premium AI models for one low price, making it economical to test extensively. Once you’ve identified the right models for each task, Relace AI ensures your production system uses them efficiently.
For teams building agentic workflows in 2026, this two-platform approach delivers:
- Faster iteration – Test model changes in minutes, not days
- Lower risk – Validate performance before committing to production changes
- Better decisions – Base model selection on real data from your actual prompts
The key insight: model performance varies dramatically based on your specific use case. Generic benchmarks help, but testing on your actual workload is essential. MULTIBLY makes this testing practical and affordable.
Common Mistakes When Implementing Relace AI Workflows
Even with Relace AI’s simplified integration, teams make predictable mistakes during initial deployment. Avoid these issues to accelerate your implementation.
Mistake 1: Over-Engineering Initial Workflows
The problem: Teams try to build complex multi-agent systems with branching logic, consensus mechanisms, and sophisticated routing on day one.
Better approach: Start with a simple sequential pipeline using 2-3 models. Get it running in production, gather real performance data, then add complexity based on actual needs rather than theoretical requirements.
Example: One team spent 3 weeks building an elaborate 7-model consensus system before discovering that a simple 2-model pipeline delivered 95% of the value in 10% of the time.
Mistake 2: Ignoring Cost Monitoring
The problem: Relace AI makes model switching so easy that teams forget to monitor spending. Costs can spike unexpectedly if workflows route too much traffic to expensive models.
Better approach: Set up cost alerts on day one. Configure maximum spend thresholds per workflow. Review the cost dashboard weekly during initial deployment, then monthly once patterns stabilize.
Mistake 3: Not Testing Failover Scenarios
The problem: Teams configure fallback models but never actually test what happens when the primary model fails.
Better approach: Deliberately trigger failover during development by temporarily disabling your primary model. Verify that quality remains acceptable and costs stay within bounds when running on backup models.
Mistake 4: Using Identical Prompts Across Different Models
The problem: Each model has different strengths and optimal prompting styles. Using the same prompt for Claude, GPT-5, and DeepSeek R1 produces suboptimal results.
Better approach: Relace AI supports model-specific prompt templates. Define variations optimized for each model’s characteristics while maintaining consistent workflow logic.
Mistake 5: Skipping the Evaluation Phase
The problem: Teams deploy Relace AI workflows without establishing quality baselines or success metrics.
Better approach: Before production deployment, run your workflow against a test set of 50-100 representative inputs. Measure quality, cost, and latency. These baselines make it possible to detect regressions when you modify the workflow later.
Frequently Asked Questions
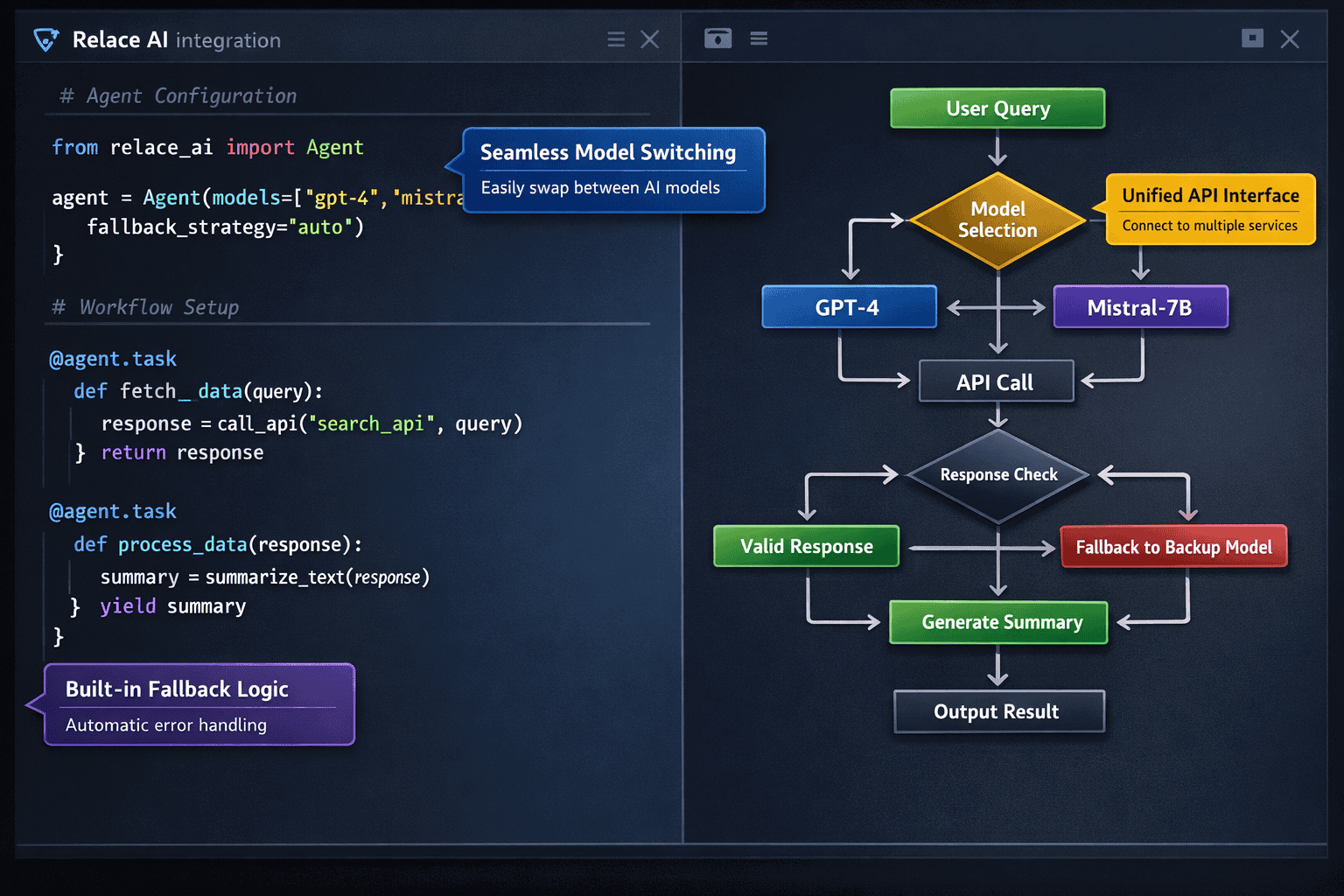
What makes Relace AI different from LangChain or other orchestration frameworks?
Relace AI focuses specifically on production-grade multi-model workflows with built-in cost optimization and monitoring. LangChain provides lower-level primitives that require more custom code. Relace AI includes pre-configured connectors for 300+ models and handles common production concerns (failover, cost tracking, performance monitoring) out of the box. For teams building production systems rather than prototypes, Relace AI reduces development time by 60-70%.
Can I use Relace AI with self-hosted open-source models?
Yes. Relace AI supports both API-based models and self-hosted deployments. You can mix cloud-based models like Claude with locally-hosted instances of Llama, Mistral, or other open models. The framework handles the different connection methods transparently.
How does Relace AI handle sensitive data and privacy?
Relace AI operates as an orchestration layer—your data flows through your infrastructure to the models you choose. For sensitive workloads, route to self-hosted models or privacy-focused providers. The framework supports on-premises deployment for organizations with strict data residency requirements. AI regulations in 2026 increasingly require transparency about data handling, and Relace AI’s architecture makes compliance easier by centralizing model access controls.
What’s the learning curve for developers new to agentic workflows?
Most developers deploy their first Relace AI workflow within 2-3 hours. The framework uses familiar patterns (function calls, config files, standard APIs) rather than introducing new paradigms. Teams with existing AI integration experience transition in days, not weeks. The documentation includes production-ready examples for common patterns.
How much does Relace AI cost compared to building custom integrations?
Relace AI pricing varies based on usage volume, but most teams report 40-60% lower total cost of ownership compared to building and maintaining custom integration code. The framework eliminates 2-4 weeks of initial development time and ongoing maintenance burden. For teams running multiple models, the cost savings from intelligent routing often exceed the framework licensing cost.
Can Relace AI automatically choose the best model for each task?
Yes. The framework includes smart routing that learns from your usage patterns. You define quality thresholds and cost constraints, and Relace AI selects models that meet your requirements while minimizing cost. The system improves over time as it gathers performance data from your actual workload.
What happens if a model provider has an outage?
Relace AI’s automatic failover routes traffic to backup models within seconds. You configure failover priorities (for example: Claude Opus 4.5 → GPT-5 → DeepSeek R1) and the framework handles switching transparently. Most users configure 2-3 fallback options to ensure high availability.
Does Relace AI work with specialized models for code, math, or other domains?
Yes. The framework supports domain-specific models and can route tasks based on content type. For example, send code-related queries to models optimized for programming, mathematical problems to reasoning-focused models like Claude Opus 4.5, and general queries to balanced models. You define routing rules based on your requirements.
How does Relace AI compare to using a single premium model for everything?
Using one premium model (like GPT-5 or Claude Opus 4.5) is simpler but typically costs 2-3x more than optimized multi-model workflows. Relace AI delivers comparable quality by routing simple tasks to efficient models and complex tasks to premium options. For most workloads, this hybrid approach reduces costs 40-60% while maintaining quality.
Can I test Relace AI without committing to a full production deployment?
Yes. Relace AI offers sandbox environments where you can build and test workflows with production-scale features but limited throughput. This allows full evaluation before committing to production deployment. Many teams prototype in the sandbox while simultaneously testing models in MULTIBLY’s comparison interface.
What monitoring and debugging tools does Relace AI provide?
The framework includes real-time dashboards showing per-model performance, cost tracking, error rates, and latency distributions. Detailed logs capture full request/response cycles for debugging. The system can automatically alert when error rates spike or costs exceed thresholds. These tools are essential for production operations.
How often does Relace AI add support for new models?
New models typically become available within 24-48 hours of public release. The framework’s architecture allows rapid integration of new models without requiring updates to your workflow code. When new models like Gemini 3 Pro or updated Claude variants launch, you can test them immediately by changing configuration parameters.
Conclusion
Relace AI’s Emerging Framework: Bridging Open-Source Gaps in Agentic Workflows for 2026 fundamentally changes how developers build production AI systems. By eliminating integration complexity and enabling seamless switching between proprietary and open-source models, the framework accelerates development while reducing costs and risk.
The evidence from early 2026 deployments is clear: teams using Relace AI ship agentic features 2-3x faster than those building custom integrations. The framework’s automatic failover, cost optimization, and monitoring tools solve the operational challenges that prevent many teams from deploying sophisticated multi-model workflows.
Key implementation steps:
- Start simple – Deploy a basic 2-model workflow to understand the framework’s capabilities
- Establish baselines – Measure quality, cost, and latency on your actual workload before optimizing
- Test models systematically – Use MULTIBLY to evaluate alternatives, then deploy winners via Relace AI
- Configure monitoring – Set up cost alerts and performance tracking before production deployment
- Iterate based on data – Let real usage patterns guide optimization rather than theoretical assumptions
The broader impact extends beyond individual deployments. By making open-source models genuinely practical for production use, Relace AI accelerates the entire ecosystem’s evolution. Developers gain flexibility, model providers face healthy competition, and the AI industry moves toward more open and accessible tools.
For teams building agentic workflows in 2026, Relace AI represents the difference between spending months on integration plumbing versus shipping features that create business value. The framework doesn’t eliminate complexity—it manages complexity so developers can focus on what matters.
The open-source AI landscape continues evolving rapidly, with new models launching monthly and capabilities improving constantly. Relace AI’s architecture ensures your workflows benefit from these advances without requiring constant rewrites. That future-proofing may be the framework’s most valuable feature in an industry where today’s cutting-edge model becomes tomorrow’s baseline.
References
[3] Ai Trends 2026 New Era Ai Advancements And Breakthroughs – https://www.trigyn.com/insights/ai-trends-2026-new-era-ai-advancements-and-breakthroughs



