
Meta’s Llama 4 introduces a 10 million token context window paired with Mixture of Experts (MoE) architecture, fundamentally changing how enterprises process long-form documents, analyze massive codebases, and extract insights from multimodal data. This breakthrough enables businesses to handle entire document collections in a single inference pass—something previously impossible with traditional AI models.
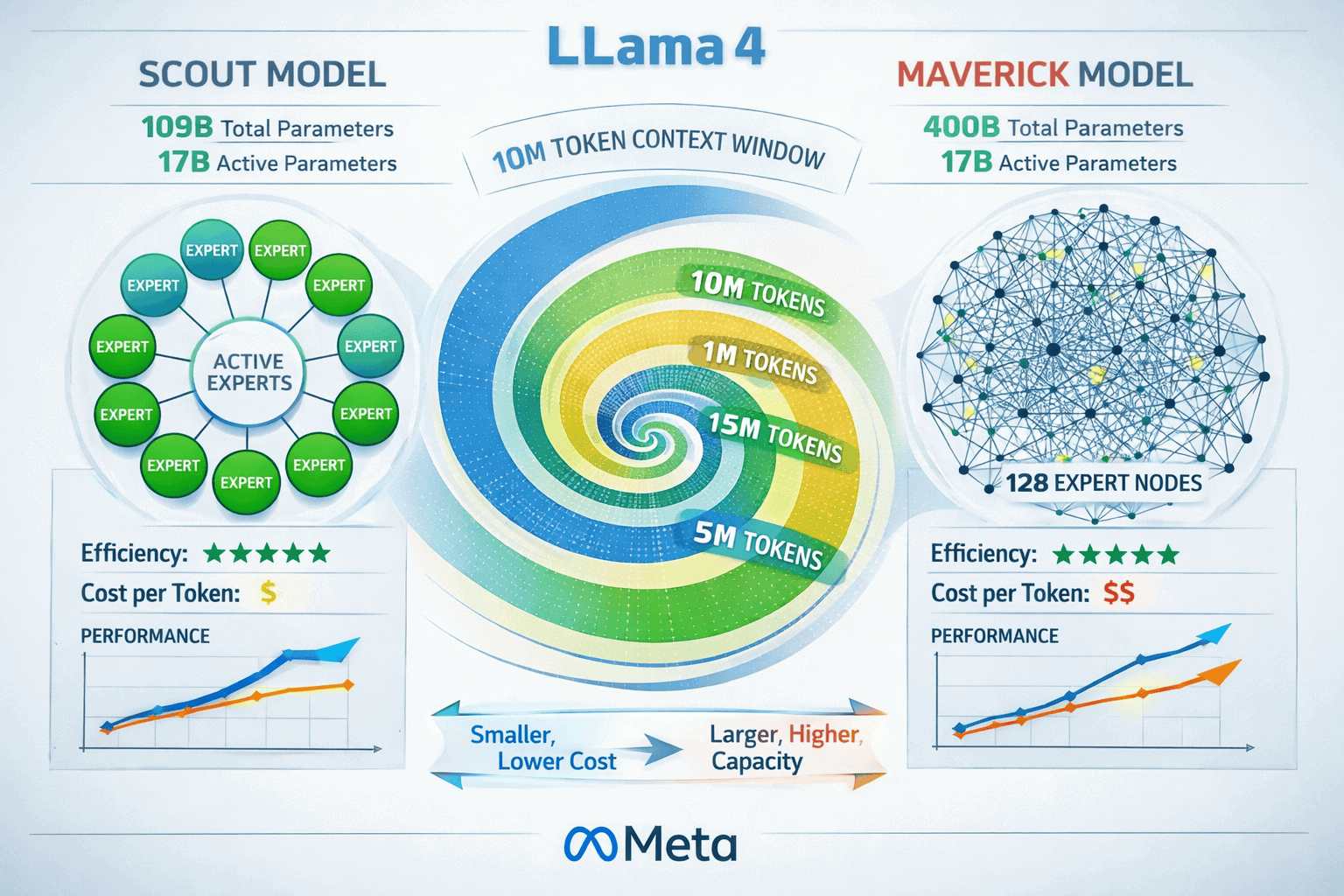
The release of Llama 4’s Scout and Maverick variants marks a decisive shift in enterprise document AI. With Scout offering 109 billion total parameters and Maverick scaling to 400 billion, both models activate just 17 billion parameters per inference, delivering exceptional cost-efficiency while processing context windows 78 times larger than Llama 3’s 128K limit[5]. This combination of scale and efficiency opens new possibilities for legal discovery, code repository analysis, and comprehensive document understanding.
- Key Takeaways
- Quick Answer
- What Makes Llama 4's 10M Context Window Different from Previous Models?
- How Does Llama 4's Mixture of Experts Architecture Enable Cost-Efficient Scaling?
- What Enterprise Applications Benefit Most from Llama 4's 10M Context Window?
- How Does Llama 4's Multimodal Capability Work with Enterprise Documents?
- What Hardware Infrastructure Does Llama 4's 10M Context Require?
- How Does Llama 4 Compare to Other Long-Context Models in 2026?
- What Are the Limitations and Challenges of Llama 4's Long-Context Processing?
- How Should Enterprises Implement Llama 4 for Document AI Workflows?
- FAQ
- Conclusion
- References
Key Takeaways
- Llama 4 Scout supports a 10 million token context window, representing a 78x increase from Llama 3’s 128K capacity and enabling processing of entire document collections in one pass[4][5]
- Dual model architecture offers Scout (109B total parameters, cost-optimized) and Maverick (400B total parameters, performance-focused), both activating only 17B parameters per inference[4][5]
- Native multimodal processing uses early fusion architecture to seamlessly integrate text, vision, and code tokens into a unified backbone, handling 8-10 images effectively[2][5]
- Training data expanded to 40 trillion tokens—a 2.66x increase from Llama 3—including unlabeled text, image, and video data for enhanced comprehension[3][5]
- Enterprise applications span legal document discovery, multi-document summarization, codebase analysis, and user activity parsing for personalization[4][5]
- Cost-efficiency breakthrough: Scout delivers $0.11 per 1M input tokens with an ELO score of 1417 on LMArena benchmarks[1][6]
- Hardware flexibility: 8x H100 GPUs can serve Scout with 1M context or Maverick with 430K context via vLLM; full 10M context requires multi-node deployment[2]
- Platform availability includes Snowflake Cortex AI, vLLM (v0.8.3+), and enterprise inference platforms with SQL and REST API integration[2][4]
- Interleaved attention layers enable length generalization from 256K pre-training context to 10M token inference capability[5]
- Mixture of Experts design reduces training compute requirements compared to dense models while maintaining superior performance across long-context tasks[1][2]
Quick Answer
Llama 4’s 10 million token context window combined with Mixture of Experts architecture enables enterprises to process entire document repositories, codebases, and multimodal datasets in a single inference pass. The Scout variant (109B total parameters) prioritizes cost-efficiency at $0.11 per 1M tokens, while Maverick (400B total parameters) maximizes performance—both activating just 17B parameters per request. This represents a fundamental shift in enterprise document AI, making previously impossible tasks like comprehensive legal discovery and full repository analysis economically viable.
For most teams, Scout provides the optimal balance of capability and cost for production deployments. Organizations requiring maximum performance for complex reasoning tasks should evaluate Maverick, particularly when processing the full 10M context window.
What Makes Llama 4’s 10M Context Window Different from Previous Models?
Llama 4’s 10 million token context window represents an industry-leading capacity that dwarfs previous generation models. Where Llama 3 maxed out at 128K tokens and competitors like Grok 4’s 2M context window offered substantial improvements, Llama 4 delivers a 78x expansion from its predecessor[5].
The key difference isn’t just raw capacity—it’s the architectural innovations that make this scale practical:
- Length generalization technology: Scout was pre-trained and post-trained with 256K context, then extrapolated to 10M tokens through advanced length generalization capabilities[5]
- Interleaved attention layers: This architectural innovation enables efficient processing across massive context windows without proportional increases in computational cost[5]
- MoE efficiency: By activating only 17 billion of Scout’s 109 billion total parameters (or Maverick’s 400 billion), the models maintain fast inference speeds despite enormous parameter counts[4][5]
In practice, this means a legal team can load 2,000+ pages of contracts into a single prompt. A development team can analyze an entire monorepo with millions of lines of code. A research group can synthesize findings from hundreds of academic papers simultaneously.
Choose Llama 4 Scout if: Your use case involves comprehensive document analysis, multi-source synthesis, or codebase reasoning where cost-efficiency matters more than absolute peak performance.
Choose Maverick if: You need maximum reasoning capability across the full 10M context for complex analytical tasks where performance justifies higher compute costs.
A common mistake is assuming longer context windows automatically improve all tasks. For queries requiring only focused retrieval or short-form generation, smaller context windows often deliver faster, more cost-effective results. The 10M window shines when the task genuinely requires understanding relationships across massive document sets.
How Does Llama 4’s Mixture of Experts Architecture Enable Cost-Efficient Scaling?
Llama 4’s Mixture of Experts (MoE) design fundamentally changes the economics of large language models by activating only a subset of parameters for each inference request. Scout uses 16 expert modules totaling 109 billion parameters but activates just 17 billion per token. Maverick employs 128 experts across 400 billion total parameters while maintaining the same 17 billion active parameter count[4][5].
This architecture delivers three critical advantages:
Reduced training compute: Despite higher total parameter counts than Llama 3, both Scout and Maverick required less computational resources during training because only active experts receive gradient updates[1]. This makes iterative improvement cycles faster and more economical.
Faster inference: By processing tokens through a fraction of total parameters, MoE models achieve inference speeds comparable to much smaller dense models. On 8x H100 GPUs, vLLM can serve Scout with a 1 million token context window efficiently[2].
Specialized expertise: Different expert modules develop specialized capabilities for distinct task types—code analysis, document summarization, visual reasoning—improving overall quality without requiring every parameter to be generalist.
The routing mechanism dynamically selects which experts process each token based on learned patterns. For a legal document, the model might activate experts specialized in formal language and logical reasoning. For code analysis, different experts focused on syntax and program flow take priority.
| Model Variant | Total Parameters | Active Parameters | Expert Count | Cost per 1M Tokens |
|---|---|---|---|---|
| Scout | 109B | 17B | 16 | $0.11[6] |
| Maverick | 400B | 17B | 128 | Higher (not disclosed) |
| Llama 3 (comparison) | 70B | 70B | N/A (dense) | Varies by provider |
Key decision rule: Choose Scout for production workloads where cost predictability and efficiency matter. Maverick makes sense for specialized analytical tasks where the performance delta justifies increased compute expense.
A common edge case involves highly specialized domains. While MoE architectures excel at general-purpose tasks, they may underperform domain-specific fine-tuned dense models in narrow verticals. Test both architectures against your specific use cases before committing to production deployment.
What Enterprise Applications Benefit Most from Llama 4’s 10M Context Window?

Llama 4’s massive context window unlocks practical applications previously constrained by token limits. The 10 million token capacity enables enterprises to process entire document collections, codebases, and multimodal datasets without chunking or retrieval augmentation.
Legal Discovery and Contract Analysis
Law firms and corporate legal departments can load thousands of pages of contracts, depositions, and case files into a single prompt. This enables:
- Cross-document pattern detection: Identifying inconsistent terms across 500+ vendor contracts simultaneously
- Comprehensive discovery: Analyzing entire case file repositories to surface relevant precedents and evidence
- Regulatory compliance: Reviewing policy documents against regulatory frameworks in one inference pass
For example, a legal team analyzing merger documentation can process all contracts, due diligence reports, and regulatory filings together—understanding relationships and dependencies that span thousands of pages[4][5].
Codebase Analysis and Software Engineering
Development teams gain unprecedented ability to reason about entire repositories:
- Full repository comprehension: Understanding dependencies, architectural patterns, and technical debt across millions of lines of code
- Refactoring assistance: Identifying safe refactoring opportunities by analyzing all call sites and dependencies simultaneously
- Security auditing: Detecting vulnerability patterns that span multiple modules and files
Meta reported compelling results in cumulative negative log-likelihoods (NLLs) over 10 million tokens of code, demonstrating the model’s ability to maintain coherent understanding across massive codebases[5].
Multi-Document Research and Synthesis
Research organizations and knowledge workers can synthesize insights from extensive literature:
- Academic research: Processing 100+ research papers to identify consensus, contradictions, and research gaps
- Market intelligence: Analyzing competitor reports, industry analyses, and market data across dozens of sources
- Due diligence: Comprehensive evaluation of acquisition targets using all available documentation
User Activity Analysis and Personalization
E-commerce platforms and SaaS companies can parse extensive user activity logs:
- Behavioral pattern detection: Understanding user journeys across months of interaction data
- Personalization engines: Generating recommendations based on comprehensive activity history
- Churn prediction: Identifying early warning signals by analyzing complete user engagement timelines
Choose Llama 4 for these applications if: Your task requires understanding relationships across massive document sets where chunking would lose critical context. For focused retrieval or question-answering over smaller document sets, consider long-context alternatives like Kimi K2’s 256K window which may offer better cost-performance ratios.
A common mistake is overloading the context window with irrelevant information. While Llama 4 can process 10M tokens, performance and cost optimize when you include only documents directly relevant to the analytical task.
How Does Llama 4’s Multimodal Capability Work with Enterprise Documents?
Llama 4 is natively multimodal using an early fusion architecture that integrates text and vision tokens into a unified processing backbone[5]. Unlike models that treat vision as a post-processing layer, Llama 4 processes visual and textual information together from the start, enabling more coherent understanding of documents containing charts, diagrams, and images.
The architecture builds on MetaCLIP vision encoder technology, trained in conjunction with a frozen Llama model to optimize encoding for the LLM component[5]. This approach enables the model to handle 8-10 images effectively within its context window[2].
Practical Enterprise Applications
Financial report analysis: Processing quarterly earnings reports that combine textual analysis, financial tables, and performance charts. The model can correlate written explanations with visual data representations, identifying discrepancies or trends.
Technical documentation: Understanding software documentation that includes architecture diagrams, flowcharts, and code snippets. The unified processing enables reasoning about how visual system designs relate to textual specifications.
Medical imaging with reports: Analyzing radiology reports alongside corresponding images, enabling comprehensive understanding that connects written findings with visual evidence.
Manufacturing quality control: Processing inspection reports that include product images, defect photographs, and textual quality assessments.
How Early Fusion Differs
Traditional multimodal approaches process text and images separately, then combine outputs. Early fusion treats both as unified token streams from the beginning:
- Vision encoder converts images into token representations
- Text tokenizer processes written content
- Both token types enter the same transformer backbone
- Attention mechanisms operate across text and vision tokens simultaneously
- The model develops integrated understanding rather than separate comprehension
This architecture proves particularly valuable for documents where meaning emerges from text-image relationships—technical manuals, scientific papers with figures, business presentations with data visualizations.
Key limitation: While Llama 4 handles 8-10 images effectively, extremely image-heavy documents (100+ images) may exceed optimal processing capacity. For such cases, consider selective image inclusion focusing on the most analytically relevant visuals.
Edge case: Pure computer vision tasks (object detection, image segmentation) still benefit from specialized vision models. Llama 4’s multimodal strength lies in understanding relationships between visual and textual information, not replacing dedicated computer vision systems.
What Hardware Infrastructure Does Llama 4’s 10M Context Require?
Deploying Llama 4 with its full 10 million token context window demands substantial computational resources, but the MoE architecture makes it more accessible than equivalent dense models. Hardware requirements scale based on the context window size you actually use and which variant you deploy.
GPU Requirements by Configuration
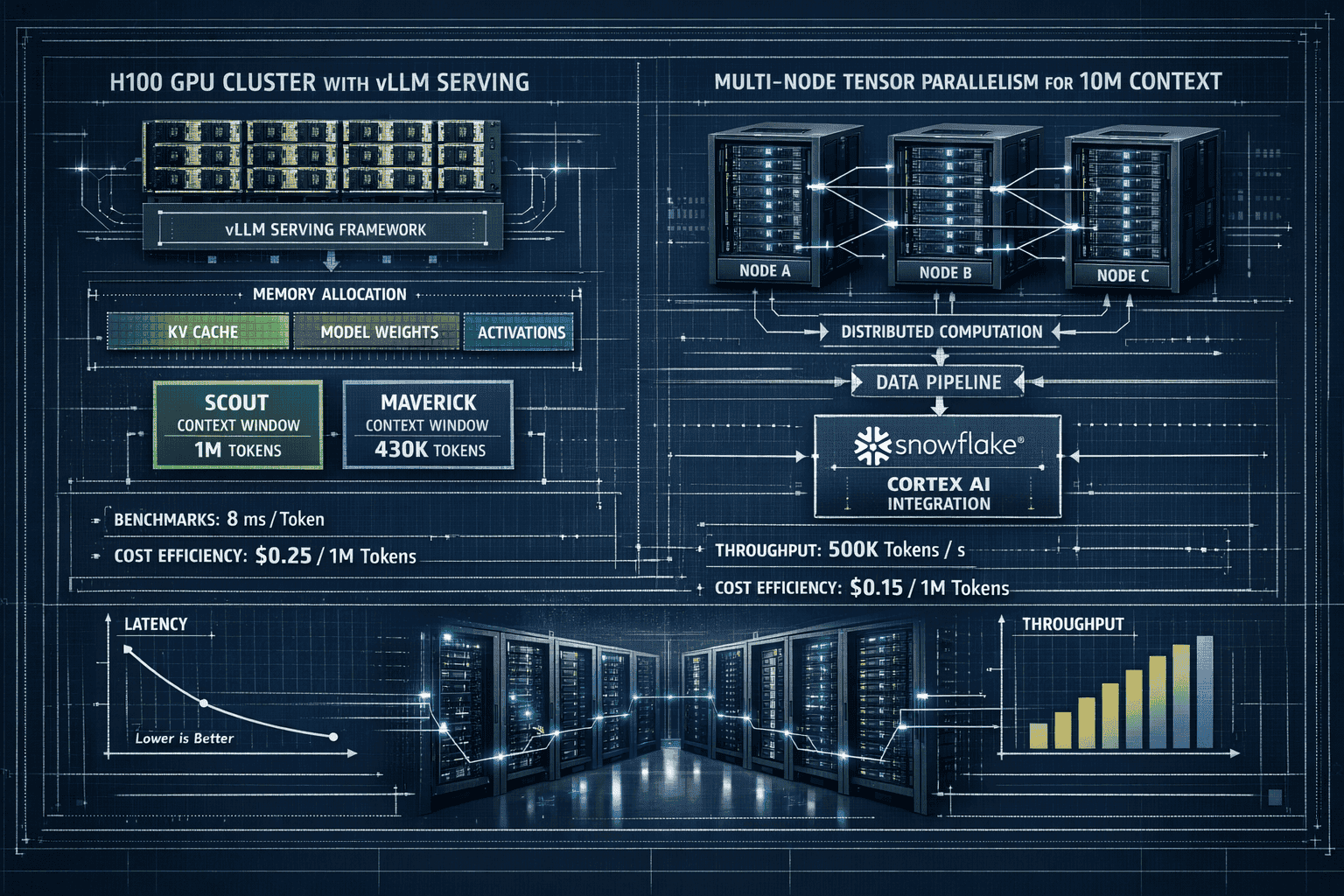
Scout with 1M context: An 8x H100 GPU cluster running vLLM can serve Scout effectively with a 1 million token context window[2]. This configuration balances capability and infrastructure costs for most enterprise applications.
Maverick with 430K context: The same 8x H100 setup handles Maverick with approximately 430K token context[2]. The larger model’s additional parameters reduce available context capacity on fixed hardware.
Full 10M context deployment: Utilizing the complete 10 million token window requires multi-node serving with tensor parallelism or pipeline parallelism[2]. This typically means 16-32 H100 GPUs distributed across multiple nodes with high-bandwidth interconnects.
Optimization Strategies
vLLM integration: Llama 4 supports vLLM v0.8.3 and later, which provides optimized inference with PagedAttention and continuous batching[2]. These optimizations significantly reduce memory overhead and improve throughput.
Context window right-sizing: Most applications don’t require the full 10M context. Analyze your actual use cases:
- Legal contract analysis: 500K-2M tokens typically sufficient
- Codebase reasoning: 1M-5M tokens for most repositories
- Multi-document synthesis: 500K-3M tokens for typical research tasks
Batch processing considerations: Larger context windows reduce batch sizes due to memory constraints. For high-throughput scenarios, consider processing multiple smaller-context requests rather than fewer massive-context requests.
Platform Deployment Options
Snowflake Cortex AI: Llama 4 is available in preview on Snowflake Cortex AI, enabling integration with existing data pipelines via SQL functions and REST API endpoints[4]. This managed deployment abstracts infrastructure complexity.
Self-hosted inference: Organizations with existing GPU infrastructure can deploy via vLLM or other inference frameworks. This offers maximum control and cost optimization for high-volume workloads.
Hybrid approaches: Use managed platforms for variable workloads and self-hosted infrastructure for predictable, high-volume production traffic.
| Configuration | Hardware | Max Context | Use Case |
|---|---|---|---|
| Scout – Standard | 8x H100 | 1M tokens | Most enterprise applications |
| Maverick – Standard | 8x H100 | 430K tokens | High-performance focused tasks |
| Scout – Extended | 16-32x H100 (multi-node) | 10M tokens | Comprehensive document analysis |
| Maverick – Extended | 32-64x H100 (multi-node) | 10M tokens | Maximum capability deployment |
Common mistake: Over-provisioning hardware for the full 10M context when actual use cases require far less. Start with 1M context deployments and scale only when specific applications demonstrate clear value from larger windows.
Edge case: Memory-constrained environments may need to use quantization (8-bit or 4-bit) to fit models on available GPUs. Test accuracy impacts carefully, as quantization can degrade performance on complex reasoning tasks.
How Does Llama 4 Compare to Other Long-Context Models in 2026?

Llama 4’s 10M context window positions it as the longest-context open model available in 2026, but context length alone doesn’t determine the best choice for every application. Performance, cost, and task-specific capabilities matter equally.
Context Window Comparison
Llama 4 Scout/Maverick: 10M tokens—industry-leading capacity for comprehensive document analysis[4][5]
Grok 4: 2M tokens—strong balance of context length and real-time processing capability, particularly for dynamic agentic workflows[6]
Kimi K2: 256K tokens—optimized for production document processing with excellent cost-performance balance[6]
Claude Opus 4.5: 200K tokens—exceptional reasoning quality within its context window, particularly for enterprise problem-solving[6]
GPT-5: Variable context across dual-model system—optimized for speed vs reasoning trade-offs[6]
Performance Considerations
Context window size doesn’t guarantee better performance. Meta reported strong results on “Needle in Haystack” retrieval tasks across the full 10M context[5], but independent evaluations using more rigorous benchmarks like RULER and NoLiMa were not released at launch[1].
In practice, retrieval accuracy often degrades in the middle portions of extremely long contexts—a phenomenon known as “lost in the middle.” For tasks requiring precise information extraction, structured retrieval with smaller context windows may outperform single-pass processing of massive contexts.
Cost-Performance Trade-offs
Llama 4 Scout at $0.11 per 1M input tokens offers exceptional value for long-context processing[6]. However, for applications requiring only 128K-256K tokens, models like Kimi K2 may deliver better cost-efficiency.
Decision framework:
- Use Llama 4 if: Your task genuinely requires understanding relationships across 1M+ tokens and open-source deployment is important
- Use Grok 4 if: You need 1M-2M context with real-time data integration and faster inference
- Use Kimi K2 if: 256K context suffices and you prioritize production stability with proven long-context performance
- Use Claude Opus 4.5 if: Reasoning quality matters more than context length and 200K tokens covers your use case
- Use GPT-5 if: You need the flexibility to choose between speed and reasoning modes based on task requirements
Multimodal Capabilities
Llama 4’s native multimodal processing with early fusion architecture differentiates it from text-only long-context models. For documents combining text, images, and diagrams, this integrated approach often outperforms text-only models even when the latter offer comparable context windows.
Compare this to Gemini 3 Pro’s multimodal optimization, which prioritizes speed for multimodal tasks over maximum context length.
Common mistake: Choosing models solely based on maximum context window size. Evaluate actual task requirements, cost constraints, and quality benchmarks relevant to your specific use cases.
What Are the Limitations and Challenges of Llama 4’s Long-Context Processing?
Despite Llama 4’s impressive capabilities, several practical limitations affect real-world deployments. Understanding these constraints helps teams set realistic expectations and architect appropriate solutions.
Computational Cost at Scale
Processing 10 million tokens requires substantial compute resources. While the MoE architecture improves efficiency compared to dense models, inference costs still scale with context length. A single 10M token inference on Maverick can consume significant GPU memory and processing time[2].
Mitigation strategy: Right-size context windows to actual needs. Most applications achieve optimal results with 1M-3M tokens rather than the full 10M capacity.
Retrieval Accuracy Degradation
Long-context models often struggle with the “lost in the middle” problem—information in the middle portions of extremely long contexts is harder to retrieve accurately than information at the beginning or end. Meta’s “Needle in Haystack” results demonstrate capability[5], but more complex retrieval tasks may show degraded performance.
Alternative approach: For applications requiring precise information retrieval, consider hybrid architectures that combine retrieval-augmented generation (RAG) with long-context processing. Use RAG to surface relevant sections, then apply long-context reasoning to understand relationships.
Benchmark Transparency
Independent evaluations using rigorous long-context benchmarks like RULER and NoLiMa were not publicly available at launch[1]. This makes it difficult to assess real-world performance compared to competing models on complex tasks.
Practical implication: Conduct thorough testing on your specific use cases before production deployment. Don’t rely solely on vendor-reported benchmarks.
Latency Considerations
Processing massive context windows increases inference latency. For applications requiring real-time or near-real-time responses, the full 10M context may introduce unacceptable delays.
Decision rule: Use smaller context windows for latency-sensitive applications. Reserve 10M context processing for batch analytical tasks where throughput matters more than response time.
Memory Requirements
Even with MoE efficiency gains, holding 10M tokens in memory alongside model parameters requires substantial RAM. Multi-node deployments add complexity around state management and synchronization[2].
Infrastructure planning: Budget for 16-32 H100 GPUs for production deployments requiring regular 10M context processing. For occasional large-context tasks, consider managed platforms like Snowflake Cortex AI that abstract infrastructure complexity[4].
Quality Consistency Across Context Lengths
Model performance may vary across different portions of the context window. Information density, document structure, and query complexity all affect output quality.
Testing framework: Evaluate performance across various context lengths (100K, 500K, 1M, 5M, 10M) with representative documents from your domain. Establish quality baselines before production deployment.
Multimodal Processing Limits
While Llama 4 handles 8-10 images effectively[2], extremely image-heavy documents may exceed optimal processing capacity. The early fusion architecture requires balancing text and vision tokens within the overall context budget.
Edge case handling: For documents with 50+ images, consider selective image inclusion or separate processing of visual and textual elements with downstream synthesis.
How Should Enterprises Implement Llama 4 for Document AI Workflows?
Successful Llama 4 deployment requires strategic planning around use cases, infrastructure, and integration patterns. Start with focused applications that demonstrate clear value, then expand to broader document AI workflows.
Implementation Roadmap
Phase 1: Use Case Selection and Validation (Weeks 1-4)
Identify applications where long-context processing delivers measurable business value:
- Legal discovery with 500+ page document sets
- Codebase analysis for repositories exceeding 100K lines
- Multi-document research synthesis across 20+ sources
- Comprehensive user activity analysis spanning months of data
Test these use cases with representative data to establish performance baselines. Compare results against existing solutions (RAG systems, traditional NLP pipelines, human analysis).
Phase 2: Infrastructure Planning (Weeks 3-6)
Choose deployment architecture based on volume, latency requirements, and existing infrastructure:
- Managed platforms (Snowflake Cortex AI): Best for teams without GPU infrastructure or variable workloads[4]
- Self-hosted inference (vLLM): Optimal for high-volume, predictable workloads with existing GPU resources[2]
- Hybrid approach: Managed platforms for development and low-volume production, self-hosted for high-throughput applications
Size hardware based on actual context requirements, not maximum capacity. Start with 8x H100 configurations supporting 1M context and scale as needed.
Phase 3: Integration Development (Weeks 5-10)
Build integration layers that connect Llama 4 to existing data pipelines:
For Snowflake deployments:
<code class="language-sql">SELECT SNOWFLAKE.CORTEX.COMPLETE(
'llama-4-scout',
CONCAT('Analyze these contracts: ', document_text)
) AS analysis
FROM contract_repository;
</code>For vLLM deployments:
- Implement REST API clients for application integration
- Build prompt templates for common document analysis tasks
- Develop post-processing pipelines for structured output extraction
Phase 4: Prompt Engineering and Optimization (Weeks 8-12)
Develop effective prompts for long-context processing:
- Structure documents clearly: Use headers, sections, and metadata to help the model navigate large contexts
- Specify output formats: Request structured outputs (JSON, tables) for downstream processing
- Include examples: Few-shot examples improve consistency, especially for domain-specific tasks
- Test context ordering: Experiment with document sequencing to optimize retrieval accuracy
Phase 5: Production Deployment and Monitoring (Week 12+)
Deploy with comprehensive monitoring:
- Latency tracking: Monitor inference times across different context lengths
- Cost analysis: Track token usage and compute costs per request
- Quality metrics: Establish accuracy benchmarks and monitor for degradation
- Error handling: Implement graceful fallbacks for timeout or capacity issues
Integration Patterns
Batch processing: Process large document sets overnight or during off-peak hours, storing results for downstream consumption.
Interactive analysis: Provide analysts with interfaces to submit document sets and receive synthesized insights within minutes.
Pipeline augmentation: Enhance existing document processing pipelines with long-context reasoning as a final synthesis step.
API services: Expose Llama 4 capabilities as internal APIs for consumption by multiple applications.
Common Implementation Mistakes
Over-engineering for maximum context: Most applications don’t need 10M tokens. Start with 1M context and expand only when specific use cases justify it.
Ignoring prompt engineering: Long-context processing requires different prompt strategies than short-context tasks. Invest time in optimization.
Inadequate testing: Comprehensive testing across representative documents is essential. Don’t assume performance generalizes from vendor benchmarks.
Underestimating infrastructure costs: Full 10M context processing requires substantial compute. Budget appropriately and consider managed platforms for cost predictability.
For teams exploring multiple AI models for different use cases, MULTIBLY’s platform provides access to 300+ premium AI models including Llama 4, enabling side-by-side comparisons to identify the optimal model for each specific task.
FAQ
What is the actual context window size of Llama 4? Llama 4 supports a 10 million token context window for both Scout and Maverick variants[4][5]. This represents a 78x increase from Llama 3’s 128K token limit and is the longest context window available in open-source models as of 2026.
How much does it cost to run Llama 4 Scout? Llama 4 Scout costs $0.11 per 1 million input tokens[6], making it one of the most cost-efficient long-context models available. Actual deployment costs depend on infrastructure choices—managed platforms charge per token while self-hosted deployments incur GPU compute costs.
Can Llama 4 process images and documents together? Yes, Llama 4 is natively multimodal using early fusion architecture that integrates text and vision tokens into a unified processing backbone[5]. The model effectively handles 8-10 images within its context window[2], making it suitable for documents combining text, charts, diagrams, and photographs.
What’s the difference between Llama 4 Scout and Maverick? Scout uses 109 billion total parameters across 16 experts and prioritizes cost-efficiency, while Maverick employs 400 billion total parameters across 128 experts for maximum performance[4][5]. Both activate only 17 billion parameters per inference. Choose Scout for production workloads where cost matters; choose Maverick for complex analytical tasks requiring peak performance.
How many GPUs do I need to run Llama 4 with full 10M context? An 8x H100 GPU cluster can serve Scout with 1M context or Maverick with 430K context[2]. Utilizing the full 10M context window requires 16-32 H100 GPUs in a multi-node configuration with tensor or pipeline parallelism[2].
Is Llama 4 better than Claude or GPT-5 for document analysis? Llama 4 excels at tasks requiring extremely long context (1M+ tokens) and offers superior cost-efficiency for open-source deployments. Claude Opus 4.5 provides better reasoning quality within its 200K context window, while GPT-5 offers flexible speed vs reasoning trade-offs. The best choice depends on your specific context requirements, quality standards, and deployment preferences.
What types of documents work best with Llama 4’s long context? Llama 4 excels with legal contracts, code repositories, research paper collections, technical documentation, financial reports, and user activity logs—any document set where understanding cross-document relationships and patterns matters more than focused retrieval of specific facts.
Can Llama 4 replace RAG systems for document processing? For some applications, yes. When tasks require comprehensive understanding of relationships across entire document sets, Llama 4’s long context eliminates the chunking and retrieval steps that RAG systems require. However, for precise fact retrieval or when documents exceed 10M tokens, hybrid approaches combining RAG with long-context processing often perform better.
How accurate is Llama 4’s retrieval across the full 10M context? Meta reported strong performance on “Needle in Haystack” retrieval tasks[5], but independent evaluations using comprehensive benchmarks were not available at launch[1]. Real-world accuracy depends on document structure, information density, and query complexity. Test thoroughly with your specific use cases before production deployment.
What platforms support Llama 4 deployment? Llama 4 is available on Snowflake Cortex AI (in preview), vLLM (v0.8.3+), and other enterprise inference platforms[2][4]. Snowflake integration supports SQL functions and REST API endpoints for seamless data pipeline integration.
Does Llama 4 support fine-tuning for domain-specific applications? As an open-source model, Llama 4 supports fine-tuning for specialized domains. However, the large parameter counts and MoE architecture require substantial computational resources for effective fine-tuning. For most applications, prompt engineering with the base model delivers strong results without fine-tuning overhead.
How does Llama 4’s MoE architecture affect inference speed? The MoE design activates only 17 billion of Scout’s 109 billion total parameters (or Maverick’s 400 billion) per inference[4][5], enabling faster processing than equivalent dense models. However, inference speed still scales with context length—processing 10M tokens takes substantially longer than 1M tokens regardless of architecture.
Conclusion
Llama 4’s 10 million token context window combined with Mixture of Experts architecture represents a fundamental shift in enterprise document AI capabilities. The Scout variant delivers exceptional cost-efficiency at $0.11 per 1M tokens while processing context windows 78 times larger than its predecessor. Maverick offers maximum performance for complex analytical tasks requiring the full 10M context capacity.
The native multimodal processing with early fusion architecture enables seamless integration of text, images, and code—critical for real-world enterprise documents that combine multiple data types. Training on 40 trillion tokens provides the foundational knowledge needed for comprehensive document understanding across diverse domains.
For enterprises, the key opportunity lies in applications previously constrained by token limits: comprehensive legal discovery across thousands of contracts, full repository code analysis, multi-document research synthesis, and extensive user activity parsing. These use cases become economically viable with Llama 4’s combination of scale and efficiency.
Successful implementation requires strategic planning around use case selection, infrastructure sizing, and integration patterns. Start with focused applications that demonstrate clear business value—legal contract analysis, codebase reasoning, or research synthesis. Test thoroughly with representative documents to establish performance baselines before expanding to production scale.
The hardware requirements are substantial but manageable. Most enterprises can start with 8x H100 GPU configurations supporting 1M context windows, scaling to multi-node deployments only when specific applications justify the full 10M capacity. Managed platforms like Snowflake Cortex AI offer infrastructure abstraction for teams without existing GPU resources.
Context window size alone doesn’t determine the best model for every task. Compare Llama 4 against alternatives like Claude Opus 4.5 for reasoning-intensive applications, Grok 4 for real-time processing, or Kimi K2 for production document workflows requiring 256K or less. The optimal choice depends on your specific context requirements, quality standards, latency constraints, and deployment preferences.
Next steps for enterprise teams:
- Identify high-value use cases where long-context processing delivers measurable business impact
- Conduct proof-of-concept testing with representative documents from your domain
- Compare performance and costs against existing solutions and alternative models using MULTIBLY’s platform to evaluate 300+ AI models side by side
- Size infrastructure based on actual context requirements, not maximum theoretical capacity
- Develop integration patterns that connect Llama 4 to existing data pipelines and workflows
- Establish monitoring frameworks to track latency, costs, and quality metrics in production
The combination of unprecedented context capacity, cost-efficient MoE architecture, and native multimodal processing positions Llama 4 as a transformative tool for enterprise document AI. Organizations that strategically deploy these capabilities will gain significant advantages in legal analysis, software engineering, research synthesis, and data-driven decision-making.
References
[1] Llama 4 – https://www.interconnects.ai/p/llama-4
[2] Llama4 – https://blog.vllm.ai/2025/04/05/llama4.html
[3] Llama 4 10m Context Coding Decent Follow Up 426n – https://dev.to/maximsaplin/llama-4-10m-context-coding-decent-follow-up-426n
[4] Meta Llama 4 Now Available Snowflake Cortex Ai – https://www.snowflake.com/en/blog/meta-llama-4-now-available-snowflake-cortex-ai/
[5] Llama 4 Multimodal Intelligence – https://ai.meta.com/blog/llama-4-multimodal-intelligence/
[6] Context Length Comparison Ai Models 2026 – https://www.elvex.com/blog/context-length-comparison-ai-models-2026
[7] Meta Llama Cheatsheet – https://www.ai-mindset.ai/meta-llama-cheatsheet



