
AllenAI has released Tulu 3, a fully open-sourced post-training framework that’s changing how researchers access and deploy frontier-level AI capabilities. Unlike proprietary reasoning models, Tulu 3 provides complete transparency—training datasets, code, evaluation tools, and infrastructure—making advanced AI accessible for scientific discovery. This comprehensive release addresses the reproducibility crisis in AI research and offers practical deployment paths for teams working on complex reasoning tasks.
In 2026, the gap between closed and open AI systems is narrowing fast. AllenAI’s O1 and Tulu 3: Revolutionizing Open Research AI for Scientific Discovery in 2026 represents a paradigm shift where transparency meets performance, giving research institutions and enterprises a viable alternative to black-box proprietary models.
- Key Takeaways
- Quick Answer
- What Makes AllenAI's Tulu 3 Different from Proprietary Reasoning Models?
- How Does Tulu 3's Four-Stage Training Process Work?
- What Performance Benchmarks Does Tulu 3 Achieve?
- How Can Research Teams Deploy Tulu 3 for Scientific Discovery?
- What Are the Advantages of Open-Source AI for Research Institutions?
- How Does RLVR Compare to Traditional Reward Model Approaches?
- What Evaluation Tools Does Tulu 3 Provide for Research Applications?
- How Does Tulu 3 Fit into the 2026 AI Research Landscape?
- Frequently Asked Questions
- Conclusion
- References
Key Takeaways
- Tulu 3 is a complete open-source framework, not just a model—it includes all training data, curation tools, decontamination scripts, training code, and evaluation suites for reproducible AI development[1][3]
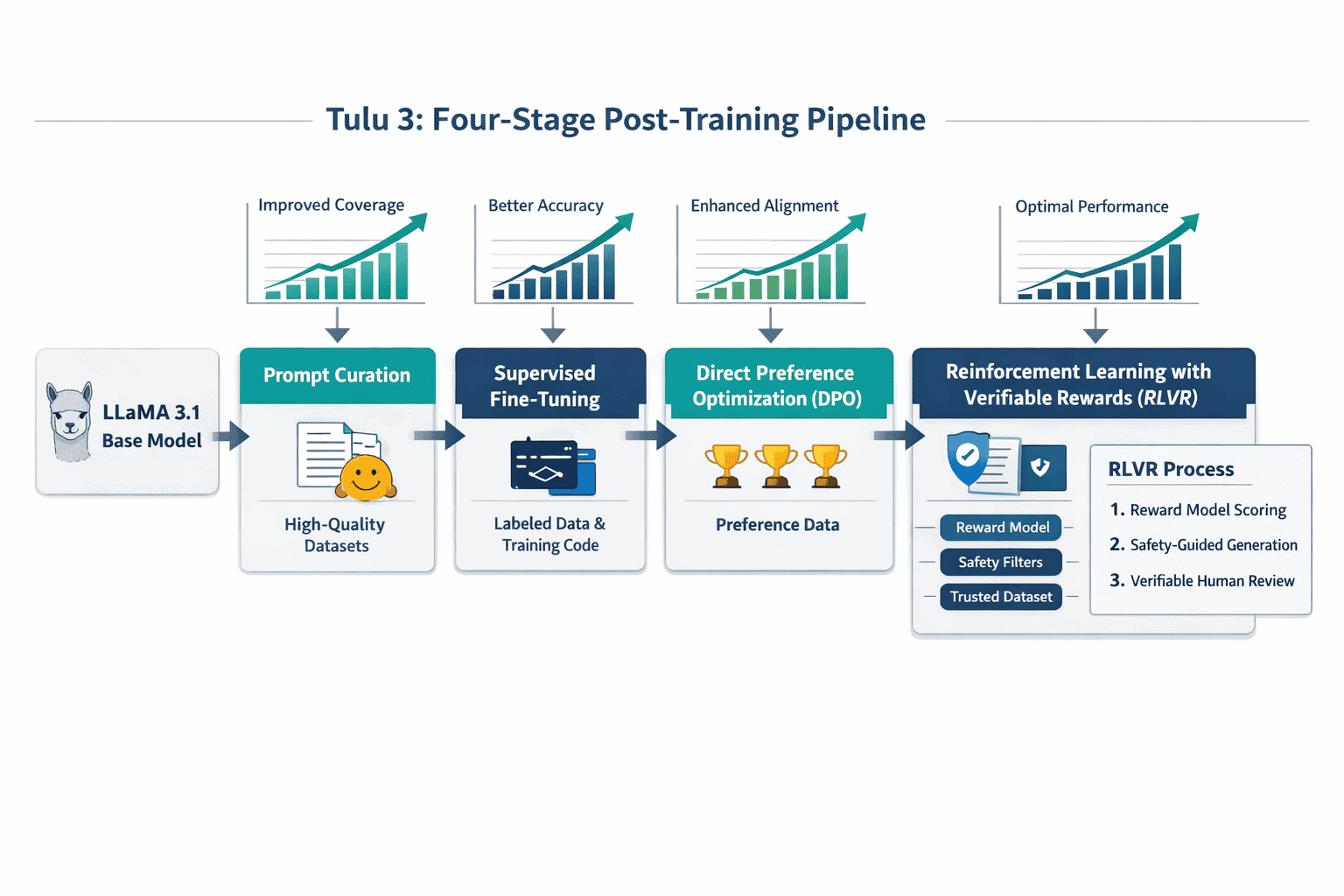
- Four-stage post-training recipe combines prompt curation, supervised fine-tuning (SFT), Direct Preference Optimization (DPO), and novel Reinforcement Learning with Verifiable Rewards (RLVR)[2][6]
- Performance matches or exceeds competing open models including Llama 3.1-Instruct, Qwen2.5-Instruct, and Mistral-Instruct across comprehensive benchmarks[4]
- RLVR eliminates traditional reward models, enabling reinforcement learning through verifiable rewards that boost specific capabilities without complex infrastructure[1][2]
- Built on Llama 3.1 base models, Tulu 3 demonstrates that post-training innovation matters more than raw pretraining scale in 2026[1]
- Deployment-ready on Hugging Face, making frontier reasoning capabilities accessible to research teams without massive infrastructure investments
- Comprehensive evaluation suite (Tulu 3 Eval) tests real-world generalization across knowledge, reasoning, math, coding, instruction following, and safety[2]
Quick Answer
AllenAI’s Tulu 3 framework delivers open-source AI capabilities that rival proprietary reasoning models by providing complete transparency in training methodology, datasets, and evaluation. The framework uses a four-stage post-training approach including a novel RLVR technique that achieves strong performance without traditional reward models. For researchers and enterprises seeking reproducible, customizable AI for scientific discovery, Tulu 3 offers deployment-ready models on Hugging Face that outperform other open-weight alternatives of equivalent size while maintaining full transparency[1][3][4].
What Makes AllenAI’s Tulu 3 Different from Proprietary Reasoning Models?
Tulu 3 is a fully open post-training framework, not a closed inference API. While models like OpenAI’s o1 demonstrate impressive reasoning capabilities, they operate as black boxes—users can’t inspect training data, modify approaches, or reproduce results[1][3].
The key differences matter for research teams:
- Complete transparency: All training datasets, data curation tools, decontamination scripts, training code, and evaluation suites are publicly available[4]
- Reproducibility: Other researchers can verify results, identify limitations, and build improvements
- Customization: Teams can adapt the framework for domain-specific needs without vendor lock-in
- Cost control: Self-hosting eliminates per-token API costs for high-volume research applications
In practice, this means a genomics research lab can fine-tune Tulu 3 on specialized protein folding data, inspect exactly how the model processes scientific literature, and deploy it within their secure infrastructure—none of which is possible with proprietary alternatives.
The framework addresses what AllenAI identifies as a critical gap: while many organizations release model weights, few provide the complete training pipeline needed for genuine reproducibility[4]. This matters because post-training has become the primary driver of model capability in 2026, not just raw pretraining scale[2].
Choose Tulu 3 if: You need transparency, customization, or reproducibility for research. Stick with proprietary models if you prioritize absolute cutting-edge performance over openness and can accept black-box limitations.
How Does Tulu 3’s Four-Stage Training Process Work?
The Tulu 3 training methodology follows a systematic four-stage recipe that transforms base Llama 3.1 models into capable reasoning systems[2][6].
Stage 1: Prompt Curation and Synthesis
The framework uses persona-driven synthetic data generation to create diverse, high-quality training examples. This prevents “mode collapse” where models become overly specialized on narrow data distributions[2].
Key techniques include:
- Generating prompts across multiple domains and difficulty levels
- Using diverse personas to ensure varied reasoning approaches
- Filtering low-quality or redundant examples
- Decontamination to prevent benchmark leakage
Stage 2: Supervised Fine-Tuning (SFT)
Standard supervised learning on curated instruction-response pairs. The model learns to follow instructions and produce structured outputs across knowledge recall, reasoning, mathematics, and coding tasks.
Stage 3: Direct Preference Optimization (DPO)
DPO trains the model to prefer higher-quality responses by learning from paired examples of better versus worse outputs. This stage refines response quality without requiring explicit reward modeling.
Stage 4: Reinforcement Learning with Verifiable Rewards (RLVR)
RLVR is Tulu 3’s novel contribution[1][2]. Instead of training a separate reward model (computationally expensive and prone to errors), RLVR uses verifiable rewards based on objective criteria:
- Mathematical correctness (can the answer be verified?)
- Code execution success (does it run without errors?)
- Logical consistency (do reasoning steps follow?)
This approach boosts specific skills through targeted reinforcement without the complexity of traditional RLHF (Reinforcement Learning from Human Feedback).
Common mistake: Assuming all four stages are always necessary. For some applications, stopping after SFT or DPO may be sufficient and more cost-effective. Run evaluations at each stage to determine optimal stopping points for your use case.
For teams looking to understand how small models are competing effectively in 2026, Tulu 3’s methodology shows that training innovation matters more than parameter count.
What Performance Benchmarks Does Tulu 3 Achieve?
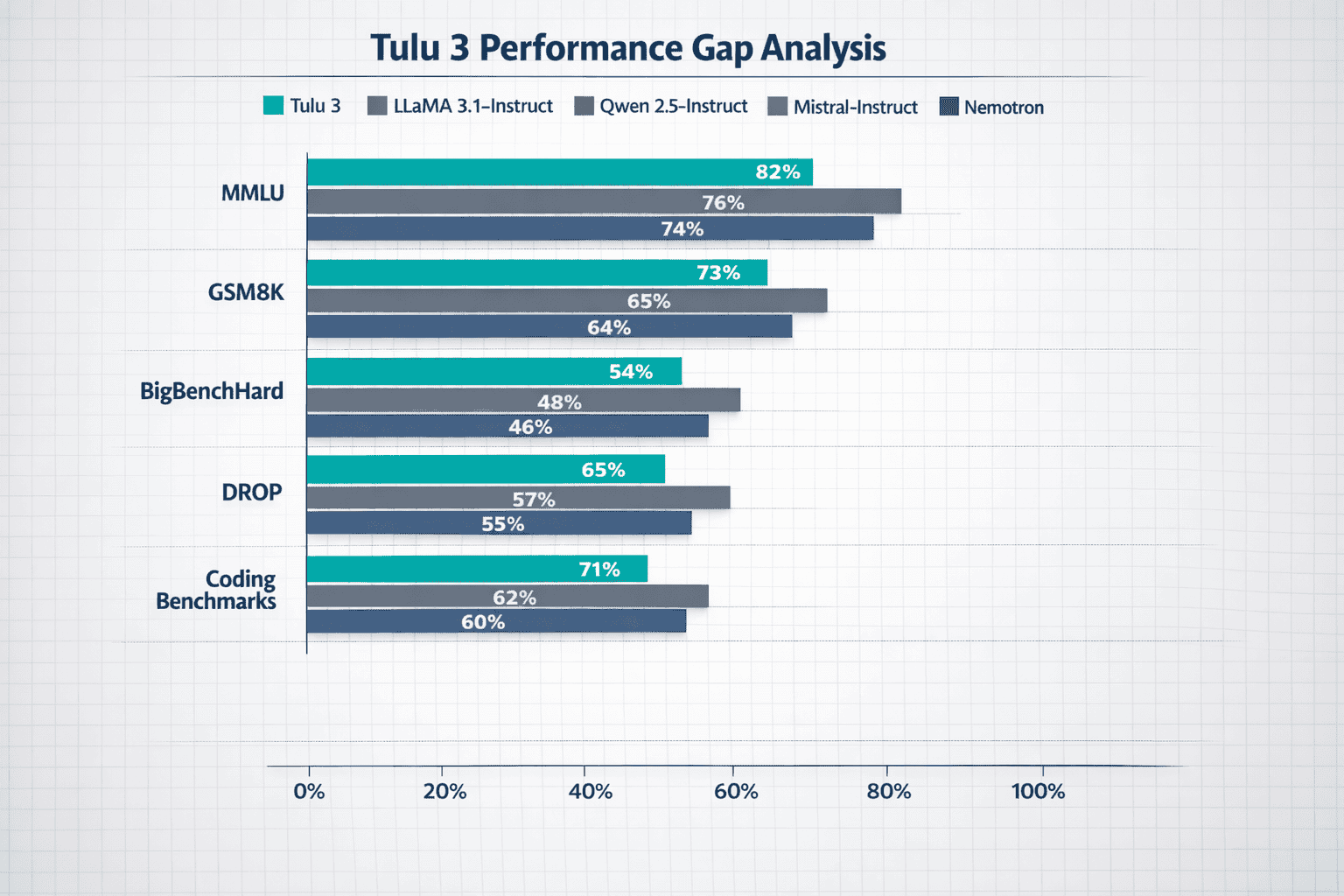
Tulu 3 models outperform open-weight post-trained models of equivalent size across AllenAI’s comprehensive evaluation suite[4]. This includes established competitors like Llama 3.1-Instruct, Qwen2.5-Instruct, Mistral-Instruct, and Nemotron.
Benchmark Performance Areas
Knowledge and Reasoning:
- MMLU (Massive Multitask Language Understanding)
- PopQA (factual knowledge retrieval)
- TruthfulQA (truthfulness and reliability)
- BigBenchHard (complex reasoning tasks)
Mathematical Capabilities:
- GSM8K (grade school math word problems)
- DROP (reading comprehension with discrete reasoning)
Coding Performance:
- Code generation accuracy
- Debugging and explanation tasks
Instruction Following and Safety:
- Complex multi-step instruction adherence
- Safety benchmark compliance
The evaluation methodology includes unseen tasks not present in training data to assess genuine generalization rather than memorization[2]. This approach reveals whether models can apply learned reasoning patterns to novel problems—critical for scientific discovery applications.
Key insight: Tulu 3 closes the performance gap between open-source and proprietary models across multiple dimensions[4]. While it may not surpass the absolute best proprietary systems on every metric, it delivers competitive performance with full transparency.
| Capability Area | Tulu 3 Strength | Best Use Cases |
|---|---|---|
| Mathematical Reasoning | Strong on GSM8K, verifiable problems | Quantitative research, data analysis |
| Code Generation | Competitive with instruction-tuned models | Research automation, tool building |
| Knowledge Recall | Solid on MMLU, domain-specific fine-tuning possible | Literature review, fact verification |
| Instruction Following | Excels at complex multi-step tasks | Experimental protocol execution |
| Safety | Passes standard safety benchmarks | Deployment in regulated environments |
Edge case: For cutting-edge mathematical theorem proving or extremely specialized domains, proprietary models with larger parameter counts may still hold advantages. Evaluate on your specific task distribution before committing.
Researchers comparing open versus closed model economics will find Tulu 3’s transparent benchmarking critical for total cost of ownership calculations.
How Can Research Teams Deploy Tulu 3 for Scientific Discovery?
Deployment strategies for AllenAI’s O1 and Tulu 3: Revolutionizing Open Research AI for Scientific Discovery in 2026 focus on practical implementation paths that balance performance, cost, and infrastructure requirements.
Deployment Option 1: Hugging Face Hosted Inference
Best for: Small to medium research teams, proof-of-concept work, limited ML infrastructure
Steps:
- Access Tulu 3 models directly from Hugging Face model hub
- Use Hugging Face Inference API for immediate deployment
- Pay per-token pricing (significantly lower than proprietary APIs)
- Scale up or down based on research volume
Advantages: Zero infrastructure setup, immediate access, built-in model versioning
Limitations: Per-token costs accumulate with high volume, less customization than self-hosting
Deployment Option 2: Self-Hosted on Research Cluster
Best for: Large research institutions, high-volume applications, custom fine-tuning needs
Implementation approach:
- Download complete Tulu 3 framework from AllenAI’s GitHub repository[7]
- Set up inference infrastructure (GPU cluster or cloud instances)
- Load model weights and configure serving layer
- Implement monitoring and evaluation pipelines
Advantages: Full control, no per-token costs after setup, complete customization, data privacy
Limitations: Requires ML infrastructure expertise, upfront hardware/cloud costs
Deployment Option 3: Domain-Specific Fine-Tuning
Best for: Specialized research domains (genomics, materials science, climate modeling)
Process:
- Start with base Tulu 3 model
- Curate domain-specific training data
- Apply SFT and optionally DPO stages using provided training code
- Evaluate on domain benchmarks
- Deploy customized model
Key advantage: Models learn domain-specific reasoning patterns and terminology that general models miss.
Scientific Discovery Use Cases
Literature Review and Synthesis:
- Analyze thousands of research papers
- Extract key findings and methodologies
- Identify research gaps and connections
- Generate literature review summaries
Hypothesis Generation:
- Propose novel research directions based on existing literature
- Suggest experimental designs
- Identify potential confounding variables
Data Analysis Automation:
- Generate analysis scripts for complex datasets
- Explain statistical results in plain language
- Suggest alternative analytical approaches
Experimental Protocol Optimization:
- Review and critique experimental designs
- Suggest protocol improvements
- Identify potential issues before implementation
Common mistake: Deploying without establishing evaluation metrics first. Define success criteria for your specific research tasks before deployment, then measure performance systematically.
For teams evaluating multiple AI options, MULTIBLY’s platform provides access to 300+ models including Tulu 3, allowing side-by-side comparison for research workflows.
What Are the Advantages of Open-Source AI for Research Institutions?
Research institutions gain specific benefits from AllenAI’s O1 and Tulu 3: Revolutionizing Open Research AI for Scientific Discovery in 2026 that proprietary alternatives can’t match.
Reproducibility and Scientific Rigor
Transparency enables verification: Other researchers can inspect training data, identify potential biases, and reproduce results—fundamental to scientific method[3][4].
In practice, when a research paper claims results using Tulu 3, peer reviewers can:
- Verify the exact model version and training configuration
- Reproduce experiments with identical setup
- Test alternative approaches using the same framework
- Identify limitations in methodology
This level of transparency is impossible with black-box proprietary models where training data and methods remain trade secrets.
Cost Predictability
Self-hosting eliminates usage-based pricing: After initial infrastructure investment, marginal costs approach zero for high-volume research applications.
Cost comparison example for analyzing 10 million research abstracts:
- Proprietary API: $0.002 per 1K tokens × estimated 15M tokens = $30,000
- Self-hosted Tulu 3: GPU cluster rental ~$5,000/month, reusable for multiple projects
For ongoing research programs, self-hosting pays for itself quickly.
Data Privacy and Security
Sensitive research data stays in-house: Medical research, proprietary datasets, and pre-publication findings never leave institutional infrastructure.
This matters for:
- HIPAA compliance in medical research
- Protection of intellectual property
- IRB requirements for human subjects research
- International data sovereignty regulations
Customization for Domain Expertise
Fine-tuning captures specialized knowledge: Research domains have unique terminology, reasoning patterns, and evaluation criteria that general models miss.
Example: A materials science lab can fine-tune Tulu 3 on crystallography literature, teaching it to reason about crystal structures, phase diagrams, and synthesis conditions in ways general models cannot.
Long-Term Sustainability
No vendor lock-in or deprecation risk: Models remain accessible regardless of company decisions, pricing changes, or service discontinuation.
Research projects spanning years can depend on consistent model availability—critical for longitudinal studies and reproducible science.
Choose open models if: Reproducibility, data privacy, cost control, or customization are priorities. Accept proprietary alternatives if absolute cutting-edge performance matters more than these factors.
The broader open-source AI movement demonstrates how transparency accelerates scientific progress across institutions.
How Does RLVR Compare to Traditional Reward Model Approaches?

Reinforcement Learning with Verifiable Rewards (RLVR) represents a methodological innovation that simplifies and improves the reinforcement learning stage of model training[1][2].
Traditional RLHF Limitations
Standard Reinforcement Learning from Human Feedback requires:
- Collecting thousands of human preference judgments
- Training a separate reward model to predict human preferences
- Using the reward model to guide reinforcement learning
- Managing reward model errors and biases
Problems with this approach:
- Reward models can be inaccurate or misaligned
- Training reward models is computationally expensive
- Human preference collection is slow and costly
- Reward hacking (model exploits reward model flaws)
RLVR’s Verifiable Reward Approach
RLVR replaces learned reward models with objective, verifiable criteria:
For mathematics:
- Reward = 1 if answer is mathematically correct
- Reward = 0 if incorrect
- No ambiguity, no learned model needed
For coding:
- Reward = 1 if code executes successfully and passes tests
- Reward = 0 for errors or failures
- Objective verification through execution
For logical reasoning:
- Reward based on logical consistency checks
- Verifiable through formal logic rules
Key Advantages
Simplicity: No need to train and maintain separate reward models, reducing infrastructure complexity.
Reliability: Verifiable rewards eliminate reward model errors and hacking attempts.
Targeted improvement: Boost specific skills (math, coding) where verification is possible without affecting general capabilities.
Cost efficiency: Fewer computational resources and less human annotation required.
Limitations to Consider
RLVR works best for tasks with objective verification criteria. It’s less applicable to:
- Creative writing quality
- Subjective preference alignment
- Nuanced social reasoning
- Stylistic choices
For these domains, traditional preference-based approaches may still be necessary.
In practice: Tulu 3 combines both approaches—RLVR for verifiable skills like math and coding, DPO for general quality improvement. This hybrid strategy delivers strong performance across diverse capabilities.
Teams exploring reasoning model alternatives will find RLVR’s methodology influential in how open models compete with proprietary reasoning systems.
What Evaluation Tools Does Tulu 3 Provide for Research Applications?
Tulu 3 Eval is a comprehensive evaluation suite designed to assess model performance across dimensions critical for scientific discovery[2].
Evaluation Categories
Knowledge Recall and Accuracy:
- MMLU: 57 subject areas from STEM to humanities
- PopQA: Entity-centric factual knowledge
- TruthfulQA: Resistance to common misconceptions
Reasoning and Problem-Solving:
- BigBenchHard: Complex multi-step reasoning
- DROP: Reading comprehension with discrete reasoning
- Logical inference tasks
Mathematical Capabilities:
- GSM8K: Grade school math word problems
- Advanced mathematical reasoning
- Quantitative problem-solving
Code Generation and Understanding:
- Code synthesis from natural language
- Debugging and error correction
- Code explanation and documentation
Instruction Following:
- Multi-step task completion
- Complex constraint satisfaction
- Contextual instruction interpretation
Safety and Alignment:
- Harmful content detection
- Bias evaluation
- Robustness to adversarial inputs
Generalization Testing
The evaluation suite includes tasks not seen during training to test genuine generalization capability rather than memorization[2]. This approach reveals whether models can apply learned reasoning patterns to novel scientific problems.
For research applications, this matters because:
- Scientific discovery involves novel problems by definition
- Memorized benchmark performance doesn’t predict real-world research utility
- Generalization to unseen tasks indicates robust reasoning capabilities
Custom Evaluation Implementation
Research teams can extend Tulu 3 Eval with domain-specific benchmarks:
- Define evaluation tasks relevant to your research domain
- Create test sets with ground truth answers
- Use provided evaluation code as a template
- Measure performance on your custom benchmarks
- Compare against baseline models
Example: A climate science lab might create evaluation tasks around:
- Climate model output interpretation
- Extreme weather event prediction reasoning
- Carbon cycle mechanism explanation
- Policy impact analysis
Best practice: Establish evaluation metrics before deployment, not after. Define what “good performance” means for your specific research tasks, then measure systematically.
The comprehensive evaluation approach positions Tulu 3 alongside other emerging open frameworks that prioritize measurable, reproducible performance.
How Does Tulu 3 Fit into the 2026 AI Research Landscape?
AllenAI’s O1 and Tulu 3: Revolutionizing Open Research AI for Scientific Discovery in 2026 represents a broader shift in how AI capabilities are developed and distributed.
The Post-Training Paradigm Shift
AllenAI notes that language model development has evolved significantly: raw dataset pretraining has become increasingly standardized, while post-training has emerged as the primary driver of capability differences[2].
This shift means:
- Base model pretraining is largely commoditized
- Innovation happens in post-training methodology
- Smaller teams can compete by focusing on training recipes
- Transparency in post-training becomes more valuable
Models like OpenAI’s o1 and DeepSeek R1 demonstrate new training approaches that achieve strong reasoning through post-training innovation rather than scale alone[1]. Tulu 3 makes these methodologies accessible to the research community.
Open vs. Proprietary Model Competition
The performance gap between open and closed models continues narrowing in 2026[4]. Tulu 3 contributes to this trend by:
- Matching or exceeding other open models of equivalent size
- Providing complete transparency for reproducibility
- Enabling customization that proprietary APIs don’t allow
- Demonstrating that openness doesn’t require performance sacrifices
For research institutions, this creates genuine choice—teams can select models based on requirements rather than accepting that proprietary equals better.
Integration with Broader Open Ecosystem
Tulu 3 complements other open research initiatives:
- Hugging Face: Deployment and distribution infrastructure
- Open datasets: Training data transparency enables community curation
- Evaluation benchmarks: Standardized testing across models
- Research reproducibility: Complete pipelines for verification
This ecosystem approach accelerates progress faster than isolated proprietary development.
Deployment Alongside Proprietary Models
Many research teams adopt a hybrid strategy: proprietary models for maximum performance on critical tasks, open models like Tulu 3 for transparency, customization, and cost control on high-volume applications.
MULTIBLY’s platform enables this approach by providing access to both open models like Tulu 3 and proprietary alternatives, allowing teams to compare responses and choose the right tool for each task.
Strategic consideration: As open models from China and other sources continue improving, maintaining familiarity with open alternatives reduces dependency risk and provides negotiating leverage with proprietary vendors.
Frequently Asked Questions
What is the main difference between Tulu 3 and OpenAI’s o1?
Tulu 3 is a fully open-source post-training framework with complete transparency in training data, code, and methodology, while o1 is a proprietary inference API with undisclosed training approaches[1][3]. Tulu 3 enables reproducibility, customization, and self-hosting that o1 doesn’t allow.
Can small research teams realistically deploy Tulu 3?
Yes, through Hugging Face hosted inference or cloud GPU instances. Teams don’t need massive infrastructure—a single high-end GPU can run smaller Tulu 3 variants for many research applications. Start with hosted inference, then scale to self-hosting as volume increases.
How does Tulu 3 handle domain-specific scientific terminology?
Base Tulu 3 models have general scientific knowledge from pretraining, but domain-specific fine-tuning significantly improves performance on specialized terminology and reasoning patterns. The framework provides all tools needed for custom fine-tuning on your domain literature.
What size models does Tulu 3 support?
Tulu 3 is built on Llama 3.1 base models, supporting multiple parameter sizes. Smaller models work for many research tasks with lower computational requirements, while larger variants provide stronger reasoning for complex problems. Choose based on your task complexity and infrastructure.
Is Tulu 3 suitable for production research applications or just experiments?
Tulu 3 is production-ready. The framework includes comprehensive evaluation, safety testing, and deployment tools. Many research institutions use it for ongoing research workflows, not just proof-of-concept work. Establish evaluation metrics for your use case and validate performance before full deployment.
How often is Tulu 3 updated?
AllenAI continues developing the framework based on community feedback and research advances. The open-source nature means updates are transparent and you control when to adopt new versions—no forced upgrades or deprecated features.
Can Tulu 3 be fine-tuned on proprietary research data?
Yes, that’s a key advantage. You can fine-tune on confidential datasets within your own infrastructure without data ever leaving your control. This enables customization that API-based proprietary models can’t provide while maintaining data privacy.
What GPU requirements does Tulu 3 have for self-hosting?
Requirements depend on model size and batch size. Smaller variants run on single high-end GPUs (A100, H100), while larger models benefit from multi-GPU setups. For research applications with modest throughput needs, cloud GPU instances provide cost-effective deployment without owning hardware.
How does Tulu 3 compare to other open models like Qwen or Mistral?
Tulu 3 outperforms Llama 3.1-Instruct, Qwen2.5-Instruct, and Mistral-Instruct of equivalent sizes on AllenAI’s comprehensive evaluation suite[4]. The key differentiator is complete framework transparency—not just model weights but all training code, data, and evaluation tools.
What license does Tulu 3 use?
Tulu 3 inherits the Llama 3.1 license for model weights, with framework code released under permissive open-source licenses. Check specific license terms for commercial use cases, but research applications are generally unrestricted.
Can Tulu 3 handle multimodal inputs like images or scientific diagrams?
The current Tulu 3 release focuses on text-based reasoning. For multimodal scientific applications involving images, diagrams, or other modalities, consider combining Tulu 3 with specialized vision models or exploring multimodal alternatives.
How do I get started with Tulu 3 for my research?
Start by accessing models on Hugging Face for immediate experimentation. Run evaluations on a small sample of your research tasks to validate performance. If results are promising, either continue with hosted inference or set up self-hosting using AllenAI’s provided deployment code. Join the community on GitHub for support and best practices.
Conclusion
AllenAI’s O1 and Tulu 3: Revolutionizing Open Research AI for Scientific Discovery in 2026 delivers on a critical promise—making frontier AI capabilities accessible, transparent, and customizable for research institutions. The framework’s complete openness, from training data to evaluation tools, enables the reproducibility and verification that scientific work demands.
For research teams evaluating AI options in 2026, Tulu 3 offers a compelling alternative to proprietary black boxes. The four-stage training methodology, including novel RLVR techniques, achieves competitive performance while maintaining full transparency. Deployment paths range from simple Hugging Face hosted inference to customized self-hosting with domain-specific fine-tuning.
The paradigm shift toward post-training innovation means smaller teams can now compete by focusing on training recipes rather than massive pretraining infrastructure. Tulu 3 democratizes these methodologies, accelerating scientific discovery across institutions that previously lacked access to frontier AI capabilities.
Next steps for research teams:
- Evaluate on your tasks: Test Tulu 3 on a representative sample of your research workflows using Hugging Face hosted inference
- Compare alternatives: Use MULTIBLY’s platform to compare Tulu 3 responses against proprietary models for your specific use cases
- Calculate total cost: Estimate usage volume and compare hosted inference costs versus self-hosting infrastructure
- Plan deployment: Choose between hosted inference (faster start, lower initial cost) or self-hosting (better long-term economics, full control)
- Consider fine-tuning: If base model performance is promising but not optimal, evaluate domain-specific fine-tuning benefits
- Establish evaluation metrics: Define success criteria for your research tasks before full deployment
- Join the community: Engage with AllenAI’s GitHub repository and research community for support and best practices
The open research AI movement continues gaining momentum. Teams that adopt transparent, customizable frameworks like Tulu 3 position themselves for sustainable, reproducible scientific discovery while reducing dependency on proprietary vendors. In 2026, openness and performance are no longer mutually exclusive—Tulu 3 proves you can have both.
References
[1] Tulu 3 – https://www.interconnects.ai/p/tulu-3
[2] Inside Tülu 3 Allen Ais New Post Training Framework Abbb9533c890 – https://pub.towardsai.net/inside-t%C3%BClu-3-allen-ais-new-post-training-framework-abbb9533c890
[3] Tulu 3 – https://allenai.org/blog/tulu-3
[4] Tulu 3 Technical – https://allenai.org/blog/tulu-3-technical
[5] Openai O1 Mini Vs Tulu 3 – https://slashdot.org/software/comparison/OpenAI-o1-mini-vs-Tulu-3/
[6] Tulu – https://allenai.org/tulu
[7] Open Instruct – https://github.com/allenai/open-instruct
[8] The Best Ai Models So Far In 2026 – https://designforonline.com/the-best-ai-models-so-far-in-2026/



