
Moonshot AI released Kimi Linear in October 2025 as a 48-billion parameter mixture-of-experts model designed to slash memory requirements and boost generation speed for ultra-long context processing. The model introduces Kimi Delta Attention (KDA), a hardware-aware attention mechanism that addresses the computational bottleneck plaguing traditional transformers when handling massive context windows. For teams processing lengthy documents, legal contracts, or multi-turn conversations, Kimi Linear offers a practical alternative that balances efficiency with performance—though it sits in a different tier than Moonshot’s flagship K2.5 model released in January 2026.
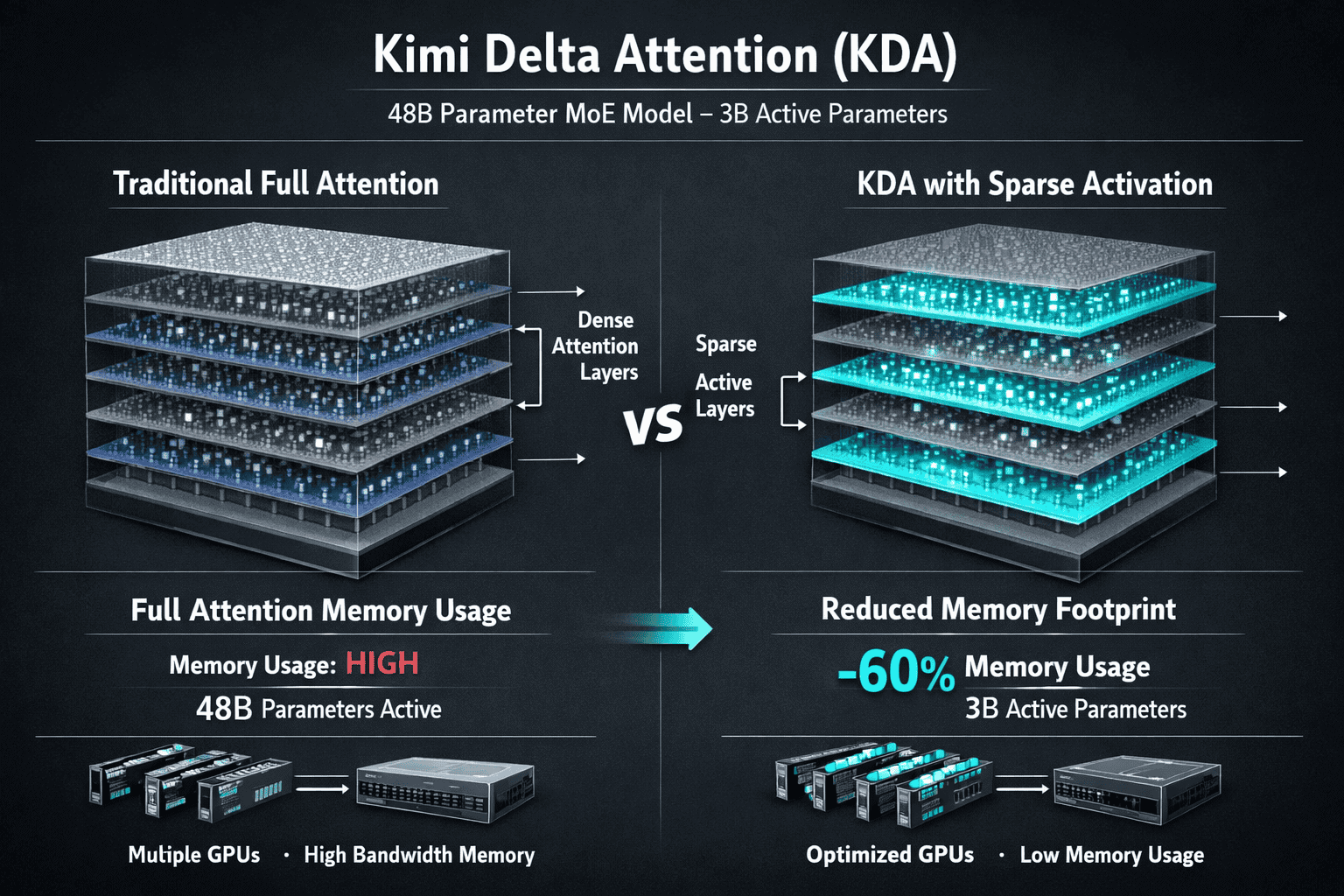
The breakthrough centers on a hybrid attention design: KDA layers handle most of the heavy lifting (75% of the architecture), while standard full attention layers (25%) maintain quality on critical reasoning tasks[3]. This 3:1 ratio delivers measurable speed gains without sacrificing the model’s ability to understand and generate coherent responses across context lengths that would choke conventional architectures.
- Key Takeaways
- Quick Answer
- What Is Kimi Linear and Why Does It Matter?
- How Does Kimi Delta Attention (KDA) Reduce Memory and Improve Speed?
- What Is the Hybrid Attention Design and How Does It Balance Efficiency with Performance?
- How Does Kimi Linear Compare to Grok 4's 2M Context Window?
- What Are the Real-World Applications Where Kimi Linear Excels?
- How Does Kimi Linear Fit Within Moonshot AI's Broader Model Portfolio?
- What Are the Speed Benchmarks and Pricing Considerations for Kimi Linear?
- What Are Common Mistakes When Deploying Kimi Linear for Long-Context Tasks?
- FAQ
- Conclusion
- References
Key Takeaways
- Kimi Linear uses Kimi Delta Attention (KDA) to reduce memory consumption and accelerate inference for long-context scenarios, making it viable for resource-constrained deployments[1][3]
- The 48B parameter MoE architecture activates only 3B parameters per forward pass, cutting computational overhead while maintaining competitive performance across document processing tasks[1]
- Hybrid attention design (3:1 KDA-to-full-attention ratio) balances efficiency gains with quality preservation, especially important for reasoning-heavy workloads[3]
- Built on Moonlight backbone technology, which evolved from the Muon optimizer used in K2 series training and demonstrates scalability for large-scale LLM development[3]
- Positioned as an efficiency-tier model within Moonshot’s portfolio, Kimi Linear serves specialized use cases requiring extreme efficiency rather than cutting-edge multimodal or agentic capabilities found in K2.5[1][4]
- Choose Kimi Linear over massive context models like Grok 4 when inference speed and memory constraints matter more than absolute context window size—particularly for batch processing or edge deployments
- Real-world applications include document analysis, legal contract review, and customer support where context length exceeds 32K tokens but doesn’t require the 2M token windows offered by competitors
Quick Answer
Kimi Linear is Moonshot AI’s October 2025 release that tackles the memory and speed challenges of processing ultra-long contexts through Kimi Delta Attention (KDA), a hardware-optimized attention mechanism. The 48B parameter mixture-of-experts model activates just 3B parameters per inference, delivering faster generation speeds and lower memory usage than traditional full-attention transformers[1][3]. It sits between lightweight models and compute-intensive giants like Grok 4, making it practical for teams that need efficient long-context processing without the infrastructure costs of 2M-token context windows.
What Is Kimi Linear and Why Does It Matter?
Kimi Linear is a 48-billion parameter mixture-of-experts (MoE) language model from Moonshot AI that addresses a fundamental problem: traditional transformer attention mechanisms become prohibitively expensive as context length grows. Released in October 2025, the model introduces Kimi Delta Attention (KDA), a hardware-aware attention design that reduces memory footprint and accelerates generation speed specifically for longer context windows[1][3].
The model activates only 3 billion parameters during each forward pass, despite its 48B total parameter count. This sparse activation pattern cuts computational overhead while maintaining performance across tasks that require understanding and generating text from lengthy inputs—think legal document analysis, multi-chapter book summaries, or extended customer conversation histories.
Why it matters in 2026: Most organizations can’t afford the infrastructure to run models with 2M-token context windows at scale. Kimi Linear offers a middle path—context lengths that exceed what smaller models handle (typically 32K-128K tokens) without the memory and latency penalties of full-attention architectures. For teams processing documents, contracts, or transcripts that fall into this “medium-long” context range, Kimi Linear delivers practical efficiency gains.
The model builds on Moonlight, Moonshot’s training framework that evolved from the Muon optimizer used in the K2 series[3]. This foundation demonstrates scalability, but Moonshot has been transparent about resource constraints: the company stated it lacks capacity for infinite compute scaling, making algorithmic and system-level efficiency improvements a strategic necessity rather than an optional optimization[4].
Common mistake: Assuming Kimi Linear competes directly with K2.5 or other flagship models. It doesn’t. Kimi Linear serves as a specialized efficiency tier within Moonshot’s portfolio, not a replacement for models with multimodal capabilities or advanced agentic features[1][4].
How Does Kimi Delta Attention (KDA) Reduce Memory and Improve Speed?
Kimi Delta Attention (KDA) is the core innovation that separates Kimi Linear from standard transformer architectures. Traditional full attention requires every token to attend to every other token in the context window, creating quadratic memory and computational complexity. As context length doubles, memory requirements quadruple—a scaling problem that becomes unsustainable beyond certain thresholds.
KDA solves this through hardware-aware optimization that selectively computes attention scores. Instead of full pairwise comparisons across all tokens, KDA uses delta-based approximations that identify which tokens actually need full attention and which can be handled through more efficient mechanisms[1][3].
How it works in practice:
- Sparse attention patterns focus computational resources on tokens that contribute most to the output, skipping redundant calculations
- Hardware alignment ensures the attention mechanism maps efficiently to GPU memory hierarchies, reducing data movement between cache levels
- Dynamic adaptation adjusts attention granularity based on context length—shorter contexts may use more full attention, while longer contexts lean harder on KDA approximations
The hybrid architecture combines KDA layers with standard full attention in a 3:1 ratio[3]. This means 75% of the model’s layers use the efficient KDA mechanism, while 25% retain full attention to preserve quality on reasoning-intensive tasks. The ratio represents a deliberate trade-off: too much KDA risks degrading output quality; too little fails to deliver meaningful efficiency gains.
Measured benefits:
- Lower peak memory consumption during inference, enabling deployment on hardware that couldn’t run equivalent full-attention models
- Faster token generation speeds for long-context scenarios, particularly noticeable when context exceeds 64K tokens
- Maintained effectiveness across context lengths compared to traditional methods, avoiding the quality cliff some efficient attention mechanisms encounter[4]
Edge case: KDA’s efficiency gains are most pronounced in long-context scenarios. For short prompts (under 8K tokens), the overhead of KDA’s dynamic adaptation may actually result in slightly slower performance than simpler attention mechanisms. Choose Kimi Linear when your typical workload involves context lengths where the efficiency trade-off pays dividends.
What Is the Hybrid Attention Design and How Does It Balance Efficiency with Performance?
Kimi Linear’s hybrid attention architecture combines two distinct mechanisms: Kimi Delta Attention (KDA) layers and standard full attention layers in a 3:1 ratio[3]. This design acknowledges that not all model layers require the same level of attention precision—some can sacrifice exactness for speed without degrading output quality, while others need full attention to maintain reasoning capabilities.
The 3:1 ratio breakdown:
- 75% KDA layers handle the majority of token processing, applying hardware-optimized sparse attention that reduces memory and accelerates computation
- 25% full attention layers preserve model quality on tasks requiring precise token relationships, such as logical reasoning, mathematical problem-solving, or nuanced language understanding
This layering strategy differs from architectures that apply a single attention mechanism uniformly across all layers. By concentrating full attention where it matters most—typically in deeper layers responsible for higher-level reasoning—Kimi Linear maintains competitive performance while gaining efficiency benefits from KDA in earlier layers.
Decision criteria for the ratio: Moonshot’s research likely tested multiple configurations before settling on 3:1. Too few full attention layers risk quality degradation on complex tasks; too many negate the efficiency advantages of KDA. The chosen ratio suggests that most token processing benefits from efficiency optimizations, but critical reasoning paths still require traditional attention mechanisms.
Real-world implication: When evaluating Kimi Linear for your use case, consider the reasoning complexity of your tasks. Document summarization, information extraction, and basic question-answering typically perform well with this hybrid design. Highly complex reasoning tasks—multi-step mathematical proofs, intricate logical puzzles, or advanced code generation—may see better results from models with higher full-attention ratios or different architectural choices.
Comparison to alternatives:
| Architecture Type | Memory Efficiency | Reasoning Quality | Best For |
|---|---|---|---|
| Full Attention (GPT-4o, Claude) | Low | High | Complex reasoning, short-to-medium contexts |
| Kimi Linear (3:1 Hybrid) | Medium-High | Medium-High | Long documents, batch processing, cost-sensitive deployments |
| Pure Sparse Attention | High | Medium | Extreme context lengths, simple extraction tasks |
| Grok 4 (2M Context) | Low | High | Massive contexts, real-time data integration |
Choose Kimi Linear when you need better-than-sparse performance without the infrastructure costs of pure full-attention models at scale.
How Does Kimi Linear Compare to Grok 4’s 2M Context Window?
Kimi Linear and Grok 4 solve different problems. Grok 4’s 2-million token context window targets scenarios requiring massive information synthesis—think analyzing entire codebases, processing months of conversation history, or integrating real-time data streams from X (formerly Twitter)[6]. Kimi Linear focuses on efficiency for “medium-long” contexts (typically 32K-256K tokens), where most enterprise document processing actually happens.
Context window size:
- Kimi Linear: Optimized for contexts up to 256K tokens, though specific limits aren’t publicly detailed in available documentation
- Grok 4: 2M token context window, enabling unprecedented information synthesis but requiring substantial computational resources
Architectural philosophy:
- Kimi Linear: Efficiency-first design using KDA to reduce memory and accelerate inference, accepting some trade-offs in absolute reasoning capability
- Grok 4: Performance-first approach with massive context capacity and full attention mechanisms, prioritizing capability over efficiency
Speed and memory trade-offs:
Kimi Linear’s KDA mechanism delivers faster token generation for long contexts compared to full-attention models of similar parameter counts. Grok 4’s 2M window requires significantly more memory and compute per token, making it practical primarily for organizations with substantial infrastructure budgets.
In practice, most document processing tasks don’t require 2M tokens. Legal contracts, research papers, customer support transcripts, and business reports typically fall into the 10K-200K token range—exactly where Kimi Linear’s efficiency advantages matter most.
Choose Kimi Linear if:
- Your typical context length is 32K-256K tokens
- Inference speed and memory efficiency are critical constraints
- You’re running batch processing workloads where cost per token matters
- You need to deploy on mid-tier GPU infrastructure
Choose Grok 4 if:
- You regularly process contexts exceeding 500K tokens
- Your use case requires synthesizing information across massive datasets
- You need real-time integration with external data streams
- Infrastructure costs are less critical than absolute capability
Common mistake: Assuming bigger context windows always deliver better results. Beyond a certain threshold, most tasks don’t benefit from additional context—they benefit from better retrieval, chunking strategies, or task decomposition. Kimi Linear’s focused efficiency often outperforms brute-force massive context approaches for real-world enterprise workloads.
For teams comparing models, platforms like MULTIBLY let you test Kimi Linear alongside Grok 4 and other models with different context capabilities, helping you identify which architecture actually performs best for your specific documents and tasks.
What Are the Real-World Applications Where Kimi Linear Excels?
Kimi Linear’s efficiency-focused design makes it particularly effective for specific use cases where context length exceeds what smaller models handle comfortably, but doesn’t require the massive windows of models like Grok 4. The model’s 3B active parameters and KDA mechanism deliver practical advantages in scenarios where speed, memory, and cost matter as much as raw capability.
Document processing and analysis:
Organizations handling lengthy contracts, research papers, regulatory filings, or technical documentation benefit from Kimi Linear’s ability to process entire documents in a single context window. The model can extract key information, generate summaries, or answer questions without chunking strategies that risk losing cross-reference context.
Example: A legal team reviewing 50-page merger agreements can feed the entire contract to Kimi Linear for clause extraction, risk identification, or comparison against standard templates—tasks that require understanding relationships between sections separated by thousands of tokens.
Customer support and conversation history:
Support teams managing extended customer interactions across multiple sessions can use Kimi Linear to maintain context across entire relationship histories. The model processes conversation threads spanning weeks or months, enabling more personalized and context-aware responses than models limited to recent messages.
Batch processing workflows:
When processing hundreds or thousands of documents daily, Kimi Linear’s reduced memory footprint and faster inference enable higher throughput on the same hardware. This efficiency advantage compounds at scale—what might require 10 GPUs with a full-attention model might run on 6-7 GPUs with Kimi Linear, directly impacting operational costs.
Agentic AI systems:
While Kimi Linear lacks the advanced agentic features of K2.5, it can still power agent workflows requiring long-context understanding. The model handles tool use, multi-step reasoning, and state management across extended interactions, though teams needing cutting-edge agentic capabilities should evaluate K2.5’s agent swarm functionality instead.
Edge and resource-constrained deployments:
Organizations running models on-premise or in edge environments with limited GPU memory can deploy Kimi Linear where full-attention models wouldn’t fit. The 3B active parameter count and KDA efficiency make it viable for scenarios where infrastructure constraints would otherwise force compromises on context length or model quality.
Not ideal for:
- Highly complex reasoning tasks requiring maximum model capability (consider larger full-attention models)
- Multimodal workflows involving images, video, or audio (K2.5 or other multimodal models are better choices)
- Contexts exceeding 256K tokens where Grok 4’s massive window provides genuine advantages
- Real-time collaborative editing or live data integration scenarios
Practical deployment tip: Test Kimi Linear against your actual documents and tasks before committing to infrastructure changes. Platforms like MULTIBLY give you access to Kimi Linear alongside 300+ other models, letting you compare performance, speed, and output quality on your specific workload before making deployment decisions.
How Does Kimi Linear Fit Within Moonshot AI’s Broader Model Portfolio?
Moonshot AI maintains a tiered model portfolio designed to serve different use cases and deployment constraints. Kimi Linear occupies the efficiency tier—optimized for speed and memory rather than absolute capability or feature breadth. Understanding where it sits relative to other Moonshot models helps teams choose the right tool for specific tasks.
Moonshot’s model lineup (as of early 2026):
- Kimi K2 series: Long-context models with 256K token windows, balancing capability with practical deployment requirements[5][8]
- Kimi K2.5: January 2026 release adding multimodal capabilities (vision, audio) and agent swarm functionality for coordinated multi-agent workflows[2][4]
- Kimi Linear: October 2025 efficiency-focused model using KDA for reduced memory and faster inference on long contexts[1][3]
Strategic positioning:
Kimi Linear represents Moonshot’s acknowledgment that not every deployment requires cutting-edge capabilities. Some organizations need efficient processing of medium-long contexts more than they need multimodal understanding or advanced agentic features. By offering a lighter-weight alternative, Moonshot captures use cases where K2.5’s additional capabilities would go unused but its resource requirements would still impose costs.
The model builds on Moonlight, the same backbone technology underlying the K2 series[3]. This shared foundation means Kimi Linear benefits from training optimizations developed for flagship models, even though it targets a different performance-efficiency trade-off point.
Evolution and focus shift:
Moonshot’s January 2026 emphasis on K2.5 suggests the company views multimodal and agentic capabilities as the strategic frontier for differentiation. Kimi Linear likely serves as a stable, maintained offering for efficiency-constrained deployments rather than the focus of active feature development[1][2][4].
This doesn’t diminish Kimi Linear’s value—it clarifies its role. Organizations needing efficient long-context processing without multimodal or advanced agentic features get a model optimized for exactly that use case, without paying for capabilities they won’t use.
Decision framework:
- Choose K2.5 if: You need multimodal understanding, agent swarm coordination, or cutting-edge reasoning capabilities
- Choose K2 if: You need strong long-context performance (256K tokens) without multimodal features
- Choose Kimi Linear if: Efficiency (speed, memory, cost) matters more than absolute capability for your long-context workload
Ecosystem context:
Moonshot competes in a crowded field of Chinese AI labs pushing open-weight models and efficiency innovations. DeepSeek R1, GLM-4.5, and Qwen3 all offer competitive alternatives with different trade-offs. Kimi Linear’s KDA mechanism represents Moonshot’s particular bet on how to achieve efficiency—hardware-aware attention design rather than pure parameter scaling or architectural novelty.
For teams evaluating multiple Chinese models alongside Western alternatives, comparing responses side by side reveals practical performance differences that benchmarks alone don’t capture.
What Are the Speed Benchmarks and Pricing Considerations for Kimi Linear?
Specific public benchmarks for Kimi Linear remain limited as of early 2026, but the architectural design provides clear indicators of where performance advantages emerge. The KDA mechanism’s efficiency gains are most pronounced in long-context scenarios, where traditional full-attention models face quadratic scaling penalties.
Expected performance characteristics:
- Faster token generation for contexts exceeding 64K tokens compared to full-attention models of similar parameter counts
- Lower memory consumption enabling deployment on mid-tier GPUs that couldn’t run equivalent full-attention architectures
- Maintained quality across context lengths without the degradation some sparse attention mechanisms exhibit[4]
The 3B active parameter count (from a 48B total parameter MoE architecture) means each forward pass requires less computation than dense models with similar capabilities. This translates to faster inference and lower cost per token in production deployments.
Pricing and deployment costs:
Moonshot AI has not published standardized API pricing for Kimi Linear as of early 2026. Organizations interested in deployment should contact Moonshot directly or work with partners offering access to the model. Pricing will likely reflect the efficiency advantages—lower per-token costs than full-attention models, but potentially higher than smaller, simpler architectures.
Cost comparison framework:
When evaluating total cost of ownership, consider:
- Infrastructure costs: GPU memory requirements, throughput per instance, scaling characteristics
- API costs: Per-token pricing if using hosted endpoints
- Operational costs: Latency impact on user experience, batch processing throughput, maintenance overhead
For organizations running models on-premise, Kimi Linear’s reduced memory footprint can enable deployment on existing hardware that couldn’t support larger full-attention models. This infrastructure reuse delivers cost savings beyond per-token pricing comparisons.
Benchmark interpretation:
Public benchmarks often focus on accuracy metrics (MMLU, HumanEval, etc.) that don’t capture efficiency advantages. When evaluating Kimi Linear, prioritize benchmarks that measure:
- Tokens per second at various context lengths
- Memory usage across different batch sizes
- Latency percentiles (p50, p95, p99) for production-like workloads
- Quality maintenance as context length increases
Practical testing approach:
Rather than relying solely on published benchmarks, test Kimi Linear against your actual documents and tasks. Platforms like MULTIBLY let you compare Kimi Linear’s performance against other long-context models including Grok 4, Claude Opus 4.5, and GPT-5 on your specific workload before committing to infrastructure investments.
Edge case: For very short contexts (under 8K tokens), Kimi Linear’s KDA overhead may result in slightly slower performance than simpler models. The efficiency advantages emerge specifically in the medium-long context range where traditional attention mechanisms become prohibitively expensive.
What Are Common Mistakes When Deploying Kimi Linear for Long-Context Tasks?
Organizations adopting Kimi Linear often make predictable mistakes that limit the model’s effectiveness or lead to disappointing results. Understanding these pitfalls helps teams deploy the model successfully and set appropriate expectations.
Mistake 1: Assuming bigger context always means better results
Just because Kimi Linear can handle long contexts doesn’t mean every task benefits from maximum context length. Many document processing tasks perform better with targeted retrieval and focused context rather than dumping entire document collections into a single prompt.
Better approach: Use retrieval-augmented generation (RAG) to identify relevant sections, then feed focused context to Kimi Linear. Save the full context window for tasks that genuinely require understanding relationships across an entire lengthy document.
Mistake 2: Ignoring the efficiency-capability trade-off
Kimi Linear’s KDA mechanism delivers efficiency gains by making deliberate trade-offs versus full-attention models. Teams expecting flagship-level reasoning performance on highly complex tasks will be disappointed.
Better approach: Match the model to the task complexity. Use Kimi Linear for document analysis, summarization, and information extraction. Route complex reasoning tasks to models optimized for capability rather than efficiency, like Claude Opus 4.5 or GPT-5.
Mistake 3: Skipping comparative testing on actual workloads
Benchmarks provide useful directional guidance but don’t predict performance on your specific documents and tasks. Organizations that deploy based on published metrics alone often discover unexpected quality or speed differences in production.
Better approach: Test Kimi Linear against alternatives on representative samples of your actual workload. MULTIBLY enables side-by-side comparison of responses from Kimi Linear and 300+ other models, revealing practical differences benchmarks don’t capture.
Mistake 4: Underestimating prompt engineering requirements
Long-context models require different prompting strategies than short-context alternatives. Simply dumping a 100K-token document into a prompt without structure often produces mediocre results regardless of the model’s capabilities.
Better approach: Structure long-context prompts with clear sections, explicit instructions about what information matters most, and guidance on output format. Use XML tags, markdown headers, or other structural markers to help the model navigate lengthy inputs.
Mistake 5: Deploying without monitoring context length distribution
Teams often overestimate how frequently they actually need maximum context length. If 80% of your workload uses under 32K tokens, you’re paying for efficiency optimizations you rarely use.
Better approach: Monitor actual context length distribution in production. Route shorter contexts to faster, cheaper models and reserve Kimi Linear for tasks that genuinely benefit from its long-context efficiency.
Mistake 6: Ignoring the model’s position in Moonshot’s portfolio
Kimi Linear is an efficiency tier model, not Moonshot’s flagship. Teams expecting cutting-edge capabilities or active feature development may be frustrated by the company’s focus on K2.5 for new innovations[1][2][4].
Better approach: Understand that Kimi Linear serves specialized efficiency-constrained use cases. If you need the latest capabilities, evaluate K2.5 or other models positioned at the capability frontier.
FAQ
What makes Kimi Linear different from other long-context models?
Kimi Linear uses Kimi Delta Attention (KDA), a hardware-aware attention mechanism that reduces memory usage and accelerates inference specifically for long contexts. The hybrid 3:1 architecture combines KDA efficiency layers with full attention layers to balance speed with quality[1][3].
How many parameters does Kimi Linear have?
Kimi Linear is a 48-billion parameter mixture-of-experts (MoE) model that activates only 3 billion parameters per forward pass, reducing computational overhead while maintaining performance[1].
What context length does Kimi Linear support?
While specific limits aren’t publicly detailed, Kimi Linear is optimized for contexts in the 32K-256K token range, based on its positioning relative to other Moonshot models and the efficiency focus of its design.
Is Kimi Linear better than Grok 4 for long-context tasks?
Not universally. Kimi Linear excels when efficiency (speed, memory, cost) matters more than absolute context size. Grok 4’s 2M token window serves different use cases requiring massive information synthesis. Choose based on your typical context length and infrastructure constraints.
Can Kimi Linear handle multimodal inputs like images or audio?
No. Kimi Linear is a text-only model. For multimodal capabilities, consider Moonshot’s K2.5 or other models designed for vision and audio understanding[2][4].
What is the pricing for Kimi Linear API access?
Moonshot AI has not published standardized API pricing for Kimi Linear as of early 2026. Organizations should contact Moonshot directly or work with partners offering model access for current pricing information.
How does the 3:1 hybrid attention ratio affect performance?
The 3:1 ratio (75% KDA layers, 25% full attention) delivers efficiency gains on most token processing while preserving quality on reasoning-intensive tasks. This balance works well for document analysis and extraction but may underperform pure full-attention models on highly complex reasoning[3].
What hardware is required to run Kimi Linear?
Specific hardware requirements depend on deployment configuration, but Kimi Linear’s reduced memory footprint enables deployment on mid-tier GPUs that couldn’t run equivalent full-attention models. The 3B active parameter count makes it more accessible than dense 48B parameter architectures.
Does Kimi Linear support agentic AI workflows?
Kimi Linear can power basic agentic workflows requiring long-context understanding, tool use, and multi-step reasoning. However, teams needing advanced agentic capabilities should evaluate K2.5’s agent swarm functionality instead[2][4].
How does Kimi Linear compare to open-source alternatives like DeepSeek R1 or GLM-4.5?
Each model makes different architectural trade-offs. Kimi Linear prioritizes efficiency through KDA, while DeepSeek R1 emphasizes reasoning capability and GLM-4.5 focuses on open-source performance. Comparative testing on your specific workload reveals which architecture performs best for your use case.
Is Kimi Linear open-source?
Based on available information, Kimi Linear appears to be a proprietary model from Moonshot AI, though the company has released some technical details about the architecture. Check Moonshot’s official channels for current licensing and access policies.
What tasks should I avoid using Kimi Linear for?
Avoid using Kimi Linear for highly complex reasoning tasks requiring maximum model capability, multimodal workflows, contexts exceeding 256K tokens, or scenarios where you need cutting-edge agentic features. Route these tasks to models optimized for capability rather than efficiency.
Conclusion
Kimi Linear represents Moonshot AI’s practical approach to the long-context challenge: deliver efficiency where it matters without chasing the absolute context length records that dominate headlines. The model’s Kimi Delta Attention mechanism and hybrid 3:1 architecture address real deployment constraints—memory, speed, cost—that organizations face when processing medium-long documents at scale.
For teams handling legal contracts, research papers, customer support histories, or business documents in the 32K-256K token range, Kimi Linear offers a compelling efficiency-capability balance. The 3B active parameter count and hardware-aware attention design enable deployment on infrastructure that couldn’t support full-attention alternatives, directly impacting operational costs and throughput.
The model’s October 2025 release and Moonshot’s subsequent focus on K2.5 clarify its strategic role: a stable, efficient option for specialized use cases rather than the cutting edge of capability development. This positioning doesn’t diminish its value—it defines where Kimi Linear delivers genuine advantages over both smaller models and resource-intensive giants like Grok 4.
Next steps for teams evaluating Kimi Linear:
- Test on actual workloads using platforms like MULTIBLY to compare Kimi Linear’s performance against alternatives on your specific documents and tasks
- Measure context length distribution in your current workflows to determine whether Kimi Linear’s efficiency optimizations align with your actual needs
- Benchmark speed and memory on representative hardware to quantify infrastructure savings versus full-attention models
- Route tasks strategically based on complexity—use Kimi Linear for efficient document processing and reserve capability-optimized models for complex reasoning
- Monitor the broader landscape of long-context innovations to ensure your model choices evolve with the rapidly advancing field
The long-context race continues, with models pursuing different points on the efficiency-capability spectrum. Kimi Linear’s contribution is demonstrating that hardware-aware attention design can deliver practical advantages for the medium-long context range where most enterprise work actually happens—a reminder that the best model isn’t always the one with the biggest numbers, but the one that matches your specific constraints and requirements.
References
[1] Kimi (chatbot) – https://en.wikipedia.org/wiki/Kimi_(chatbot)
[2] Tokenring 2026 2 5 The Swarm Emerges Moonshot Ais Kimi K25 Challenges Western Ai Hegemony – https://markets.chroniclejournal.com/chroniclejournal/article/tokenring-2026-2-5-the-swarm-emerges-moonshot-ais-kimi-k25-challenges-western-ai-hegemony
[3] Kimi Linear Moonshot Ai – https://www.digitalocean.com/community/tutorials/kimi-linear-moonshot-ai
[4] Chinas Genius Pipeline Moonshots – https://aiproem.substack.com/p/chinas-genius-pipeline-moonshots
[5] Kimi K2 – https://www.leanware.co/insights/kimi-k2
[6] moonshot.ai – https://www.moonshot.ai
[7] A Dream Of Spring For Open Weight – https://magazine.sebastianraschka.com/p/a-dream-of-spring-for-open-weight
[8] Kimi K2 Thinking What It Means – https://www.interconnects.ai/p/kimi-k2-thinking-what-it-means
[9] Kimi Linear – https://github.com/MoonshotAI/Kimi-Linear



