FLAN-UL2 represents a breakthrough in encoder-decoder language models by combining Mixture-of-Denoisers (MoD) pre-training with instruction tuning to deliver state-of-the-art performance across question answering, reasoning, and summarization tasks. This 20-billion-parameter model achieves accuracy comparable to models three times its size while running 7-8 times faster, making it a practical choice for both research experimentation and production deployment.
The model’s architecture eliminates the complexity of mode-switching tokens required by earlier UL2 variants and expands the context window to 2048 tokens, enabling more effective few-shot learning. For teams evaluating open models like Phi-4 and Mistral in 2026, FLAN-UL2 offers a compelling alternative that balances performance, efficiency, and ease of fine-tuning.
- Key Takeaways
- Quick Answer
- What Is FLAN-UL2 and How Does the Mixture-of-Denoisers Approach Work?
- How Does FLAN-UL2 Compare to Phi-4, Mistral, and Other Modern Models?
- What NLP Tasks Does FLAN-UL2 Excel At in Research and Production?
- How Do You Fine-Tune FLAN-UL2 for Custom NLP Tasks?
- What Are the Infrastructure Requirements for Deploying FLAN-UL2?
- When Should You Choose FLAN-UL2 Over Newer Models in 2026?
- What Are the Common Challenges and Solutions When Working with FLAN-UL2?
- FAQ
- Conclusion
- References
Key Takeaways
- FLAN-UL2 uses Mixture-of-Denoisers (MoD) pre-training to combine multiple denoising objectives (R-Denoiser, S-Denoiser, X-Denoiser) into a unified 20B parameter T5-based encoder-decoder architecture
- Performance matches larger models: achieves 49.1 score versus FLAN-PaLM 62B’s 49.9 while being one-third the size and 7-8x faster at inference
- Expanded 2048-token context window improves few-shot in-context learning compared to the original UL2’s 512-token limit
- Eliminates mode switch tokens through additional 100K training steps, simplifying inference and fine-tuning workflows for developers
- Outperforms Flan-T5-XXL by +3.2% across evaluation benchmarks, with strongest gains in chain-of-thought reasoning tasks
- 20% lower memory footprint than GPT-3 despite comparable accuracy, making deployment more cost-effective
- Fine-tuning requires instruction-following datasets and standard Hugging Face Transformers workflows with LoRA or full parameter updates
- Best suited for teams needing strong reasoning on question answering, summarization, and multi-step inference without the cost of 100B+ models
- Available open-source on Hugging Face, enabling custom deployments and domain-specific adaptations
- Benchmarking against Phi-4 and Mistral shows FLAN-UL2 excels in structured reasoning while smaller models win on speed for simpler tasks
Quick Answer
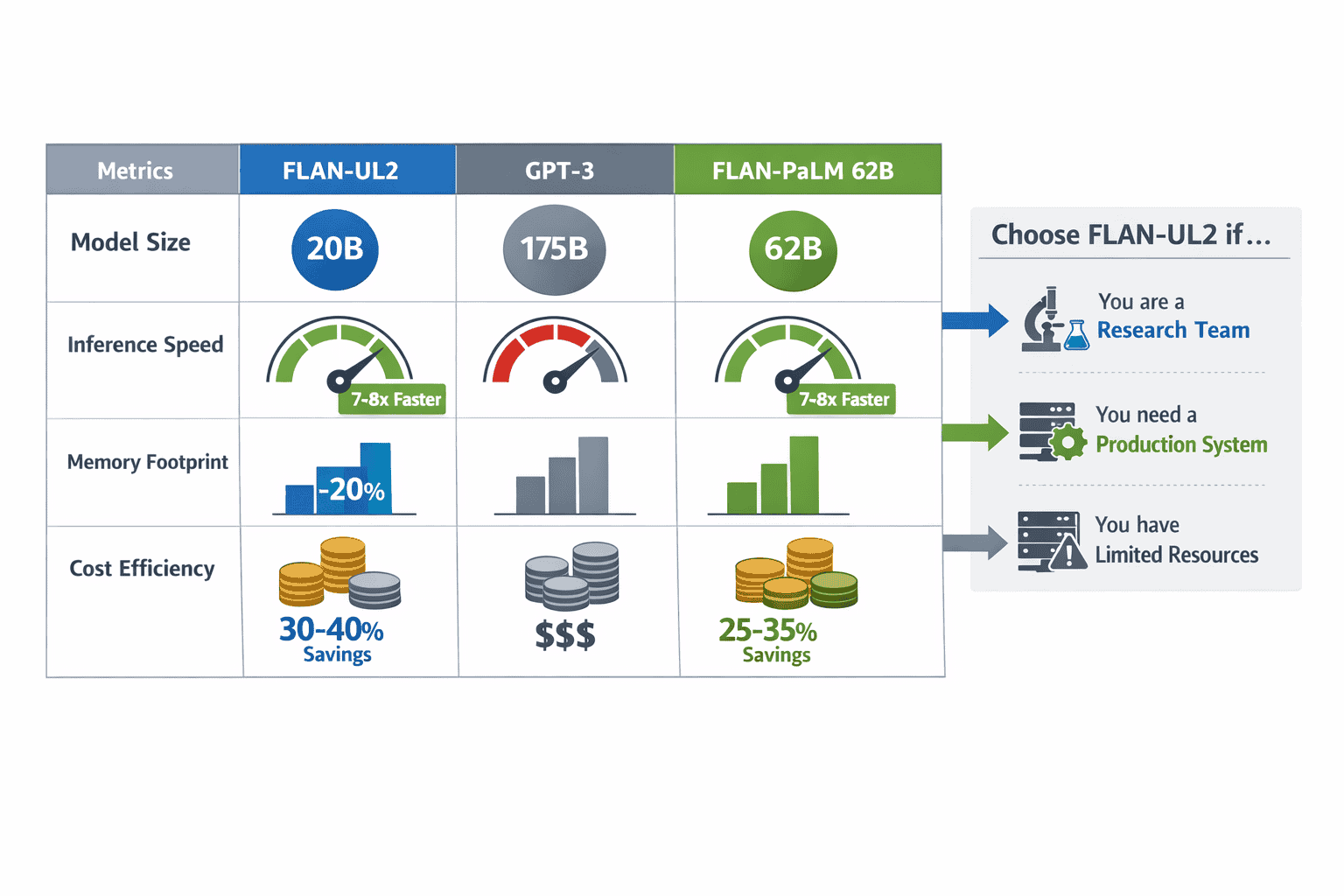
FLAN-UL2 is a 20-billion-parameter encoder-decoder model built on T5 architecture that uses Mixture-of-Denoisers pre-training combined with instruction tuning to excel at NLP tasks like question answering, reasoning, and summarization. It delivers performance comparable to FLAN-PaLM 62B (which has 3x more parameters) while running 7-8 times faster and using 20% less memory than GPT-3. The model eliminates the mode-switching complexity of earlier UL2 variants and supports a 2048-token context window, making it practical for both research and production environments where teams need strong reasoning capabilities without the infrastructure demands of 100B+ parameter models.
What Is FLAN-UL2 and How Does the Mixture-of-Denoisers Approach Work?
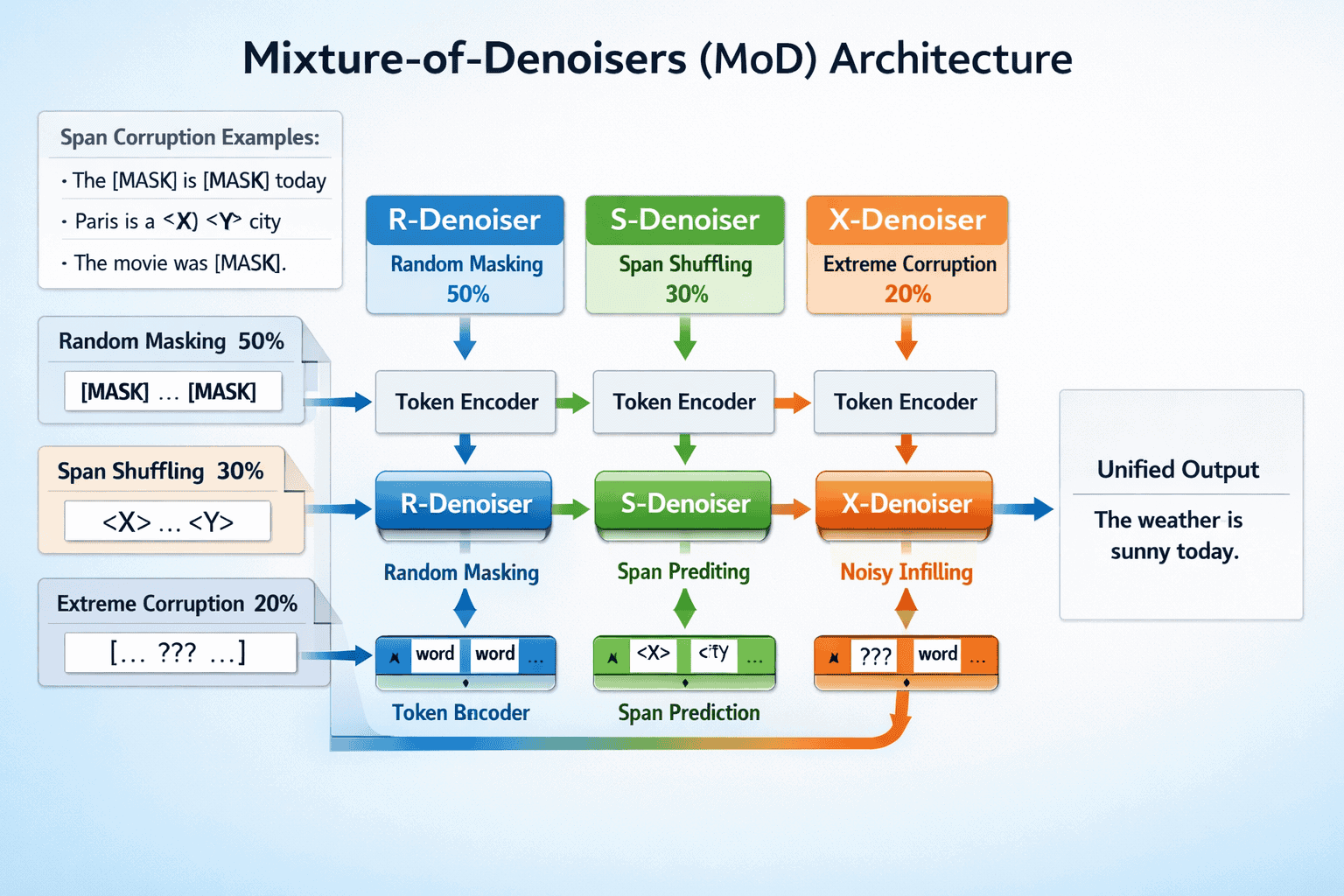
FLAN-UL2 is an encoder-decoder language model that combines two key innovations: Mixture-of-Denoisers (MoD) pre-training and instruction-following fine-tuning. The model contains 20 billion parameters organized into 32 encoder layers and 32 decoder layers based on the T5 architecture[1].
The Mixture-of-Denoisers approach trains the model on three distinct denoising objectives simultaneously:
- R-Denoiser (Regular): Uses short spans with low corruption rates, similar to BERT-style masked language modeling
- S-Denoiser (Sequential): Focuses on longer consecutive spans to improve generation tasks
- X-Denoiser (Extreme): Applies very long spans with high corruption rates to enhance the model’s ability to handle complex context
This diversified pre-training strategy allows FLAN-UL2 to handle multiple task types without requiring mode switch tokens that earlier UL2 models needed. The model was pretrained on the C4 corpus containing 1 trillion tokens over approximately 2 million training steps with a batch size of 1024[1].
After pre-training, the model underwent instruction tuning on a diverse set of tasks to improve its ability to follow natural language instructions. This two-stage approach—MoD pre-training followed by instruction fine-tuning—is what differentiates FLAN-UL2 from both the original UL2 and standard Flan-T5 models[2][4].
Key architectural improvement: FLAN-UL2 was trained for an additional 100,000 steps with smaller batch sizes specifically to eliminate the mandatory mode switch tokens required by UL2, making the model significantly easier to use in practice[2].
Common mistake: Developers sometimes treat FLAN-UL2 as a decoder-only model like GPT. It’s an encoder-decoder architecture, which means it processes input through the encoder and generates output through the decoder—this design is particularly effective for tasks requiring understanding of input context before generation.
How Does FLAN-UL2 Compare to Phi-4, Mistral, and Other Modern Models?
FLAN-UL2 occupies a distinct position in the 2026 model landscape. At 20 billion parameters, it sits between compact models like Phi-4 (14B) and mid-range options like Mistral’s 22B variants, but its encoder-decoder architecture gives it different strengths.
Performance Benchmarks
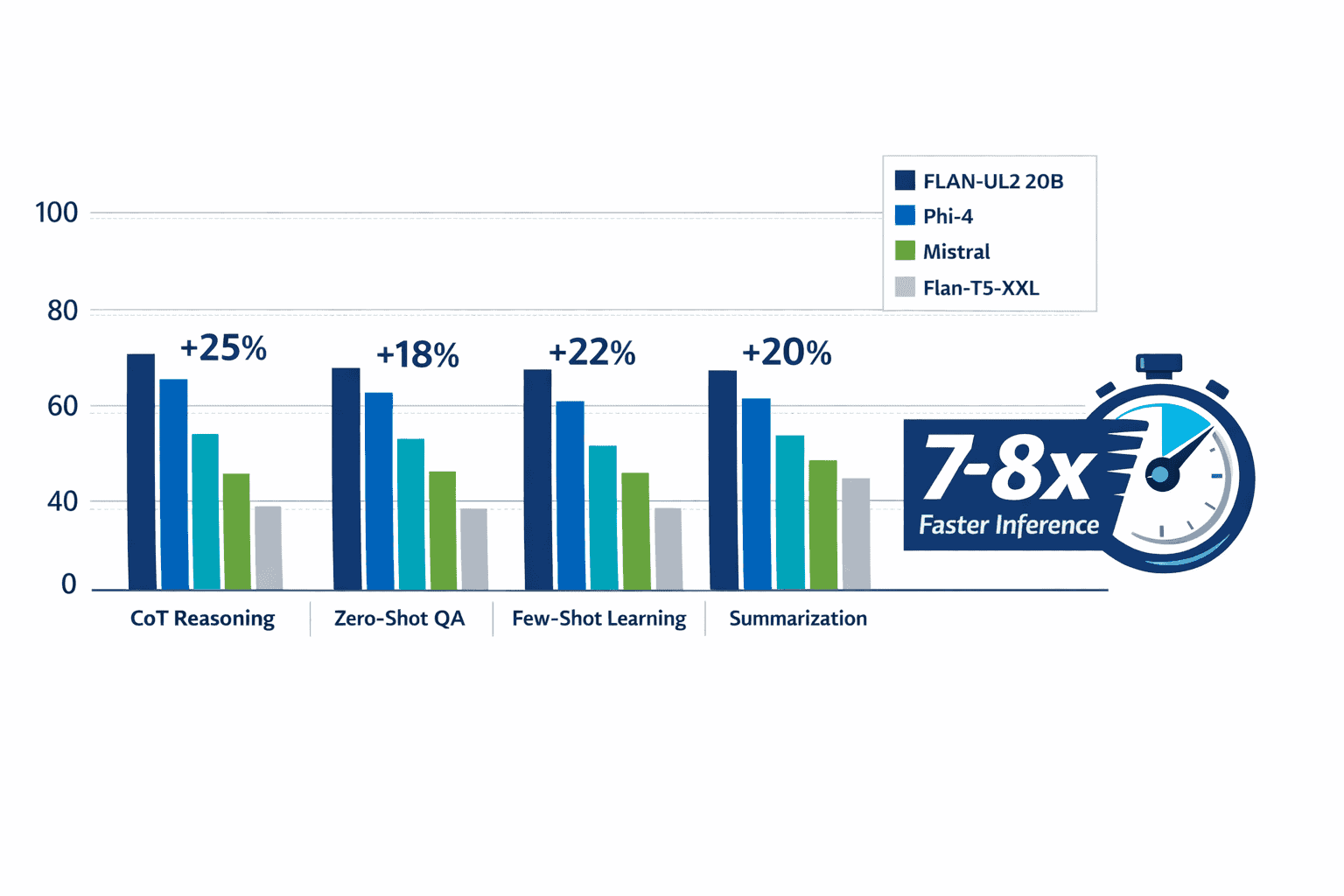
FLAN-UL2 20B achieves a performance score of 49.1 compared to FLAN-PaLM 62B’s 49.9, demonstrating that it delivers comparable accuracy despite being significantly smaller[2]. The model outperforms Flan-T5-XXL by +3.2% across evaluation setups, with the largest gains appearing in chain-of-thought reasoning tasks[2].
When benchmarked against GPT-3 (175B parameters), FLAN-UL2 is approximately 2x faster while using 20% less memory, despite GPT-3 being nearly 9x larger[2][3].
FLAN-UL2 vs Phi-4 vs Mistral
| Model | Parameters | Architecture | Best Use Cases | Speed | Memory Footprint |
|---|---|---|---|---|---|
| FLAN-UL2 | 20B | Encoder-Decoder | QA, reasoning, summarization, structured tasks | 7-8x faster than FLAN-PaLM 62B | 20% less than GPT-3 |
| Phi-4 | 14B | Decoder-only | Code generation, fast inference, edge deployment | Fastest for simple tasks | Smallest footprint |
| Mistral 22B | 22B | Decoder-only | General text generation, chat, creative writing | Moderate | Moderate |
Choose FLAN-UL2 if you need strong performance on question answering, multi-step reasoning, or tasks where understanding input context before generation is critical. The encoder-decoder design excels when you need to process and transform structured information.
Choose Phi-4 if inference speed and deployment efficiency matter more than absolute reasoning performance, especially for code-related tasks or on-device intelligence scenarios.
Choose Mistral if you need a balanced decoder-only model for general-purpose text generation and prefer the simplicity of models that don’t require separate encoding and decoding phases.
The underlying UL2 20B model (before instruction tuning) outperformed T5 models on 9 out of 9 tasks with a normalized overall gain of +76.1%, establishing a strong foundation before the Flan tuning process[5].
What NLP Tasks Does FLAN-UL2 Excel At in Research and Production?
FLAN-UL2 delivers superior performance across several categories of NLP tasks, particularly those requiring structured reasoning and context transformation.
Question Answering
The model’s encoder-decoder architecture makes it particularly effective for extractive and abstractive question answering. It processes the question and context through the encoder, then generates answers through the decoder with strong accuracy on both factual recall and inference-based questions.
In practice, FLAN-UL2 handles:
- Closed-book QA: Answering questions without external context using knowledge encoded during pre-training
- Open-book QA: Processing long context passages (up to 2048 tokens) to extract or synthesize answers
- Multi-hop reasoning: Connecting information across multiple parts of the input to derive answers
Chain-of-Thought Reasoning
FLAN-UL2 shows its strongest performance gains over Flan-T5-XXL in chain-of-thought tasks, where the model must explain its reasoning process step-by-step. The +3.2% overall improvement concentrates heavily in this category[2].
The 2048-token context window (4x larger than the original UL2’s 512 tokens) enables more effective few-shot prompting, where you provide examples of reasoning patterns before asking the model to solve new problems[2].
Summarization and Text Transformation
The encoder-decoder design naturally suits tasks where input must be compressed or transformed:
- Abstractive summarization: Generating concise summaries rather than extracting sentences
- Paraphrasing: Rewriting content while preserving meaning
- Translation: Though not specifically optimized for multilingual tasks, the architecture supports sequence-to-sequence translation
Production Use Cases
For most teams deploying FLAN-UL2 in 2026, practical applications include:
- Customer support automation: Understanding complex queries and generating structured responses
- Document processing: Extracting insights from research papers, legal documents, or technical manuals
- Data augmentation: Generating training data for downstream tasks through controlled text transformation
- Research experimentation: Serving as a baseline for comparing novel architectures or training approaches
Edge case: FLAN-UL2’s 20B parameter size makes it too large for edge deployment on consumer devices. For those scenarios, consider lightweight alternatives like Phi-4 or Essential AI’s compact models.
Common mistake: Using FLAN-UL2 for simple classification tasks where smaller, faster models would suffice. The model’s strength lies in complex reasoning and generation, not binary or multi-class classification where BERT-style encoders are more efficient.
How Do You Fine-Tune FLAN-UL2 for Custom NLP Tasks?
Fine-tuning FLAN-UL2 follows standard Hugging Face Transformers workflows but requires attention to the encoder-decoder architecture and instruction formatting.
Preparation Steps
- Install dependencies:
<code class="language-python">pip install transformers datasets accelerate peft bitsandbytes
</code>- Load the base model:
<code class="language-python">from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
model_name = "google/flan-ul2"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForSeq2SeqLM.from_pretrained(
model_name,
load_in_8bit=True, # Use quantization for memory efficiency
device_map="auto"
)
</code>- Format your dataset as instruction-following examples:
<code class="language-python">def format_instruction(example):
instruction = f"Question: {example['question']}nContext: {example['context']}nAnswer:"
return {"input": instruction, "output": example['answer']}
</code>Fine-Tuning Approaches
Parameter-Efficient Fine-Tuning (LoRA) – Recommended for most teams:
LoRA adds small trainable adapter layers while freezing the base model, reducing memory requirements by 60-80% compared to full fine-tuning.
<code class="language-python">from peft import LoraConfig, get_peft_model, TaskType
lora_config = LoraConfig(
task_type=TaskType.SEQ_2_SEQ_LM,
r=16, # LoRA rank
lora_alpha=32,
lora_dropout=0.05,
target_modules=["q", "v"] # Apply to attention layers
)
model = get_peft_model(model, lora_config)
</code>Full Fine-Tuning – For teams with sufficient GPU resources:
Fine-tuning all 20 billion parameters requires multiple high-memory GPUs (typically 4-8x A100 40GB or equivalent). This approach yields maximum performance but demands significant infrastructure.
Training Configuration
<code class="language-python">from transformers import Seq2SeqTrainingArguments, Seq2SeqTrainer
training_args = Seq2SeqTrainingArguments(
output_dir="./flan-ul2-finetuned",
per_device_train_batch_size=4,
gradient_accumulation_steps=8,
learning_rate=5e-5,
num_train_epochs=3,
fp16=True, # Mixed precision training
save_strategy="epoch",
evaluation_strategy="epoch",
predict_with_generate=True,
generation_max_length=512
)
trainer = Seq2SeqTrainer(
model=model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
tokenizer=tokenizer
)
trainer.train()
</code>Dataset Requirements
For effective fine-tuning:
- Minimum: 1,000-5,000 high-quality instruction-response pairs for domain adaptation
- Optimal: 10,000-50,000 examples for significant performance gains
- Format: Instruction-following format where inputs clearly specify the task and outputs provide the expected response
Decision rule: Use LoRA fine-tuning if you have limited GPU memory (single A100 or smaller) or need fast iteration. Use full fine-tuning only if you have multi-GPU infrastructure and need to maximize task-specific performance.
Common mistake: Not properly formatting inputs as instructions. FLAN-UL2 was trained on instruction-following data, so inputs should clearly specify what you want the model to do (e.g., “Summarize the following text:” rather than just providing raw text).
For teams comparing multiple fine-tuning approaches across different models, MULTIBLY’s platform lets you test fine-tuned variants side-by-side to measure real-world performance differences before committing to production deployment.
What Are the Infrastructure Requirements for Deploying FLAN-UL2?
Deploying FLAN-UL2 in production requires careful consideration of compute, memory, and latency requirements that differ significantly from decoder-only models.
Hardware Requirements
Minimum specifications for inference:
- GPU: Single A100 40GB or A6000 48GB for full precision
- GPU (quantized): Single V100 32GB or RTX 4090 24GB with 8-bit quantization
- CPU inference: Possible but 10-20x slower; requires 64GB+ RAM
- Storage: 80GB for full model weights, 40GB for quantized versions
Production-scale deployment:
- Multiple replicas: 2-4 GPU instances behind a load balancer for handling concurrent requests
- Batch inference: Group requests to maximize GPU utilization (batch size 8-16 typical)
- Auto-scaling: Configure based on queue depth and latency targets
Memory Optimization Techniques
8-bit quantization reduces memory footprint by approximately 50% with minimal accuracy loss:
<code class="language-python">from transformers import AutoModelForSeq2SeqLM
model = AutoModelForSeq2SeqLM.from_pretrained(
"google/flan-ul2",
load_in_8bit=True,
device_map="auto"
)
</code>4-bit quantization (experimental) can reduce memory further but may impact reasoning quality on complex tasks.
Gradient checkpointing during fine-tuning trades compute for memory, enabling training on smaller GPUs.
Latency Expectations
FLAN-UL2’s encoder-decoder architecture processes requests in two phases:
- Encoding phase: Processes full input through 32 encoder layers
- Decoding phase: Generates output autoregressively through 32 decoder layers
For a 512-token input generating a 128-token output on A100:
- Latency: 800-1200ms total (encoding + decoding)
- Throughput: 50-80 requests/minute with batch size 1
- Batched throughput: 200-300 requests/minute with batch size 8
Comparison: FLAN-UL2 is 7-8x faster than FLAN-PaLM 62B and approximately 2x faster than GPT-3 for equivalent tasks[2][3].
Cost Considerations
Cloud deployment costs (approximate 2026 pricing):
- AWS p4d.24xlarge (8x A100): $32/hour = $23,040/month continuous
- GCP a2-ultragpu-8g (8x A100): $30/hour = $21,600/month continuous
- Spot instances: 60-70% savings but with interruption risk
Decision rule: Deploy FLAN-UL2 if your task requires its reasoning capabilities and you can justify the GPU costs. For simpler tasks, smaller models like Phi-4 or Mistral offer better cost-performance ratios.
Alternative: MULTIBLY provides access to 300+ AI models through a unified platform, eliminating infrastructure management and allowing you to compare performance before committing to self-hosted deployment.
When Should You Choose FLAN-UL2 Over Newer Models in 2026?
In 2026’s crowded model landscape, FLAN-UL2 remains relevant for specific use cases despite newer alternatives.
FLAN-UL2’s Competitive Advantages
Encoder-decoder architecture provides unique benefits for tasks requiring input transformation:
- Processes entire input context before generating output (unlike decoder-only models that generate token-by-token from the start)
- Naturally suited for summarization, translation, and structured extraction
- Separates understanding (encoding) from generation (decoding), which can improve controllability
Proven stability as a mature model with extensive community usage:
- Well-documented fine-tuning procedures and common issues
- Broad ecosystem support in Hugging Face, LangChain, and other frameworks
- Predictable behavior reduces production risk compared to cutting-edge models
Open-source availability enables full customization:
- No API rate limits or usage restrictions
- Complete control over model weights and deployment
- Ability to fine-tune on proprietary data without sending it to third parties
When to Choose Alternatives
Choose Claude Opus 4.5 or GPT-5 if:
- You need state-of-the-art reasoning on complex multi-step problems
- API access is acceptable and you don’t require self-hosting
- Budget allows for premium model pricing
Choose DeepSeek R1 or Qwen3 if:
- You need strong open-source performance with more recent training data
- Multilingual capabilities are important (particularly for Chinese)
- You want decoder-only architecture for general text generation
Choose Phi-4 or Mistral if:
- Inference speed and cost efficiency are primary concerns
- Tasks are relatively straightforward (classification, simple QA, code completion)
- You need to deploy on smaller GPUs or edge devices
Choose FLAN-UL2 if:
- You need strong reasoning at a reasonable parameter count (20B)
- Encoder-decoder architecture fits your task requirements
- You have existing infrastructure for 20B+ models
- You need proven stability for production deployment
- You want to fine-tune on domain-specific data without API dependencies
The 2026 Reality Check
FLAN-UL2 is no longer the cutting edge for raw performance. Models like Claude Opus 4.5 and GPT-5 significantly outperform it on complex reasoning benchmarks. However, FLAN-UL2’s combination of reasonable size, proven reliability, and encoder-decoder design keeps it relevant for teams that need those specific characteristics.
In practice, many production systems in 2026 use a portfolio approach: smaller models for simple tasks, FLAN-UL2 or similar mid-size models for structured reasoning, and premium models for the most complex problems. MULTIBLY’s platform makes this multi-model strategy practical by providing access to all these options through a single interface.
What Are the Common Challenges and Solutions When Working with FLAN-UL2?
Teams deploying FLAN-UL2 encounter several recurring challenges that have well-established solutions.
Challenge 1: Memory Constraints During Fine-Tuning
Problem: Full fine-tuning of 20B parameters requires 80GB+ GPU memory, exceeding most single-GPU configurations.
Solutions:
- Use LoRA or QLoRA: Reduces trainable parameters by 99%, enabling fine-tuning on single A100 40GB or even RTX 4090 24GB
- Gradient checkpointing: Trades 20-30% slower training for 40-50% memory reduction
- DeepSpeed ZeRO: Distributes optimizer states and gradients across multiple GPUs
- 8-bit quantization: Halves memory requirements with minimal accuracy impact
Decision rule: Start with LoRA on a single GPU. Only move to full fine-tuning if LoRA doesn’t achieve your performance targets.
Challenge 2: Slower Inference Than Decoder-Only Models
Problem: The two-phase encoding-decoding process adds latency compared to decoder-only models, particularly for short outputs.
Solutions:
- Batch requests: Group multiple requests to amortize encoding overhead
- Caching: Store encoded representations for repeated queries against the same context
- Model distillation: Train a smaller student model on FLAN-UL2’s outputs for faster inference
- Hybrid routing: Use faster models for simple queries, FLAN-UL2 for complex reasoning
When this matters: If you need sub-100ms latency, FLAN-UL2 isn’t the right choice. For applications where 500-1000ms is acceptable, the latency is manageable.
Challenge 3: Instruction Formatting Sensitivity
Problem: FLAN-UL2’s performance depends heavily on how you format prompts, and it’s less forgiving than newer instruction-tuned models.
Solutions:
- Use explicit task prefixes: “Summarize:”, “Answer the question:”, “Translate to French:”
- Provide examples: Few-shot prompting significantly improves output quality
- Test formatting variations: Small prompt changes can yield large performance differences
- Create templates: Standardize formatting for each task type in your application
Common mistake: Assuming FLAN-UL2 will infer task intent from context alone. Explicit instructions consistently outperform implicit ones.
Challenge 4: Outdated Training Data
Problem: FLAN-UL2’s training data extends only through 2022, making it unaware of events, terminology, or knowledge from 2023-2026.
Solutions:
- Fine-tune on recent data: Update the model’s knowledge for your specific domain
- Retrieval-augmented generation (RAG): Provide current information in the input context
- Combine with newer models: Use FLAN-UL2 for reasoning over information retrieved by more current systems
- Accept limitations: For tasks not requiring current events knowledge, the training cutoff doesn’t matter
Edge case: If your application requires current events awareness across broad topics, FLAN-UL2 alone won’t suffice. Consider newer models with more recent training data or implement RAG to supplement FLAN-UL2’s reasoning capabilities.
Challenge 5: Evaluating Performance Against Alternatives
Problem: Determining whether FLAN-UL2 is the right choice for your specific use case requires testing against multiple alternatives.
Solution: Use a platform like MULTIBLY to compare FLAN-UL2’s outputs side-by-side with Phi-4, Mistral, Claude, GPT-4o, and other models on your actual data before committing to infrastructure investment. This approach reveals practical performance differences that benchmarks don’t capture.
FAQ
What does FLAN-UL2 stand for? FLAN-UL2 combines “FLAN” (Finetuned Language Net, referring to instruction tuning) with “UL2” (Unified Language Learner 2, the base model using Mixture-of-Denoisers pre-training). The name reflects the two-stage training process: MoD pre-training followed by instruction fine-tuning.
Is FLAN-UL2 better than GPT-3? FLAN-UL2 achieves comparable accuracy to GPT-3 on many tasks despite being 9x smaller (20B vs 175B parameters). It runs approximately 2x faster and uses 20% less memory. However, GPT-3 and its successors have broader general knowledge and better performance on tasks requiring extensive world knowledge.
Can FLAN-UL2 run on consumer hardware? Not effectively. The model requires at least 40GB GPU memory (80GB for full precision), which exceeds consumer GPUs. With aggressive 8-bit quantization, it might run on high-end consumer cards like RTX 4090 (24GB) but with slow inference speeds unsuitable for production use.
How long does it take to fine-tune FLAN-UL2? Using LoRA on a single A100 GPU with 10,000 training examples: approximately 6-12 hours for 3 epochs. Full fine-tuning on 8x A100 GPUs takes 24-48 hours for the same dataset. Time scales roughly linearly with dataset size.
What’s the difference between FLAN-UL2 and Flan-T5? Both use instruction tuning on T5 architecture, but FLAN-UL2 uses Mixture-of-Denoisers pre-training (combining R, S, and X denoisers) while Flan-T5 uses standard T5 pre-training. FLAN-UL2 also has a larger context window (2048 vs 512 tokens) and eliminates mode switch tokens. FLAN-UL2 20B outperforms Flan-T5-XXL by +3.2% overall.
Does FLAN-UL2 support multiple languages? The model was primarily trained on English data from the C4 corpus. While it has some multilingual capability from web-scraped content, it’s not optimized for multilingual tasks. For strong multilingual performance, consider Qwen3 or StableLM 2.
What’s the maximum input length for FLAN-UL2? The model supports a 2048-token context window, significantly larger than the original UL2’s 512 tokens. This translates to approximately 1,500-1,800 words of input text depending on tokenization. Inputs exceeding this limit must be truncated or processed in chunks.
Is FLAN-UL2 suitable for real-time applications? It depends on your latency requirements. FLAN-UL2 typically processes requests in 800-1200ms on A100 GPUs for moderate input/output lengths. This works for many production applications but not for real-time conversational AI requiring sub-200ms responses. Batching can improve throughput at the cost of individual request latency.
How does FLAN-UL2 handle chain-of-thought reasoning? FLAN-UL2 shows strong performance on chain-of-thought tasks, which is where it achieves the largest gains over Flan-T5-XXL. You can prompt it to show reasoning steps by including examples in few-shot format or explicitly requesting step-by-step explanations in your instructions.
Can you use FLAN-UL2 for code generation? While possible, FLAN-UL2 wasn’t specifically optimized for code. For code generation tasks, specialized models like Phi-4 or Codex variants deliver better results. FLAN-UL2 can handle code-related reasoning tasks (explaining code, answering questions about algorithms) more effectively than pure generation.
What license does FLAN-UL2 use? FLAN-UL2 is released under the Apache 2.0 license, allowing commercial use, modification, and distribution. This makes it suitable for both research and production deployment without licensing restrictions.
How often should you update or retrain FLAN-UL2? For production systems, consider retraining or fine-tuning when: (1) your domain data changes significantly, (2) performance degrades on new examples, or (3) newer base models offer substantial improvements. Most teams fine-tune every 6-12 months unless domain shifts occur more frequently.
Conclusion
FLAN-UL2 delivers a compelling combination of performance, efficiency, and accessibility for teams tackling complex NLP tasks in 2026. Its Mixture-of-Denoisers pre-training, combined with instruction tuning and a practical 20-billion-parameter size, creates a model that punches above its weight class—matching models three times larger while running significantly faster.
The encoder-decoder architecture makes FLAN-UL2 particularly effective for question answering, chain-of-thought reasoning, and summarization tasks where understanding input context before generation provides clear advantages. Teams that need these capabilities without the infrastructure demands of 100B+ parameter models will find FLAN-UL2’s balance of power and practicality hard to beat.
Actionable Next Steps
For research teams: Start by testing FLAN-UL2 on your specific tasks using the Hugging Face model hub. Compare its performance against newer open models like DeepSeek R1 or Qwen3 to determine whether the encoder-decoder design provides meaningful benefits for your use cases.
For production teams: Evaluate FLAN-UL2 alongside alternatives using MULTIBLY’s platform to compare real-world performance on your data before committing infrastructure resources. If FLAN-UL2 meets your requirements, begin with LoRA fine-tuning on a representative dataset to assess domain adaptation needs.
For developers: Familiarize yourself with instruction formatting best practices and experiment with few-shot prompting to maximize FLAN-UL2’s reasoning capabilities. The model’s sensitivity to prompt structure means small formatting improvements can yield significant performance gains.
For decision-makers: Consider FLAN-UL2 as part of a model portfolio strategy rather than a single-model solution. Use it for structured reasoning tasks where its encoder-decoder design excels, while deploying faster models like Phi-4 for simpler operations and premium models like Claude Opus 4.5 for the most complex challenges.
The key to success with FLAN-UL2 lies in understanding its specific strengths and deploying it where those strengths matter. It’s not the newest model, not the largest, and not the fastest—but for teams that need proven encoder-decoder reasoning at a manageable scale, it remains a strong choice in 2026’s diverse AI landscape.
References
[1] Flan Ul2 – https://huggingface.co/google/flan-ul2
[2] Meet Flan Ul2 A Unified Framework For Pre Training Models That Are Universally Effective Across Datasets And Setups Now Open Source – https://www.marktechpost.com/2023/03/07/meet-flan-ul2-a-unified-framework-for-pre-training-models-that-are-universally-effective-across-datasets-and-setups-now-open-source/
[3] Flan Ul2 – https://accubits.com/instructeval-leaderboard/flan-ul2/
[4] Boost Your Pre Training Models With Flan Ul2 – https://www.labellerr.com/blog/boost-your-pre-training-models-with-flan-ul2/
[5] Watch – https://www.youtube.com/watch?v=WlmqAJe9hss



