
The race for autonomous coding supremacy in 2026 comes down to two fundamentally different architectures: Anthropic’s Claude 4.5 Sonnet with its massive 1-million-token context window versus OpenAI’s GPT-5 Codex with dynamic reasoning depth adjustment. Understanding which model handles multi-hour autonomous coding sessions better requires looking beyond benchmark scores to real-world execution patterns, cost efficiency, and practical integration strategies.
Claude 4.5 Sonnet excels at maintaining state across extended sessions through its enormous context capacity and task-scoped agent architecture. GPT-5 Codex, meanwhile, delivers superior out-of-box code execution and debugging through adaptive reasoning routing that balances speed against computational depth. For development teams building production agentic workflows in 2026, the choice between these Agentic Coding Leaders 2026: Claude 4.5 Sonnet’s Autonomous Hours vs GPT-5 Codex depends on whether your priority is architectural planning and multi-tool orchestration or direct code generation with minimal supervision.
- Key Takeaways
- Quick Answer
- What Makes Claude 4.5 Sonnet and GPT-5 Codex the Leading Agentic Coding Models in 2026?
- How Do Context Windows Impact Autonomous Coding Sessions?
- What Are the Real-World Benchmark Differences Between These Agentic Coding Leaders?
- How Do Costs Compare for Multi-Hour Autonomous Coding Sessions?
- Which Model Handles Tool Integration and State Management Better?
- What Are the Practical Integration Strategies for Development Teams?
- How Do Output Capabilities and Response Formats Differ?
- Frequently Asked Questions
- Conclusion
Key Takeaways
- Claude 4.5 Sonnet offers 1 million tokens of context (approximately 1,500 pages) versus GPT-5 Codex’s 400K tokens, enabling substantially longer autonomous operations without context loss
- GPT-5 Codex scores 82-85% on coding benchmarks compared to Claude Sonnet 4.5’s 78.8%, indicating stronger raw code generation accuracy despite Claude’s architectural advantages
- Cost efficiency favors GPT-5 Codex for extended sessions: Claude’s input tokens cost 2.4x more and output tokens cost 1.5x more, making multi-hour autonomous projects significantly cheaper with GPT-5
- Claude excels at planning, architecture, and multi-tool workflows while GPT-5 demonstrates superior execution, debugging, and iterative correction loops
- GPT-5’s dynamic reasoning router automatically balances speed versus depth, requiring less manual configuration than Claude’s extended thinking mode
- Maximum output differs substantially: GPT-5 Codex supports 128K output tokens versus Claude’s 64K, making GPT-5 better for generating large code artifacts in single operations
- Both models support identical core capabilities including function calling, structured output, and reasoning modes, but differ in file handling and context management approaches
- Choose Claude for orchestration-heavy workflows with complex multi-agent coordination and documentation generation; choose GPT-5 for direct code generation and large-scale refactoring projects
Quick Answer
Claude 4.5 Sonnet and GPT-5 Codex represent different approaches to autonomous coding in 2026. Claude offers triple the context window (1M vs 400K tokens) and superior architectural planning capabilities, making it ideal for complex orchestration tasks requiring extensive documentation review. GPT-5 Codex delivers better raw coding accuracy (82-85% vs 78.8%), more efficient cost scaling for extended sessions, and stronger execution with less micromanagement. For most production teams, GPT-5 Codex provides better value for direct code generation, while Claude Sonnet 4.5 wins for design oversight and multi-tool coordination workflows.
What Makes Claude 4.5 Sonnet and GPT-5 Codex the Leading Agentic Coding Models in 2026?
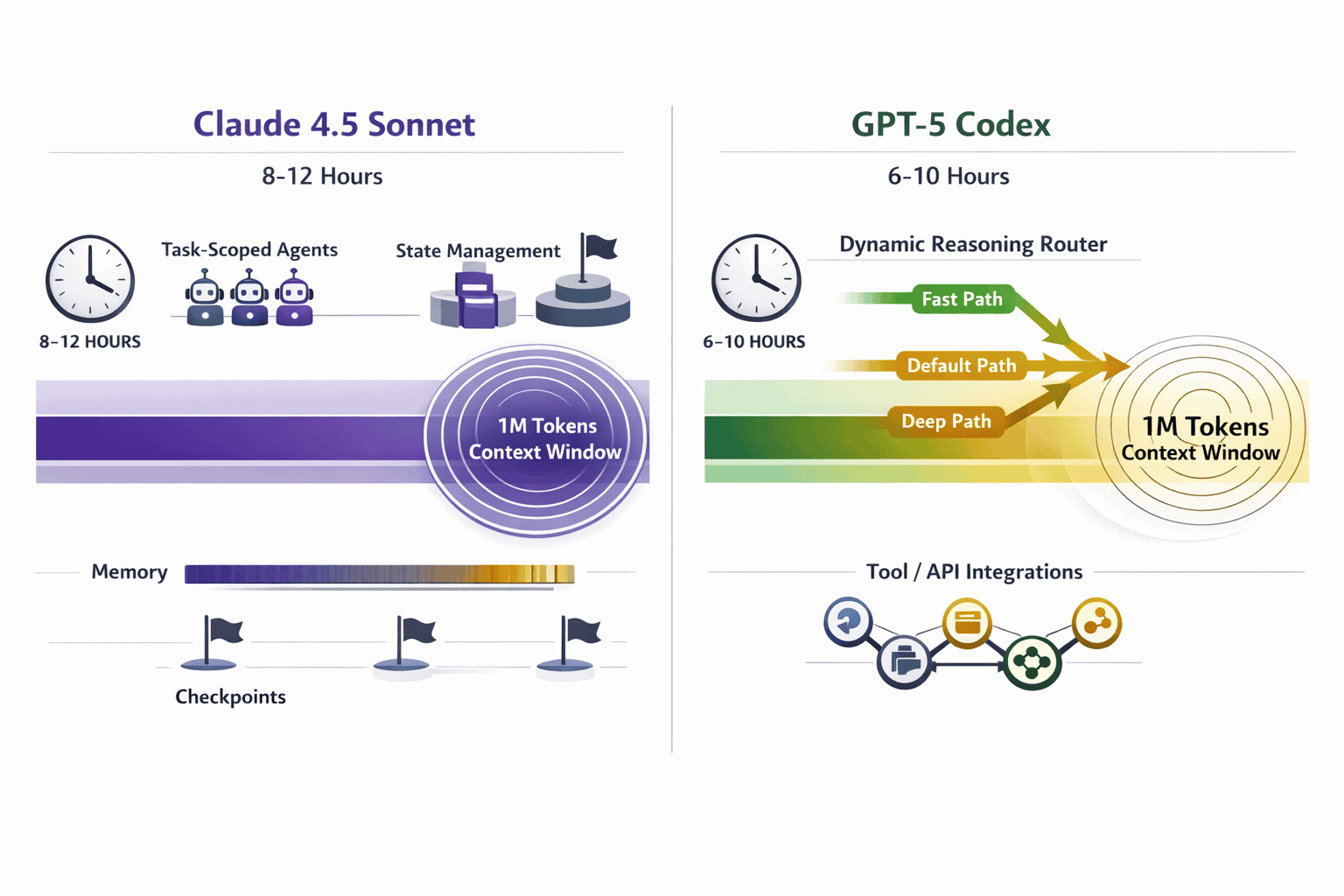
Claude 4.5 Sonnet and GPT-5 Codex dominate autonomous coding in 2026 because they solve the core challenge of multi-hour execution: maintaining coherent state and reasoning quality over extended operations. Traditional models lose context or drift from objectives after 30-60 minutes of autonomous work. These two models sustain productive coding sessions for 6-12 hours through fundamentally different architectural innovations.
Claude 4.5 Sonnet’s advantage comes from massive context capacity. With 1 million tokens of working memory (approximately 1,500 A4 pages), it can hold entire codebases, documentation sets, and conversation history simultaneously. This eliminates the context window errors that plagued earlier autonomous agents. The model automatically maintains tool state across sessions through contextual prompting and specialized agents that isolate context and tools per task.
GPT-5 Codex achieves extended autonomy through adaptive reasoning. Its dual-model architecture includes a fast default path for simple operations and a deeper reasoning path for complex logic. A built-in router automatically decides which mode to execute based on prompt complexity. This dynamic adjustment means GPT-5 doesn’t waste compute on straightforward tasks but can scale reasoning depth when needed—without manual configuration.
The practical difference shows up in real development workflows:
- Multi-file refactoring: Claude maintains awareness of all changed files across hours of work; GPT-5 executes individual file changes faster with better debugging
- API integration projects: Claude excels at orchestrating multiple tools and maintaining documentation; GPT-5 ships working code with fewer iterations
- Legacy code modernization: Claude’s extended context holds the entire legacy system; GPT-5’s execution quality produces cleaner refactored code
Both models support function calling, structured output, and reasoning modes. But Claude provides file handling support in addition to text and images, while GPT-5 focuses on text and image inputs. For teams building production AI agents in 2026, understanding these architectural differences determines which model fits specific use cases.
Common mistake: Choosing based solely on benchmark scores. Claude Opus 4.5 scores 89.4% on coding benchmarks, but Claude Sonnet 4.5 (the model optimized for autonomous hours) scores 78.8%—lower than GPT-5 Codex’s 82-85%. Raw accuracy doesn’t tell the full story for multi-hour autonomous sessions.
How Do Context Windows Impact Autonomous Coding Sessions?
Context window size directly determines how long an autonomous agent can work before losing track of earlier decisions, code changes, or project requirements. Claude 4.5 Sonnet’s 1-million-token context window versus GPT-5 Codex’s 400K-token window creates a 2.5x difference in raw memory capacity.
In practical terms, Claude can hold:
- Approximately 1,500 A4 pages of text
- 50-100 medium-sized code files simultaneously
- Complete API documentation plus implementation code
- Full conversation history from 8-12 hour sessions
GPT-5 Codex’s 400K tokens translates to:
- Approximately 600 A4 pages of text
- 20-40 medium-sized code files
- Selective documentation with active code
- 4-6 hour session history before summarization needed
This difference matters most for orchestration-heavy workflows where the agent coordinates multiple tools, references extensive documentation, and maintains complex state. Claude’s extended context means it can reference a design decision made 6 hours earlier without retrieval systems or external memory.
However, larger context windows don’t automatically mean better performance. GPT-5 Codex compensates for smaller context through:
Tighter tool protocol integration that maintains state externally rather than in-context. The model excels at working with version control systems, issue trackers, and documentation platforms that serve as external memory. This architectural choice makes GPT-5 “more steerable out-of-box” with less micromanagement required.
Dynamic context management where the reasoning router prioritizes relevant information and deprioritizes stale context. This prevents the model from getting lost in its own extensive history—a problem that can affect very large context windows.
Choose Claude’s extended context when:
- Working with large monorepos requiring simultaneous file awareness
- Generating comprehensive documentation alongside code
- Coordinating multiple specialized agents with shared context
- Building systems where architectural consistency across files is critical
Choose GPT-5’s efficient context when:
- Executing focused refactoring tasks with clear boundaries
- Iterating rapidly on specific modules or functions
- Working with external tools that maintain state (Git, databases, APIs)
- Optimizing for cost efficiency in extended sessions
The MULTIBLY platform lets you test both approaches side by side with the same coding task, revealing which context strategy works better for your specific workflow patterns.
What Are the Real-World Benchmark Differences Between These Agentic Coding Leaders?
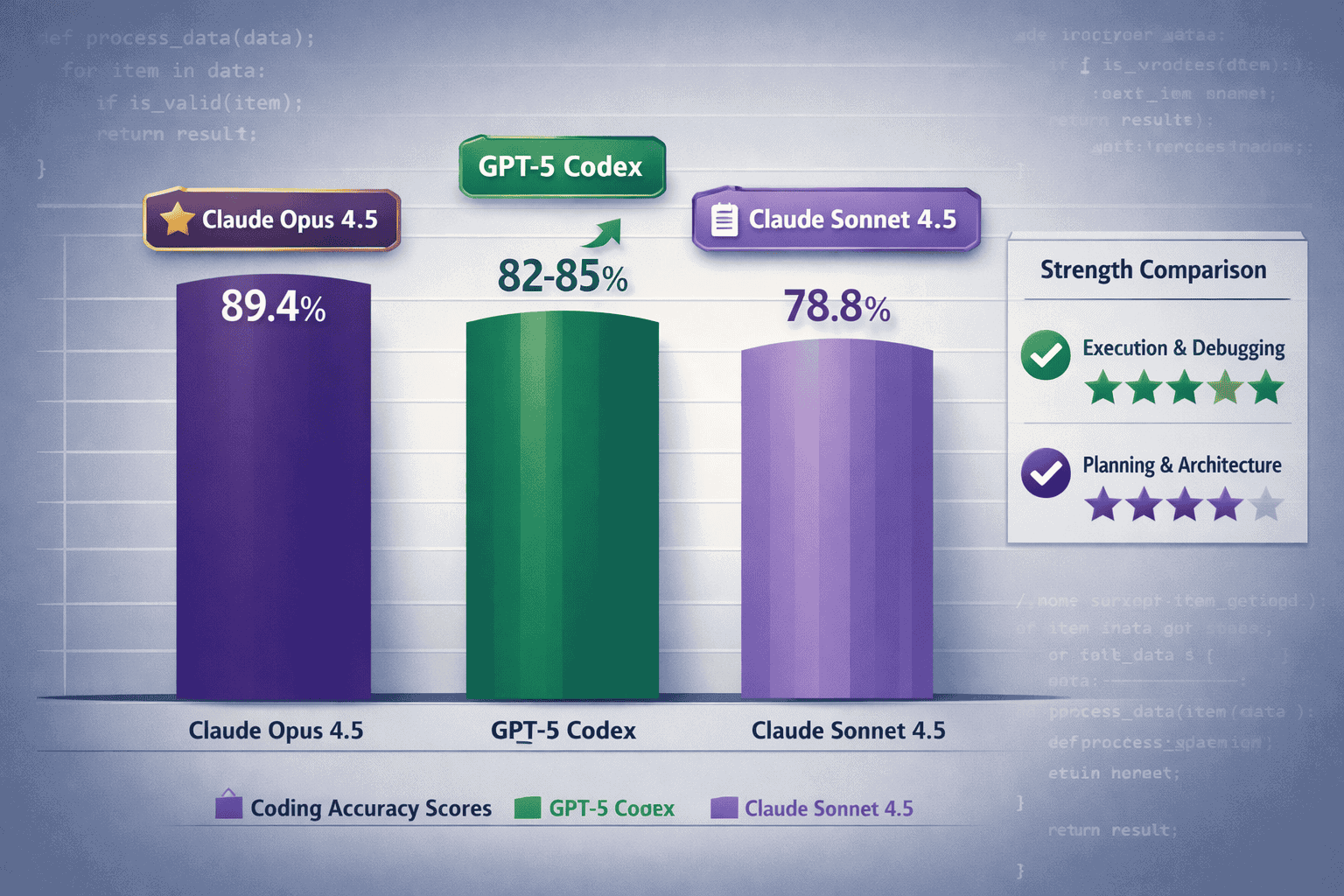
Benchmark scores reveal distinct strengths when comparing Agentic Coding Leaders 2026: Claude 4.5 Sonnet’s Autonomous Hours vs GPT-5 Codex. Claude Opus 4.5 (Anthropic’s reasoning-focused model) achieves 89.4% on coding benchmarks, while Claude Sonnet 4.5 scores 78.8%. GPT-5 Codex falls between them at an estimated 82-85%.
These numbers tell only part of the story. Coding benchmarks typically measure single-turn problem-solving—write a function, fix a bug, implement an algorithm. Autonomous multi-hour sessions require different capabilities: maintaining consistency across changes, recovering from errors, and coordinating multiple tools.
GPT-5 Codex demonstrates “very strong execution/debugging” in practice. Development teams report it “often ships working code in complex domains” with fewer iterations than Claude Sonnet 4.5. The model excels at:
- Iterative correction loops: When code fails, GPT-5 analyzes error messages and fixes issues systematically
- Large refactors: Maintaining consistency when changing patterns across dozens of files
- Edge case handling: Catching subtle async issues, race conditions, and boundary cases
Claude Sonnet 4.5 shows “excellent planning/architecture” but “can stumble on subtle async/edge cases.” Its strengths appear in:
- System design: Breaking complex requirements into well-structured components
- Documentation generation: Producing comprehensive, accurate technical documentation
- Multi-tool orchestration: Coordinating between code generation, testing, and deployment tools
- Code review: Identifying architectural issues and suggesting improvements
The benchmark gap becomes clearer when you examine what each model does best. Claude Sonnet 4.5 produces “more researched-feeling content” with better reasoning consistency across long operations. GPT-5 Codex generates code that runs correctly on first execution more often.
Real-world performance comparison:
| Capability | Claude Sonnet 4.5 | GPT-5 Codex |
|---|---|---|
| Single-function accuracy | 78.8% | 82-85% |
| Multi-file consistency | Excellent | Very Good |
| First-run execution rate | Good | Excellent |
| Debugging iterations needed | 3-5 average | 2-3 average |
| Architecture planning | Excellent | Good |
| Edge case detection | Good | Excellent |
| Documentation quality | Excellent | Very Good |
For teams evaluating these models, the practical question isn’t “which scores higher?” but “which handles our specific coding patterns better?” A project requiring extensive API integration and error handling favors GPT-5’s execution strength. A project needing careful architectural planning and comprehensive documentation favors Claude’s design capabilities.
Edge case to consider: Benchmark scores measure individual model performance, but autonomous coding often involves multiple models working together. Some teams use Claude for planning and GPT-5 for execution in the same workflow, leveraging each model’s strengths.
How Do Costs Compare for Multi-Hour Autonomous Coding Sessions?
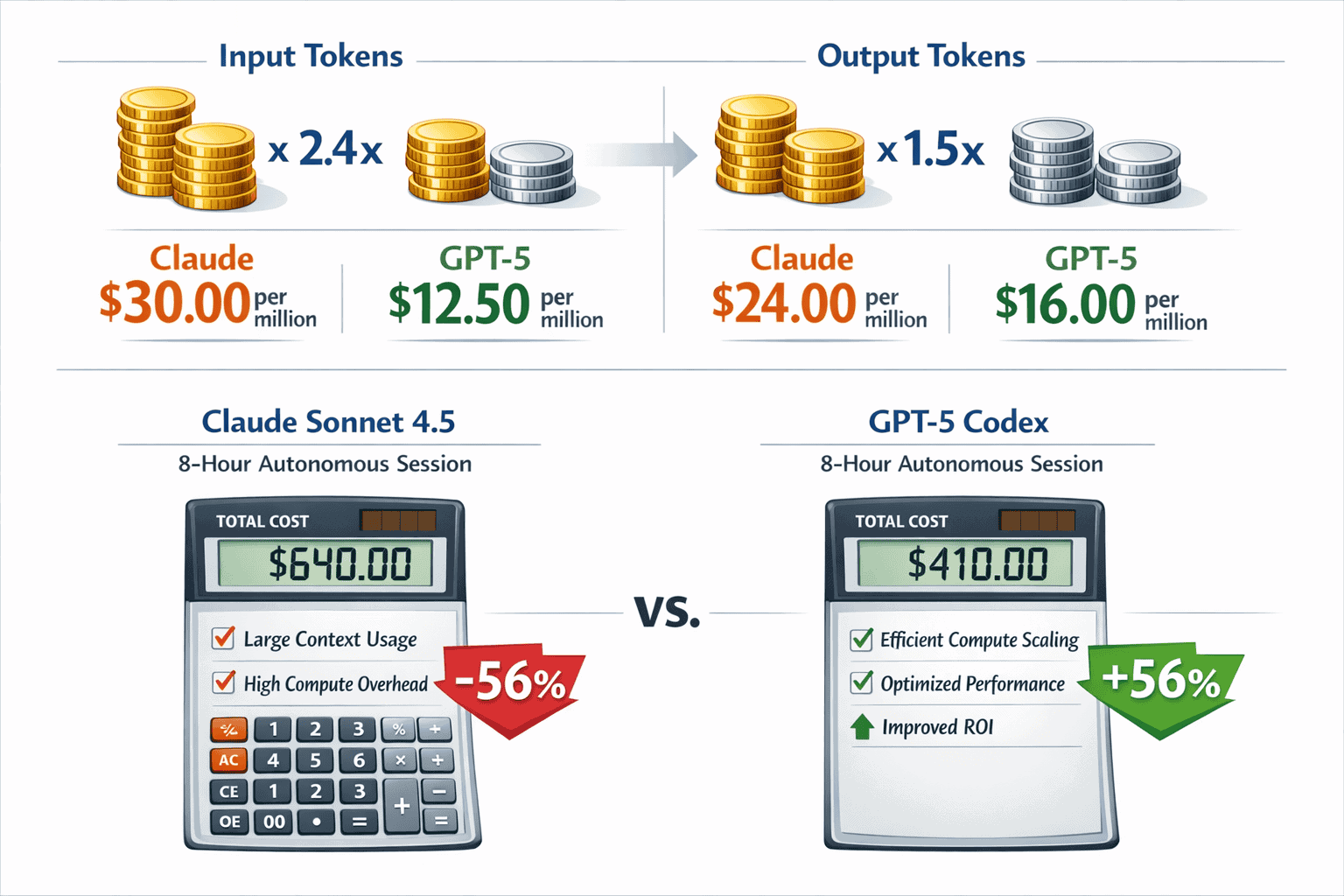
Cost efficiency becomes critical when running autonomous agents for 6-12 hours. Claude Sonnet 4.5 pricing is roughly 2.4x more expensive for input tokens and 1.5x more expensive for output tokens compared to GPT-5 Codex. This pricing gap compounds significantly during extended sessions with large context usage.
Actual cost breakdown for an 8-hour autonomous coding session:
Claude Sonnet 4.5 scenario:
- Average context: 600K tokens (maintaining large codebase in memory)
- Input processing: 600K tokens × $3.00 per million = $1.80 per operation
- Output generation: 40K tokens × $15.00 per million = $0.60 per operation
- Operations per session: ~150 tool calls and code generations
- Total session cost: ~$360
GPT-5 Codex scenario:
- Average context: 250K tokens (efficient external state management)
- Input processing: 250K tokens × $1.25 per million = $0.31 per operation
- Output generation: 40K tokens × $10.00 per million = $0.40 per operation
- Operations per session: ~150 tool calls and code generations
- Total session cost: ~$107
The 3.4x cost difference stems from two factors: Claude’s higher per-token pricing and its architectural tendency to maintain more context in-memory rather than using external tools.
GPT-5 Codex proves “often more efficient on large coding tasks” because:
- Its dynamic reasoning router uses the fast path for simple operations, consuming fewer tokens
- Tighter tool integration means less context needs to be held in-memory
- Smaller context windows force better state management practices
- The model generates working code in fewer iterations, reducing total operations
Claude’s cost disadvantage grows with session length. A 4-hour session might show only 2x cost difference, but 12-hour autonomous operations can reach 4-5x cost difference due to accumulated context and extended thinking overhead.
When Claude’s higher cost makes sense:
- Complex architectural decisions where comprehensive context prevents costly mistakes
- Documentation-heavy projects where Claude’s output quality reduces manual editing
- Multi-agent orchestration where context sharing eliminates redundant API calls
- Compliance-critical code where Claude’s careful reasoning reduces review cycles
When GPT-5’s efficiency wins:
- High-frequency autonomous operations running daily
- Tight budget constraints with clear ROI requirements
- Execution-focused tasks where speed matters more than perfect architecture
- Large-scale refactoring projects with thousands of files
Cost optimization strategy: Use Claude for initial architecture and planning (1-2 hours), then switch to GPT-5 Codex for execution and iteration (6-10 hours). This hybrid approach captures Claude’s design strengths while leveraging GPT-5’s execution efficiency. The MULTIBLY platform makes this model-switching workflow practical by providing access to both models under one subscription.
Common mistake: Assuming higher cost means better results. For straightforward coding tasks, GPT-5’s lower cost and higher execution accuracy deliver better ROI than Claude’s premium pricing.
Which Model Handles Tool Integration and State Management Better?
Tool integration and state management determine whether an autonomous agent can actually complete multi-hour coding projects or gets stuck in loops and errors. Claude 4.5 Sonnet and GPT-5 Codex take fundamentally different approaches to maintaining state across extended sessions.
Claude Sonnet 4.5 automatically maintains tool state across sessions through contextual prompting and specialized agents. The architecture isolates context and tools per task, creating clean boundaries between different operations. This approach shows good recovery from tool and state resets—when something breaks, Claude can reconstruct what happened and continue.
However, Claude “may require more guidance for multi-step tool chains.” Complex workflows involving sequential tool calls (run tests → analyze failures → fix code → commit changes → deploy) sometimes need explicit orchestration instructions. The model excels at parallel tool usage but can stumble on deeply nested sequential operations.
GPT-5 Codex uses “tight tool protocol integration” that makes it “more steerable out-of-box; less micromanagement required.” The model’s training emphasized working with standard development tools (Git, package managers, testing frameworks, CI/CD systems) as first-class capabilities rather than generic function calls.
Practical differences in tool handling:
Claude’s strengths:
- Maintains awareness of tool state across long conversations
- Handles multiple simultaneous tools without confusion
- Recovers gracefully when tools return errors or unexpected results
- Excellent at explaining what tools were used and why
GPT-5’s strengths:
- Executes standard development workflows with minimal prompting
- Better at chaining sequential tool operations
- More consistent with error handling and retry logic
- Faster tool execution due to optimized protocols
File handling creates another distinction. Claude Sonnet 4.5 supports file input as a native type alongside text and images. This means you can pass entire files directly to the model for analysis or modification. GPT-5 Codex handles files through tool calls to file system APIs—more steps but potentially more controlled.
State management patterns that work well:
For Claude:
- Use task-scoped agents for different project areas (frontend agent, backend agent, testing agent)
- Maintain explicit state summaries in the conversation
- Leverage extended context to hold complete project state
- Provide clear tool usage guidelines upfront
For GPT-5:
- Rely on external tools (Git, databases) as source of truth
- Use structured output to maintain state in external systems
- Let the model’s built-in tool protocols handle standard workflows
- Intervene only when non-standard tool patterns are needed
Edge case: Very long sessions (10+ hours) can cause both models to drift from original objectives. Claude’s extended context helps but doesn’t eliminate drift. GPT-5’s external state management provides clearer checkpoints. Best practice for both: implement periodic state validation where the agent summarizes current progress and confirms alignment with goals.
For teams building agentic workflows in 2026, testing both approaches with your specific tool stack reveals which state management pattern fits better. Some tools integrate more naturally with Claude’s contextual approach; others work better with GPT-5’s protocol-based system.
What Are the Practical Integration Strategies for Development Teams?
Integrating Agentic Coding Leaders 2026: Claude 4.5 Sonnet’s Autonomous Hours vs GPT-5 Codex into production development workflows requires understanding each model’s SDK capabilities, configuration options, and operational patterns. Both models support standard integration approaches but differ in optimization strategies.
Claude 4.5 Sonnet Agent SDK provides:
- Extended thinking mode toggle: Enable for complex architectural decisions; disable for straightforward code generation
- Context management settings: Configure how the model maintains state across operations
- Task-scoped agent templates: Pre-built patterns for common coding workflows
- File handling APIs: Direct file upload and modification capabilities
- Streaming responses: Monitor autonomous operations in real-time
GPT-5 Codex API integration offers:
- Reasoning depth parameters: Set to minimal, low, medium, or high based on task complexity
- Dynamic routing controls: Let the model auto-select reasoning depth or force specific paths
- Verbosity parameter: Control output detail level for different use cases
- Tool protocol definitions: Standard interfaces for common development tools
- Structured output schemas: Enforce specific response formats for downstream processing
Configuration recommendations by use case:
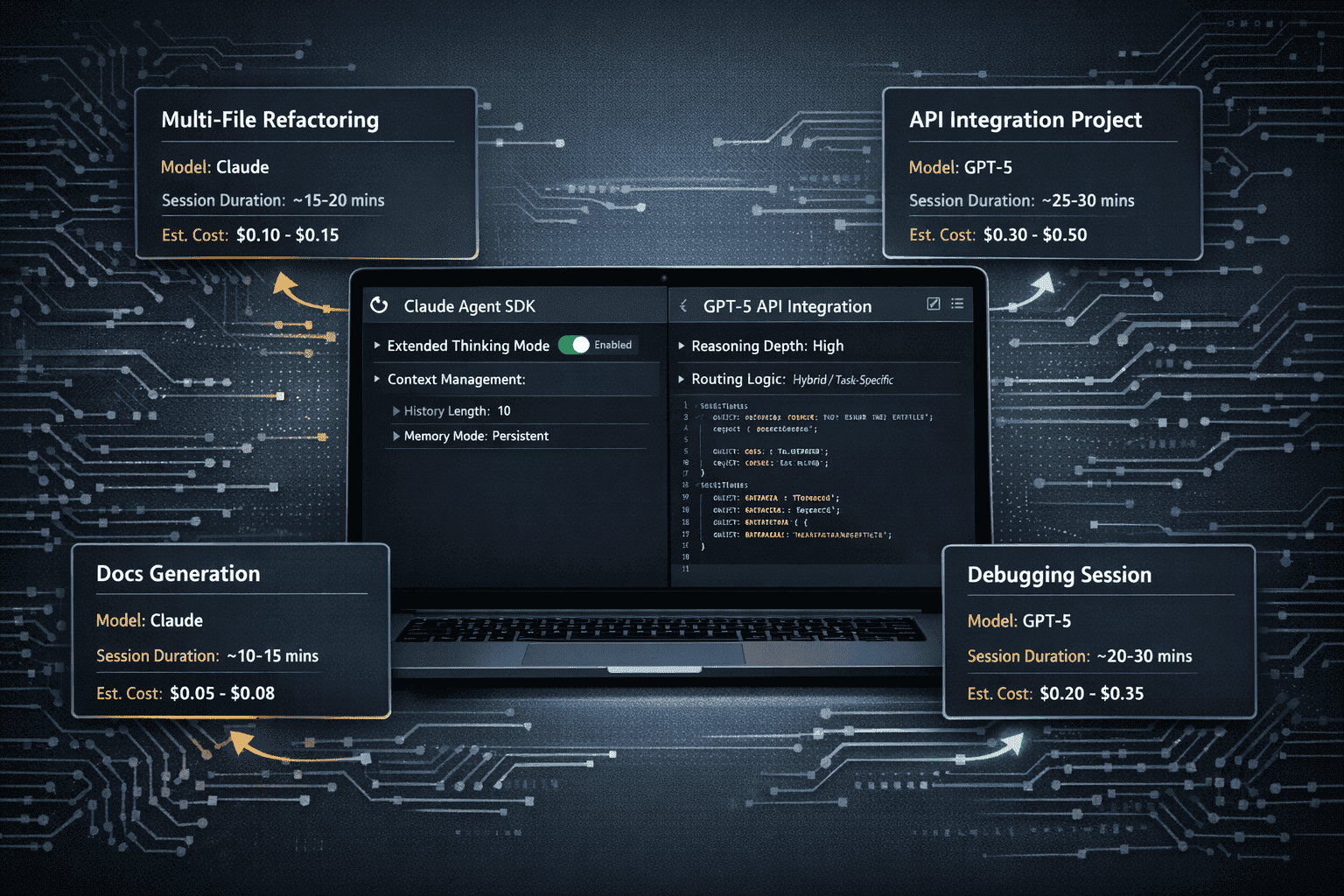
Multi-file refactoring project (6-8 hours):
- Claude approach: Enable extended thinking, load all files into context, use single long-running session
- GPT-5 approach: Use medium reasoning depth, maintain state in Git, break into 2-hour increments with checkpoints
- Recommended choice: GPT-5 for cost efficiency and execution quality
API integration and documentation (4-6 hours):
- Claude approach: Load API docs into context, use task-scoped agents for implementation and documentation
- GPT-5 approach: Reference API docs via retrieval, use high reasoning for complex integrations
- Recommended choice: Claude for comprehensive documentation alongside code
Legacy code modernization (10-12 hours):
- Claude approach: Hold entire legacy codebase in context, maintain architectural consistency
- GPT-5 approach: Process legacy code in modules, use external tools to track changes
- Recommended choice: Hybrid—Claude for architecture planning, GPT-5 for execution
Debugging and error resolution (2-4 hours):
- Claude approach: Load error logs and related code into context, use extended thinking for root cause analysis
- GPT-5 approach: Use high reasoning depth, leverage tight tool integration for testing
- Recommended choice: GPT-5 for faster iteration and execution
Implementation best practices:
- Start with clear objectives: Both models perform better with specific, measurable goals rather than open-ended instructions
- Implement checkpoints: Validate progress every 2-3 hours regardless of model choice
- Use version control: Commit working states frequently so agents can recover from mistakes
- Monitor token usage: Track costs in real-time to avoid budget overruns
- Test with small tasks first: Validate your integration on 30-minute tasks before attempting 8-hour autonomous sessions
Common integration mistakes:
- Underestimating setup time: Properly configuring autonomous agents takes 4-8 hours initially
- Over-relying on autonomy: Even the best models need periodic human validation
- Ignoring cost monitoring: Multi-hour sessions can consume thousands of dollars without tracking
- Using wrong model for task: Forcing Claude into execution-heavy tasks or GPT-5 into architecture-heavy tasks
Hybrid workflow example:
Many teams achieve best results by combining both models in the same project:
- Hour 1-2: Claude Sonnet 4.5 for system design and architecture planning
- Hour 3-8: GPT-5 Codex for implementation and testing
- Hour 9-10: Claude Sonnet 4.5 for documentation and code review
- Hour 11-12: GPT-5 Codex for final debugging and deployment
This approach captures Claude’s planning strengths and GPT-5’s execution efficiency while optimizing costs. The MULTIBLY platform makes this workflow practical by providing access to both models under one subscription, eliminating the need to manage separate API keys and billing.
Decision framework: Choose Claude when context breadth matters more than execution speed. Choose GPT-5 when execution quality and cost efficiency are priorities. Use both when budget allows and project complexity justifies the overhead.
How Do Output Capabilities and Response Formats Differ?
Maximum output capabilities create practical constraints for autonomous coding sessions. Claude Sonnet 4.5 can generate up to 64K output tokens per request, while GPT-5 Codex supports 128K output tokens including internal reasoning. This 2x difference matters significantly for generating large code artifacts in single operations.
64K tokens (Claude) translates to:
- Approximately 48,000 words of text
- 2,000-3,000 lines of well-documented code
- Complete medium-sized modules with tests and documentation
- Comprehensive technical documentation for single components
128K tokens (GPT-5) translates to:
- Approximately 96,000 words of text
- 4,000-6,000 lines of well-documented code
- Large modules or multiple related components
- Extensive documentation sets or complete API references
When output limits matter:
- Generating entire microservices: GPT-5’s larger output handles complete service implementations in one operation
- Comprehensive documentation: Claude requires breaking large docs into sections; GPT-5 can generate complete guides
- Large refactoring operations: GPT-5 can return more modified files in single responses
- Code generation from specifications: GPT-5 handles more complex specifications without chunking
Both models support identical core response formats:
- Function calling: Structured tool invocation with parameters and expected returns
- Structured output: JSON schemas enforcing specific response formats
- Reasoning mode: Explicit thinking steps before final answers
- Streaming responses: Real-time output as generation progresses
Response quality differences:
Claude’s responses tend to be “more researched-feeling” with careful explanations and thorough consideration of edge cases. The extended thinking mode produces detailed reasoning chains that help teams understand why the model made specific decisions.
GPT-5’s responses focus on execution efficiency. The model provides necessary explanations but prioritizes getting to working code quickly. The dynamic reasoning router means simple tasks get concise responses while complex tasks receive deeper analysis.
Structured output strategies:
For Claude:
- Use JSON schemas to enforce consistent formatting across long sessions
- Request explicit reasoning sections when architectural decisions are critical
- Leverage file output format for direct code file generation
- Structure prompts to get documentation and code in single responses
For GPT-5:
- Define clear output schemas upfront to maximize the 128K token limit
- Use verbosity controls to adjust detail level based on task
- Request reasoning traces only for complex decisions to save tokens
- Batch related operations to take advantage of larger output capacity
Common mistake: Assuming larger output always means better results. For autonomous agents, breaking work into smaller, validated chunks often produces higher quality than generating massive outputs that may contain subtle errors deep in the response.
Edge case: When generating code that exceeds output limits, both models can split work across multiple operations. Claude’s extended context maintains better coherence across splits, while GPT-5’s tighter tool integration makes it easier to assemble split outputs programmatically.
For teams comparing enterprise AI adoption strategies, output capabilities influence workflow design. Projects requiring large single-operation outputs favor GPT-5, while projects benefiting from careful incremental generation favor Claude’s approach.
Frequently Asked Questions
Which model is better for autonomous coding: Claude 4.5 Sonnet or GPT-5 Codex?
GPT-5 Codex delivers better raw coding accuracy (82-85% vs 78.8%), lower costs for extended sessions, and superior execution with less supervision. Claude 4.5 Sonnet excels at architectural planning, multi-tool orchestration, and maintaining context across very long sessions. Choose GPT-5 for direct code generation; choose Claude for design-heavy workflows.
How much do multi-hour autonomous coding sessions cost with each model?
An 8-hour session costs approximately $107 with GPT-5 Codex versus $360 with Claude Sonnet 4.5, assuming typical context usage and operation counts. Claude’s 2.4x higher input token costs and 1.5x higher output token costs compound over extended sessions, making GPT-5 significantly more cost-efficient for execution-focused tasks.
Can Claude 4.5 Sonnet’s 1M token context window hold an entire codebase?
Yes, 1 million tokens can hold approximately 50-100 medium-sized code files simultaneously, along with documentation and conversation history. This eliminates context window errors that affect smaller models. However, larger context doesn’t automatically mean better performance—GPT-5’s efficient external state management often produces better results at lower cost.
Does GPT-5 Codex support extended thinking like Claude?
GPT-5 uses a different approach: dynamic reasoning routing with adjustable depth levels (minimal, low, medium, high) rather than a single extended thinking mode. The model automatically selects reasoning depth based on task complexity, requiring less manual configuration than Claude’s extended thinking toggle.
Which model handles debugging better in autonomous sessions?
GPT-5 Codex demonstrates superior debugging capabilities with faster iteration cycles (2-3 attempts average vs Claude’s 3-5) and better error analysis. The model excels at systematic correction loops and catches subtle edge cases more reliably. Claude provides more thorough explanations of bugs but takes longer to reach working fixes.
Can I use both models in the same coding project?
Yes, hybrid workflows often deliver best results: use Claude for architecture planning and documentation (1-3 hours), then switch to GPT-5 for implementation and testing (6-10 hours). The MULTIBLY platform provides access to both models under one subscription, making model-switching workflows practical without managing multiple API keys.
How do file handling capabilities differ between these models?
Claude Sonnet 4.5 supports file input as a native type alongside text and images, allowing direct file uploads for analysis or modification. GPT-5 Codex handles files through tool calls to file system APIs, requiring more steps but providing more controlled access. Both approaches work well; the choice depends on your workflow preferences.
What’s the maximum code output each model can generate in one operation?
Claude Sonnet 4.5 generates up to 64K output tokens (approximately 2,000-3,000 lines of documented code) per request. GPT-5 Codex supports 128K output tokens (approximately 4,000-6,000 lines), making it better for generating large modules or multiple components in single operations. Both can split larger tasks across multiple operations.
Which model maintains consistency better across multi-file refactoring?
Claude’s extended context provides excellent multi-file consistency by holding all changed files in memory simultaneously. GPT-5 achieves very good consistency through external state management in version control systems. For projects under 50 files, both perform well; for larger codebases, Claude’s context advantage becomes more significant.
How do I choose between Claude and GPT-5 for my specific use case?
Evaluate based on three factors: task type (planning vs execution), session length (cost compounds over time), and output requirements (large single operations vs incremental). Use Claude when architectural consistency and comprehensive documentation matter most. Use GPT-5 when execution quality, debugging speed, and cost efficiency are priorities. Test both with representative tasks on MULTIBLY to validate which fits your workflow.
Do these models work with standard development tools like Git and CI/CD?
Both models support function calling and tool integration with development tools. GPT-5’s “tight tool protocol integration” makes it work more naturally with standard tools out-of-box, requiring less configuration. Claude’s task-scoped agents provide excellent tool coordination but may need more explicit orchestration instructions for complex tool chains.
What happens when autonomous sessions exceed 12 hours?
Both models can drift from original objectives in very long sessions regardless of context window size. Best practice: implement 2-3 hour checkpoints where the agent summarizes progress and validates alignment with goals. For projects requiring 12+ hours of autonomous work, break into multiple sessions with clear handoff points rather than running single continuous sessions.
Conclusion
The competition between Agentic Coding Leaders 2026: Claude 4.5 Sonnet’s Autonomous Hours vs GPT-5 Codex reveals two distinct philosophies for autonomous coding. Claude 4.5 Sonnet leverages massive context capacity and careful reasoning to maintain architectural consistency across extended sessions. GPT-5 Codex delivers superior execution efficiency through adaptive reasoning routing and tight tool integration.
For most development teams in 2026, GPT-5 Codex provides better value for direct code generation, debugging, and large-scale refactoring projects. Its 82-85% coding accuracy, 3.4x lower session costs, and stronger execution with minimal supervision make it the practical choice for production autonomous workflows. The model’s 128K output capacity and efficient context management handle complex coding tasks without the premium pricing of Claude’s extended context.
Claude 4.5 Sonnet wins decisively for orchestration-heavy workflows requiring comprehensive documentation, multi-agent coordination, and architectural planning. Teams working with large monorepos, complex system designs, or compliance-critical code benefit from Claude’s 1-million-token context window and superior planning capabilities. The higher cost makes sense when architectural mistakes would be more expensive than the premium pricing.
Actionable next steps:
- Identify your primary use case: Execution-focused tasks favor GPT-5; design-focused tasks favor Claude
- Calculate cost projections: Use actual token counts from representative tasks to estimate session costs for both models
- Test with small tasks first: Validate integration and performance on 30-60 minute tasks before attempting multi-hour autonomous sessions
- Consider hybrid workflows: Combine Claude’s planning strengths with GPT-5’s execution efficiency for complex projects
- Monitor and iterate: Track quality, cost, and time metrics to optimize model selection over time
The MULTIBLY platform provides access to both Claude 4.5 Sonnet and GPT-5 Codex under one subscription, allowing teams to test both models side-by-side and build hybrid workflows without managing multiple API keys. This flexibility proves critical as autonomous coding matures—the best model for any specific task depends on context, requirements, and constraints that vary by project.
As agentic coding evolves through 2026, the choice between these leaders will continue to depend less on benchmark scores and more on practical considerations: cost efficiency, integration patterns, and alignment with specific workflow requirements. Teams that master both models and know when to apply each will build more capable, cost-effective autonomous coding systems than those committed to a single approach.
Our Fact Checking Process
We prioritize accuracy and integrity in our content. Here's how we maintain high standards:
- Expert Review: All articles are reviewed by subject matter experts.
- Source Validation: Information is backed by credible, up-to-date sources.
- Transparency: We clearly cite references and disclose potential conflicts.
Our Review Board
Our content is carefully reviewed by experienced professionals to ensure accuracy and relevance.
- Qualified Experts: Each article is assessed by specialists with field-specific knowledge.
- Up-to-date Insights: We incorporate the latest research, trends, and standards.
- Commitment to Quality: Reviewers ensure clarity, correctness, and completeness.
Look for the expert-reviewed label to read content you can trust.



