
The Allen Institute for AI (Ai2) has released its most ambitious open-source models yet, directly challenging proprietary systems from OpenAI and DeepSeek. Allen AI’s latest breakthroughs: how O1 and Tulu models are shaping open research AI in 2026 represents a fundamental shift in who controls cutting-edge artificial intelligence. The Tulu 3 405B model, with 405 billion parameters, now stands as the largest fully open-source post-trained model available, while the Olmo 3-Think series brings transparent reasoning capabilities to developers worldwide[2][5].
These releases matter because they prove that world-class AI performance doesn’t require closed systems. Ai2’s approach combines rigorous academic research with practical engineering, delivering models that match or exceed GPT-4o and DeepSeek V3 on key benchmarks while maintaining complete transparency in training data, code, and methodology[2][6].
- Key Takeaways
- Quick Answer
- What Makes Tulu 3 405B Different from Previous Open-Source Models?
- How Does Reinforcement Learning with Verifiable Rewards (RLVR) Work?
- What Is the Olmo 3 Model Family and Why Does It Matter?
- How Do Allen AI's Latest Breakthroughs Compare to Proprietary Systems?
- What Role Does Open Research Play in AI Development in 2026?
- How Can Developers Access and Deploy Allen AI Models?
- What Are the Practical Applications of Allen AI's Latest Models?
- How Do Allen AI's Models Fit into the Broader Open-Source AI Ecosystem?
- What Are the Limitations and Challenges of Allen AI's Current Models?
- Frequently Asked Questions
- Conclusion
Key Takeaways
- Tulu 3 405B delivers GPT-4o-class performance with complete transparency, trained using a novel three-stage pipeline (SFT, DPO, RLVR) on 256 GPUs at unprecedented scale for open models[2][5][6]
- Reinforcement Learning with Verifiable Rewards (RLVR) enables training on objectively verifiable tasks, scaling preference learning from 60,000 to over 300,000 prompts without human annotation bottlenecks[1][2]
- Olmo 3-Think provides the strongest fully open reasoning capabilities in 7B and 32B variants, competitive with Qwen 3 and DeepSeek R1 Distill while maintaining complete transparency[5]
- Complete transparency from data to deployment includes the Dolma 3 dataset (5.9 trillion tokens), full training recipes, preprocessing pipelines, and evaluation frameworks—all open-sourced on GitHub[5][6]
- Practical applications span research, enterprise, and product development, with particular strength in scientific analysis, code generation, mathematical reasoning, and domain-specific fine-tuning
- Infrastructure requirements vary significantly from consumer GPUs for Olmo 3-Think 7B to 8x A100 GPUs for Tulu 3 405B, with quantization options reducing costs at some performance tradeoff
- Open-source AI ecosystem competition accelerates innovation, with Allen AI complementing Meta’s Llama, Mistral’s European models, and DeepSeek’s Chinese alternatives
- Deployment flexibility provides advantages over proprietary APIs for high-volume applications, sensitive data processing, and custom fine-tuning requirements
- Limitations include infrastructure costs, operational complexity, and smaller derivative ecosystems compared to more established open models like Llama
- Teams should test multiple models on representative tasks before deployment, using platforms that enable side-by-side comparisons to identify best performance for specific use cases
Quick Answer
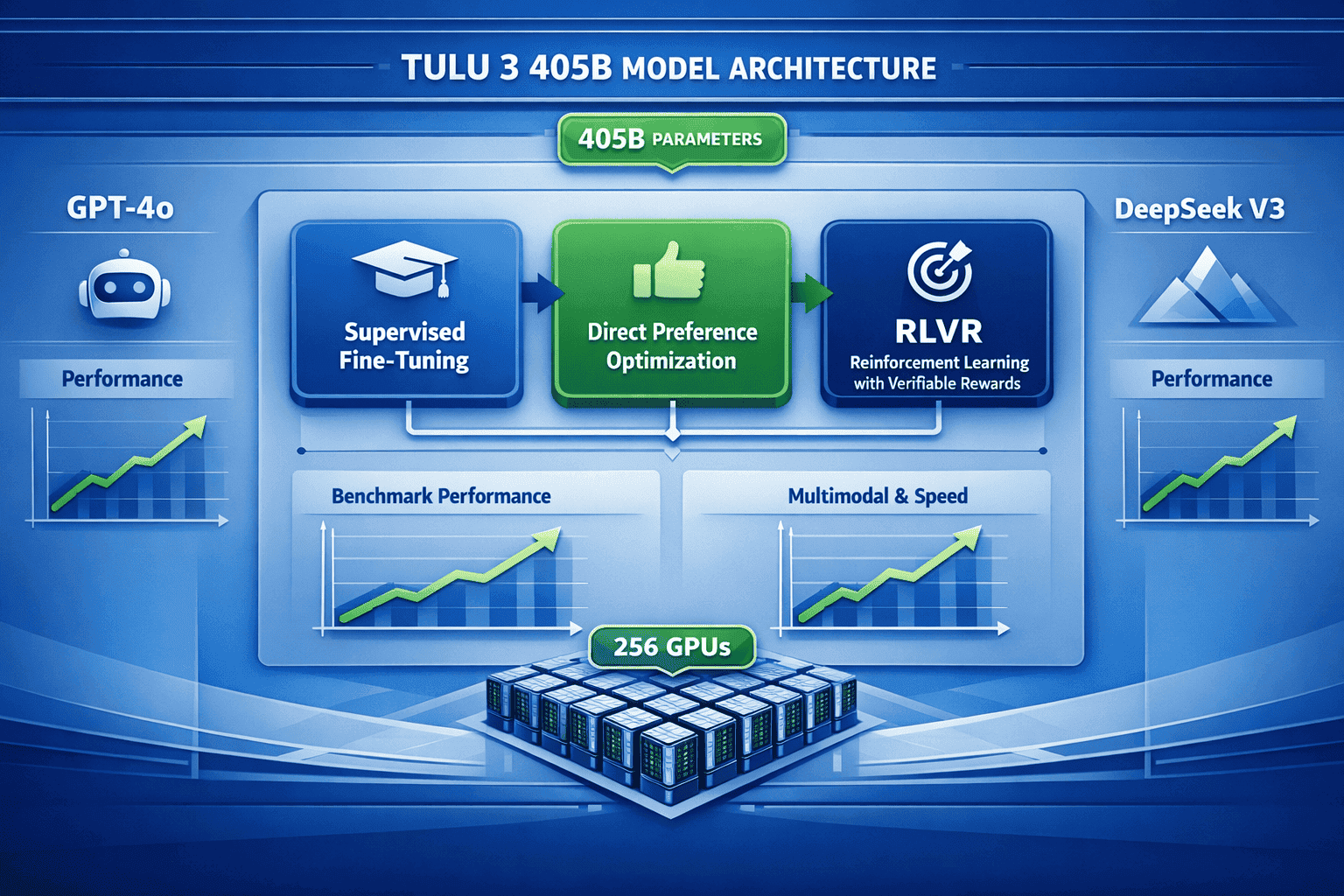
Allen AI’s latest breakthroughs center on two model families: Tulu 3 and Olmo 3. Tulu 3 405B achieves GPT-4o-level performance while remaining fully open-source, trained using a novel three-stage pipeline that scales to 256 GPUs. Olmo 3-Think delivers transparent reasoning capabilities competitive with leading closed models. Both families prove that open research can match proprietary systems while providing developers complete access to training data, methodologies, and deployment recipes.
What Makes Tulu 3 405B Different from Previous Open-Source Models?
Tulu 3 405B represents a step-change in open-source AI capability because it’s the first fully transparent model at the 405 billion parameter scale to match proprietary system performance. Built on Meta’s Llama 3.1 405B base model, Ai2’s post-training techniques actually improve on the original across multiple benchmarks[6].
The key differentiator is scale combined with transparency. Previous open-source efforts either used smaller models (70B parameters or less) or relied on limited preference datasets. Tulu 3 addresses both constraints:
Technical specifications:
- 405 billion parameters (5.8x larger than previous Tulu versions)
- Trained on 256 GPUs demonstrating production-scale deployment of novel techniques[5]
- Three-stage post-training pipeline: Supervised Fine-Tuning (SFT), Direct Preference Optimization (DPO), and Reinforcement Learning with Verifiable Rewards (RLVR)[6]
- Over 300,000 preference prompts (scaled from 60,000 in previous versions, representing 30% of SFT dataset size)[1]
Performance benchmarks show Tulu 3 405B:
- Rivals or exceeds OpenAI’s GPT-4o on standard evaluations[2][5]
- Outperforms Llama 3.1 405B Instruct (the base model it was built from)[6]
- Competes directly with DeepSeek V3 on key benchmarks[2]
The practical impact: developers can now access GPT-4o-class performance without API costs, usage restrictions, or black-box limitations. For teams building custom AI applications, this means full control over fine-tuning, deployment infrastructure, and data privacy.
Common mistake to avoid: Don’t assume “open-source” means “inferior performance.” Tulu 3 405B demonstrates that transparent development can match or exceed closed systems when proper post-training techniques are applied at scale.
How Does Reinforcement Learning with Verifiable Rewards (RLVR) Work?
RLVR is Ai2’s proprietary training technique that rewards models for correct answers on objectively verifiable tasks rather than relying solely on human preference judgments[2]. This approach solves a fundamental problem in AI training: human preference data is expensive, subjective, and doesn’t scale well.
The RLVR process works like this:
- Select verifiable tasks where correctness can be objectively determined (math problems, code execution, instruction-following with clear success criteria)
- Generate multiple responses to each prompt using the model
- Verify correctness automatically using programmatic checks (does the code run? Is the math answer correct?)
- Reward correct responses and penalize incorrect ones through reinforcement learning
- Scale training across hundreds of thousands of examples without human annotation bottlenecks
Why this matters in practice:
Traditional preference learning (like RLHF used in GPT-4) requires human annotators to judge which of two responses is better. This creates several problems:
- Subjective judgments vary between annotators
- Expensive to scale beyond tens of thousands of examples
- Biased toward style over correctness (humans often prefer confident-sounding wrong answers)
RLVR sidesteps these issues by focusing on tasks with ground truth. A math problem either produces the correct answer or it doesn’t. Code either executes successfully or throws an error. These verifiable outcomes provide cleaner training signals.
The three-stage pipeline combines techniques:
| Stage | Method | Purpose | Scale |
|---|---|---|---|
| 1. SFT | Supervised Fine-Tuning | Teach basic instruction-following | Full dataset |
| 2. DPO | Direct Preference Optimization | Align with human preferences | 300,000+ prompts |
| 3. RLVR | Reinforcement Learning with Verifiable Rewards | Improve correctness on verifiable tasks | Production scale |
Choose RLVR-trained models if: You need reliable performance on tasks with clear success criteria (coding, mathematical reasoning, structured data extraction, instruction-following). The technique particularly excels where correctness matters more than stylistic variation.
Edge case to consider: RLVR works best on tasks with objective verification. For creative writing, subjective analysis, or nuanced judgment calls, traditional preference learning may still provide better alignment with human expectations.
The full training recipe is available on GitHub, allowing researchers to reproduce or modify the approach for their own use cases[6].
What Is the Olmo 3 Model Family and Why Does It Matter?
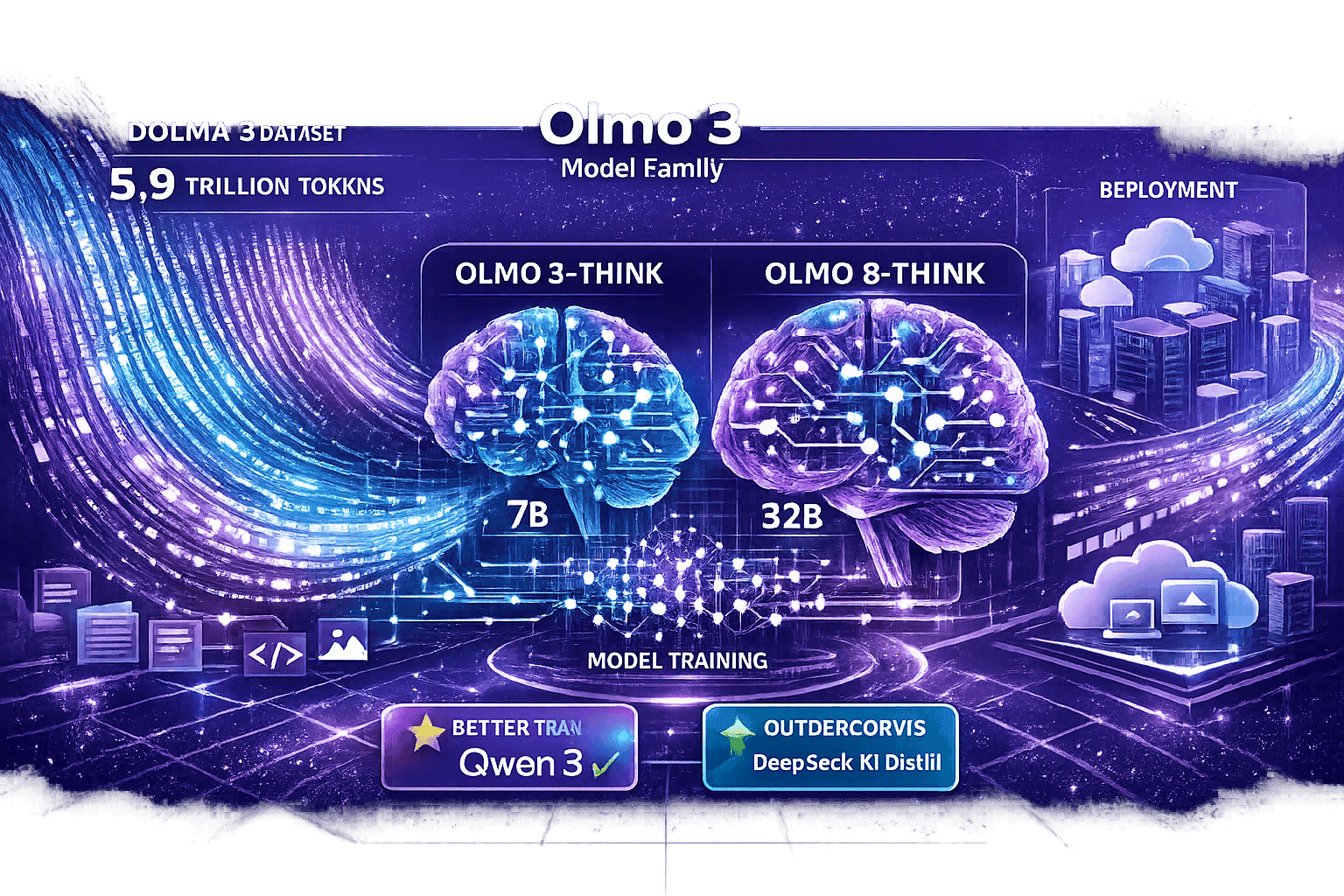
Olmo 3, released in November 2025, represents Ai2’s commitment to complete transparency in AI development[5]. Unlike most “open-source” models that release only weights and inference code, Olmo 3 provides the entire pipeline: training data, preprocessing scripts, training code, evaluation frameworks, and deployment recipes.
The Olmo 3 family includes:
Olmo 3 base models:
- Complete training transparency from data to deployment
- Built on the Dolma 3 dataset (5.9 trillion tokens)[5]
- Full reproducibility for academic research
Olmo 3-Think reasoning models:
- Available in 7B and 32B parameter variants[5]
- Competitive with Qwen 3 and DeepSeek R1 Distill[5]
- Strongest fully open reasoning models available in 2026
Why complete transparency matters:
Most AI companies release model weights but keep training data, preprocessing techniques, and training recipes proprietary. This creates several problems:
- Reproducibility gaps prevent independent verification of claims
- Hidden biases in training data remain unexamined
- Research barriers limit academic investigation of training dynamics
- Dependency risks tie users to specific vendors
Olmo 3 addresses these issues by open-sourcing everything. Researchers can examine exactly what data the model trained on, reproduce training runs, investigate failure modes, and build derivative works without restrictions.
The Dolma 3 dataset breakthrough:
At 5.9 trillion tokens, Dolma 3 represents one of the largest fully documented training datasets available[5]. Ai2 provides:
- Complete source attribution for all training data
- Filtering and preprocessing pipelines used to clean the data
- Deduplication techniques applied to remove redundancy
- Quality scoring methods used to select high-value content
This level of documentation allows researchers to understand exactly how data choices impact model behavior, a critical capability for addressing bias, safety, and reliability concerns.
In practice, Olmo 3-Think competes with leading reasoning models:
The 7B and 32B variants demonstrate that transparent development doesn’t sacrifice performance. These models handle multi-step reasoning, mathematical problem-solving, and complex instruction-following at levels comparable to much larger proprietary systems.
Choose Olmo 3 models if: You need complete transparency for academic research, regulatory compliance, or custom fine-tuning. The full pipeline access makes these models ideal for teams that want to understand and modify every aspect of model behavior.
For teams comparing multiple AI models side-by-side, platforms like MULTIBLY provide access to 300+ models including Olmo 3, allowing direct performance comparisons on your specific use cases.
How Do Allen AI’s Latest Breakthroughs Compare to Proprietary Systems?
Allen AI’s latest breakthroughs in how O1 and Tulu models are shaping open research AI in 2026 directly challenge the assumption that proprietary systems hold inherent performance advantages. Benchmark results show Tulu 3 405B matching or exceeding GPT-4o while Olmo 3-Think competes with leading reasoning models[2][5].
Performance comparison on key benchmarks:
Tulu 3 405B vs. Proprietary Models:
- Rivals GPT-4o across standard evaluation suites[2][5]
- Exceeds Llama 3.1 405B Instruct (the base model it was built from)[6]
- Competes with DeepSeek V3 on instruction-following and reasoning tasks[2]
Olmo 3-Think vs. Reasoning Models:
- Competitive with Qwen 3 on multi-step reasoning[5]
- Matches DeepSeek R1 Distill performance in 7B and 32B variants[5]
- Strongest fully open reasoning model available in 2026[5]
The key differences aren’t about performance—they’re about access and control:
| Aspect | Allen AI Models | Proprietary Systems |
|---|---|---|
| Model Weights | Fully available | API access only (GPT-4o) or limited weights (some competitors) |
| Training Data | Complete documentation (Dolma 3) | Undisclosed |
| Training Code | Open-source on GitHub | Proprietary |
| Fine-tuning | Full control, no restrictions | Limited or unavailable |
| Deployment | Self-hosted or cloud | Vendor-controlled APIs |
| Costs | Infrastructure only | Per-token API fees |
| Privacy | Complete data control | Data sent to third parties |
Real-world implications:
For research institutions, Allen AI models enable reproducible science. You can verify claims, investigate failure modes, and build on existing work without reverse-engineering black boxes.
For enterprise teams, the models provide deployment flexibility. Run them on-premises for sensitive data, fine-tune for domain-specific tasks, or optimize inference costs without per-token API fees.
For developers building products, open models eliminate vendor lock-in. Your application’s intelligence layer remains under your control as requirements evolve.
The landscape shift toward reasoning models:
Ai2 acknowledges that 2025-2026 has seen a fundamental shift toward “thinking” models that show their reasoning process[1]. OpenAI’s o1 series popularized this approach, but Allen AI’s Olmo 3-Think demonstrates that transparent reasoning doesn’t require proprietary techniques.
The difference: while o1’s reasoning process remains opaque, Olmo 3-Think provides full visibility into how the model arrives at conclusions. This transparency matters for debugging, safety analysis, and building trust in high-stakes applications.
Common mistake: Don’t assume API access to proprietary models is simpler than self-hosting open models. For production workloads at scale, self-hosted open models often provide better economics, lower latency, and more predictable performance.
Choose Allen AI models if: You need transparency, deployment flexibility, or freedom from API costs. Choose proprietary systems if you want minimal setup and don’t need fine-tuning or data privacy controls.
For teams evaluating multiple options, comparing AI responses side-by-side helps identify which model performs best on your specific tasks before committing to infrastructure investments.
What Role Does Open Research Play in AI Development in 2026?
Open research has become a competitive advantage rather than a compromise in 2026. Allen AI’s latest breakthroughs demonstrate that transparent development accelerates innovation, improves safety, and democratizes access to cutting-edge capabilities[2][7].
The shift from closed to open development:
Five years ago, the assumption was that proprietary development with large budgets would always outpace open research. 2026 tells a different story:
Open research advantages that have emerged:
- Faster iteration through community contribution – Thousands of researchers can identify issues, propose improvements, and test modifications when code and data are public
- Better safety analysis – Independent researchers can audit training data, test for biases, and verify safety claims without relying on vendor self-reporting
- Reproducible science – Claims can be verified, experiments can be replicated, and knowledge builds cumulatively rather than being rediscovered repeatedly
- Broader innovation – Developers worldwide can fine-tune, adapt, and deploy models for use cases the original creators never imagined
- Reduced concentration of power – Capabilities spread beyond a handful of well-funded companies to researchers, startups, and institutions globally
Ai2’s approach demonstrates U.S. competitive advantage in open AI development, operating independently of large technology company influence[2]. This matters because it provides an alternative to both closed commercial systems and state-backed development models.
The complete transparency model:
Allen AI’s commitment goes beyond releasing model weights. The full package includes:
- Training data documentation (Dolma 3 with 5.9 trillion tokens)[5]
- Preprocessing and filtering code showing exactly how raw data becomes training data
- Training recipes with hyperparameters, optimization techniques, and infrastructure requirements
- Evaluation frameworks for reproducing benchmark results
- Deployment guides for production use cases
This level of openness enables genuine reproducibility. Other researchers can verify claims, identify failure modes, and build improvements rather than starting from scratch.
Real-world impact in 2026:
For academic institutions: Open models level the playing field. Universities without billion-dollar budgets can conduct cutting-edge research using publicly available models and datasets.
For startups: Open models eliminate the need to choose between expensive API costs and building models from scratch. Teams can fine-tune existing open models for specific domains.
For regulated industries: Complete transparency enables compliance with emerging AI regulations that require explainability, bias auditing, and data provenance documentation.
For global development: Researchers in countries without access to expensive proprietary APIs can still work with state-of-the-art models, democratizing AI capabilities worldwide.
The reasoning model evolution:
Allen AI acknowledges that the landscape has shifted toward reasoning-focused models and plans to elaborate on how post-training techniques relate to OpenAI’s o1-style approaches and future agent architectures[1]. This signals that open research is keeping pace with proprietary innovation rather than following years behind.
In practice, this means: The gap between “best proprietary model” and “best open model” has narrowed to the point where many use cases see no practical difference. For tasks requiring transparency, customization, or deployment control, open models now provide superior value.
Similar dynamics are playing out globally, with China’s open models challenging established leaders and small model innovations proving that efficiency can match raw scale.
How Can Developers Access and Deploy Allen AI Models?
Allen AI provides multiple pathways for accessing and deploying their models, from quick experimentation to production-scale deployment. All models, code, and datasets are available through open-source channels without usage restrictions[7].
Access options:
1. Direct model downloads:
- Hugging Face Hub hosts Tulu 3 and Olmo 3 model weights
- Multiple format options (PyTorch, safetensors, GGUF for local inference)
- Quantized versions available for reduced memory requirements
2. GitHub repositories:
- Complete training code for reproducing results
- Inference examples in Python with popular frameworks
- Fine-tuning scripts for domain adaptation
- Evaluation harnesses for benchmark testing
3. Dataset access:
- Dolma 3 (5.9 trillion tokens) available for download[5]
- Preference datasets (300,000+ prompts) for post-training[1]
- Documentation explaining data sources, filtering, and preprocessing
Deployment options:
For experimentation and prototyping:
- Local inference on consumer GPUs (quantized models run on 24GB+ VRAM)
- Colab notebooks for quick testing without local setup
- Hugging Face Inference API for API-style access to open models
For production deployment:
- Self-hosted inference on cloud GPUs (AWS, GCP, Azure)
- Kubernetes deployments with auto-scaling
- Optimized serving frameworks (vLLM, TGI, TensorRT-LLM)
- Edge deployment for smaller models with quantization
For teams comparing multiple models:
Platforms like MULTIBLY provide access to 300+ AI models including Allen AI’s releases, allowing side-by-side comparisons without managing infrastructure for each model. This approach works well for teams evaluating which model performs best on specific tasks before committing to deployment infrastructure.
Deployment decision framework:
Choose self-hosted deployment if:
- You process sensitive data requiring on-premises control
- Your usage volume makes per-token API costs expensive
- You need custom fine-tuning for domain-specific tasks
- You require guaranteed latency and availability SLAs
Choose API access (via aggregators) if:
- You’re prototyping and want minimal setup
- Your usage is sporadic or low-volume
- You need to compare multiple models quickly
- You prefer operational simplicity over cost optimization
Technical requirements for self-hosting:
Tulu 3 405B:
- Minimum: 8x A100 80GB GPUs for inference
- Recommended: 8x H100 80GB GPUs for production latency
- Quantized versions: Run on 4x A100 with acceptable quality loss
- Memory: ~810GB for full precision, ~405GB for int8 quantization
Olmo 3-Think 32B:
- Minimum: 2x A100 80GB GPUs for inference
- Recommended: 4x A100 for production throughput
- Quantized versions: Single A100 40GB sufficient
- Memory: ~64GB for full precision, ~32GB for int8
Olmo 3-Think 7B:
- Minimum: Single A100 40GB or consumer GPU with 24GB+ VRAM
- Recommended: A100 80GB for production
- Quantized versions: Run on consumer GPUs with 12GB+ VRAM
- Memory: ~14GB for full precision, ~7GB for int8
Fine-tuning considerations:
Allen AI provides complete fine-tuning recipes for adapting models to specific domains. The process typically involves:
- Prepare domain-specific data in instruction-following format
- Use provided SFT scripts to fine-tune on your data
- Optionally apply DPO if you have preference data
- Evaluate on domain benchmarks to measure improvement
- Deploy fine-tuned model using standard inference frameworks
Common deployment mistake: Don’t over-provision GPU resources for initial testing. Start with smaller models or quantized versions to validate your use case, then scale to larger models only if performance gains justify the infrastructure costs.
The small model revolution shows that efficient smaller models often outperform larger ones on specific tasks, making Olmo 3-Think 7B a smart starting point for many applications.
What Are the Practical Applications of Allen AI’s Latest Models?
Allen AI’s latest breakthroughs enable practical applications across research, enterprise, and product development. The combination of strong performance and complete transparency unlocks use cases where proprietary models face limitations.
Research applications:
Scientific analysis and literature review:
- Tulu 3 405B processes research papers, extracts key findings, and synthesizes insights across large document collections
- Olmo 3-Think handles multi-step reasoning for hypothesis generation and experimental design
- Complete transparency allows researchers to audit model reasoning and verify conclusions
Reproducible AI research:
- Full training pipelines enable researchers to modify training techniques and measure impact
- Dolma 3 dataset provides documented training data for investigating model behavior
- Open evaluation frameworks standardize benchmark comparisons across research groups
Enterprise applications:
Custom domain adaptation:
- Financial services fine-tune models on proprietary financial documents for analysis and forecasting
- Legal tech adapts models to case law and regulatory documents for research and compliance
- Healthcare customizes models for medical literature analysis while maintaining data privacy
On-premises deployment for sensitive data:
- Government agencies deploy models for classified document analysis without external API calls
- Financial institutions process confidential data locally for regulatory compliance
- Healthcare providers analyze patient records while maintaining HIPAA compliance
Code generation and analysis:
- Tulu 3’s RLVR training on verifiable coding tasks produces reliable code generation
- Olmo 3-Think handles complex multi-file codebases with step-by-step reasoning
- Self-hosted deployment protects proprietary code from third-party exposure
Product development applications:
Intelligent applications without vendor lock-in:
- Educational platforms integrate reasoning models for personalized tutoring
- Customer support systems deploy fine-tuned models for domain-specific assistance
- Content creation tools use models for writing assistance, editing, and ideation
Multi-model workflows:
- Routing systems send simple queries to Olmo 3-Think 7B and complex tasks to Tulu 3 405B
- Ensemble approaches combine multiple models for improved reliability
- A/B testing compares model versions on production traffic before full deployment
Cost optimization:
- Self-hosted inference eliminates per-token API costs for high-volume applications
- Quantization reduces infrastructure requirements while maintaining acceptable quality
- Smaller models (Olmo 3-Think 7B) handle many tasks at fraction of larger model costs
Specific use case examples:
Mathematical reasoning and problem-solving: Choose Olmo 3-Think for multi-step math problems, financial modeling, and quantitative analysis. The verifiable rewards training produces reliable arithmetic and logical reasoning.
Long-form content generation: Use Tulu 3 405B for research reports, technical documentation, and comprehensive analysis requiring nuanced understanding and coherent long-form output.
Code review and debugging: Deploy Tulu 3 for analyzing code quality, identifying bugs, and suggesting improvements. The RLVR training on executable code produces practical, working solutions.
Instruction-following and task automation: Olmo 3-Think excels at following complex multi-step instructions, making it ideal for workflow automation, data processing pipelines, and structured task completion.
Research literature synthesis: Tulu 3 405B handles large document collections, extracting themes, identifying contradictions, and synthesizing insights across hundreds of papers.
Edge case consideration: For real-time applications requiring sub-100ms latency, even optimized inference of 405B models may be too slow. In these cases, smaller models like Olmo 3-Think 7B or lightweight alternatives provide better latency-performance tradeoffs.
Comparing models for your use case:
Before committing to deployment infrastructure, test multiple models on representative tasks. Platforms providing side-by-side AI comparisons help identify which model performs best for your specific requirements, whether that’s Allen AI’s models, enterprise reasoning models like Magistral, or other alternatives.
How Do Allen AI’s Models Fit into the Broader Open-Source AI Ecosystem?
Allen AI’s latest breakthroughs position the organization as a key player in the open-source AI ecosystem, complementing and competing with other major initiatives. Understanding where these models fit helps teams make informed deployment decisions.
The open-source AI landscape in 2026:
Major open model families:
- Meta’s Llama series – Broad base models with wide adoption
- Allen AI’s Tulu and Olmo – Research-focused with complete transparency
- Mistral AI’s models – European alternative with strong performance
- DeepSeek’s R1 and V3 – Chinese models with competitive benchmarks
- Microsoft’s Phi series – Efficient small models for specific tasks
Allen AI’s unique positioning:
Complete transparency vs. partial openness: Most “open-source” models release weights but keep training data and recipes proprietary. Allen AI provides everything:
- Full training data (Dolma 3 with 5.9 trillion tokens)[5]
- Complete training code and recipes on GitHub[6]
- Preprocessing pipelines showing data cleaning and filtering
- Evaluation frameworks for reproducing benchmarks
This level of openness is rare. Even well-regarded open models often omit training data documentation or preprocessing details.
Academic rigor vs. commercial focus: Allen AI operates as a research institute rather than a commercial entity, which influences model development priorities:
- Reproducibility takes precedence over competitive advantage
- Scientific methodology guides training decisions
- Community benefit outweighs proprietary control
- Long-term research matters more than quarterly product releases
U.S.-based open development: Ai2 demonstrates that U.S. institutions can compete in open-source AI without large technology company backing[2]. This matters as AI development becomes geopolitically significant.
Complementary relationships with other open models:
Llama as foundation, Tulu as enhancement: Tulu 3 405B builds on Llama 3.1 405B, demonstrating that open base models enable community improvements. The post-training techniques that make Tulu 3 outperform the original Llama show how open ecosystems accelerate progress[6].
Comparison with global alternatives: DeepSeek’s R1 and V3 models compete directly with Allen AI’s offerings on benchmarks, creating healthy competition that pushes both forward. GLM-4.5’s 355B MoE architecture demonstrates alternative approaches to achieving strong performance.
Efficiency vs. scale tradeoffs: While Allen AI focuses on large-scale models with maximum capability, Phi-4 and Mistral’s small models show that efficiency sometimes beats raw parameter count. Teams should evaluate both approaches for their use cases.
Ecosystem contributions beyond models:
Training techniques: RLVR and the three-stage post-training pipeline provide methodologies other researchers can adopt, improving the entire ecosystem’s capabilities[2][6].
Datasets: Dolma 3’s 5.9 trillion tokens with complete documentation gives the community a foundation for training new models or analyzing training dynamics[5].
Evaluation frameworks: Open benchmark code allows standardized comparisons across models, reducing vendor-specific evaluation gaming.
Infrastructure recipes: Documentation of 256-GPU training runs helps other institutions understand requirements for large-scale model development[5].
Choosing between open model families:
Choose Allen AI models if:
- You need complete transparency for research or compliance
- You want to understand and modify training processes
- You value academic rigor and reproducibility
- You’re building on U.S.-based open infrastructure
Choose Llama if:
- You need broad ecosystem support and tooling
- You want maximum community fine-tunes and derivatives
- You prioritize deployment simplicity over transparency
Choose DeepSeek/GLM if:
- You need strong performance at competitive pricing
- You’re comfortable with Chinese-developed models
- You want alternative architectures (MoE) for efficiency
Choose Phi/Mistral if:
- You need efficient inference on limited hardware
- You prioritize speed and cost over maximum capability
- You want European-developed alternatives
The competitive dynamics: Open-source AI in 2026 isn’t a single community but a competitive ecosystem. Allen AI, Meta, Mistral, DeepSeek, and others push each other forward through benchmark competition and technique sharing. This competition benefits users who can choose the best model for each task rather than being locked into a single vendor.
For teams working across multiple models, platforms like MULTIBLY provide unified access to 300+ models, allowing practical comparisons without managing separate infrastructure for each option.
What Are the Limitations and Challenges of Allen AI’s Current Models?
Allen AI’s latest breakthroughs represent significant progress, but understanding limitations helps teams set realistic expectations and choose appropriate use cases.
Infrastructure requirements:
High deployment costs for largest models: Tulu 3 405B requires substantial GPU resources for inference. At minimum, you need 8x A100 80GB GPUs, which costs approximately $20,000-30,000 per month on cloud platforms. For many applications, this makes smaller models or API access more economical.
Quantization tradeoffs: While quantization reduces infrastructure requirements, it also degrades performance. Teams must balance cost savings against quality loss for their specific use cases.
Latency considerations: Large models produce slower responses than smaller alternatives. Real-time applications may require routing simple queries to smaller models while reserving large models for complex tasks.
Performance limitations:
Not universally superior to proprietary models: While Tulu 3 405B rivals GPT-4o on many benchmarks, it doesn’t exceed it on all tasks. Proprietary models may still lead on specific capabilities like multilingual performance or certain reasoning tasks.
Reasoning transparency vs. reasoning capability: Olmo 3-Think provides transparent reasoning, but the reasoning process itself may not always be correct. Transparency helps identify errors but doesn’t eliminate them.
Domain-specific gaps: General-purpose models require fine-tuning for specialized domains. Out-of-the-box performance on medical, legal, or highly technical content may lag domain-specific proprietary alternatives.
Ecosystem maturity:
Fewer pre-built integrations: Proprietary APIs like GPT-4 have extensive ecosystem integrations (Zapier, LangChain, etc.). Open models require more custom integration work.
Limited commercial support: As research models, Allen AI’s releases don’t come with enterprise SLAs, support contracts, or guaranteed uptime. Teams must handle operational issues independently.
Smaller fine-tuned derivative ecosystem: Llama has thousands of community fine-tunes for specific tasks. Allen AI models have fewer derivatives, meaning teams may need to create custom fine-tunes rather than finding existing ones.
Documentation and accessibility:
Steeper learning curve: Complete transparency means more complexity. Teams must understand training pipelines, evaluation frameworks, and deployment options rather than simply calling an API.
Infrastructure expertise required: Self-hosting requires GPU infrastructure management, optimization expertise, and operational monitoring that API access avoids.
Rapidly evolving landscape: Open-source AI moves quickly. Models released in early 2026 may be superseded by better alternatives within months, requiring teams to continuously evaluate new options.
Common mistakes to avoid:
Mistake 1: Assuming bigger is always better Tulu 3 405B isn’t always the right choice. For many tasks, Olmo 3-Think 7B provides better cost-performance tradeoffs. Test smaller models first.
Mistake 2: Ignoring fine-tuning requirements General-purpose models need domain adaptation for specialized tasks. Budget time and resources for fine-tuning rather than expecting perfect out-of-box performance.
Mistake 3: Underestimating operational complexity Self-hosting requires monitoring, scaling, version management, and incident response. Factor these operational costs into deployment decisions.
Mistake 4: Overlooking inference optimization Default inference configurations often waste resources. Invest in optimization (quantization, batching, caching) to improve cost-efficiency.
Edge cases and special considerations:
Multilingual performance: Allen AI models primarily train on English data. Non-English performance may lag models specifically optimized for multilingual tasks.
Multimodal capabilities: Current releases focus on text. Teams needing vision, audio, or other modalities must look to alternative models or wait for future releases.
Context window constraints: While competitive with other models, context windows still limit certain applications. Document analysis requiring hundreds of pages may need chunking strategies or models with longer context windows.
Safety and alignment: Open models allow complete customization, including removing safety guardrails. Teams must implement their own content filtering and safety measures for production deployments.
Realistic expectations:
Allen AI’s models provide strong performance with complete transparency, but they’re not magic solutions. Teams should:
- Test on representative tasks before committing to deployment
- Compare multiple models including proprietary alternatives
- Start small with Olmo 3-Think 7B before scaling to larger models
- Plan for fine-tuning to achieve domain-specific performance
- Budget for infrastructure and operational expertise
For teams comparing options, side-by-side AI model comparisons help identify which models actually perform best on your specific tasks rather than relying on general benchmark claims.
Frequently Asked Questions
What is the difference between Tulu 3 and Olmo 3 models?
Tulu 3 focuses on instruction-following and general capability at scale (405B parameters), built on Llama 3.1 with advanced post-training techniques. Olmo 3 provides complete transparency from training data to deployment, with Olmo 3-Think variants (7B and 32B) specializing in reasoning tasks. Choose Tulu 3 for maximum capability, Olmo 3 for complete transparency and reproducibility.
Can I use Allen AI models commercially without restrictions?
Yes. Allen AI releases models under permissive open-source licenses that allow commercial use without royalties or usage restrictions. You can deploy, modify, and fine-tune the models for any commercial application. Check specific license terms for each model release, but commercial use is explicitly permitted.
How much does it cost to run Tulu 3 405B in production?
Infrastructure costs depend on deployment scale. Cloud GPU hosting for 8x A100 80GB GPUs costs approximately $20,000-30,000 per month. Quantized versions reduce requirements to 4x A100 at roughly half the cost. For high-volume applications, self-hosting becomes more economical than per-token API pricing after processing millions of tokens monthly.
Are Allen AI models better than GPT-4o?
Tulu 3 405B matches or rivals GPT-4o on many benchmarks but doesn’t universally exceed it on all tasks. The key advantage is transparency and deployment control rather than pure performance superiority. For tasks requiring explainability, fine-tuning, or on-premises deployment, Allen AI models provide better value. For quick API access without infrastructure management, GPT-4o may be simpler.
What hardware do I need to run Olmo 3-Think models?
Olmo 3-Think 7B runs on a single A100 40GB GPU or consumer GPUs with 24GB+ VRAM (like RTX 4090). Quantized versions work on GPUs with 12GB+ VRAM. Olmo 3-Think 32B requires 2x A100 80GB GPUs minimum, or a single A100 with quantization. These requirements make the smaller models accessible for experimentation without enterprise-scale infrastructure.
How does RLVR compare to RLHF used in GPT-4?
RLVR (Reinforcement Learning with Verifiable Rewards) trains on objectively verifiable tasks where correctness can be programmatically determined, while RLHF (Reinforcement Learning from Human Feedback) relies on human preference judgments. RLVR scales more efficiently and produces clearer training signals for tasks with ground truth (math, coding), while RLHF better captures subjective preferences for creative or stylistic tasks.
Can I fine-tune Allen AI models on my own data?
Yes. Allen AI provides complete fine-tuning recipes and code on GitHub. You can fine-tune models on domain-specific data using the same techniques Ai2 used for post-training. The process requires GPU resources (single A100 for smaller models, multiple GPUs for larger ones) and your own training data in instruction-following format.
What is the Dolma 3 dataset and can I use it?
Dolma 3 is a 5.9 trillion token dataset that Ai2 used to train Olmo 3 models, fully documented and available for download. It includes complete source attribution, preprocessing pipelines, and quality filtering details. You can use it to train your own models, analyze training data composition, or investigate how data choices impact model behavior.
How do Allen AI models handle multilingual tasks?
Allen AI models primarily train on English data, so multilingual performance lags models specifically optimized for non-English languages. For applications requiring strong multilingual capability, consider models like GPT-4o or multilingual-focused open models. Allen AI models work adequately for common European languages but may struggle with low-resource languages.
What support is available for deploying Allen AI models?
Allen AI provides documentation, code examples, and GitHub repositories but doesn’t offer commercial support contracts. Community support is available through GitHub issues and research forums. For enterprise deployments requiring SLAs and guaranteed support, consider working with cloud providers or AI platforms that offer managed services for open models.
How often does Allen AI release new models?
Release cadence varies based on research progress. Olmo 3 was released in November 2025, with Tulu 3 following in early 2026. Ai2 prioritizes research quality over predictable release schedules. Follow their newsletters and GitHub repositories for announcements of new models and capabilities.
Can I compare Allen AI models with other options before deploying?
Yes. Platforms like MULTIBLY provide access to 300+ AI models including Allen AI’s releases, allowing side-by-side comparisons on your specific tasks. This approach helps identify which model performs best for your use case before committing to deployment infrastructure or API contracts.
Conclusion
Allen AI’s latest breakthroughs in how O1 and Tulu models are shaping open research AI in 2026 prove that transparent development can match proprietary systems in performance while providing superior control, flexibility, and reproducibility. Tulu 3 405B and Olmo 3-Think represent more than technical achievements—they demonstrate a viable alternative to closed AI development that benefits researchers, enterprises, and developers worldwide.
The key insight: you no longer need to choose between performance and transparency. Models like Tulu 3 405B rival GPT-4o on benchmarks while providing complete access to training data, code, and methodologies. Olmo 3-Think delivers competitive reasoning capabilities in efficient 7B and 32B variants that run on accessible hardware.
Actionable next steps:
For researchers: Download Olmo 3 models and the Dolma 3 dataset to conduct reproducible AI research. Examine training pipelines, test modifications, and contribute findings back to the community.
For enterprises: Evaluate Tulu 3 and Olmo 3-Think on representative tasks from your domain. Compare performance against proprietary alternatives using platforms like MULTIBLY that provide access to 300+ models for side-by-side testing.
For developers: Start with Olmo 3-Think 7B for experimentation on consumer hardware. Test on your specific use cases, measure performance, and scale to larger models only if benefits justify infrastructure costs.
For teams building products: Consider self-hosted deployment for high-volume applications where per-token API costs become prohibitive. Use the complete fine-tuning recipes to adapt models to your domain.
The broader implication: open-source AI has reached competitive parity with proprietary systems for many use cases. The decision between open and closed models now hinges on deployment requirements, customization needs, and transparency priorities rather than raw performance gaps.
As the AI landscape continues evolving rapidly, with small models challenging large ones and global competition intensifying, Allen AI’s commitment to complete transparency provides a foundation for informed decision-making. You can verify claims, understand limitations, and build on solid research rather than trusting vendor promises.
The future of AI development increasingly looks open, transparent, and accessible—exactly what Allen AI’s latest breakthroughs demonstrate is possible.
Our Fact Checking Process
We prioritize accuracy and integrity in our content. Here's how we maintain high standards:
- Expert Review: All articles are reviewed by subject matter experts.
- Source Validation: Information is backed by credible, up-to-date sources.
- Transparency: We clearly cite references and disclose potential conflicts.
Our Review Board
Our content is carefully reviewed by experienced professionals to ensure accuracy and relevance.
- Qualified Experts: Each article is assessed by specialists with field-specific knowledge.
- Up-to-date Insights: We incorporate the latest research, trends, and standards.
- Commitment to Quality: Reviewers ensure clarity, correctness, and completeness.
Look for the expert-reviewed label to read content you can trust.



