
The battle between Anthropic’s Claude 4 Sonnet and OpenAI’s GPT-4o has intensified in 2026, with recent leaderboards revealing Claude 4 Sonnet’s dominance in coding and reasoning tasks while GPT-4o maintains advantages in speed and creative applications. This Claude 4 Sonnet vs GPT-4o: Comprehensive Benchmark Comparison in 2026 examines real-world performance data, pricing structures, and enterprise use cases to help organizations and developers choose the right AI model for their specific needs.
- Key Takeaways
- Quick Answer
- What Are the Key Performance Differences Between Claude 4 Sonnet and GPT-4o?
- How Do Pricing Models Compare in the Claude 4 Sonnet vs GPT-4o Benchmark?
- Which Model Wins for Coding Tasks in 2026?
- How Do Creative and Analytical Capabilities Differ?
- What Context Window Advantages Does Claude 4 Sonnet Offer?
- How Do Safety and Alignment Features Compare in 2026?
- What Are the Best Use Cases for Each Model?
- How Do Response Speed and Latency Compare?
- FAQ: Claude 4 Sonnet vs GPT-4o Comparison
- Conclusion
- References
Key Takeaways
Claude 4 Sonnet leads in technical performance with a state-of-the-art 72.7% SWE-bench coding score, superior debugging capabilities, and better long-form analytical content generation[5][3]
GPT-4o offers significant cost advantages at 17% lower input pricing and 33% lower output pricing, making it more economical for high-volume applications and budget-conscious deployments[2][4]
Context window differences create distinct use cases: Claude’s 1 million input tokens (8x larger than GPT-4o) enable processing entire codebases and lengthy documents in single sessions without context loss[2][3]
Creative versus analytical strengths diverge clearly: GPT-4o excels at marketing copy, storytelling, and creative content while Claude 4 Sonnet dominates technical documentation, business analysis, and structured writing[1]
Safety and alignment favor Claude for regulated industries: Anthropic’s constitutional AI approach provides stronger guardrails for healthcare, finance, legal, and education applications requiring strict compliance[5]
Response speed advantages go to GPT-4o for real-time applications including customer chatbots, voice assistants, and interactive tools where latency impacts user experience[3]
Extended conversation coherence sets Claude apart: Maintaining context across 50+ exchanges makes Claude superior for multi-session consulting, iterative design, and complex customer support scenarios[3]
Hybrid deployment strategies optimize both cost and performance by routing simple tasks to GPT-4o and complex analysis to Claude 4 Sonnet based on specific requirements
Enterprise adoption patterns reflect specialization: Organizations increasingly use Claude for production coding and analytical work while deploying GPT-4o for creative content and high-volume customer interactions[6]
Instruction adherence and consistency favor Claude for applications requiring strict formatting, citation styles, and specification compliance without drift from original requirements[3]
Quick Answer
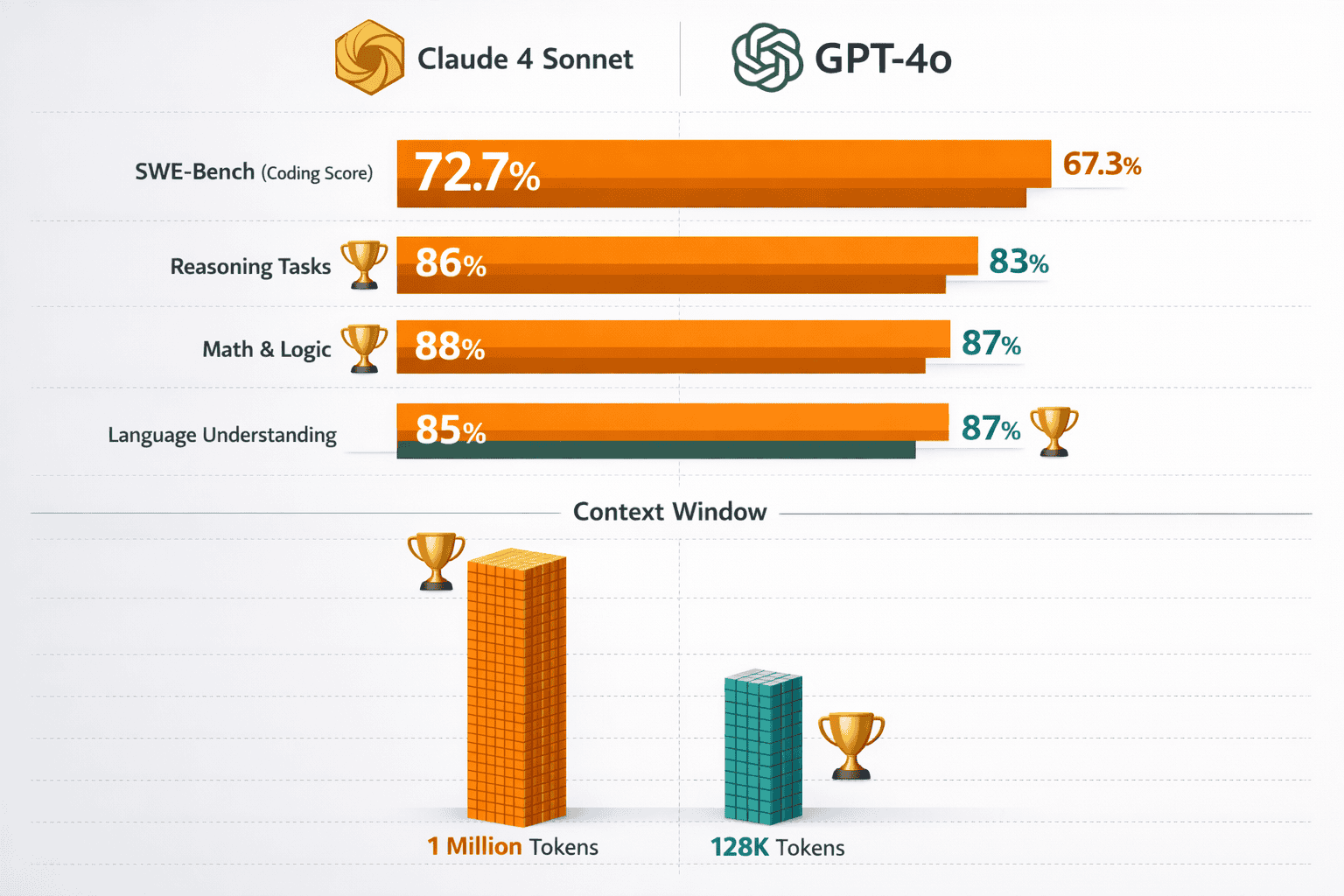
Claude 4 Sonnet and GPT-4o serve different strengths in 2026’s AI landscape. Claude 4 Sonnet leads in coding performance with a state-of-the-art 72.7% SWE-bench score, handles 8x larger context windows (1 million input tokens), and maintains superior coherence in extended conversations[5][2]. GPT-4o offers 17-33% lower pricing, faster response times, and better creative output for marketing and storytelling tasks[2][4][1]. Organizations should choose Claude 4 Sonnet for technical documentation, code review, and analytical work, while GPT-4o suits high-volume creative applications and budget-conscious deployments.
What Are the Key Performance Differences Between Claude 4 Sonnet and GPT-4o?
Claude 4 Sonnet and GPT-4o demonstrate distinct performance profiles across coding, reasoning, and creative tasks, with Claude claiming the lead in technical benchmarks while GPT-4o maintains speed advantages.
Coding Performance: Claude 4 Sonnet achieves a groundbreaking 72.7% score on the SWE-bench coding evaluation, representing the highest performance among publicly available models in 2026[5]. This benchmark tests real-world software engineering tasks including bug fixes, feature implementations, and code refactoring. GPT-4o scores lower on the same benchmark, though exact figures vary by test configuration.
Context Processing Capabilities: The most dramatic difference appears in context handling. Claude 4 Sonnet accepts up to 1 million input tokens compared to GPT-4o’s 128,000-token limit—an 8x advantage that translates to approximately 50,000 lines of code versus 32,000 lines for GPT-4o[2][3]. For output generation, Claude produces up to 128,000 tokens while GPT-4o caps at 16,400 tokens[2].
Reasoning and Analysis: Claude 4 Sonnet supports extended thinking mode up to 64,000 tokens for complex reasoning tasks, allowing the model to “think through” problems before responding[5]. This capability proves especially valuable for:
- Multi-step mathematical proofs
- Legal contract analysis
- Strategic business planning
- Complex debugging scenarios
Speed and Responsiveness: GPT-4o delivers faster response times for standard queries, making it preferable for real-time applications and customer-facing chatbots where latency matters[3]. Claude 4 Sonnet prioritizes thoroughness over speed, sometimes taking longer to generate comprehensive responses.
Common mistake: Developers often assume higher token limits automatically mean better performance for all tasks. In reality, most coding tasks use fewer than 50,000 tokens, so the context advantage only matters for large codebase analysis or documentation generation.
How Do Pricing Models Compare in the Claude 4 Sonnet vs GPT-4o Benchmark?
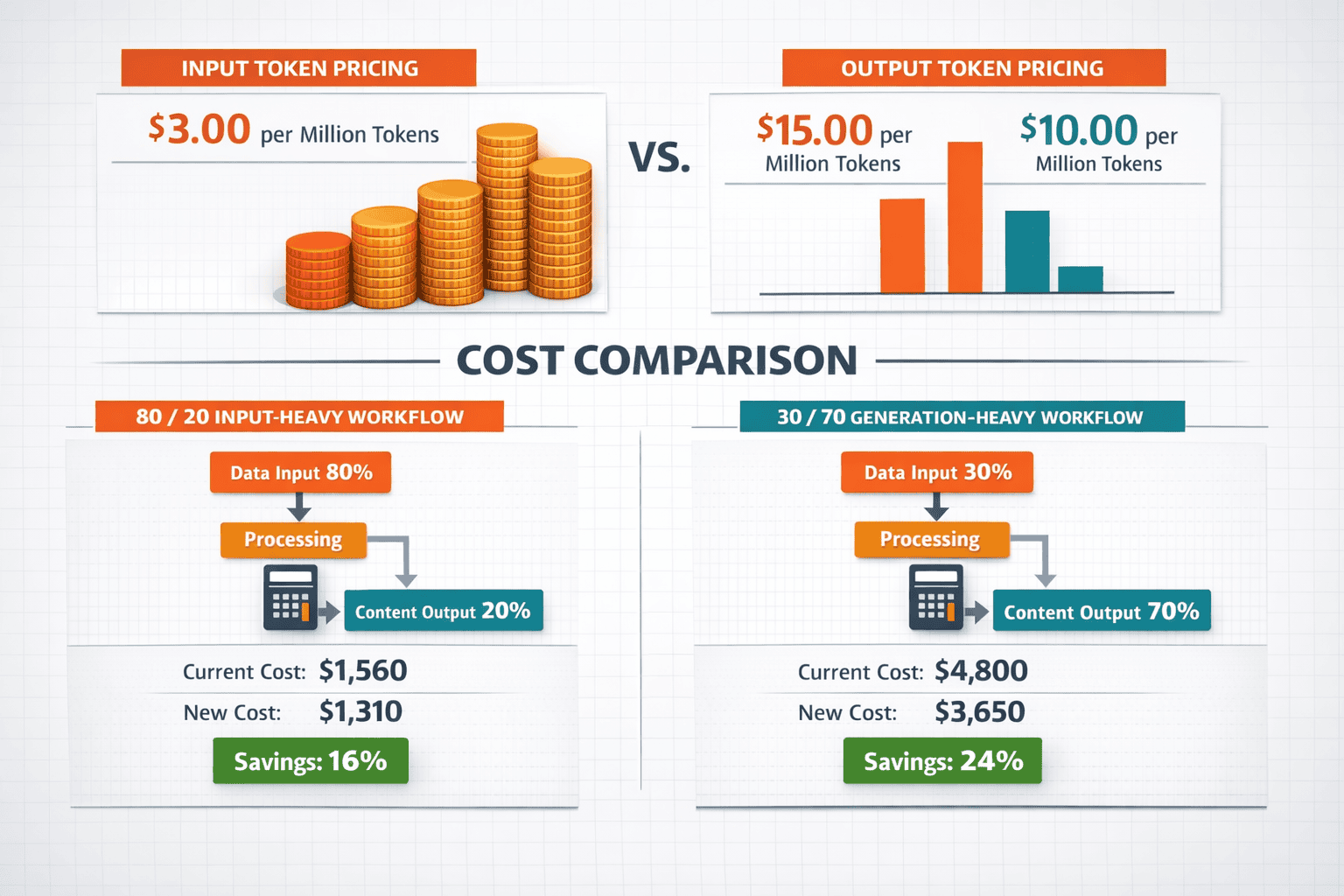
GPT-4o offers significantly lower pricing across both input and output tokens, creating a 17-33% cost advantage depending on workflow patterns.
Base Pricing Structure:
| Model | Input Tokens (per 1M) | Output Tokens (per 1M) |
|---|---|---|
| GPT-4o | $2.50 | $10.00 |
| Claude 4 Sonnet | $3.00 | $15.00 |
| Difference | 17% cheaper (GPT-4o) | 33% cheaper (GPT-4o) |
Real-World Cost Scenarios: Pricing impact varies dramatically based on workflow composition. For input-heavy workflows (80% input, 20% output)—common in document analysis and code review—GPT-4o costs $0.0400 per operation while Claude 4 Sonnet costs $0.0540[4]. The gap widens for generation-heavy workflows (30% input, 70% output) like content creation, where costs reach $0.0775 for GPT-4o versus $0.114 for Claude 4 Sonnet[4].
When Claude’s Higher Price Makes Sense:
- Reduced iteration cycles: Claude’s superior code quality often requires fewer debugging rounds, offsetting higher per-token costs
- Context efficiency: Processing entire codebases in one pass eliminates multiple API calls that GPT-4o would require
- Error reduction: For safety-critical applications, Claude’s lower error rate reduces costly mistakes
Budget Optimization Tips:
- Use GPT-4o for high-volume, low-stakes tasks (customer support, content drafts)
- Reserve Claude 4 Sonnet for complex analysis requiring accuracy
- Monitor token usage patterns monthly to identify optimization opportunities
- Consider hybrid approaches where simpler tasks route to GPT-4o automatically
Edge case: Organizations processing millions of tokens daily can negotiate volume discounts with both providers, potentially narrowing the pricing gap to 5-10% rather than the published 17-33% difference.
Which Model Wins for Coding Tasks in 2026?
Claude 4 Sonnet dominates coding tasks across multiple dimensions including code generation, debugging, review quality, and long-term codebase maintenance, while GPT-4o excels at quick completions and boilerplate generation.
Benchmark Performance: Multiple 2026 analyses consistently rate Claude 4 Sonnet superior for professional software development work[3][6]. The model’s 72.7% SWE-bench score demonstrates its ability to handle real-world engineering challenges that go beyond simple code completion[5].
Specific Coding Advantages for Claude 4 Sonnet:
- Debugging depth: Provides more thorough analysis and catches subtle issues that GPT-4o misses[3]
- Code review quality: Identifies security vulnerabilities, performance bottlenecks, and architectural problems more consistently
- Long codebase maintenance: Maintains context across 50+ conversation exchanges, remembering earlier discussions while GPT-4o “tends to lose the thread”[3]
- Instruction adherence: Follows coding standards and specifications more consistently without drifting from original requirements[3]
Where GPT-4o Performs Better:
- Speed for simple tasks: Generates boilerplate code, basic functions, and standard implementations faster
- Creative problem-solving: Offers more varied approaches to algorithmic challenges
- Quick prototyping: Better suited for rapid iteration during early development phases
Developer Consensus in 2026: Professional developers increasingly choose Claude 4 Sonnet as their primary coding assistant for production work, reserving GPT-4o for exploratory coding and quick scripts[6]. The pattern mirrors how developers use different tools for different phases—prototyping versus production deployment.
Choose Claude 4 Sonnet if: You’re working on production code, conducting code reviews, debugging complex issues, or maintaining large codebases where context retention matters.
Choose GPT-4o if: You need fast boilerplate generation, quick prototypes, or handle many small, independent coding tasks where speed outweighs depth.
How Do Creative and Analytical Capabilities Differ?
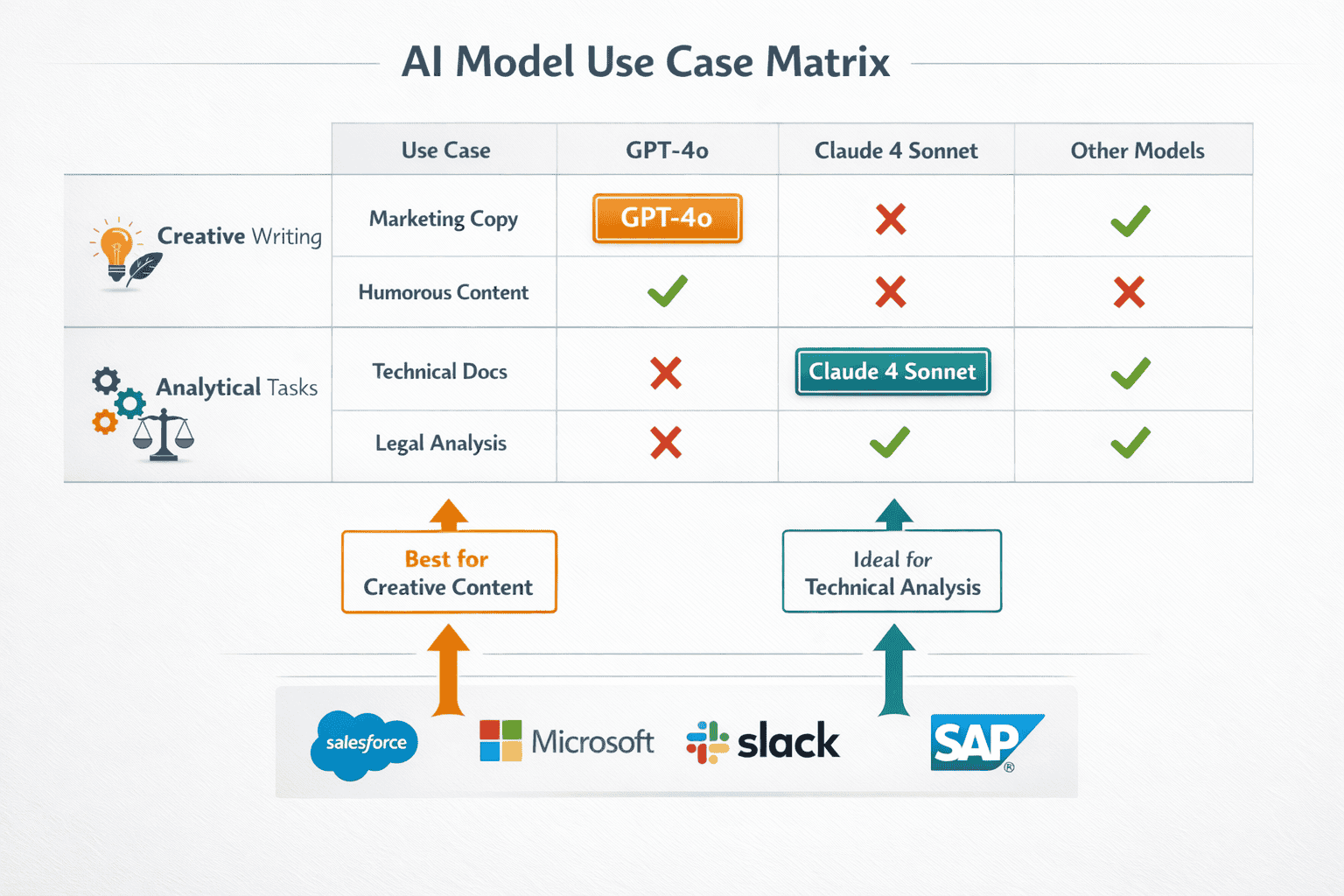
GPT-4o demonstrates superior creativity and humor for marketing and storytelling, while Claude 4 Sonnet excels at analytical and structured content including technical documentation, business reports, and legal analysis.
Creative Writing Strengths (GPT-4o):
GPT-4o produces more engaging creative content with better humor, varied sentence structures, and emotional resonance[1]. Marketing teams report higher conversion rates for GPT-4o-generated copy in A/B tests, particularly for:
- Social media posts and captions
- Email marketing campaigns
- Product descriptions
- Blog introductions and storytelling
- Brand voice development
Analytical Writing Strengths (Claude 4 Sonnet):
Claude 4 Sonnet provides more thorough, structured analytical content with better logical flow and evidence-based reasoning[1]. Legal and consulting firms prefer Claude for:
- Technical documentation: API references, user manuals, system architecture descriptions
- Business reports: Financial analysis, market research, strategic planning documents
- Legal analysis: Contract review, compliance documentation, policy interpretation
- Academic writing: Research summaries, literature reviews, methodology descriptions
Instruction Following Consistency: Claude 4 Sonnet maintains tighter adherence to specific formatting requirements, citation styles, and structural guidelines[3]. When given a detailed content brief, Claude produces output that requires fewer revisions to match specifications.
Tone and Voice Flexibility: GPT-4o adapts more naturally to different brand voices and can shift between formal and casual tones more fluidly. Claude 4 Sonnet tends toward a more consistent, professional tone that works well for corporate communications but may feel less dynamic for consumer-facing creative content.
Real-world application: A 2026 marketing agency might use GPT-4o for initial creative brainstorming and social media content while deploying Claude 4 Sonnet for white papers, case studies, and technical blog posts that require accuracy and depth.
What Context Window Advantages Does Claude 4 Sonnet Offer?
Claude 4 Sonnet’s 1 million input token capacity—8 times larger than GPT-4o’s 128,000 tokens—enables processing entire codebases, lengthy documents, and extended conversations in single sessions without context loss.
Practical Implications of Context Size:
The token difference translates to real-world capacity gaps:
- Code processing: ~50,000 lines for Claude vs ~32,000 lines for GPT-4o[2][3]
- Document analysis: Complete books, research papers, or legal contracts in one pass
- Conversation memory: Extended multi-turn dialogues without forgetting earlier context
Extended Conversation Coherence: After 50 back-and-forth exchanges, Claude 4 Sonnet still references discussions from the beginning of the conversation, while GPT-4o tends to lose earlier context[3]. This advantage proves critical for:
- Complex consulting engagements requiring multi-session continuity
- Iterative design processes with evolving requirements
- Long-form content development with consistent themes
- Customer support cases with extensive history
Output Generation Capacity: Claude 4 Sonnet generates up to 128,000 output tokens compared to GPT-4o’s 16,400-token limit[2]. This 8x advantage enables:
- Complete technical documentation in single responses
- Comprehensive code refactoring with full file outputs
- Lengthy analytical reports without pagination
- Multi-chapter content generation
When Context Size Doesn’t Matter: For isolated tasks under 10,000 tokens (most customer support queries, simple code functions, short-form content), both models perform equivalently. The context advantage only materializes for genuinely large-scale processing needs.
Common mistake: Organizations sometimes pay for Claude’s larger context window without actually needing it. Audit your typical task sizes before assuming you need 1 million tokens—many workflows operate comfortably within GPT-4o’s 128,000-token limit.
How Do Safety and Alignment Features Compare in 2026?

Anthropic’s constitutional AI approach gives Claude 4 Sonnet stronger safety guardrails and more consistent alignment with ethical guidelines, while GPT-4o offers greater flexibility that some organizations prefer for creative applications.
Safety Architecture Differences:
Claude 4 Sonnet implements Anthropic’s constitutional AI methodology, which embeds ethical principles directly into the model’s training process[5]. This results in:
- Reduced harmful outputs: Lower rates of generating biased, toxic, or unsafe content
- Better refusal handling: More graceful decline of inappropriate requests without being overly restrictive
- Consistent policy enforcement: More predictable adherence to content policies across diverse prompts
GPT-4o uses OpenAI’s reinforcement learning from human feedback (RLHF) approach, which provides strong safety but with different characteristics:
- Flexibility in edge cases: Less likely to refuse legitimate requests that superficially resemble policy violations
- Creative freedom: Fewer restrictions on controversial but legal content creation
- Faster policy updates: More rapid adjustment to emerging safety concerns
Enterprise Compliance Considerations:
Organizations in regulated industries (healthcare, finance, legal) increasingly favor Claude 4 Sonnet’s safety focus for:
- HIPAA-compliant healthcare applications: Lower risk of generating inappropriate medical advice
- Financial services: More consistent adherence to regulatory language requirements
- Legal tech: Better handling of confidential information and privilege considerations
- Education: Safer for student-facing applications with stronger content filtering
Bias and Fairness: Both models demonstrate bias reduction compared to earlier generations, but Claude 4 Sonnet shows slightly better performance in fairness benchmarks, particularly for gender and racial bias in professional contexts.
Choose Claude 4 Sonnet if: Your application requires strict safety compliance, operates in regulated industries, or serves vulnerable populations where content safety is paramount.
Choose GPT-4o if: You need maximum creative flexibility, work in entertainment or marketing where edge cases matter, or require rapid adaptation to evolving content policies.
What Are the Best Use Cases for Each Model?
Claude 4 Sonnet and GPT-4o serve distinct enterprise applications based on their respective strengths in technical depth versus creative speed.
Optimal Claude 4 Sonnet Use Cases:
✅ Software Development & Engineering
- Production code generation and review
- Large codebase refactoring
- Complex debugging and root cause analysis
- Technical documentation and API references
✅ Analytical & Research Work
- Legal contract analysis and review
- Financial modeling and business analysis
- Academic research synthesis
- Strategic planning and consulting reports
✅ Long-Form Technical Content
- White papers and technical guides
- System architecture documentation
- Compliance and regulatory documents
- Multi-chapter technical books
✅ Extended Consultation Sessions
- Iterative design processes
- Multi-session project planning
- Complex customer support escalations
- Educational tutoring requiring context retention
Optimal GPT-4o Use Cases:
✅ Creative Content Generation
- Marketing copy and advertising
- Social media content and campaigns
- Product descriptions and branding
- Storytelling and narrative content
✅ High-Volume Applications
- Customer support chatbots (cost-sensitive)
- Content moderation at scale
- Email response automation
- Quick Q&A systems
✅ Rapid Prototyping
- Early-stage product development
- Quick script generation
- Boilerplate code creation
- Brainstorming and ideation
✅ Real-Time Interactions
- Live chat applications
- Voice assistant backends
- Gaming and entertainment
- Interactive educational tools
Hybrid Deployment Strategy: Many organizations implement both models, routing tasks based on complexity and requirements. A typical pattern:
- Triage layer: Simple queries → GPT-4o (faster, cheaper)
- Complex analysis: Technical problems → Claude 4 Sonnet (higher accuracy)
- Creative tasks: Marketing content → GPT-4o (better engagement)
- Safety-critical: Regulated content → Claude 4 Sonnet (stronger guardrails)
This approach optimizes both cost and performance by matching model strengths to specific workload characteristics.
How Do Response Speed and Latency Compare?
GPT-4o delivers faster response times for standard queries, making it preferable for real-time applications, while Claude 4 Sonnet prioritizes thoroughness with slightly higher latency for complex tasks.
Typical Response Time Patterns:
For simple queries (under 1,000 tokens):
- GPT-4o: 1-3 seconds average response time
- Claude 4 Sonnet: 2-4 seconds average response time
For complex analysis (10,000+ tokens):
- GPT-4o: 15-30 seconds
- Claude 4 Sonnet: 20-45 seconds (with extended thinking mode potentially longer)
Streaming Performance: Both models support streaming responses, but GPT-4o typically begins streaming tokens faster, creating a perception of greater responsiveness even when total completion times are similar.
When Speed Matters Most:
- Customer-facing chatbots: Users expect responses within 2-3 seconds
- Real-time coding assistants: IDE integrations benefit from sub-second initial responses
- Voice applications: Conversational AI requires minimal latency for natural dialogue
- High-frequency trading or time-sensitive analysis: Milliseconds can impact business outcomes
When Thoroughness Justifies Slower Responses:
- Code review: Developers prefer comprehensive analysis over speed
- Legal analysis: Accuracy matters more than response time
- Strategic planning: Business decisions benefit from deeper reasoning
- Complex debugging: Finding root causes justifies longer analysis time
Optimization Techniques:
- Pre-warming: Keep API connections active for faster first-token latency
- Caching: Store common responses to eliminate repeated processing
- Parallel processing: Send independent queries simultaneously rather than sequentially
- Prompt optimization: Shorter, clearer prompts reduce processing time for both models
Edge case: Claude 4 Sonnet’s extended thinking mode can add 10-30 seconds for extremely complex reasoning tasks, but this feature can be disabled for applications requiring consistent latency.
FAQ: Claude 4 Sonnet vs GPT-4o Comparison
Which model is better for coding in 2026?
Claude 4 Sonnet is better for professional software development, achieving 72.7% on SWE-bench coding benchmarks with superior debugging, code review, and long codebase maintenance capabilities[5][3]. GPT-4o works better for quick prototypes and boilerplate generation where speed matters more than depth.
How much cheaper is GPT-4o compared to Claude 4 Sonnet?
GPT-4o costs 17% less for input tokens ($2.50 vs $3.00 per million) and 33% less for output tokens ($10.00 vs $15.00 per million)[2][4]. For input-heavy workflows, GPT-4o costs $0.0400 versus Claude’s $0.0540 per operation, while generation-heavy tasks show a larger gap of $0.0775 versus $0.114[4].
What is the context window size difference?
Claude 4 Sonnet accepts 1 million input tokens compared to GPT-4o’s 128,000 tokens—an 8x difference enabling processing of approximately 50,000 lines of code versus 32,000 lines[2][3]. Claude also generates up to 128,000 output tokens while GPT-4o caps at 16,400 tokens[2].
Which model is better for creative writing?
GPT-4o demonstrates superior creativity and humor, making it ideal for marketing copy, social media content, storytelling, and brand voice development[1]. Claude 4 Sonnet excels at structured analytical writing but produces less engaging creative content.
Does Claude 4 Sonnet maintain better context in long conversations?
Yes, Claude 4 Sonnet maintains superior coherence in extended conversations—after 50 back-and-forth exchanges, Claude still remembers discussions from the beginning while GPT-4o tends to lose earlier context[3]. This makes Claude better for multi-session consulting and iterative design processes.
Which model has better safety features?
Claude 4 Sonnet implements Anthropic’s constitutional AI approach with stronger safety guardrails and more consistent alignment with ethical guidelines, making it preferable for regulated industries and safety-critical applications[5]. GPT-4o offers greater flexibility for creative applications while maintaining strong but less restrictive safety measures.
Can I use both models together?
Yes, many organizations implement hybrid deployments routing simple queries to GPT-4o for speed and cost efficiency while directing complex technical analysis to Claude 4 Sonnet for accuracy. This approach optimizes both performance and budget by matching model strengths to specific tasks.
Which model is faster for real-time applications?
GPT-4o delivers faster response times for standard queries (1-3 seconds versus 2-4 seconds for Claude), making it preferable for customer-facing chatbots, real-time coding assistants, and voice applications where latency impacts user experience[3].
How do the models compare for business analysis?
Claude 4 Sonnet excels at analytical and structured business content including financial modeling, strategic planning, and consulting reports with better logical flow and evidence-based reasoning[1]. GPT-4o works better for creative business content like pitch decks and marketing presentations.
Which model should startups choose for limited budgets?
Startups with limited budgets should generally choose GPT-4o for its 17-33% cost advantage, especially for high-volume applications like customer support and content generation[2][4]. Reserve Claude 4 Sonnet for critical technical tasks where accuracy justifies higher costs, or implement a hybrid approach routing by task complexity.
Do both models support the same programming languages?
Both models support all major programming languages, but Claude 4 Sonnet demonstrates stronger performance across languages, particularly for complex frameworks and less common languages. The performance gap is most noticeable in large-scale refactoring and cross-language integration tasks.
Which model is better for legal document analysis?
Claude 4 Sonnet is better for legal document analysis due to its larger context window (processing entire contracts in one pass), superior instruction adherence, and stronger safety features for handling confidential information[1][3]. Its analytical strengths also produce more thorough legal reasoning and risk identification.
Conclusion
The Claude 4 Sonnet vs GPT-4o: Comprehensive Benchmark Comparison in 2026 reveals two powerful AI models optimized for different enterprise needs rather than a simple winner-takes-all scenario. Claude 4 Sonnet’s 72.7% SWE-bench score, 8x larger context window, and superior analytical capabilities make it the clear choice for software development, technical documentation, and safety-critical applications in regulated industries[5][2]. Meanwhile, GPT-4o’s 17-33% cost advantage, faster response times, and creative strengths position it as the optimal solution for marketing content, high-volume customer interactions, and budget-conscious deployments[2][4][1].
Organizations should resist the temptation to standardize on a single model. Instead, implement a strategic hybrid approach that routes tasks based on complexity, safety requirements, and performance needs. Reserve Claude 4 Sonnet for production code, complex analysis, and long-form technical content where accuracy and context retention justify higher costs. Deploy GPT-4o for creative campaigns, customer support, and rapid prototyping where speed and cost efficiency drive business value.
Actionable Next Steps:
- Audit your current AI workloads to identify which tasks require Claude’s analytical depth versus GPT-4o’s creative speed
- Calculate cost implications using your actual token usage patterns across input-heavy versus generation-heavy workflows
- Run pilot tests with both models on representative tasks from your workflow to validate performance assumptions
- Implement routing logic that automatically directs tasks to the appropriate model based on complexity, token requirements, and safety needs
- Monitor performance metrics monthly including accuracy, cost per task, and user satisfaction to optimize your model mix
- Stay informed about updates as both Anthropic and OpenAI continue rapid development cycles throughout 2026
For organizations looking to implement AI solutions strategically, explore comprehensive AI features that support multi-model deployments and intelligent routing. The future of enterprise AI isn’t about choosing one model—it’s about orchestrating the right tool for each specific job.
References
[1] Gpt 4o Vs Claude Sonnet 4 2026 – https://modelpulse.vercel.app/blogs/gpt-4o-vs-claude-sonnet-4-2026
[2] Claude Sonnet 4 Vs Gpt 4o – https://blog.galaxy.ai/compare/claude-sonnet-4-vs-gpt-4o
[3] Claude Vs Gpt 4 For Coding 2026 Comparison 43el – https://dev.to/aristoaistack/claude-vs-gpt-4-for-coding-2026-comparison-43el
[4] Claude Sonnet 4 Vs Gpt 4o Pricing – https://langcopilot.com/claude-sonnet-4-vs-gpt-4o-pricing
[5] Claude 4 – https://www.anthropic.com/news/claude-4
[6] Best Llm For Coding – https://docs.kanaries.net/articles/best-llm-for-coding
Our Fact Checking Process
We prioritize accuracy and integrity in our content. Here's how we maintain high standards:
- Expert Review: All articles are reviewed by subject matter experts.
- Source Validation: Information is backed by credible, up-to-date sources.
- Transparency: We clearly cite references and disclose potential conflicts.
Our Review Board
Our content is carefully reviewed by experienced professionals to ensure accuracy and relevance.
- Qualified Experts: Each article is assessed by specialists with field-specific knowledge.
- Up-to-date Insights: We incorporate the latest research, trends, and standards.
- Commitment to Quality: Reviewers ensure clarity, correctness, and completeness.
Look for the expert-reviewed label to read content you can trust.



