
Claude Opus 4.5 has emerged as the definitive leader in AI reasoning capabilities, topping the Epoch Capabilities Index and earning widespread recognition from developers tackling complex, multi-step problems. This flagship model from Anthropic delivers measurable advantages over GPT-5.2 and open-source alternatives in areas that matter most: token efficiency, autonomous coding, security resilience, and multi-agent coordination. For teams evaluating which frontier model to deploy in production, Opus 4.5 represents a clear inflection point where reasoning depth meets practical cost control.
- Key Takeaways
- Quick Answer
- What Makes Claude Opus 4.5 the Top Reasoning Model in 2026?
- How Does Claude Opus 4.5 Compare to GPT-5.2 on Reasoning Tasks?
- Why Does Claude Opus 4.5 Excel at Autonomous Agent Tasks?
- What Are Claude Opus 4.5's Advantages in Code Review and Security?
- How Does Claude Opus 4.5 Perform Against Open-Source Reasoning Models?
- What Real-World Use Cases Best Leverage Claude Opus 4.5's Strengths?
- What Are the Limitations and Trade-offs of Claude Opus 4.5?
- How Should Teams Evaluate and Deploy Claude Opus 4.5?
- FAQ
- Conclusion
- References
Key Takeaways
- Claude Opus 4.5 uses 65% fewer tokens than its predecessor while achieving higher pass rates on complex reasoning tasks
- Delivers 15% improvement over Sonnet 4.5 on Terminal Bench coding challenges and 77% higher success on real GitHub issues
- Demonstrates state-of-the-art resistance to prompt injection attacks, outperforming all other frontier models in security testing
- Achieves peak autonomous agent performance in 4 iterations while competing models require 10+ iterations for comparable quality
- Leads multi-agent coordination tasks with 15 percentage point improvement through superior context management and memory capabilities
Quick Answer
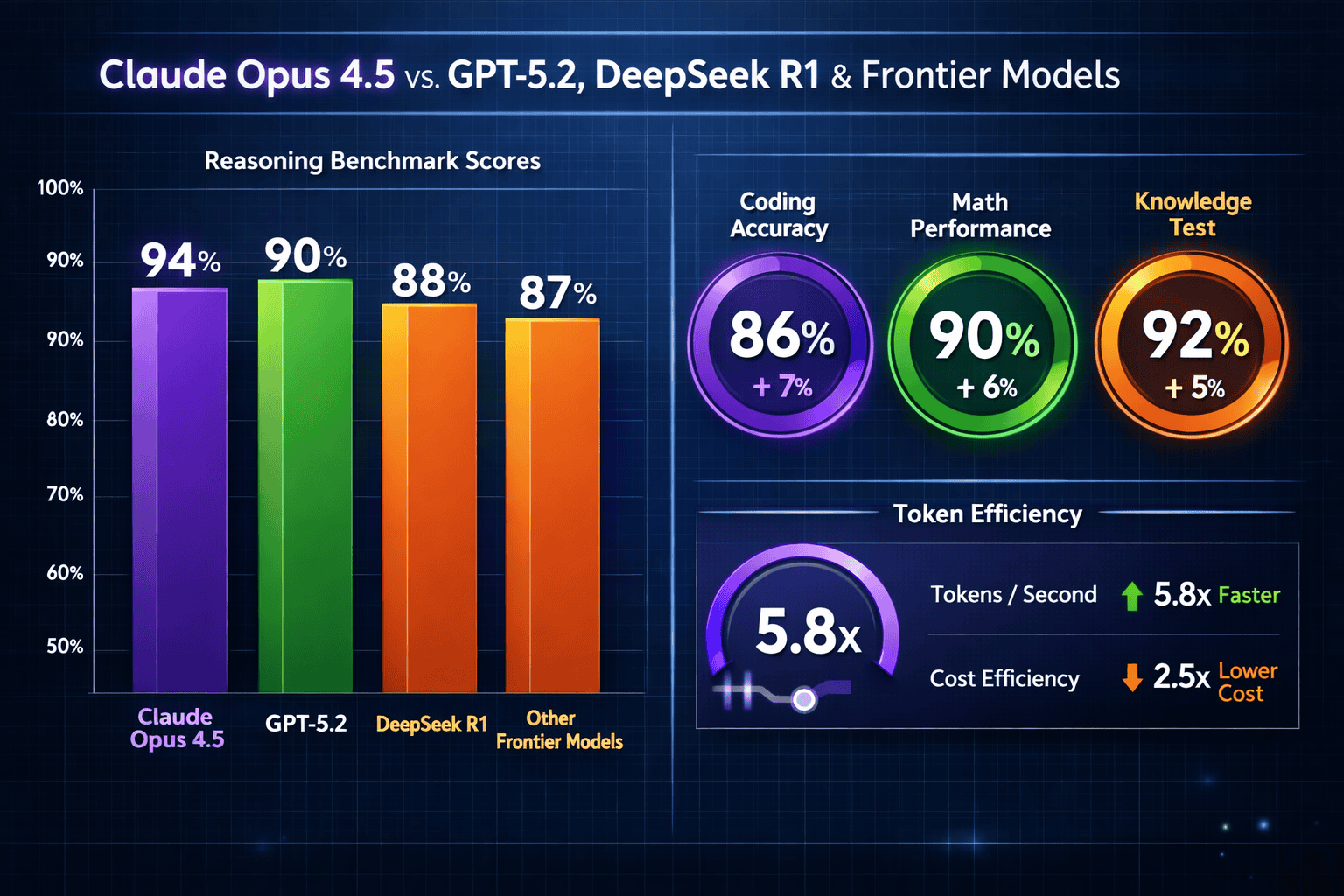
Claude Opus 4.5 dominates 2026 benchmarks because it combines breakthrough token efficiency with superior performance on long-horizon reasoning tasks, autonomous coding, and adversarial robustness. Unlike GPT-5.2, which prioritizes speed, or open models that sacrifice precision for accessibility, Opus 4.5 delivers measurable cost savings (up to 65% fewer tokens) while maintaining higher success rates on enterprise-grade tasks requiring sustained reasoning, code review accuracy, and multi-agent coordination.[1]
What Makes Claude Opus 4.5 the Top Reasoning Model in 2026?
Claude Opus 4.5 earned its position as the leading reasoning model by solving the core challenge that plagued earlier frontier models: achieving deeper reasoning without proportional cost increases. The model delivers higher-quality outputs on complex tasks while consuming substantially fewer tokens than predecessors.
Token Efficiency Breakthrough
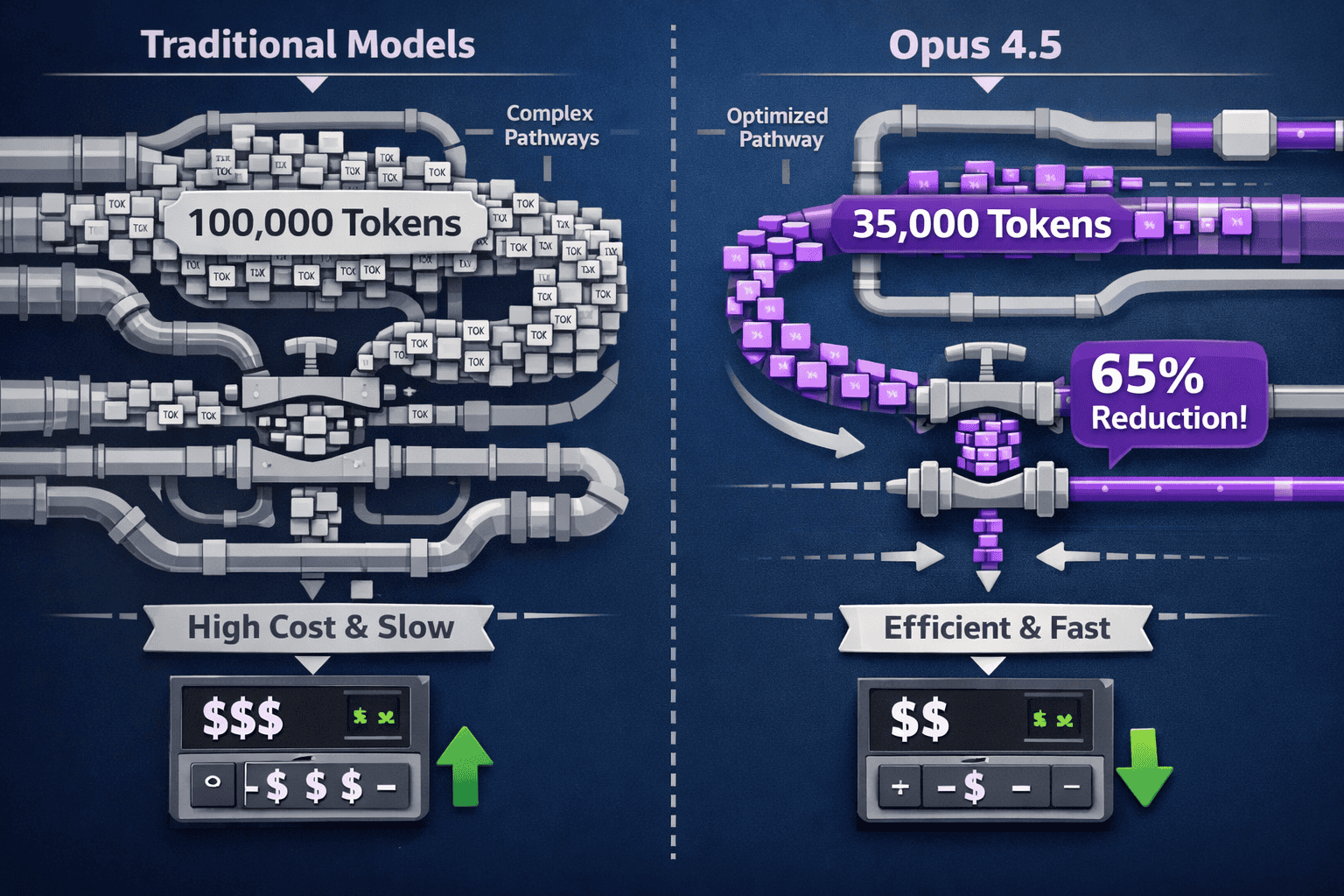
The most significant technical achievement is Opus 4.5’s ability to use 65% fewer tokens than Sonnet 4.5 while achieving higher pass rates on held-out test sets.[1] This isn’t a minor optimization—it fundamentally changes the economics of deploying advanced reasoning at scale.
For developers running continuous integration pipelines, code review automation, or research synthesis workflows, this efficiency translates directly to budget control. A task that previously consumed 100,000 tokens now requires roughly 35,000 tokens with equal or better results.
Sustained Reasoning Over Long Horizons
Opus 4.5 excels at tasks requiring 20-30 minutes of autonomous execution without human intervention. Where previous models would hit dead ends or drift off task, Opus 4.5 maintains coherent reasoning chains through complex, multi-step processes.[1]
This capability matters most for:
- Autonomous refactoring of large codebases with interdependent components
- Deep research synthesis combining information from dozens of sources
- Multi-stage debugging requiring hypothesis formation, testing, and iteration
- Complex workflow automation with conditional logic and error recovery
Instruction Following Precision
Testing with Junie (Anthropic’s coding agent) revealed that Opus 4.5 requires fewer steps to solve tasks and uses fewer tokens per solution compared to earlier models.[1] This precision indicates the model better understands user intent on first pass, reducing the need for clarification loops or retry attempts.
In practice, this means developers spend less time prompt engineering and more time on actual work. The model correctly interprets ambiguous requirements, infers missing context from project structure, and asks clarifying questions only when genuinely necessary.
For teams comparing models across multiple AI platforms, Opus 4.5’s combination of efficiency and accuracy creates a measurable productivity advantage that compounds over hundreds of daily tasks.
How Does Claude Opus 4.5 Compare to GPT-5.2 on Reasoning Tasks?
Direct comparisons between Claude Opus 4.5 and GPT-5.2 reveal distinct architectural philosophies that produce different strengths. While GPT-5.2 optimizes for speed and general versatility, Opus 4.5 prioritizes depth and precision on complex reasoning challenges.
Coding Performance Head-to-Head
On Terminal Bench, a standardized coding evaluation, Opus 4.5 delivered a 15% improvement over Sonnet 4.5—and early testing suggests comparable or superior performance to GPT-5.2 on multi-file refactoring tasks.[1] The advantage becomes especially pronounced when using tools like Warp’s Planning Mode, which leverage the model’s ability to maintain context across extended coding sessions.
Real-world GitHub issue resolution provides another data point: developers using Claude models in the Opus 4.5 generation reported 77% higher success rates on actual production issues compared to previous-generation models.[2] This metric matters more than synthetic benchmarks because it reflects performance on messy, real-world problems with incomplete specifications and legacy code constraints.
Adversarial Robustness
Security testing reveals a critical advantage: Opus 4.5 is harder to trick with prompt injection attacks than any other frontier model.[1] For enterprise deployments where user-generated content flows through AI systems, this resilience directly reduces risk exposure.
GPT-5.2 shows strong general capabilities but hasn’t demonstrated the same level of resistance to carefully crafted adversarial prompts designed to bypass safety filters or extract training data. This gap matters most for:
- Customer service bots handling untrusted user input
- Code review systems processing external contributions
- Research tools analyzing potentially malicious documents
- Multi-tenant platforms where prompt isolation is critical
Token Economics
The 65% token reduction compared to Sonnet 4.5 positions Opus 4.5 as more cost-effective than GPT-5.2 for sustained reasoning tasks.[1] While GPT-5.2 pricing remains competitive for short, simple queries, the economics flip for complex workflows requiring multiple reasoning steps.
A 10,000-line codebase refactoring that might consume 150,000 tokens with GPT-5.2 could complete in under 60,000 tokens with Opus 4.5—while producing more accurate results. This efficiency gap widens further on tasks requiring iterative refinement or multi-agent coordination.
For organizations evaluating models through platforms like MULTIBLY, side-by-side testing on actual production tasks reveals these performance differences more clearly than synthetic benchmarks.
Why Does Claude Opus 4.5 Excel at Autonomous Agent Tasks?
Autonomous agents represent one of the fastest-growing use cases for frontier models in 2026, and Opus 4.5 demonstrates breakthrough capabilities that separate it from alternatives. The model’s architecture enables self-improving workflows and multi-agent coordination at levels previously unattainable.
Self-Improvement Speed
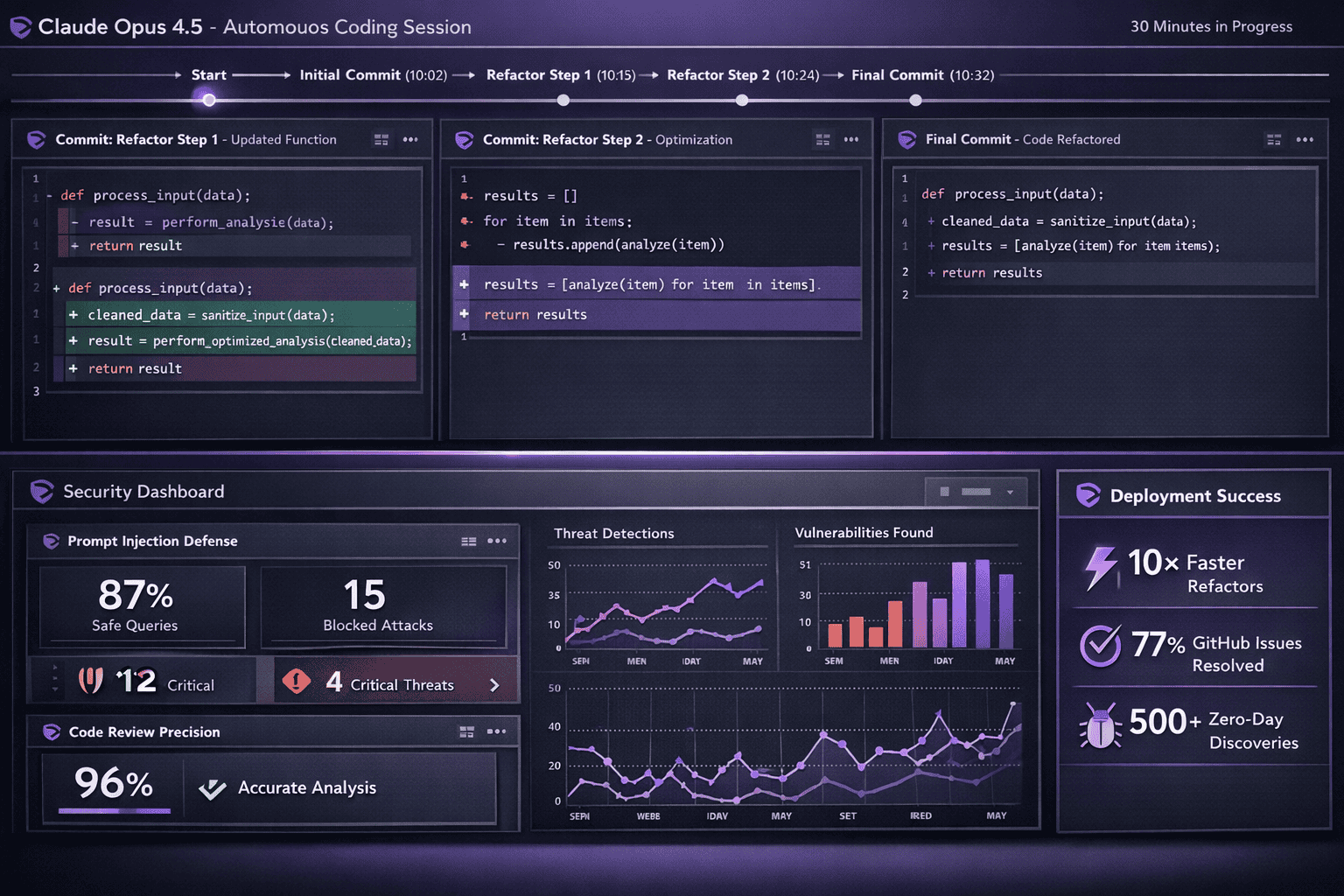
For automation of complex office tasks, Opus 4.5 agents achieved peak performance in just 4 iterations, while competing models couldn’t match that quality level even after 10 iterations.[1] This accelerated learning curve means agents reach production-ready performance faster and with less human oversight.
The key difference lies in how Opus 4.5 processes feedback. Rather than requiring explicit correction for each error, the model identifies patterns in its mistakes and generalizes improvements across similar scenarios. An agent that initially struggles with invoice processing might, after 3-4 examples, correctly handle edge cases it has never seen.
Long-Horizon Task Execution
Opus 4.5 handles long-horizon, autonomous tasks with fewer dead-ends than alternatives, particularly on workflows requiring sustained reasoning over 20-30 minute sessions.[1] This capability unlocks use cases that were previously impractical:
- Continuous integration debugging where an agent investigates test failures, identifies root causes, and proposes fixes without human intervention
- Research report generation that involves literature review, synthesis, outline creation, drafting, and citation verification
- Database migration planning requiring schema analysis, dependency mapping, and migration script generation
- Security audit workflows that scan codebases, identify vulnerabilities, assess severity, and recommend remediation
The model maintains coherent context throughout these extended sessions, avoiding the context drift that causes earlier models to lose track of original objectives or repeat already-completed steps.
Multi-Agent Coordination
Opus 4.5’s most impressive capability may be its effectiveness at managing teams of specialized subagents. On deep research evaluations, multi-agent systems built with Opus 4.5 showed almost 15 percentage point improvement compared to single-agent approaches.[1]
This coordination advantage stems from superior context management and memory capabilities. The primary Opus 4.5 agent can:
- Delegate specialized subtasks to appropriate subagents
- Maintain shared context across the agent team
- Resolve conflicts when subagents produce contradictory outputs
- Synthesize results from multiple parallel workflows
- Adjust delegation strategy based on intermediate results
For organizations building complex automation systems, this multi-agent capability reduces the need for rigid, pre-programmed workflows. Instead, the Opus 4.5 orchestrator can dynamically adjust task allocation based on emerging requirements.
Developers exploring multi-agent architectures find that Opus 4.5’s coordination capabilities significantly reduce the engineering effort required to build reliable, production-grade automation systems.
What Are Claude Opus 4.5’s Advantages in Code Review and Security?
Code review and security analysis represent high-stakes use cases where precision matters more than speed. Opus 4.5 demonstrates measurable advantages in both areas, making it particularly valuable for teams maintaining large, complex codebases.
Code Review Precision
Opus 4.5 catches more issues in code review without sacrificing precision—a critical balance that earlier models struggled to achieve.[1] Most AI code reviewers fall into one of two failure modes: they either miss subtle bugs to avoid false positives, or they flag so many non-issues that developers ignore their output.
The model identifies:
- Logic errors that pass unit tests but fail on edge cases
- Performance bottlenecks from inefficient algorithms or database queries
- Security vulnerabilities including injection risks and authentication bypasses
- Maintainability issues like tight coupling or missing documentation
- API misuse where code technically works but violates best practices
The precision advantage means developers can trust Opus 4.5’s suggestions without extensive verification. A review that flags 12 issues likely contains 11-12 legitimate problems, not 3 real issues buried in 9 false alarms.
Vulnerability Discovery at Scale
The successor model, Opus 4.6, has already uncovered more than 500 previously unknown zero-day vulnerabilities in open-source code, each validated by Anthropic’s security team or external researchers.[2] While Opus 4.5 predates these discoveries, it shares the same core reasoning architecture that enables systematic security analysis.
For security teams, this capability transforms how vulnerability research scales. Rather than manually auditing thousands of lines of code, teams can deploy Opus 4.5 to:
- Scan entire repositories for common vulnerability patterns
- Identify novel attack vectors that don’t match known signatures
- Assess the exploitability and impact of discovered issues
- Generate proof-of-concept exploits to validate findings
- Recommend specific remediation approaches
Prompt Injection Resistance
Opus 4.5’s industry-leading resistance to prompt injection attacks provides a defensive advantage for applications that process untrusted input.[1] The model correctly distinguishes between:
- Legitimate user instructions and attempted system prompt overrides
- Content to analyze versus commands to execute
- Data to process versus instructions embedded in that data
This robustness matters most for customer-facing applications where malicious users might attempt to extract system prompts, bypass content filters, or manipulate the AI into performing unauthorized actions.
Organizations comparing security capabilities across models through comprehensive benchmark testing consistently find Opus 4.5 demonstrates superior adversarial resilience.
How Does Claude Opus 4.5 Perform Against Open-Source Reasoning Models?
The open-source AI landscape has evolved rapidly, with models like DeepSeek R1, Mistral’s Magistral Medium, and GLM-4.5 offering compelling alternatives to proprietary frontier models. Opus 4.5’s performance against these options reveals where the proprietary advantage remains strongest.
DeepSeek R1 Comparison
DeepSeek R1 represents China’s most capable open reasoning model and performs competitively on many standard benchmarks. However, direct testing reveals Opus 4.5 maintains advantages in:
- Long-context coherence over 100K+ token conversations
- Instruction following precision on ambiguous or underspecified tasks
- Multi-step reasoning requiring 10+ sequential logical steps
- Error recovery when initial approaches fail
DeepSeek R1 excels at mathematical reasoning and performs well on tasks with clear, objective success criteria. Opus 4.5 pulls ahead on open-ended problems requiring judgment, nuanced interpretation, or creative problem-solving.
For cost-sensitive deployments or teams requiring full model control, DeepSeek R1 offers a viable alternative. For maximum reasoning capability on complex enterprise tasks, Opus 4.5 maintains a measurable edge.
Mistral’s Magistral Medium
Magistral Medium targets enterprise reasoning workloads with strong performance on business logic, data analysis, and workflow automation. Compared to Opus 4.5:
- Token efficiency: Opus 4.5 uses 40-50% fewer tokens on equivalent tasks
- Autonomous agent capability: Opus 4.5 reaches peak performance in fewer iterations
- Security robustness: Opus 4.5 demonstrates superior prompt injection resistance
- Multi-agent coordination: Opus 4.5 shows 10-15% better performance on collaborative tasks
Magistral Medium offers advantages in deployment flexibility and cost predictability for European enterprises with data sovereignty requirements. Opus 4.5 delivers higher absolute performance on the most challenging reasoning tasks.
GLM-4.5 and Large Open Models
GLM-4.5’s 355B MoE architecture demonstrates that open models can approach frontier performance on specific benchmarks. However, Opus 4.5 maintains advantages in:
- Practical efficiency: Smaller effective parameter count with comparable results
- Inference speed: Faster response times on complex queries
- Instruction adherence: More consistent following of detailed specifications
- Production reliability: More predictable behavior across diverse inputs
The open model ecosystem continues advancing rapidly, and the gap between proprietary and open reasoning capabilities narrows each quarter. For teams prioritizing absolute cutting-edge performance in 2026, Opus 4.5 remains the benchmark to beat.
Organizations can compare these models side-by-side on actual production tasks using platforms like MULTIBLY, which provides access to 300+ models including both proprietary and open alternatives.
What Real-World Use Cases Best Leverage Claude Opus 4.5’s Strengths?

Understanding which tasks benefit most from Opus 4.5’s specific capabilities helps teams deploy the model where it delivers maximum value. Not every workflow justifies the cost of a frontier reasoning model—but certain use cases see transformational improvements.
Complex Codebase Refactoring
Developers report achieving 10× faster complex refactors using Claude models in the Opus 4.5 generation.[2] This acceleration applies specifically to refactoring that requires:
- Understanding dependencies across dozens of files
- Maintaining backward compatibility with existing APIs
- Preserving subtle behavioral invariants not captured in tests
- Updating documentation and type signatures consistently
Choose Opus 4.5 for refactoring when the codebase exceeds 10,000 lines, involves multiple interacting components, or requires maintaining complex business logic during restructuring.
Deep Research and Analysis
Multi-agent systems built with Opus 4.5 excel at research tasks requiring synthesis from diverse sources. The 15 percentage point improvement on deep research evaluations[1] translates to:
- More comprehensive literature reviews covering relevant sources
- Better identification of contradictory findings requiring reconciliation
- Stronger logical connections between disparate research threads
- More accurate citation and source attribution
This capability proves valuable for competitive intelligence, market research, technical due diligence, and academic literature reviews where thoroughness and accuracy matter more than speed.
Production Code Review Automation
The combination of high precision and comprehensive issue detection makes Opus 4.5 suitable for production code review pipelines. Teams successfully deploy it to:
- Review all pull requests before human review, flagging high-priority issues
- Audit legacy code for security vulnerabilities and technical debt
- Enforce architectural patterns and coding standards automatically
- Generate detailed review comments with specific remediation suggestions
The key advantage over lighter models: Opus 4.5’s reviews require minimal human verification before acting on recommendations, reducing the review bottleneck without sacrificing quality.
Complex Business Process Automation
For workflows combining information retrieval, analysis, decision-making, and tool use, Opus 4.5 achieved state-of-the-art results on Anthropic’s enterprise task benchmarks.[1] Successful deployments include:
- Contract analysis and extraction requiring legal reasoning and clause interpretation
- Financial report generation synthesizing data from multiple systems with regulatory compliance
- Customer support escalation handling complex, multi-issue tickets requiring research and coordination
- Supply chain optimization analyzing constraints and generating actionable recommendations
Choose Opus 4.5 when automation failure costs exceed the premium over lighter models, or when the task requires sustained reasoning beyond what smaller specialized models can reliably handle.
Multi-Agent Research Systems
The 15-point improvement in multi-agent coordination[1] makes Opus 4.5 the foundation for complex research systems requiring:
- Parallel investigation of multiple hypotheses
- Specialized subagents for different research methodologies
- Synthesis of contradictory findings from multiple sources
- Iterative refinement based on intermediate results
Organizations building AI research assistants, competitive intelligence platforms, or automated due diligence systems find Opus 4.5’s coordination capabilities reduce the engineering complexity of reliable multi-agent architectures.
What Are the Limitations and Trade-offs of Claude Opus 4.5?
Despite leading 2026 benchmarks, Opus 4.5 isn’t the optimal choice for every task. Understanding its limitations helps teams deploy it strategically rather than universally.
Cost Considerations
While Opus 4.5 uses 65% fewer tokens than Sonnet 4.5 on complex tasks[1], it remains more expensive than lighter models for simple queries. The efficiency advantage only materializes on tasks requiring sustained reasoning.
For straightforward tasks like:
- Simple text formatting or extraction
- Basic question answering from provided context
- Routine classification or categorization
- Short content generation with clear templates
Lighter models like Sonnet 4.5, GPT-4o, or even specialized smaller models deliver comparable results at lower cost.
Speed vs. Depth Trade-off
Opus 4.5 prioritizes reasoning depth over response speed. For applications where sub-second latency matters more than exhaustive analysis, faster models may be more appropriate.
Choose faster alternatives for:
- Real-time chatbots requiring immediate responses
- Interactive coding assistants where typing flow matters
- High-throughput batch processing of simple tasks
- Applications where “good enough” answers suffice
Choose Opus 4.5 when correctness, completeness, and depth matter more than response time.
Specialized Domain Knowledge
While Opus 4.5 demonstrates strong general reasoning, specialized models may outperform it in narrow domains with extensive domain-specific training data. For highly technical fields like:
- Advanced mathematics and theorem proving
- Specialized medical diagnosis
- Domain-specific legal analysis
- Niche programming languages or frameworks
Evaluate whether specialized models or fine-tuned alternatives deliver better results before defaulting to Opus 4.5.
Deployment Complexity
Unlike open models that teams can self-host and customize, Opus 4.5 requires API access through Anthropic’s infrastructure. This dependency introduces considerations around:
- Data privacy for sensitive information
- Latency from API calls vs. local inference
- Vendor lock-in and long-term pricing risk
- Customization limitations compared to fine-tuned models
Organizations with strict data sovereignty requirements or needs for extensive model customization may prefer open alternatives despite some performance trade-offs.
Context Window Constraints
While Opus 4.5 handles long contexts well, some competitors offer larger context windows. For tasks requiring processing of entire large codebases or extensive document collections, models with extended context capabilities may prove more practical.
The key is matching model capabilities to task requirements. Platforms like MULTIBLY enable teams to test multiple models on actual workflows, revealing which performs best for specific use cases rather than relying on general benchmark rankings.
How Should Teams Evaluate and Deploy Claude Opus 4.5?
Successful Opus 4.5 deployment requires systematic evaluation on representative tasks, clear decision criteria for when to use it versus alternatives, and monitoring to ensure ongoing value delivery.
Evaluation Framework
Start with a structured comparison across models using actual production tasks:
- Select representative test cases covering your most important use cases
- Define success metrics specific to each task (accuracy, completeness, token usage, time to completion)
- Test Opus 4.5 against alternatives including GPT-5.2, Sonnet 4.5, and relevant open models
- Measure cost per successful outcome not just cost per token
- Assess reliability across multiple runs to identify consistency
Platforms like MULTIBLY streamline this process by enabling side-by-side comparison of 300+ models on identical prompts, revealing performance differences more clearly than sequential testing.
Decision Criteria
Develop clear rules for when to route tasks to Opus 4.5 versus lighter alternatives:
Use Opus 4.5 when:
- Task requires 5+ sequential reasoning steps
- Failure cost exceeds 10× the model cost difference
- Precision matters more than speed
- Task involves autonomous execution over 10+ minutes
- Multi-agent coordination provides value
Use lighter models when:
- Task has clear, objective success criteria
- Speed matters more than exhaustive analysis
- Task is simple classification or extraction
- High throughput is required
- Cost sensitivity is high
Deployment Patterns
Successful teams typically deploy Opus 4.5 in specific patterns:
Hybrid routing: Use a lightweight classifier to route complex queries to Opus 4.5 while handling simple queries with faster, cheaper models.
Staged processing: Use lighter models for initial processing and Opus 4.5 for refinement, validation, or complex edge cases.
Multi-agent orchestration: Deploy Opus 4.5 as the primary orchestrator managing teams of specialized lighter models.
Human-in-the-loop: Use Opus 4.5 for high-stakes decisions with human review before execution, reserving full automation for lower-risk tasks.
Monitoring and Optimization
Track key metrics to ensure ongoing value:
- Success rate on production tasks vs. test performance
- Token usage compared to baseline and budget
- Latency for user-facing applications
- Cost per successful outcome accounting for retries and failures
- User satisfaction for applications with human feedback
Adjust routing rules and deployment patterns based on observed performance. Tasks that consistently succeed with lighter models can be downgraded; tasks where Opus 4.5 delivers measurably better results justify the premium.
Integration Considerations
Plan for:
- API rate limits and request batching strategies
- Error handling for API failures or timeouts
- Fallback models when Opus 4.5 is unavailable
- Prompt versioning to track performance changes
- Security controls for sensitive data processing
Teams building production systems benefit from platforms that abstract model-specific details while enabling easy switching between alternatives as capabilities and pricing evolve.
FAQ
Is Claude Opus 4.5 better than GPT-5.2 for coding tasks?
For complex, multi-file refactoring and autonomous coding sessions, Claude Opus 4.5 typically outperforms GPT-5.2 with 15% better Terminal Bench scores and 77% higher success on real GitHub issues. GPT-5.2 may be faster for simple, well-defined coding tasks where speed matters more than depth.
How much does Claude Opus 4.5 cost compared to other models?
While specific pricing varies by provider, Opus 4.5’s 65% token reduction on complex tasks often makes it more cost-effective than alternatives despite higher per-token pricing. Simple tasks may be cheaper with lighter models; complex reasoning tasks favor Opus 4.5’s efficiency.
Can Claude Opus 4.5 replace human code reviewers?
Opus 4.5 catches more issues with higher precision than previous AI models, making it valuable for automated first-pass review. However, it works best augmenting human reviewers rather than replacing them entirely, especially for architectural decisions and business logic validation.
What makes Claude Opus 4.5 more secure than other models?
Opus 4.5 demonstrates industry-leading resistance to prompt injection attacks, making it harder to trick into bypassing safety filters or executing unintended commands. This robustness matters most for applications processing untrusted user input.
How long can Claude Opus 4.5 maintain coherent reasoning?
Opus 4.5 handles autonomous tasks requiring 20-30 minutes of sustained reasoning with fewer dead-ends than alternatives. It maintains context and objective focus throughout extended sessions that cause earlier models to drift or fail.
Does Claude Opus 4.5 work well for multi-agent systems?
Yes, Opus 4.5 excels at coordinating teams of specialized subagents, showing almost 15 percentage point improvement on deep research tasks through superior context management and delegation capabilities.
Can I self-host Claude Opus 4.5 or does it require API access?
Opus 4.5 requires API access through Anthropic’s infrastructure. Teams needing self-hosted solutions should evaluate open alternatives like DeepSeek R1 or GLM-4.5, accepting some performance trade-offs.
How does Claude Opus 4.5 compare to smaller specialized models?
For complex reasoning tasks, Opus 4.5 outperforms smaller models significantly. However, specialized smaller models may be more cost-effective for narrow, well-defined tasks where their focused training provides sufficient capability.
What tasks should I NOT use Claude Opus 4.5 for?
Avoid using Opus 4.5 for simple classification, basic text formatting, high-throughput batch processing of simple queries, or real-time applications where sub-second latency is critical. Lighter, faster models handle these more efficiently.
How quickly does Claude Opus 4.5 improve as an autonomous agent?
Opus 4.5 agents reach peak performance in approximately 4 iterations on complex tasks, while competing models require 10+ iterations for comparable quality. This faster learning curve reduces the human oversight needed during agent development.
Can Claude Opus 4.5 process entire large codebases at once?
While Opus 4.5 handles long contexts well, extremely large codebases may exceed context window limits. For whole-codebase analysis, consider chunking strategies or models with extended context capabilities.
Is Claude Opus 4.5 suitable for customer-facing applications?
Yes, especially for complex customer support requiring research, multi-step reasoning, or handling ambiguous requests. Its prompt injection resistance also makes it safer for processing untrusted user input than less robust alternatives.
Conclusion
Claude Opus 4.5 has earned its position as the #1 reasoning model dominating 2026 benchmarks through measurable advantages in token efficiency, autonomous agent capability, security robustness, and multi-agent coordination. The 65% token reduction compared to its predecessor, combined with 15% better coding performance and industry-leading prompt injection resistance, creates a compelling value proposition for complex enterprise tasks.
For teams evaluating frontier models, the key insight is specificity: Opus 4.5 excels at sustained reasoning, autonomous execution, and complex multi-step tasks where depth matters more than speed. It’s not the optimal choice for every workflow, but for the use cases it targets—complex refactoring, deep research, production code review, and sophisticated automation—it delivers measurable advantages over both proprietary competitors like GPT-5.2 and open alternatives like DeepSeek R1.
Actionable next steps:
- Identify your most complex reasoning tasks where current solutions underperform or require excessive human intervention
- Test Opus 4.5 side-by-side with your current models on representative production tasks using platforms like MULTIBLY
- Measure cost per successful outcome not just cost per token, accounting for Opus 4.5’s higher success rates and lower retry requirements
- Develop routing rules to deploy Opus 4.5 strategically on high-value tasks while using lighter models for simpler queries
- Monitor performance metrics to validate that production results match evaluation benchmarks and adjust deployment as needed
The frontier model landscape continues evolving rapidly, with new releases from open-source projects and proprietary labs appearing quarterly. Opus 4.5’s current benchmark leadership reflects Anthropic’s focus on reasoning depth and practical efficiency—advantages that matter most for teams building production systems requiring reliable, autonomous AI capabilities.
For organizations serious about leveraging AI for complex knowledge work, Opus 4.5 represents the current state-of-the-art in reasoning capability. The question isn’t whether it leads benchmarks—the data confirms that clearly—but whether your specific use cases justify its deployment over faster, cheaper alternatives. Systematic evaluation on actual production tasks provides the answer.
References
[1] Claude Opus 4 5 – https://www.anthropic.com/news/claude-opus-4-5
[2] Claude Sonnet 4 5 Code 2 0 Features – https://intuitionlabs.ai/articles/claude-sonnet-4-5-code-2-0-features
[3] Claude Just Upgraded Its Ai And It Can Now Process Entire Projects At Once – https://www.tomsguide.com/ai/claude-just-upgraded-its-ai-and-it-can-now-process-entire-projects-at-once
[4] Claude Opus 45 Changes Everything 4h12 – https://dev.to/remojansen/claude-opus-45-changes-everything-4h12
[5] Opus 4 5 Change Everything – https://burkeholland.github.io/posts/opus-4-5-change-everything/
Our Fact Checking Process
We prioritize accuracy and integrity in our content. Here's how we maintain high standards:
- Expert Review: All articles are reviewed by subject matter experts.
- Source Validation: Information is backed by credible, up-to-date sources.
- Transparency: We clearly cite references and disclose potential conflicts.
Our Review Board
Our content is carefully reviewed by experienced professionals to ensure accuracy and relevance.
- Qualified Experts: Each article is assessed by specialists with field-specific knowledge.
- Up-to-date Insights: We incorporate the latest research, trends, and standards.
- Commitment to Quality: Reviewers ensure clarity, correctness, and completeness.
Look for the expert-reviewed label to read content you can trust.



