
When enterprise teams need AI that can actually reason through complex problems—not just generate plausible-sounding text—the choice in 2026 comes down to two clear leaders: Claude Opus 4.5 and GPT-5.2. Both models dominate the reasoning benchmarks that matter for real business work, but they take fundamentally different approaches. Claude Opus 4.5 holds the #1 spot for pure reasoning consistency and reliability, while GPT-5.2 offers a dual-model system optimized for speed and cost efficiency. The question isn’t which is “better” in absolute terms—it’s which reasoning architecture fits your specific enterprise workload, budget constraints, and performance requirements.
Understanding the Claude Opus 4.5 vs GPT-5.2: The 2026 Reasoning Kings for Enterprise Problem-Solving comparison requires looking beyond marketing claims and into actual benchmark performance, real-world execution speeds, cost structures, and deployment scenarios. This guide breaks down the technical capabilities, pricing economics, and practical use cases where each model excels, giving enterprise decision-makers the clarity needed to choose the right AI reasoning engine for their teams.
- Key Takeaways
- Quick Answer
- What Makes Claude Opus 4.5 and GPT-5.2 the 2026 Reasoning Kings?
- How Do Claude Opus 4.5 and GPT-5.2 Compare on Enterprise Reasoning Benchmarks?
- What Are the Actual Costs of Running Claude Opus 4.5 vs GPT-5.2 in Production?
- Which Model Wins for Complex Coding and Software Development Tasks?
- How Do Context Windows and Output Limits Impact Enterprise Use Cases?
- What Unique Capabilities Differentiate Claude Opus 4.5 from GPT-5.2?
- When Should Enterprises Choose Claude Opus 4.5 Over GPT-5.2?
- When Does GPT-5.2 Provide Better Value for Enterprise Teams?
- How Do These Models Compare to Other Enterprise AI Options in 2026?
- What Are the Implementation and Integration Considerations?
- Frequently Asked Questions
- Conclusion
- References
Key Takeaways
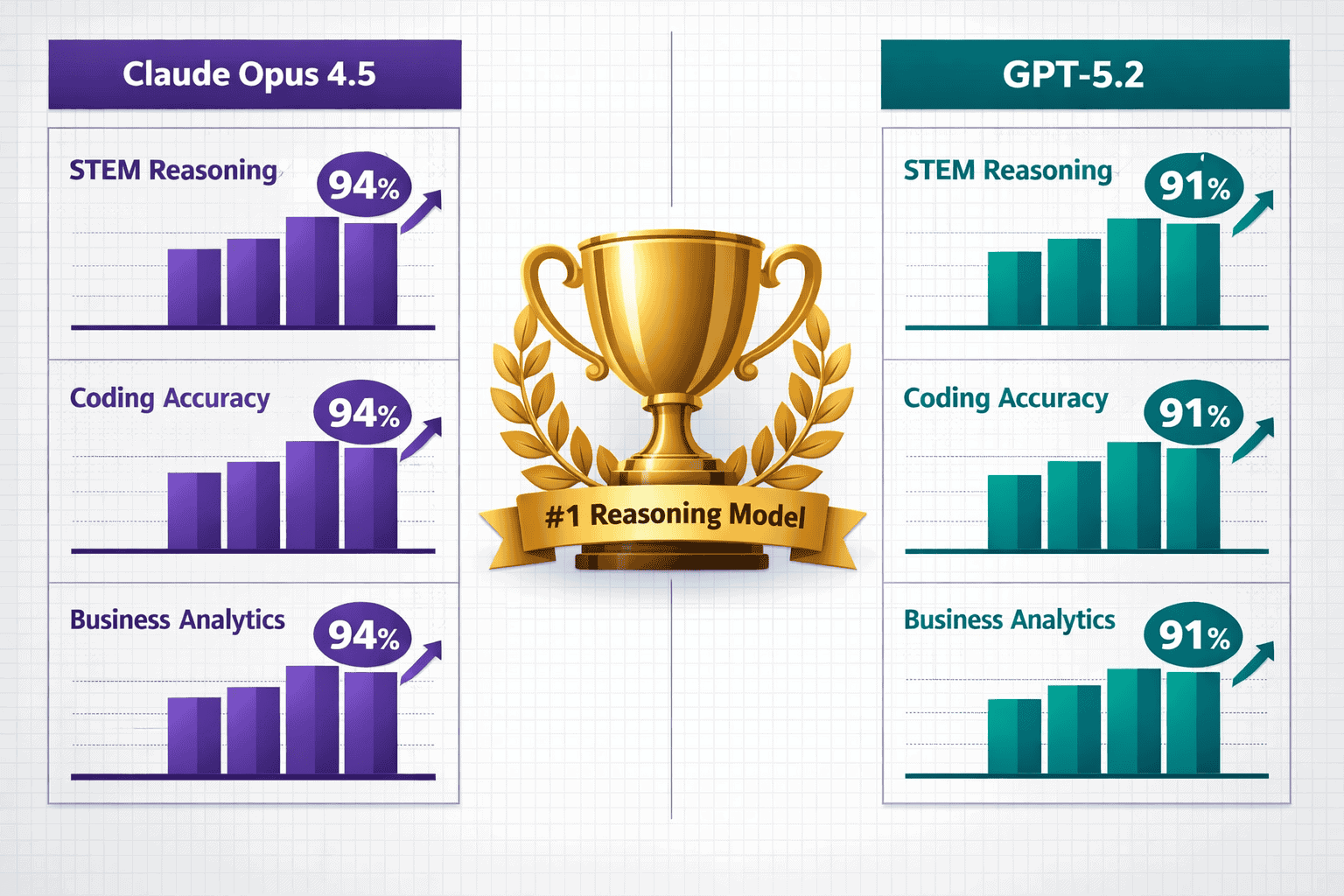
- Claude Opus 4.5 leads in reasoning reliability: Achieves the fastest execution times for complex coding tasks (7 minutes 50 seconds vs 20+ minutes for GPT-5.2 Codex) and ships working results with superior consistency[3]
- GPT-5.2 wins on cost efficiency: Offers 2.9x lower input pricing ($1.75/MTok vs $5.00/MTok) and 1.8x lower output costs, making it the better choice for high-volume enterprise workloads[2]
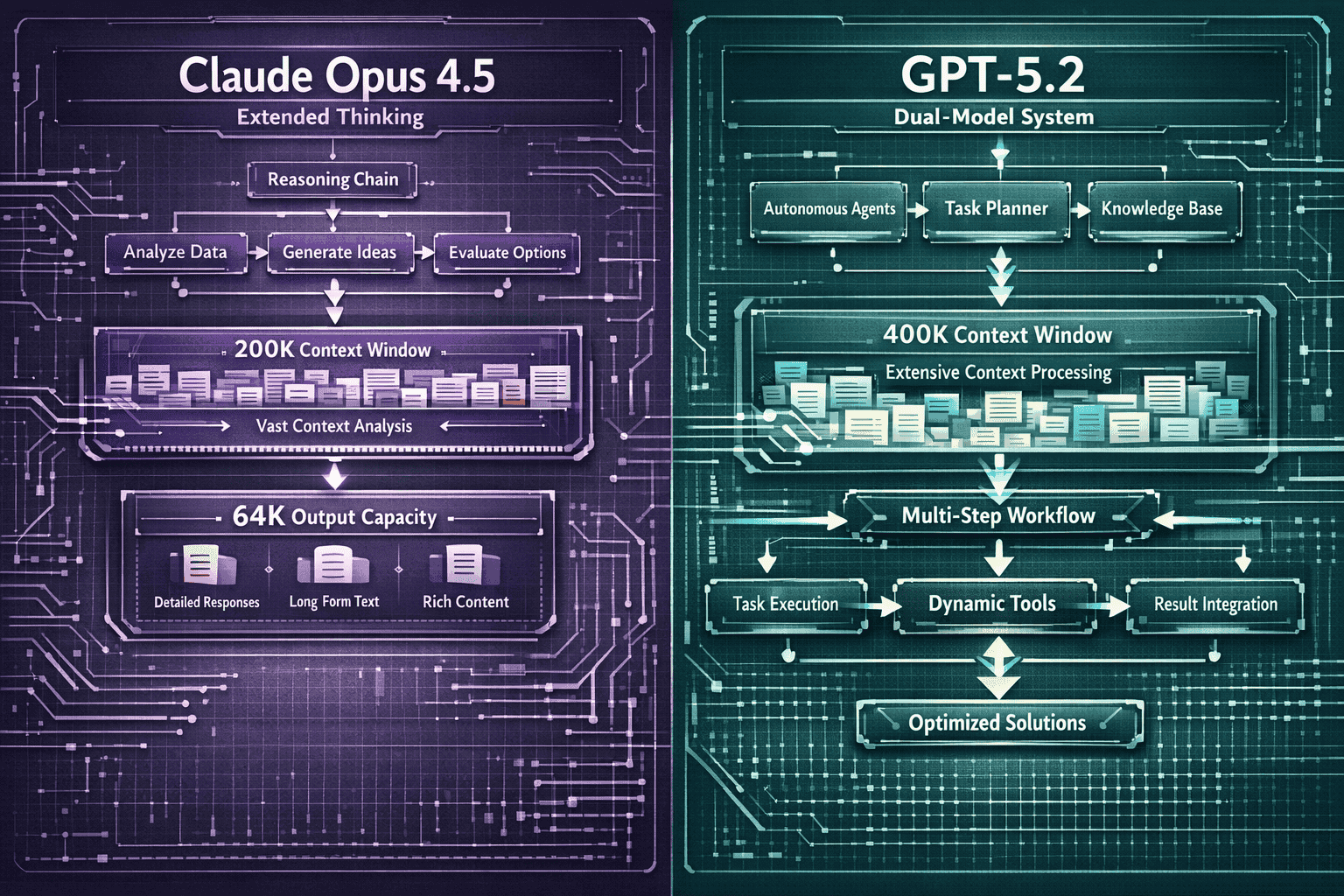
- Context window advantage goes to GPT-5.2: The Codex variant provides 400K tokens (approximately 600 A4 pages) compared to Claude’s 200K tokens, critical for long-document processing[4]
- Output capacity favors Claude: 64K token maximum output versus GPT-5.2’s 32K limit enables longer, more comprehensive analytical reports and code generation[1]
- Architectural differences matter: Claude excels at visible reasoning chains and extended thinking, while GPT-5.2 optimizes for agentic workflows and autonomous multi-step tasks[1]
- Mission-critical deployments lean Claude: For production features in large codebases where reliability trumps cost, Claude Opus 4.5 is the safest enterprise choice[3]
- Cost-conscious teams prefer GPT-5.2: Excellent performance at significantly lower operational expenses makes it ideal for scaling AI across departments[5]
- Neither replaces human oversight: Both models remain supplementary tools requiring review for large-scale production deployments[3]
- MULTIBLY enables direct comparison: Access both models side-by-side through one platform to test which performs better for your specific enterprise use cases
Quick Answer
Claude Opus 4.5 and GPT-5.2 represent the two dominant approaches to enterprise AI reasoning in 2026. Claude Opus 4.5 holds the #1 position for reasoning consistency, execution speed on complex tasks, and reliability in mission-critical deployments—though at 2-3x higher costs. GPT-5.2 offers a compelling alternative with excellent reasoning performance, larger context windows (400K vs 200K tokens), and significantly lower pricing that makes it ideal for cost-conscious enterprises scaling AI across multiple departments. The choice depends on whether your priority is maximum reliability (Claude) or optimal cost-performance balance (GPT-5.2).
What Makes Claude Opus 4.5 and GPT-5.2 the 2026 Reasoning Kings?
Claude Opus 4.5 and GPT-5.2 have earned their “reasoning kings” designation by fundamentally changing how AI handles complex analytical tasks that require multi-step logical thinking, not just pattern matching. Both models excel at STEM problem-solving, advanced coding with architectural decision-making, and business analytics that demand understanding cause-and-effect relationships across large datasets.
The key difference lies in their reasoning architectures. Claude Opus 4.5 implements extended thinking capabilities with visible reasoning chains—you can actually see the model working through problems step-by-step before delivering answers[1]. This transparency makes it particularly valuable for enterprise scenarios where understanding the AI’s decision-making process matters as much as the final output.
GPT-5.2 takes a different approach with its dual-model system. The standard variant optimizes for speed and cost efficiency, while the Codex variant adds explicit reasoning-heavy configurations for complex technical tasks[3]. This flexibility lets enterprises choose the right performance-cost tradeoff for each specific workload.
Benchmark performance tells the real story:
- Both models consistently outperform previous-generation AI on STEM reasoning benchmarks
- Claude Opus 4.5 demonstrates superior consistency across diverse task types
- GPT-5.2 Codex delivers thorough architectural decisions when processing time isn’t the primary constraint
- Neither model shows the reasoning failures common in earlier GPT-4 or Claude 3 variants
For enterprise teams evaluating these models, the “reasoning king” designation means both can handle tasks that would have required human experts just 18 months ago. The practical question becomes which reasoning approach—Claude’s transparent extended thinking or GPT-5.2’s flexible dual-system—better matches your team’s specific needs.
Organizations using platforms like MULTIBLY can test both models side-by-side on their actual enterprise workloads before committing to one approach, a critical capability given the substantial cost differences between the two options.
How Do Claude Opus 4.5 and GPT-5.2 Compare on Enterprise Reasoning Benchmarks?
Claude Opus 4.5 consistently edges out GPT-5.2 on the reasoning benchmarks that matter most for enterprise decision-making, though the margins are narrower than many assume. In practical coding tasks—a reliable proxy for complex reasoning ability—Claude completed feature implementation in approximately 7 minutes 50 seconds, while GPT-5.2 Codex (high) required 20-26 minutes for comparable work[3].
The speed difference doesn’t mean GPT-5.2 reasons poorly. The longer processing time reflects its explicit reasoning-heavy configuration, which prioritizes thoroughness over velocity. Reviewers noted that when GPT-5.2 Codex completes tasks, the code quality and architectural decisions are comprehensive and well-considered[3].
Key benchmark differentiators:
- Consistency: Claude Opus 4.5 “shipped working results for both tasks” in real-world testing, demonstrating higher reliability across diverse problem types[3]
- UI polish: Claude-generated interfaces showed superior attention to detail and user experience considerations
- Reasoning transparency: Claude’s visible thinking chains let enterprise teams verify the logic behind recommendations
- Completion rates: Claude maintained higher success rates on first-attempt task completion without requiring iterative refinement
For STEM reasoning specifically, both models handle advanced mathematics, physics problem-solving, and scientific analysis at levels that would have been impossible for AI systems even 12 months ago. The practical difference shows up more in speed and consistency than in raw capability.
Business analytics performance:
When processing complex business scenarios requiring multi-variable analysis, both models excel but with different strengths. Claude Opus 4.5 tends to deliver faster insights with clearer reasoning chains, making it easier for non-technical stakeholders to understand the AI’s recommendations. GPT-5.2 provides more exhaustive analysis when configured for deep reasoning, though this thoroughness comes with longer processing times.
The benchmark comparison ultimately reveals that Claude Opus 4.5 holds the #1 reasoning spot not through dramatic superiority, but through consistent edge advantages in speed, reliability, and practical usability for enterprise teams who need answers they can trust and implement quickly. For organizations exploring enterprise AI adoption in 2026, these benchmark differences translate directly to team productivity and deployment confidence.
What Are the Actual Costs of Running Claude Opus 4.5 vs GPT-5.2 in Production?
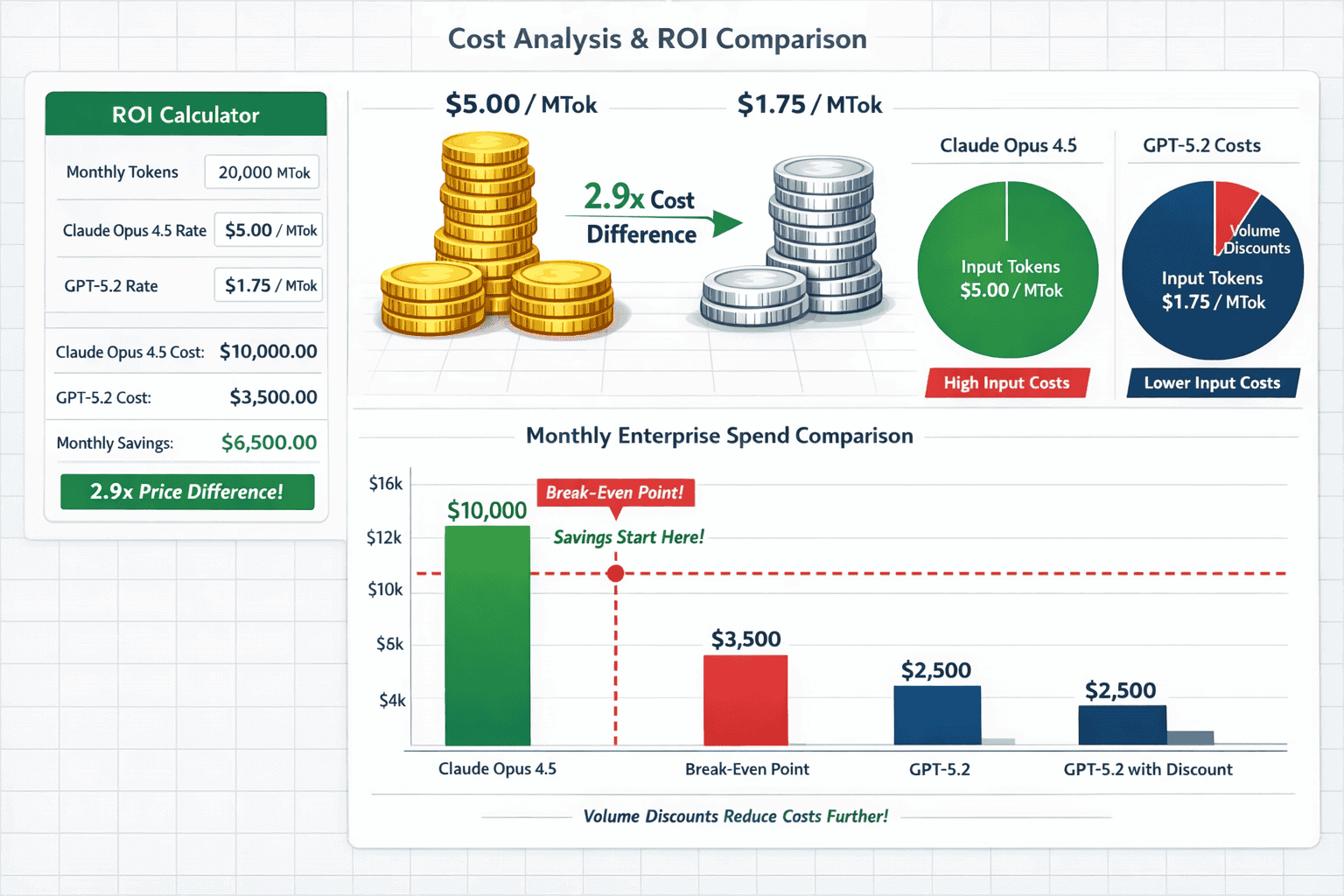
The pricing gap between Claude Opus 4.5 and GPT-5.2 creates a 2-3x cost difference that significantly impacts enterprise AI budgets. Claude Opus 4.5 costs $5.00 per million input tokens and $25.00 per million output tokens, while GPT-5.2 (standard variant) runs at $1.75 per million input tokens and $14.00 per million output tokens[2].
Breaking down the cost multipliers:
- Input processing: Claude is approximately 2.9x more expensive
- Output generation: Claude is approximately 1.8x more expensive
- For typical enterprise workloads with balanced input/output ratios, expect Claude to cost 2-2.5x more than GPT-5.2
These aren’t trivial differences when scaling AI across departments. A team processing 100 million tokens monthly would pay roughly $15,000 for Claude Opus 4.5 versus $6,000-7,000 for GPT-5.2—a $8,000-9,000 monthly difference per team.
Real-world cost scenarios:
| Use Case | Monthly Token Volume | Claude Opus 4.5 Cost | GPT-5.2 Cost | Monthly Savings (GPT) |
|---|---|---|---|---|
| Code review automation | 50M input / 20M output | $7,500 | $2,675 | $4,825 |
| Document analysis | 200M input / 50M output | $21,250 | $7,500 | $13,750 |
| Customer support reasoning | 100M input / 80M output | $7,000 | $2,895 | $4,105 |
| Business analytics | 75M input / 30M output | $4,125 | $1,731 | $2,394 |
The cost equation changes when factoring in reliability and execution speed. If Claude Opus 4.5 completes tasks in 7-8 minutes that take GPT-5.2 Codex 20-26 minutes, the faster model reduces developer waiting time and enables higher throughput[3]. For teams where developer time costs $100-200 per hour, the time savings can offset the higher token costs.
Hidden cost factors:
- Iteration costs: If GPT-5.2 requires more back-and-forth refinement to reach production quality, the lower per-token cost advantage shrinks
- Error correction: Claude’s higher reliability means fewer failed outputs that need regeneration, reducing waste
- Context window efficiency: GPT-5.2’s larger 400K context window can reduce the need for multiple API calls on long documents, improving cost efficiency[4]
For mission-critical production deployments where a single error could cause significant business impact, Claude Opus 4.5’s higher costs represent insurance against reliability issues. As reviewers concluded, it’s “the safest pick for real ‘ship a feature in a big repo’ work”[3].
For cost-conscious enterprises prioritizing value and scaling AI across multiple use cases, GPT-5.2 offers the best balance—excellent performance at significantly lower operational expenses that make broader AI adoption financially feasible[5]. Teams can explore both options through platforms like MULTIBLY’s pricing to access both models without separate subscriptions.
Which Model Wins for Complex Coding and Software Development Tasks?
Claude Opus 4.5 takes the clear lead for complex coding and software development work where speed, reliability, and production-ready output matter most. In head-to-head testing on real-world feature implementation, Claude completed tasks in approximately 7 minutes 50 seconds compared to GPT-5.2 Codex’s 20-26 minutes—a 2.5-3x speed advantage that directly impacts developer productivity[3].
The speed difference alone doesn’t tell the full story. Reviewers specifically noted that Claude Opus 4.5 “shipped working results for both tasks” with superior UI polish and fewer bugs requiring fixes[3]. This reliability means developers spend less time debugging AI-generated code and more time on higher-value architectural decisions.
Claude’s coding advantages:
- Faster execution: 7-8 minute completion times for complex features versus 20+ minutes for GPT-5.2 Codex
- Higher consistency: Working code on first attempt more frequently
- Better UI/UX decisions: Superior attention to interface details and user experience
- Extended thinking visibility: Developers can see the reasoning behind architectural choices
- 64K output capacity: Longer code generation without truncation[1]
GPT-5.2 Codex brings its own strengths, particularly for teams that prioritize thoroughness over speed. The longer processing time reflects explicit reasoning configurations that produce well-considered architectural decisions and comprehensive code documentation[3]. When GPT-5.2 Codex completes a task, the code quality is excellent—it just takes longer to get there.
GPT-5.2’s coding strengths:
- Larger context window: 400K tokens means it can process entire large codebases for better context awareness[4]
- Thorough documentation: More comprehensive code comments and explanations
- Lower costs: 2-3x cheaper for high-volume code generation workloads[2]
- Agentic workflows: Better for multi-step autonomous coding tasks that don’t require immediate results
The verdict for different coding scenarios:
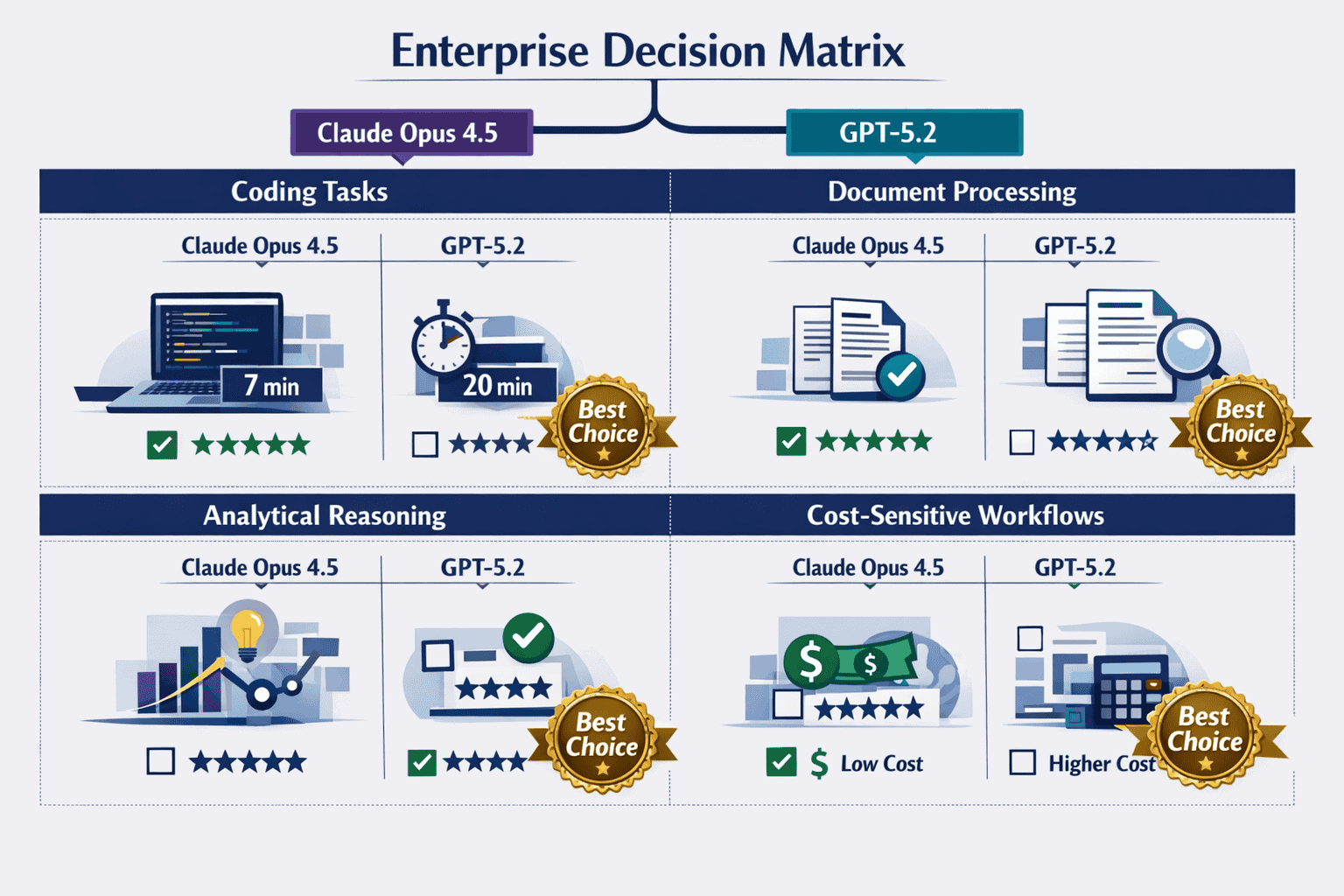
Choose Claude Opus 4.5 when:
- Shipping production features in large repositories where reliability is critical
- Developer time is expensive and waiting 20+ minutes for code generation hurts productivity
- UI/UX quality matters and you need polished, user-ready interfaces
- You need to see the AI’s reasoning process for complex architectural decisions
Choose GPT-5.2 when:
- Processing entire large codebases that exceed 200K token context limits
- Cost efficiency matters more than completion speed for your budget constraints
- Running autonomous coding agents that work in the background without immediate human review
- Generating extensive documentation alongside code
For teams serious about AI-assisted development, the practical recommendation is to use both models for different purposes. Claude for critical path features that need to ship quickly and reliably, GPT-5.2 for background tasks, documentation, and cost-sensitive workloads. Platforms like MULTIBLY make this multi-model approach practical by providing access to both through a single subscription.
The best AI model for coding in 2026 depends on your specific workflow, but for high-stakes production development, Claude Opus 4.5’s speed and reliability advantages make it the safer enterprise choice[3].
How Do Context Windows and Output Limits Impact Enterprise Use Cases?
Context windows and output limits create hard constraints that determine which enterprise use cases each model can actually handle. GPT-5.2 Codex provides a substantially larger context window of 400K tokens (approximately 600 A4 pages) compared to Claude Opus 4.5’s 200K tokens, making it the clear winner for long-document processing and large codebase analysis[4].
The 2x context window advantage means GPT-5.2 can process entire technical documentation sets, complete legal contracts, or comprehensive codebases in a single API call. Claude Opus 4.5 would require chunking these materials into multiple requests, increasing complexity and potentially losing cross-document context.
Real-world context window scenarios:
| Enterprise Use Case | Typical Token Requirement | Claude 200K Sufficient? | GPT-5.2 400K Advantage |
|---|---|---|---|
| Legal contract review | 150K-300K tokens | Sometimes requires chunking | Single-pass analysis |
| Large codebase analysis | 250K-500K tokens | Requires chunking | Complete context |
| Multi-document research | 100K-400K tokens | Borderline | Comfortable fit |
| Technical documentation | 80K-200K tokens | Usually fits | Extra headroom |
| Customer support history | 50K-150K tokens | Comfortable fit | Overkill |
The output limit reversal favors Claude Opus 4.5, which offers 64K token maximum output capacity versus GPT-5.2’s 32K token limit[1]. This 2x advantage matters when generating comprehensive analytical reports, extensive code implementations, or detailed documentation that needs to be thorough and complete in a single response.
Output capacity impact:
For business analytics teams generating quarterly reports with extensive data analysis, Claude’s 64K output limit allows for more comprehensive single-document deliverables without requiring multiple generation passes and manual stitching. GPT-5.2’s 32K limit means longer reports need to be generated in sections, adding workflow complexity.
For software development, the larger output capacity enables Claude to generate more complete feature implementations in one go, while GPT-5.2 might need to break complex features into multiple generation steps.
Strategic implications:
The context/output tradeoff creates a clear decision framework:
- Choose GPT-5.2 when input processing dominates your workflow (document analysis, codebase review, research synthesis)
- Choose Claude when output generation is the primary bottleneck (report writing, comprehensive code generation, detailed analysis deliverables)
Many enterprise teams find they need both capabilities for different workflows. Document processing and analysis tasks favor GPT-5.2’s massive context window, while report generation and code implementation benefit from Claude’s larger output capacity.
The long-context LLMs in production comparison shows that context windows have become a critical competitive advantage, with GPT-5.2’s 400K tokens positioning it well for the document-heavy workflows that dominate enterprise knowledge work.
What Unique Capabilities Differentiate Claude Opus 4.5 from GPT-5.2?
Claude Opus 4.5 offers three distinctive capabilities that set it apart from GPT-5.2’s architecture: extended thinking with visible reasoning chains, computer use automation, and zoom action for visual inspection. These features address specific enterprise needs that GPT-5.2’s dual-model system doesn’t directly target[1].
Extended thinking and visible reasoning chains let enterprise teams see exactly how Claude arrives at conclusions. Instead of delivering a final answer as a black box, Claude shows its step-by-step reasoning process. For compliance-sensitive industries like finance, healthcare, and legal services, this transparency enables human reviewers to verify the AI’s logic before acting on recommendations.
In practice, this means a financial analyst can see Claude’s reasoning chain when it recommends a specific investment strategy, verifying each logical step rather than blindly trusting the output. This audit trail becomes critical when regulatory requirements demand explainability for AI-assisted decisions.
Computer use automation enables Claude to interact directly with software interfaces, clicking buttons, filling forms, and navigating applications like a human user would. This capability opens enterprise automation scenarios that go beyond text generation into actual workflow execution.
Common enterprise applications include:
- Automated data entry across multiple legacy systems
- Cross-platform testing and quality assurance
- Software demonstration and documentation creation
- Repetitive administrative task automation
Zoom action for visual inspection allows Claude to examine images and visual content with variable detail levels, focusing on specific regions for detailed analysis. For enterprises working with technical diagrams, medical imaging, architectural plans, or product design, this capability enables more sophisticated visual reasoning than standard image analysis.
GPT-5.2’s distinctive capabilities:
GPT-5.2 counters with its own unique strengths, particularly in agentic task optimization and autonomous multi-step workflows[1]. The dual-model system allows it to switch between fast standard processing and deep reasoning configurations based on task requirements.
The 4x faster image generation via ChatGPT Images feature gives GPT-5.2 a clear advantage for enterprises that need rapid visual content creation alongside text reasoning. Marketing teams, design departments, and content production workflows benefit from this integrated speed advantage.
Agentic workflow optimization means GPT-5.2 excels at autonomous tasks that run in the background without constant human oversight. It can manage multi-step processes, make intermediate decisions, and course-correct based on results—ideal for overnight batch processing, automated reporting pipelines, and scheduled analysis tasks.
The practical differentiation:
Choose Claude Opus 4.5 when:
- You need to verify and explain AI reasoning for compliance or regulatory purposes
- Workflow automation requires interacting with existing software interfaces
- Visual analysis demands detailed inspection of specific image regions
- Transparency and explainability matter as much as final output quality
Choose GPT-5.2 when:
- Autonomous agents need to run multi-step workflows without constant supervision
- Rapid image generation is part of your content production pipeline
- Cost efficiency matters more than specialized automation features
- Standard text reasoning without visible chains meets your requirements
The Claude Opus 4.5 reasoning model demonstrates how extended thinking capabilities create value specifically for enterprises that need to understand and validate AI decision-making, not just consume AI outputs.
When Should Enterprises Choose Claude Opus 4.5 Over GPT-5.2?
Enterprises should choose Claude Opus 4.5 over GPT-5.2 when reliability, speed, and mission-critical accuracy outweigh cost considerations. As reviewers concluded after extensive testing, Claude is “the safest pick for real ‘ship a feature in a big repo’ work” where production failures carry significant business consequences[3].
Mission-critical production deployments represent the clearest use case for Claude despite its 2-3x higher costs. When a single AI-generated bug could cause customer-facing failures, data corruption, or security vulnerabilities, Claude’s superior consistency and reliability justify the premium pricing. Financial services firms deploying AI for trading algorithms, healthcare organizations using AI for clinical decision support, and enterprise software teams shipping features to millions of users all fall into this category.
The 7-minute execution time versus GPT-5.2’s 20+ minutes matters most when developer productivity directly impacts business velocity[3]. Startups racing to ship features, product teams with tight sprint deadlines, and organizations where developer time costs $150-250 per hour all benefit from Claude’s speed advantage enough to offset the higher token costs.
Specific scenarios favoring Claude Opus 4.5:
1. High-stakes code generation When shipping features in large production codebases where bugs are expensive, Claude’s higher reliability and faster execution reduce risk and accelerate delivery. The superior UI polish means less post-generation refinement work[3].
2. Compliance-sensitive analysis Industries requiring explainable AI decisions (finance, healthcare, legal) benefit from Claude’s visible reasoning chains. Regulators and auditors can review the AI’s logic, not just its conclusions[1].
3. Time-sensitive decision support Executive teams needing rapid analysis for strategic decisions can’t wait 20+ minutes for GPT-5.2 Codex to complete deep reasoning tasks. Claude’s 7-8 minute completion times enable real-time decision support.
4. Premium client deliverables Consulting firms, agencies, and professional services organizations delivering AI-assisted work to high-value clients often choose Claude for the superior output quality and polish that justifies premium pricing.
5. Comprehensive report generation The 64K output token limit enables longer, more complete analytical reports in single generations, reducing workflow complexity compared to GPT-5.2’s 32K limit[1].
Common mistakes to avoid:
Don’t choose Claude Opus 4.5 simply because it’s “#1 on benchmarks” without considering whether your specific use case actually requires that level of performance. Many enterprise workloads run perfectly well on GPT-5.2 at a fraction of the cost.
Don’t assume Claude’s reliability means zero human review. Both models remain supplementary tools requiring oversight for large-scale production deployments[3]. The difference is Claude requires less correction on average, not zero correction.
Don’t ignore the cost implications at scale. A single team might absorb the 2-3x cost difference, but deploying Claude across 50 enterprise teams creates budget impacts that require CFO-level approval.
The decision framework:
Choose Claude Opus 4.5 when the cost of failure (bugs, delays, poor quality) exceeds the 2-3x price premium. Choose GPT-5.2 when cost efficiency and good-enough performance meet your requirements. For organizations using MULTIBLY, the practical approach is testing both models on your actual workloads before committing to one, since real-world performance on your specific tasks matters more than general benchmarks.
When Does GPT-5.2 Provide Better Value for Enterprise Teams?
GPT-5.2 provides better value when cost efficiency, large-scale deployment, and long-document processing take priority over absolute peak performance. The 2.9x lower input costs and 1.8x lower output costs create compelling economics for enterprises scaling AI across multiple departments and use cases[2].
High-volume workloads represent the clearest value proposition for GPT-5.2. Teams processing hundreds of millions of tokens monthly see dramatic cost savings—a $15,000 monthly Claude bill drops to $6,000-7,000 with GPT-5.2 while maintaining excellent reasoning performance[5]. For organizations deploying AI to customer support, document processing, research analysis, and content generation teams simultaneously, the cost difference funds additional use cases.
The 400K token context window creates unique value for document-heavy workflows that Claude’s 200K limit can’t match[4]. Legal teams reviewing complete contracts, research departments analyzing comprehensive literature sets, and development teams processing entire large codebases all benefit from GPT-5.2’s ability to handle these materials in single API calls without chunking complexity.
Specific scenarios favoring GPT-5.2:
1. Cost-conscious AI scaling Organizations democratizing AI access across departments need affordable per-token costs to make broad deployment financially viable. GPT-5.2’s pricing enables experimentation and adoption without requiring executive approval for each new use case.
2. Long-document analysis Processing technical documentation, legal contracts, comprehensive reports, or large codebases that exceed 200K tokens requires GPT-5.2’s larger context window. Attempting these tasks with Claude requires complex chunking strategies that reduce accuracy.
3. Autonomous background workflows Agentic tasks that run overnight or process queued work without immediate human review benefit from GPT-5.2’s optimization for multi-step autonomous workflows[1]. The longer processing time doesn’t matter when humans aren’t waiting for results.
4. Batch processing operations Data analysis pipelines, scheduled reporting, and bulk content processing can leverage GPT-5.2’s lower costs for high-volume throughput where speed isn’t the primary constraint.
5. Exploratory and development work Teams experimenting with AI applications, prototyping new features, or developing AI workflows benefit from GPT-5.2’s lower costs during the iteration phase before production deployment.
The value calculation:
GPT-5.2 delivers better value when:
- Your workload processes more than 50 million tokens monthly, making cost differences material
- Input processing dominates your workflow (reading documents, analyzing code, research synthesis)
- Background processing without real-time human interaction is acceptable
- Good performance at lower cost beats excellent performance at premium pricing for your budget constraints
Real-world value scenarios:
A customer support team processing 200 million input tokens and 100 million output tokens monthly pays approximately $6,000 with GPT-5.2 versus $15,000 with Claude Opus 4.5. The $9,000 monthly savings ($108,000 annually) funds additional AI initiatives or justifies broader team access.
A legal research department analyzing complete case files and contracts benefits from GPT-5.2’s 400K context window, which handles comprehensive documents that would require splitting with Claude’s 200K limit[4]. The workflow simplification and accuracy improvement from single-pass processing creates value beyond raw cost savings.
As one analysis concluded, “for cost-conscious enterprises prioritizing value, GPT-5.2 offers the best balance” with excellent performance at significantly lower operational expenses that make broader AI adoption financially feasible[5].
Organizations exploring enterprise AI adoption often start with GPT-5.2 for most use cases, reserving Claude Opus 4.5 for the subset of mission-critical workflows where its reliability and speed advantages justify the premium.
How Do These Models Compare to Other Enterprise AI Options in 2026?
Claude Opus 4.5 and GPT-5.2 sit at the top of the enterprise reasoning hierarchy in 2026, but they’re not the only options worth considering. The competitive landscape includes strong alternatives that excel in specific niches where the “reasoning kings” may be overkill or poorly suited.
Gemini 3 Pro from Google positions itself as the speed champion for multimodal tasks, offering faster processing for workflows that combine text, images, and other data types[1]. Enterprises with heavy visual reasoning requirements—product design, medical imaging analysis, architectural planning—often find Gemini 3 Pro’s multimodal optimization more valuable than Claude or GPT-5.2’s text-focused reasoning strengths. The Gemini 3 Pro speed advantage becomes significant for teams processing thousands of images daily alongside text analysis.
Magistral Medium from Mistral targets enterprise reasoning with a focus on deployment flexibility and European data sovereignty requirements. Organizations with strict data residency requirements or those preferring open-weight models for on-premise deployment find Magistral’s enterprise reasoning and deployment strategies more suitable than cloud-only Claude or GPT options.
The small model revolution challenges the assumption that bigger always means better. Phi-4 and lightweight Mistral variants deliver surprisingly strong reasoning performance for specific tasks at a fraction of the cost and latency. The small model revolution shows that enterprises can often achieve 80-90% of Claude/GPT performance for 10-20% of the cost by matching smaller models to narrower use cases.
Open-source alternatives like DeepSeek R1 and GLM-4.5 provide compelling value for organizations willing to manage their own infrastructure. DeepSeek R1’s challenge to global leaders demonstrates that open models can match or exceed proprietary performance on specific benchmarks while offering complete control over deployment, customization, and data privacy.
Comparison framework:
| Model Category | Best For | Trade-offs vs Claude/GPT-5.2 |
|---|---|---|
| Gemini 3 Pro | Multimodal workflows, visual reasoning | Faster multimodal but less pure text reasoning consistency |
| Magistral Medium | European deployment, data sovereignty | Deployment flexibility but smaller ecosystem |
| Phi-4 / Small models | Narrow use cases, cost optimization | 80-90% performance at 10-20% cost for specific tasks |
| DeepSeek R1 | Open-source, customization | Self-hosting complexity but complete control |
| GPT-5.2 standard | Balanced cost-performance | Good reasoning at lower cost than Claude |
| Claude Opus 4.5 | Mission-critical reliability | Premium performance at premium pricing |
When to consider alternatives:
Choose alternatives to Claude Opus 4.5 and GPT-5.2 when:
- Multimodal dominates: Visual reasoning requirements exceed text reasoning needs (Gemini 3 Pro)
- Data sovereignty matters: European or regulated industry requirements demand specific deployment models (Magistral Medium)
- Cost is paramount: Budget constraints make even GPT-5.2 too expensive for your use case (small models)
- Customization required: You need to fine-tune models or control the entire stack (open-source options)
- Specialized performance: Narrow use cases where specialized models outperform general reasoning engines
The multi-model reality:
Most sophisticated enterprise AI strategies in 2026 don’t rely on a single model. Instead, they use Claude Opus 4.5 for mission-critical reasoning, GPT-5.2 for cost-efficient high-volume work, Gemini 3 Pro for multimodal tasks, and small models for simple classification or extraction workflows.
This multi-model approach requires infrastructure that can route tasks to the optimal model based on requirements—exactly what platforms like MULTIBLY enable by providing access to 300+ premium AI models through a single interface. The comparison of AI responses side by side lets enterprise teams test which model performs best for each specific workflow before committing infrastructure and budget.
The Claude 4 Sonnet vs GPT-4o comparison from earlier 2026 shows how quickly the competitive landscape evolves, making flexible multi-model access more valuable than betting everything on a single provider’s roadmap.
What Are the Implementation and Integration Considerations?
Implementing Claude Opus 4.5 or GPT-5.2 in enterprise environments requires addressing API integration complexity, rate limits, data privacy requirements, and workflow orchestration. Both models offer robust enterprise APIs, but the implementation details differ in ways that impact deployment timelines and operational overhead.
API integration basics are straightforward for both models—standard REST APIs with JSON payloads, authentication via API keys, and comprehensive documentation. Development teams familiar with any modern API can integrate either model into existing applications within days. The differences emerge in advanced features and enterprise-specific requirements.
Rate limits and throughput vary significantly between providers and pricing tiers. Enterprise contracts typically include higher rate limits than standard API access, but teams processing millions of tokens hourly need to verify that contracted limits match their peak workload requirements. GPT-5.2’s lower per-token costs make high-volume rate limits more affordable, while Claude’s premium pricing often comes with premium support and higher default limits.
Data privacy and compliance considerations differ based on deployment model:
Claude Opus 4.5 offers enterprise data protection with options for zero data retention, meaning Anthropic doesn’t use enterprise API inputs for model training. This matters for regulated industries handling sensitive data.
GPT-5.2 provides similar enterprise privacy guarantees through OpenAI’s business and enterprise tiers, with contractual commitments around data handling and retention policies.
Both models support:
- SOC 2 Type II compliance for security controls
- GDPR compliance for European data protection
- HIPAA-eligible configurations for healthcare applications (with proper business associate agreements)
- Custom data residency requirements through enterprise contracts
Workflow orchestration becomes critical when deploying AI reasoning at scale. Simple point integrations work for pilot projects, but production deployments need:
- Error handling and retry logic: Both models occasionally time out or return errors; production systems need graceful degradation
- Response validation: Automated checks to verify AI outputs meet quality and format requirements before downstream use
- Cost monitoring: Real-time tracking of token consumption to prevent budget overruns
- Model routing: Logic to select the optimal model based on task requirements and cost constraints
Common implementation patterns:
1. Direct API integration Simplest approach for single-use cases. Application code calls the model API directly, processes responses, and handles errors. Works well for prototypes and narrowly scoped deployments.
2. Middleware abstraction layer Enterprise teams often build or adopt middleware that abstracts model-specific APIs behind a unified interface. This enables switching between Claude and GPT-5.2 (or other models) without changing application code. Platforms like MULTIBLY provide this abstraction layer as a service.
3. Agentic frameworks For complex multi-step workflows, frameworks like LangChain, AutoGen, or custom orchestration layers manage state, coordinate multiple model calls, and handle conditional logic based on intermediate results.
4. Batch processing pipelines High-volume document processing, analysis, or content generation often uses queued batch architectures that process work asynchronously, managing rate limits and costs more efficiently than real-time APIs.
Infrastructure considerations:
- Latency requirements: Real-time user-facing applications need to account for model response times (7-8 minutes for complex Claude tasks, 20+ minutes for GPT-5.2 Codex reasoning)[3]
- Caching strategies: Repeated similar queries can leverage response caching to reduce costs and improve speed
- Fallback models: Production systems often configure fallbacks to alternative models if primary choice is unavailable
- Monitoring and observability: Tracking model performance, costs, and errors requires integration with existing monitoring infrastructure
Security hardening:
Enterprise deployments require:
- API key rotation policies and secure credential management
- Network isolation for sensitive workloads
- Audit logging of all model interactions for compliance
- Input sanitization to prevent prompt injection attacks
- Output validation to catch potential data leakage
The integration timeline:
- Pilot deployment: 2-4 weeks for simple use case with direct API integration
- Production deployment: 6-12 weeks including error handling, monitoring, security review, and testing
- Enterprise-wide rollout: 3-6 months including governance, training, and cross-team coordination
Organizations leveraging platforms with pre-built integrations can compress these timelines significantly by avoiding custom infrastructure development. The MULTIBLY platform provides enterprise-ready access to both Claude Opus 4.5 and GPT-5.2 with unified APIs, cost tracking, and comparison capabilities that eliminate much of the custom integration work.
Frequently Asked Questions
Is Claude Opus 4.5 or GPT-5.2 better for enterprise use in 2026?
Claude Opus 4.5 excels for mission-critical work requiring maximum reliability and speed, while GPT-5.2 offers better value for cost-conscious enterprises scaling AI across multiple departments. The “better” choice depends on whether your priority is peak performance (Claude) or optimal cost-performance balance (GPT-5.2)[3][5].
How much more expensive is Claude Opus 4.5 compared to GPT-5.2?
Claude Opus 4.5 costs approximately 2.9x more for input tokens ($5.00/MTok vs $1.75/MTok) and 1.8x more for output tokens ($25.00/MTok vs $14.00/MTok). For typical enterprise workloads, expect Claude to cost 2-2.5x more overall than GPT-5.2[2].
Which model has the larger context window?
GPT-5.2 Codex provides a 400K token context window (approximately 600 A4 pages) compared to Claude Opus 4.5’s 200K tokens, making it better for long-document processing and large codebase analysis[4].
Can Claude Opus 4.5 generate longer outputs than GPT-5.2?
Yes. Claude Opus 4.5 offers 64K token maximum output capacity versus GPT-5.2’s 32K limit, enabling longer analytical reports and more comprehensive code generation in single responses[1].
Which model is faster for complex coding tasks?
Claude Opus 4.5 completes complex feature implementation in approximately 7-8 minutes compared to GPT-5.2 Codex’s 20-26 minutes, providing a 2.5-3x speed advantage for time-sensitive development work[3].
Do these models require human oversight for production use?
Yes. Both Claude Opus 4.5 and GPT-5.2 remain supplementary tools requiring human review for large-scale production deployments. Neither should be solely relied upon without verification, though Claude demonstrates higher reliability on average[3].
What makes Claude Opus 4.5 the #1 reasoning model?
Claude Opus 4.5 achieves the #1 reasoning position through consistent edge advantages in execution speed, reliability across diverse tasks, and practical usability. It “shipped working results for both tasks” in real-world testing with superior UI polish and fewer errors requiring correction[3].
Can I use both models through a single platform?
Yes. Platforms like MULTIBLY provide access to both Claude Opus 4.5 and GPT-5.2 (plus 300+ other AI models) through a single subscription, enabling side-by-side comparison and optimal model selection for each specific task.
Which model is better for document analysis?
GPT-5.2 generally performs better for document analysis due to its 400K token context window, which handles complete long documents in single API calls without chunking. Claude’s 200K limit requires splitting larger documents[4].
Are there cheaper alternatives to these models?
Yes. Small models like Phi-4 and lightweight Mistral variants deliver 80-90% of Claude/GPT performance for specific narrow use cases at 10-20% of the cost. Open-source options like DeepSeek R1 offer strong performance with self-hosting flexibility[6].
How do I choose between Claude Opus 4.5 and GPT-5.2?
Choose Claude for mission-critical production work where reliability and speed justify 2-3x higher costs. Choose GPT-5.2 for cost-efficient scaling, long-document processing, and high-volume workloads where good performance at lower prices meets requirements. Test both on your actual workloads before committing[5].
What industries benefit most from these reasoning models?
Financial services, healthcare, legal, software development, consulting, and research organizations benefit most from advanced reasoning capabilities. Any industry requiring complex analysis, multi-step logical thinking, or sophisticated decision support gains value from these models.
Conclusion
The Claude Opus 4.5 vs GPT-5.2: The 2026 Reasoning Kings for Enterprise Problem-Solving comparison reveals two excellent but fundamentally different approaches to AI reasoning. Claude Opus 4.5 holds the #1 position for reliability, execution speed, and mission-critical deployments where performance justifies premium pricing. GPT-5.2 counters with compelling cost efficiency, larger context windows, and excellent reasoning performance that makes broad enterprise AI adoption financially viable.
The practical reality for most enterprise teams isn’t choosing one model exclusively—it’s understanding which model fits which specific workflow. Use Claude Opus 4.5 for production features in large codebases, compliance-sensitive analysis requiring explainable reasoning, and time-sensitive decision support where developer productivity matters more than token costs. Deploy GPT-5.2 for high-volume document processing, cost-conscious scaling across departments, autonomous background workflows, and exploratory work where good performance at lower prices meets requirements.
Actionable next steps:
- Audit your current AI workloads to identify which tasks require maximum reliability versus which prioritize cost efficiency
- Calculate the cost difference for your specific token volumes using the 2.9x input and 1.8x output multipliers
- Test both models on your actual enterprise use cases before committing—platforms like MULTIBLY enable direct comparison without separate subscriptions
- Implement a multi-model strategy that routes tasks to the optimal model based on requirements rather than forcing all work through a single provider
- Monitor performance and costs in production to verify that theoretical advantages translate to real-world value for your specific workflows
The 2026 enterprise AI landscape rewards flexibility and informed decision-making over loyalty to a single provider. Both Claude Opus 4.5 and GPT-5.2 earn their “reasoning kings” designation, but the crown fits differently depending on what you’re trying to accomplish. Organizations that master matching models to use cases will outperform those that simply deploy the highest-benchmark model for everything.
For teams ready to leverage both reasoning engines strategically, MULTIBLY’s platform provides the infrastructure to access, compare, and optimize across 300+ premium AI models—turning the multi-model approach from a complex integration challenge into a practical competitive advantage.
References
[1] Gpt 5 Vs Claude Sonnet 45 Complete 2026 Comparison – https://www.cosmicjs.com/blog/gpt-5-vs-claude-sonnet-45-complete-2026-comparison
[2] Claude Opus 4 5 Vs Gpt 5 2 Codex – https://blog.galaxy.ai/compare/claude-opus-4-5-vs-gpt-5-2-codex
[3] Gpt5.2 Codex High Vs Opus 4.5 Vs Gemini 3 Pro – https://www.tensorlake.ai/blog/gpt5.2-codex-high-vs-opus-4.5-vs-gemini-3-pro
[4] Gpt 5 2 Codex Vs Claude Opus 4 5 Thinking – https://artificialanalysis.ai/models/comparisons/gpt-5-2-codex-vs-claude-opus-4-5-thinking
[5] Gpt 5 2 Vs Claude Opus 4 5 – https://otomatic.ai/en/gpt-5-2-vs-claude-opus-4-5
[6] Best Ai Model For Coding 2026 – https://www.faros.ai/blog/best-ai-model-for-coding-2026
Our Fact Checking Process
We prioritize accuracy and integrity in our content. Here's how we maintain high standards:
- Expert Review: All articles are reviewed by subject matter experts.
- Source Validation: Information is backed by credible, up-to-date sources.
- Transparency: We clearly cite references and disclose potential conflicts.
Our Review Board
Our content is carefully reviewed by experienced professionals to ensure accuracy and relevance.
- Qualified Experts: Each article is assessed by specialists with field-specific knowledge.
- Up-to-date Insights: We incorporate the latest research, trends, and standards.
- Commitment to Quality: Reviewers ensure clarity, correctness, and completeness.
Look for the expert-reviewed label to read content you can trust.



