
The ability to remember more is reshaping how AI models handle real-world tasks. Context Windows as a Competitive Advantage: Kimi K2’s 256K and the Race for Longer Memory in LLMs represents a fundamental shift in how language models process information, with Moonshot AI’s Kimi K2 offering 256,000 token capacity that enables processing approximately 190,000 words in a single session.[2] This extended memory isn’t just a bigger number—it’s functional infrastructure that changes which tasks AI can reliably complete.
While competitors race to advertise million-token windows, the practical question matters more: what can extended context actually do that shorter windows cannot? The answer determines whether longer memory serves as genuine competitive advantage or marketing spectacle.
- Key Takeaways
- What Makes Context Windows a Competitive Advantage in Modern LLMs?
- How Does Kimi K2's 256K Context Window Compare to Competitors?
- What Use Cases Benefit Most from Extended Context Windows?
- How Does Context Window Architecture Impact Model Performance?
- What Infrastructure Do Extended Context Windows Require?
- How Are Context Windows Reshaping the Competitive Landscape?
- What Are the Practical Limitations of Extended Context Windows?
- FAQ
- Conclusion
- References
Key Takeaways
- Kimi K2’s 256K context window represents working memory architecture designed for sustained reasoning across 200-300 tool invocations, not just passive information storage[3][6]
- The mixture-of-experts design with INT4 quantization enables enterprise deployment on 8× A100 GPUs while maintaining reasoning stability across extended sequences[5][6]
- Optimal use cases cluster around sustained coherence tasks: complete codebase analysis, multi-document research synthesis, lengthy legal document review, and complex agentic workflows requiring hundreds of sequential operations[3]
- Infrastructure requirements span from enterprise GPU clusters (50-100 tokens/second) to single consumer GPUs (1-7 tokens/second) with significant performance trade-offs[2][5]
- Extended context introduces measurable costs in latency, computation, and infrastructure that only justify deployment when task requirements demand sustained reasoning across large information sets
- The competitive landscape differentiates on implementation quality rather than maximum specifications, with reasoning stability and deployment flexibility becoming critical differentiators[7]
- Microsoft Azure Foundry integration provides enterprise-grade managed deployment as of early 2026, eliminating infrastructure management overhead[6]
- Open-weight availability democratizes access to extended context capabilities previously exclusive to closed-source systems, accelerating community innovation and specialized applications[7]
- Context window size should match task requirements, not serve as default configuration—use minimum necessary context to optimize speed and cost
- Platforms enabling intelligent model routing maximize value by matching task characteristics with optimal context window sizes and model architectures
What Makes Context Windows a Competitive Advantage in Modern LLMs?
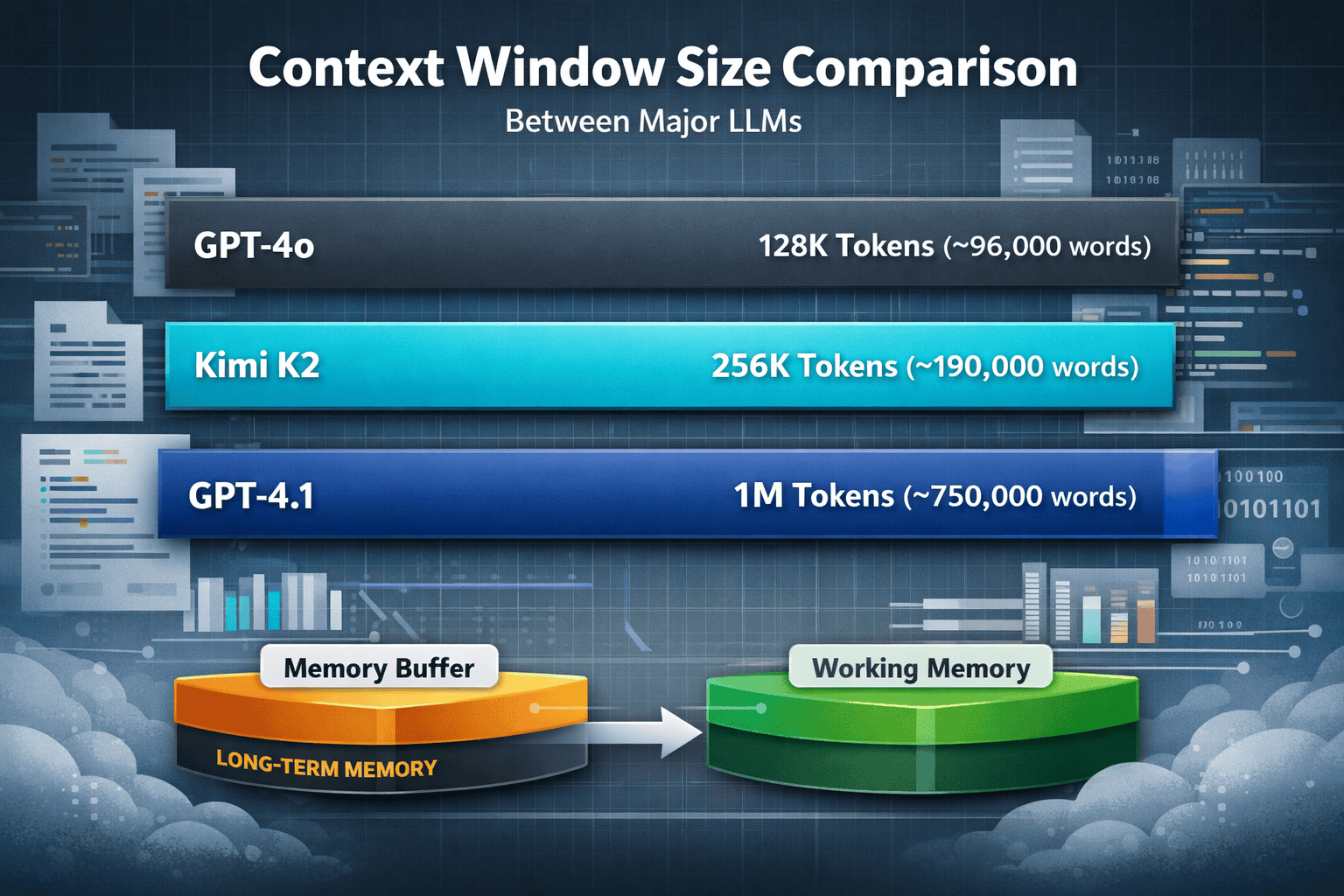
Context windows determine how much information a language model can actively consider when generating responses. For Kimi K2, the 256K token capacity translates to approximately 190,000 words of active working memory—enough to hold entire codebases, lengthy legal documents, or multi-document research collections in a single processing session.[2]
The competitive advantage emerges not from capacity alone, but from how that capacity supports sustained reasoning. Traditional models with smaller windows require chunking long documents, losing coherence across segments. K2’s architecture treats the 256K window as a “thinking buffer” designed specifically for long-term reasoning support, enabling the model to retain reasoning chains, tool invocation states, multi-stage reflection, and uninterrupted long tasks.[3]
The Working Memory Paradigm
Standard context windows function like passive storage—the model can reference earlier text but doesn’t maintain active reasoning state across extended sequences. K2’s design philosophy differs fundamentally:
- Reasoning chain persistence: The model maintains logical connections across hundreds of reasoning steps without drift
- Tool invocation stability: Achieves stable execution of 200-300 sequential tool calls, compared to typical models that experience reasoning drift after 30-50 calls[6]
- Multi-stage reflection: Supports iterative refinement processes that require revisiting and revising earlier conclusions
- State management: Tracks variables, dependencies, and intermediate results across complex workflows
This architectural approach positions context length as functional infrastructure rather than a marketing metric. The difference becomes apparent in production environments where reasoning quality must remain stable across extended task sequences.
Competitive Landscape Comparison
The race for longer memory reveals different strategic priorities across providers:
| Model | Context Window | Design Philosophy | Primary Trade-off |
|---|---|---|---|
| Kimi K2 | 256K tokens | Working memory for sustained reasoning | Capacity vs. stability |
| GPT-4o | 128K tokens | Balanced general-purpose performance | Accessibility vs. specialization |
| GPT-4.1 | 1M tokens | Maximum passive context capacity | Raw capacity vs. cost |
| Claude 3.5 | 200K tokens | Document analysis optimization | Context vs. speed |
K2’s 256K window matches GPT-4o’s capabilities while falling short of GPT-4.1’s million-token context, though K2’s implementation emphasizes working memory stability for reasoning chains over raw capacity.[7] The architectural focus differs: K2’s 256K is designed as a “thinking buffer” for sustained multi-stage reasoning rather than passive context padding.[3]
Common mistake: Assuming larger context windows automatically deliver better results. In practice, most tasks don’t benefit from million-token windows if the model can’t maintain reasoning coherence across that span. Choose models based on task requirements, not maximum specifications.
How Does Kimi K2’s 256K Context Window Compare to Competitors?
Kimi K2’s 256K token capacity positions it between mid-range models like GPT-4o (128K) and extreme-capacity systems like GPT-4.1 (1M tokens). The practical difference lies in architectural implementation and sustained reasoning stability rather than raw numbers.
Technical Architecture Differences
K2 maintains a 1.04 trillion total parameter count with 32 billion active parameters per token through a mixture-of-experts (MoE) design, using 384 total experts with 8+1 selected per token.[2] This selective activation reduces computational requirements compared to monolithic models while maintaining reasoning capability.
The native INT4 quantization approach enables 2× speed improvements and significantly lower memory usage while maintaining reasoning chain stability—particularly critical for preventing timeout failures during deep thinking sequences.[6] This quantization-aware training (QAT) approach was specifically designed to ensure “deep reasoning chains do not break due to insufficient computing power” on non-H100 hardware.[3]
Real-World Performance Implications
The 256K window enables specific capabilities that shorter contexts cannot reliably support:
Complete codebase analysis: Process entire repositories without chunking, maintaining awareness of cross-file dependencies, architectural patterns, and refactoring implications across thousands of lines of code.
Multi-document research synthesis: Analyze 20-30 research papers simultaneously, identifying contradictions, synthesizing findings, and generating comprehensive literature reviews without losing inter-document connections.
Complex legal document review: Process complete contracts, case files, and regulatory documents in single sessions, maintaining awareness of clause interactions, precedent references, and regulatory compliance requirements.
Extended agentic workflows: Execute 200-300 sequential tool calls with stable reasoning, enabling complex automation sequences like comprehensive code refactoring, multi-stage data analysis, or iterative research processes.[3][6]
When 256K Matters vs. When It Doesn’t
Choose K2’s 256K window when:
- Tasks require maintaining coherence across entire documents or codebases
- Reasoning chains span hundreds of logical steps
- Tool invocation sequences exceed 50-100 calls
- Multi-document synthesis requires cross-referencing without re-reading
Shorter contexts suffice when:
- Single-document summarization or Q&A
- Code completion or simple debugging
- Conversational interactions without deep research requirements
- Tasks that naturally segment into independent subtasks
The features offered by MULTIBLY enable teams to match task requirements with optimal model selection, routing complex reasoning tasks to K2 while using faster models for simpler operations.
What Use Cases Benefit Most from Extended Context Windows?
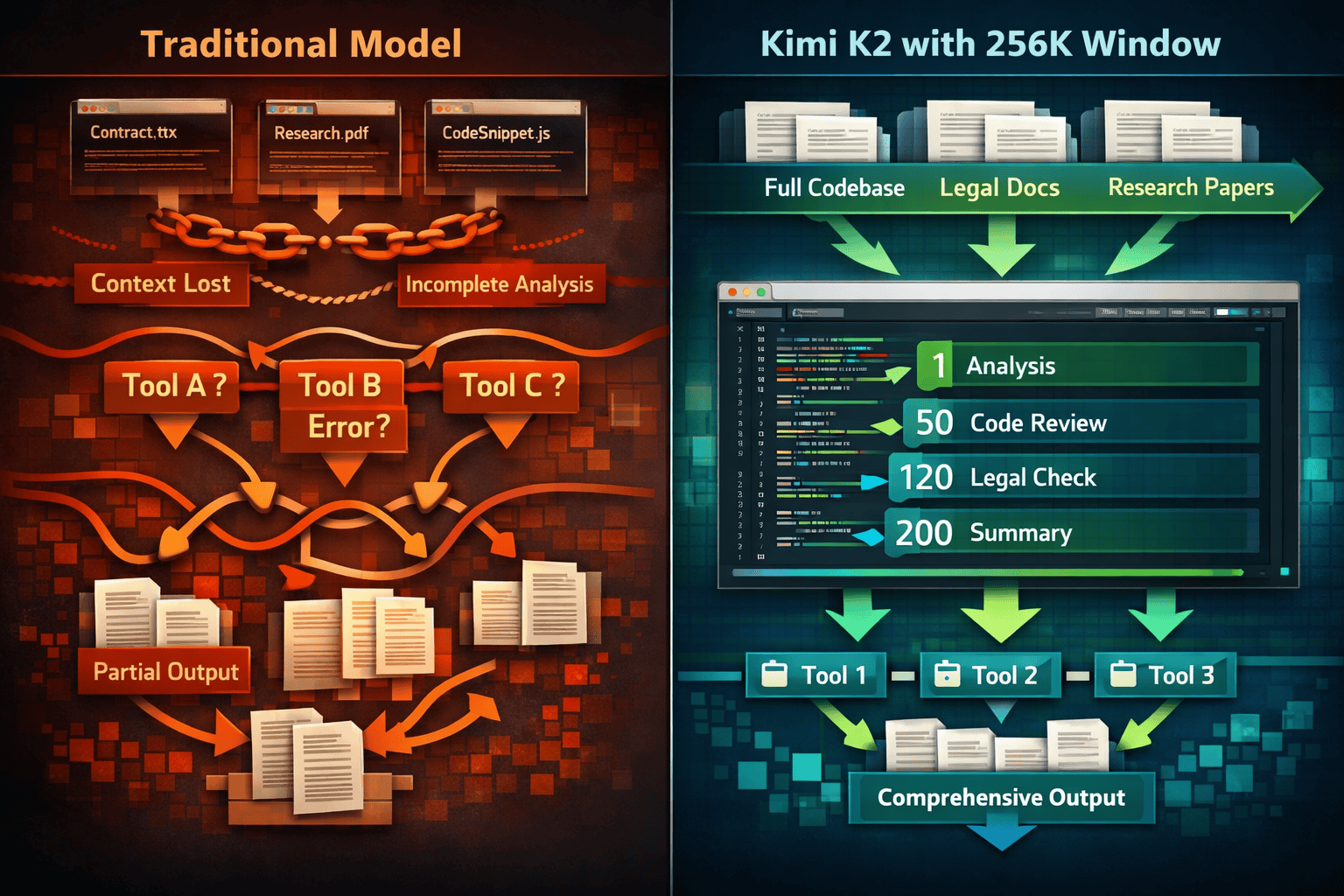
Extended context windows deliver measurable advantages when tasks require sustained coherence across large information sets. The 256K capacity becomes valuable infrastructure rather than theoretical capability in specific scenarios.
Document Processing and Analysis
Legal document review represents an ideal use case. Complete contracts, regulatory filings, or case documentation often span 50,000-150,000 words. Processing these documents in a single session enables the model to:
- Identify clause interactions and potential conflicts across hundreds of pages
- Maintain awareness of defined terms and their usage throughout documents
- Cross-reference regulatory requirements with contract provisions
- Generate comprehensive summaries that preserve document structure and dependencies
Research paper synthesis benefits similarly. Academic researchers can load 15-25 full-text papers (approximately 150,000-200,000 words) simultaneously, enabling the model to identify methodological patterns, contradictory findings, and research gaps across an entire literature domain without losing inter-paper connections.
Code Analysis and Refactoring
Software development tasks show dramatic quality improvements with extended context:
Entire repository analysis: Load complete codebases (50,000-150,000 lines) to understand architectural patterns, identify technical debt, and suggest refactoring strategies that account for cross-file dependencies. Traditional chunking approaches miss these system-level insights.
Complex refactoring operations: Maintain awareness of all affected files, functions, and dependencies throughout multi-stage refactoring processes. K2’s stable tool invocation across 200-300 sequential calls enables automated refactoring that would require extensive manual coordination with shorter-context models.[3][6]
Dependency mapping: Trace function calls, data flows, and architectural relationships across entire projects without losing context, enabling accurate impact analysis for proposed changes.
Multi-Turn Reasoning and Research Tasks
Extended context enables sustained reasoning chains that shorter windows fragment:
Multi-stage problem solving: Complex analytical tasks requiring iterative hypothesis generation, testing, and refinement benefit from maintaining complete reasoning history. The model can revisit earlier assumptions, identify logical gaps, and refine conclusions without re-explaining context.
Comprehensive research synthesis: Combine information from multiple sources, identify patterns, resolve contradictions, and generate novel insights while maintaining awareness of all source material and intermediate reasoning steps.
Agentic workflow orchestration: Execute complex automation sequences requiring hundreds of tool invocations—data collection, analysis, synthesis, validation, and reporting—with stable reasoning state throughout the entire process.[6]
Edge Cases and Limitations
When extended context underperforms:
- Simple Q&A or summarization tasks where context overhead slows response time
- Highly structured data better suited to database queries than language model processing
- Real-time applications where latency requirements conflict with large context processing time
- Tasks requiring frequent context updates where maintaining 256K tokens becomes inefficient
Common mistake: Loading maximum context regardless of task requirements. In practice, use the minimum context necessary for task completion to optimize speed and cost. Extended windows should support specific capabilities, not serve as default configuration.
How Does Context Window Architecture Impact Model Performance?
The relationship between context window size and model performance depends heavily on architectural implementation. Kimi K2’s approach demonstrates that how a model uses context matters more than raw capacity.
Mixture-of-Experts (MoE) Design
K2’s MoE architecture activates 32 billion parameters per token from a total pool of 1.04 trillion parameters, using 384 experts with 8+1 selected per token.[2] This selective activation delivers several advantages for extended context processing:
Computational efficiency: Only a fraction of total parameters activate for each token, reducing memory bandwidth requirements and enabling faster processing despite large total parameter count.
Specialized reasoning paths: Different expert combinations handle different reasoning types—code analysis activates different experts than legal document review, optimizing performance across diverse tasks.
Scalable context processing: The selective activation pattern scales more efficiently across extended contexts than monolithic architectures, maintaining consistent performance as context length increases.
INT4 Quantization Strategy
K2’s native INT4 quantization represents a non-standard approach specifically designed for extended reasoning stability.[6] Traditional quantization often degrades reasoning quality, particularly in long chains. K2’s quantization-aware training (QAT) maintains reasoning coherence while delivering:
- 2× speed improvements compared to FP16 implementations
- Significantly lower memory usage, enabling deployment on more accessible hardware
- Reasoning chain stability across deep thinking sequences, preventing timeout failures
- Consistent performance on non-H100 hardware configurations[3]
This architectural choice reflects a specific design philosophy: extended context serves sustained reasoning tasks where stability matters more than peak theoretical performance.
Working Memory vs. Passive Storage
The critical architectural distinction separates models that treat context as working memory from those using it as passive storage:
Working memory implementation (K2’s approach):
- Maintains active reasoning state across extended sequences
- Supports stable tool invocation chains (200-300 calls)[6]
- Enables multi-stage reflection and iterative refinement
- Preserves logical dependencies across reasoning steps
Passive storage implementation (typical approach):
- Provides reference access to earlier text
- Experiences reasoning drift in extended sequences
- Requires external state management for complex workflows
- Treats context primarily as information retrieval resource
The difference becomes apparent in production environments. Tasks requiring sustained coherence—complex refactoring, multi-document synthesis, extended research workflows—show measurably better results with working memory architectures.
Performance Trade-offs
Extended context windows introduce specific trade-offs that architectural choices address differently:
Latency: Processing 256K tokens requires more computation than 8K tokens. K2’s MoE design and INT4 quantization mitigate this through selective activation and optimized computation, achieving 50-100 tokens/second on enterprise hardware.[5]
Memory requirements: Larger contexts demand more GPU memory. K2’s quantization enables deployment on 8× A100 80GB GPUs with approximately 630GB storage, making enterprise deployment feasible without exclusive reliance on H100 hardware.[5]
Reasoning stability: Longer contexts risk coherence degradation. K2’s architecture specifically addresses this through working memory design and quantization strategies that maintain reasoning quality across extended sequences.[3]
Cost efficiency: Extended context processing costs more per token. Teams using MULTIBLY’s platform can route tasks intelligently, using extended context only when task requirements justify the additional cost.
What Infrastructure Do Extended Context Windows Require?
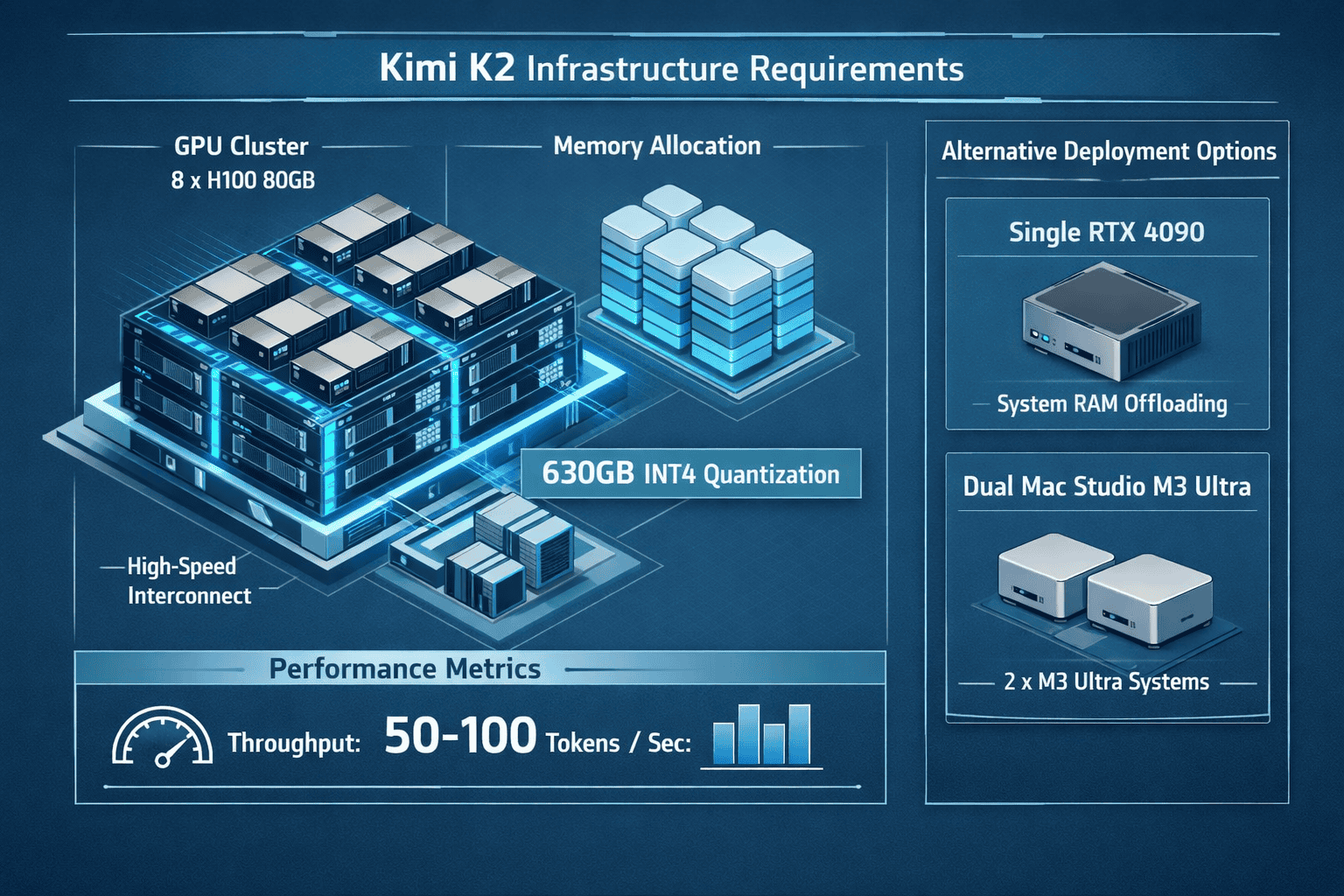
Deploying models with 256K context windows demands significant computational resources, though implementation options span from enterprise GPU clusters to consumer hardware with trade-offs in performance.
Enterprise-Grade Deployment
Production environments requiring optimal performance need substantial infrastructure. For Kimi K2 with INT4 quantization, the standard configuration includes:[5]
GPU requirements:
- 8× H100 80GB GPUs (preferred configuration)
- 8× A100 80GB GPUs (alternative configuration)
- Approximately 630GB storage for model weights
- 50-100 tokens/second inference speed
System specifications:
- High-bandwidth GPU interconnect (NVLink or equivalent)
- Sufficient CPU resources for orchestration and preprocessing
- Fast storage subsystem for model loading and checkpointing
- Network infrastructure for distributed inference if scaling beyond single node
This configuration supports stable production workloads with consistent performance across extended reasoning tasks. The INT4 quantization significantly reduces requirements compared to FP16 implementations, which would demand substantially more GPU memory.[6]
Consumer Hardware Options
Researchers and developers can deploy K2 on more accessible hardware with performance trade-offs:
Single RTX 4090 deployment (extreme compression):[5]
- GPU: RTX 4090 24GB
- System RAM: 256GB
- Storage: 240GB
- Quantization: 1.58-bit (extreme compression)
- Performance: 1-2 tokens/second
- Trade-off: Complete MoE layer offloading to system memory
Single RTX 3090 deployment (community configurations):[2]
- GPU: RTX 3090 24GB
- Quantization: Optimized quantized versions
- Performance: Approximately 7 tokens/second
- Trade-off: Reduced reasoning stability with aggressive quantization
Mac Studio M3 Ultra deployment (dual-system configuration):[8]
- Configuration: 2× Mac Studio M3 Ultra
- Memory: 512GB unified memory per system
- Framework: MLX with sharded generation
- Performance: Approximately 21.9 tokens/second
- Trade-off: High memory utilization, specialized setup
Performance vs. Accessibility Trade-offs
The infrastructure spectrum reflects fundamental trade-offs between performance, cost, and accessibility:
Choose enterprise configuration when:
- Production workloads require consistent performance
- Reasoning stability matters more than deployment cost
- Multi-user access demands concurrent request handling
- Tasks involve sustained 200-300 tool invocation sequences
Choose consumer hardware when:
- Research and development work tolerates slower inference
- Budget constraints prevent enterprise GPU access
- Single-user scenarios don’t require high throughput
- Experimentation and prototyping precede production deployment
Common mistake: Underestimating memory requirements for extended context processing. The 256K window requires substantial memory even with quantization. Ensure hardware configurations include adequate headroom beyond minimum specifications to prevent out-of-memory failures during peak usage.
Cloud vs. On-Premises Deployment
Teams evaluating deployment options face strategic infrastructure decisions:
Microsoft Azure Foundry integration (as of early 2026):[6]
- Managed K2 deployment with enterprise-grade security
- Pay-per-use pricing eliminates upfront infrastructure costs
- Automatic scaling for variable workloads
- Integration with Azure ecosystem and compliance frameworks
On-premises deployment:
- Full control over data residency and security
- Predictable costs for sustained high-volume usage
- Customization flexibility for specialized workflows
- Requires internal GPU infrastructure management
Organizations using MULTIBLY’s platform can access multiple deployment options through a unified interface, routing tasks to optimal infrastructure based on performance requirements and cost constraints.
How Are Context Windows Reshaping the Competitive Landscape?
The race for longer memory in LLMs reveals diverging strategic priorities across providers, with Context Windows as a Competitive Advantage: Kimi K2’s 256K and the Race for Longer Memory in LLMs representing a specific approach that prioritizes reasoning stability over maximum capacity.
The Open-Weight Movement
By early 2026, the K2 model family became one of the most downloaded open-weight LLM series on Hugging Face, representing China’s entry into the “era of thinking models” with capabilities previously exclusive to closed-source systems.[7] This shift challenges the competitive dynamics that favored proprietary models.
Strategic implications:
- Democratized access: Extended context capabilities reach researchers, startups, and organizations unable to afford closed-source API costs
- Customization potential: Open weights enable fine-tuning for domain-specific applications, creating specialized variants optimized for particular industries
- Transparency: Architectural details and training approaches become public knowledge, accelerating community innovation
- Competitive pressure: Closed-source providers must justify premium pricing against increasingly capable open alternatives
Differentiation Beyond Raw Specifications
The competitive landscape increasingly differentiates on implementation quality rather than specification maximums:
Reasoning stability (K2’s focus): Maintaining coherent reasoning across 200-300 tool invocations matters more for production workflows than theoretical million-token capacity that degrades in extended sequences.[3][6]
Deployment flexibility: Supporting diverse hardware configurations—from enterprise GPU clusters to consumer hardware—expands addressable market beyond organizations with unlimited infrastructure budgets.[5]
Ecosystem integration: Adjacent tooling like Kimi Code (Apache 2.0 open-source coding agent) and Agent SDK for custom agent development expands competitive surface area beyond raw model capability.[8]
Cost efficiency: INT4 quantization and MoE architecture deliver production-grade performance at lower computational cost than monolithic models, changing total cost of ownership calculations.[6]
Market Segmentation by Use Case
Extended context windows create natural market segmentation based on task requirements:
High-capacity passive storage (GPT-4.1’s 1M tokens):
- Massive document collections requiring reference access
- Extreme edge cases with hundreds of documents
- Marketing differentiation through maximum specifications
- Limited practical applications justify the capacity
Balanced working memory (K2’s 256K, Claude’s 200K):
- Sustained reasoning tasks requiring stable coherence
- Complete codebase or document analysis
- Multi-stage research and synthesis workflows
- Production agentic systems with hundreds of tool calls
Optimized general-purpose (GPT-4o’s 128K):
- Broad task coverage with balanced performance
- Standard document processing and analysis
- Conversational applications with moderate context needs
- Cost-optimized deployment for typical workloads
Teams using MULTIBLY’s features benefit from this segmentation through intelligent routing—matching task requirements with optimal model selection based on context needs, reasoning stability requirements, and cost constraints.
The Reasoning Model Paradigm
K2’s January 2026 K2.5 release introduced native multimodal capabilities and an agent swarm paradigm, advancing from the November 2025 K2 Thinking variant.[2] This evolution reflects a broader industry shift toward reasoning models that treat context windows as infrastructure for sustained thinking rather than passive information storage.
Key characteristics of reasoning model competition:
- Multi-stage reflection: Models that can revisit and revise earlier conclusions across extended sequences
- Tool invocation stability: Reliable execution of hundreds of sequential function calls without reasoning drift
- State management: Maintaining variables, dependencies, and intermediate results across complex workflows
- Iterative refinement: Supporting continuous improvement cycles within single inference sessions
This paradigm shift changes competitive evaluation criteria. Raw benchmarks measuring single-turn performance become less relevant than assessments of sustained reasoning quality across extended task sequences.
Future Competitive Dynamics
The trajectory suggests several emerging competitive dimensions:
Efficiency optimization: As context windows expand, computational efficiency becomes critical differentiator. Models delivering extended context at lower cost gain advantage in production deployments.
Specialized architectures: Domain-specific optimizations—legal document analysis, code reasoning, scientific research—may fragment the market beyond general-purpose models.
Hybrid approaches: Combining extended context with retrieval-augmented generation (RAG) or external memory systems may deliver better performance than pure context expansion.
Reasoning verification: As models handle more complex tasks, mechanisms for validating reasoning quality across extended sequences become competitive differentiators.
What Are the Practical Limitations of Extended Context Windows?
Extended context windows deliver measurable advantages for specific tasks, but they introduce practical constraints that affect deployment decisions and use case selection.
Computational Cost and Latency
Processing 256K tokens requires substantially more computation than shorter contexts, creating direct trade-offs between capability and performance:
Inference latency: Generating responses from 256K context takes longer than from 8K context, even with optimized architectures. K2 achieves 50-100 tokens/second on enterprise hardware, but this represents significant latency for interactive applications.[5]
Memory bandwidth: Large contexts stress GPU memory bandwidth, potentially creating bottlenecks that limit throughput regardless of computational capacity.
Cost per token: Extended context processing costs more per generated token, affecting economics for high-volume applications. Organizations must evaluate whether task requirements justify the additional cost.
Energy consumption: Larger contexts consume more energy per inference, introducing environmental and operational cost considerations for sustained production workloads.
Quality Degradation Patterns
Even well-architected extended context implementations show specific degradation patterns:
Attention dilution: As context grows, the model’s attention mechanism must distribute across more tokens, potentially reducing focus on critical information. This affects tasks requiring precise detail extraction from specific context segments.
Reasoning drift: While K2’s architecture specifically addresses this through working memory design, even optimized implementations show gradual coherence degradation in extreme edge cases beyond typical usage patterns.[3]
Hallucination risk: Larger contexts provide more opportunities for the model to generate plausible but incorrect information, particularly when synthesizing across many documents with contradictory details.
Retrieval accuracy: Finding and correctly utilizing specific information within 256K tokens becomes challenging, particularly when relevant details appear in multiple locations with subtle variations.
Task-Specific Limitations
Extended context windows don’t uniformly improve all task types:
Real-time applications: Latency requirements for conversational AI or interactive tools often conflict with extended context processing time. Shorter contexts deliver better user experience for these scenarios.
Structured data processing: Tasks involving databases, spreadsheets, or highly structured information often perform better with specialized tools than language model context windows, regardless of size.
Frequent context updates: Applications requiring continuous context modification—like collaborative editing or streaming data analysis—face efficiency challenges with large context windows that must be rebuilt frequently.
Simple tasks: Straightforward summarization, translation, or Q&A operations don’t benefit from extended context and incur unnecessary latency and cost overhead.
Deployment and Operational Constraints
Production deployments face practical challenges beyond raw capability:
Infrastructure requirements: The 630GB storage and 8× GPU configuration for enterprise deployment represents significant capital investment that may exceed budget constraints for smaller organizations.[5]
Scaling complexity: Distributed inference across multiple GPUs introduces coordination overhead and potential failure points that simpler deployments avoid.
Monitoring and debugging: Tracking reasoning quality across 256K token contexts and hundreds of tool invocations requires sophisticated observability tooling beyond standard logging.
Version management: Model updates and fine-tuning become more complex with large contexts, as validation must confirm reasoning stability across extended sequences rather than just benchmark performance.
Common mistake: Deploying extended context models for all tasks regardless of requirements. In practice, maintain a portfolio approach—use extended context for tasks that genuinely require it, and route simpler operations to faster, cheaper models. Platforms like MULTIBLY enable this intelligent routing without manual intervention.
When to Choose Shorter Contexts
Specific scenarios favor shorter context windows despite extended capacity availability:
Choose shorter contexts when:
- Task completion time matters more than comprehensive context
- Budget constraints require cost optimization
- Simple operations don’t require cross-document reasoning
- Real-time interaction demands low latency
- Structured data queries better suit database tools
Choose extended contexts when:
- Task requires maintaining coherence across complete documents or codebases
- Reasoning chains span hundreds of logical steps
- Multi-document synthesis demands cross-referencing without re-reading
- Agentic workflows require stable execution across 200+ tool calls
- Quality improvements justify additional latency and cost
FAQ
What is a context window in large language models? A context window defines how many tokens (roughly words or word pieces) a language model can actively process in a single session. Kimi K2’s 256K context window holds approximately 190,000 words, enabling the model to maintain awareness of entire documents, codebases, or multi-document collections without chunking or losing information across segments.[2]
How does Kimi K2’s 256K context compare to GPT-4? K2’s 256K token window doubles GPT-4o’s 128K capacity but falls short of GPT-4.1’s 1 million tokens. The practical difference lies in implementation: K2 emphasizes working memory stability for sustained reasoning across 200-300 tool invocations, while GPT-4.1 prioritizes maximum passive storage capacity.[7] For most production tasks requiring extended reasoning, K2’s architecture delivers more reliable results than raw capacity alone.
What tasks benefit most from extended context windows? Complete codebase analysis, multi-document research synthesis, lengthy legal document review, and agentic workflows requiring hundreds of sequential tool calls show the most dramatic improvements with extended context.[3] Tasks requiring sustained coherence across large information sets—where chunking would break logical connections—justify the additional computational cost of processing 256K tokens.
Can I run Kimi K2 on consumer hardware? Yes, but with significant performance trade-offs. A single RTX 4090 with 256GB system RAM can run K2 using 1.58-bit quantization at 1-2 tokens/second, while RTX 3090 configurations achieve approximately 7 tokens/second with optimized quantization.[2][5] Enterprise deployment on 8× H100 GPUs delivers 50-100 tokens/second for production workloads.[5]
What infrastructure do I need for production deployment? Production-grade performance requires 8× H100 80GB or 8× A100 80GB GPUs with approximately 630GB storage for INT4 quantized weights.[5] Alternative deployment through Microsoft Azure Foundry provides managed infrastructure without upfront hardware investment.[6] Choose on-premises for data residency control and predictable high-volume costs, or cloud for variable workloads and reduced infrastructure management.
How does context window size affect cost? Larger contexts require more computation per token generated, directly increasing cost. Processing 256K tokens costs substantially more than 8K tokens, though the exact multiplier depends on pricing model and deployment configuration. Evaluate whether task quality improvements justify additional cost—use extended context only when task requirements demand it, not as default configuration.
What is the difference between working memory and passive storage in context windows? Working memory architectures (like K2’s approach) maintain active reasoning state across extended sequences, supporting stable tool invocation chains and multi-stage reflection.[3] Passive storage implementations provide reference access to earlier text but experience reasoning drift in extended sequences. The difference becomes critical for tasks requiring sustained coherence across hundreds of reasoning steps.
Does longer context always mean better performance? No. Extended context introduces latency, increases cost, and can dilute attention across too many tokens. Simple tasks perform better with shorter contexts that deliver faster responses at lower cost. Use the minimum context necessary for task completion—extended windows should support specific capabilities, not serve as default configuration regardless of requirements.
How does Kimi K2 maintain reasoning stability across 256K tokens? K2 uses a mixture-of-experts architecture with native INT4 quantization specifically designed to prevent reasoning drift during deep thinking sequences.[6] The model achieves stable execution across 200-300 sequential tool calls through working memory design that maintains logical dependencies and reasoning state across extended sequences.[3] This architectural approach prioritizes stability over raw capacity.
What are the main limitations of extended context windows? Computational cost and latency increase with context size, affecting economics for high-volume applications. Attention dilution can reduce focus on critical details within massive contexts. Infrastructure requirements for production deployment—8× GPUs and 630GB storage—represent significant capital investment.[5] Real-time applications often require shorter contexts despite extended capacity availability to meet latency requirements.
Is Kimi K2 available as open-source? K2 is released as an open-weight model, meaning the trained weights are publicly available but the training data and complete training process may not be fully disclosed. By early 2026, K2 became one of the most downloaded open-weight LLM series on Hugging Face.[7] This enables customization, fine-tuning, and on-premises deployment while maintaining transparency about model architecture and capabilities.
How do I choose between different context window sizes for my use case? Match context size to task requirements: use 256K for complete codebase analysis, multi-document synthesis, or agentic workflows requiring hundreds of tool calls; use 128K for standard document processing and analysis; use shorter contexts for simple Q&A, summarization, or real-time applications. Platforms like MULTIBLY enable intelligent routing based on task characteristics, optimizing performance and cost without manual model selection.
Conclusion
Context Windows as a Competitive Advantage: Kimi K2’s 256K and the Race for Longer Memory in LLMs demonstrates that extended context capabilities deliver genuine competitive advantage when architectural implementation supports sustained reasoning rather than just passive information storage. K2’s 256K token capacity enables processing approximately 190,000 words with stable reasoning across 200-300 sequential tool invocations, fundamentally changing which tasks AI can reliably complete.
The practical implications extend beyond raw specifications. Organizations evaluating extended context models should focus on task-architecture fit rather than maximum capacity numbers. Complete codebase analysis, multi-document research synthesis, lengthy legal document review, and complex agentic workflows show measurable quality improvements that justify the additional computational cost and infrastructure requirements. Simple tasks benefit more from faster, cheaper models with shorter contexts.
Actionable Next Steps
For development teams: Evaluate current workflows to identify tasks requiring sustained coherence across large information sets. Test K2 on representative workloads—complete repository refactoring, multi-stage research synthesis, or extended tool invocation sequences—to measure quality improvements against infrastructure costs.
For enterprise decision-makers: Compare deployment options between on-premises GPU infrastructure (8× A100/H100 configuration) and managed cloud services through Microsoft Azure Foundry. Calculate total cost of ownership including infrastructure, operations, and per-token processing costs for anticipated workload volumes.
For researchers and startups: Explore consumer hardware deployment options using quantized versions on RTX 4090 or Mac Studio M3 Ultra configurations for prototyping and development work. Validate reasoning stability on representative tasks before committing to production infrastructure.
For AI strategy leaders: Implement intelligent routing systems that match task requirements with optimal model selection. Platforms like MULTIBLY enable this portfolio approach, using extended context only when task characteristics justify the additional cost while routing simpler operations to faster, cheaper alternatives.
The race for longer memory in LLMs continues, but the competitive advantage emerges from how models use context, not just how much they can theoretically hold. K2’s working memory architecture demonstrates that 256K tokens of stable, coherent reasoning delivers more practical value than million-token passive storage that degrades across extended sequences. Organizations that match context window capabilities with genuine task requirements—rather than chasing maximum specifications—will extract the most value from extended memory investments.
References
[1] Kimi K25 In 2026 The Ultimate Guide To Open Source Visual Agentic Intelligence 18od – https://dev.to/czmilo/kimi-k25-in-2026-the-ultimate-guide-to-open-source-visual-agentic-intelligence-18od
[2] Kimi K2 – https://www.leanware.co/insights/kimi-k2
[3] Kimi K2 Thinking Cn Awakening – https://jimmysong.io/blog/kimi-k2-thinking-cn-awakening/
[4] Kimi K2 Thinking How To Run Locally – https://unsloth.ai/docs/models/tutorials/kimi-k2-thinking-how-to-run-locally
[5] Kimi K2 5 Paper Parameters Requirements Guide En – https://help.apiyi.com/en/kimi-k2-5-paper-parameters-requirements-guide-en.html
[6] techcommunity.microsoft – https://techcommunity.microsoft.com/blog/azure-ai-foundry-blog/kimi-k2-thinking-now-in-microsoft-foundry/4476116
[7] Kimi K2 Open Weight Llm Analysis – https://intuitionlabs.ai/articles/kimi-k2-open-weight-llm-analysis
[8] Ainews Moonshot Kimi K25 Beats Sonnet – https://www.latent.space/p/ainews-moonshot-kimi-k25-beats-sonnet
Our Fact Checking Process
We prioritize accuracy and integrity in our content. Here's how we maintain high standards:
- Expert Review: All articles are reviewed by subject matter experts.
- Source Validation: Information is backed by credible, up-to-date sources.
- Transparency: We clearly cite references and disclose potential conflicts.
Our Review Board
Our content is carefully reviewed by experienced professionals to ensure accuracy and relevance.
- Qualified Experts: Each article is assessed by specialists with field-specific knowledge.
- Up-to-date Insights: We incorporate the latest research, trends, and standards.
- Commitment to Quality: Reviewers ensure clarity, correctness, and completeness.
Look for the expert-reviewed label to read content you can trust.



