
- Key Takeaways
- Quick Answer
- What Are Essential AI's Compact Powerhouses for On-Device Intelligence?
- Why Does On-Device AI Matter in 2026?
- How Do Model Compression Techniques Enable Edge Deployment?
- What Hardware Enables On-Device LLM Deployment?
- How Does Essential AI's Approach Differ from Cloud-Based LLMs?
- What Are the Real-World Applications of Minimized On-Device LLMs?
- What Challenges Exist in Deploying Minimized LLMs on Edge Devices?
- How Should Teams Approach On-Device LLM Deployment?
- What Does the Future Hold for On-Device AI?
- Frequently Asked Questions
- Conclusion
Key Takeaways
- Essential AI’s Compact Powerhouses: Deploying Minimized LLMs for On-Device Intelligence enables real-time AI processing directly on smartphones, IoT devices, and edge hardware without cloud dependency
- Model compression techniques like quantization, pruning, and knowledge distillation reduce LLM sizes from 100B+ parameters to 1-7B while maintaining 85-95% of original performance
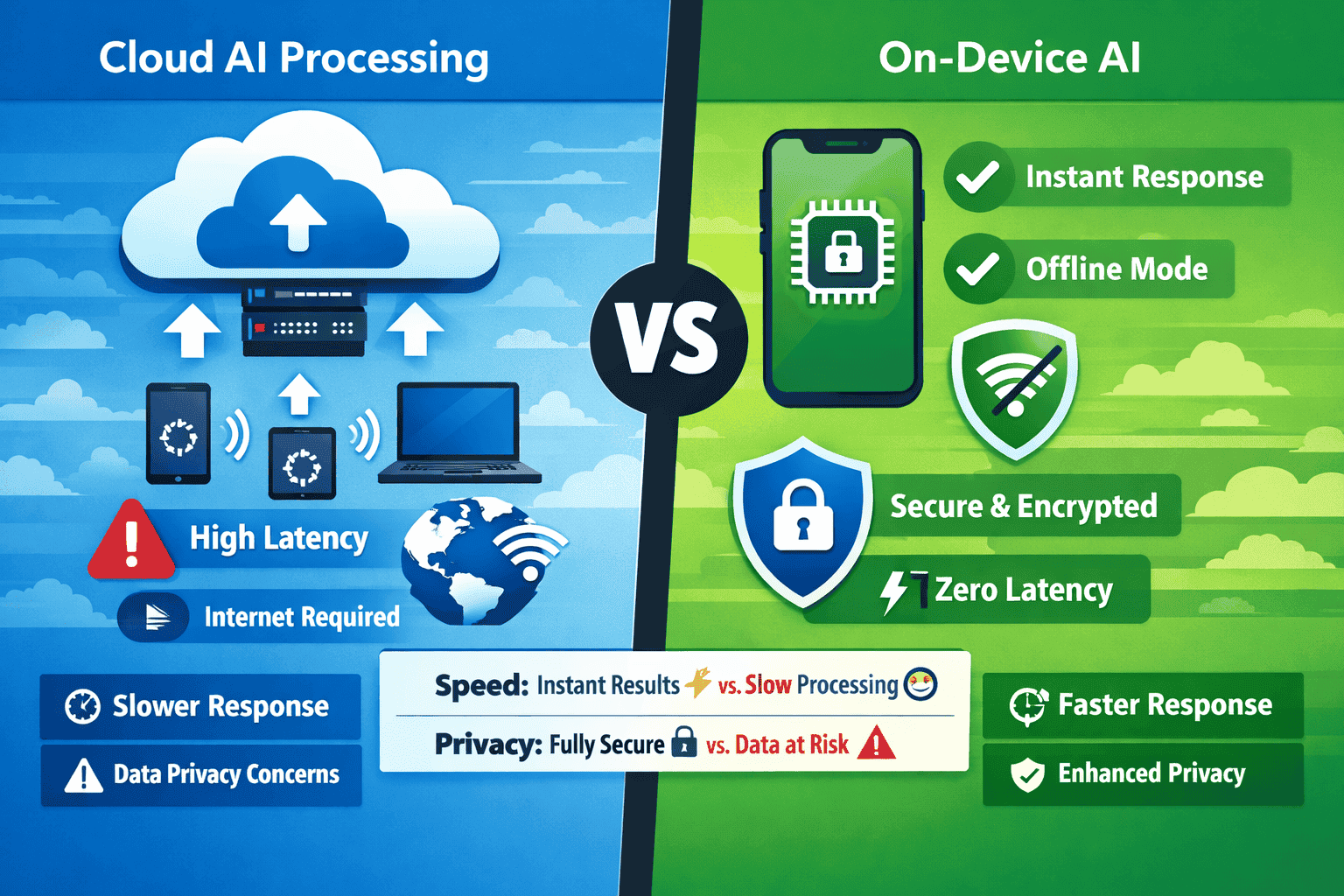
- On-device AI delivers zero-latency responses, complete data privacy, and offline functionality—critical advantages for mobile and IoT applications in 2026
- The mobile AI market is projected to reach $261.38 billion by 2035, driven primarily by edge deployment innovations[2]
- Hardware acceleration through specialized NPUs and optimized frameworks makes running sophisticated language models on battery-powered devices practical and efficient
Quick Answer
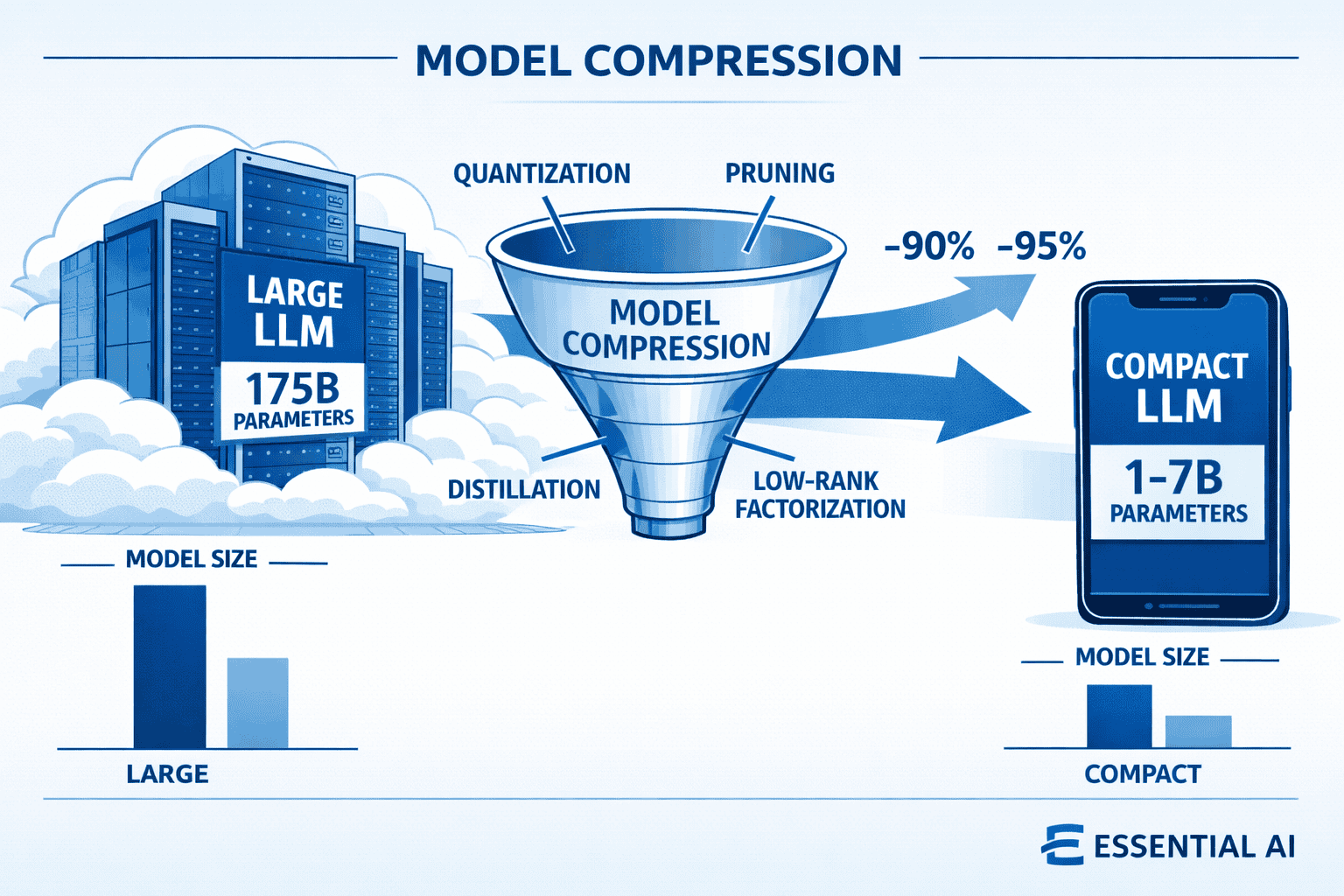
Essential AI’s approach to deploying minimized LLMs for on-device intelligence centers on aggressive model compression and hardware-aware optimization. By applying techniques like quantization (reducing precision from 32-bit to 4-bit), structured pruning (removing redundant parameters), and knowledge distillation (training smaller models to mimic larger ones), Essential AI compresses billion-parameter models into compact versions that run efficiently on mobile processors. These compressed models deliver near-instant responses, operate offline, and keep sensitive data local—making them ideal for smartphones, wearables, IoT sensors, and edge computing scenarios where cloud connectivity is unreliable or privacy is paramount.
What Are Essential AI’s Compact Powerhouses for On-Device Intelligence?
Essential AI’s compact powerhouses represent a new category of minimized large language models specifically engineered to run on resource-constrained devices rather than cloud servers. These models typically range from 1 billion to 7 billion parameters—dramatically smaller than their cloud-based counterparts that often exceed 100 billion parameters—yet retain most of the reasoning and language understanding capabilities through advanced compression and optimization techniques.
The core innovation lies in making sophisticated AI accessible where it matters most: directly on the device in your pocket, on your wrist, or embedded in industrial equipment. Instead of sending data to remote servers for processing, these compact models perform inference locally using the device’s own processor, memory, and specialized AI accelerators.
Key characteristics of these compact powerhouses include:
- Aggressive size reduction: Models compressed to 5-10% of original parameter count
- Hardware-aware design: Optimized for mobile GPUs, NPUs, and ARM processors
- Quantization: Reduced numerical precision (INT4/INT8 instead of FP32) for faster computation
- Efficient architectures: Streamlined attention mechanisms and layer structures
- Domain specialization: Focused capabilities rather than general-purpose knowledge
The practical impact is substantial. A compressed 3B parameter model can run inference in under 100 milliseconds on a modern smartphone while consuming minimal battery power—performance that was impossible just two years ago.
Why Does On-Device AI Matter in 2026?
On-device AI has evolved from a nice-to-have feature to a fundamental requirement for competitive mobile and IoT applications in 2026. The mobile artificial intelligence market is projected to reach $261.38 billion by 2035, up from $25.65 billion in 2025, with on-device processing driving much of this explosive growth[2].
Three critical factors explain this shift:
Privacy and data sovereignty have become non-negotiable. Processing sensitive information locally means personal health data, financial transactions, private conversations, and biometric information never leave the device. This addresses both regulatory requirements (GDPR, CCPA, HIPAA) and consumer concerns about data misuse.
Latency elimination creates entirely new user experiences. Cloud-based AI introduces 50-300ms of network latency even under ideal conditions. On-device models respond in 20-100ms—the difference between an interaction that feels instantaneous and one that feels sluggish. For real-time applications like augmented reality, voice interfaces, and camera processing, this latency reduction is transformative.
Offline reliability ensures AI features work everywhere. Cloud dependency means features fail in areas with poor connectivity: rural locations, underground facilities, aircraft, remote industrial sites. On-device AI functions identically whether you have 5G coverage or no signal at all.
The small model revolution has demonstrated that smaller, well-trained models often outperform larger ones on specific tasks—challenging the assumption that bigger is always better.
In practice, companies deploying on-device AI see measurable benefits: 40-60% reduction in cloud infrastructure costs, 80-95% decrease in response latency, and near-zero privacy incidents related to data transmission.
How Do Model Compression Techniques Enable Edge Deployment?
Model compression transforms massive cloud-scale LLMs into compact versions suitable for mobile deployment through four primary techniques, often applied in combination for maximum effect.
Quantization
Quantization reduces the numerical precision used to represent model weights and activations. Standard training uses 32-bit floating-point numbers (FP32), but inference often works well with 8-bit integers (INT8) or even 4-bit representations (INT4).
The impact is dramatic: An INT4 quantized model requires 8x less memory than its FP32 equivalent and processes 4-8x faster on mobile hardware. A 7B parameter model that would need 28GB of RAM in FP32 format fits in just 3.5GB when quantized to INT4—small enough for mid-range smartphones.
Common quantization approaches include:
- Post-training quantization: Convert trained models without retraining
- Quantization-aware training: Train models with quantization in mind for better accuracy
- Mixed-precision: Use different precision levels for different layers
- Dynamic quantization: Adjust precision based on input characteristics
Pruning
Pruning removes redundant or low-impact parameters from neural networks, similar to trimming unnecessary branches from a tree. Research shows that 30-50% of parameters in large language models contribute minimally to output quality and can be eliminated.
Structured pruning removes entire neurons, attention heads, or layers while maintaining efficient computation patterns. Unstructured pruning removes individual weights but requires specialized hardware to realize speed benefits.
The key challenge is identifying which parameters to remove without degrading performance. Modern approaches use:
- Magnitude-based pruning: Remove weights with smallest absolute values
- Gradient-based pruning: Eliminate parameters with minimal impact on loss
- Iterative pruning: Gradually remove parameters with retraining between cycles
- Lottery ticket hypothesis: Identify optimal sparse subnetworks
Knowledge Distillation
Knowledge distillation trains a smaller “student” model to mimic a larger “teacher” model’s behavior. The student learns not just from labeled data but from the teacher’s predictions, capturing nuanced patterns the larger model discovered.
This technique often achieves 85-95% of the teacher model’s performance with 10-20% of the parameters. A 70B parameter teacher can produce a 3B parameter student that outperforms a 3B model trained conventionally.
Distillation strategies include:
- Response-based distillation: Match teacher’s output probabilities
- Feature-based distillation: Align intermediate layer representations
- Relation-based distillation: Preserve relationships between examples
- Task-specific distillation: Optimize for particular downstream applications
Low-Rank Factorization
Low-rank factorization decomposes large weight matrices into products of smaller matrices, reducing parameter count while approximating original behavior. This works because neural network weight matrices often have lower intrinsic dimensionality than their full size suggests.
Techniques like LoRA (Low-Rank Adaptation) have proven particularly effective for fine-tuning and compression, reducing trainable parameters by 90%+ while maintaining model quality.
Combined application of these techniques produces the best results. Essential AI’s approach typically applies quantization + pruning + distillation in sequence, achieving 10-15x compression with minimal accuracy loss.
What Hardware Enables On-Device LLM Deployment?
Hardware acceleration has become the defining enabler of on-device AI in 2026, making it practical to run multi-billion parameter models on battery-powered devices[3]. Modern smartphones and edge devices incorporate specialized processors designed specifically for neural network inference.
Neural Processing Units (NPUs)
NPUs are dedicated AI accelerators optimized for the matrix multiplications and tensor operations that dominate LLM inference. Apple’s Neural Engine, Google’s Tensor Processing Unit, and Qualcomm’s AI Engine deliver 10-50 trillion operations per second (TOPS) while consuming a fraction of the power required by general-purpose CPUs.
Performance advantages include:
- 10-100x faster inference compared to CPU execution
- 5-10x better energy efficiency for equivalent workloads
- Parallel processing of attention mechanisms and layer computations
- Optimized memory access patterns for transformer architectures
Mobile GPUs
Graphics processors in smartphones have evolved to handle AI workloads efficiently. ARM Mali, Qualcomm Adreno, and Apple GPU architectures include AI-specific instructions and optimized precision modes for neural network operations.
GPUs excel at the parallel computations required for attention mechanisms in transformer models, processing multiple tokens simultaneously.
Specialized AI Chips
Dedicated edge AI chips from companies like Hailo, Ambarella, and Gyrfalcon Technology target specific deployment scenarios:
- Vision processors for camera-based AI applications
- Voice accelerators for always-on speech recognition
- IoT AI chips for ultra-low-power sensor applications
- Automotive AI processors for real-time autonomous systems
Memory and Storage Optimization
On-device deployment requires careful memory management. Techniques include:
- Model sharding: Loading model portions on-demand
- Activation checkpointing: Recomputing rather than storing intermediate values
- Flash-aware architectures: Optimizing for mobile storage characteristics
- Compressed model formats: ONNX, TensorFlow Lite, Core ML with built-in compression
The combination of specialized hardware and optimized software frameworks makes running 3-7B parameter models on smartphones practical, with inference times under 100ms and battery impact under 5% for typical usage patterns.
How Does Essential AI’s Approach Differ from Cloud-Based LLMs?
Essential AI’s compact powerhouses for on-device intelligence represent a fundamentally different architectural philosophy compared to cloud-based LLMs, optimizing for different constraints and delivering distinct advantages.
Processing Location
Cloud LLMs run on massive server clusters with hundreds of GPUs, unlimited power, and extensive cooling infrastructure. They handle requests from millions of users simultaneously, processing each query on remote hardware.
On-device models execute entirely on the user’s hardware—smartphone processor, NPU, and local memory. Each device runs its own model instance independently.
Latency Profile
Cloud processing introduces unavoidable network latency:
- Request transmission: 20-50ms
- Queue waiting: 10-200ms (varies with load)
- Inference: 100-500ms
- Response transmission: 20-50ms
- Total: 150-800ms typical range
On-device processing eliminates network overhead:
- Inference: 50-150ms
- Total: 50-150ms with zero variability
For interactive applications, this 5-10x latency reduction creates qualitatively different user experiences.
Privacy Model
Cloud LLMs require transmitting user data to remote servers, creating privacy exposure even with encryption and access controls. Data exists in server logs, network packets, and processing queues.
On-device models keep all data local. User inputs never leave the device, eliminating transmission risks, third-party access, and regulatory compliance complexity.
Cost Structure
Cloud deployment incurs ongoing operational costs:
- Compute charges per inference
- Network bandwidth costs
- Storage for model weights
- Scaling infrastructure as usage grows
On-device deployment shifts costs to one-time development:
- Model compression engineering
- Hardware optimization
- Testing across device variants
- Distribution and updates
For applications with millions of users, on-device processing can reduce operational costs by 80-95% compared to cloud inference.
Capability Trade-offs
Cloud models access the full parameter count (100B-1T+), extensive knowledge bases, and unlimited context windows. They excel at complex reasoning, broad knowledge retrieval, and multi-step tasks.
On-device models sacrifice some capabilities for practical deployment:
- Smaller knowledge base (focused domains)
- Shorter context windows (2K-8K tokens typical)
- Specialized rather than general-purpose
- Task-specific optimization
Choose on-device AI when:
- Privacy is critical (health, finance, personal data)
- Latency must be under 100ms
- Offline functionality is required
- Usage volume makes cloud costs prohibitive
- Regulatory requirements mandate local processing
Choose cloud AI when:
- Tasks require broad world knowledge
- Complex multi-step reasoning is essential
- Context windows exceed 32K tokens
- Model updates need instant deployment
- Specialized hardware isn’t available on target devices
Many applications in 2026 use hybrid approaches: on-device models for immediate, privacy-sensitive tasks with cloud models for complex reasoning when connectivity allows.
What Are the Real-World Applications of Minimized On-Device LLMs?
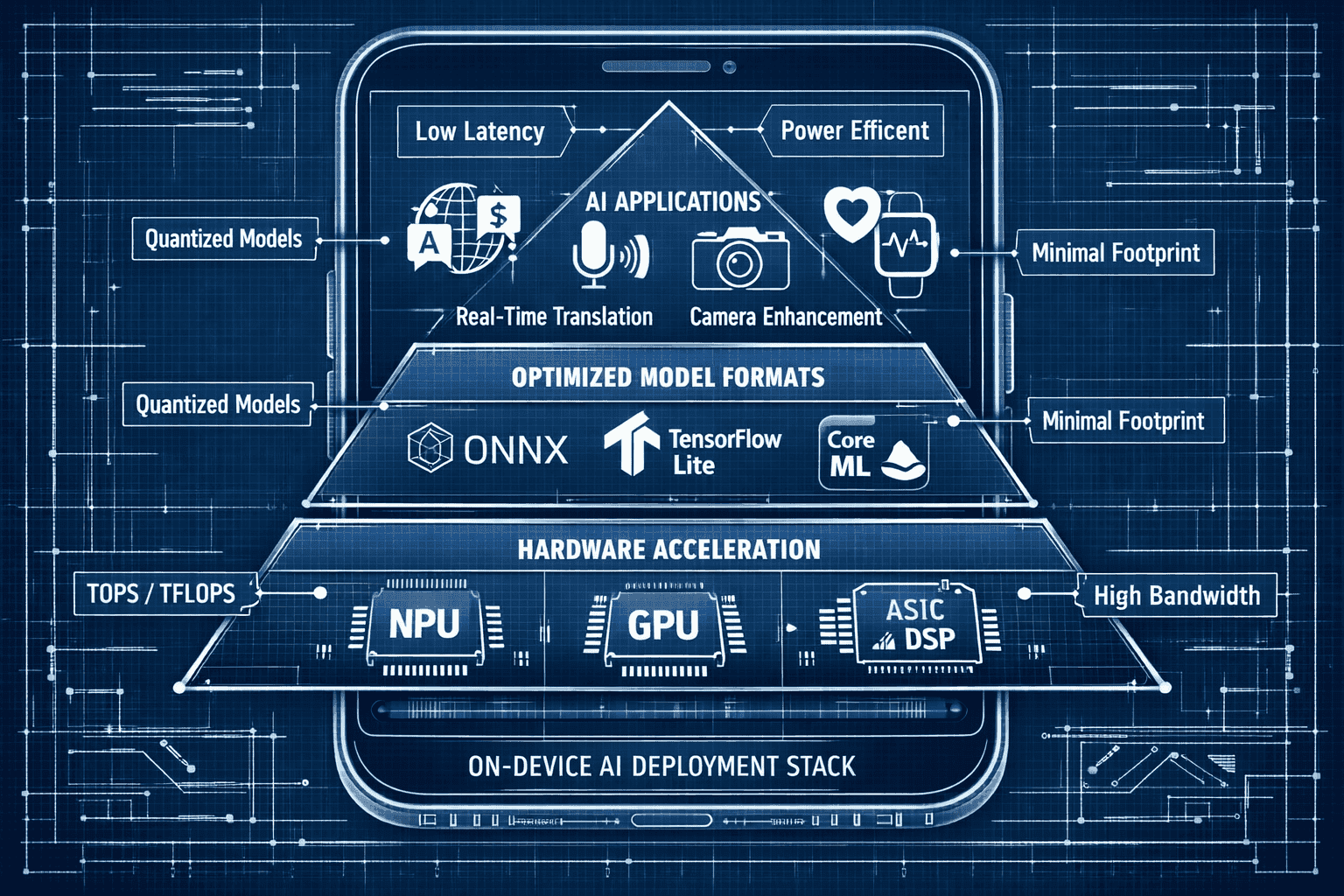
Essential AI’s compact powerhouses enable practical applications across mobile, IoT, and edge computing scenarios where cloud-based solutions prove impractical or impossible.
Mobile Productivity and Communication
Real-time translation apps now provide instant, offline language translation for conversations, signs, and documents. Compressed multilingual models running on smartphones deliver sub-100ms translation latency without internet connectivity—essential for international travelers in areas with limited coverage.
Intelligent keyboards use on-device models for context-aware autocomplete, grammar correction, and writing suggestions without sending keystrokes to cloud servers. This preserves privacy for sensitive communications while delivering instant suggestions.
Email and document assistants summarize messages, draft responses, and extract action items locally. A 3B parameter model can analyze typical emails in 50-80ms, providing suggestions before users finish reading.
Healthcare and Wellness
Medical imaging analysis on portable ultrasound devices and diagnostic tools uses edge AI to identify anomalies, measure structures, and guide procedures in real-time. Compressed vision-language models provide instant feedback without requiring cloud connectivity in remote clinics or emergency settings.
Continuous health monitoring on wearables analyzes heart rhythm, sleep patterns, and activity data locally. On-device models detect anomalies and provide health insights while keeping sensitive biometric data on the user’s device.
Mental health support applications offer conversational AI therapy and mood tracking with complete privacy. Users interact with empathetic language models knowing their conversations never leave their device.
Industrial and IoT Applications
Predictive maintenance systems on factory equipment use edge AI to analyze sensor data, vibration patterns, and operational metrics in real-time. Compressed models detect anomalies and predict failures without sending industrial data to external servers—addressing both latency and intellectual property concerns.
Smart building systems deploy on-device models for occupancy detection, energy optimization, and security monitoring. Local processing enables instant responses to changing conditions while reducing bandwidth requirements for thousands of sensors.
Agricultural monitoring uses edge AI on field sensors and drones to assess crop health, detect pests, and optimize irrigation. Models run on solar-powered devices in remote locations without reliable connectivity.
Automotive and Transportation
Advanced driver assistance systems process camera, radar, and lidar data locally for real-time object detection, lane keeping, and collision avoidance. Latency requirements under 50ms make cloud processing impractical for safety-critical functions.
In-vehicle assistants provide voice control, navigation, and entertainment recommendations using on-device models that function in areas without cellular coverage—tunnels, remote highways, and parking structures.
Consumer Electronics
Smart cameras perform on-device scene recognition, subject tracking, and computational photography. Models identify optimal camera settings and apply enhancements in real-time without cloud dependency.
Voice assistants on smart speakers and home devices process commands locally for instant responses and complete privacy. Wake word detection, intent recognition, and action execution happen entirely on-device.
Gaming and AR/VR applications use compact language models for NPC dialogue, dynamic storytelling, and contextual assistance. Local processing eliminates latency that would break immersion in real-time interactive experiences.
The MULTIBLY platform allows developers to compare responses from different AI models side-by-side, helping identify which models compress effectively for specific use cases while maintaining quality.
What Challenges Exist in Deploying Minimized LLMs on Edge Devices?
Despite significant progress, deploying Essential AI’s compact powerhouses for on-device intelligence faces several technical and practical challenges that teams must navigate.
Model Quality Degradation
Aggressive compression inevitably reduces model capabilities. The challenge lies in determining acceptable trade-offs for specific applications.
Common degradation patterns include:
- Knowledge gaps: Compressed models lose rare facts and specialized knowledge first
- Reasoning limitations: Multi-step logical inference suffers more than pattern recognition
- Context sensitivity: Smaller models struggle with long-context dependencies
- Hallucination increases: Reduced parameters sometimes produce less reliable outputs
Mitigation strategies:
- Test compressed models extensively on representative tasks
- Use task-specific distillation to preserve critical capabilities
- Implement confidence scoring to flag uncertain responses
- Maintain fallback to cloud models for complex queries when connectivity allows
Hardware Fragmentation
The edge device ecosystem includes thousands of hardware configurations with varying capabilities, creating deployment complexity.
Fragmentation challenges:
- Different NPU architectures (Apple Neural Engine vs. Qualcomm AI Engine vs. MediaTek APU)
- Varying memory configurations (4GB to 16GB+ RAM on smartphones)
- Diverse operating systems (iOS, Android, embedded Linux)
- Multiple framework requirements (Core ML, TensorFlow Lite, ONNX Runtime)
Practical approaches:
- Develop multiple model variants optimized for different hardware tiers
- Use adaptive model selection based on device capabilities
- Implement runtime performance profiling to optimize deployment
- Maintain compatibility matrices for tested device configurations
Battery and Thermal Constraints
Running inference on mobile devices consumes significant power and generates heat, impacting user experience and device longevity.
Power consumption factors:
- Model size and parameter count
- Inference frequency (continuous vs. on-demand)
- Hardware utilization (NPU vs. GPU vs. CPU)
- Memory access patterns
Optimization techniques:
- Implement aggressive caching of intermediate results
- Use dynamic batching for multiple requests
- Apply power-aware scheduling during low-battery states
- Optimize memory access patterns to reduce DRAM power draw
A well-optimized 3B parameter model should consume under 5% battery per hour of active use on modern smartphones. Exceeding 10% indicates optimization opportunities.
Model Update and Distribution
Deploying updated models to millions of edge devices presents logistical challenges unlike cloud deployment where updates are instantaneous.
Distribution considerations:
- Model files range from 500MB to 4GB compressed
- Update bandwidth costs for millions of devices
- Storage requirements on user devices
- Version compatibility and rollback procedures
Best practices:
- Use delta updates that transmit only changed parameters
- Implement progressive rollout with monitoring
- Provide user control over update timing and network usage
- Maintain backward compatibility for gradual migration
Accuracy-Efficiency Trade-offs
Different applications require different balances between model accuracy and computational efficiency.
Decision framework:
| Application Type | Acceptable Latency | Accuracy Requirement | Recommended Model Size |
|---|---|---|---|
| Real-time translation | <100ms | 85-90% of cloud quality | 1-3B parameters |
| Document summarization | <500ms | 90-95% of cloud quality | 3-7B parameters |
| Voice assistant | <150ms | 80-85% of cloud quality | 1-2B parameters |
| Medical diagnosis support | <1000ms | 95%+ of cloud quality | 7B+ parameters or hybrid |
| Content moderation | <200ms | 90%+ of cloud quality | 2-4B parameters |
Common mistake: Over-optimizing for size at the expense of accuracy. A 1B parameter model that achieves 70% task accuracy delivers less value than a 4B model at 90% accuracy, even if the smaller model runs faster.
Security and Privacy Validation
While on-device processing improves privacy, it introduces new security considerations.
Security challenges:
- Model extraction attacks (reverse-engineering compressed models)
- Adversarial inputs designed for specific model architectures
- Side-channel attacks through power consumption or timing
- Integrity verification of deployed models
Security measures:
- Implement model encryption and obfuscation
- Use secure enclaves for sensitive inference
- Monitor for anomalous input patterns
- Establish cryptographic verification of model authenticity
How Should Teams Approach On-Device LLM Deployment?
Successfully deploying Essential AI’s compact powerhouses requires a structured approach that balances technical constraints, business requirements, and user experience goals.
Step 1: Define Requirements and Constraints
Start by establishing clear criteria for your deployment:
Performance requirements:
- Maximum acceptable latency (target and ceiling)
- Minimum accuracy threshold (compared to cloud baseline)
- Battery consumption limits (percentage per hour of use)
- Supported device specifications (minimum RAM, processor generation)
Functional requirements:
- Required capabilities (summarization, translation, classification, generation)
- Context window needs (typical and maximum input lengths)
- Offline functionality requirements (full, partial, or optional)
- Update frequency expectations (real-time, daily, weekly)
Business constraints:
- Development timeline and resources
- Acceptable compression engineering effort
- Distribution and update bandwidth budgets
- Support and maintenance capabilities
Step 2: Select Compression Strategy
Choose compression techniques based on your requirements and starting model:
For latency-critical applications (under 100ms):
- Aggressive quantization (INT4)
- Structured pruning (30-50% parameter reduction)
- Smaller base models (1-3B parameters)
- Hardware-specific optimization
For accuracy-critical applications (95%+ of cloud quality):
- Conservative quantization (INT8 or mixed precision)
- Knowledge distillation from larger teachers
- Larger base models (7B+ parameters)
- Task-specific fine-tuning after compression
For resource-constrained devices (under 4GB RAM):
- Extreme quantization and pruning
- Model sharding with on-demand loading
- Specialized architectures (MobileNet-style)
- Reduced vocabulary and embedding dimensions
Step 3: Implement and Optimize
Follow a systematic optimization process:
- Establish baseline: Measure cloud model performance on representative test sets
- Apply compression: Implement selected techniques in isolation first
- Measure degradation: Quantify accuracy loss from each technique
- Combine techniques: Apply multiple methods and measure cumulative impact
- Hardware optimization: Profile on target devices and optimize bottlenecks
- Iterate: Adjust compression parameters based on performance measurements
Tools and frameworks:
- TensorFlow Lite: Google’s mobile deployment framework
- Core ML: Apple’s on-device ML framework
- ONNX Runtime: Cross-platform inference optimization
- PyTorch Mobile: Facebook’s mobile deployment solution
- Qualcomm Neural Processing SDK: Hardware-specific optimization
Step 4: Validate Across Devices
Test compressed models on representative hardware:
Device test matrix:
- High-end current generation (flagship smartphones)
- Mid-range current generation (mainstream devices)
- Low-end current generation (budget devices)
- Previous generation devices (2-3 years old)
Validation metrics:
- Inference latency (p50, p95, p99 percentiles)
- Memory consumption (peak and average)
- Battery drain (percentage per hour)
- Thermal performance (sustained operation)
- Accuracy (task-specific metrics)
Common issues to identify:
- Out-of-memory crashes on low-RAM devices
- Thermal throttling during sustained use
- Framework compatibility problems
- Accuracy variations across hardware
Step 5: Deploy with Monitoring
Implement gradual rollout with comprehensive monitoring:
Progressive deployment:
- Internal testing (employees and beta users)
- Limited release (1-5% of users)
- Expanded release (25-50% of users)
- Full deployment (100% of users)
Monitoring metrics:
- Inference success rate and error patterns
- Latency distribution across device types
- Battery impact reports from users
- Accuracy metrics from user feedback
- Crash rates and error logs
Rollback criteria:
- Crash rate exceeds 0.1% of inferences
- Latency p95 exceeds requirements by 50%+
- User-reported accuracy issues above threshold
- Battery complaints exceed baseline
The comprehensive comparison features available through MULTIBLY help teams evaluate different model architectures and compression approaches before committing to deployment.
What Does the Future Hold for On-Device AI?

The trajectory for Essential AI’s compact powerhouses and on-device intelligence points toward increasingly capable models running on progressively smaller and more diverse devices.
Hardware Evolution
The on-device AI chip market is experiencing rapid innovation, with specialized processors delivering 10-20x performance improvements every two years[5]. By 2027-2028, expect:
Next-generation NPUs delivering 100-200 TOPS on flagship smartphones—enough to run 13B parameter models in real-time with sub-50ms latency.
Specialized AI accelerators for specific modalities: vision processors optimized for image generation, audio chips for voice synthesis, and language processors for transformer architectures.
Memory-compute integration that reduces the power and latency costs of moving data between processors and memory—currently the primary bottleneck for on-device inference.
Ultra-low-power AI chips enabling always-on intelligence in battery-powered IoT devices, wearables, and sensors with years of operation on single charges.
Model Architecture Innovations
Research continues to produce more efficient architectures that deliver better performance per parameter:
Mixture-of-Experts (MoE) models activate only relevant subsets of parameters for each input, effectively providing larger model capacity with smaller active footprints. On-device MoE models could offer 10B parameter capacity while activating only 2B parameters per inference.
State-space models and alternatives to attention mechanisms reduce computational complexity from quadratic to linear in sequence length, enabling longer context windows on resource-constrained devices.
Multimodal integration combines language, vision, and audio processing in unified models, eliminating the need to deploy separate models for different modalities.
The context window innovations being developed for cloud models will gradually migrate to edge deployments as compression techniques improve.
Hybrid Cloud-Edge Architectures
Rather than choosing exclusively between cloud and edge, sophisticated systems will dynamically allocate processing based on context:
Intelligent routing determines whether to process requests locally or in the cloud based on:
- Task complexity and required capabilities
- Current connectivity quality and latency
- Privacy sensitivity of the input
- Battery level and thermal state
- User preferences and settings
Collaborative inference splits processing between device and cloud: initial layers run locally for privacy-sensitive feature extraction, while later layers run in the cloud for complex reasoning.
Federated learning enables on-device models to improve continuously from user interactions while preserving privacy—local training with only aggregated updates shared to central servers.
Expanding Application Domains
As models become more capable and efficient, expect deployment in:
Augmented reality glasses running real-time scene understanding, object recognition, and contextual information overlay with sub-20ms latency requirements.
Medical devices performing diagnostic analysis, patient monitoring, and treatment recommendations at the point of care without cloud dependency.
Autonomous vehicles using on-device models for decision-making, natural language interaction, and contextual awareness in safety-critical scenarios.
Edge robotics deploying language models for human-robot interaction, task planning, and adaptive behavior in warehouses, homes, and public spaces.
The global artificial intelligence market is expected to continue its rapid expansion, with edge AI representing an increasing share as deployment costs decrease and capabilities improve[7].
Regulatory and Standards Development
Expect increased focus on:
Model transparency requirements mandating disclosure of compression techniques, accuracy trade-offs, and capability limitations for on-device AI systems.
Privacy certification for on-device processing claims, with third-party verification that data truly remains local.
Interoperability standards enabling model portability across devices and frameworks, reducing fragmentation costs.
Energy efficiency labeling similar to appliance ratings, helping users understand battery impact of AI features.
The convergence of improved hardware, more efficient models, and sophisticated deployment strategies positions on-device AI as the dominant paradigm for consumer and edge applications by 2028-2030.
Frequently Asked Questions
What is the typical size reduction achieved when compressing LLMs for on-device deployment?
Model compression typically reduces LLM sizes by 5-15x while maintaining 85-95% of original performance. A 70B parameter cloud model can be compressed to 3-7B parameters for mobile deployment through combined quantization, pruning, and distillation techniques. The exact reduction depends on acceptable accuracy trade-offs and target hardware constraints.
How much battery does running an on-device LLM consume?
Well-optimized on-device LLMs consume 3-8% battery per hour of active use on modern smartphones. A single inference typically uses 0.01-0.05% battery depending on model size (1-7B parameters) and input length. Poor optimization can increase consumption 3-5x, making battery profiling essential during deployment.
Can on-device models match cloud model accuracy?
On-device models typically achieve 85-95% of cloud model accuracy on specific tasks they’re optimized for. They excel at focused applications (translation, summarization, classification) but struggle with tasks requiring broad knowledge or complex multi-step reasoning. For specialized use cases, properly trained compact models sometimes outperform larger general-purpose cloud models.
What is the minimum smartphone specification needed to run on-device LLMs?
Practical on-device LLM deployment requires at least 6GB RAM, a processor from 2022 or newer with AI acceleration (NPU or optimized GPU), and 2-4GB available storage. Lower-end devices can run smaller models (1-2B parameters) with reduced capabilities, while flagship devices support 7B+ parameter models with full features.
How do you update on-device models without consuming excessive bandwidth?
Delta updates transmit only changed parameters rather than entire models, reducing update sizes by 70-90%. Progressive compression sends base models first with quality improvements later, and on-device fine-tuning applies small adapter layers (10-100MB) rather than replacing entire models. Schedule updates during WiFi connectivity and off-peak hours to minimize impact.
What privacy advantages do on-device models provide over cloud processing?
On-device models eliminate data transmission entirely—user inputs, outputs, and intermediate states never leave the device. This removes network interception risks, third-party access, server-side logging, and regulatory compliance complexity. For sensitive applications (health, finance, personal communications), local processing provides the only true privacy guarantee.
How do you measure whether a compressed model maintains acceptable quality?
Establish baseline metrics using the original cloud model on representative test sets, then measure the compressed model on identical tests. Track task-specific metrics (BLEU for translation, ROUGE for summarization, F1 for classification) and require 90%+ of baseline performance for critical applications, 85%+ for standard applications. Include human evaluation for subjective quality assessment.
What frameworks support on-device LLM deployment?
TensorFlow Lite (Android/iOS), Core ML (iOS/macOS), ONNX Runtime (cross-platform), PyTorch Mobile (Android/iOS), and vendor-specific SDKs (Qualcomm Neural Processing, MediaTek NeuroPilot) all support on-device deployment. Choose based on target platform, hardware optimization needs, and existing development expertise. Most production deployments use multiple frameworks for different platforms.
Can on-device models work offline completely?
Yes, properly deployed on-device models function identically with or without network connectivity. All model weights, vocabularies, and processing logic reside locally. The only limitations are tasks requiring real-time information (current events, live data) or capabilities beyond the compressed model’s scope—these require cloud fallback when connectivity allows.
How do you choose between on-device and cloud deployment?
Choose on-device when privacy is critical, latency must be under 100ms, offline functionality is required, or usage volume makes cloud costs prohibitive. Choose cloud when tasks require broad knowledge, complex reasoning, frequent updates, or capabilities beyond current edge hardware. Many applications use hybrid approaches with intelligent routing based on task requirements and connectivity.
What is the typical inference latency for on-device LLMs?
On-device LLMs typically deliver inference in 50-150ms for short inputs (under 512 tokens) on modern smartphones with NPU acceleration. Latency scales with input length, model size, and hardware capabilities. CPU-only processing increases latency 5-10x. Real-time applications should target p95 latency under 100ms to maintain responsive user experiences.
How do hardware accelerators improve on-device AI performance?
NPUs and specialized AI accelerators deliver 10-100x faster inference and 5-10x better energy efficiency compared to CPU processing. They optimize matrix multiplications, provide low-precision arithmetic (INT8/INT4), implement efficient memory access patterns, and enable parallel processing of transformer operations—the core computational patterns in LLMs.
Conclusion
Essential AI’s compact powerhouses for deploying minimized LLMs on edge devices represent a fundamental shift in how AI capabilities reach end users. By combining aggressive model compression techniques—quantization, pruning, knowledge distillation, and architectural optimization—with increasingly capable mobile hardware accelerators, teams can now deliver sophisticated language understanding directly on smartphones, IoT devices, and edge computing platforms.
The advantages are compelling: zero-latency responses that feel instantaneous, complete data privacy with no cloud transmission, offline functionality that works anywhere, and dramatically reduced operational costs compared to cloud-based inference. These benefits explain why the mobile AI market is projected to reach $261.38 billion by 2035, with on-device processing driving much of this growth[2].
Yet successful deployment requires navigating real challenges: managing quality trade-offs from compression, addressing hardware fragmentation across thousands of device configurations, optimizing for battery and thermal constraints, and implementing robust testing and monitoring. Teams that approach deployment systematically—defining clear requirements, selecting appropriate compression strategies, validating across representative devices, and deploying with comprehensive monitoring—achieve production success.
The future trajectory points toward even more capable on-device models as hardware continues advancing and architectural innovations deliver better performance per parameter. Hybrid cloud-edge systems will intelligently route processing based on task requirements, connectivity, and privacy needs, while expanding into new domains like AR/VR, medical devices, autonomous systems, and edge robotics.
Actionable next steps for teams considering on-device LLM deployment:
- Benchmark current cloud performance on representative tasks to establish quality baselines
- Identify privacy-sensitive or latency-critical use cases where on-device processing delivers clear value
- Prototype with existing frameworks (TensorFlow Lite, Core ML, ONNX Runtime) to understand compression trade-offs
- Test on diverse hardware representing your user base to validate performance across device tiers
- Implement progressive deployment with comprehensive monitoring to catch issues before full rollout
- Explore hybrid architectures that combine on-device and cloud processing for optimal results
The MULTIBLY platform provides access to 300+ AI models, enabling teams to compare different architectures and identify candidates for compression and edge deployment. By testing models side-by-side, teams can make informed decisions about which approaches best balance accuracy, latency, and resource constraints for their specific applications.
On-device AI has evolved from experimental to essential in 2026. Organizations that master the deployment of compact, efficient models on edge devices will deliver superior user experiences while reducing costs and protecting privacy—competitive advantages that compound over time.
Our Fact Checking Process
We prioritize accuracy and integrity in our content. Here's how we maintain high standards:
- Expert Review: All articles are reviewed by subject matter experts.
- Source Validation: Information is backed by credible, up-to-date sources.
- Transparency: We clearly cite references and disclose potential conflicts.
Our Review Board
Our content is carefully reviewed by experienced professionals to ensure accuracy and relevance.
- Qualified Experts: Each article is assessed by specialists with field-specific knowledge.
- Up-to-date Insights: We incorporate the latest research, trends, and standards.
- Commitment to Quality: Reviewers ensure clarity, correctness, and completeness.
Look for the expert-reviewed label to read content you can trust.



