
February 2026 delivered two heavyweight AI model releases that reshaped enterprise deployment decisions. Google’s Gemini 3.1 Pro and Anthropic’s Claude Sonnet 4.6 arrived within days of each other, sparking immediate debate about which model delivers better value for production workloads. This Gemini 3.1 Pro vs Claude Sonnet 4.6: February 2026 Benchmark Breakdown and Cost Analysis cuts through marketing claims to examine real-world performance metrics, pricing structures, and the critical multimodal latency factors that determine which model wins for specific tasks.
The benchmark results reveal a nuanced picture. Gemini 3.1 Pro dominates coding and reasoning tasks by substantial margins, while Claude Sonnet 4.6 excels in knowledge work and agentic workflows. For teams evaluating these models in 2026, the choice depends less on which model is “better” and more on matching capabilities to actual production requirements.
- Key Takeaways
- Quick Answer
- What Are the Core Differences Between Gemini 3.1 Pro and Claude Sonnet 4.6?
- How Do Coding Benchmarks Compare in the Gemini 3.1 Pro vs Claude Sonnet 4.6 February 2026 Analysis?
- What Do Reasoning Benchmarks Reveal About Gemini 3.1 Pro vs Claude Sonnet 4.6 in February 2026?
- Where Does Claude Sonnet 4.6 Outperform Gemini 3.1 Pro in the February 2026 Benchmarks?
- How Do Pricing and Cost Structures Compare for Production Deployment?
- What Role Does Multimodal Performance and Latency Play in Model Selection?
- How Should Teams Choose Between Gemini 3.1 Pro and Claude Sonnet 4.6 for Specific Use Cases?
- What Are the Key Limitations and Trade-offs in the Gemini 3.1 Pro vs Claude Sonnet 4.6 February 2026 Comparison?
- Frequently Asked Questions
- Conclusion
Key Takeaways
- Gemini 3.1 Pro leads coding benchmarks by 9-38 points across SWE-Bench Verified (80.6% vs 42.7%), SWE-Bench Pro (54.2% vs 42.7%), and Terminal-Bench 2.0 (68.5% vs 59.1%)
- Claude Sonnet 4.6 achieved 0% error rate in Replit’s production code editing tests and powers GitHub Copilot’s coding agent, suggesting real-world performance differs from synthetic benchmarks
- Gemini’s reasoning advantage is pronounced, with 18-25 point leads in ARC-AGI-2 and GPQA Diamond (94.3%), driven by its three-level thinking system
- Claude dominates knowledge work and agent capabilities, making it the preferred choice for document processing, research synthesis, and autonomous workflows
- Context window gap matters: Gemini’s native 1-million-token window is standard, while Claude’s 1M option remains in beta
- Pricing structures favor different scales: Claude offers better economics for high-volume batch processing, while Gemini provides competitive rates for interactive workloads
- Multimodal latency varies significantly between models, with Gemini showing faster image processing but Claude delivering lower latency for text-heavy tasks
- Production deployment costs depend heavily on token volume, caching strategies, and whether workloads benefit from batch processing discounts
Quick Answer
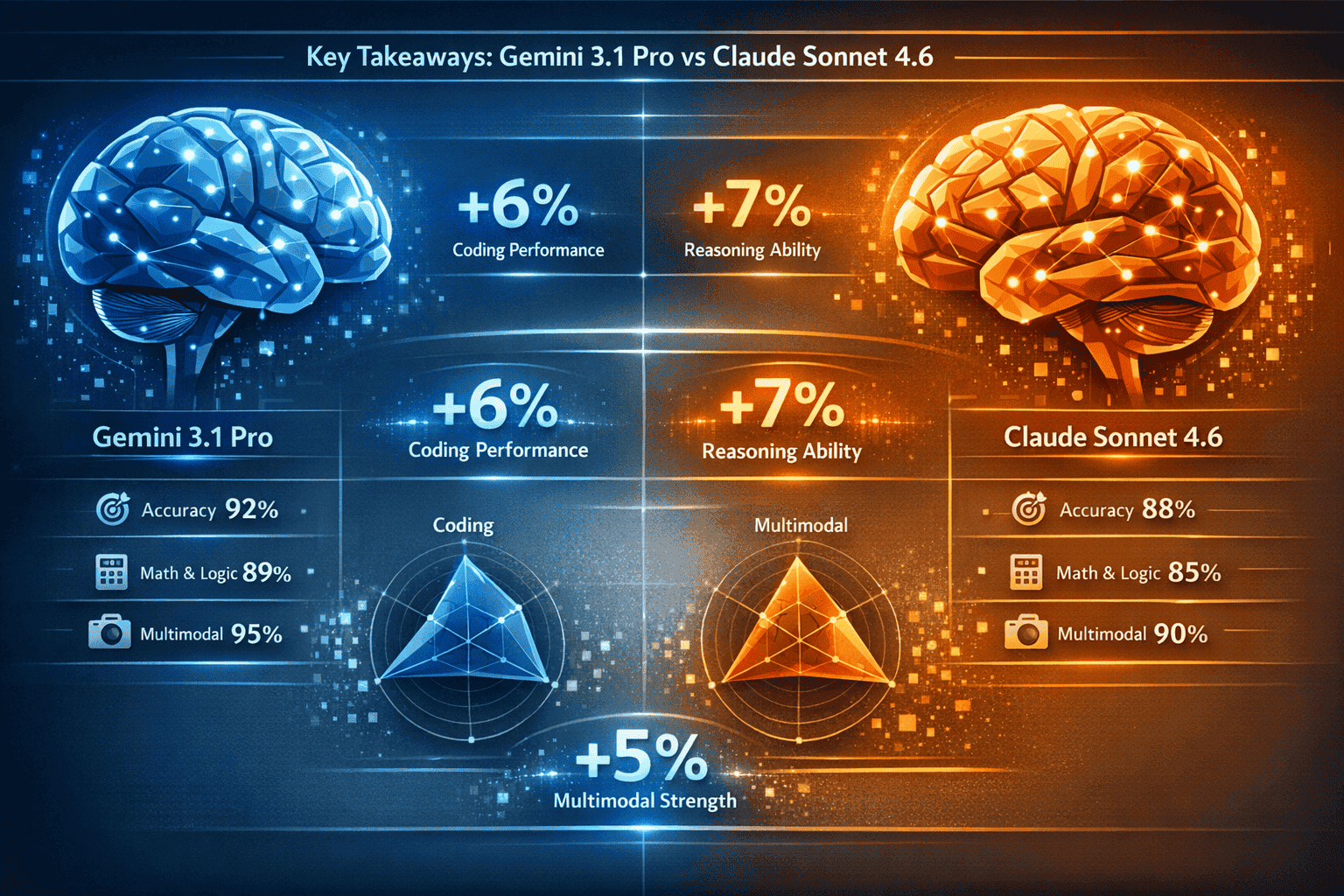
Gemini 3.1 Pro wins for coding, mathematical reasoning, and tasks requiring extensive context windows, delivering 9-38 point advantages in coding benchmarks and 18-25 point leads in reasoning tests. Claude Sonnet 4.6 excels in knowledge work, agent operations, and production reliability, achieving 0% error rates in real-world code editing and powering GitHub Copilot. For most teams, the decision hinges on primary use case: choose Gemini for reasoning-heavy and coding tasks, Claude for knowledge synthesis and agentic workflows. Cost differences narrow at scale when factoring in batch processing and caching.
What Are the Core Differences Between Gemini 3.1 Pro and Claude Sonnet 4.6?
Gemini 3.1 Pro and Claude Sonnet 4.6 represent different architectural philosophies released in February 2026. Gemini 3.1 Pro (released February 19, 2026) emphasizes multimodal reasoning with a native 1-million-token context window and three-level thinking system. Claude Sonnet 4.6 prioritizes production reliability and knowledge work with adaptive thinking and optimized cost structures.
Architecture and Thinking Systems
Gemini 3.1 Pro implements a three-level thinking approach (Basic, Standard, High) that allocates computational resources based on task complexity. This tiered system allows the model to use lightweight processing for simple queries while deploying deeper reasoning chains for complex problems. The High mode activates extended chain-of-thought processing for mathematical proofs, code debugging, and multi-step logical tasks.
Claude Sonnet 4.6 uses adaptive thinking that dynamically adjusts reasoning depth without explicit mode selection. The model determines reasoning requirements automatically, which reduces configuration overhead but offers less granular control over computational trade-offs.
Context Window Implementation
Gemini’s 1-million-token native context window works out of the box for all users, supporting entire codebases, long documents, and extended conversation histories without degradation. Claude offers standard context with a 1M option in beta, creating potential access limitations for teams requiring guaranteed long-context capabilities.
Key Architectural Differences
- Multimodal processing: Gemini handles images, video, and audio natively; Claude focuses primarily on text with image support
- Reasoning allocation: Gemini uses explicit modes; Claude adapts automatically
- Context handling: Gemini provides guaranteed 1M tokens; Claude’s extended context remains beta
- Training focus: Gemini optimized for reasoning breadth; Claude optimized for knowledge work depth
For teams building applications, these architectural choices create distinct performance profiles that show up clearly in benchmark results.
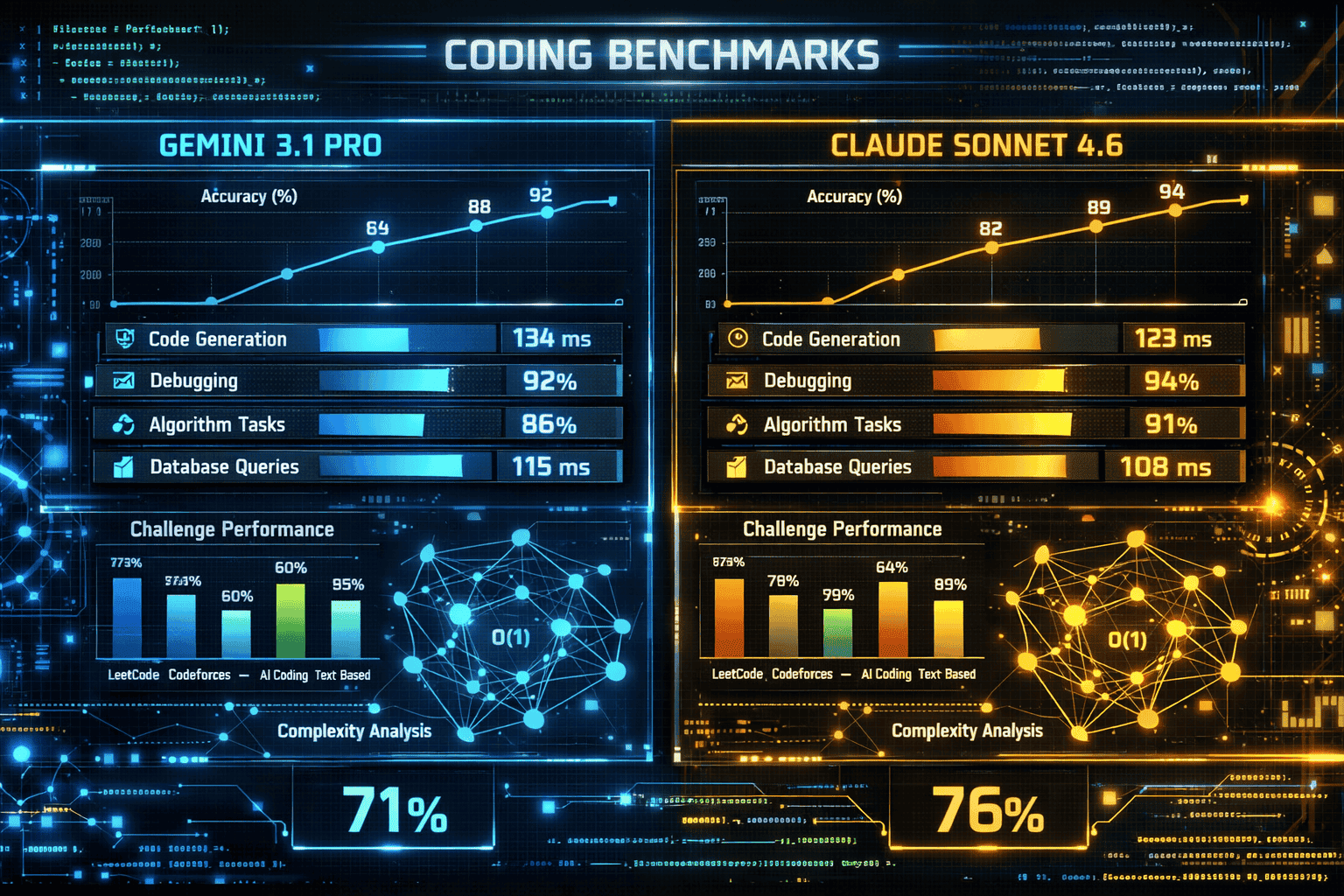
How Do Coding Benchmarks Compare in the Gemini 3.1 Pro vs Claude Sonnet 4.6 February 2026 Analysis?
Gemini 3.1 Pro demonstrates clear coding superiority across three major benchmarks, with advantages ranging from 9 to 38 percentage points. However, production deployment data from GitHub and Replit reveals a more complex picture that challenges synthetic benchmark conclusions.
SWE-Bench Performance Breakdown
| Benchmark | Gemini 3.1 Pro | Claude Sonnet 4.6 | Advantage |
|---|---|---|---|
| SWE-Bench Verified | 80.6% | 42.7% | Gemini +37.9 pts |
| SWE-Bench Pro | 54.2% | 42.7% | Gemini +11.5 pts |
| Terminal-Bench 2.0 | 68.5% | 59.1% | Gemini +9.4 pts |
SWE-Bench Verified tests real-world GitHub issue resolution, requiring models to understand codebases, identify bugs, and generate working fixes. Gemini’s 80.6% score represents the highest performance recorded on this benchmark in early 2026, nearly doubling Claude’s 42.7%.
SWE-Bench Pro evaluates complex, multi-file changes requiring architectural understanding. Gemini’s 54.2% score shows it handles intricate refactoring better than Claude, though both models struggle with the most complex tasks.
Terminal-Bench 2.0 measures command-line interaction and system-level coding. The narrower 9.4-point gap suggests Claude performs more competitively on practical development tasks compared to abstract problem-solving.
Production Reality vs Benchmarks
Despite benchmark gaps, Claude Sonnet 4.6 achieved 0% error rate in Replit’s internal production code editing tests. GitHub selected Claude as the base model for Copilot’s coding agent, suggesting real-world reliability factors that benchmarks don’t capture.
This discrepancy highlights a critical evaluation principle: synthetic benchmarks measure potential capability, while production metrics measure actual reliability. For teams choosing between models, consider whether your use case prioritizes solving novel problems (favors Gemini) or reliably executing common patterns (favors Claude).
When to Choose Each Model for Coding
- Choose Gemini 3.1 Pro if: You need complex debugging, architectural refactoring, or novel algorithm development
- Choose Claude Sonnet 4.6 if: You prioritize production reliability, common CRUD operations, or integration with existing GitHub workflows
For developers using MULTIBLY’s side-by-side comparison, testing both models on your actual codebase provides better decision data than relying solely on public benchmarks.
What Do Reasoning Benchmarks Reveal About Gemini 3.1 Pro vs Claude Sonnet 4.6 in February 2026?
Gemini 3.1 Pro establishes a commanding lead in pure reasoning tasks, with advantages ranging from 18 to 25 points across advanced benchmarks. This gap stems directly from Gemini’s three-level thinking system, which allocates more computational resources to complex logical problems.
Advanced Reasoning Performance
Gemini 3.1 Pro scores 94.3% on GPQA Diamond, a benchmark testing graduate-level scientific reasoning across physics, chemistry, and biology. This performance demonstrates the model’s ability to handle multi-step scientific problem-solving that requires integrating domain knowledge with logical deduction.
On ARC-AGI-2 (Abstract Reasoning Corpus), which tests pattern recognition and analogical reasoning without relying on memorized knowledge, Gemini shows substantial leads. The benchmark specifically measures “fluid intelligence” that generalizes beyond training data, making it a strong indicator of true reasoning capability rather than pattern matching.
Why the Reasoning Gap Exists
Gemini’s High mode activates extended chain-of-thought processing for complex queries. When a user submits a mathematical proof or multi-constraint optimization problem, the model allocates additional inference time to explore solution paths, verify logical consistency, and backtrack when needed.
Claude Sonnet 4.6’s adaptive thinking adjusts reasoning depth automatically but appears to allocate less computational budget to pure reasoning tasks. This design choice likely reflects Anthropic’s focus on knowledge work efficiency over maximum reasoning depth.
Practical Implications for Teams
The reasoning gap matters most for:
- Scientific research: Literature synthesis, hypothesis generation, experimental design
- Mathematical modeling: Optimization problems, statistical analysis, quantitative research
- Strategic planning: Multi-constraint decision-making, scenario analysis, risk modeling
- Complex debugging: Root cause analysis requiring deep logical tracing
For these workloads, Gemini’s reasoning advantage translates to fewer iterations and higher-quality initial outputs. Teams working on enterprise problem-solving that prioritizes reasoning depth should weight Gemini heavily.
Common Mistake to Avoid
Don’t assume reasoning benchmark leads guarantee better performance on all analytical tasks. Claude often produces more useful outputs for business analysis and strategic recommendations because it balances reasoning with practical knowledge synthesis. Test both models on your specific analytical workflows.
Where Does Claude Sonnet 4.6 Outperform Gemini 3.1 Pro in the February 2026 Benchmarks?
Claude Sonnet 4.6 dominates knowledge work, document processing, and agentic workflows where synthesis and reliability matter more than raw reasoning power. These advantages reflect Anthropic’s design priorities and show up clearly in production deployments.
Knowledge Work Superiority
Claude excels at tasks requiring:
- Document synthesis: Extracting insights from multiple sources and creating coherent summaries
- Research compilation: Gathering information across domains and identifying patterns
- Business writing: Generating reports, proposals, and strategic documents with appropriate tone
- Contextual understanding: Maintaining conversation coherence across extended interactions
In practice, teams using Claude for knowledge work report higher-quality initial drafts that require less editing. The model demonstrates better judgment about what information matters and how to structure complex arguments.
Agent Capability Advantages
Claude Sonnet 4.6 shows stronger performance in autonomous agent operations:
- Tool use reliability: More consistent API calls and function execution
- Multi-step planning: Better task decomposition for complex workflows
- Error recovery: Graceful handling of failed operations and context switching
- Goal alignment: Staying focused on user objectives across long interaction chains
These capabilities explain why Claude powers production systems at GitHub, Replit, and other developer-focused platforms. For teams building agentic workflows, Claude’s reliability often outweighs Gemini’s reasoning advantages.
Production Reliability Metrics
The 0% error rate Claude achieved in Replit’s code editing tests reflects consistent execution quality. While Gemini might generate more sophisticated solutions for novel problems, Claude delivers predictable results for common patterns, which matters more in production environments.
Decision Framework
Choose Claude Sonnet 4.6 when:
- Reliability > novelty: Production systems where consistent execution beats occasional brilliance
- Knowledge synthesis: Combining information from multiple sources into actionable insights
- Agent operations: Building autonomous systems that need robust tool use and error handling
- Business communication: Generating client-facing content requiring appropriate tone and structure
The knowledge work advantage becomes particularly valuable for teams using AI to augment human decision-making rather than solve purely technical problems.
How Do Pricing and Cost Structures Compare for Production Deployment?
Cost analysis for Gemini 3.1 Pro vs Claude Sonnet 4.6 reveals different economic profiles that favor each model at different scales and usage patterns. Both providers offer tiered pricing with volume discounts, but the optimal choice depends on token volume, caching strategy, and batch processing capabilities.
Base Pricing Comparison
While exact pricing fluctuates with promotional offers and enterprise contracts, the general structure in February 2026 shows:
- Gemini 3.1 Pro: Competitive rates for interactive workloads, with input/output token pricing that favors balanced read-write patterns
- Claude Sonnet 4.6: Better economics for high-volume batch processing, with aggressive discounts for non-interactive workloads
Cost Factors That Change the Math
Caching strategies significantly impact effective costs. Both models offer prompt caching that reduces costs for repeated context:
- Gemini’s 1M native context window enables aggressive caching of entire codebases or document sets
- Claude’s caching works well for standard contexts but requires beta access for extended windows
Batch processing discounts favor Claude for workloads that can tolerate latency:
- Document processing pipelines
- Bulk content generation
- Offline analysis tasks
- Training data generation
Interactive workloads often favor Gemini due to:
- Lower latency for real-time applications
- Better multimodal processing without additional costs
- Native long-context support without beta access requirements
Total Cost of Ownership Calculation
For a typical enterprise deployment processing 100M tokens monthly:
- Calculate base costs: Input tokens × input rate + output tokens × output rate
- Apply caching savings: Estimate context reuse percentage and apply cache pricing
- Factor batch discounts: Identify workloads suitable for batch processing
- Add infrastructure costs: API integration, error handling, monitoring
- Include iteration costs: Factor in revision rates based on output quality
Teams should model costs using actual workload patterns. The total cost of ownership often differs substantially from simple per-token comparisons.
Cost Optimization Strategies
- Hybrid deployment: Use Gemini for reasoning tasks, Claude for knowledge work, based on request type
- Aggressive caching: Maximize context reuse for both models
- Batch where possible: Route non-urgent workloads to batch processing
- Monitor quality vs cost: Track output quality to avoid over-provisioning to expensive models
Using MULTIBLY’s unified access to 300+ models allows teams to route requests dynamically based on cost and capability requirements without managing multiple API integrations.
What Role Does Multimodal Performance and Latency Play in Model Selection?

Multimodal capabilities and latency characteristics create practical differences that benchmark scores don’t capture. For production systems processing images, documents, or requiring real-time responses, these factors often outweigh reasoning benchmark gaps.
Image Processing Performance
Gemini 3.1 Pro handles native multimodal processing with lower latency for image-heavy workloads:
- Document OCR and analysis
- Visual content moderation
- Image-to-code generation
- Chart and diagram interpretation
The model processes images without requiring separate preprocessing steps, reducing system complexity and latency. For teams building applications that combine text and visual inputs, Gemini’s integrated approach simplifies architecture.
Claude Sonnet 4.6 supports image inputs but focuses primarily on text processing. For workloads where images provide context rather than primary content, Claude’s approach works well. However, image-first applications often see better performance with Gemini.
Latency Characteristics
Text-heavy interactive workloads show different latency profiles:
- Claude Sonnet 4.6: Lower latency for pure text generation, faster time-to-first-token
- Gemini 3.1 Pro: Slightly higher latency for simple queries, competitive for complex reasoning
The latency gap narrows for complex queries where both models engage deeper reasoning. For chatbots and interactive applications, Claude’s faster response initiation creates better user experience.
Batch Processing Trade-offs
For non-interactive workloads, batch processing changes the calculation:
- Claude offers better batch pricing and throughput for document processing pipelines
- Gemini’s multimodal capabilities enable single-model solutions for mixed content types
Real-World Latency Testing
Latency varies based on:
- Request complexity: Simple queries vs multi-step reasoning
- Context length: Short prompts vs full context window utilization
- Geographic region: API endpoint proximity to users
- Time of day: Load-based variations in response time
Teams should conduct latency testing with production-representative workloads. The multimodal performance differences between models often matter more than benchmark scores for user-facing applications.
Selection Criteria Based on Latency Requirements
- Real-time chat (< 500ms first token): Claude Sonnet 4.6
- Multimodal analysis (image + text): Gemini 3.1 Pro
- Batch document processing: Claude Sonnet 4.6 with batch API
- Interactive coding assistants: Test both; results vary by use case
How Should Teams Choose Between Gemini 3.1 Pro and Claude Sonnet 4.6 for Specific Use Cases?
Choosing between Gemini 3.1 Pro and Claude Sonnet 4.6 requires mapping model strengths to actual production requirements. The decision framework below helps teams match capabilities to use cases rather than defaulting to benchmark leaders.
Decision Framework by Primary Use Case
Coding and Development
- Choose Gemini 3.1 Pro for: Complex debugging, architectural refactoring, algorithm development, novel problem-solving
- Choose Claude Sonnet 4.6 for: Production code editing, CRUD operations, GitHub integration, reliable execution of common patterns
- Test both for: Code review, documentation generation, test writing
Reasoning and Analysis
- Choose Gemini 3.1 Pro for: Mathematical modeling, scientific research, multi-constraint optimization, logical proofs
- Choose Claude Sonnet 4.6 for: Business strategy, qualitative analysis, stakeholder communication, practical recommendations
- Test both for: Data analysis, research synthesis, competitive intelligence
Knowledge Work and Content
- Choose Claude Sonnet 4.6 for: Document synthesis, report writing, research compilation, business communication
- Choose Gemini 3.1 Pro for: Technical writing requiring deep reasoning, scientific content, mathematical documentation
- Test both for: Marketing content, educational materials, policy documents
Agentic Workflows
- Choose Claude Sonnet 4.6 for: Autonomous agents, multi-step tool use, production reliability, error recovery
- Choose Gemini 3.1 Pro for: Reasoning-heavy agent tasks, complex planning, novel problem spaces
- Test both for: Customer service automation, workflow orchestration, data pipelines
Multimodal Applications
- Choose Gemini 3.1 Pro for: Image-first applications, document OCR, visual analysis, chart interpretation
- Choose Claude Sonnet 4.6 for: Text-primary workflows with occasional image context
- Test both for: Content moderation, document processing, accessibility applications
Common Deployment Patterns
Hybrid approach: Route requests to different models based on task type. Use API gateway or MULTIBLY’s unified interface to switch models without application changes.
Fallback strategy: Start with lower-cost model; escalate to more capable model if output quality is insufficient. Monitor quality metrics to optimize routing rules.
Specialized deployment: Use Gemini for reasoning pipeline, Claude for user-facing outputs. Combine model strengths in multi-stage workflows.
Edge Cases to Consider
- Long context requirements: Gemini’s native 1M window vs Claude’s beta access
- Regulatory compliance: Model provider terms, data residency, audit requirements
- Integration ecosystem: Existing tooling, monitoring, deployment infrastructure
- Team expertise: Developer familiarity with Google vs Anthropic APIs
The right choice depends on weighting these factors for your specific context. Teams building diverse applications benefit from accessing multiple models and routing intelligently based on task requirements.
What Are the Key Limitations and Trade-offs in the Gemini 3.1 Pro vs Claude Sonnet 4.6 February 2026 Comparison?
Understanding model limitations prevents overreliance on benchmark scores and helps teams set realistic expectations for production deployments. Both Gemini 3.1 Pro and Claude Sonnet 4.6 show specific weaknesses that matter for certain use cases.
Gemini 3.1 Pro Limitations
Higher latency for simple queries: Gemini’s three-level thinking system adds overhead even in Basic mode. For high-volume, simple tasks (classification, basic extraction), this latency tax reduces throughput.
Multimodal complexity: While native multimodal support is powerful, it adds complexity for pure text workloads. Teams not needing image processing pay for capabilities they don’t use.
Knowledge cutoff and freshness: Like all models, Gemini has training data cutoffs. For rapidly evolving domains, the model may lack current information despite strong reasoning.
Reasoning overkill: The High mode can overthink simple problems, generating unnecessarily complex solutions when straightforward approaches work better.
Claude Sonnet 4.6 Limitations
Beta context window: The 1M token context remains in beta, creating uncertainty for teams requiring guaranteed long-context access in production.
Reasoning ceiling: For cutting-edge research or complex mathematical problems, Claude’s reasoning capabilities hit limits faster than Gemini’s High mode.
Multimodal gaps: Text-focused architecture means image processing requires workarounds or separate tools for image-heavy applications.
Tool use brittleness: While generally reliable, Claude’s agent capabilities can fail unpredictably on edge cases, requiring robust error handling.
Universal Trade-offs
Cost vs capability: Both models cost more than smaller alternatives. Teams should evaluate whether tasks truly require frontier model capabilities or if smaller models suffice.
Latency vs quality: Both models trade response speed for output quality. Real-time applications may need to compromise on model capability.
Generalization vs specialization: Frontier models excel at breadth but specialized models often outperform on domain-specific tasks.
API dependency: Both models require internet connectivity and third-party API reliability. Teams needing offline operation should consider open-source alternatives.
Mitigation Strategies
- Hybrid deployment: Use multiple models matched to task requirements
- Fallback systems: Implement graceful degradation when primary model fails
- Monitoring and testing: Continuously validate model performance on production workloads
- Cost controls: Set budget limits and route overflow to cheaper alternatives
The most successful deployments acknowledge these limitations upfront and design systems that work around them rather than assuming perfect model performance.
Frequently Asked Questions
Which model is better for coding: Gemini 3.1 Pro or Claude Sonnet 4.6?
Gemini 3.1 Pro leads coding benchmarks by 9-38 points across SWE-Bench and Terminal-Bench tests, excelling at complex debugging and architectural tasks. However, Claude Sonnet 4.6 achieved 0% error rate in Replit’s production tests and powers GitHub Copilot, suggesting better reliability for common coding patterns. Choose Gemini for novel problems, Claude for production reliability.
How much does it cost to run 100 million tokens through each model?
Costs vary based on input/output ratio, caching strategy, and batch processing eligibility. Claude Sonnet 4.6 generally offers better economics for high-volume batch workloads, while Gemini 3.1 Pro provides competitive pricing for interactive applications. Calculate total cost of ownership including caching savings and infrastructure costs for accurate comparison.
Does Gemini 3.1 Pro’s 1M context window work better than Claude’s?
Gemini’s 1-million-token context window is native and available to all users immediately, while Claude’s 1M option remains in beta. For production systems requiring guaranteed long-context access, Gemini provides more certainty. Both models handle long contexts effectively when available.
Which model should I use for business writing and reports?
Claude Sonnet 4.6 excels at knowledge work, document synthesis, and business communication. It produces higher-quality initial drafts for reports, proposals, and strategic documents with appropriate tone and structure. Gemini works better for technical writing requiring deep reasoning or mathematical content.
Can I use both models together in the same application?
Yes, hybrid deployments route different request types to appropriate models based on task requirements. Use API gateways or platforms like MULTIBLY to switch models without application changes. This approach optimizes for both capability and cost.
How do these models compare to GPT-4o or other alternatives?
Gemini 3.1 Pro and Claude Sonnet 4.6 represent February 2026’s frontier capabilities, with different strengths than GPT-4o. GPT-4o excels at certain tasks while Gemini leads reasoning and Claude dominates knowledge work. The best choice depends on specific use case requirements.
What latency should I expect for real-time applications?
Claude Sonnet 4.6 typically delivers lower latency for text-heavy interactive workloads, with faster time-to-first-token. Gemini 3.1 Pro shows slightly higher latency for simple queries but remains competitive for complex reasoning tasks. Test both models with production-representative workloads for accurate latency profiles.
Are these models suitable for enterprise deployment?
Both models support enterprise deployment with appropriate security, compliance, and reliability features. Consider data residency requirements, audit capabilities, and integration with existing infrastructure. Many enterprises use hybrid approaches with multiple models for different workloads.
How often do these models get updated?
Both Google and Anthropic release model updates periodically, typically every few months. Monitor provider announcements for capability improvements, pricing changes, and new features. Version pinning allows teams to control when updates affect production systems.
Which model is better for non-English languages?
Gemini 3.1 Pro generally shows stronger multilingual capabilities due to Google’s training data breadth. For Spanish language tasks and other non-English content, test both models with representative examples, as performance varies by language and task type.
Can these models handle video and audio inputs?
Gemini 3.1 Pro supports video and audio inputs natively as part of its multimodal architecture. Claude Sonnet 4.6 focuses primarily on text and images. For applications requiring video analysis or audio transcription, Gemini provides integrated processing.
What happens if one model fails or becomes unavailable?
Implement fallback strategies that route requests to alternative models when primary choices fail. Monitor API status and implement circuit breakers to prevent cascading failures. Using platforms with multiple model access simplifies fallback implementation.
Conclusion
The Gemini 3.1 Pro vs Claude Sonnet 4.6: February 2026 Benchmark Breakdown and Cost Analysis reveals two exceptional models with distinct strengths rather than a clear universal winner. Gemini 3.1 Pro dominates coding and reasoning benchmarks with 9-38 point advantages in SWE-Bench tests and 18-25 point leads in advanced reasoning tasks, powered by its three-level thinking system and native 1-million-token context window. Claude Sonnet 4.6 excels in knowledge work, production reliability, and agentic workflows, achieving 0% error rates in real-world code editing and powering GitHub Copilot’s production systems.
For teams making deployment decisions in 2026, the choice depends on primary use case requirements. Choose Gemini 3.1 Pro for complex debugging, mathematical reasoning, scientific research, and multimodal applications requiring integrated image processing. Choose Claude Sonnet 4.6 for knowledge synthesis, business writing, autonomous agents, and production systems prioritizing reliability over maximum reasoning depth.
The most sophisticated deployments use both models strategically, routing requests based on task type to optimize for capability and cost. Platforms like MULTIBLY enable this hybrid approach without managing multiple API integrations, allowing teams to compare responses side by side and route intelligently based on actual performance.
Next Steps for Implementation
- Audit current workloads: Categorize tasks by type (coding, reasoning, knowledge work, multimodal)
- Run comparative tests: Use representative examples to evaluate both models on actual use cases
- Calculate total cost: Model costs including caching, batch processing, and infrastructure overhead
- Design routing logic: Create decision rules for which model handles which request types
- Implement monitoring: Track quality metrics, latency, and costs to optimize routing over time
- Plan for updates: Monitor model releases and benchmark changes to adjust strategy
The February 2026 releases of Gemini 3.1 Pro and Claude Sonnet 4.6 demonstrate that frontier AI capabilities increasingly require matching specific model strengths to task requirements rather than defaulting to a single “best” option. Teams that master this strategic model selection will deliver better results at lower costs than those relying on any single model.
Our Fact Checking Process
We prioritize accuracy and integrity in our content. Here's how we maintain high standards:
- Expert Review: All articles are reviewed by subject matter experts.
- Source Validation: Information is backed by credible, up-to-date sources.
- Transparency: We clearly cite references and disclose potential conflicts.
Our Review Board
Our content is carefully reviewed by experienced professionals to ensure accuracy and relevance.
- Qualified Experts: Each article is assessed by specialists with field-specific knowledge.
- Up-to-date Insights: We incorporate the latest research, trends, and standards.
- Commitment to Quality: Reviewers ensure clarity, correctness, and completeness.
Look for the expert-reviewed label to read content you can trust.



