
- Key Takeaways
- Quick Answer
- What Makes GLM-4.5's 355B MoE Architecture Different?
- How Does GLM-4.5 from Z.ai Compare to Leading Closed-Source Models?
- What Advanced Training Techniques Power GLM-4.5's Performance?
- How Does GLM-4.5 Enable Advanced Agent and Coding Applications?
- What Are the Practical Deployment Considerations for GLM-4.5?
- How Has GLM-4.5 Evolved and What Came After?
- What Are the Key Advantages of Open-Source Access to GLM-4.5?
- What Challenges and Limitations Should You Consider?
- How to Get Started with GLM-4.5 for Your Projects
- Frequently Asked Questions
- Conclusion
- References
Key Takeaways
GLM-4.5 delivers 355 billion total parameters with 32 billion active through mixture-of-experts architecture, achieving efficiency gains of approximately 11x versus dense models while maintaining competitive performance with leading closed-source systems.
The model was purpose-built for agent applications, featuring Interleaved Thinking before every response and tool call, sophisticated artifact generation across multiple formats, and seamless integration with agent frameworks.
Advanced training techniques including Muon optimizer, QK-Norm stabilization, and mixed-precision data generation enable superior performance and training efficiency, making the model both powerful and practical to deploy.
Open-source availability provides full customization, on-premises deployment, data privacy, and no vendor lock-in, creating tangible advantages for organizations building production AI applications, particularly in regulated industries.
GLM-4.5-Air offers a lighter alternative with 106 billion total and 12 billion active parameters, serving use cases where computational constraints are tighter but strong performance is still required.
The model excels at code generation, creating sophisticated standalone applications including interactive games, simulations, and polished front-end interfaces across HTML, SVG, Python, and other formats.
Self-hosting becomes cost-effective at approximately 5-10 million tokens monthly, with break-even points varying based on infrastructure costs and API pricing for comparable closed-source alternatives.
GLM-4.5 established a foundation that Z.ai built upon with GLM-4.7 (December 2025) and GLM-5 (February 2026), demonstrating continuous improvement while maintaining backward compatibility for existing deployments.
Infrastructure requirements include 64GB+ GPU memory for GLM-4.5, with cloud rental costs of $1,000-$2,000 monthly for single-GPU deployments and $3,000-$8,000 for multi-GPU production setups.
The model’s limitations include substantial hardware requirements, MoE routing complexity, and limited native multimodal capabilities, making it essential to validate fit for specific use cases before committing to deployment infrastructure.
Quick Answer
GLM-4.5 from Z.ai: The 355B MoE Model Redefining Open-Source Performance represents a significant milestone in accessible AI. The model uses 355 billion total parameters with only 32 billion active at inference time, delivering performance comparable to leading closed-source models while remaining fully open for developer customization. This mixture-of-experts approach combines efficiency with capability, making enterprise-grade AI accessible to teams building custom applications.
When Z.ai released GLM-4.5, the company made a clear statement: open-source models could compete directly with proprietary giants. The 355 billion parameter mixture-of-experts architecture delivers benchmark results that rival GPT-4 and Claude, but with a crucial difference—developers get full access to customize, deploy, and integrate the model however they need.
For teams evaluating AI models in 2026, GLM-4.5 from Z.ai: The 355B MoE Model Redefining Open-Source Performance offers a compelling alternative to closed platforms. The model doesn’t just match closed-source performance; it introduces architectural innovations specifically designed for the agent-first applications that define modern AI development.
What Makes GLM-4.5’s 355B MoE Architecture Different?
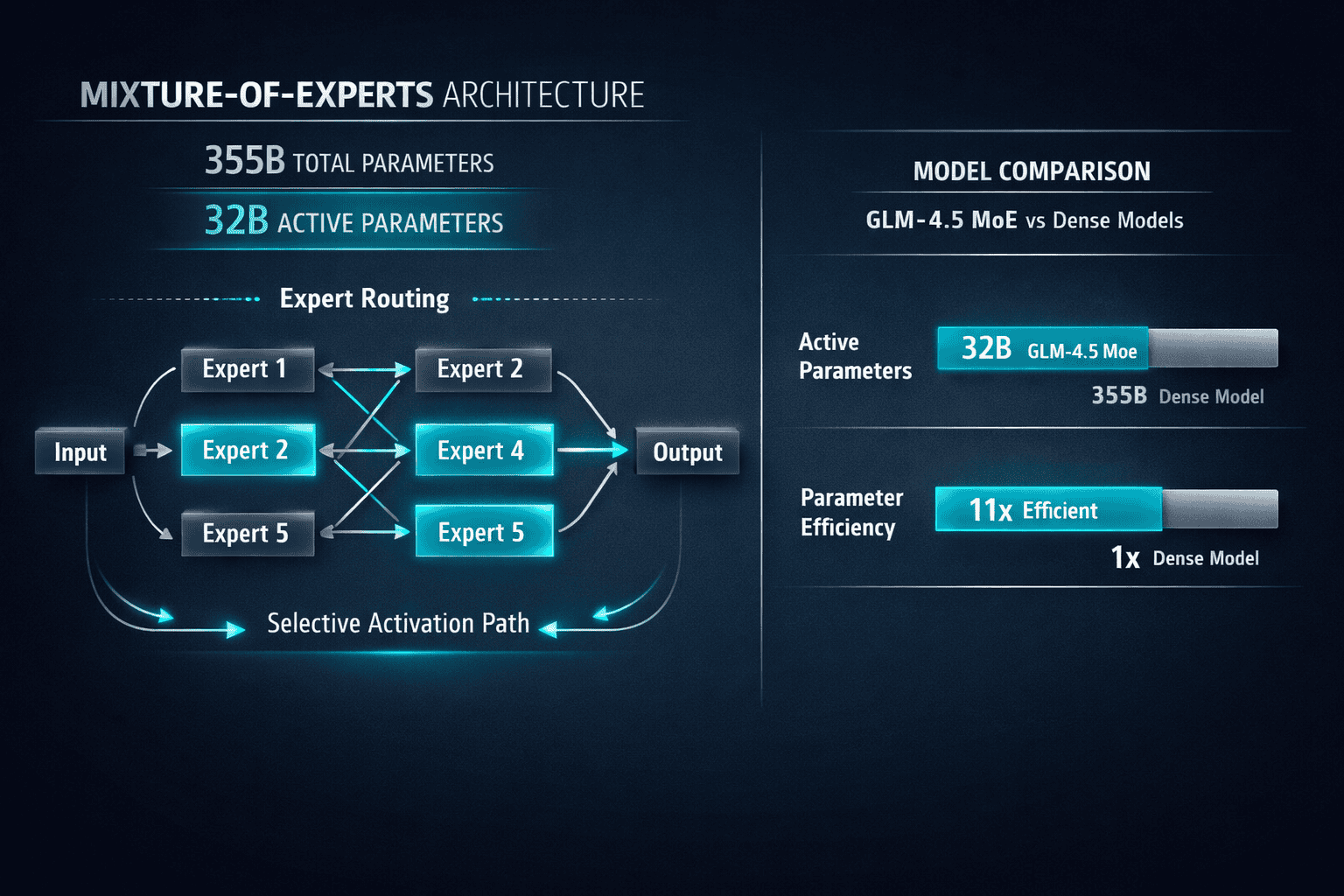
GLM-4.5 uses a mixture-of-experts (MoE) design with 355 billion total parameters, but only 32 billion parameters activate during any single inference pass[3]. This architectural choice delivers two critical advantages: the model maintains the knowledge capacity of much larger systems while keeping computational costs closer to smaller models.
The MoE approach works by routing each input to specialized expert modules. Instead of processing every token through all 355 billion parameters, the model intelligently selects which 32 billion parameters are most relevant for each specific task. Think of it as having a team of specialists where you consult the right expert for each question, rather than asking everyone every time.
How the Parameter Efficiency Works in Practice
Active vs. Total Parameters:
- Total parameters: 355 billion (full knowledge base)
- Active parameters: 32 billion (used per inference)
- Efficiency gain: ~11x reduction in computational cost vs. dense 355B model
This design means GLM-4.5 can run on infrastructure that would struggle with a traditional 355 billion parameter dense model. For developers, this translates to lower hosting costs and faster inference times without sacrificing capability.
The model also includes a lighter variant: GLM-4.5-Air with 106 billion total parameters and 12 billion active parameters[3]. This version serves use cases where computational constraints are tighter but strong performance is still required.
Choose GLM-4.5 if: You need maximum capability for complex reasoning, multi-step coding tasks, or sophisticated agent workflows.
Choose GLM-4.5-Air if: You’re optimizing for cost and speed while maintaining strong general performance across standard tasks.
A common mistake is assuming MoE models sacrifice quality for efficiency. In practice, GLM-4.5’s selective activation often improves performance because the model routes tasks to the most specialized experts rather than diluting computation across irrelevant parameters.
How Does GLM-4.5 from Z.ai Compare to Leading Closed-Source Models?
GLM-4.5 from Z.ai: The 355B MoE Model Redefining Open-Source Performance holds its own against GPT-4, Claude, and other proprietary systems across key benchmarks. The model was specifically designed to satisfy the increasingly complicated requirements of agent applications[3], which means it excels in areas that matter for real-world deployment.
In coding benchmarks, GLM-4.5 demonstrates strong performance, though subsequent releases like GLM-4.7 showed even more significant gains. GLM-4.7 achieved 73.8% on SWE-bench (a 5.8% improvement over GLM-4.5), 66.7% on SWE-bench Multilingual (12.9% improvement), and 41% on Terminal Bench 2.0 (16.5% improvement)[1].
Performance Across Key Dimensions
| Capability Area | GLM-4.5 Strength | Competitive Position |
|---|---|---|
| Code Generation | Creates sophisticated standalone artifacts including interactive games and simulations[3][1] | Matches GPT-4 for complex coding tasks |
| Reasoning | Interleaved Thinking before every response and tool call[1] | Competitive with Claude for multi-step reasoning |
| Agent Tasks | Unified architecture for reasoning, coding, and agentic capabilities[3] | Purpose-built for agent workflows vs. general-purpose competitors |
| Long-Context | Efficient handling through MoE routing | Strong performance, though specialized models like Kimi K2’s 256K context window may excel for extreme length |
The key difference is access. While GPT-4 and Claude require API calls to proprietary services, GLM-4.5 gives developers full model access. This means you can fine-tune for domain-specific tasks, deploy on your own infrastructure, and avoid vendor lock-in.
For most teams building production AI applications, the combination of competitive performance and open access makes GLM-4.5 particularly attractive. You’re not choosing between quality and control—you get both.
Edge case to consider: If you need absolute cutting-edge performance on specific benchmarks and cost is no concern, the latest closed-source models may still hold a slight edge. But for practical applications, GLM-4.5’s performance gap is minimal while the deployment flexibility is substantial.
Similar to how DeepSeek R1 and V3.1 challenged global leaders with open-source alternatives, GLM-4.5 demonstrates that the performance moat around closed models continues to narrow.
What Advanced Training Techniques Power GLM-4.5’s Performance?

GLM-4.5 incorporates several architectural innovations that enable its strong performance. These aren’t just incremental improvements—they represent fundamental advances in how large language models are trained and deployed.
Muon Optimizer for Faster Convergence
The model uses the Muon optimizer for faster convergence and larger batch tolerance[3]. Traditional optimizers like Adam can struggle with very large batch sizes, which limits training efficiency. Muon addresses this by maintaining stable training dynamics even as batch sizes increase.
In practice, this means GLM-4.5 could be trained more efficiently, reducing the computational resources required to reach target performance levels. For the open-source community, this matters because it makes retraining or fine-tuning more accessible.
QK-Norm for Attention Stability
GLM-4.5 incorporates QK-Norm to stabilize attention logit ranges[3]. Attention mechanisms are the core of transformer models, but they can become unstable during training, especially at large scales. QK-Norm normalizes the query and key vectors before computing attention scores.
The result is more stable training and more reliable inference. The model is less likely to produce erratic outputs or fail on edge cases where attention scores might otherwise diverge.
MTP Layer for Speculative Decoding
The model includes an MTP (Multi-Token Prediction) layer for speculative decoding during inference[3]. Traditional language models generate one token at a time, which creates a sequential bottleneck. The MTP layer predicts multiple potential next tokens simultaneously.
During inference, this enables faster generation by allowing the model to speculatively compute several steps ahead, then validate and commit the correct path. Users experience faster response times without sacrificing output quality.
Mixed-Precision Data Generation
One of GLM-4.5’s most innovative training techniques is mixed-precision data generation using FP8 format for rollouts while retaining BF16 for model training[3]. This approach dramatically increases data generation speed without compromising training quality.
How it works:
- Generate synthetic training data using faster FP8 precision
- Train the actual model using higher-quality BF16 precision
- Achieve 2-4x faster data generation with minimal quality loss
This technique is particularly valuable for reinforcement learning from human feedback (RLHF) and other data-intensive training phases where generating high-quality synthetic examples is a bottleneck.
Common mistake: Assuming all precision reductions harm quality. In practice, carefully chosen mixed-precision approaches like GLM-4.5’s can maintain quality while substantially improving efficiency. The key is using lower precision only where it doesn’t impact the final model weights.
How Does GLM-4.5 Enable Advanced Agent and Coding Applications?
GLM-4.5 from Z.ai: The 355B MoE Model Redefining Open-Source Performance was explicitly designed for agent-first applications. This isn’t just marketing—the architectural choices reflect a clear focus on the multi-step, tool-using workflows that define modern AI agents.
Interleaved Thinking for Enhanced Reasoning
GLM-4.5 introduced Interleaved Thinking, where the model thinks before every response and tool calling[1]. This approach mirrors how humans tackle complex problems: we don’t just react immediately, we pause to consider the best approach.
When you query GLM-4.5 in an agent context, the model:
- Receives your input
- Generates internal reasoning about the best approach
- Decides whether to respond directly or call a tool
- Executes the chosen action
- Repeats for multi-step workflows
This internal reasoning isn’t just for show. It measurably improves accuracy on complex tasks because the model explicitly considers its strategy before committing to an action.
Later releases enhanced this with Preserved Thinking capabilities for multi-turn coding agent scenarios[1], allowing the model to maintain reasoning context across extended interactions.
Sophisticated Artifact Generation
The model creates sophisticated standalone artifacts including interactive mini-games, physics simulations, and visually polished front-end pages across HTML, SVG, Python, and other formats[3][1].
Example use cases:
- Generate a complete interactive data visualization from a dataset
- Create a working physics simulation for educational content
- Build a functional web interface prototype from requirements
- Produce executable Python scripts for data processing pipelines
These aren’t simple code snippets. GLM-4.5 generates complete, functional applications that work out of the box. For developers, this means rapid prototyping and reduced time from concept to working demo.
Integrated Agent Framework Support
GLM-4.5’s design allows seamless integration across multiple agent frameworks[3]. The model supports diverse tasks and efficiently manages long-horizon rollouts through a unified interface.
Choose GLM-4.5 for agent applications if:
- You need multi-step reasoning with tool use
- Your workflow requires generating complex code artifacts
- You’re building custom agents that need to maintain context across many turns
- You want to avoid vendor lock-in with proprietary agent platforms
The unified architecture means you’re not cobbling together separate models for reasoning, coding, and tool use. One model handles the full agent workflow, reducing complexity and potential points of failure.
For teams exploring agent development, platforms like MULTIBLY let you compare GLM-4.5’s agent capabilities against other models side-by-side, helping you identify the right tool for your specific use case.
What Are the Practical Deployment Considerations for GLM-4.5?
Open-source access to GLM-4.5 from Z.ai: The 355B MoE Model Redefining Open-Source Performance means developers can deploy the model on their own infrastructure. This flexibility comes with important considerations around hardware requirements, optimization, and cost.
Hardware and Infrastructure Requirements
Minimum requirements for GLM-4.5 (355B total, 32B active):
- GPU memory: 64GB+ (for inference)
- Recommended: 80GB A100 or H100 GPUs
- For production: Multi-GPU setup with tensor parallelism
GLM-4.5-Air (106B total, 12B active) is more accessible:
- GPU memory: 24GB+ (for inference)
- Can run on consumer-grade RTX 4090 or professional A10G/A100 40GB
- Better suited for teams with limited infrastructure
The MoE architecture helps significantly. Because only 32 billion parameters activate per inference, memory requirements are lower than a dense 355B model. You’re loading the full parameter set but only computing through the active subset.
Optimization Strategies
Quantization options:
- FP16: Standard precision, best quality
- INT8: 2x memory reduction, minimal quality loss
- INT4: 4x memory reduction, acceptable for many tasks
For most production deployments, INT8 quantization offers the best balance. You cut memory requirements in half while maintaining near-original performance.
Batching considerations:
- MoE models can be sensitive to batch size due to expert routing
- Start with smaller batches (2-8) and scale up while monitoring quality
- Dynamic batching can improve throughput for variable request loads
Cost Analysis
Self-hosted GLM-4.5 (estimated monthly costs):
- Single A100 80GB: $1,000-$2,000/month (cloud rental)
- Multi-GPU setup: $3,000-$8,000/month depending on scale
- One-time setup and optimization: 40-80 hours of engineering time
Compare to API-based alternatives:
- GPT-4: ~$30 per million tokens (input) + $60 per million tokens (output)
- Claude: Similar pricing structure
- Break-even point: Typically 5-10 million tokens/month makes self-hosting competitive
Choose self-hosted GLM-4.5 if:
- You process millions of tokens monthly
- You need data privacy and on-premises deployment
- You require custom fine-tuning for domain-specific tasks
- You want to avoid API rate limits and vendor dependencies
Stick with API services if:
- Your usage is sporadic or low-volume
- You need zero infrastructure management
- You want to test multiple models without commitment (platforms like MULTIBLY provide access to 80+ models including GLM variants for one subscription)
A common mistake is underestimating the engineering effort required for production deployment. Budget for monitoring, optimization, and ongoing maintenance—not just the initial setup.
How Has GLM-4.5 Evolved and What Came After?
GLM-4.5 from Z.ai: The 355B MoE Model Redefining Open-Source Performance established a foundation that Z.ai continued to build upon. Understanding this evolution helps contextualize where GLM-4.5 fits in the broader landscape.
From GLM-4.5 to GLM-4.7
In December 2025, Z.ai released GLM-4.7, which showed significant improvements over GLM-4.5 across coding benchmarks[1]. The architectural foundation remained similar, but refinements in training and optimization delivered measurable gains.
GLM-4.7 improvements over GLM-4.5:
- SWE-bench: 73.8% (+5.8 percentage points)
- SWE-bench Multilingual: 66.7% (+12.9 percentage points)
- Terminal Bench 2.0: 41% (+16.5 percentage points)
These aren’t trivial improvements. A 12.9 percentage point gain on SWE-bench Multilingual represents a substantial leap in the model’s ability to handle coding tasks across different programming languages.
The progression from GLM-4.5 to GLM-4.7 demonstrates Z.ai’s iterative approach: establish a strong architectural foundation, then refine through improved training data, optimization techniques, and targeted enhancements.
GLM-5: The Current Flagship
On February 12, 2026, Z.ai released GLM-5, scaling to 744 billion parameters with 40 billion active parameters[2][5]. This represents more than a doubling of total capacity while maintaining manageable inference costs through the MoE architecture.
Key GLM-5 innovations:
- DeepSeek Sparse Attention: Improved efficiency for long-context processing
- “Slime” post-training technology: Novel approach for enhanced reasoning and coding capabilities[2][5]
- Larger active parameter count (40B vs. 32B) for more nuanced outputs
GLM-5 builds directly on the foundation GLM-4.5 established. The core MoE principles, agent-first design philosophy, and open-source commitment remain consistent. What changed is scale and refinement.
Where GLM-4.5 Still Makes Sense
Even with GLM-5 available, GLM-4.5 remains relevant for specific use cases:
Choose GLM-4.5 over GLM-5 if:
- You have tighter computational constraints (32B active vs. 40B active)
- Your infrastructure is already optimized for the 355B parameter scale
- You’re running large-scale deployments where the efficiency difference matters
- You need a proven, stable model rather than the latest release
Choose GLM-5 if:
- You need cutting-edge performance on complex reasoning tasks
- You’re building new deployments and can optimize for the latest architecture
- Your use case benefits from the enhanced coding and agent capabilities
- You want the longest runway before needing to upgrade again
The relationship between GLM-4.5 and GLM-5 mirrors the broader trend in AI: continuous improvement rather than revolutionary leaps. Each generation builds incrementally on the last, and older generations remain viable for many applications.
This progression also highlights the value of open-source models. When Z.ai releases GLM-5, GLM-4.5 doesn’t disappear behind a deprecated API. Developers who invested in GLM-4.5 deployments can continue using them indefinitely, upgrading only when the benefits justify the migration effort.
For context on how this compares to other model families, small models like Phi-4 and Mistral are also seeing rapid iteration, though at different scales and for different use cases.
What Are the Key Advantages of Open-Source Access to GLM-4.5?
The defining characteristic of GLM-4.5 from Z.ai: The 355B MoE Model Redefining Open-Source Performance is its open availability. This isn’t just a philosophical preference—it creates tangible advantages for developers and organizations building AI applications.
Full Model Customization
With open-source access, you can fine-tune GLM-4.5 for domain-specific tasks. A medical AI company can train the model on clinical data. A legal tech startup can specialize it for contract analysis. A financial services firm can adapt it for regulatory compliance.
Fine-tuning approaches:
- Full fine-tuning: Update all parameters for maximum customization (resource-intensive)
- LoRA (Low-Rank Adaptation): Efficient fine-tuning that updates a small subset of parameters
- Prefix tuning: Add task-specific prefixes without modifying base weights
- Instruction tuning: Refine the model’s instruction-following behavior for your use case
Closed-source models like GPT-4 offer limited fine-tuning options, and you never get access to the full model weights. With GLM-4.5, you have complete control.
Data Privacy and On-Premises Deployment
When you use API-based models, your data passes through the provider’s infrastructure. For healthcare, finance, government, and other regulated industries, this creates compliance challenges.
GLM-4.5 can run entirely on your infrastructure:
- No data leaves your environment
- Full audit trail of model behavior
- Compliance with HIPAA, GDPR, SOC 2, and other frameworks
- No risk of provider data breaches affecting your data
Real-world scenario: A healthcare provider building a clinical decision support tool needs to ensure patient data never leaves their HIPAA-compliant infrastructure. GLM-4.5 deployed on-premises solves this completely, while GPT-4 API calls create compliance risk.
No Vendor Lock-In
API-based models create dependency on the provider. If pricing changes, service degrades, or the model is deprecated, you’re forced to adapt or migrate.
With GLM-4.5:
- You control the deployment timeline
- No risk of sudden price increases
- Model remains available even if Z.ai changes direction
- You can maintain older versions if they work better for your use case
This independence is particularly valuable for long-term projects. A model you deploy today will still be available in five years, regardless of market changes.
Cost Predictability
API pricing can fluctuate based on demand, provider strategy, or market conditions. Self-hosted GLM-4.5 has predictable costs:
- Fixed infrastructure expenses
- No per-token charges
- Costs scale linearly with usage (add more GPUs for more capacity)
- One-time optimization investment amortizes over time
Cost comparison example:
- API-based (GPT-4): $30-60 per million tokens = $3,000-6,000 for 100M tokens/month
- Self-hosted GLM-4.5: $2,000-4,000/month infrastructure + one-time setup = break-even at ~50-100M tokens/month
For high-volume applications, self-hosting becomes dramatically cheaper. For low-volume or experimental use, APIs remain more cost-effective.
Community Innovation
Open-source models benefit from community contributions. Developers worldwide create optimizations, tools, and integrations that improve the ecosystem.
Community contributions for GLM models include:
- Quantization scripts for reduced memory usage
- Integration libraries for popular frameworks
- Deployment guides for various cloud platforms
- Performance benchmarks across different hardware
You benefit from this collective innovation without waiting for a single vendor to prioritize your needs.
Common mistake: Assuming open-source means “free.” While the model weights are free, production deployment requires infrastructure, engineering effort, and ongoing maintenance. Budget accordingly.
For teams that want to experiment with GLM-4.5 alongside other models before committing to infrastructure, MULTIBLY’s platform provides access to compare responses across 80+ models, including GLM variants, helping you validate fit before investing in deployment.
What Challenges and Limitations Should You Consider?
GLM-4.5 from Z.ai: The 355B MoE Model Redefining Open-Source Performance delivers impressive capabilities, but no model is perfect for every use case. Understanding the limitations helps you make informed decisions.
Infrastructure Requirements
The 355 billion parameter scale, even with only 32 billion active, requires substantial hardware. Small teams or individual developers may struggle with the infrastructure costs.
Mitigation strategies:
- Use GLM-4.5-Air (106B total, 12B active) for lower resource requirements
- Leverage cloud GPU rentals for burst capacity
- Apply aggressive quantization (INT4) for inference
- Consider API access through platforms that host the model
Specialized Domain Performance
While GLM-4.5 performs well across general tasks, highly specialized domains may benefit from models specifically trained for that area. A model trained exclusively on legal documents might outperform GLM-4.5 for contract analysis, even if GLM-4.5 has broader capabilities.
When to choose specialized models:
- Your use case is narrow and well-defined
- Domain-specific accuracy is critical
- You have access to high-quality domain data for fine-tuning
- The specialized model has proven benchmarks in your area
When GLM-4.5’s generalist approach wins:
- You need versatility across multiple tasks
- Your application combines reasoning, coding, and agent capabilities
- You want one model rather than managing multiple specialized systems
- Your domain doesn’t have strong specialized alternatives
Rapidly Evolving Landscape
AI models improve quickly. GLM-4.5 was released as a flagship, then superseded by GLM-4.7 and GLM-5 within months. This rapid evolution can create upgrade fatigue.
Managing model evolution:
- Establish clear upgrade criteria (performance thresholds, feature requirements)
- Don’t chase every release—upgrade when benefits justify migration costs
- Build abstraction layers so swapping models doesn’t require full rewrites
- Test new releases in parallel before migrating production systems
MoE Routing Complexity
Mixture-of-experts models can exhibit less predictable behavior than dense models. Different inputs might route to different experts, creating subtle variations in output style or quality.
Practical implications:
- Outputs may vary more than with dense models for similar inputs
- Batch processing might show more variation than sequential processing
- Some inputs might hit less-trained experts, reducing quality
Mitigation:
- Test thoroughly across representative inputs
- Use temperature and sampling parameters to control variation
- Monitor output quality metrics in production
- Consider ensemble approaches for critical applications
Limited Multimodal Capabilities
GLM-4.5 focuses primarily on text and code. While it handles these modalities exceptionally well, it doesn’t natively process images, audio, or video like some multimodal competitors.
If you need multimodal capabilities:
- Combine GLM-4.5 with specialized vision or audio models
- Use preprocessing to convert other modalities to text descriptions
- Consider multimodal alternatives if your use case heavily depends on image/video understanding
- Watch for future GLM releases that may add multimodal support
Edge case: For applications that combine text reasoning with image analysis, you might use a vision model to describe images, then pass those descriptions to GLM-4.5 for reasoning. This pipeline approach can work well but adds complexity.
Understanding these limitations doesn’t diminish GLM-4.5’s value—it helps you deploy it effectively. Every model has trade-offs. The question isn’t whether GLM-4.5 is perfect, but whether its strengths align with your requirements better than alternatives.
How to Get Started with GLM-4.5 for Your Projects

Moving from understanding GLM-4.5 from Z.ai: The 355B MoE Model Redefining Open-Source Performance to actually using it requires a clear implementation path. Here’s a practical roadmap.
Step 1: Validate Fit Before Committing Infrastructure
Before investing in deployment infrastructure, confirm GLM-4.5 meets your needs.
Validation approaches:
- API access: Use hosted versions through platforms that provide GLM-4.5 access
- Side-by-side comparison: Test GLM-4.5 against alternatives on your actual use cases
- Benchmark on representative tasks: Don’t rely on published benchmarks—test your specific workflows
Platforms like MULTIBLY let you compare GLM-4.5 responses against 80+ other models, helping you identify the best fit before committing to infrastructure.
Step 2: Choose Your Deployment Path
Based on your requirements and resources, select the appropriate deployment approach.
Deployment options:
| Approach | Best For | Considerations |
|---|---|---|
| Self-hosted (cloud) | High volume, data privacy needs | Requires GPU infrastructure, ongoing management |
| Self-hosted (on-prem) | Regulated industries, maximum control | Highest upfront cost, full control |
| Hosted API | Testing, low volume, minimal infrastructure | Less control, per-token costs |
| Hybrid | Variable workloads | Use hosted for spikes, self-hosted for baseline |
Step 3: Set Up Infrastructure
For self-hosted deployments, provision and configure your infrastructure.
Infrastructure setup checklist:
- Provision GPU instances (A100 80GB recommended for GLM-4.5)
- Install required dependencies (PyTorch, transformers, etc.)
- Download model weights from official sources
- Configure tensor parallelism for multi-GPU setups
- Apply quantization if needed (INT8 recommended for production)
- Set up monitoring and logging
- Implement request batching for efficiency
- Configure security and access controls
Step 4: Optimize for Your Use Case
Generic deployment rarely delivers optimal results. Tailor the model to your needs.
Optimization strategies:
- Prompt engineering: Develop effective prompts for your specific tasks
- Few-shot examples: Include examples in prompts to guide behavior
- Fine-tuning: If you have domain-specific data, fine-tune for better performance
- Parameter tuning: Adjust temperature, top-p, and other sampling parameters
- Caching: Implement prompt caching for repeated queries
Step 5: Implement Production Safeguards
Moving from testing to production requires additional considerations.
Production checklist:
- Implement rate limiting to prevent abuse
- Set up output filtering for inappropriate content
- Create fallback mechanisms for model failures
- Establish monitoring for latency, throughput, and quality
- Document model behavior and limitations for users
- Plan for model updates and version management
- Implement A/B testing framework for improvements
Step 6: Monitor and Iterate
Deployment isn’t the end—it’s the beginning of an optimization cycle.
Key metrics to track:
- Latency: Time from request to response
- Throughput: Requests processed per second
- Quality: Task-specific accuracy or user satisfaction
- Cost: Infrastructure and operational expenses
- Reliability: Uptime and error rates
Iterate based on data:
- Identify bottlenecks and optimize
- Collect user feedback on output quality
- Compare performance against benchmarks
- Test new optimization techniques
- Consider upgrading to GLM-4.7 or GLM-5 when benefits justify migration
Common mistake: Deploying once and assuming you’re done. Production AI systems require ongoing monitoring, optimization, and adaptation. Budget for continuous improvement, not just initial deployment.
For teams exploring multiple models, comparing Claude 4 Sonnet vs GPT-4o performance alongside GLM-4.5 can help identify which model best suits different tasks within your workflow.
Frequently Asked Questions
What is the difference between GLM-4.5 and GLM-4.5-Air?
GLM-4.5 features 355 billion total parameters with 32 billion active, while GLM-4.5-Air has 106 billion total parameters with 12 billion active[3]. GLM-4.5 delivers maximum capability for complex tasks, while GLM-4.5-Air offers strong performance with lower computational requirements. Choose GLM-4.5 for demanding reasoning and agent workflows; choose GLM-4.5-Air for cost-sensitive deployments where good performance is sufficient.
Can GLM-4.5 run on consumer hardware?
GLM-4.5 (355B) requires professional-grade GPUs with 64GB+ memory, making consumer hardware insufficient for the full model. GLM-4.5-Air (106B) can run on high-end consumer GPUs like RTX 4090 with 24GB VRAM, especially with INT8 quantization. For most users, cloud GPU rental or hosted API access is more practical than consumer hardware deployment.
How does GLM-4.5’s mixture-of-experts architecture improve efficiency?
MoE architecture activates only 32 billion of the 355 billion total parameters per inference, reducing computational cost by approximately 11x compared to a dense 355B model[3]. This selective activation maintains the knowledge capacity of the full parameter set while keeping inference costs closer to a 32B dense model. The routing mechanism directs each input to the most relevant expert modules, often improving quality while reducing computation.
Is GLM-4.5 better than GPT-4 for coding tasks?
GLM-4.5 delivers competitive coding performance with GPT-4, particularly for agent-based workflows and artifact generation[3]. The model creates sophisticated standalone applications including interactive games and simulations. For multi-step coding tasks with tool use, GLM-4.5’s Interleaved Thinking and agent-first design can outperform GPT-4. For general code completion, performance is comparable. The key advantage is open-source access for customization and on-premises deployment.
What are the ongoing costs of running GLM-4.5 in production?
Cloud-hosted GLM-4.5 costs approximately $1,000-$2,000 monthly for a single A100 80GB GPU, with multi-GPU setups ranging from $3,000-$8,000 monthly depending on scale. On-premises deployment has higher upfront hardware costs but lower ongoing expenses. Break-even versus API-based models typically occurs around 5-10 million tokens monthly. Include engineering time for setup (40-80 hours) and ongoing optimization in total cost calculations.
Can I fine-tune GLM-4.5 for my specific domain?
Yes, GLM-4.5’s open-source availability enables full fine-tuning for domain-specific applications. You can apply full fine-tuning, LoRA (Low-Rank Adaptation), prefix tuning, or instruction tuning depending on your resources and requirements. Fine-tuning requires access to quality domain data and GPU infrastructure, but allows you to specialize the model for medical, legal, financial, or other specific use cases where general models may underperform.
How does GLM-4.5 handle long-context tasks?
GLM-4.5 handles extended context through efficient MoE routing, though it doesn’t match specialized long-context models like Kimi K2’s 256K context window. For most agent and coding tasks, GLM-4.5’s context handling is sufficient. If your application requires processing extremely long documents (100K+ tokens), consider specialized long-context models or implement retrieval-augmented generation (RAG) to provide relevant context chunks to GLM-4.5.
What programming languages and frameworks does GLM-4.5 support best?
GLM-4.5 generates sophisticated code across HTML, SVG, Python, JavaScript, and other common languages[3][1]. The model performs particularly well on Python for data science and backend tasks, and JavaScript/HTML for front-end development. It supports integration with multiple agent frameworks through a unified interface. For specialized languages or frameworks, test performance on representative tasks before committing to production use.
Should I use GLM-4.5 or upgrade to GLM-5?
Choose GLM-4.5 if you have infrastructure optimized for 355B parameters with 32B active, need a proven stable model, or have tighter computational constraints. Choose GLM-5 if you need cutting-edge performance (744B total, 40B active)[2][5], are building new deployments, or require the latest reasoning and coding enhancements. For existing GLM-4.5 deployments, upgrade when specific GLM-5 capabilities justify the migration effort.
How does GLM-4.5 compare to other open-source alternatives?
GLM-4.5 competes directly with models like DeepSeek R1 and V3.1 in the open-source space. GLM-4.5’s strengths include agent-first design, sophisticated artifact generation, and Interleaved Thinking capabilities[3][1]. DeepSeek models may excel in specific reasoning benchmarks. The best choice depends on your specific use case—test both on representative tasks. Platforms like MULTIBLY allow side-by-side comparison to identify the optimal model for your needs.
What security considerations apply when deploying GLM-4.5?
Self-hosted GLM-4.5 requires standard security practices: implement access controls, rate limiting, input validation, and output filtering. Monitor for adversarial inputs attempting to manipulate model behavior. For regulated industries, ensure your deployment meets compliance requirements (HIPAA, GDPR, etc.). The advantage of self-hosting is complete control over data flow—no information leaves your infrastructure. Implement logging and auditing to track model usage and detect anomalies.
Can GLM-4.5 replace my entire AI infrastructure?
GLM-4.5’s unified architecture for reasoning, coding, and agent tasks means it can consolidate multiple specialized models for many use cases[3]. However, highly specialized domains (medical imaging, speech recognition, etc.) may still benefit from purpose-built models. Evaluate whether GLM-4.5’s general capabilities meet your quality requirements across all tasks, or whether a hybrid approach combining GLM-4.5 with specialized models delivers better results.
Conclusion
GLM-4.5 from Z.ai: The 355B MoE Model Redefining Open-Source Performance represents a milestone in accessible AI. The combination of 355 billion parameters with efficient mixture-of-experts activation delivers performance that matches proprietary giants while remaining fully open for developer customization and deployment.
For teams building AI applications in 2026, the model offers a compelling value proposition: competitive capability without vendor lock-in, full control over deployment and data, and the flexibility to fine-tune for domain-specific needs. The agent-first design philosophy, sophisticated code generation, and Interleaved Thinking capabilities make GLM-4.5 particularly well-suited for modern AI workflows that combine reasoning, tool use, and multi-step execution.
The key question isn’t whether GLM-4.5 is the “best” model in absolute terms—that depends entirely on your specific requirements. The question is whether the combination of strong performance, open access, and deployment flexibility aligns better with your needs than closed alternatives.
Next Steps
If you’re evaluating GLM-4.5 for your projects:
Test before committing – Use platforms like MULTIBLY to compare GLM-4.5 against alternatives on your actual use cases before investing in infrastructure.
Start with GLM-4.5-Air if resources are constrained – The 106B variant delivers strong performance with lower computational requirements, providing a practical entry point.
Calculate your break-even point – Compare self-hosting costs against API pricing based on your expected token volume to determine the most cost-effective approach.
Plan for evolution – The rapid progression from GLM-4.5 to GLM-4.7 to GLM-5 demonstrates continuous improvement. Build abstraction layers that allow model upgrades without complete rewrites.
Leverage the open-source advantage – If data privacy, customization, or vendor independence matter for your use case, GLM-4.5’s open availability creates value that closed models can’t match.
The open-source AI landscape continues to mature rapidly. Models like GLM-4.5, alongside DeepSeek’s offerings and the small model revolution, demonstrate that the performance gap between open and closed models continues to narrow. The question increasingly isn’t whether open-source models can compete, but which specific model best fits your specific needs.
For most teams, the answer involves testing multiple options, understanding the trade-offs, and choosing based on actual performance rather than marketing claims. GLM-4.5 deserves serious consideration in that evaluation—not because it’s perfect for every use case, but because it delivers a rare combination of capability, accessibility, and control that makes it genuinely competitive with the industry’s leading closed-source alternatives.
References
[1] Glm 4 – https://github.com/zai-org/GLM-4.5
[2] New Released – https://docs.z.ai/release-notes/new-released
[3] Glm 4 – https://z.ai/blog/glm-4.5
[4] Glm 5 Lands On Atlas Cloud Access Zhipu Ais 744b Moe Flagship For Complex Reasoning Coding And Agentic Capabilities – https://www.atlascloud.ai/blog/GLM-5-Lands-on-Atlas-Cloud-Access-ZHIPU-AIs-744B-MoE-Flagship-for-Complex-Reasoning-Coding-and-Agentic-Capabilities
[5] Glm 5 Launch Signals A New Era In Ai When Models Become Engineers – https://www.businesswire.com/news/home/20260215030665/en/GLM-5-Launch-Signals-a-New-Era-in-AI-When-Models-Become-Engineers
Our Fact Checking Process
We prioritize accuracy and integrity in our content. Here's how we maintain high standards:
- Expert Review: All articles are reviewed by subject matter experts.
- Source Validation: Information is backed by credible, up-to-date sources.
- Transparency: We clearly cite references and disclose potential conflicts.
Our Review Board
Our content is carefully reviewed by experienced professionals to ensure accuracy and relevance.
- Qualified Experts: Each article is assessed by specialists with field-specific knowledge.
- Up-to-date Insights: We incorporate the latest research, trends, and standards.
- Commitment to Quality: Reviewers ensure clarity, correctness, and completeness.
Look for the expert-reviewed label to read content you can trust.



