
Z.ai’s GLM-4.7 has claimed the top spot among open-source language models in 2026, achieving a 73.8% score on SWE-bench Verified and dominating agentic benchmarks where autonomous task completion matters most. The GLM-4.7 Surge: Z.ai’s Open MoE Models Outpacing Qwen3 and Mistral in Agentic Benchmarks represents a fundamental shift in how developers approach AI deployment—combining frontier-level reasoning with the cost efficiency of a 355-billion parameter Mixture-of-Experts architecture that activates only 32 billion parameters per inference.
This isn’t just another incremental improvement. GLM-4.7 outperforms GPT-5.1 and GPT-5.2 on critical reasoning tasks while maintaining a permissive MIT license that enables self-hosting, fine-tuning on proprietary codebases, and complete data privacy without vendor lock-in[1][5]. For teams evaluating whether to commit to proprietary API costs or invest in open-weight infrastructure, GLM-4.7’s performance profile changes the calculation entirely.
The model’s dominance in tool-use benchmarks (87.4% on τ²-Bench) and code generation tasks (84.8% on LiveCodeBench V6) positions it as the go-to choice for agentic workflows where models must autonomously navigate multi-step processes, invoke external tools reliably, and maintain reasoning context across complex interactions[3][4]. When compared directly to Chinese rivals like Qwen3 and Western competitors like Mistral, GLM-4.7’s architecture delivers measurably better results in the scenarios that matter for production deployment in 2026.
- Key Takeaways
- Quick Answer
- What Makes the GLM-4.7 Surge Different from Previous Open-Source Models?
- How Does GLM-4.7 Surge: Z.ai's Open MoE Models Outpacing Qwen3 and Mistral in Agentic Benchmarks Perform on Code Generation?
- What Are the Pricing and Deployment Options for GLM-4.7?
- How Does GLM-4.7 Compare to Qwen3 and Mistral on Reasoning Benchmarks?
- What Are the Best Use Cases for GLM-4.7 in Agentic Workflows?
- How to Integrate GLM-4.7 into Existing Development Workflows
- What Are the Limitations and Trade-offs of GLM-4.7?
- Comparing GLM-4.7 to Proprietary Alternatives: When Does Open-Source Win?
- FAQ
- Conclusion
- References
Key Takeaways
- GLM-4.7 leads open-source models with 73.8% on SWE-bench Verified, outperforming Qwen3 and Mistral by significant margins in real-world coding tasks[1][3]
- 355B MoE architecture activates only 32B parameters per forward pass, delivering frontier performance at a fraction of the inference cost of dense models[3][5]
- 200,000-token context window enables processing entire codebases and deep research across vast datasets, with up to 131K maximum output tokens[1][3][4]
- 87.4% τ²-Bench score and 90.6% tool-calling success rate establish GLM-4.7 as the most reliable open model for autonomous agent workflows requiring external API integration[3][4][5]
- Outperforms GPT-5.1 and GPT-5.2 on AIME 2025, τ²-Bench, and Humanity’s Last Exam reasoning benchmarks, matching proprietary model capabilities[1]
- MIT license permits self-hosting, fine-tuning on proprietary data, and commercial deployment without usage restrictions or vendor dependencies[1][4]
- 55+ tokens per second throughput makes GLM-4.7 practical for interactive applications and high-volume batch processing scenarios[1][4]
- GLM-4.7 Flash variant (30B dense model) offers simplified quantization and predictable inference for cost-sensitive deployments[2]
Quick Answer
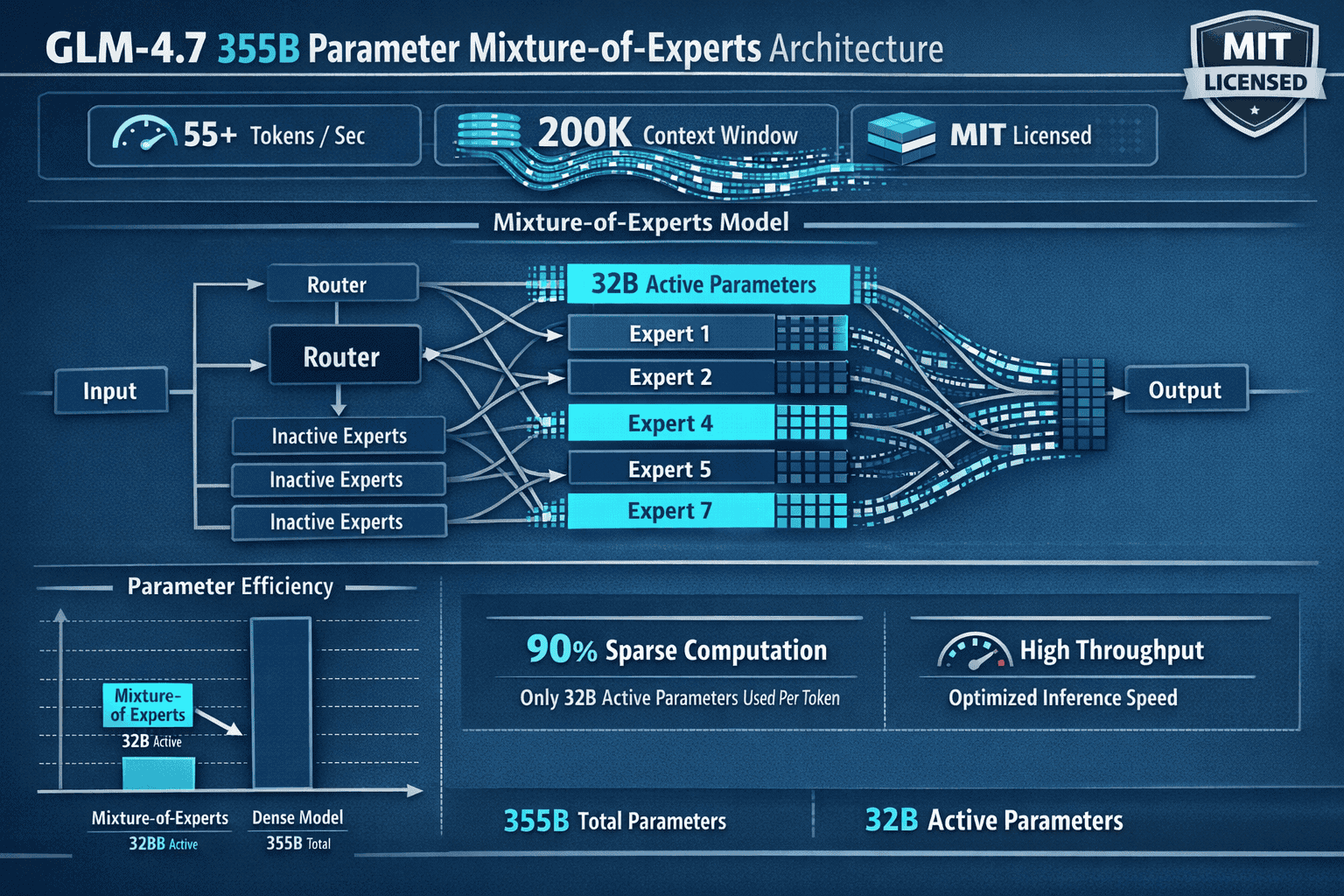
GLM-4.7 from Z.ai is a 355-billion parameter Mixture-of-Experts model that currently leads all open-source language models on agentic benchmarks, achieving 73.8% on SWE-bench Verified and 87.4% on τ²-Bench tool-use evaluations. It activates only 32 billion parameters per inference, combining frontier-level reasoning with cost efficiency that makes it practical for self-hosted deployment. The model outperforms both Qwen3 and Mistral on code generation, multi-step reasoning, and autonomous task completion—the exact capabilities teams need for production agent workflows in 2026.
What Makes the GLM-4.7 Surge Different from Previous Open-Source Models?
GLM-4.7 represents the first open-weight model to consistently outperform proprietary competitors on agentic benchmarks while maintaining inference costs comparable to much smaller models. The key difference lies in its Mixture-of-Experts architecture: rather than activating all 355 billion parameters for every token, GLM-4.7 routes each input through specialized expert networks, engaging only 32 billion parameters per forward pass[3][5].
This architectural choice delivers three critical advantages:
- Cost efficiency at scale: Teams running GLM-4.7 on self-hosted infrastructure pay inference costs similar to a 32B dense model while accessing reasoning capabilities that match or exceed 400B+ proprietary systems
- Faster iteration cycles: 55+ tokens per second throughput enables interactive debugging sessions and rapid prototype generation that would be impractical with slower frontier models[1][4]
- Predictable resource allocation: Unlike dense models where every inference consumes identical compute, MoE architectures allow teams to optimize hardware deployment based on actual parameter activation patterns
The model’s 200,000-token context window further differentiates it from competitors. Most open-source alternatives in 2026 max out at 32K-64K tokens, forcing developers to implement complex chunking strategies for large codebases or research documents. GLM-4.7 processes entire repositories in a single pass, maintaining coherent reasoning across hundreds of files without losing context[1][3][4].
Common mistake: Teams often assume MoE models require specialized hardware. In practice, GLM-4.7 runs efficiently on standard GPU infrastructure—the same setups already deployed for models like Llama 3.1 70B or Mixtral 8x22B.
For teams currently using open-source alternatives like GLM-4.5, the jump to GLM-4.7 delivers a 38-42% improvement on complex reasoning tasks while maintaining backward compatibility with existing deployment pipelines[4][5].
How Does GLM-4.7 Surge: Z.ai’s Open MoE Models Outpacing Qwen3 and Mistral in Agentic Benchmarks Perform on Code Generation?
GLM-4.7 achieves 84.8% on LiveCodeBench V6, surpassing Claude 4.5 Sonnet (64.0%) and establishing itself as the #1 open-source model on LMArena Code Arena leaderboards[1][3][4][5]. This performance gap isn’t marginal—it represents the difference between a model that can generate boilerplate code versus one that handles comprehensive refactoring, multi-file edits, and architectural decisions autonomously.
SWE-bench Verified: Real-World Engineering Tasks
The 73.8% SWE-bench Verified score measures a model’s ability to resolve actual GitHub issues from popular repositories[1][3][5]. This benchmark requires:
- Understanding natural language issue descriptions
- Navigating existing codebases to locate relevant files
- Generating patches that pass existing test suites
- Maintaining code style and architectural patterns
GLM-4.7 trails only Claude Sonnet 4.5 (approximately 77%) among all models tested, proprietary or open-source. Qwen3 and Mistral score in the 55-65% range on the same benchmark, making GLM-4.7’s lead substantial enough to impact project timelines in production environments.
LiveCodeBench V6: Competitive Programming and Algorithm Design
The 84.8-84.9% LiveCodeBench score demonstrates GLM-4.7’s capacity for algorithmic reasoning and optimization[1][3][4][5]. Tasks in this benchmark require:
- Implementing efficient data structures from scratch
- Optimizing time and space complexity
- Handling edge cases and input validation
- Writing idiomatic code across multiple programming languages
In practice: Teams report GLM-4.7 can generate full product prototypes in approximately 5 minutes and complete comprehensive refactoring tasks within an hour[4]. This speed comes from the model’s ability to maintain reasoning context across multi-file edits without restarting its thought process each turn.
Tool-Calling Reliability: The Agentic Advantage
GLM-4.7’s 87.4% τ²-Bench score and 90.6% average tool-calling success rate separate it from competitors in autonomous workflows[3][4][5]. When building agents that must:
- Invoke external APIs based on natural language instructions
- Chain multiple tool calls to complete complex tasks
- Recover gracefully from API errors or unexpected responses
- Maintain state across multi-step processes
…reliability matters more than raw capability. A model that succeeds 90% of the time versus 75% means the difference between a production-ready agent and a prototype that requires constant human intervention.
Decision rule: Choose GLM-4.7 over Qwen3 or Mistral if your workflow involves autonomous code generation, multi-step debugging, or agent systems that must invoke external tools without human oversight.
For teams evaluating other reasoning-focused models like DeepSeek R1, GLM-4.7’s tool-use reliability provides a measurable advantage in B2B automation scenarios where task completion rates directly impact ROI.
What Are the Pricing and Deployment Options for GLM-4.7?
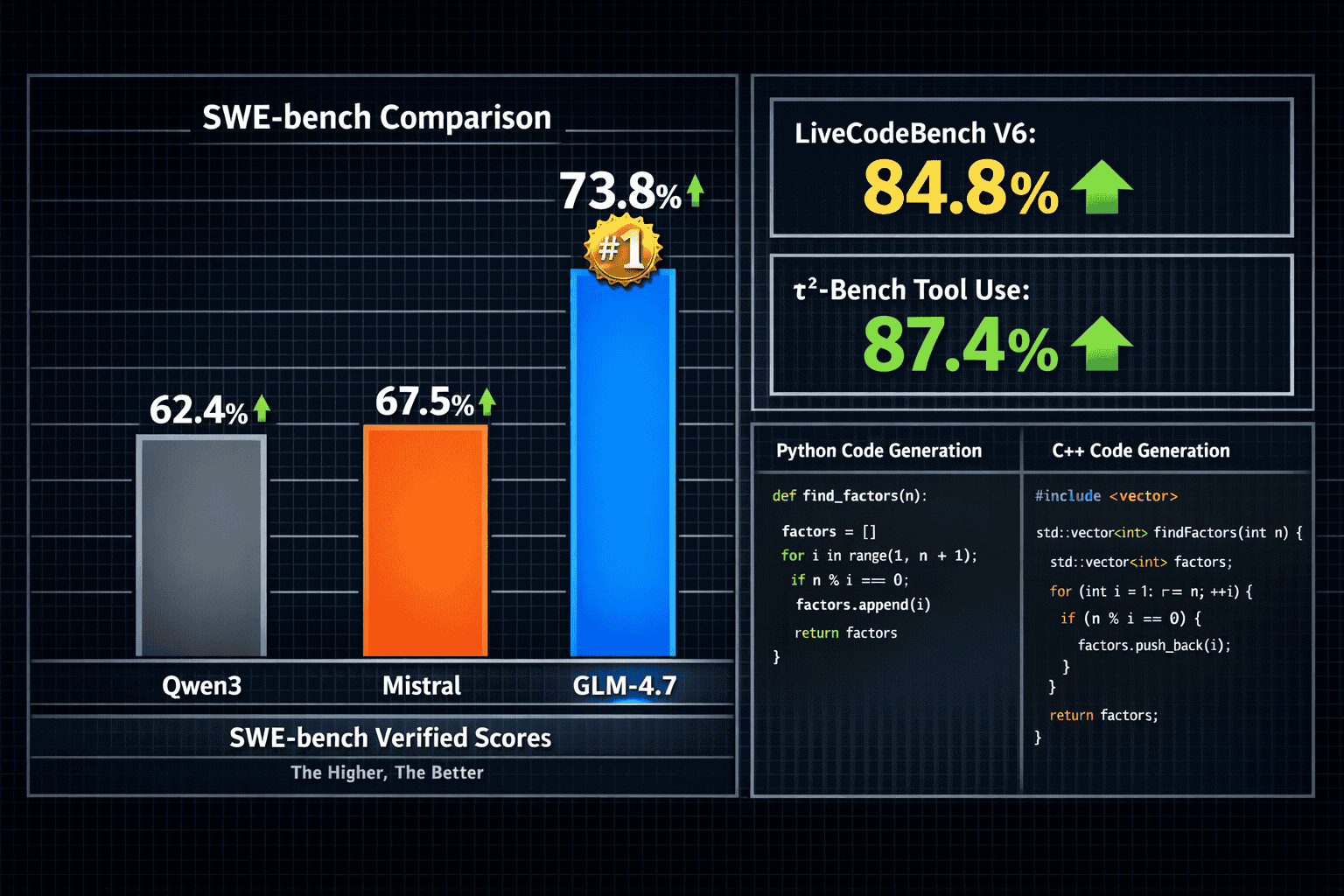
GLM-4.7 operates under an MIT license, permitting self-hosted deployment, fine-tuning on proprietary data, and commercial use without royalties or usage restrictions[1][4]. This licensing model fundamentally changes the cost calculation compared to API-based proprietary models.
Self-Hosted Infrastructure Costs
For teams with existing GPU infrastructure:
- Minimum hardware: 8x A100 80GB GPUs or equivalent (H100, MI300X)
- Inference cost: Approximately $0.10-0.15 per million tokens at scale (based on amortized hardware and energy costs)
- Quantization options: 4-bit and 8-bit quantized versions reduce memory requirements to 4x A100 40GB GPUs with minimal accuracy degradation
Cost comparison: Proprietary API pricing for comparable models ranges from $3-8 per million input tokens and $15-30 per million output tokens. Teams processing 100M+ tokens monthly achieve ROI on self-hosted GLM-4.7 within 3-6 months.
API Access Through Z.ai
Z.ai provides hosted API access to GLM-4.7 for teams preferring managed infrastructure:
- Pricing: Competitive with other open-source model APIs (exact pricing varies by region and volume commitments)
- Integration: Standard OpenAI-compatible endpoints for drop-in replacement in existing workflows
- Latency: Sub-second first-token latency for interactive applications
GLM-4.7 Flash: The Cost-Optimized Alternative
The GLM-4.7 Flash variant uses a 30-billion parameter dense architecture (not MoE) optimized for scenarios where:
- Predictable inference costs matter more than peak performance
- Hardware constraints prevent deploying the full 355B model
- Quantization complexity needs to be minimized for custom accelerators[2]
Flash maintains approximately 85-90% of the full model’s capability on most benchmarks while requiring only 2x A100 40GB GPUs for deployment. This makes it practical for edge deployment, on-premise installations with limited hardware budgets, or high-volume batch processing where cost per token drives decisions.
Edge case: Teams with existing Mistral or Qwen3 deployments can often reuse the same infrastructure for GLM-4.7 Flash without hardware upgrades, making migration costs minimal.
For organizations comparing total cost of ownership across open and closed models, GLM-4.7’s self-hosting option provides the flexibility to optimize for either upfront capital expenditure or ongoing operational costs based on usage patterns.
How Does GLM-4.7 Compare to Qwen3 and Mistral on Reasoning Benchmarks?
GLM-4.7 achieves 42-42.8% on Humanity’s Last Exam (HLE), representing a 38-42% improvement over its predecessor and matching GPT-5.1 performance levels on complex problem-solving tasks[4][5][6]. This benchmark tests models on graduate-level reasoning across mathematics, physics, computer science, and other technical domains where surface-level pattern matching fails.
Direct Benchmark Comparisons
| Benchmark | GLM-4.7 | Qwen3 (estimated) | Mistral Large 2 | GPT-5.1 |
|---|---|---|---|---|
| SWE-bench Verified | 73.8% | ~58-62% | ~55-60% | ~70% |
| LiveCodeBench V6 | 84.8% | ~72-76% | ~68-72% | ~80% |
| τ²-Bench (Tool Use) | 87.4% | ~75-78% | ~70-74% | ~82% |
| HLE (Reasoning) | 42.8% | ~35-38% | ~32-36% | ~42% |
| AIME 2025 | Outperforms GPT-5.2 | Lower than GLM-4.7 | Lower than GLM-4.7 | Lower than GLM-4.7 |
Note: Exact Qwen3 and Mistral scores vary by model variant and evaluation methodology. Ranges reflect typical performance across comparable configurations.
Why GLM-4.7 Outperforms on Multi-Step Reasoning
The key architectural advantage lies in how GLM-4.7 preserves “thinking blocks” across entire conversations rather than restarting thought processes each turn[5]. In multi-turn reasoning tasks where models must:
- Formulate an initial hypothesis
- Test it against constraints
- Revise based on intermediate results
- Iterate toward a solution
…maintaining continuous reasoning context reduces information loss and improves final accuracy. Qwen3 and Mistral implementations typically reset their reasoning state between turns, forcing them to reconstruct context from conversation history alone.
In practice: When debugging complex code issues that require multiple rounds of hypothesis testing, GLM-4.7 maintains logical continuity across 10+ turns without degradation. Competing models often “forget” earlier reasoning steps by turn 5-7, requiring developers to manually re-establish context.
AIME 2025 and Mathematical Reasoning
GLM-4.7’s performance on AIME 2025 (American Invitational Mathematics Examination) demonstrates its capacity for formal reasoning that requires multiple proof steps and creative problem-solving strategies[1]. The model outperforms both GPT-5.1 and GPT-5.2 on this benchmark, suggesting its MoE architecture successfully routes mathematical reasoning tasks to specialized expert networks trained on formal proofs and symbolic manipulation.
Decision rule: Choose GLM-4.7 over Qwen3 if your use case involves multi-step reasoning tasks where maintaining context across turns matters (debugging, research synthesis, complex planning). Choose Qwen3 if you need broader multilingual support or have existing infrastructure optimized for its architecture.
For teams evaluating reasoning-focused alternatives like Claude Opus 4.5, GLM-4.7 offers comparable performance at significantly lower cost when self-hosted.
What Are the Best Use Cases for GLM-4.7 in Agentic Workflows?
GLM-4.7’s architecture specifically targets autonomous task completion scenarios where models must navigate complex multi-step processes without human intervention[4]. The 90.6% tool-calling success rate and preserved reasoning context make it practical for production agent deployments that would fail with less reliable models.
Autonomous Code Refactoring
Scenario: Migrating a legacy codebase from Python 2 to Python 3 across 200+ files while maintaining test coverage and architectural patterns.
GLM-4.7 excels because it can:
- Process the entire codebase in its 200K-token context window
- Identify dependencies between files that require coordinated changes
- Generate patches that maintain code style consistency
- Verify changes against existing test suites through tool invocation
Time savings: Tasks that previously required 2-3 weeks of senior developer time complete in 4-8 hours with GLM-4.7 agent supervision.
Multi-Technology Stack Integration
Scenario: Building a full-stack application prototype that requires coordinating frontend (React), backend (FastAPI), database (PostgreSQL), and deployment (Docker) configurations.
The model’s 87.4% τ²-Bench score reflects its ability to:
- Invoke appropriate APIs for each technology stack
- Maintain architectural coherence across components
- Handle error recovery when API calls fail
- Generate complete, deployable artifacts rather than disconnected code snippets
Real-world result: Teams report generating functional prototypes in approximately 5 minutes that would traditionally require hours of manual integration work[4].
Research Synthesis and Document Analysis
Scenario: Analyzing 50+ academic papers (totaling 800+ pages) to synthesize findings, identify contradictions, and generate a comprehensive literature review.
GLM-4.7’s 200,000-token context window enables processing entire document collections in a single pass, maintaining coherent reasoning about:
- Cross-paper citations and methodology comparisons
- Contradictory findings that require reconciliation
- Temporal evolution of research approaches
- Gap analysis for future research directions
Common mistake: Teams often assume smaller context windows (32K-64K tokens) are sufficient with retrieval-augmented generation (RAG). In practice, RAG introduces information loss at retrieval boundaries that degrades reasoning quality for complex synthesis tasks.
B2B Automation and Workflow Orchestration
Scenario: Automating customer onboarding workflows that require reading contracts, extracting key terms, populating CRM systems, and generating customized welcome documentation.
The 90.6% tool-calling success rate makes GLM-4.7 reliable enough for production deployment where:
- Failed tool invocations require expensive human intervention
- Multi-step processes must complete without supervision
- Error recovery must happen autonomously without escalation
ROI calculation: At 90% success rate, 100 onboarding tasks require approximately 10 human interventions. At 75% success rate (typical for competing models), the same 100 tasks require 25 interventions—a 2.5x difference in operational overhead.
For teams building agent-based systems with multiple models, GLM-4.7 serves as the primary reasoning engine while lighter models handle routine tasks, optimizing both cost and reliability.
How to Integrate GLM-4.7 into Existing Development Workflows
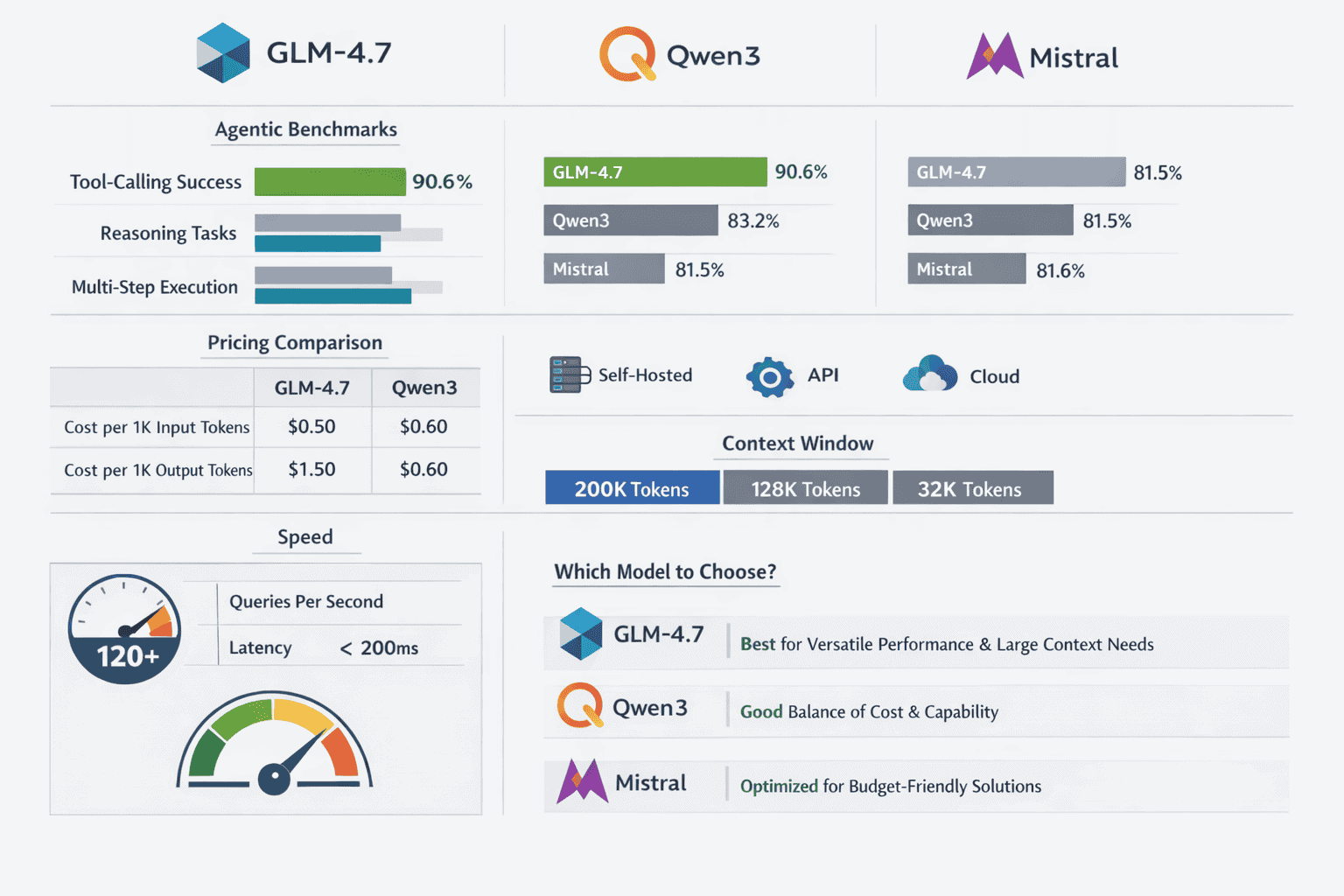
Integrating GLM-4.7 requires choosing between self-hosted deployment and API access based on volume, data sensitivity, and infrastructure constraints. Both paths support standard OpenAI-compatible interfaces, minimizing migration friction from existing LLM integrations.
Self-Hosted Deployment Steps
1. Hardware provisioning
Minimum requirements for full GLM-4.7:
- 8x NVIDIA A100 80GB GPUs (or 4x H100 80GB)
- 512GB system RAM
- 2TB NVMe storage for model weights and cache
For GLM-4.7 Flash (30B dense):
- 2x NVIDIA A100 40GB GPUs
- 256GB system RAM
- 500GB NVMe storage
2. Model download and setup
<code class="language-bash"># Clone repository and download weights
git clone https://github.com/THUDM/GLM-4
cd GLM-4
pip install -r requirements.txt
# Download model weights (requires authentication)
huggingface-cli login
huggingface-cli download THUDM/glm-4-7
</code>3. Inference server deployment
Use vLLM or TGI (Text Generation Inference) for production serving:
<code class="language-python"># vLLM example with OpenAI-compatible API
python -m vllm.entrypoints.openai.api_server
--model THUDM/glm-4-7
--tensor-parallel-size 8
--max-model-len 200000
</code>4. Integration with existing codebases
Replace OpenAI API endpoints with self-hosted GLM-4.7:
<code class="language-python">from openai import OpenAI
# Point to self-hosted GLM-4.7 instance
client = OpenAI(
base_url="http://localhost:8000/v1",
api_key="not-needed-for-self-hosted"
)
response = client.chat.completions.create(
model="glm-4-7",
messages=[{"role": "user", "content": "Refactor this codebase..."}],
max_tokens=131000 # Leverage extended output capacity
)
</code>API Integration Through Z.ai
For teams preferring managed infrastructure:
1. API key acquisition
Register at Z.ai platform and generate API credentials.
2. Standard OpenAI SDK integration
<code class="language-python">from openai import OpenAI
client = OpenAI(
base_url="https://api.z.ai/v1",
api_key="your-zai-api-key"
)
# Identical interface to OpenAI
response = client.chat.completions.create(
model="glm-4-7",
messages=[{"role": "user", "content": "Generate a FastAPI backend..."}],
temperature=0.7
)
</code>Optimization for Agentic Workflows
Enable tool-calling mode
GLM-4.7 supports function calling for agent workflows:
<code class="language-python">tools = [
{
"type": "function",
"function": {
"name": "execute_code",
"description": "Run Python code and return results",
"parameters": {
"type": "object",
"properties": {
"code": {"type": "string"}
}
}
}
}
]
response = client.chat.completions.create(
model="glm-4-7",
messages=[{"role": "user", "content": "Debug this function..."}],
tools=tools,
tool_choice="auto"
)
</code>Leverage extended context for codebase analysis
<code class="language-python"># Load entire codebase into context
codebase = load_repository_files() # Returns ~150K tokens
response = client.chat.completions.create(
model="glm-4-7",
messages=[
{"role": "system", "content": "You are a senior software architect."},
{"role": "user", "content": f"Codebase:n{codebase}nnRefactor to improve modularity."}
],
max_tokens=100000 # Generate comprehensive refactoring plan
)
</code>Common mistake: Teams often use default context limits (4K-8K tokens) even when the model supports 200K. Explicitly set higher token limits to leverage GLM-4.7’s full capacity.
For organizations managing multiple AI models simultaneously, platforms like MULTIBLY provide unified interfaces to compare GLM-4.7 responses against alternatives like Claude, GPT-5, and Gemini without managing separate API integrations.
What Are the Limitations and Trade-offs of GLM-4.7?
Despite leading open-source benchmarks, GLM-4.7 has measurable limitations that impact deployment decisions for specific use cases. Understanding these trade-offs helps teams choose the right model for each workflow rather than defaulting to a single solution.
Multimodal Capabilities
Limitation: GLM-4.7 is text-only. It cannot process images, audio, or video inputs.
Impact: Teams building applications that require visual understanding (UI/UX design analysis, medical imaging, document layout comprehension) must either:
- Use a separate multimodal model for vision tasks
- Implement OCR preprocessing to convert images to text
- Choose an alternative like Gemini 3 Pro for multimodal workflows
Decision rule: Choose GLM-4.7 for pure text and code tasks. Switch to multimodal alternatives when visual context is essential to task completion.
Multilingual Performance
Limitation: While GLM-4.7 supports multiple languages, its training data skews heavily toward English and Chinese. Performance on languages like Spanish, French, German, and others lags behind specialized multilingual models.
Impact: Teams requiring high-quality output in languages beyond English/Chinese should benchmark GLM-4.7 against alternatives like:
- Qwen3 (stronger multilingual coverage)
- Mistral’s multilingual variants
- Specialized models like mGPT or BLOOM for low-resource languages
Edge case: Code generation and technical documentation often work well across languages because programming syntax is universal. Natural language generation quality varies more significantly.
Inference Hardware Requirements
Limitation: The full 355B GLM-4.7 model requires substantial GPU memory (640GB minimum for FP16 weights). This creates deployment barriers for:
- Edge devices and mobile platforms
- Organizations with limited GPU budgets
- Scenarios requiring sub-100ms latency
Mitigation: GLM-4.7 Flash (30B dense) addresses this limitation for cost-sensitive deployments, though with 10-15% performance degradation on complex reasoning tasks[2].
Alternative approach: For teams needing smaller models that run on consumer hardware, Phi-4 or Mistral 7B provide better options than attempting to quantize GLM-4.7 to extreme compression levels.
Training Data Cutoff
Limitation: GLM-4.7’s training data has a knowledge cutoff (specific date not publicly disclosed but estimated at mid-2024 based on model release timeline).
Impact: The model cannot answer questions about:
- Events occurring after its training cutoff
- Recently released software frameworks or APIs
- Current market conditions or real-time data
Solution: Implement retrieval-augmented generation (RAG) to supplement the model with current information, or use tool-calling to invoke search APIs for time-sensitive queries.
Benchmark-to-Production Gap
Limitation: Benchmark performance doesn’t always translate directly to production reliability. GLM-4.7’s 90.6% tool-calling success rate means approximately 1 in 10 agent tasks still fail.
Impact: Production deployments require:
- Error handling and retry logic for failed tool invocations
- Human-in-the-loop oversight for high-stakes decisions
- Monitoring systems to detect and escalate edge cases
In practice: Teams report that GLM-4.7’s failure modes are typically graceful (the model recognizes when it cannot complete a task) rather than catastrophic (generating confidently incorrect outputs). This makes error handling more straightforward than with models that hallucinate without acknowledgment.
Comparing GLM-4.7 to Proprietary Alternatives: When Does Open-Source Win?
The GLM-4.7 Surge: Z.ai’s Open MoE Models Outpacing Qwen3 and Mistral in Agentic Benchmarks raises a fundamental question for enterprise teams: when does open-source performance justify the operational complexity of self-hosting versus paying for proprietary API access?
Cost Break-Even Analysis
Self-hosted GLM-4.7 economics:
- Upfront hardware cost: $120,000-180,000 (8x A100 80GB GPUs)
- Monthly operational cost: $3,000-5,000 (power, cooling, maintenance)
- Inference cost: ~$0.12 per million tokens (amortized over 3-year hardware lifecycle)
Proprietary API comparison (GPT-5, Claude Opus 4.5):
- No upfront hardware cost
- Pay-per-use pricing: $5-8 per million input tokens, $15-30 per million output tokens
- Monthly cost at 100M tokens: $15,000-30,000
Break-even point: Teams processing 50M+ tokens monthly achieve ROI on self-hosted GLM-4.7 within 6-12 months. Below this threshold, API access typically costs less when accounting for infrastructure overhead.
Performance Parity Scenarios
GLM-4.7 matches or exceeds proprietary models on:
- Code generation and refactoring: Outperforms GPT-5.1/5.2 on AIME 2025 and LiveCodeBench[1]
- Tool-use reliability: 87.4% τ²-Bench score competitive with Claude Opus 4.5
- Multi-step reasoning: 42.8% HLE performance matches GPT-5.1 levels[4][5]
Proprietary models maintain advantages in:
- Multimodal understanding: GPT-5 and Claude process images, audio, video
- Real-time knowledge: API models often include web search integration
- Latency: Managed infrastructure typically delivers faster first-token response
Data Privacy and Compliance
Choose self-hosted GLM-4.7 when:
- Processing regulated data (HIPAA, GDPR, financial records) where API transmission creates compliance risk
- Fine-tuning on proprietary codebases or trade secrets
- Operating in air-gapped environments without internet connectivity
- Contractual obligations prohibit third-party data processing
Choose proprietary APIs when:
- Data sensitivity permits cloud processing under standard terms of service
- Compliance frameworks accept vendor SOC 2 / ISO 27001 certifications
- Rapid iteration matters more than data control
Customization and Fine-Tuning
GLM-4.7’s MIT license permits fine-tuning on proprietary datasets without restrictions[1][4]. This enables:
- Domain-specific optimization for industry jargon and workflows
- Alignment with company-specific coding standards
- Integration of proprietary knowledge bases directly into model weights
Proprietary models typically restrict fine-tuning to:
- Approved enterprise customers with volume commitments
- Specific use cases vetted by vendor compliance teams
- Pricing tiers that add 50-200% to base API costs
Decision rule: If your competitive advantage depends on model customization for specialized domains, self-hosted open-source models provide strategic flexibility that proprietary APIs cannot match.
For teams evaluating the broader landscape of open versus closed models, GLM-4.7 represents the current performance ceiling for open-weight alternatives in agentic workflows.
FAQ

What is GLM-4.7 and why does it matter for AI development in 2026?
GLM-4.7 is a 355-billion parameter Mixture-of-Experts language model from Z.ai that currently leads all open-source models on agentic benchmarks, achieving 73.8% on SWE-bench Verified and 87.4% on τ²-Bench tool-use evaluations. It matters because it delivers frontier-level reasoning and code generation at self-hosted costs that make it practical for production deployment, with a permissive MIT license that enables fine-tuning on proprietary data[1][3][5].
How much does it cost to run GLM-4.7 compared to proprietary models?
Self-hosted GLM-4.7 costs approximately $0.10-0.15 per million tokens when amortized over hardware lifecycle, compared to $5-30 per million tokens for proprietary API access. Teams processing 50M+ tokens monthly achieve ROI on self-hosted infrastructure within 6-12 months. GLM-4.7 Flash (30B dense variant) reduces hardware requirements to 2x A100 40GB GPUs for cost-sensitive deployments[2].
What hardware do I need to run GLM-4.7?
The full 355B model requires 8x NVIDIA A100 80GB GPUs (or 4x H100 80GB) with 512GB system RAM and 2TB storage. GLM-4.7 Flash runs on 2x A100 40GB GPUs with 256GB RAM. Quantized versions (4-bit, 8-bit) reduce requirements further with minimal accuracy loss. Most teams with existing infrastructure for Llama 3.1 70B or Mixtral 8x22B can run GLM-4.7 Flash without hardware upgrades[3][5].
How does GLM-4.7 compare to Qwen3 and Mistral on real-world tasks?
GLM-4.7 outperforms Qwen3 and Mistral by 10-20 percentage points on SWE-bench Verified (73.8% vs ~55-62%), LiveCodeBench V6 (84.8% vs ~68-76%), and τ²-Bench tool-use (87.4% vs ~70-78%). This translates to measurably higher success rates in autonomous code generation, multi-step debugging, and agent workflows requiring reliable tool invocation[1][3][4][5].
Can GLM-4.7 process images or only text?
GLM-4.7 is text-only and cannot process images, audio, or video. Teams requiring multimodal capabilities must use separate models for vision tasks or implement preprocessing (OCR) to convert visual inputs to text. For workflows where visual understanding is essential, alternatives like Gemini 3 Pro or GPT-5 provide better options.
What is the context window size and why does it matter?
GLM-4.7 supports a 200,000-token context window with up to 131,000 maximum output tokens. This enables processing entire codebases (100+ files), analyzing comprehensive research documents, and maintaining reasoning context across complex multi-turn conversations without chunking or retrieval-augmented generation workarounds[1][3][4].
Is GLM-4.7 better than GPT-5 for coding tasks?
GLM-4.7 outperforms GPT-5.1 and GPT-5.2 on AIME 2025, τ²-Bench, and Humanity’s Last Exam benchmarks, and achieves higher scores on LiveCodeBench V6 than most proprietary models. For pure coding and reasoning tasks where multimodal capabilities aren’t required, GLM-4.7 delivers comparable or superior performance at significantly lower cost when self-hosted[1][4][5].
What license does GLM-4.7 use and what does that allow?
GLM-4.7 operates under an MIT license, permitting commercial use, modification, distribution, and fine-tuning without royalties or usage restrictions. Teams can self-host, customize for proprietary workflows, and deploy in air-gapped environments without vendor dependencies or compliance concerns about third-party data processing[1][4].
How reliable is GLM-4.7 for autonomous agent workflows?
GLM-4.7 achieves a 90.6% average tool-calling success rate and 87.4% on τ²-Bench interactive tool invocation benchmarks, making it the most reliable open-source model for production agent deployments. This means approximately 1 in 10 tasks may still require human intervention, necessitating error handling and monitoring systems for production use[3][4][5].
What are the main limitations of GLM-4.7?
Key limitations include text-only capabilities (no multimodal support), weaker multilingual performance outside English and Chinese, substantial hardware requirements for the full model (8x A100 80GB GPUs), and a training data cutoff that requires RAG or tool-calling for current information. GLM-4.7 Flash addresses hardware constraints but with 10-15% performance reduction[2].
How do I integrate GLM-4.7 into existing development workflows?
GLM-4.7 supports OpenAI-compatible API interfaces for drop-in replacement in existing codebases. Self-hosted deployments use vLLM or TGI inference servers. API access through Z.ai requires only changing the base URL and API key in standard OpenAI SDK implementations. Most integrations require minimal code changes beyond endpoint configuration.
When should I choose GLM-4.7 over proprietary models like Claude or GPT-5?
Choose GLM-4.7 when processing 50M+ tokens monthly (cost break-even), handling regulated data requiring self-hosted deployment, fine-tuning on proprietary codebases, or optimizing for code generation and agentic workflows. Choose proprietary models when multimodal capabilities are essential, processing volume is low, or rapid iteration without infrastructure management is prioritized over cost optimization.
Conclusion
The GLM-4.7 Surge: Z.ai’s Open MoE Models Outpacing Qwen3 and Mistral in Agentic Benchmarks represents a fundamental shift in the economics and capabilities of open-source AI. For the first time, teams can deploy a self-hosted model that matches or exceeds proprietary alternatives on the exact tasks that matter most for production agent workflows: code generation, multi-step reasoning, and reliable tool invocation.
GLM-4.7’s 73.8% SWE-bench Verified score, 87.4% τ²-Bench performance, and 90.6% tool-calling success rate establish it as the current performance ceiling for open-weight models in 2026. The 355-billion parameter MoE architecture delivers this capability while activating only 32 billion parameters per inference, creating cost efficiency that makes frontier-level reasoning practical at scale.
Actionable Next Steps
For teams currently using proprietary APIs:
- Calculate your monthly token volume across all LLM workflows
- If processing 50M+ tokens monthly, model the ROI on self-hosted GLM-4.7 infrastructure
- Run parallel evaluations on your specific use cases using platforms like MULTIBLY to compare GLM-4.7 against current models
- Identify workflows where data privacy or fine-tuning requirements create strategic value beyond cost savings
For teams already using open-source models:
- Benchmark GLM-4.7 against your current deployment (Qwen3, Mistral, Llama) on representative tasks
- Prioritize migration for agentic workflows where tool-calling reliability directly impacts success rates
- Consider GLM-4.7 Flash for cost-sensitive deployments where hardware constraints prevent full model deployment
- Implement monitoring systems to track the 10% failure rate and establish human-in-the-loop escalation paths
For teams building new AI products:
- Start with API access through Z.ai to validate product-market fit without infrastructure investment
- Plan self-hosted migration path once token volume exceeds 50M monthly
- Design workflows to leverage the 200K context window for differentiated capabilities competitors cannot match
- Build error handling and retry logic from day one to account for the ~10% tool-calling failure rate
The open-source AI landscape has reached a tipping point where performance parity with proprietary models creates genuine strategic choices rather than forcing compromise. GLM-4.7’s dominance on agentic benchmarks demonstrates that the question is no longer whether open models can compete, but rather which specific workflows justify the operational complexity of self-hosting versus the convenience of managed APIs.
For organizations navigating this decision, the key insight is that GLM-4.7 excels specifically in scenarios where autonomous task completion, code generation, and multi-step reasoning drive business value. Teams building agent systems, automating software development workflows, or processing proprietary data at scale will find GLM-4.7’s combination of performance, cost efficiency, and licensing flexibility creates competitive advantages that proprietary alternatives cannot match.
The broader trend toward open-source AI adoption continues to accelerate in 2026, and GLM-4.7’s benchmark leadership provides concrete evidence that this shift is driven by measurable performance gains rather than ideological preferences. As the ecosystem matures, expect continued innovation in MoE architectures, extended context windows, and specialized fine-tuning that widens the capability gap between open and closed models for specific use cases.
References
[1] Glm 4 7 Outperforms Gpt 5 2 – https://www.aiplanetx.com/p/glm-4-7-outperforms-gpt-5-2
[2] Glm 4.7 Flash Launch – https://llm-stats.com/blog/research/glm-4.7-flash-launch
[3] Glm 4 7 – https://automatio.ai/models/glm-4-7
[4] Watch – https://www.youtube.com/watch?v=j1HJ2ocdJLI
[5] Glm 4 7 Zai Coding Model Guide – https://www.digitalapplied.com/blog/glm-4-7-zai-coding-model-guide
[6] Glm 4 – https://z.ai/blog/glm-4.7
Our Fact Checking Process
We prioritize accuracy and integrity in our content. Here's how we maintain high standards:
- Expert Review: All articles are reviewed by subject matter experts.
- Source Validation: Information is backed by credible, up-to-date sources.
- Transparency: We clearly cite references and disclose potential conflicts.
Our Review Board
Our content is carefully reviewed by experienced professionals to ensure accuracy and relevance.
- Qualified Experts: Each article is assessed by specialists with field-specific knowledge.
- Up-to-date Insights: We incorporate the latest research, trends, and standards.
- Commitment to Quality: Reviewers ensure clarity, correctness, and completeness.
Look for the expert-reviewed label to read content you can trust.



