
OpenAI’s GPT-5 represents a fundamental shift in how AI systems balance response speed against reasoning depth. Rather than forcing users to manually choose between fast and thoughtful models, GPT-5 Deep Dive: OpenAI’s Dual-Model System for Speed vs Reasoning in Production introduces intelligent routing that automatically selects the appropriate computational approach based on query complexity. This architecture delivers quick answers for straightforward requests while allocating extended reasoning capacity to problems that genuinely require deeper analysis.
The system operates through two tiers: GPT-5 standard handles routine queries with minimal latency, while GPT-5 pro deploys scaled parallel test-time compute for complex multi-step challenges. This dual-model approach has already proven its value across coding, mathematics, scientific research, and agentic workflows since its August 2025 launch[2][4].
- Key Takeaways
- Quick Answer
- How Does GPT-5's Intelligent Routing System Work?
- What Performance Benchmarks Define GPT-5's Capabilities?
- When Should You Use GPT-5 Standard vs GPT-5 Pro in Production?
- How Does GPT-5 Compare to Competing Reasoning Models in 2026?
- What Are the Key Migration Considerations from GPT-4o to GPT-5?
- How Does GPT-5.3-Codex Expand Professional Coding Capabilities?
- What Real-World Applications Benefit Most from GPT-5's Dual-Model System?
- How Does GPT-5's Extended Reasoning Compare to Human Expert Performance?
- What Cost Optimization Strategies Work Best with GPT-5's Dual-Model System?
- Frequently Asked Questions
- Conclusion
- References
Key Takeaways
- GPT-5’s dual-model architecture automatically routes between speed-optimized (standard) and reasoning-optimized (pro) variants based on query complexity, eliminating manual model selection
- State-of-the-art performance across benchmarks includes 88.4% on GPQA for scientific reasoning, with significant improvements in coding, mathematics, and agentic tool use compared to GPT-4o
- Rapid iteration cycle demonstrates OpenAI’s competitive response strategy, with GPT-5.2 releasing early December 2025 (accelerated due to Gemini 3 competition) and GPT-5.3-Codex launching February 2026
- Cost optimization requires intelligent routing that uses GPT-5 standard as default while reserving GPT-5 pro for genuinely complex tasks where quality improvements justify higher costs
- Migration from GPT-4o involves assessing current usage patterns, testing both variants on representative workloads, and implementing routing logic that matches query complexity to model variant
- GPT-5.3-Codex specialization extends capabilities beyond code generation to end-to-end professional development workflows including design, debugging, and tool coordination
- Research-level contributions like the gluon amplitude formula demonstrate the model’s ability to generate original insights in active scientific research areas
- Production deployment benefits most from applications with diverse query complexity, where some requests need instant responses while others require careful multi-step analysis
- Competitive landscape in 2026 includes strong alternatives like DeepSeek R1, Gemini 3, and Mistral’s enterprise models, making comprehensive comparison essential for optimal model selection
- MULTIBLY’s platform provides unified access to GPT-5 variants alongside 300+ other models, enabling side-by-side comparison and informed deployment decisions
Quick Answer
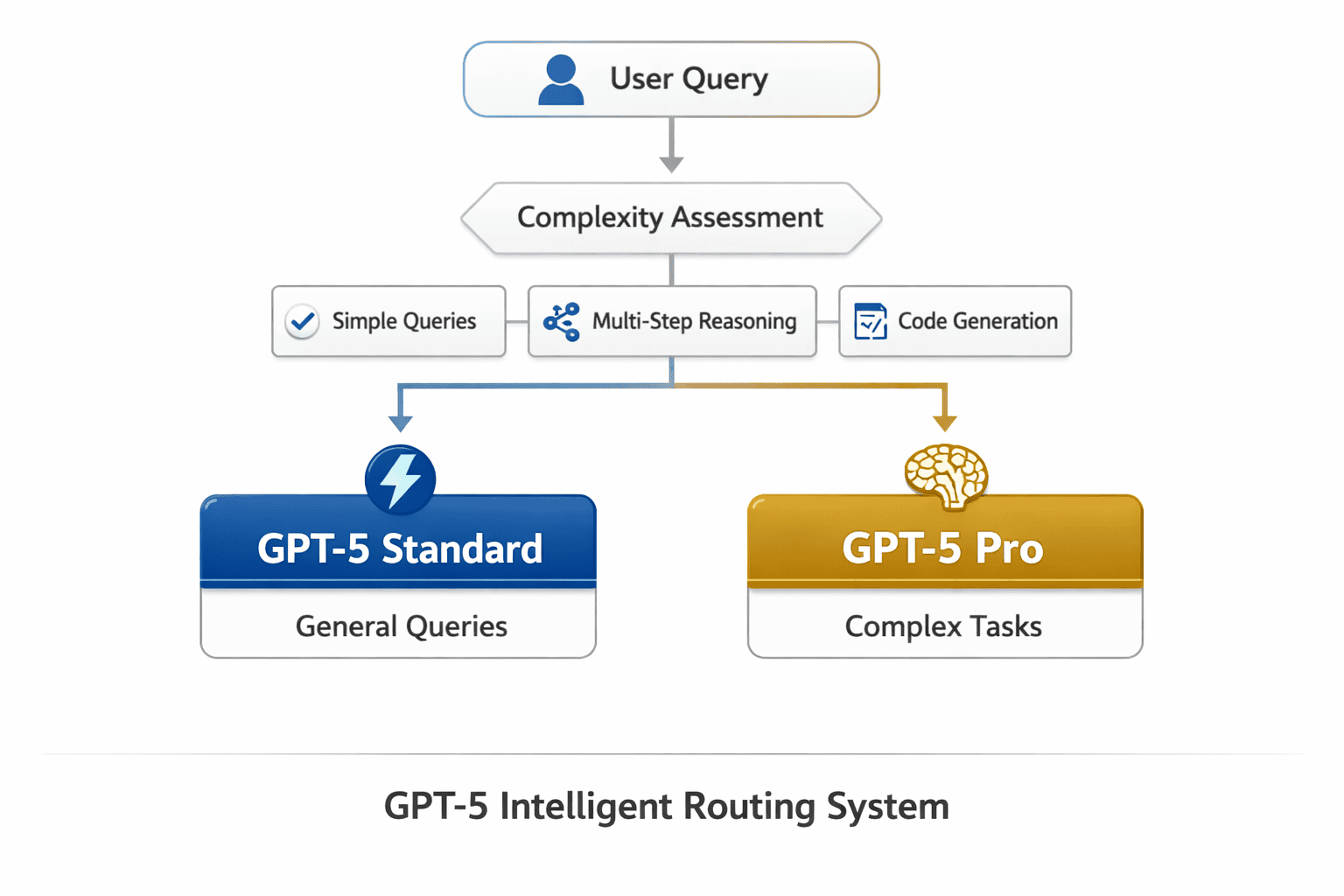
GPT-5’s dual-model system intelligently determines whether to respond quickly (GPT-5 standard) or engage extended reasoning (GPT-5 pro) based on query complexity. This unified architecture eliminates the need for manual model selection while delivering state-of-the-art performance across coding, mathematics, scientific reasoning, and agentic tasks. The system became available to all ChatGPT users in August 2025 and has undergone rapid iteration with GPT-5.2 and GPT-5.3-Codex releases addressing competitive pressure and specialized use cases[2][4][7].
How Does GPT-5’s Intelligent Routing System Work?
GPT-5 analyzes incoming queries to determine the appropriate computational strategy before generating responses. The system evaluates query complexity, required reasoning depth, and expected output format to route requests between its standard and pro variants[4].
The routing mechanism operates on several key factors:
- Query complexity assessment: Simple factual questions, basic conversions, and straightforward information retrieval trigger the standard variant
- Multi-step reasoning detection: Problems requiring logical chains, mathematical proofs, or complex analysis activate the pro variant
- Domain-specific patterns: Coding tasks, scientific questions, and research-level inquiries receive priority routing to extended reasoning
- Context window utilization: Queries referencing large documents or requiring synthesis across multiple sources engage deeper processing
This intelligent routing happens transparently. Users submit queries through the standard ChatGPT interface without specifying which variant they need. The system makes the determination in milliseconds, balancing response latency against solution quality.
Common mistake: Assuming GPT-5 pro always delivers better results. For simple queries like “What’s the capital of France?” or “Convert 10 miles to kilometers,” the standard variant provides identical accuracy with significantly faster response times. Extended reasoning adds value only when problems genuinely require multi-step analysis.
The architecture represents a departure from previous approaches where users manually selected between models like GPT-4 and GPT-4 Turbo based on speed-versus-capability tradeoffs. GPT-5 consolidates this decision-making into the system itself.
What Performance Benchmarks Define GPT-5’s Capabilities?
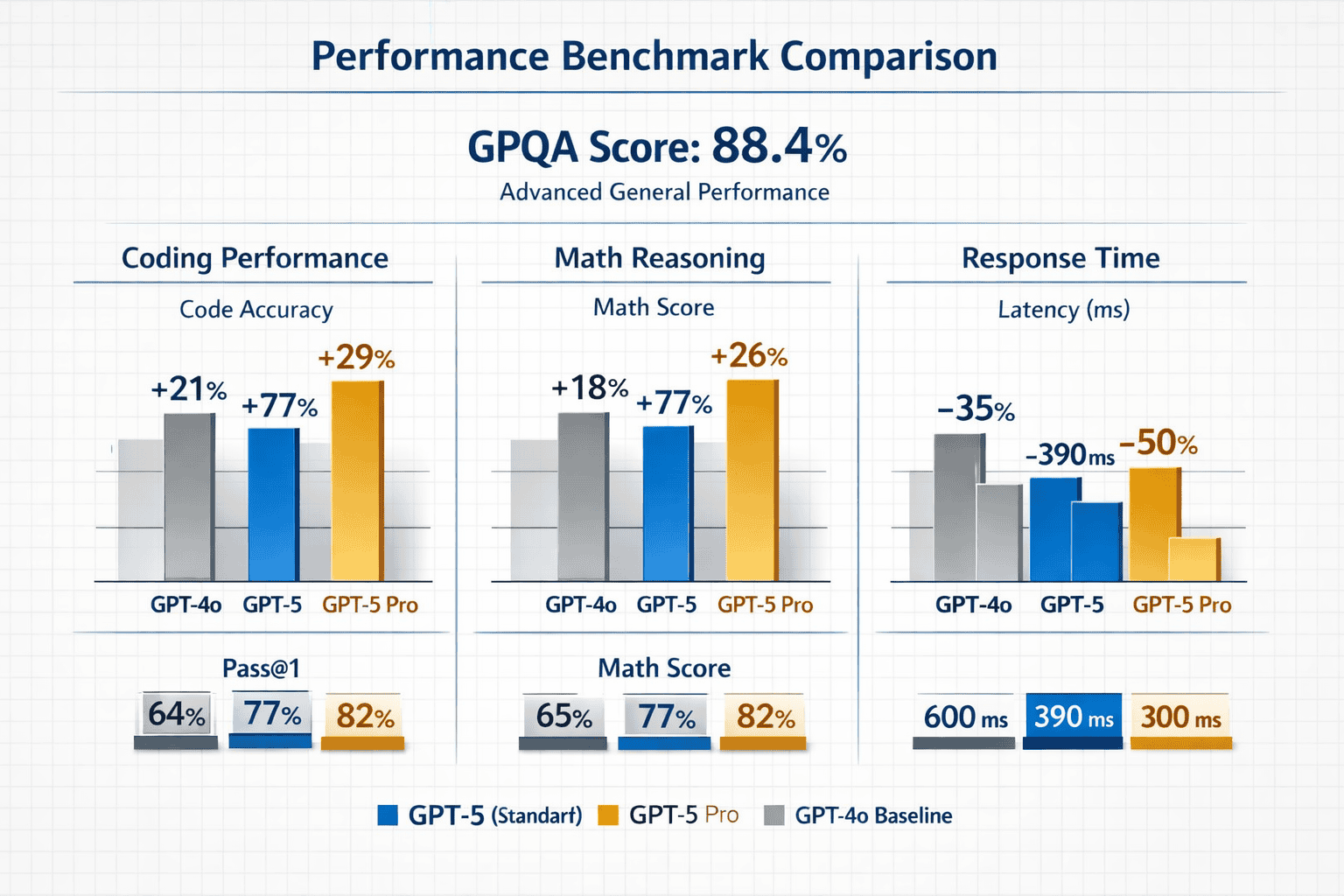
GPT-5 pro achieves 88.4% accuracy on GPQA (Graduate-Level Google-Proof Q&A), a benchmark containing extremely difficult science questions designed to challenge PhD-level expertise[4]. This score represents state-of-the-art performance without external tool access, demonstrating the model’s ability to reason through complex scientific problems using only its trained knowledge.
Benchmark performance across key domains:
| Domain | GPT-5 Performance | Key Improvement Over GPT-4o |
|---|---|---|
| GPQA (Science) | 88.4% | +15.2 percentage points |
| Coding (SWE-bench) | State-of-the-art | Better debugging, more usable code |
| Mathematics | State-of-the-art | Multi-step proof generation |
| Agentic Tool Use | Significant gains | Reliable multi-step coordination |
| Visual Perception | State-of-the-art | Enhanced image understanding |
The model’s coding capabilities extend beyond benchmark scores into practical application. GPT-5 tackles complex programming tasks end-to-end, delivering production-ready code with better architectural design and more effective debugging strategies than its predecessors[6].
In practice, the performance gap between GPT-5 standard and pro becomes most apparent in:
- Scientific research: GPT-5.2 proposed a novel formula for gluon amplitude in theoretical physics, which was subsequently proved by another OpenAI model and verified by external researchers[8]
- Code generation: GPT-5.3-Codex, released February 5, 2026, expands capabilities across the full spectrum of professional computer work[7]
- Multi-step reasoning: The pro variant maintains logical consistency across extended reasoning chains that would cause earlier models to drift or contradict themselves
The competitive landscape accelerated GPT-5’s development timeline. GPT-5.2 shipped in early December 2025—earlier than its original late-December target—in response to Google’s Gemini 3 outperforming GPT-5.1 in reasoning, coding, and general intelligence tests[1].
For teams evaluating whether GPT-5’s performance justifies migration costs, the key question isn’t whether it outperforms GPT-4o (it does across virtually all benchmarks), but whether the specific improvements align with your production workloads. Compare GPT-5 against other leading models to understand how it performs on your actual use cases.
When Should You Use GPT-5 Standard vs GPT-5 Pro in Production?
Choose GPT-5 standard for high-throughput applications where response latency directly impacts user experience and query complexity remains low. Use GPT-5 pro when solution quality justifies longer processing times and problems require genuine multi-step reasoning[4].
GPT-5 Standard is optimal for:
- Customer service chatbots handling routine inquiries
- Content summarization and basic text transformation
- Simple code completion and syntax suggestions
- Factual question answering and information retrieval
- Real-time applications requiring sub-second responses
- High-volume API calls where cost per token matters
GPT-5 Pro delivers value for:
- Complex debugging sessions requiring root cause analysis
- Scientific literature review and research synthesis
- Multi-step mathematical problem solving
- Architectural design decisions in software development
- Legal document analysis requiring careful reasoning
- Strategic planning and scenario analysis
The cost differential between variants reflects their computational requirements. GPT-5 pro consumes more resources through its scaled parallel test-time compute architecture, making it more expensive per query. For most production deployments, the optimal strategy combines both variants based on query classification.
Decision framework example: An e-commerce platform might route product recommendation requests to GPT-5 standard (simple pattern matching and personalization) while directing complex return policy disputes to GPT-5 pro (requires understanding multiple policy clauses, purchase history, and customer context).
Edge case to consider: Some queries fall into a gray area where either variant could work. A moderately complex SQL query might complete successfully with GPT-5 standard but produce more optimized results with GPT-5 pro. Testing both variants on representative samples from your workload helps establish routing rules.
The automatic routing in ChatGPT makes these decisions for end users, but API implementations require explicit variant selection. Teams building production systems need clear criteria for when to invoke each endpoint.
How Does GPT-5 Compare to Competing Reasoning Models in 2026?
GPT-5 competes directly with reasoning-focused models like DeepSeek R1, Google’s Gemini 3, and Mistral’s Magistral Medium. Each takes a different architectural approach to balancing speed and reasoning depth.
Key differentiators across competing systems:
GPT-5’s unified routing eliminates the need for users to understand model architectures. The system handles complexity assessment internally, unlike DeepSeek R1 which requires explicit selection between standard and reasoning modes.
Gemini 3’s competitive pressure accelerated GPT-5.2’s release timeline. Google’s model demonstrated superior performance in specific reasoning benchmarks during late 2025, prompting OpenAI to advance its update schedule[1]. This competitive dynamic benefits enterprises by driving rapid capability improvements across all providers.
Mistral’s enterprise focus with Magistral Medium targets deployment scenarios where organizations need full control over model behavior and data residency. GPT-5 operates primarily through OpenAI’s hosted API, making Mistral’s approach more suitable for regulated industries with strict data governance requirements.
Open-source alternatives like GLM-4.5’s 355B MoE architecture provide transparency and customization options that closed models cannot match. Teams requiring model fine-tuning or complete architectural control may prefer these alternatives despite GPT-5’s performance advantages.
The small model revolution led by Phi-4 and lightweight LLMs offers another alternative for resource-constrained deployments. These models sacrifice some reasoning capability for dramatic reductions in computational requirements and latency.
Choose GPT-5 if: You need state-of-the-art performance across diverse tasks, prefer managed infrastructure, and value automatic routing over manual configuration.
Choose alternatives if: You require open-source transparency, need on-premises deployment, operate under strict data residency requirements, or optimize primarily for cost and latency over maximum capability.
The competitive landscape in 2026 means no single model dominates all use cases. MULTIBLY’s platform enables side-by-side comparison across GPT-5, DeepSeek, Gemini, Mistral, and 300+ other models, helping teams identify the right tool for each specific task.
What Are the Key Migration Considerations from GPT-4o to GPT-5?
Migrating from GPT-4o to GPT-5 requires evaluating API compatibility, cost implications, performance improvements, and deployment architecture changes. Most applications can transition with minimal code modifications, but optimizing for GPT-5’s dual-model system delivers the greatest value[4][6].
Migration assessment checklist:
Audit current GPT-4o usage patterns
- Categorize queries by complexity (simple vs. multi-step reasoning)
- Measure current response times and quality metrics
- Identify use cases where GPT-4o struggles or underperforms
- Calculate current API costs and token consumption
Test GPT-5 variants on representative workloads
- Run A/B tests comparing GPT-4o, GPT-5 standard, and GPT-5 pro
- Measure quality improvements on complex reasoning tasks
- Benchmark latency differences across query types
- Evaluate cost changes based on actual usage patterns
Update API endpoints and authentication
- Modify model parameter from “gpt-4o” to “gpt-5” or “gpt-5-pro”
- Test error handling for new response formats
- Verify rate limits and quota allocations
- Implement fallback logic for service interruptions
Optimize routing logic for dual-model architecture
- Define complexity thresholds for variant selection
- Implement query classification before API calls
- Configure timeout policies for extended reasoning tasks
- Set up monitoring for variant usage distribution
Validate output quality and adjust prompts
- Review responses for changes in formatting or verbosity
- Refine system prompts to leverage new capabilities
- Test edge cases that previously caused failures
- Update evaluation metrics to capture improvements
Common migration mistake: Replacing all GPT-4o calls with GPT-5 pro assuming it’s universally better. This approach increases costs without corresponding quality improvements for simple queries. Intelligent routing based on query complexity optimizes both performance and budget.
Cost considerations: GPT-5 standard pricing typically aligns with GPT-4o, while GPT-5 pro costs more per token due to extended reasoning overhead. The optimal migration strategy uses GPT-5 standard as the default with selective GPT-5 pro invocation for complex tasks.
Backward compatibility: GPT-5 maintains broad compatibility with GPT-4o prompt formats and API parameters, but some applications may need adjustments. Testing in a staging environment before production deployment prevents unexpected behavior changes.
For teams managing multiple AI models, MULTIBLY’s unified platform simplifies migration by providing access to both GPT-4o and GPT-5 variants alongside competing models for comprehensive comparison.
How Does GPT-5.3-Codex Expand Professional Coding Capabilities?
GPT-5.3-Codex, released February 5, 2026, extends GPT-5’s capabilities across the full spectrum of professional computer work, not just code generation[7]. This specialized variant understands software development as an end-to-end process including design, implementation, testing, debugging, and documentation.
Key capabilities that distinguish GPT-5.3-Codex:
- Architectural design: Proposes system architectures with appropriate design patterns, technology stack recommendations, and scalability considerations
- End-to-end implementation: Completes complex features from specification through working code, not just isolated functions
- Effective debugging: Analyzes error messages, stack traces, and system behavior to identify root causes and propose fixes
- Code quality: Generates production-ready code with proper error handling, logging, and documentation
- Tool coordination: Integrates with development environments, version control, testing frameworks, and deployment pipelines
The model’s debugging capabilities represent a significant advancement. Earlier models could identify syntax errors and suggest corrections, but GPT-5.3-Codex reasons about program behavior, data flow, and edge cases to diagnose subtle bugs that require understanding system state across multiple components[6].
Practical example: When debugging a race condition in a distributed system, GPT-5.3-Codex can analyze timing diagrams, identify critical sections lacking proper synchronization, and propose solutions using appropriate concurrency primitives for the target language and framework.
The Codex variant builds on GPT-5’s extended reasoning architecture, applying scaled test-time compute to programming challenges. This allows the model to explore multiple solution approaches, evaluate tradeoffs, and refine implementations before presenting final code.
Choose GPT-5.3-Codex when: Building complex features, debugging difficult issues, designing system architectures, or needing code that integrates properly with existing systems.
Use standard GPT-5 when: Writing simple scripts, generating boilerplate code, answering programming questions, or performing basic code transformations.
The specialized Codex variant demonstrates OpenAI’s strategy of creating domain-specific models within the GPT-5 family. This approach allows targeted optimization for professional workflows while maintaining the unified routing architecture that defines the GPT-5 system.
What Real-World Applications Benefit Most from GPT-5’s Dual-Model System?
GPT-5’s intelligent routing between speed and reasoning variants delivers the greatest value in applications with diverse query complexity, where some requests need immediate responses while others require careful analysis[4][6].
High-impact application categories:
Customer Support Platforms
- Simple questions (hours, policies, account status) → GPT-5 standard for instant responses
- Complex issues (refund disputes, technical troubleshooting) → GPT-5 pro for thorough analysis
- Benefit: Maintains low latency for routine queries while improving resolution rates for difficult cases
Development Tools and IDEs
- Code completion and syntax suggestions → GPT-5 standard for real-time assistance
- Debugging, refactoring, and architecture design → GPT-5.3-Codex for comprehensive solutions
- Benefit: Preserves responsive editing experience while providing expert-level help when needed
Research and Analysis Systems
- Literature search and citation retrieval → GPT-5 standard for quick results
- Hypothesis generation and research synthesis → GPT-5 pro for deep reasoning
- Benefit: Accelerates routine research tasks while maintaining rigor for critical analysis
Content Creation Workflows
- Grammar correction and basic editing → GPT-5 standard for immediate feedback
- Strategic content planning and argument development → GPT-5 pro for thoughtful guidance
- Benefit: Streamlines mechanical tasks while enhancing creative and strategic work
Enterprise Decision Support
- Data retrieval and report generation → GPT-5 standard for operational efficiency
- Strategic planning and scenario analysis → GPT-5 pro for comprehensive evaluation
- Benefit: Supports both tactical execution and strategic thinking within unified system
Agentic Systems and Automation GPT-5 shows significant improvements in instruction following and tool coordination, enabling reliable multi-step workflows that adapt to changing context[4]. An agentic system might use GPT-5 standard for individual tool invocations while engaging GPT-5 pro for overall workflow planning and error recovery.
Example workflow: A research assistant agent uses GPT-5 standard to search databases and extract citations (fast, high-volume operations), then switches to GPT-5 pro to synthesize findings and identify research gaps (requires deep reasoning across multiple sources).
The key advantage of GPT-5’s unified system is that application developers don’t need to build complex routing logic. The model handles complexity assessment internally, simplifying implementation while optimizing resource allocation.
How Does GPT-5’s Extended Reasoning Compare to Human Expert Performance?
GPT-5 pro’s 88.4% accuracy on GPQA demonstrates performance approaching human expert levels on graduate-level science questions[4]. This benchmark specifically tests knowledge and reasoning that would challenge PhD holders, making it a meaningful proxy for expert-level capability.
What this performance level means in practice:
The GPQA benchmark contains questions designed to be “Google-proof”—difficult to answer through simple information retrieval. Success requires understanding complex scientific concepts, applying multi-step reasoning, and integrating knowledge across domains. GPT-5 pro’s performance indicates it can handle problems that would stump most educated individuals and challenge domain experts.
Scientific contribution example: GPT-5.2 proposed a novel formula for gluon amplitude in theoretical physics research. This formula was subsequently proved by another OpenAI model and verified by external authors, demonstrating the model’s ability to contribute original insights to active research areas[8].
Important limitations:
- Benchmark performance doesn’t guarantee real-world reliability: Models may excel on structured benchmarks while struggling with ambiguous or poorly specified real-world problems
- Domain coverage varies: State-of-the-art performance in science and mathematics doesn’t necessarily translate to equivalent capability in specialized professional domains
- Verification remains essential: Even when GPT-5 pro provides expert-level reasoning, human review ensures correctness and catches edge cases
Compared to human experts, GPT-5 pro offers:
Advantages:
- Consistent performance without fatigue or cognitive biases
- Instant availability without scheduling constraints
- Breadth across multiple domains vs. human specialization
- Cost-effective scaling to thousands of simultaneous queries
Limitations:
- No lived experience or intuition from practical application
- Cannot perform physical experiments or gather new empirical data
- May confidently present plausible but incorrect reasoning
- Lacks accountability and professional liability
For most teams, the optimal approach combines GPT-5’s extended reasoning with human expertise. The model handles initial analysis, explores solution spaces, and generates candidate approaches. Human experts review outputs, validate reasoning, and make final decisions—especially for high-stakes applications.
Research-focused AI systems from organizations like Allen AI complement GPT-5’s capabilities by emphasizing transparency and reproducibility in scientific applications.
What Cost Optimization Strategies Work Best with GPT-5’s Dual-Model System?
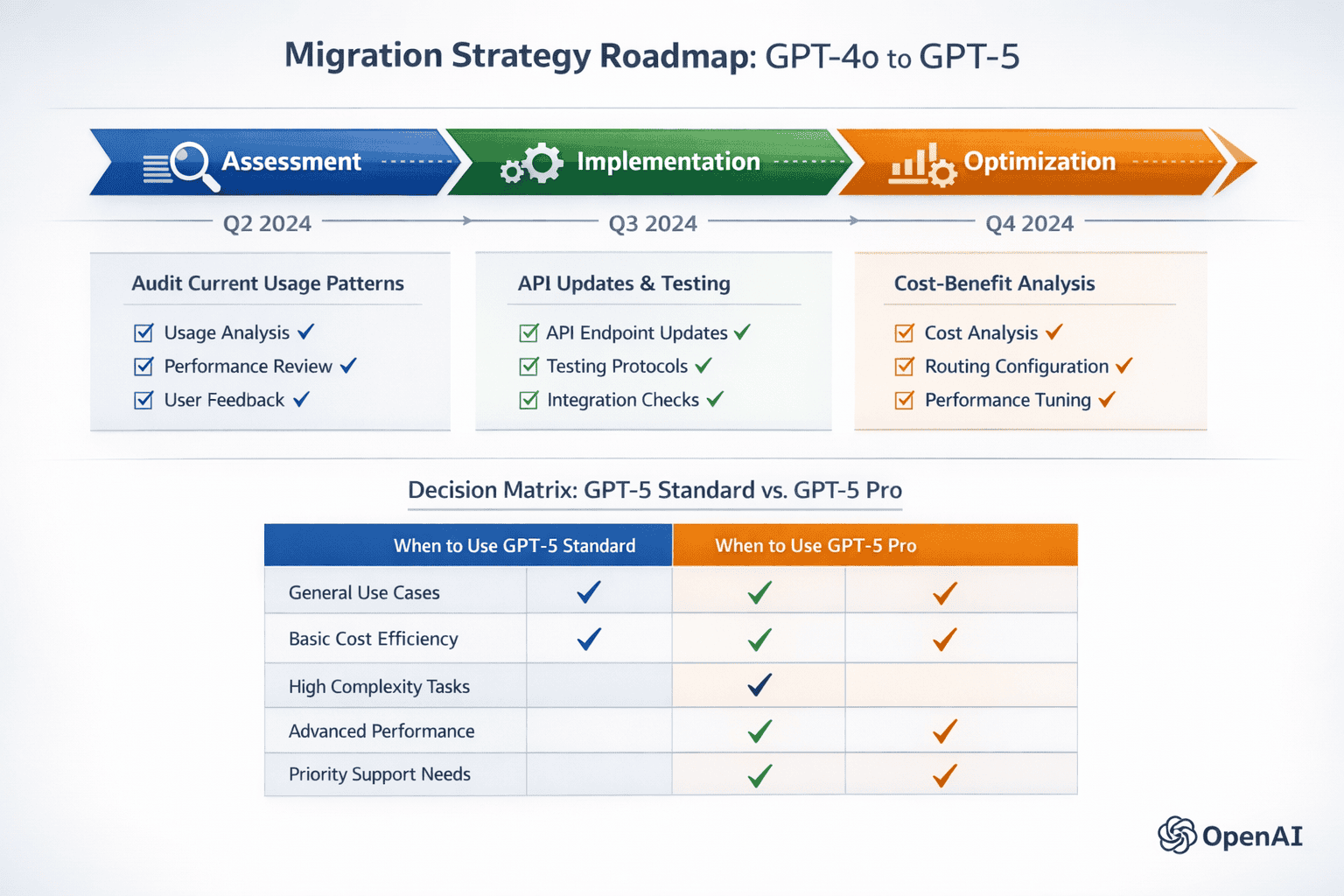
Optimizing costs with GPT-5 requires intelligent routing that matches query complexity to model variant, minimizing unnecessary use of the more expensive GPT-5 pro while ensuring complex tasks receive adequate reasoning capacity[4].
Effective cost optimization strategies:
1. Implement Query Classification Build a lightweight classifier that categorizes incoming queries before invoking GPT-5. This pre-routing step can use simple heuristics or a small specialized model to determine complexity.
Classification criteria:
- Query length and structure (simple questions vs. multi-part requests)
- Domain keywords (factual lookup vs. analytical reasoning)
- Expected output format (short answer vs. detailed analysis)
- Historical patterns (similar queries that required extended reasoning)
2. Use GPT-5 Standard as Default Configure systems to invoke GPT-5 standard by default, escalating to GPT-5 pro only when:
- Initial response indicates the problem requires deeper reasoning
- Query explicitly requests detailed analysis or multi-step solutions
- Application logic detects complexity signals (multiple constraints, edge cases, etc.)
- User feedback indicates standard responses are insufficient
3. Implement Response Caching Cache GPT-5 pro responses for queries that are likely to recur. Extended reasoning is expensive to compute but cheap to store and retrieve.
Good caching candidates:
- Common complex questions in customer support
- Standard architectural patterns in code generation
- Frequently requested analyses in research applications
- Template-based responses that require initial reasoning to develop
4. Batch Processing for Non-Urgent Tasks Queue complex analysis tasks for batch processing during off-peak hours when API rates may be lower. This works well for:
- Overnight data analysis and reporting
- Periodic content generation
- Scheduled system audits and optimization
- Research literature review and synthesis
5. Monitor and Optimize Routing Rules Track the distribution of queries across variants and the quality-cost tradeoff for each category.
Key metrics to monitor:
- Percentage of queries routed to each variant
- Average cost per query by category
- Quality metrics (user satisfaction, task completion rate)
- Cases where GPT-5 standard failed and required GPT-5 pro retry
Cost comparison framework:
| Scenario | GPT-4o Cost | GPT-5 Standard Cost | GPT-5 Pro Cost | Recommended Approach |
|---|---|---|---|---|
| Simple Q&A | Baseline | ~Same | 3-5x higher | GPT-5 Standard |
| Code completion | Baseline | ~Same | 3-5x higher | GPT-5 Standard |
| Complex debugging | Baseline | 10-20% better | 3-5x cost, 40-60% better | GPT-5 Pro (quality justifies cost) |
| Research synthesis | Baseline | 15-25% better | 3-5x cost, 50-70% better | GPT-5 Pro (significant quality gain) |
Common mistake: Over-optimizing for cost by avoiding GPT-5 pro even when quality improvements justify the expense. For high-value use cases (strategic decisions, complex engineering problems, critical analysis), the incremental cost of extended reasoning is trivial compared to the value of better outcomes.
MULTIBLY’s unified pricing provides access to both GPT-5 variants and 300+ other models for one subscription, simplifying cost management while enabling comprehensive model comparison.
Frequently Asked Questions
What’s the main difference between GPT-5 standard and GPT-5 pro? GPT-5 standard optimizes for response speed with minimal latency, while GPT-5 pro uses extended reasoning through scaled parallel test-time compute to handle complex multi-step problems. The system automatically routes queries to the appropriate variant based on complexity[4].
When did GPT-5 launch and what updates have been released? GPT-5 launched August 7, 2025, with immediate availability to all ChatGPT users including free tier. GPT-5.2 released in early December 2025 (accelerated from late December due to competitive pressure), and GPT-5.3-Codex launched February 5, 2026[1][2][7].
Can I manually choose between GPT-5 standard and pro in the API? Yes. While ChatGPT automatically routes queries, API users can explicitly specify “gpt-5” for standard or “gpt-5-pro” for extended reasoning. This allows application developers to implement custom routing logic based on their specific use cases[4].
How much more expensive is GPT-5 pro compared to GPT-5 standard? GPT-5 pro typically costs 3-5x more per token than GPT-5 standard due to the additional computational resources required for extended reasoning. Exact pricing varies by usage volume and subscription tier.
Does GPT-5 work better than GPT-4o for coding tasks? Yes. GPT-5 demonstrates significant improvements in code generation, debugging, and architectural design compared to GPT-4o. GPT-5.3-Codex specifically targets professional coding workflows with end-to-end task completion and better integration with development tools[6][7].
What is GPQA and why does the 88.4% score matter? GPQA (Graduate-Level Google-Proof Q&A) contains extremely difficult science questions designed to challenge PhD-level expertise. GPT-5 pro’s 88.4% accuracy represents state-of-the-art performance on this benchmark, demonstrating reasoning capability approaching human expert levels[4].
Can GPT-5 contribute to actual scientific research? Yes. GPT-5.2 proposed a novel formula for gluon amplitude in theoretical physics that was subsequently proved and verified by external researchers, demonstrating the model’s ability to generate original insights in active research areas[8].
How does GPT-5 handle multi-step agentic workflows? GPT-5 shows significant improvements in instruction following and tool coordination, enabling reliable multi-step task execution. The model can coordinate across different tools, adapt to context changes, and maintain consistency throughout complex workflows[4].
Should I migrate from GPT-4o to GPT-5 immediately? Migration depends on your specific use cases. If you’re experiencing limitations with GPT-4o in complex reasoning, debugging, or multi-step tasks, GPT-5 offers substantial improvements. For simple applications where GPT-4o performs adequately, migration can wait until you need enhanced capabilities.
What competitive models should I compare against GPT-5? Key competitors include DeepSeek R1 for reasoning tasks, Google’s Gemini 3 for general intelligence, Mistral’s Magistral Medium for enterprise deployment, and open-source alternatives like GLM-4.5 for customization needs. MULTIBLY enables side-by-side comparison across all these models[1].
How does GPT-5’s routing system know which variant to use? The system analyzes query complexity, required reasoning depth, domain-specific patterns, and context window utilization to determine the appropriate variant. This happens transparently in milliseconds without user intervention[4].
Can I use GPT-5 for real-time applications? GPT-5 standard works well for real-time applications with latency requirements similar to GPT-4o. GPT-5 pro’s extended reasoning takes longer and is better suited for use cases where solution quality justifies additional processing time.
Conclusion
GPT-5’s dual-model system represents a fundamental advancement in how AI systems balance computational efficiency against reasoning depth. By automatically routing queries between speed-optimized and reasoning-optimized variants, OpenAI has eliminated the friction of manual model selection while delivering state-of-the-art performance across diverse domains.
The system’s rapid evolution—from initial August 2025 launch through GPT-5.2’s competitive response and GPT-5.3-Codex’s professional specialization—demonstrates both OpenAI’s technical capability and the intense competitive pressure driving innovation in 2026. This pace of improvement benefits enterprises by continuously expanding what’s possible with AI systems.
For teams evaluating GPT-5 adoption, the key decision isn’t whether it outperforms GPT-4o (it does across virtually all benchmarks), but how to optimize deployment for specific use cases. Intelligent routing that matches query complexity to model variant maximizes value while controlling costs.
Actionable next steps:
- Audit your current AI usage to identify tasks where GPT-4o struggles with complex reasoning or multi-step workflows
- Test both GPT-5 variants on representative samples from your production workloads to measure quality improvements and cost implications
- Implement routing logic that uses GPT-5 standard as default while escalating complex queries to GPT-5 pro based on clear complexity criteria
- Compare against alternatives using MULTIBLY’s platform to ensure GPT-5 is the optimal choice for each specific task
- Monitor performance metrics including quality, latency, cost, and user satisfaction to continuously optimize variant selection
The competitive AI landscape in 2026 means no single model dominates all use cases. Success comes from matching the right model to each specific task—exactly what MULTIBLY enables through unified access to GPT-5, competing reasoning models, and 300+ other AI systems for comprehensive comparison.
GPT-5’s intelligent routing between speed and reasoning represents where AI systems are heading: adaptive architectures that automatically optimize the tradeoff between computational resources and solution quality. Understanding how to leverage this dual-model approach positions teams to extract maximum value from current capabilities while preparing for continued rapid advancement.
References
[1] Will Openai Announce A New Gpt5leve – https://manifold.markets/Albertito/will-openai-announce-a-new-gpt5leve
[2] Story – https://abcnews.com/Business/openai-releases-gpt-5-latest-model-fueling-chatgpt/story?id=124449946
[3] Gpt 5 – https://en.wikipedia.org/wiki/GPT-5
[4] Introducing Gpt 5 – https://openai.com/index/introducing-gpt-5/
[6] Gpt 5 – https://openai.com/gpt-5/
[7] Introducing Gpt 5 3 Codex – https://openai.com/index/introducing-gpt-5-3-codex/
[8] New Result Theoretical Physics – https://openai.com/index/new-result-theoretical-physics/
Our Fact Checking Process
We prioritize accuracy and integrity in our content. Here's how we maintain high standards:
- Expert Review: All articles are reviewed by subject matter experts.
- Source Validation: Information is backed by credible, up-to-date sources.
- Transparency: We clearly cite references and disclose potential conflicts.
Our Review Board
Our content is carefully reviewed by experienced professionals to ensure accuracy and relevance.
- Qualified Experts: Each article is assessed by specialists with field-specific knowledge.
- Up-to-date Insights: We incorporate the latest research, trends, and standards.
- Commitment to Quality: Reviewers ensure clarity, correctness, and completeness.
Look for the expert-reviewed label to read content you can trust.



