
OpenAI’s release of gpt-oss-120b and gpt-oss-20b in August 2025 marked a turning point in AI accessibility. For the first time since GPT-2, OpenAI released fully open-source language models—but these aren’t simple text generators. They’re sophisticated reasoning models trained with proprietary techniques previously reserved for o3 and o4, now available under a permissive Apache 2.0 license. The gpt-oss-120b achieves near-parity with o4-mini on core reasoning benchmarks while running on a single 80GB GPU, and the 20B variant operates on edge devices with just 16GB of memory.[2][3]
This shift matters because advanced reasoning capabilities are no longer locked behind API costs or usage restrictions. Developers can now build cost-effective reasoning agents that run locally, process sensitive data without external API calls, and scale without per-token pricing concerns.
- Key Takeaways
- Quick Answer
- What Makes gpt-oss from OpenAI Different from Previous Open Models?
- How Does gpt-oss Performance Compare to Proprietary o3 and o4 Models?
- What Hardware Do You Need to Run gpt-oss Models?
- How Does the Three-Level Reasoning Effort System Work?
- What Are the Licensing Terms and Commercial Use Restrictions?
- How Do You Deploy gpt-oss Models for Production Reasoning Agents?
- How Does gpt-oss Compare to Other Open Reasoning Models in 2026?
- What Are the Key Limitations and Trade-offs of gpt-oss Models?
- Conclusion
- FAQ
- References
Key Takeaways
- gpt-oss-120b matches o4-mini performance on reasoning benchmarks including competition coding, mathematics, and health queries while running on consumer-grade hardware[2]
- Mixture-of-experts architecture activates only 5.1 billion of 117 billion parameters per token, enabling efficient inference on single 80GB GPUs[2]
- Apache 2.0 license removes all restrictions on commercial use, user count, and deployment context—no hidden limitations[1][2]
- Three-level reasoning effort system lets developers trade latency for accuracy, with high-effort mode dedicating 80% of tokens to reasoning processes[1][2]
- gpt-oss-20b outperforms o3-mini on competition mathematics despite being 6 times smaller, proving efficiency gains from advanced training techniques[2][3]
- Local deployment tools like Ollama and LM Studio enable immediate use without cloud infrastructure or API dependencies[1]
- Tool-calling and agent capabilities are built-in, supporting multi-step workflows and chained API calls for real-world applications[2][4]
- Knowledge cutoff of June 2024 means current events require external tool integration or retrieval-augmented generation[1]
Quick Answer
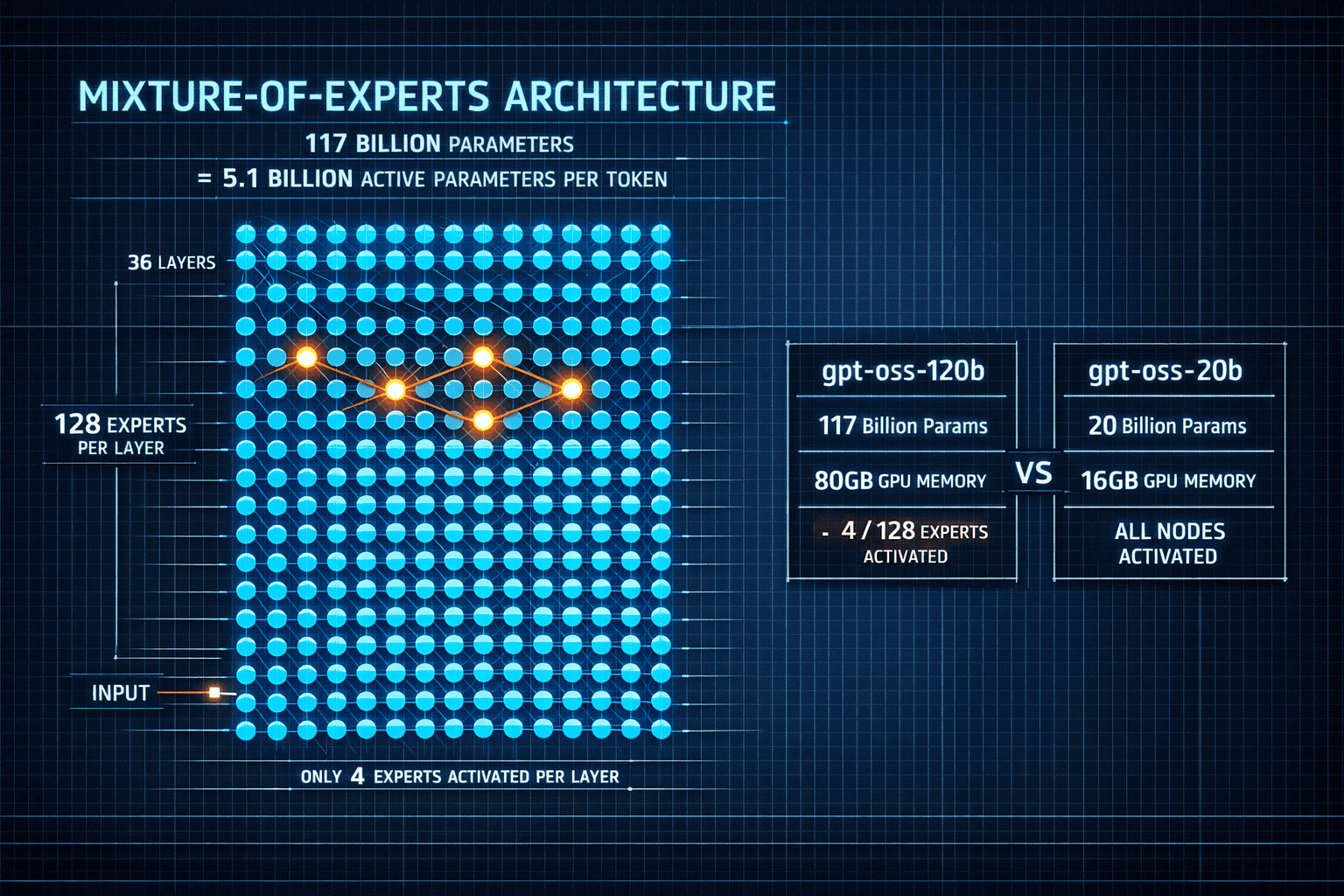
OpenAI’s gpt-oss models bring o3-level reasoning capabilities to open-source through mixture-of-experts architecture that activates only 4-5 billion parameters per token. The 120B model matches proprietary o4-mini performance on coding, mathematics, and problem-solving benchmarks while running on a single 80GB GPU. The 20B variant operates on 16GB edge devices yet outperforms o3-mini on several tasks. Both support adjustable reasoning effort levels and are released under Apache 2.0, enabling unrestricted commercial deployment for cost-effective reasoning agents.
What Makes gpt-oss from OpenAI Different from Previous Open Models?
gpt-oss represents OpenAI’s first major open-source release since GPT-2 in 2019, but the gap between then and now is massive. These models incorporate training techniques from o3 and o4—OpenAI’s most advanced proprietary systems—including reinforcement learning methods that weren’t available in earlier open releases.[2][5]
Key architectural differences:
- Mixture-of-experts (MoE) design: The 120B model contains 117 billion total parameters organized into 36 layers with 128 experts per layer, but only 4 experts activate for any given token[2]
- Active parameter efficiency: Only 5.1 billion parameters (120B model) or 3.6 billion parameters (20B model) process each token, dramatically reducing computational requirements[2]
- Reasoning-optimized training: Unlike standard language models trained purely on next-token prediction, gpt-oss models use reinforcement learning to develop multi-step reasoning capabilities[2][5]
- Tool-use integration: Native support for function calling and API chaining enables agentic workflows without additional fine-tuning[2][4]
The practical impact is substantial. While models like DeepSeek R1 and V3.1 demonstrated that open models could compete on benchmarks, gpt-oss brings OpenAI’s specific training methodology into the open-source ecosystem. This includes the three-level reasoning effort system that lets developers choose between speed and accuracy based on task requirements.
Common mistake to avoid: Don’t assume gpt-oss-120b requires 120GB of memory. The MoE architecture means only active parameters need to be loaded, so the model runs comfortably on a single 80GB GPU—the same hardware many teams already use for inference.[2]
How Does gpt-oss Performance Compare to Proprietary o3 and o4 Models?
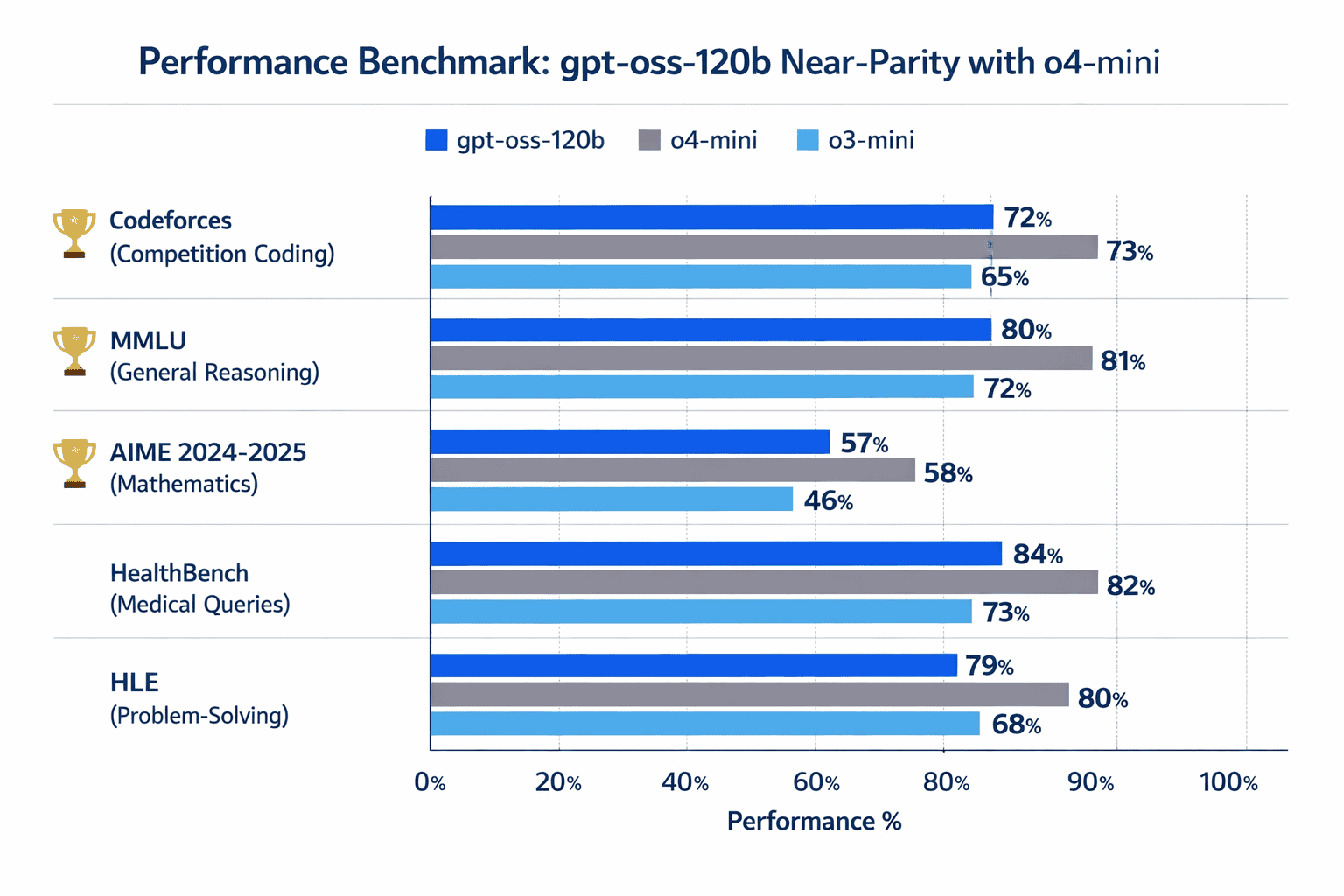
gpt-oss-120b achieves near-parity with o4-mini across core reasoning benchmarks, while the smaller 20B model matches or exceeds o3-mini despite being significantly smaller.[2][3]
Benchmark performance breakdown:
| Task Category | gpt-oss-120b | o4-mini | o3-mini | gpt-oss-20b |
|---|---|---|---|---|
| Competition Coding (Codeforces) | Outperforms | Baseline | Lower | Matches o3-mini |
| General Reasoning (MMLU) | Matches | Baseline | Lower | Matches o3-mini |
| Competition Math (AIME 2024-2025) | Outperforms | Lower | Baseline | Outperforms |
| Health Queries (HealthBench) | Outperforms | Baseline | Lower | Matches o3-mini |
| Problem Solving (HLE) | Matches | Baseline | Lower | Slightly lower |
The most surprising result: gpt-oss-20b outperforms o3-mini on competition mathematics despite being 6 times smaller.[2] This demonstrates the efficiency gains from OpenAI’s advanced training techniques, which are now accessible to the broader developer community.
In practice, this means:
- For coding tasks: gpt-oss-120b handles Codeforces-level competitive programming problems at o4-mini quality
- For mathematical reasoning: Both gpt-oss models excel at AIME-level problems, often surpassing larger proprietary models
- For health and medical queries: The 120B model shows particular strength on HealthBench, suggesting strong domain-specific reasoning
- For general knowledge: Performance matches o4-mini on MMLU, though the June 2024 knowledge cutoff means current events require external tools
Edge case: The models perform best on tasks requiring multi-step reasoning rather than pure knowledge retrieval. For knowledge-intensive queries about events after June 2024, integrate retrieval-augmented generation or browsing tools—both models support tool-calling for this purpose.[2]
When comparing total cost of ownership, gpt-oss models eliminate per-token API costs entirely. Teams running high-volume inference workloads can achieve significant savings versus proprietary models while maintaining comparable reasoning quality.
What Hardware Do You Need to Run gpt-oss Models?
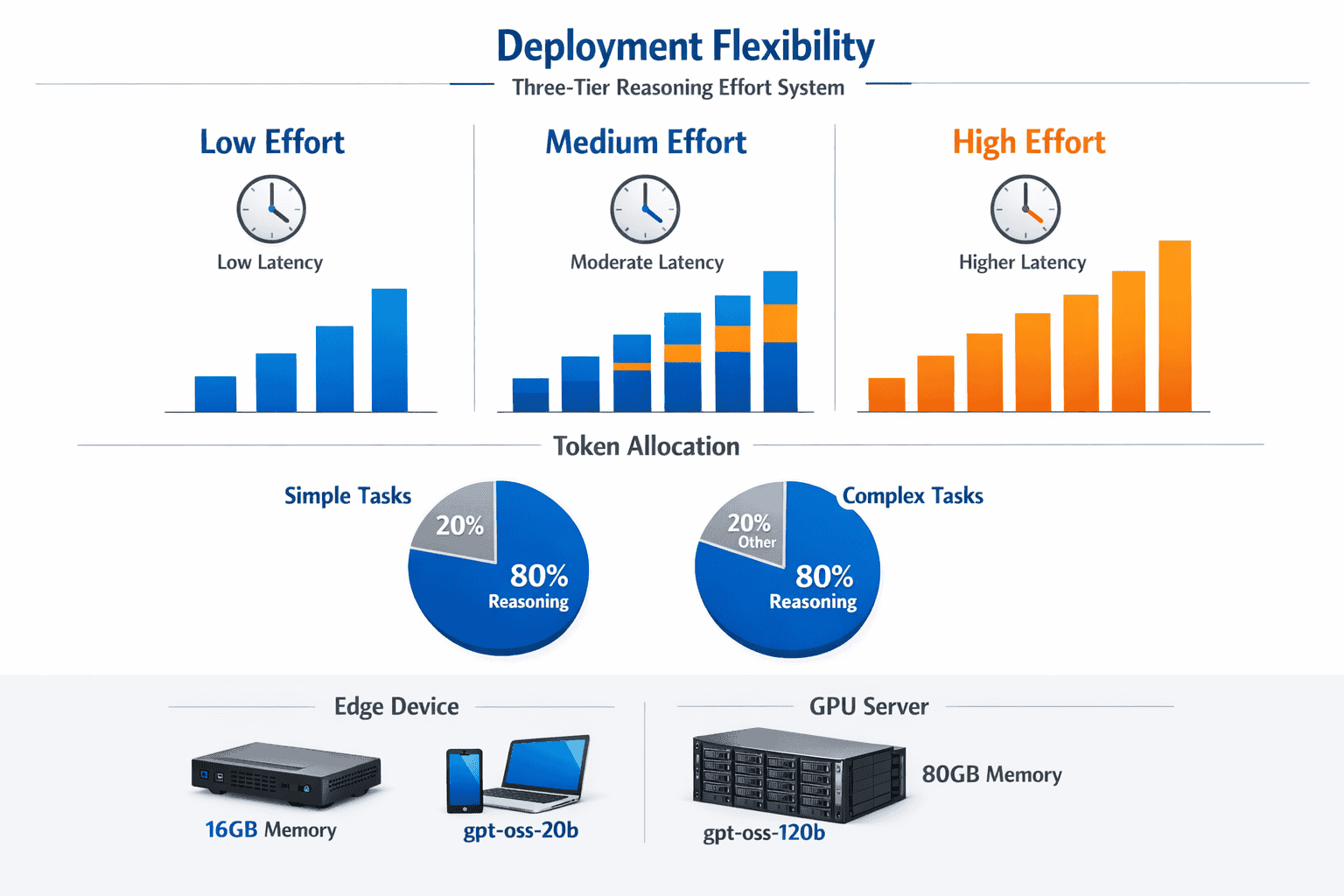
The hardware requirements for gpt-oss models are surprisingly accessible compared to other 100B+ parameter systems, thanks to the mixture-of-experts architecture that activates only a fraction of total parameters.
gpt-oss-120b requirements:
- Minimum: Single 80GB GPU (A100, H100, or equivalent)
- Recommended: 80GB+ GPU with high memory bandwidth for faster inference
- RAM: 32GB+ system memory for loading and preprocessing
- Storage: 250GB+ for model weights and cache
gpt-oss-20b requirements:
- Minimum: 16GB GPU memory (RTX 4090, A10, or equivalent)
- Edge deployment: Can run on devices with 16GB unified memory
- RAM: 16GB+ system memory
- Storage: 50GB+ for model weights
Both models are optimized for consumer hardware and can run locally using tools like Ollama and LM Studio, which handle quantization and memory optimization automatically.[1][5]
Deployment options:
- Local inference: Download weights and run on your own hardware with full data privacy
- Cloud deployment: Spin up GPU instances on AWS, GCP, or Azure for on-demand scaling
- Edge devices: Deploy gpt-oss-20b on powerful laptops or edge servers for low-latency applications
- Hybrid approach: Run smaller model locally for most queries, route complex reasoning to cloud-hosted 120B model
Choose gpt-oss-120b if you need maximum reasoning quality and have access to 80GB GPUs. Choose gpt-oss-20b if you’re deploying on edge devices, need faster inference, or want to minimize infrastructure costs while maintaining strong reasoning capabilities.
The NVIDIA RTX AI Garage provides optimized configurations for running gpt-oss models on consumer RTX hardware, including quantization settings that reduce memory requirements further without significant quality loss.[5]
Common mistake: Don’t over-provision hardware. The MoE architecture means you don’t need 120GB of VRAM for the 120B model—80GB is sufficient because only active experts load into memory during inference.
How Does the Three-Level Reasoning Effort System Work?
gpt-oss models include an adjustable reasoning effort parameter that controls how much computational budget the model dedicates to thinking through problems before generating answers. This system trades latency for accuracy based on task requirements.[1][2]
Three effort levels explained:
Low effort (fast mode):
- Uses minimal tokens for internal reasoning
- Fastest inference speed (2-3x faster than high effort)
- Best for simple queries, code completion, or real-time applications
- Comparable to standard language model behavior
Medium effort (balanced mode):
- Allocates moderate token budget to reasoning
- Balanced speed-accuracy trade-off
- Suitable for most production use cases
- Default setting for general applications
High effort (maximum reasoning):
- Dedicates roughly 80% of available tokens to reasoning processes
- Slowest inference but highest accuracy
- Best for competition-level coding, complex mathematics, or critical decisions
- Approaches o4-mini quality on challenging benchmarks
In practice, the reasoning effort system works by controlling how many “thinking tokens” the model generates internally before producing its final answer. Higher effort levels mean the model explores more solution paths, checks its work more thoroughly, and considers edge cases more carefully.
Decision framework:
- Use low effort for: Autocomplete, simple Q&A, high-throughput batch processing, chatbot responses
- Use medium effort for: Code generation, document analysis, general problem-solving, standard business logic
- Use high effort for: Competitive programming, mathematical proofs, medical diagnosis support, security-critical decisions
The system is particularly valuable for agentic workflows where different reasoning steps require different effort levels. For example, an agent might use low effort for simple API calls and high effort for complex decision points.
Edge case: High-effort mode can occasionally produce verbose reasoning traces. If you need concise outputs, use medium effort and implement post-processing to extract final answers, or fine-tune the model on your specific output format preferences.
What Are the Licensing Terms and Commercial Use Restrictions?
gpt-oss models are released under the Apache 2.0 license, one of the most permissive open-source licenses available. This removes virtually all restrictions that have limited previous open model releases.[1][2]
What Apache 2.0 means in practice:
- No user count limits: Deploy to unlimited users without license fees
- No revenue restrictions: Use in commercial products regardless of company size or revenue
- No deployment context limits: Run on-premise, in cloud, or on edge devices
- Modification allowed: Fine-tune, distill, or adapt models for specific use cases
- Redistribution permitted: Share modified versions (with attribution)
- Patent protection: Includes explicit patent grant from OpenAI
No hidden restrictions:
Unlike some “open” models that include usage caps or require commercial licensing above certain thresholds, gpt-oss has zero restrictions based on:
- Number of users or requests
- Commercial vs non-commercial use
- Company size or revenue
- Geographic location
- Industry or application type
This contrasts sharply with earlier releases like LLaMA 2, which restricted commercial use for companies with over 700 million monthly active users, or models with research-only licenses.
What you still need to do:
- Provide attribution to OpenAI in derivative works
- Include the Apache 2.0 license text with distributions
- Note any modifications you make to the original model
Choose gpt-oss if you need guaranteed freedom to deploy without future licensing concerns. The Apache 2.0 license means your deployment strategy won’t be disrupted by licensing changes or usage tier restrictions.
For teams evaluating multiple open models, compare gpt-oss licensing against alternatives like GLM-4.5’s MoE architecture or Mistral’s enterprise options to understand the full landscape of open reasoning models in 2026.
How Do You Deploy gpt-oss Models for Production Reasoning Agents?
Deploying gpt-oss models for production agentic workflows requires understanding tool integration, context management, and reasoning effort optimization. Both models are designed specifically for agent use cases with built-in tool-calling capabilities.[2][4]
Step-by-step deployment process:
1. Choose your deployment environment
- Local inference: Download weights via Hugging Face or OpenAI’s model hub
- Cloud deployment: Use containerized inference on Kubernetes or serverless GPU platforms
- Hybrid: Run 20B model locally for fast queries, route complex tasks to cloud-hosted 120B
2. Set up inference infrastructure
- Install Ollama, LM Studio, or vLLM for optimized serving
- Configure GPU memory allocation and batch size
- Enable tool-calling endpoints for agent integration
- Set up monitoring for latency and token usage
3. Integrate tool-calling capabilities
- Define function schemas for external APIs (search, databases, calculators)
- Implement tool execution layer that handles model function calls
- Configure safety checks for tool use in production
- Test multi-step tool chaining for complex workflows
4. Optimize reasoning effort by task type
- Map task categories to effort levels (low/medium/high)
- Implement dynamic effort selection based on query complexity
- Monitor accuracy vs latency trade-offs in production
- Fine-tune effort thresholds based on user feedback
5. Handle the June 2024 knowledge cutoff
- Integrate browsing tools for current information
- Implement retrieval-augmented generation for domain-specific knowledge
- Cache frequently requested current information
- Update tool-use patterns as knowledge gaps emerge
Production considerations:
The gpt-oss-120b model can quickly aggregate up-to-date information using browsing tools, including chaining together 10+ subsequent API calls for complex research tasks.[2] This makes it particularly effective for agents that need to gather and synthesize current information despite the knowledge cutoff.
Example agent architecture:
<code>User Query → Intent Classification → Reasoning Effort Selection
↓
gpt-oss Model (appropriate effort level)
↓
Tool Calls (search, APIs, databases) ← Iterative refinement
↓
Response Synthesis → Quality Check → User Response
</code>Common mistakes to avoid:
- Over-using high effort: Not every query needs maximum reasoning. Profile your workload and use low/medium effort where appropriate to reduce latency.
- Ignoring context window limits: Both models support long contexts, but extremely long conversations still require context management strategies.
- Skipping tool-use testing: The models are trained for tool use, but your specific API schemas need thorough testing before production.
- Neglecting fallback strategies: Have backup plans for when reasoning fails or tools return unexpected results.
For teams building sophisticated multi-model systems, platforms like MULTIBLY enable side-by-side comparison of gpt-oss outputs against other reasoning models to validate quality and choose the right model for each task.
Edge case: For latency-critical applications, consider running gpt-oss-20b with low effort for initial responses, then asynchronously running the 120B model with high effort for quality verification or complex follow-ups.
How Does gpt-oss Compare to Other Open Reasoning Models in 2026?
The open reasoning model landscape in 2026 includes strong competitors from multiple organizations, each with different strengths and trade-offs compared to gpt-oss.[3]
Key competitors and differentiators:
DeepSeek R1 and V3.1:
- Larger total parameter counts but similar active parameters
- Strong performance on Chinese language tasks
- Different training methodology focused on reinforcement learning from scratch
- Competitive on global benchmarks but different licensing terms
GLM-4.5 and GLM-4.7:
- 355B total parameters with MoE architecture
- Strong performance on agentic benchmarks
- Particularly effective for multi-step workflows
- Larger memory footprint than gpt-oss-120b
Qwen3 series:
- Excellent multilingual capabilities
- Strong on non-English reasoning tasks
- Different architectural choices optimized for diverse languages
- Competitive licensing terms
Mistral’s open models:
- Smaller, more efficient architectures
- Focus on enterprise deployment scenarios
- Different reasoning approach compared to o3-style training
- Strong European language support
Comparative strengths of gpt-oss:
- Training pedigree: Direct lineage from o3 and o4 training techniques not available in other open models[2][5]
- Hardware efficiency: MoE architecture optimized specifically for consumer GPU deployment[2]
- Licensing clarity: Apache 2.0 with zero restrictions provides maximum deployment flexibility[1][2]
- Tool-use optimization: Built-in agent capabilities without additional fine-tuning[2][4]
- Reasoning effort control: Three-level system provides more granular control than most alternatives[1][2]
Choose gpt-oss over alternatives if:
- You need proven reasoning techniques from OpenAI’s proprietary models
- Apache 2.0 licensing is critical for your deployment
- You want optimized performance on 80GB GPUs
- English-language reasoning is your primary use case
- You need adjustable reasoning effort for cost-latency trade-offs
Choose alternatives if:
- You need stronger multilingual support (consider Qwen3 or GLM series)
- You’re optimizing for even smaller hardware (consider Mistral or Phi-4)
- You need larger total parameter counts for specific domains
- You have specific regional compliance requirements
The broader trend shows open-source models challenging proprietary dominance across reasoning benchmarks, with gpt-oss representing OpenAI’s contribution to this ecosystem shift.
What Are the Key Limitations and Trade-offs of gpt-oss Models?
Understanding gpt-oss limitations helps teams make informed deployment decisions and plan appropriate mitigations.
Primary limitations:
1. Knowledge cutoff (June 2024)
- No information about events after mid-2024
- Requires tool integration for current information
- Can produce outdated answers if not supplemented with retrieval
- Mitigation: Implement browsing tools or RAG for current topics[2]
2. Inference costs for high-effort reasoning
- High-effort mode uses 80% of tokens for reasoning, increasing latency
- Longer reasoning traces mean higher computational costs per query
- Not ideal for real-time applications requiring sub-second responses
- Mitigation: Use low/medium effort for most queries, reserve high effort for critical tasks[1][2]
3. Hardware requirements still significant
- 80GB GPU for 120B model is accessible but not trivial
- 16GB for 20B model excludes lower-end hardware
- Quantization reduces quality to some degree
- Mitigation: Use cloud deployment for burst capacity, edge deployment for 20B model[1][5]
4. Training data biases
- Inherits biases from training data (not fully disclosed)
- May reflect patterns from internet-scale text corpora
- Requires testing on your specific use cases
- Mitigation: Implement output validation and bias testing for production applications
5. Not state-of-the-art on all tasks
- Matches o4-mini but doesn’t exceed it consistently
- Proprietary models like Claude Opus 4.5 or GPT-5 may outperform on specific benchmarks
- Trade-off between open access and absolute performance
- Mitigation: Use MULTIBLY to compare outputs across models for critical tasks
Trade-offs to consider:
Open vs Closed:
- Gain: Complete control, no API costs, data privacy
- Lose: Automatic updates, zero-maintenance inference, potentially higher peak performance
Size vs Efficiency:
- 120B model: Better reasoning, higher hardware requirements
- 20B model: More accessible, slightly lower performance on complex tasks
Effort vs Speed:
- High effort: Best accuracy, 2-3x slower
- Low effort: Fastest inference, reduced reasoning quality
Common deployment mistakes:
- Assuming open means free: Hardware costs, maintenance, and optimization effort have real costs
- Skipping benchmark validation: Always test on your specific tasks before committing
- Ignoring knowledge cutoff: Implement current information sources from day one
- Over-optimizing for benchmarks: Real-world performance may differ from published numbers
Edge case: For applications requiring both speed and accuracy, consider running both models in parallel—use gpt-oss-20b for initial fast responses and gpt-oss-120b with high effort for verification or complex queries.
Conclusion
OpenAI’s gpt-oss models fundamentally change the economics of advanced reasoning AI. By releasing 120B and 20B parameter models trained with o3 and o4 techniques under Apache 2.0, OpenAI has democratized access to reasoning capabilities that previously required expensive API calls or proprietary infrastructure.
The key insight: you no longer need to choose between reasoning quality and deployment control. gpt-oss-120b matches o4-mini performance on core benchmarks while running on a single 80GB GPU, and the 20B variant delivers o3-mini-level reasoning on 16GB edge devices. The mixture-of-experts architecture makes this possible by activating only 4-5 billion parameters per token, dramatically reducing computational requirements without sacrificing quality.
For developers building reasoning agents in 2026, gpt-oss models offer:
- Cost predictability: No per-token charges, no usage tiers, no surprise bills
- Data privacy: Process sensitive information locally without external API calls
- Deployment flexibility: Run on-premise, in cloud, or on edge devices based on your needs
- Reasoning control: Adjust effort levels to optimize the speed-accuracy trade-off for each task
- License clarity: Apache 2.0 removes all commercial restrictions and user count limits
Actionable next steps:
- Evaluate hardware requirements: Determine if you have 80GB GPUs for the 120B model or can deploy the 20B variant on existing infrastructure
- Test on your workload: Download models via Ollama or LM Studio and benchmark against your specific use cases
- Compare against alternatives: Use platforms like MULTIBLY to validate gpt-oss performance against other reasoning models for your tasks
- Plan tool integration: Design your agent architecture with browsing and API tools to handle the June 2024 knowledge cutoff
- Optimize reasoning effort: Profile your queries to identify which tasks need high effort and which can use faster low/medium settings
- Calculate total cost of ownership: Compare infrastructure costs for local deployment versus API costs for proprietary alternatives
The broader implication extends beyond individual deployments. gpt-oss represents OpenAI’s recognition that the future of AI includes both proprietary and open models, each serving different needs. For teams that value control, privacy, and cost predictability over absolute cutting-edge performance, open reasoning models like gpt-oss now provide a viable path forward.
The question is no longer whether open models can compete with proprietary systems on reasoning tasks—gpt-oss proves they can. The question is which deployment model best serves your specific requirements, constraints, and values.
FAQ
What is gpt-oss from OpenAI? gpt-oss is OpenAI’s first major open-source language model release since GPT-2, consisting of 120B and 20B parameter models trained with techniques from o3 and o4. Both use mixture-of-experts architecture and are released under Apache 2.0 license for unrestricted commercial use.[2][3]
How much does it cost to run gpt-oss models? There are no API or licensing fees. Costs include hardware (80GB GPU for 120B model or 16GB for 20B model), electricity, and maintenance. Cloud GPU instances range from $1-3 per hour depending on provider and GPU type, while on-premise deployment has upfront hardware costs but lower ongoing expenses.
Can gpt-oss-20b really outperform larger models? Yes, gpt-oss-20b outperforms o3-mini on competition mathematics despite being 6 times smaller, demonstrating efficiency gains from advanced training techniques. The MoE architecture activates only 3.6 billion parameters per token, enabling strong performance with minimal compute.[2][3]
What is the knowledge cutoff for gpt-oss models? Both models have a knowledge cutoff of June 2024. For current information, integrate browsing tools or retrieval-augmented generation. The models support tool-calling to access up-to-date data through external APIs.[1][2]
How do I choose between gpt-oss-120b and gpt-oss-20b? Choose the 120B model if you need maximum reasoning quality and have 80GB GPUs available. Choose the 20B model if you’re deploying on edge devices, need faster inference, or want to minimize infrastructure costs while maintaining strong reasoning capabilities.
What license restrictions apply to gpt-oss? None. Apache 2.0 license includes no restrictions on user count, revenue, deployment context, or commercial use. You can modify, redistribute, and deploy without limitations, requiring only attribution to OpenAI.[1][2]
Can gpt-oss models use external tools and APIs? Yes, both models have built-in tool-calling capabilities optimized for agentic workflows. They can chain together 10+ API calls for complex tasks and support function calling without additional fine-tuning.[2][4]
How does the reasoning effort system affect performance? Low effort provides fastest inference (2-3x faster than high), medium balances speed and accuracy, and high effort dedicates 80% of tokens to reasoning for maximum quality. Choose based on task complexity and latency requirements.[1][2]
What hardware do I need to run gpt-oss locally? gpt-oss-120b requires a single 80GB GPU (A100, H100, or equivalent) plus 32GB+ system RAM. gpt-oss-20b runs on 16GB GPU memory (RTX 4090, A10, or equivalent) plus 16GB+ system RAM. Both work with Ollama and LM Studio.[1][5]
How does gpt-oss compare to Claude Opus 4.5 or GPT-5? gpt-oss-120b matches o4-mini but doesn’t consistently exceed top proprietary models like Claude Opus 4.5 or GPT-5 on all benchmarks. The trade-off is open access and deployment control versus absolute peak performance. Test on your specific workload to determine which matters more.
Can I fine-tune gpt-oss models for my domain? Yes, Apache 2.0 license permits modification including fine-tuning. You can adapt models for specific domains, distill them into smaller versions, or combine them with other systems without restrictions.
What happens if OpenAI releases gpt-oss-2 or updates the models? You control update timing. Unlike API-based models that update automatically, you choose when to upgrade local deployments. This provides stability for production systems but requires manual effort to incorporate improvements.
References
[1] Watch – https://www.youtube.com/watch?v=guHW1Eb3xSs
[2] Introducing Gpt Oss – https://openai.com/index/introducing-gpt-oss/
[3] Openai Gpt Oss – https://fireworks.ai/blog/openai-gpt-oss
[4] community.openai – https://community.openai.com/t/openais-open-weight-models-are-here-gpt-oss-120b-and-20b/1334739
[5] Rtx Ai Garage Openai Oss – https://blogs.nvidia.com/blog/rtx-ai-garage-openai-oss/
Our Fact Checking Process
We prioritize accuracy and integrity in our content. Here's how we maintain high standards:
- Expert Review: All articles are reviewed by subject matter experts.
- Source Validation: Information is backed by credible, up-to-date sources.
- Transparency: We clearly cite references and disclose potential conflicts.
Our Review Board
Our content is carefully reviewed by experienced professionals to ensure accuracy and relevance.
- Qualified Experts: Each article is assessed by specialists with field-specific knowledge.
- Up-to-date Insights: We incorporate the latest research, trends, and standards.
- Commitment to Quality: Reviewers ensure clarity, correctness, and completeness.
Look for the expert-reviewed label to read content you can trust.



