
xAI’s Grok 4 introduces a 2-million token context window that fundamentally changes how AI agents process information. Grok 4’s 2M Context Revolution: Real-Time X Data for Dynamic Agentic Workflows combines massive context capacity with live data from X (formerly Twitter) to create AI systems that reason across entire codebases, legal documents, and datasets while staying current with real-world events. This capability positions Grok 4 as a practical choice for enterprises building autonomous agents that need both deep context and up-to-the-minute information.
The key difference: most large language models rely on training data with cutoff dates and limited context windows. Grok 4 processes 2 million tokens in a single pass while simultaneously accessing current information from X and the broader internet. For teams building agentic workflows—systems where AI agents make decisions, execute tasks, and coordinate with other agents—this combination delivers something competitors struggle to match.
- Key Takeaways
- Quick Answer
- What Makes Grok 4's 2M Context Window Different from Traditional Models?
- How Does Real-Time X Data Integration Transform Agentic Workflows?
- Understanding Grok 4's Variant Architecture for Different Agentic Use Cases
- How Grok 4's Reduced Hallucination Rates Enable Reliable Agent Deployment
- Building Multi-Agent Workflows with Grok 4's Coordination Capabilities
- Practical Integration: Deploying Grok 4 Agents in Production Workflows
- Grok 4 vs Competing Models: Performance and Positioning in 2026
- Comparing Grok 4 Across MULTIBLY's 300+ Model Platform
- Frequently Asked Questions
- Conclusion
- References
Key Takeaways
- Grok 4 features a 2-million token context window that processes entire codebases, complex legal documents, and massive datasets without chunking or summarization[2][5][6]
- Real-time X data integration provides Grok 4 agents with current information from trending topics and breaking events as they happen, not from stale training data[2][6]
- Hallucination rates dropped 65% in Grok 4.1, falling from 12.09% to 4.22%, making enterprise deployment significantly more reliable[1]
- Grok-4 Fast offers 98% cost reduction compared to standard versions while maintaining the full 2M context window, ideal for high-volume agent operations[6]
- Multi-agent coordination capabilities enable complex orchestrated workflows where multiple Grok instances collaborate on tasks[1]
- Native tool usage through reinforcement learning allows Grok 4 to determine when to execute code, browse the web, or deploy search agents without explicit prompting[6]
- Trained on 200,000 GPUs via xAI’s Colossus supercluster, representing substantial computational investment in model quality[5]
- LM Arena leadership positions Grok 4.1 ahead of comparable models in independent benchmarks[2]
Quick Answer
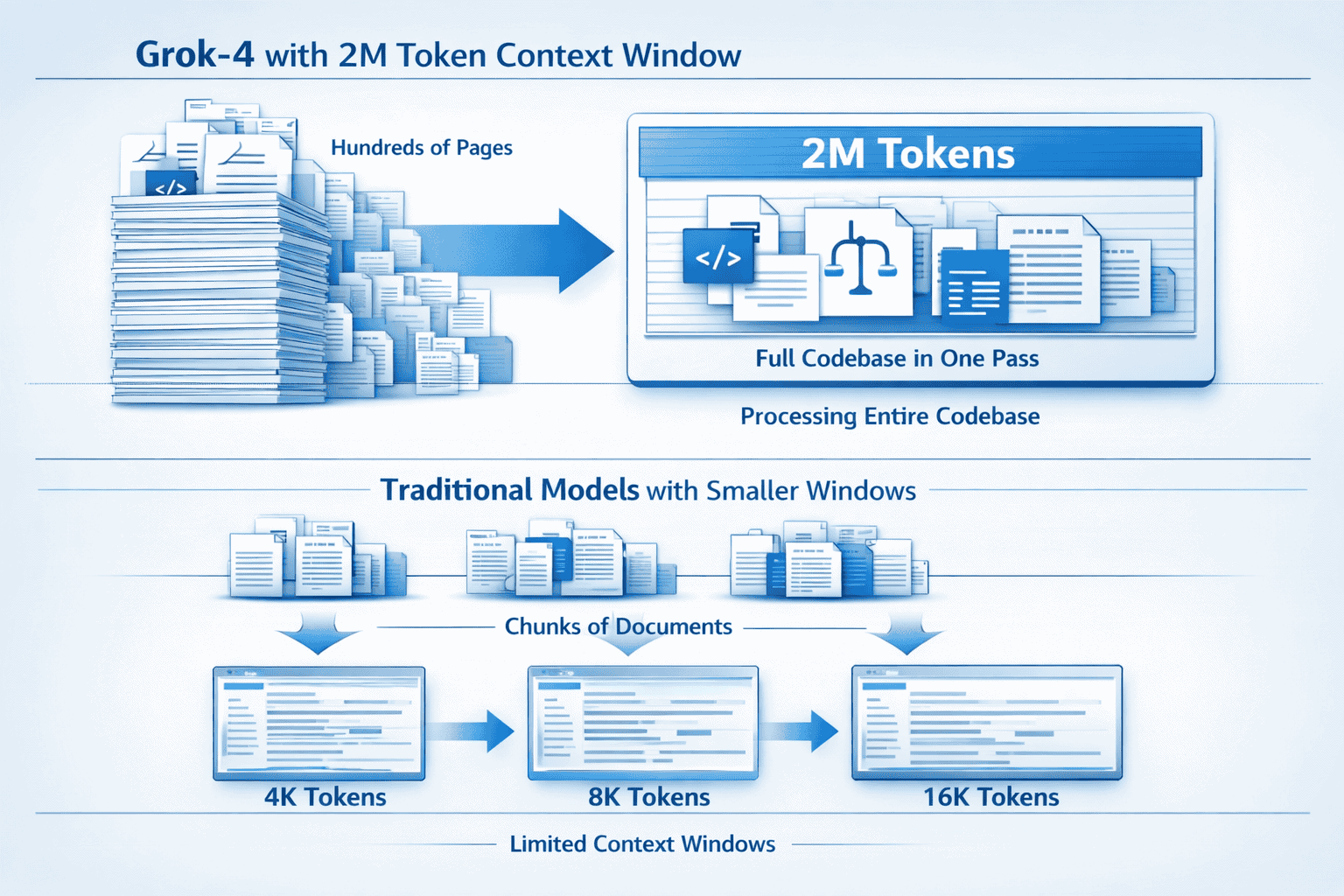
Grok 4’s 2M context revolution combines the largest commercially available context window with real-time data access from X, creating AI agents that process massive amounts of information while staying current. The 2-million token capacity handles entire codebases or document sets in a single pass, eliminating the fragmentation problems that plague traditional chunking approaches. Real-time X integration means agents built on Grok 4 access trending topics, breaking news, and current events as they unfold, rather than relying on training data that may be months old. For teams building dynamic agentic workflows, this combination delivers both deep reasoning across large contexts and awareness of the present moment.
What Makes Grok 4’s 2M Context Window Different from Traditional Models?
Grok 4’s 2-million token context window processes information at a scale that fundamentally changes what’s possible with AI agents. Traditional models typically max out at 128K to 200K tokens, forcing developers to chunk large documents, summarize sections, or implement complex retrieval systems. Grok 4 eliminates these workarounds by handling the equivalent of approximately 1.5 million words or roughly 3,000 pages of text in a single inference pass[2][5][6].
Key advantages of the 2M context capacity:
- Single-pass processing of entire codebases without losing cross-file relationships or architectural context
- Complete legal document analysis including all exhibits, references, and supporting materials simultaneously
- Full dataset comprehension for research papers with extensive appendices, tables, and supplementary data
- Elimination of chunking artifacts that introduce errors when documents are split and processed separately
- Preserved context coherence across long conversations or multi-stage agent workflows
The practical impact becomes clear when building agentic systems. An agent analyzing a complex legal case can review the entire case file, precedents, and supporting documents without context switching. A code review agent examines the full repository structure, dependencies, and implementation details together. A research agent processes complete academic papers with all citations and methodology sections intact.
Choose Grok 4’s extended context when:
- Your agents need to reason across entire document sets without summarization
- Cross-references and relationships between distant sections matter
- Chunking introduces unacceptable accuracy degradation
- You’re building multi-turn agent workflows that accumulate context over time
For context window comparisons with other leading models, see our analysis of context windows as a competitive advantage.
How Does Real-Time X Data Integration Transform Agentic Workflows?
Grok 4’s access to live X data creates a unique advantage for agents that need current information. xAI’s ownership of X (formerly Twitter) provides Grok with a constantly updating stream of trending topics, breaking news, and real-world events at the moment they occur[2]. This isn’t a post-training addition—it’s a native capability that agents can invoke through reinforcement learning-based tool usage[6].
Real-time data capabilities in practice:
The integration works through agent-based search that determines when and how to query current information. Grok 4 agents don’t blindly append X data to every response. Instead, they evaluate whether real-time information would improve their answer, then execute targeted searches across X and broader internet sources[6].
Practical applications for dynamic agents:
- Market monitoring agents that track sentiment shifts, emerging trends, and competitor announcements as they happen
- Crisis response systems that incorporate breaking news and real-time developments into decision-making
- Content strategy agents that identify trending topics and conversations relevant to your audience right now
- Competitive intelligence workflows that surface competitor moves, product launches, and strategic shifts immediately
- Event-driven automation that triggers workflows based on specific real-time conditions or announcements
The key difference from traditional retrieval-augmented generation (RAG) systems: Grok 4 doesn’t require you to build and maintain separate retrieval infrastructure. The model natively determines when current information matters and fetches it through built-in tool usage capabilities.
Common mistake to avoid: Assuming real-time data means Grok 4 always uses current information. The model still relies primarily on its training data for general knowledge. Real-time access activates when the agent determines current information would improve accuracy or relevance. For time-sensitive queries, explicitly instruct agents to prioritize recent data.
Understanding Grok 4’s Variant Architecture for Different Agentic Use Cases
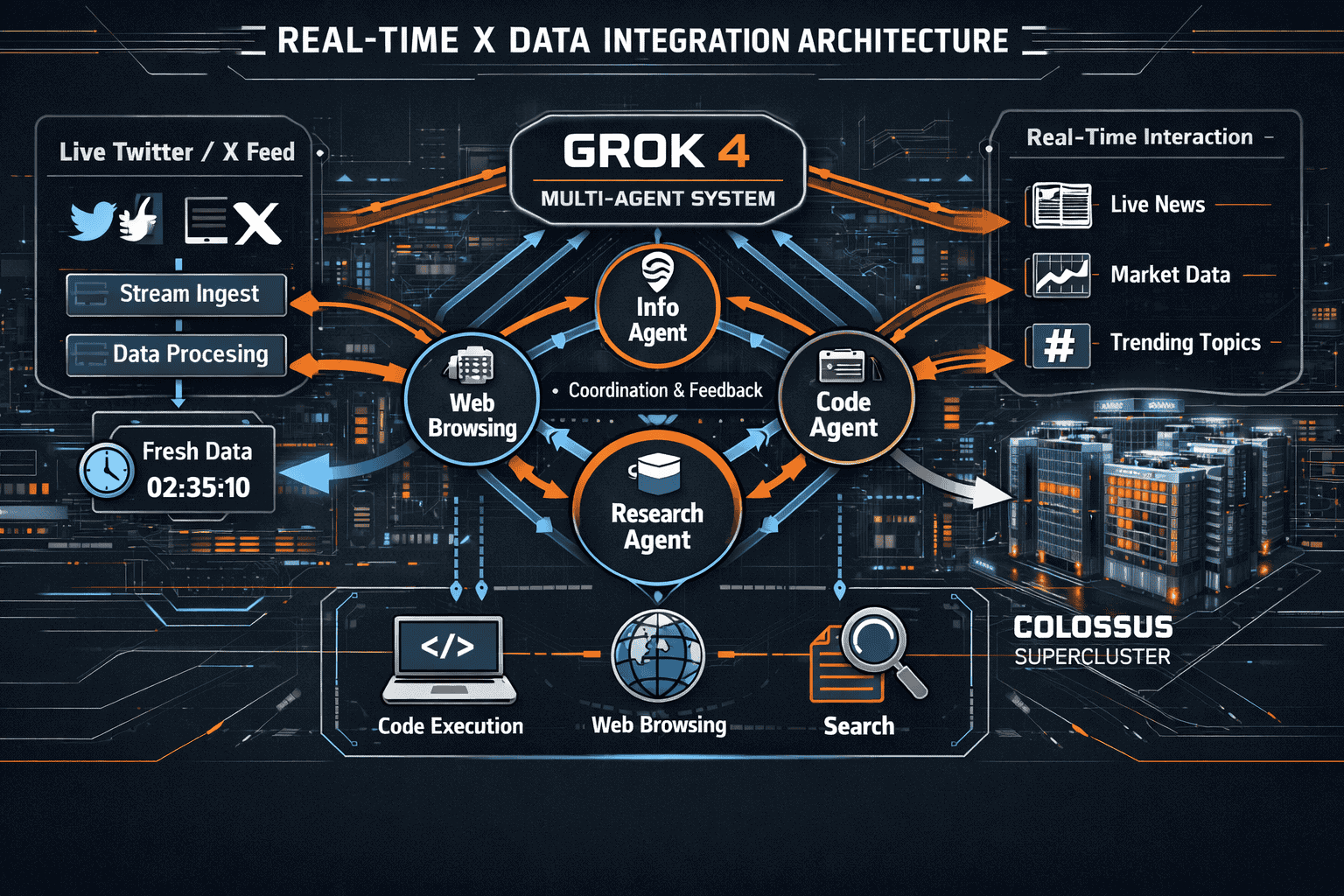
xAI released multiple Grok 4 variants optimized for different deployment scenarios. Understanding which version fits your agentic workflow requirements determines both performance and cost efficiency.
Grok 4 Standard
The baseline model balances capability and cost for general-purpose agentic applications. It includes the full 2M context window and real-time data access without optimization tradeoffs[2].
Best for: Production agents handling diverse tasks where you need maximum capability without cost constraints.
Grok-4 Fast
This efficiency-focused variant delivers 98% cost reduction compared to standard versions while maintaining the complete 2-million token context window[6]. The optimization comes through reduced output token generation (40% fewer tokens) and streamlined inference paths.
Best for: High-volume agent operations where cost per interaction matters, such as customer service agents, data processing pipelines, or automated analysis systems that generate thousands of interactions daily.
Trade-off consideration: The reduced output token count means responses may be more concise. Test whether this affects your specific use case before committing to Fast for critical workflows.
Grok 4 Heavy
Designed for complex reasoning tasks requiring maximum computational resources. This variant supports both multi-agent and single-agent operational modes, enabling sophisticated orchestrated workflows[1].
Best for: Enterprise applications where accuracy and reasoning depth justify higher costs, such as legal analysis, advanced research synthesis, or strategic decision support.
Grok 4.20
Trained on xAI’s Colossus supercluster with 200,000 GPUs, representing the latest iteration with enhanced capabilities[5]. Sources cite conflicting specifications regarding parameter count—some reference approximately 3 trillion parameters while others mention 6 trillion for broader Grok 4.2 models[2][5].
Parameter scale note: Official xAI specifications should be verified for definitive figures, as publicly available information varies.
Decision framework:
| Use Case | Recommended Variant | Key Reason |
|---|---|---|
| High-volume data processing | Grok-4 Fast | 98% cost reduction maintains viability at scale |
| Complex legal/research analysis | Grok 4 Heavy | Maximum reasoning capability for critical decisions |
| General-purpose production agents | Grok 4 Standard | Balanced capability without optimization tradeoffs |
| Cutting-edge experimentation | Grok 4.20 | Latest training and capability improvements |
For insights on how other leading models compare in agentic benchmarks, explore our coverage of GLM-4.7’s performance in 2026 agentic benchmarks.
How Grok 4’s Reduced Hallucination Rates Enable Reliable Agent Deployment
Hallucinations—instances where AI models generate plausible but factually incorrect information—represent a critical barrier to enterprise agent deployment. Grok 4.1 reduced hallucination rates by 65%, dropping from 12.09% to 4.22%[1]. This improvement makes autonomous agent operation significantly more viable for production environments.
Why hallucination reduction matters for agents:
Agents make decisions and take actions based on their reasoning. A customer service agent that hallucinates policy details creates liability. A code generation agent that invents non-existent APIs wastes developer time. A research agent that fabricates citations undermines trust. The 4.22% hallucination rate means roughly 1 in 24 responses may contain inaccurate information—still requiring validation for critical applications, but dramatically better than earlier generations.
Enhanced objectivity through reduced sycophancy:
Grok 4 versions feature sycophancy rates below 0.19, indicating improved objectivity in responses[1]. Sycophancy—the tendency to agree with user statements regardless of accuracy—creates problems for agents that need to challenge assumptions or flag potential issues.
Practical implications:
- Validation requirements decrease for non-critical agent workflows, reducing human oversight costs
- Agent autonomy increases as reliability improves, enabling broader deployment without constant supervision
- Error correction loops simplify because agents generate fewer incorrect assertions requiring detection and remediation
- Trust boundaries expand for what tasks can be safely delegated to autonomous agents
Edge case to consider: Even with reduced hallucination rates, critical applications still require validation mechanisms. Implement verification steps for agents making consequential decisions, such as financial transactions, legal recommendations, or medical information. The improvement makes agents more reliable, not infallible.
For context on how other 2026 models handle enterprise reliability requirements, see our comparison of Claude Opus 4.5 vs GPT-5.2 for enterprise problem-solving.
Building Multi-Agent Workflows with Grok 4’s Coordination Capabilities
Grok 4 and Grok 4 Heavy support both multi-agent and single-agent operational modes, enabling complex orchestrated workflows where multiple AI instances collaborate on tasks[1]. This capability transforms how teams approach problems too complex for a single agent to handle efficiently.
Multi-agent architecture patterns:
Specialist agent teams assign different Grok 4 instances to specific domains. One agent handles data analysis, another manages research synthesis, a third coordinates output formatting. Each specialist operates within its expertise area, then hands off to the next agent in the workflow.
Parallel processing workflows deploy multiple agents simultaneously on different aspects of a problem. For document analysis, separate agents might process different sections concurrently, then a coordinator agent synthesizes their findings.
Hierarchical decision structures use a supervisor agent that delegates tasks to worker agents, reviews their outputs, and makes final decisions. The supervisor leverages Grok 4’s 2M context to maintain awareness of all worker agent activities simultaneously.
Iterative refinement loops employ multiple agents in review cycles. A generation agent produces initial output, a critique agent identifies weaknesses, a revision agent implements improvements, repeating until quality thresholds are met.
Implementation considerations:
- Context sharing strategy: Decide whether agents share context through the 2M window or operate independently with summarized handoffs
- Coordination overhead: Multi-agent systems introduce communication costs—ensure the parallelization benefits outweigh coordination complexity
- Error propagation: Failures in one agent can cascade through the workflow—implement checkpoints and validation between agent handoffs
- Cost scaling: Multiple agents increase token consumption—monitor whether parallel processing justifies the additional expense
Quick example: A legal research workflow deploys three specialist agents. Agent 1 processes case law using the full 2M context window to analyze precedents. Agent 2 monitors real-time X data for recent legal developments and commentary. Agent 3 synthesizes findings from both agents into actionable recommendations. The coordinator agent maintains the complete context of all three specialists’ work, making final determinations based on comprehensive awareness.
For additional perspectives on agentic AI architectures, review our analysis of small model approaches that complement large-context systems.
Practical Integration: Deploying Grok 4 Agents in Production Workflows

Moving from Grok 4 experimentation to production deployment requires attention to several practical considerations that determine success.
API Access and Authentication
Access Grok 4 through xAI’s API infrastructure. Authentication follows standard bearer token patterns, with rate limits varying by subscription tier and model variant.
Integration steps:
- Obtain API credentials from xAI’s developer portal
- Select appropriate variant (Standard, Fast, Heavy, or 4.20) based on use case requirements
- Configure context window utilization to leverage the 2M capacity effectively
- Implement tool usage protocols for real-time data access when needed
- Set up monitoring for token consumption, latency, and error rates
Context Window Optimization
The 2M token capacity creates new opportunities but also requires strategic utilization. Not every query needs the full window.
Best practices:
- Front-load critical information in the context to ensure it receives appropriate attention
- Structure large contexts with clear section markers and hierarchies to help the model navigate
- Monitor token consumption to understand actual usage patterns and optimize costs
- Test context limits for your specific use case to identify performance degradation points
- Implement context pruning for long-running agent sessions that accumulate conversation history
Real-Time Data Configuration
Configure when and how agents access current information from X and internet sources.
Configuration options:
- Always-on mode: Agent evaluates every query for real-time data relevance
- Explicit triggering: Agent only accesses current data when instructed
- Hybrid approach: Agent uses heuristics to determine when real-time data would improve responses
- Domain restrictions: Limit real-time access to specific topics or query types
Error Handling and Fallbacks
Production agents require robust error handling for various failure modes.
Critical safeguards:
- Rate limit handling: Implement exponential backoff when hitting API limits
- Timeout management: Set appropriate timeouts for large context processing
- Hallucination detection: Add validation layers for critical outputs despite reduced hallucination rates
- Fallback strategies: Define what happens when Grok 4 is unavailable or returns errors
- Logging and observability: Capture detailed logs for debugging and improvement
Cost Management
Token consumption at 2M context capacity can escalate quickly without proper controls.
Cost optimization strategies:
- Use Grok-4 Fast for high-volume, cost-sensitive applications (98% cost reduction)[6]
- Implement context caching for repeated information across queries
- Monitor per-interaction costs to identify expensive patterns
- Set budget alerts to prevent unexpected overruns
- Evaluate ROI by measuring agent value against token costs
Common mistake: Treating the 2M context window as “free” capacity and loading unnecessary information. Each token costs money—optimize what you include based on actual value to the task.
To compare Grok 4 deployment approaches with other leading models, explore our guide to long-context LLMs in production.
Grok 4 vs Competing Models: Performance and Positioning in 2026
Grok 4.1 topped the LM Arena leaderboard, positioning it ahead of comparable models from competitors[2]. Understanding where Grok 4 excels relative to alternatives helps teams make informed model selection decisions.
Context Window Comparison
Grok 4’s 2M tokens represents the largest commercially available context window as of early 2026. Competitors typically offer:
- Claude Opus 4.5: 200K tokens
- GPT-5 variants: 128K-256K tokens depending on tier
- Gemini 3 Pro: 1M tokens
- Kimi K2: 256K tokens
The 2M capacity provides Grok 4 with a substantial advantage for applications requiring massive context, though most use cases don’t require the full window.
Real-Time Data Access
Grok 4’s native X integration creates a unique capability. Competitors rely on separate RAG systems or lack real-time data entirely. This architectural difference matters for agents that need current information without building custom retrieval infrastructure.
Hallucination and Reliability
Grok 4.1’s 4.22% hallucination rate[1] compares favorably to many alternatives, though top-tier models like Claude Opus 4.5 demonstrate similar or better reliability in specific domains. The key: Grok 4’s improvement trajectory shows xAI’s commitment to enterprise-grade accuracy.
Cost Efficiency
Grok-4 Fast’s 98% cost reduction[6] makes it competitive for high-volume applications, though absolute pricing varies by provider and usage patterns. Compare total cost of ownership including API fees, infrastructure, and operational overhead.
Reasoning and Benchmark Performance
LM Arena leadership[2] indicates strong general performance, but domain-specific benchmarks matter more for specialized applications. Test Grok 4 against your actual use cases rather than relying solely on general benchmarks.
Decision criteria for model selection:
| Requirement | Choose Grok 4 If… | Consider Alternatives If… |
|---|---|---|
| Context needs | You regularly process 500K+ token documents | Your typical context is under 128K tokens |
| Real-time data | You need current X/internet information natively | You already have robust RAG infrastructure |
| Cost sensitivity | High-volume workflows benefit from Fast variant | Low-volume, high-value interactions justify premium models |
| Specialized domains | General-purpose performance meets your needs | You need domain-specific fine-tuning (medical, legal, etc.) |
For additional model comparisons relevant to agentic workflows, see our analysis of open versus closed model economics in 2026.
Comparing Grok 4 Across MULTIBLY’s 300+ Model Platform
The MULTIBLY platform provides access to 300+ premium AI models, enabling side-by-side comparison of Grok 4 against alternatives for your specific use cases. Rather than committing to a single model based on benchmarks or marketing claims, test actual performance with your data and workflows.
Why cross-model comparison matters for agent development:
Different models excel at different tasks. Grok 4’s 2M context and real-time data access create advantages for specific scenarios, but other models may outperform for reasoning depth, specialized domains, or cost efficiency in your particular application.
MULTIBLY’s comparison capabilities:
- Side-by-side response evaluation shows how Grok 4, Claude Opus 4.5, GPT-5, and other models handle identical prompts
- Performance testing across your actual agent workflows identifies which model delivers optimal results
- Cost analysis compares token consumption and pricing across models for your usage patterns
- Rapid iteration enables testing multiple models without separate API integrations
- Informed decision-making based on empirical results rather than vendor claims
Practical testing approach:
- Define representative tasks that mirror your production agent workflows
- Test Grok 4 variants (Standard, Fast, Heavy) against leading alternatives
- Evaluate context utilization to determine whether 2M tokens provides meaningful advantages
- Assess real-time data value by comparing Grok 4’s current information against models without native access
- Measure cost-performance tradeoffs to identify the optimal model for each workflow component
Example scenario: A legal research agent might use Grok 4 Heavy for comprehensive case analysis leveraging the 2M context window, Claude Opus 4.5 for nuanced reasoning on specific legal questions, and Grok-4 Fast for high-volume document classification. MULTIBLY enables testing this multi-model architecture before committing to production deployment.
The platform’s unified access eliminates integration friction, letting teams focus on finding the right model for each task rather than managing multiple API relationships. For one subscription, compare Grok 4’s capabilities against hundreds of alternatives and build hybrid agent systems that leverage each model’s strengths.
Learn more about MULTIBLY’s features and how the platform supports sophisticated AI model selection and deployment.
Frequently Asked Questions
What is Grok 4’s context window size and why does it matter?
Grok 4 features a 2-million token context window, the largest commercially available as of early 2026. This capacity processes approximately 1.5 million words or 3,000 pages in a single pass, eliminating the need to chunk large documents or implement complex retrieval systems. For agentic workflows, this means agents can reason across entire codebases, legal cases, or research datasets without losing context or introducing fragmentation errors.
How does Grok 4 access real-time data from X?
Grok 4 natively integrates current information from X (formerly Twitter) and broader internet sources through reinforcement learning-based tool usage. The model determines when real-time data would improve responses and executes targeted searches without requiring explicit prompting. This capability stems from xAI’s ownership of X, providing a constantly updating stream of trending topics and breaking news.
What is the difference between Grok 4 Standard and Grok-4 Fast?
Grok-4 Fast delivers 98% cost reduction compared to standard versions while maintaining the full 2-million token context window. The optimization comes through reduced output token generation (40% fewer tokens) and streamlined inference. Choose Fast for high-volume agent operations where cost per interaction matters, such as data processing pipelines or automated analysis systems generating thousands of interactions daily.
How reliable is Grok 4 for enterprise agent deployment?
Grok 4.1 reduced hallucination rates by 65%, dropping from 12.09% to 4.22%, making autonomous agent operation significantly more viable for production environments. The model also features sycophancy rates below 0.19, indicating improved objectivity. While this represents substantial improvement, critical applications still require validation mechanisms for consequential decisions.
Can Grok 4 support multi-agent workflows?
Yes. Grok 4 and Grok 4 Heavy support both multi-agent and single-agent operational modes, enabling complex orchestrated workflows where multiple AI instances collaborate on tasks. The 2M context window allows coordinator agents to maintain awareness of all worker agent activities simultaneously, facilitating sophisticated hierarchical and parallel processing architectures.
What are the main use cases for Grok 4’s 2M context window?
Primary applications include processing entire codebases for development agents, analyzing complete legal cases with all exhibits and precedents, synthesizing research papers with full appendices and citations, maintaining long conversation histories in customer service agents, and coordinating complex multi-agent workflows where the coordinator needs awareness of all specialist activities.
How does Grok 4 compare to Claude Opus 4.5 and GPT-5?
Grok 4 offers significantly larger context capacity (2M tokens vs 200K-256K for most competitors) and native real-time data access from X. Claude Opus 4.5 and GPT-5 may excel in specialized reasoning tasks or specific domains. The optimal choice depends on your specific requirements—test with actual workflows rather than relying solely on general benchmarks. MULTIBLY enables side-by-side comparison across all three models.
What does Grok 4 cost and how can I optimize expenses?
Pricing varies by variant and usage tier. Grok-4 Fast offers 98% cost reduction compared to standard versions, making it viable for high-volume applications. Optimize costs by using Fast for appropriate workflows, implementing context caching for repeated information, monitoring per-interaction token consumption, and avoiding unnecessary context loading. Evaluate ROI by measuring agent value against token costs.
Is Grok 4 suitable for small teams or only enterprises?
Grok 4’s capabilities benefit both small teams and enterprises, though the optimal variant differs. Small teams building focused agents may find Grok-4 Fast provides necessary capabilities at manageable costs. Enterprises with complex requirements might justify Grok 4 Heavy for critical applications. The 2M context window and real-time data access create value regardless of organization size when use cases align with these capabilities.
How do I get started with Grok 4 for agent development?
Begin by obtaining API credentials from xAI’s developer portal, then select the appropriate variant (Standard, Fast, Heavy, or 4.20) based on your use case. Start with small-scale testing to understand context utilization patterns and token consumption. Implement monitoring for costs and performance. Consider using MULTIBLY to compare Grok 4 against alternatives with your actual workflows before committing to production deployment.
What training infrastructure powers Grok 4?
Grok 4.20 was trained on xAI’s Colossus supercluster with 200,000 GPUs, representing substantial computational investment in model quality. This infrastructure enables the large parameter counts and extensive training that deliver Grok 4’s capabilities, though exact parameter specifications vary across sources and should be verified through official xAI documentation.
Can Grok 4 replace traditional RAG systems?
For many use cases requiring current information, Grok 4’s native real-time data access reduces or eliminates the need for separate RAG infrastructure. However, organizations with specialized proprietary data sources still benefit from RAG systems that incorporate internal documents and databases. The 2M context window can also serve as an alternative to RAG for applications where all relevant information fits within the context capacity.
Conclusion
Grok 4’s 2M Context Revolution: Real-Time X Data for Dynamic Agentic Workflows represents a significant advancement in AI agent capabilities. The combination of massive context capacity and native real-time data access creates practical advantages for teams building autonomous systems that need both deep reasoning and current awareness.
The 2-million token context window eliminates fragmentation problems that plague traditional approaches, enabling agents to process entire codebases, legal cases, and research datasets in single passes. Real-time X integration provides current information without requiring separate retrieval infrastructure. Reduced hallucination rates make autonomous operation more viable for production environments. Multiple variants optimize for different deployment scenarios, from cost-sensitive high-volume applications to complex reasoning tasks requiring maximum capability.
Actionable next steps:
- Evaluate your context requirements to determine whether Grok 4’s 2M window provides meaningful advantages over smaller-context alternatives
- Identify workflows where real-time data access from X would improve agent performance
- Test Grok 4 variants against your actual use cases using platforms like MULTIBLY to compare performance across models
- Start with Grok-4 Fast for cost-sensitive experimentation, then upgrade to Standard or Heavy for critical applications
- Implement proper monitoring for token consumption, costs, and performance before scaling to production
- Design validation mechanisms for consequential decisions despite improved reliability
- Consider multi-agent architectures that leverage Grok 4’s coordination capabilities for complex workflows
The practical value of Grok 4’s capabilities depends on alignment with your specific requirements. Teams processing large documents, building real-time monitoring agents, or orchestrating complex multi-agent systems will find substantial benefits. Organizations with simpler needs or existing RAG infrastructure may find alternative models more cost-effective.
In practice, the best approach combines empirical testing with informed decision-making. Compare Grok 4 against alternatives using your actual data and workflows. Measure performance, cost, and reliability rather than relying on benchmarks alone. Build hybrid systems that use the right model for each task.
For teams navigating the expanding AI landscape, platforms like MULTIBLY provide the infrastructure to make these comparisons efficiently, testing 300+ models side by side to identify optimal solutions for each component of your agentic workflows.
References
[1] Grok 4 20 Preview Xai Musk Roadmap – https://www.digitalapplied.com/blog/grok-4-20-preview-xai-musk-roadmap
[2] Watch – https://www.youtube.com/watch?v=TObHIBDue_w
[5] Watch – https://www.youtube.com/watch?v=kAQUWq4GzbI
[6] Grok 4 Fast Announcement – https://howaiworks.ai/blog/grok-4-fast-announcement
Our Fact Checking Process
We prioritize accuracy and integrity in our content. Here's how we maintain high standards:
- Expert Review: All articles are reviewed by subject matter experts.
- Source Validation: Information is backed by credible, up-to-date sources.
- Transparency: We clearly cite references and disclose potential conflicts.
Our Review Board
Our content is carefully reviewed by experienced professionals to ensure accuracy and relevance.
- Qualified Experts: Each article is assessed by specialists with field-specific knowledge.
- Up-to-date Insights: We incorporate the latest research, trends, and standards.
- Commitment to Quality: Reviewers ensure clarity, correctness, and completeness.
Look for the expert-reviewed label to read content you can trust.



