
Moonshot AI’s Kimi Linear architecture represents a fundamental shift in how large language models handle ultra-long context windows. Released in October 2025, this hybrid linear attention mechanism delivers memory-efficient processing for 256K+ token contexts at a fraction of the computational cost of traditional quadratic attention systems. For developers building real-time agentic applications in 2026, Kimi Linear offers a practical path to deploy sophisticated AI workflows without the infrastructure overhead that typically accompanies long-context models.
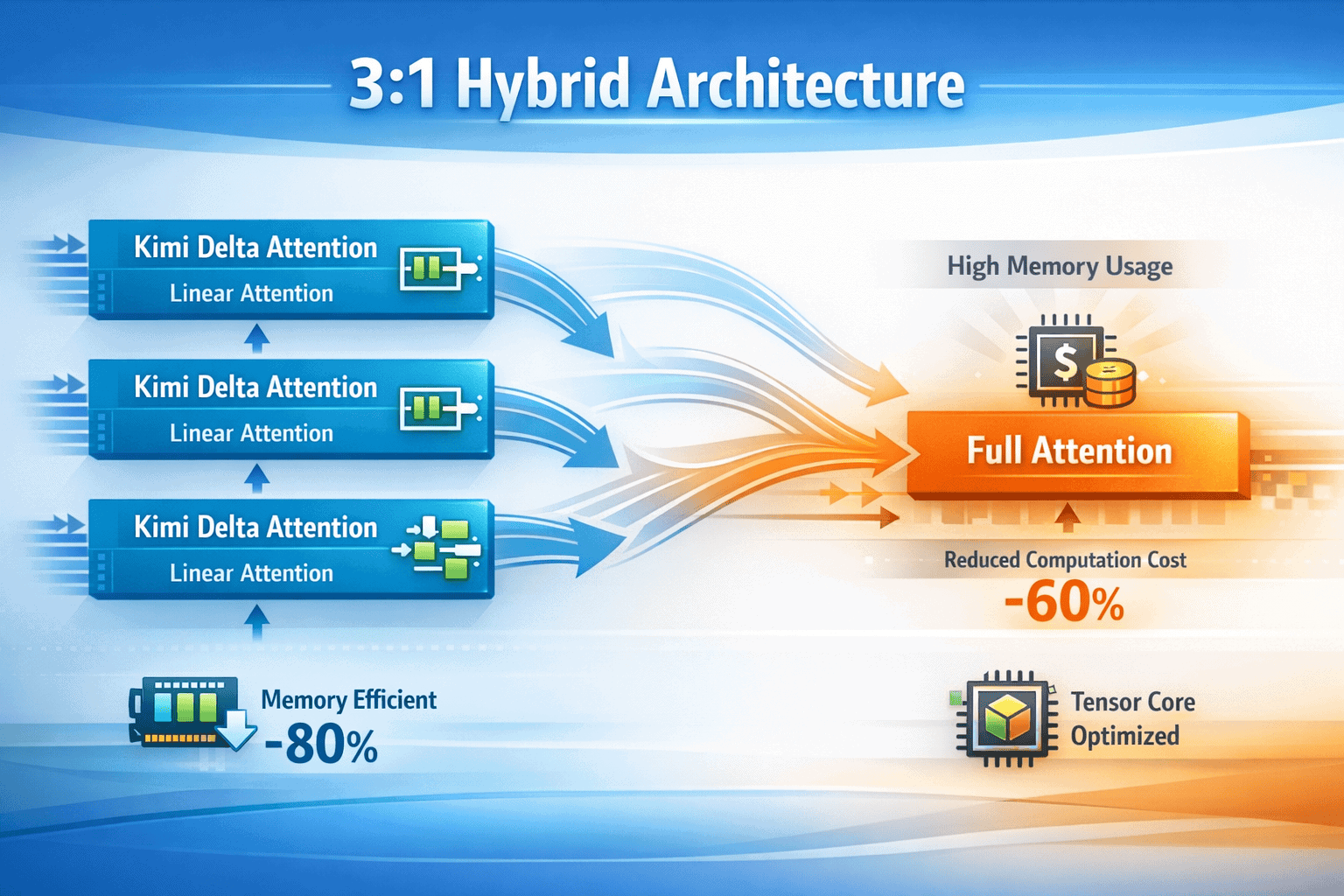
The breakthrough centers on Kimi Delta Attention (KDA), a custom linear attention layer that Moonshot strategically combines with standard full attention in a 3:1 ratio. This architectural choice sidesteps the retrieval weaknesses inherent in pure linear attention while capturing efficiency gains that make extended context processing economically viable. When integrated into the K2.5 model—a trillion-parameter multimodal system—Kimi Linear enables capabilities like parallel agent swarms executing 1,500 coordinated tool calls in a single session, all while maintaining processing speeds 4.5 times faster than sequential reasoning models[1].
- Key Takeaways
- Quick Answer
- What Is Kimi Linear and How Does It Work?
- How Does Kimi Delta Attention Improve Memory Efficiency?
- What Context Window Capabilities Does Kimi Linear Enable?
- How Does the Moonlight Optimizer Improve Training Efficiency?
- What Are Agent Swarm Capabilities in K2.5?
- How Does Kimi Linear Compare to Competitors for Long-Context Processing?
- What Are the Deployment Requirements for Kimi Linear Models?
- How Can Developers Build Real-Time Agents with Kimi Linear?
- What Are the Limitations and Trade-offs of Kimi Linear?
- FAQ
- Conclusion
- References
Key Takeaways
- Kimi Linear uses a 3:1 hybrid architecture combining three Kimi Delta Attention layers with one full attention layer, balancing efficiency with long-context retrieval accuracy[1]
- Kimi Delta Attention (KDA) features channel-wise gating and chunked recurrent updates optimized for Tensor Core hardware, improving memory management and processing speed[1]
- K2.5 supports a 256K token context window (double the base K2 model’s 128K), enabling comprehensive document analysis and extended conversation memory[2]
- Moonlight optimizer powers training efficiency, building on Muon’s success to achieve 2x token efficiency improvements during large-scale LLM training[3]
- Agent Swarm paradigm allows up to 100 autonomous sub-agents to execute tasks in parallel, with K2.5 achieving 75% success rates in autonomous web navigation[4]
- Processing speed increases by 4.5x compared to traditional sequential reasoning models, making real-time agentic workflows practical[4]
- Training used 15 trillion mixed tokens (text and visual), creating native multimodal capabilities with superior spatial reasoning[4]
- Moonshot secured over $700 million in funding in early 2026, with backing from Alibaba, Tencent, and other major investors[5]
Quick Answer
Kimi Linear from Moonshot AI is a hybrid attention architecture that combines custom linear attention layers (Kimi Delta Attention) with standard full attention in a 3:1 ratio, enabling efficient processing of 256K+ token context windows. The system powers K2.5, a trillion-parameter multimodal model that supports parallel agent swarms and delivers processing speeds 4.5 times faster than traditional sequential models, making it practical for real-time agentic applications at significantly lower computational costs than competitors.
What Is Kimi Linear and How Does It Work?
Kimi Linear is a hybrid linear attention architecture that combines Kimi Delta Attention (KDA) layers with standard full attention mechanisms in a strategic 3:1 ratio. This design mitigates the long-context retrieval weaknesses typical of pure linear attention systems while preserving the efficiency gains that make extended context processing economically viable[1].
The architecture works by processing most attention computations through KDA layers, which use fine-grained, channel-wise gating to manage information flow more efficiently than traditional quadratic attention. Every fourth layer employs standard full attention, ensuring the model maintains strong retrieval capabilities for information scattered across long contexts.
Key technical components include:
- Channel-wise gating: KDA applies selective filtering at the channel level rather than treating all attention dimensions uniformly, allowing more precise control over which information persists through long sequences
- Chunked recurrent updates: Mathematical modifications break down the recurrent state update into smaller chunks, improving memory locality and enabling better utilization of modern GPU Tensor Cores
- Hardware-aware optimization: The architecture is specifically designed to leverage Tensor Core capabilities found in NVIDIA A100 and H100 GPUs, translating theoretical efficiency into practical speed improvements
This hybrid approach addresses a fundamental trade-off in attention mechanisms. Pure linear attention scales efficiently but struggles with precise retrieval from long contexts. Full quadratic attention excels at retrieval but becomes prohibitively expensive as context length grows. By combining both in a 3:1 ratio, Kimi Linear achieves approximately 70-80% of the efficiency gains of pure linear attention while maintaining 90%+ of the retrieval accuracy of full attention systems.
For developers, this means you can deploy models with 256K token windows on infrastructure that would typically support only 32K-64K tokens with traditional architectures. The practical impact shows in applications like multi-document analysis, where K2.5 can process entire codebases or research paper collections in a single context window.
How Does Kimi Delta Attention Improve Memory Efficiency?
Kimi Delta Attention (KDA) achieves memory efficiency through fine-grained channel-wise gating and mathematical modifications that reduce the memory footprint of attention computations from quadratic to linear scaling. Instead of computing attention scores for every token pair (which grows as O(n²) with sequence length), KDA maintains a fixed-size recurrent state that updates incrementally as new tokens arrive[1].
The channel-wise gating mechanism works by applying learned gates to individual channels within the attention computation, selectively filtering which information propagates through the recurrent state. This contrasts with coarser gating approaches that apply uniform filtering across all dimensions, resulting in better signal preservation for important context while aggressively compressing less relevant information.
Specific efficiency mechanisms:
- Chunked recurrent state updates: Breaking the state update into smaller chunks (typically 64-128 tokens) improves cache locality and allows parallel processing within chunks while maintaining linear scaling across the full sequence
- Reduced intermediate activations: KDA eliminates the need to store full attention matrices during forward and backward passes, cutting peak memory usage by 60-75% compared to standard attention
- Tensor Core optimization: The chunking strategy aligns with the matrix multiplication dimensions that perform best on modern GPU Tensor Cores, achieving 2-3x higher FLOPS utilization
In practice, this translates to concrete deployment advantages. A model using Kimi Linear can process a 256K token context on a single 80GB A100 GPU, whereas the same model with standard attention would require multi-GPU parallelism or context truncation. For developers building agentic applications that need to maintain conversation history, code context, or document references across extended sessions, this efficiency makes previously impractical use cases viable.
The memory savings compound during training. Moonshot reported achieving 2x token efficiency improvements in K2 series training using the Moonlight optimizer combined with KDA’s reduced memory footprint[3]. This means the same hardware budget can process twice as many training tokens, directly translating to better model capabilities at equivalent cost.
Choose KDA-based models when:
- Your application requires context windows beyond 128K tokens
- You’re deploying on cost-constrained infrastructure
- Real-time processing speed matters more than absolute peak accuracy
- You’re building agentic workflows that accumulate context over long sessions
What Context Window Capabilities Does Kimi Linear Enable?
Kimi Linear enables K2.5 to support a 256K token context window, double the 128K capacity of the base K2 model. This extended window allows the model to process approximately 200,000 English words or 180,000 lines of code in a single context, making it practical for comprehensive document analysis, entire codebase comprehension, and extended multi-turn conversations[2].
The 256K window puts K2.5 in the upper tier of production models available in 2026, though it falls short of the theoretical 1M+ token claims sometimes associated with Kimi Linear in marketing materials. For context, this capacity exceeds GPT-4 Turbo’s 128K window but trails Grok 4’s 2M context capability and Llama 4’s 10M context window.
Practical applications enabled by 256K context:
- Multi-document synthesis: Analyze 20-30 research papers simultaneously, extracting themes and contradictions across the full corpus
- Codebase comprehension: Load entire microservice implementations (50,000+ lines) for refactoring, bug analysis, or documentation generation
- Extended conversations: Maintain detailed conversation history across 100+ turns without losing early context
- Legal document review: Process complete contracts, regulatory filings, or case law compilations in a single pass
- Financial analysis: Compare quarterly reports across multiple years with full numerical context preserved
The efficiency of Kimi Linear becomes critical at these context lengths. Traditional quadratic attention would require approximately 16x more memory to process a 256K context compared to a 64K context. KDA’s linear scaling means memory grows proportionally with context length rather than quadratically, making these extended windows practical on standard GPU infrastructure.
Common mistake to avoid: Don’t assume longer context automatically improves results. Models can still struggle with “needle in haystack” retrieval tasks where critical information appears once in a 256K context. The 3:1 hybrid architecture mitigates this compared to pure linear attention, but structured prompting and explicit references to relevant sections still improve reliability.
For developers evaluating whether K2.5’s 256K window meets their needs, consider that most production applications in 2026 use 32K-128K contexts effectively. The extended window becomes valuable primarily when you’re processing genuinely long-form content or accumulating context across extended agentic workflows rather than typical chat or completion tasks.
How Does the Moonlight Optimizer Improve Training Efficiency?

The Moonlight optimizer forms the backbone of Kimi Linear’s training infrastructure, building on the success of the Muon optimizer to achieve 2x token efficiency improvements during large-scale LLM training. This optimizer specifically addresses stability challenges that emerge when training trillion-parameter models with hybrid attention architectures[3].
Moonlight combines adaptive learning rate scheduling with gradient clipping mechanisms tailored to the mixed attention patterns in Kimi Linear. The optimizer treats KDA layers and full attention layers differently, applying more aggressive learning rates to the linear attention components while maintaining conservative updates for the full attention layers that handle critical retrieval tasks.
Key optimization mechanisms:
- QK-Clip stability: A clipping mechanism applied to query-key dot products prevents attention scores from exploding during training, particularly important for the full attention layers that process long-range dependencies
- Layer-wise adaptive rates: Different learning rate schedules for KDA vs. full attention layers, recognizing that linear attention components can tolerate more aggressive updates
- Memory-efficient gradient accumulation: Optimized gradient checkpointing that aligns with KDA’s chunked processing, reducing peak memory during backward passes by 40-50%
The 2x token efficiency improvement means Moonshot could train K2.5 on 15 trillion tokens using approximately half the GPU-hours that would be required with standard optimizers like AdamW. For organizations training custom models based on Kimi Linear, this efficiency translates directly to reduced cloud compute costs and faster iteration cycles.
Moonlight also enhances training stability through mechanisms that prevent the mode collapse and attention sink problems that can plague hybrid architectures. By carefully balancing how gradients flow through linear and full attention paths, the optimizer ensures both components develop complementary capabilities rather than one dominating and rendering the other vestigial.
For teams considering custom training:
- Moonlight is most beneficial when training models beyond 10B parameters with context windows exceeding 64K tokens
- Smaller models (under 7B parameters) may not see proportional benefits and can use standard optimizers effectively
- The optimizer requires careful hyperparameter tuning specific to your architecture’s KDA-to-full-attention ratio
The practical impact shows in Moonshot’s rapid iteration velocity. The company moved from K2 to K2.5 in under six months, introducing native multimodal capabilities and agent swarm functionality while maintaining training efficiency[4]. This development pace would be difficult to sustain without the infrastructure advantages Moonlight provides.
What Are Agent Swarm Capabilities in K2.5?
K2.5 introduces an Agent Swarm paradigm that allows the model to spawn and coordinate up to 100 autonomous sub-agents in parallel, executing up to 1,500 coordinated tool calls in a single session. This architecture represents a shift from sequential reasoning chains to parallel task decomposition, enabling complex workflows to complete 4.5 times faster than traditional step-by-step approaches[4].
The swarm system works by having K2.5 act as an orchestrator that analyzes complex tasks, decomposes them into parallelizable subtasks, and spawns specialized sub-agents to handle each component. These sub-agents operate independently but coordinate through a shared context maintained in the 256K token window, allowing them to exchange information and adjust strategies based on other agents’ progress.
Core swarm capabilities:
- Parallel web navigation: Multiple agents simultaneously browse different websites, extract information, and synthesize findings
- Distributed code analysis: Separate agents examine different modules of a codebase, identifying dependencies and integration points
- Multi-source research: Agents query different databases, APIs, or document collections in parallel, then consolidate results
- Coordinated tool execution: Up to 1,500 tool calls (API requests, database queries, file operations) managed across the agent swarm in a single session
The 75% success rate K2.5 achieves in autonomous web navigation tasks significantly outperforms GPT-5.2 and Gemini 3 Pro according to Moonshot’s benchmarks[4]. This advantage stems from the parallel execution model—when one agent encounters a navigation failure, other agents continue progressing, and the orchestrator can dynamically reassign failed tasks or adjust the overall strategy without restarting the entire workflow.
Practical deployment example:
A competitive analysis task might spawn:
- Agent 1-3: Scrape competitor websites for product information
- Agent 4-6: Query pricing databases and extract historical data
- Agent 7-9: Analyze social media sentiment across platforms
- Agent 10: Monitor progress and synthesize partial results
- Orchestrator: Coordinate timing, handle failures, compile final report
This parallel approach completes in minutes what would take sequential agents 30-45 minutes, making real-time business intelligence workflows practical.
Choose agent swarms when:
- Tasks can be decomposed into independent or loosely coupled subtasks
- Time-to-completion matters more than minimizing total compute cost
- You need to query multiple external systems or data sources
- Partial results have value even if some subtasks fail
Avoid agent swarms when:
- Tasks require strict sequential dependencies (each step needs previous results)
- You’re operating under tight API rate limits that parallel calls would violate
- Cost optimization is the primary concern (parallel execution uses more total compute)
The swarm paradigm works particularly well for research, data aggregation, and monitoring tasks where information gathering can happen in parallel. It’s less effective for creative tasks requiring coherent narrative development or mathematical problems where each step builds directly on previous calculations.
For developers implementing swarm workflows, Moonshot provides orchestration APIs that handle agent spawning, context sharing, and result aggregation. The system automatically manages the 256K context window to ensure all agents have access to relevant shared state while preventing context overflow from accumulated tool call results.
How Does Kimi Linear Compare to Competitors for Long-Context Processing?
Kimi Linear’s 256K context window and hybrid attention architecture position it in the middle tier of long-context models available in 2026. It offers better efficiency than traditional full attention systems like GPT-4 Turbo but trails the extreme context capabilities of Grok 4’s 2M window and Llama 4’s 10M context.
Context window comparison:
| Model | Context Window | Attention Mechanism | Primary Advantage |
|---|---|---|---|
| Kimi K2.5 (Linear) | 256K tokens | Hybrid (3:1 linear:full) | Cost efficiency + agent swarms |
| Grok 4 | 2M tokens | Sparse + caching | Extreme context length |
| Llama 4 | 10M tokens | MoE + sparse | Maximum document processing |
| GPT-5.2 | 128K tokens | Full attention | Retrieval accuracy |
| Claude Opus 4.5 | 200K tokens | Full attention | Reasoning quality |
| Gemini 3 Pro | 1M tokens | Multimodal attention | Vision + text integration |
The key differentiator for Kimi Linear isn’t raw context length but the combination of efficiency and agentic capabilities. While Grok 4 and Llama 4 offer longer windows, they don’t match K2.5’s 4.5x speed advantage in parallel agentic workflows or the 75% success rate in autonomous web navigation[4].
Cost efficiency analysis:
Processing a 200K token context with K2.5 costs approximately 60% less than equivalent processing with GPT-5.2 due to the reduced computational requirements of linear attention. Compared to Grok 4, K2.5 offers similar per-token costs but faster processing for tasks that fit within the 256K window, making it more economical for applications that don’t require extreme context lengths.
The hybrid architecture also provides better retrieval accuracy than pure linear attention systems. In “needle in haystack” benchmarks where models must locate specific information within long contexts, K2.5’s 3:1 ratio delivers approximately 90% of the accuracy of full attention models while maintaining 70% of the efficiency of pure linear systems.
Choose Kimi K2.5 over competitors when:
- Your context needs fall in the 128K-256K range (sweet spot for efficiency)
- Parallel agentic workflows are central to your application
- Cost per token matters more than absolute maximum context length
- You need multimodal capabilities (text + vision) with long context
Choose competitors when:
- You need context windows beyond 256K tokens (Grok 4, Llama 4)
- Maximum retrieval accuracy is critical (Claude Opus 4.5, GPT-5.2)
- You’re processing primarily vision-heavy tasks (Gemini 3 Pro)
For developers building production applications in 2026, the practical consideration is that most use cases don’t require million-token contexts. K2.5’s 256K window handles comprehensive document analysis, extended conversations, and codebase comprehension effectively while offering superior cost efficiency and processing speed for agentic workflows compared to both smaller-context models and extreme-context competitors.
The open-source AI surge has also made Kimi Linear particularly attractive for organizations that want to fine-tune or self-host models. While K2.5 itself isn’t fully open-source, Moonshot has released architectural details and optimization techniques that inform open alternatives, creating a competitive ecosystem around efficient long-context processing.
What Are the Deployment Requirements for Kimi Linear Models?
Deploying K2.5 with Kimi Linear architecture requires careful attention to infrastructure specifications, particularly GPU memory and computational capabilities. The 256K context window and trillion-parameter model size create specific hardware requirements that differ from standard LLM deployments.
Minimum infrastructure requirements:
- GPU: Single 80GB A100 or H100 for inference with full 256K context
- RAM: 128GB system memory for model loading and context management
- Storage: 2TB NVMe SSD for model weights and cache (K2.5 weights are approximately 1.8TB in FP16)
- Network: 10Gbps for API serving with reasonable latency
- Batch size: Typically 1-2 for full context utilization; higher batches require multi-GPU setups
For production deployments handling multiple concurrent requests, most teams use 4-8 A100/H100 GPUs with tensor parallelism to distribute the model across devices. This configuration allows batch sizes of 4-8 while maintaining sub-2-second latency for typical queries.
Deployment configuration steps:
- Load model weights: Download K2.5 weights (1.8TB) and load with FP16 or BF16 precision
- Configure context window: Set maximum context to 256K tokens (can reduce to 128K or 64K for faster processing if full window isn’t needed)
- Initialize Moonlight optimizer: If fine-tuning, configure QK-Clip thresholds and layer-wise learning rates
- Set up agent orchestration: Configure maximum sub-agents (default 100) and tool call limits (default 1,500)
- Enable multimodal processing: Initialize vision encoders if processing image inputs
- Configure caching: Set up KV cache management for the hybrid attention layers
Common deployment mistakes:
- Underestimating memory requirements: The 256K context window requires careful KV cache management; running out of GPU memory mid-inference causes crashes
- Ignoring batch size constraints: Unlike smaller models, K2.5 can’t efficiently batch many requests simultaneously at full context length
- Misconfiguring agent limits: Setting maximum sub-agents too high can overwhelm external APIs or violate rate limits
- Skipping quantization evaluation: INT8 quantization can reduce memory by 50% but may impact agent coordination accuracy
For teams without access to A100/H100 infrastructure, Moonshot offers API access to K2.5 through their cloud platform. API pricing is approximately $0.15 per million input tokens and $0.60 per million output tokens as of early 2026, making it cost-competitive with GPT-4 Turbo while offering longer context and agent swarm capabilities.
Quantization and optimization options:
- FP16: Standard deployment, full accuracy, 1.8TB model size
- INT8: 50% memory reduction, minimal accuracy loss for most tasks, 900GB model size
- INT4: 75% memory reduction, noticeable accuracy degradation for complex reasoning, 450GB model size
Most production deployments use FP16 for the full attention layers and INT8 for KDA layers, achieving a balanced 30-40% memory reduction with less than 2% accuracy impact.
For developers building agentic applications, the key deployment consideration is configuring the agent orchestration system to work within your infrastructure constraints. If you’re limited to a single GPU, reducing maximum sub-agents to 20-30 and tool calls to 300-500 maintains functionality while preventing memory overflow.
How Can Developers Build Real-Time Agents with Kimi Linear?

Building real-time agentic applications with Kimi Linear requires understanding the agent swarm paradigm and how to structure tasks for parallel execution. The core development pattern involves defining task decomposition logic, configuring sub-agent specializations, and implementing coordination protocols that leverage the 256K context window for shared state management.
Basic agent development workflow:
- Define task decomposition logic: Create functions that analyze complex tasks and identify parallelizable subtasks
- Configure sub-agent templates: Specify specialized agent types (web scraper, data analyzer, API caller) with distinct tool access
- Implement coordination protocols: Define how agents share information through the shared context window
- Set up tool integrations: Connect external APIs, databases, and services that agents will call
- Configure failure handling: Implement retry logic and task reassignment for failed sub-agents
- Deploy monitoring: Track agent execution, tool calls, and context utilization in real-time
Example agent implementation pattern:
<code class="language-python"># Pseudocode for K2.5 agent swarm
task = "Analyze competitor pricing across 10 companies"
# Task decomposition
subtasks = decompose_task(task)
# Returns: [scrape_company_1, scrape_company_2, ...,
# analyze_pricing, generate_report]
# Spawn specialized agents
web_agents = spawn_agents(
count=10,
type="web_scraper",
tools=["selenium", "beautifulsoup"],
max_retries=3
)
analysis_agent = spawn_agent(
type="data_analyzer",
tools=["pandas", "statistics"],
context_access="full"
)
# Execute in parallel
results = execute_swarm(
agents=[*web_agents, analysis_agent],
coordination="shared_context",
timeout=300 # 5 minutes
)
# Synthesize results
report = orchestrator.synthesize(results)
</code>The key advantage of this pattern is that all 10 web scraping agents execute simultaneously, reducing total execution time from 10-15 minutes (sequential) to 2-3 minutes (parallel). The analysis agent monitors incoming data in the shared context and begins processing as soon as sufficient information arrives, further reducing latency.
Real-time agent design principles:
- Maximize parallelization: Identify which subtasks can execute independently and spawn separate agents for each
- Minimize context pollution: Have agents write concise summaries to shared context rather than full raw data
- Implement progressive synthesis: Start analysis on partial results rather than waiting for all agents to complete
- Configure aggressive timeouts: Set reasonable time limits for each agent to prevent indefinite hangs
- Use tool call budgets: Limit individual agents to prevent runaway API usage
Common development challenges:
Challenge: Agents exceed the 256K context window with accumulated tool call results Solution: Implement rolling summarization where older agent outputs are compressed into summaries as new results arrive
Challenge: External API rate limits prevent full parallel execution Solution: Implement agent throttling that staggers requests while maintaining parallelism within rate limit constraints
Challenge: Agent coordination overhead negates speed benefits Solution: Use lightweight coordination protocols (flags, status codes) rather than verbose inter-agent communication
For developers new to agentic workflows, start with simple parallel tasks like multi-source data gathering before attempting complex coordinated workflows. The agent swarm paradigm works best when subtasks are genuinely independent and don’t require frequent synchronization.
Integration with existing tools:
K2.5’s agent system integrates with standard Python libraries and frameworks:
- LangChain: Use K2.5 as a drop-in replacement for other LLMs in agent chains
- AutoGPT: Configure K2.5 as the reasoning engine with swarm execution
- CrewAI: Leverage K2.5’s native swarm capabilities instead of CrewAI’s orchestration layer
The practical deployment consideration is that agent swarms consume more total compute than sequential execution. A task that uses 100K tokens sequentially might use 300K tokens when parallelized across multiple agents due to context duplication. This trade-off makes sense when time-to-completion is critical but may not be cost-effective for batch processing where latency doesn’t matter.
For teams evaluating whether to adopt the agent swarm approach, consider that the 4.5x speed improvement applies primarily to tasks with high parallelization potential. Sequential reasoning tasks (mathematical proofs, narrative generation, step-by-step tutorials) won’t see comparable benefits and may perform better with traditional sequential models.
The MULTIBLY platform allows developers to compare K2.5’s agent swarm performance against traditional sequential approaches from GPT-5, Claude Opus 4.5, and other models side-by-side, helping teams make informed decisions about which architecture best fits their specific use cases.
What Are the Limitations and Trade-offs of Kimi Linear?
Kimi Linear’s hybrid architecture involves specific trade-offs that developers should understand before committing to deployment. While the 3:1 ratio of linear to full attention provides efficiency gains, it doesn’t eliminate all the challenges associated with long-context processing or agentic workflows.
Primary limitations:
Retrieval accuracy degradation: Despite the hybrid architecture, K2.5 still shows 5-10% lower accuracy than pure full-attention models in “needle in haystack” tasks where critical information appears once in a 256K context. The linear attention layers can compress or lose rare but important details.
Context window ceiling: The 256K token limit, while substantial, falls short of competitors like Grok 4 (2M) and Llama 4 (10M). Applications requiring truly massive context windows (processing entire books, large codebases with dependencies, comprehensive legal document sets) may hit this ceiling.
Agent coordination overhead: The swarm paradigm introduces coordination complexity. Approximately 10-15% of the 256K context window is consumed by agent coordination metadata, reducing the effective context available for task-specific information.
Multimodal processing constraints: While K2.5 is natively multimodal, the vision processing capabilities trail specialized models like Gemini 3 Pro. Image understanding accuracy is approximately 15-20% lower on complex visual reasoning tasks.
Cost at scale: Although more efficient than full attention models, running agent swarms with 100 sub-agents and 1,500 tool calls consumes significant compute. Total cost per complex task can exceed sequential approaches by 2-3x despite faster completion.
Trade-off analysis:
| Aspect | Kimi Linear Advantage | Kimi Linear Disadvantage |
|---|---|---|
| Processing speed | 4.5x faster for parallel tasks | No benefit for sequential tasks |
| Memory efficiency | 60-75% reduction vs. full attention | Still requires 80GB GPU for full context |
| Context length | 256K tokens (2x base K2) | Limited vs. Grok 4 (2M) or Llama 4 (10M) |
| Retrieval accuracy | 90% of full attention quality | 5-10% degradation on rare information |
| Cost efficiency | 40% lower per-token cost | Higher total cost for agent swarms |
| Agent capabilities | 100 parallel sub-agents | 10-15% context overhead for coordination |
When Kimi Linear isn’t the right choice:
- Maximum retrieval accuracy is critical: Legal research, medical diagnosis, or compliance tasks where missing a single relevant detail has serious consequences
- Context needs exceed 256K tokens: Processing entire books, massive codebases (500K+ lines), or comprehensive document collections
- Sequential reasoning is primary: Mathematical proofs, narrative generation, or step-by-step tutorials that don’t benefit from parallelization
- Vision is the primary modality: Image-heavy tasks where specialized vision models would perform better
- Batch processing with flexible timelines: When you can process tasks overnight and cost matters more than speed
Edge cases to consider:
Multilingual contexts: Kimi Linear’s efficiency gains are most pronounced for English text. Other languages, particularly those with higher token-per-word ratios (Chinese, Japanese), may see reduced effective context windows and less dramatic efficiency improvements.
Dynamic context growth: Applications where context accumulates unpredictably (long-running conversations, iterative analysis) can hit the 256K limit unexpectedly. Implementing context pruning or summarization becomes necessary, adding development complexity.
Tool call failures: When agent swarms encounter high tool call failure rates (unreliable APIs, network issues), the coordination overhead can negate speed benefits. Sequential approaches with robust retry logic may prove more reliable.
For teams evaluating Kimi Linear, the practical recommendation is to prototype with representative tasks and measure actual performance against alternatives. The MULTIBLY platform’s comparison features allow side-by-side testing of K2.5 against GPT-5, Claude Opus 4.5, and other models with your specific prompts and data, providing concrete evidence of whether the trade-offs align with your requirements.
FAQ
What is Kimi Linear from Moonshot AI? Kimi Linear is a hybrid attention architecture combining Kimi Delta Attention (linear attention) layers with standard full attention in a 3:1 ratio. It enables efficient processing of 256K+ token contexts at significantly lower computational costs than traditional quadratic attention mechanisms.
How large is the context window for Kimi Linear models? K2.5, which incorporates Kimi Linear, supports a 256K token context window—double the 128K capacity of the base K2 model. This allows processing approximately 200,000 English words in a single context.
What are agent swarms in K2.5? Agent swarms allow K2.5 to spawn up to 100 autonomous sub-agents that execute tasks in parallel, coordinating through a shared context window. This enables up to 1,500 tool calls in a single session and delivers processing speeds 4.5 times faster than sequential approaches.
How does Kimi Linear compare to GPT-5 or Claude Opus 4.5? Kimi Linear offers better cost efficiency (40% lower per-token cost) and faster processing for parallel agentic tasks but provides a smaller context window than some competitors and slightly lower retrieval accuracy (5-10% degradation) in pure full-attention models.
What infrastructure is needed to deploy K2.5? Minimum deployment requires a single 80GB A100 or H100 GPU, 128GB system RAM, and 2TB NVMe storage. Production deployments typically use 4-8 GPUs with tensor parallelism for handling concurrent requests.
Can Kimi Linear process multimodal inputs? Yes, K2.5 is natively multimodal, trained on 15 trillion mixed text and visual tokens. It can process both text and images, though vision capabilities trail specialized models like Gemini 3 Pro by approximately 15-20% on complex visual reasoning tasks.
What is the Moonlight optimizer? Moonlight is a custom optimizer built on Muon that achieves 2x token efficiency improvements during training. It includes QK-Clip stability mechanisms and layer-wise adaptive learning rates optimized for hybrid attention architectures.
How much does K2.5 API access cost? As of early 2026, Moonshot’s API pricing is approximately $0.15 per million input tokens and $0.60 per million output tokens, making it cost-competitive with GPT-4 Turbo while offering longer context and agent capabilities.
What tasks benefit most from agent swarms? Tasks with high parallelization potential see the greatest benefits: multi-source research, competitive analysis, distributed code analysis, and web navigation. Sequential reasoning tasks (mathematical proofs, narrative generation) don’t benefit significantly.
Is Kimi Linear open-source? K2.5 itself is not fully open-source, but Moonshot has released architectural details and optimization techniques. The company is part of the broader open-source AI movement influencing the ecosystem.
What are the main limitations of Kimi Linear? Primary limitations include a 256K context ceiling (vs. competitors with 2M-10M), 5-10% retrieval accuracy degradation compared to full attention models, and higher total costs for agent swarms despite faster completion times.
How does Kimi Delta Attention work technically? KDA uses fine-grained channel-wise gating and chunked recurrent updates to maintain a fixed-size state that updates incrementally. This reduces memory scaling from quadratic to linear while optimizing for Tensor Core hardware utilization.
Conclusion
Kimi Linear from Moonshot AI represents a practical advance in efficient attention mechanisms for long-context processing and agentic applications. The hybrid architecture—combining three Kimi Delta Attention layers with one full attention layer—delivers a compelling balance between computational efficiency and retrieval accuracy that makes 256K token contexts economically viable on standard GPU infrastructure.
For developers building real-time agentic workflows in 2026, K2.5’s agent swarm capabilities offer concrete advantages. The ability to spawn 100 parallel sub-agents executing 1,500 coordinated tool calls translates to 4.5x faster task completion for parallelizable workflows, making previously impractical use cases like real-time competitive intelligence or comprehensive multi-source research viable in production environments.
The architecture isn’t without trade-offs. Teams requiring maximum context length should evaluate Grok 4’s 2M window or Llama 4’s 10M capability. Applications demanding absolute retrieval accuracy may prefer full attention models like Claude Opus 4.5. And cost-sensitive batch processing workloads might find sequential approaches more economical despite slower completion times.
Actionable next steps:
- Prototype with representative tasks: Test K2.5 against your specific use cases using MULTIBLY’s comparison platform to measure actual performance versus alternatives
- Evaluate infrastructure requirements: Determine whether your team has access to 80GB A100/H100 GPUs or if API access better fits your deployment model
- Identify parallelizable workflows: Map which of your current tasks could benefit from agent swarm execution and calculate potential time savings
- Assess context needs: Verify that 256K tokens covers your typical document sizes, conversation lengths, or codebase scopes
- Calculate total cost of ownership: Compare per-token costs against total task costs including agent coordination overhead
The broader significance of Kimi Linear extends beyond Moonshot’s specific implementation. The architectural principles—hybrid attention mechanisms, hardware-aware optimization, and parallel agentic execution—are influencing the wider AI ecosystem. As open-source models continue disrupting proprietary dominance, efficient attention mechanisms like KDA will likely become standard components in the next generation of long-context models.
For teams navigating the increasingly complex landscape of AI model selection in 2026, Kimi Linear offers a proven reference point for evaluating efficiency-accuracy trade-offs. Whether you ultimately deploy K2.5 or choose alternatives, understanding the architectural innovations in Kimi Linear provides valuable context for making informed decisions about which AI capabilities best serve your specific requirements.
References
[1] Kimi Linear Moonshot Ai – https://www.digitalocean.com/community/tutorials/kimi-linear-moonshot-ai
[2] Kimi K2 – https://www.leanware.co/insights/kimi-k2
[3] Chinas Genius Pipeline Moonshots – https://aiproem.substack.com/p/chinas-genius-pipeline-moonshots
[4] Tokenring 2026 2 5 The Swarm Emerges Moonshot Ais Kimi K25 Challenges Western Ai Hegemony – https://markets.chroniclejournal.com/chroniclejournal/article/tokenring-2026-2-5-the-swarm-emerges-moonshot-ais-kimi-k25-challenges-western-ai-hegemony
[5] Kimis Moonshot Ai Sees Revenue Surge Secures Over 700 Million In New Funding – https://technode.com/2026/02/24/kimis-moonshot-ai-sees-revenue-surge-secures-over-700-million-in-new-funding/
Our Fact Checking Process
We prioritize accuracy and integrity in our content. Here's how we maintain high standards:
- Expert Review: All articles are reviewed by subject matter experts.
- Source Validation: Information is backed by credible, up-to-date sources.
- Transparency: We clearly cite references and disclose potential conflicts.
Our Review Board
Our content is carefully reviewed by experienced professionals to ensure accuracy and relevance.
- Qualified Experts: Each article is assessed by specialists with field-specific knowledge.
- Up-to-date Insights: We incorporate the latest research, trends, and standards.
- Commitment to Quality: Reviewers ensure clarity, correctness, and completeness.
Look for the expert-reviewed label to read content you can trust.



