
Meta’s Llama 4 Scout introduces an unprecedented 10 million token context window that fundamentally changes how enterprises process massive documents, codebases, and datasets. Unlike previous models that required chunking and summarization, Scout processes entire document collections in a single pass—enabling AI applications that were previously impossible with open-source alternatives.
This breakthrough represents a 78x increase from Llama 3’s 128K context limit and positions Scout as the first open-source model capable of competing with proprietary giants in long-context scenarios. For organizations managing extensive legal documents, multi-year financial reports, or enterprise-scale codebases, Scout eliminates the architectural complexity of traditional retrieval-augmented generation (RAG) systems.
- Key Takeaways
- Quick Answer
- What Makes Llama 4 Scout's 10M Token Context Window Different?
- How Does Scout's Architecture Enable Massive Document Processing?
- What Real-World Applications Does the 10M Context Enable?
- How Does Scout Compare to Proprietary Long-Context Models?
- What Are the Deployment Options and Platform Availability?
- What Are the Performance Benchmarks and Limitations?
- How Should Organizations Implement Scout for Production Workloads?
- What Are the Cost Considerations for Scout Deployment?
- What's Next for Long-Context Open-Source Models?
- Frequently Asked Questions
- Conclusion
- References
Key Takeaways
- Llama 4 Scout features a 10 million token context window—78x larger than Llama 3’s 128K limit—enabling processing of entire document collections without chunking or summarization
- The model uses a Mixture of Experts (MoE) architecture with 109B total parameters and 17B active parameters across 16 expert modules for efficient processing
- Scout achieves over 40,000 output tokens per second on NVIDIA Blackwell B200 GPUs with FP8 optimization, delivering 3.4x faster throughput than H200 GPUs
- Deployment requires just a single NVIDIA H100 GPU when quantized to int4, with hardware costs around $20,000—making enterprise adoption accessible
- The model was trained on 40 trillion tokens—nearly 3x more than Llama 3—and supports native multimodal capabilities across 12 languages
- Scout is available on major platforms including Cloudflare Workers AI, AWS SageMaker JumpStart, and Amazon Bedrock (coming soon)
- Key use cases include multi-document summarization, codebase reasoning, financial analysis, and personalization from extensive user activity logs
- Independent testing shows variable performance on real-world coding tasks, with some limitations in following complex instructions across the full context window
Quick Answer
Llama 4 Scout’s 10 million token context window allows enterprises to process entire document collections, massive codebases, and multi-year reports in a single inference pass without chunking or summarization. Built on a 109B parameter Mixture of Experts architecture with 17B active parameters, Scout delivers efficient long-context processing that was previously only available in proprietary models. The model runs on a single NVIDIA H100 GPU when quantized, making it accessible for organizations seeking open-source alternatives to GPT-4 and Claude for document-intensive AI applications.
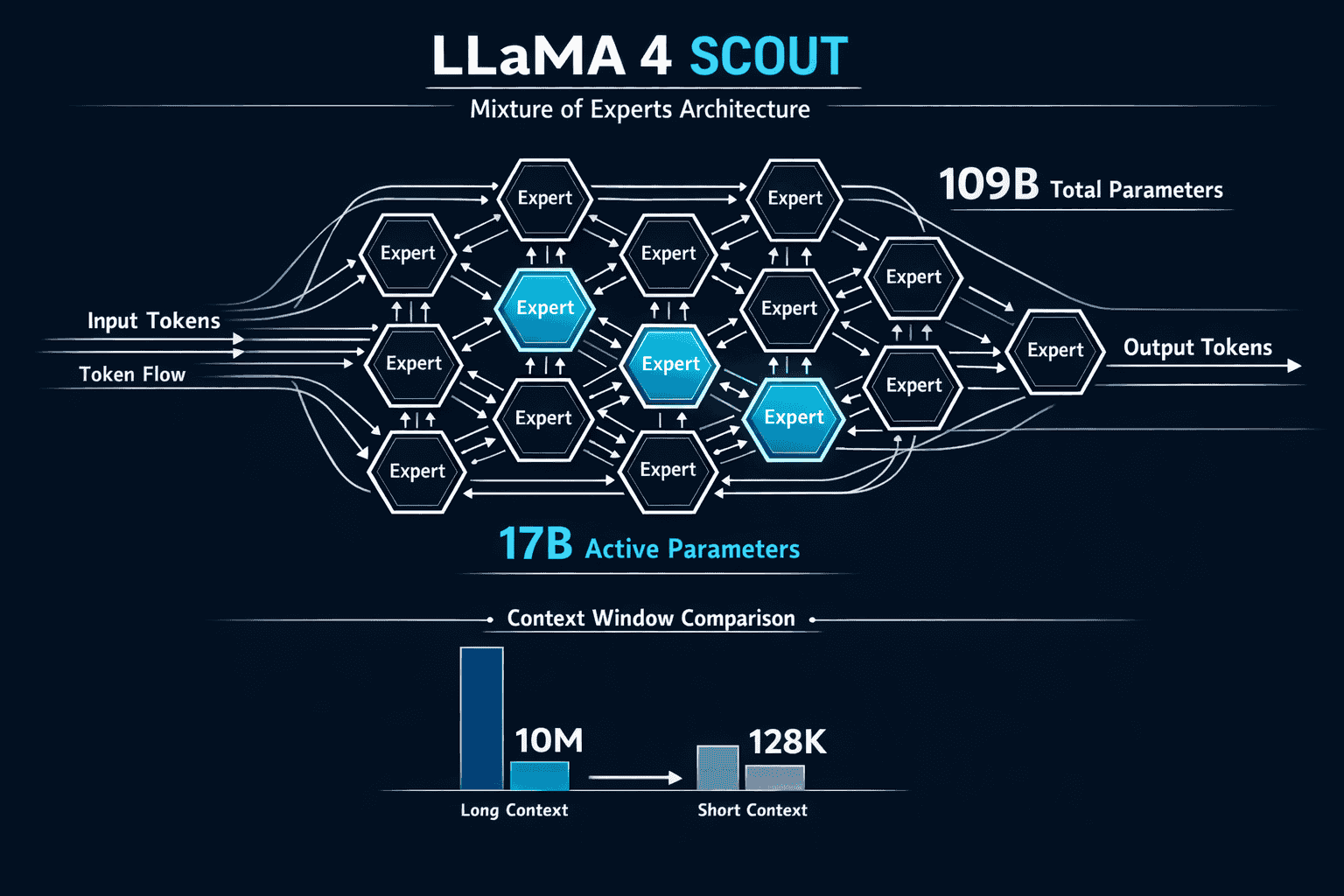
What Makes Llama 4 Scout’s 10M Token Context Window Different?
Llama 4 Scout’s 10 million token context window represents the largest context capacity in any open-source language model as of 2026. This capacity allows the model to process approximately 7.5 million words or roughly 15,000 pages of text in a single inference pass.[1]
The context window expansion from Llama 3’s 128,000 tokens to 10 million tokens fundamentally changes architectural requirements for document AI systems. Traditional approaches required:
- Chunking strategies to split documents into manageable segments
- Embedding-based retrieval to find relevant sections
- Multiple inference passes to process complete document sets
- Complex orchestration to maintain coherence across chunks
Scout eliminates these requirements for most enterprise use cases. The model processes complete document collections directly, maintaining full context awareness throughout the inference process.
Training Methodology for Long Context
Meta achieved the 10M context capability through a specialized training approach. Scout was pre-trained and post-trained with a 256K context length, then extended to 10M through mid-training recipes and specialized long context extension datasets.[2]
This training methodology enables what Meta calls “length generalization”—the model’s ability to effectively utilize context windows far beyond what it saw during training. The approach differs from simply increasing training context length, which becomes computationally prohibitive at this scale.
Key architectural decisions:
- 109 billion total parameters with Mixture of Experts design
- 16 expert modules with 17 billion active parameters per request
- Native multimodal support for image and text understanding
- 12-language multilingual capability built into the foundation model
The MoE architecture proves critical for managing the computational demands of 10M context processing. By activating only 17B parameters per request instead of the full 109B, Scout maintains efficiency while providing specialist expertise through its expert modules.
For organizations evaluating open-source alternatives to proprietary models, Scout’s architecture demonstrates that long-context capabilities no longer require closed-source solutions.
How Does Scout’s Architecture Enable Massive Document Processing?
The Mixture of Experts (MoE) architecture forms the foundation of Scout’s ability to handle 10M token contexts efficiently. Unlike dense models that activate all parameters for every request, Scout’s design activates only the relevant expert modules needed for each specific task.[3]
Architecture breakdown:
- Total parameters: 109 billion
- Active parameters per request: 17 billion
- Expert modules: 16 specialized networks
- Routing mechanism: Dynamic expert selection based on input
This selective activation reduces computational overhead by approximately 84% compared to a hypothetical dense 109B model processing the same context. The efficiency gain makes 10M context processing economically viable for enterprise deployment.
Hardware Requirements and Deployment Options
Scout’s hardware requirements vary significantly based on precision format and optimization level. Meta designed the model to be accessible for organizations without massive GPU clusters.[3][4]
Deployment configurations:
| Configuration | Hardware | Precision | Performance | Use Case |
|---|---|---|---|---|
| Maximum Performance | NVIDIA B200 | FP8 | 40,000+ tokens/sec | High-throughput production |
| Balanced | NVIDIA H200 | FP8 | ~12,000 tokens/sec | Standard enterprise workloads |
| Cost-Optimized | Single H100 | int4 quantized | Variable | Budget-conscious deployment |
| Edge Deployment | Multiple H100s | FP6/FP4 | Application-dependent | Distributed processing |
The single H100 deployment option deserves particular attention. Meta optimized Scout to run on a single NVIDIA H100 GPU when quantized to int4 precision, with estimated hardware costs around $20,000.[5] This accessibility democratizes long-context AI for mid-sized organizations.
Choose the single H100 configuration if your organization needs long-context capabilities but lacks the budget for multi-GPU clusters. The performance tradeoff is acceptable for many document analysis, legal review, and codebase reasoning applications.
Common deployment mistake: Organizations often over-provision hardware based on total parameter count rather than active parameters. Scout’s MoE architecture means you don’t need hardware capable of running a full 109B dense model—the 17B active parameter count determines actual memory and compute requirements.
For teams comparing deployment options, Llama 4’s broader model family offers additional configurations optimized for different workload types.
What Real-World Applications Does the 10M Context Enable?
Llama 4 Scout’s 10M token context window unlocks specific enterprise applications that were previously impractical with open-source models. The extended context eliminates architectural complexity while improving output quality for document-intensive workflows.

Multi-Document Financial Analysis
Scout processes multi-year financial reports without summarization or chunking. AWS demonstrated this capability using multiple years of Amazon 10-K reports, where Scout analyzed trends, extracted insights, and answered complex questions spanning the entire document set.[4]
Choose this approach for:
- Comparative financial analysis across fiscal years
- Regulatory compliance document review
- Investment research requiring comprehensive historical context
- Audit preparation and risk assessment
The model maintains coherence across the full context, identifying patterns and relationships that would be lost in chunked processing approaches.
Codebase Reasoning and Software Development
For software development teams, Scout processes entire codebases in a single context window. This enables:
- Cross-file dependency analysis without manual code mapping
- Refactoring recommendations that account for system-wide impacts
- Bug identification by analyzing interaction patterns across modules
- Documentation generation that accurately reflects complete system architecture
Independent testing shows variable results on complex coding tasks, particularly when instructions require following specific patterns across the full 10M context.[5] The model performs better on analysis and explanation tasks than on generating new code that must maintain consistency across massive contexts.
Practical limitation: While Scout can ingest entire codebases, output quality degrades when tasks require precise adherence to constraints across the full context. For most teams, using Scout for codebase analysis and understanding works better than using it for large-scale code generation.
User Activity Personalization
E-commerce and content platforms leverage Scout to analyze extensive user activity logs for personalization. The model processes months or years of user interactions, purchases, browsing history, and engagement data to generate:
- Highly contextualized product recommendations
- Personalized content curation based on long-term preferences
- Churn prediction using complete user journey analysis
- Customer lifetime value modeling with full historical context
This application eliminates the need for complex feature engineering and manual summarization of user histories that traditional ML approaches require.
Legal Document Review and Contract Analysis
Legal teams use Scout for comprehensive contract review, due diligence, and case law research. The 10M context handles:
- Complete M&A document packages without splitting
- Multi-party contract analysis with cross-reference validation
- Regulatory compliance review across document portfolios
- Case law research with full opinion text analysis
For organizations managing these workloads, comparing long-context model options helps identify the right balance of context window size, cost, and performance.
How Does Scout Compare to Proprietary Long-Context Models?
Llama 4 Scout’s 10M token context window positions it competitively against proprietary models, though important performance differences remain. Understanding these tradeoffs helps organizations make informed deployment decisions.
Context Window Comparison
Leading models by context capacity (2026):
- Llama 4 Scout: 10,000,000 tokens (open-source)
- Gemini 1.5 Pro: 2,000,000 tokens (proprietary)
- Claude 3 Opus: 200,000 tokens (proprietary)
- GPT-4 Turbo: 128,000 tokens (proprietary)
- Kimi K2: 256,000 tokens (open-source)
Scout’s context window exceeds all major proprietary alternatives, making it the technical leader in raw context capacity. However, context window size alone doesn’t determine practical utility—retrieval accuracy, instruction following, and output quality across the full context matter equally.
Retrieval Performance: Needle in the Haystack
Meta claims “nearly perfect retrieval” performance in Needle in the Haystack tests, where the model must locate specific information buried within massive contexts.[2] Independent evaluations show more variable results.
In practice: Scout performs well on straightforward retrieval tasks (finding specific facts, dates, or quotes) but struggles with tasks requiring synthesis of information scattered across the full 10M context. The model’s attention mechanism appears to prioritize recent context over earlier portions of the window, similar to other long-context models.
Choose Scout for applications where relevant information clusters together (complete documents, sequential codebases) rather than scenarios requiring equal attention across randomly distributed information.
Cost and Licensing Advantages
Scout’s open-source licensing provides significant total cost of ownership benefits compared to proprietary alternatives:
Deployment cost factors:
- No per-token API fees for self-hosted deployment
- Hardware amortization over unlimited inference volume
- No vendor lock-in or pricing changes
- Complete data privacy and control
For high-volume document processing workloads, the economics favor self-hosted Scout deployment once monthly inference volume exceeds the break-even threshold. Organizations processing millions of documents annually typically reach this threshold within 3-6 months.
Organizations evaluating open versus closed model economics should model total cost across a 3-year deployment horizon rather than focusing solely on initial setup costs.
What Are the Deployment Options and Platform Availability?
Llama 4 Scout is available across multiple deployment platforms, each with different context window limits, performance characteristics, and pricing models. Understanding these options helps organizations choose the right deployment path.

Cloudflare Workers AI
Cloudflare Workers AI offers Scout deployment with simplified infrastructure management. The platform currently supports a 131,000 token context window at launch, with plans to increase this limit toward the full 10M capacity in future updates.[1]
Cloudflare deployment characteristics:
- Serverless execution with automatic scaling
- Global edge network for low-latency inference
- Pay-per-request pricing model
- No GPU infrastructure management required
Choose Cloudflare Workers AI if your organization needs rapid deployment without infrastructure investment, and your use cases fit within the current 131K context limit. This works well for most document analysis applications that don’t require the full 10M window.
AWS SageMaker JumpStart and Bedrock
Amazon Web Services provides Scout access through SageMaker JumpStart, with Amazon Bedrock availability coming soon. The AWS deployment offers greater control over infrastructure and context window configuration.[4]
AWS deployment benefits:
- Full 10M context window support
- Integration with existing AWS services and data pipelines
- Customizable instance types and scaling policies
- VPC deployment for enhanced security
The SageMaker deployment requires more infrastructure management than Cloudflare but provides complete flexibility for enterprise requirements. Organizations with existing AWS infrastructure typically find this path most efficient.
Self-Hosted NVIDIA Infrastructure
For maximum control and cost efficiency at scale, organizations deploy Scout on self-managed NVIDIA infrastructure using TensorRT-LLM optimization.[3]
NVIDIA deployment specifications:
- Recommended hardware: NVIDIA H100, H200, or B200 GPUs
- Optimization framework: TensorRT-LLM with FP8/FP6/FP4 precision support
- Minimum configuration: Single H100 with int4 quantization
- Performance: Up to 40,000+ tokens/sec on B200 with FP8
Self-hosted deployment makes economic sense when monthly inference volume exceeds approximately 50 million tokens or when data privacy requirements prevent cloud deployment.
Implementation checklist for self-hosted deployment:
- Provision NVIDIA H100 or better GPU infrastructure
- Install TensorRT-LLM optimization framework
- Download and quantize Scout model weights
- Configure inference server with desired precision format
- Implement monitoring and scaling policies
- Benchmark performance on representative workloads
- Establish backup and disaster recovery procedures
Organizations without existing GPU infrastructure should carefully evaluate total cost of ownership before committing to self-hosted deployment. The break-even point typically occurs between 6-18 months depending on inference volume.
For teams comparing deployment strategies across multiple models, platforms like MULTIBLY provide access to 300+ AI models including Scout, enabling side-by-side testing before infrastructure investment.
What Are the Performance Benchmarks and Limitations?
Understanding Scout’s real-world performance helps set appropriate expectations and identify optimal use cases. While the 10M context window is technically impressive, practical performance varies significantly by application type.
Throughput and Latency Characteristics
Scout’s inference performance depends heavily on hardware configuration and precision format. NVIDIA provides detailed benchmarks across their GPU lineup.[3]
Performance by hardware configuration:
- NVIDIA B200 (FP8): 40,000+ output tokens/sec, 3.4x faster than H200
- NVIDIA H200 (FP8): ~12,000 output tokens/sec
- NVIDIA H100 (int4): Variable, typically 3,000-8,000 tokens/sec
- Cost per token: 2.6x better on B200 vs H200
These throughput numbers apply to output generation. Input processing (ingesting the 10M context) requires separate consideration and varies based on context size and content type.
Latency considerations: Time-to-first-token increases linearly with context size. Processing a full 10M token context before generating the first output token can take 30-90 seconds depending on hardware. For interactive applications, this latency may be prohibitive.
Choose Scout for batch processing applications (overnight document analysis, scheduled report generation) rather than real-time interactive use cases when utilizing contexts above 1M tokens.
Coding Performance and Instruction Following
Independent testing reveals important limitations in Scout’s coding capabilities, particularly for complex tasks requiring consistency across massive contexts.[5]
Observed performance patterns:
- Strong performance on code explanation and documentation tasks
- Good results for bug identification and analysis
- Variable results on code generation requiring cross-file consistency
- Difficulty maintaining specific formatting or style constraints across full context
- Tendency to “forget” earlier instructions when context exceeds ~2M tokens
The model performs better as a coding assistant for analysis and understanding than as a code generation tool for large-scale refactoring or new feature development spanning entire codebases.
Common mistake: Organizations expect Scout to generate production-ready code across entire applications by ingesting complete codebases. In practice, Scout works better for targeted analysis, documentation, and understanding tasks rather than wholesale code generation.
Multimodal and Multilingual Capabilities
Scout’s native multimodal support enables image and text understanding within the same 10M context window. The model processes documents containing images, diagrams, charts, and text without separate preprocessing.[2]
Supported languages: Scout handles 12 languages natively, though performance varies by language. English, Spanish, French, German, and Italian show strongest results. For organizations requiring multilingual AI capabilities, testing on representative content in target languages is essential.
The multimodal capabilities work well for:
- Financial reports with embedded charts and graphs
- Technical documentation with diagrams
- Legal documents with scanned signatures and exhibits
- Research papers with figures and tables
Image understanding quality decreases when images appear in the earlier portions of very long contexts (beyond ~5M tokens), suggesting similar attention bias issues that affect text retrieval.
How Should Organizations Implement Scout for Production Workloads?
Successful Scout deployment requires careful planning around data preparation, infrastructure sizing, and application architecture. Organizations that treat Scout as a drop-in replacement for existing models often encounter unexpected challenges.

Data Preparation and Context Optimization
Even with a 10M token context window, thoughtful data preparation improves output quality and reduces costs.
Data preparation best practices:
- Structure documents hierarchically with clear section markers and metadata
- Place the most relevant information in the latter half of the context (Scout shows recency bias)
- Remove redundant content even though the context window can accommodate it
- Include explicit cross-references when relationships between distant sections matter
- Test with progressively larger contexts rather than immediately using the full 10M window
Organizations often find that 1-3M token contexts provide the optimal balance of performance, cost, and output quality for most applications. Reserve the full 10M capacity for use cases that genuinely require it.
Monitoring and Quality Assurance
Production Scout deployments require robust monitoring to detect quality degradation and performance issues.
Critical monitoring metrics:
- Time-to-first-token by context size
- Output tokens per second
- Memory utilization and GPU saturation
- Context window utilization distribution
- Output quality scores on representative test cases
- Cost per inference by context size tier
Implement automated quality checks on Scout outputs, particularly for applications where the model must extract specific information or follow precise formatting requirements. The model’s variable performance across the full context window means that outputs require validation.
Quality assurance approach:
- Maintain a test suite of representative documents with known correct answers
- Run automated quality checks on each model version or configuration change
- Implement human review for high-stakes applications (legal, financial, medical)
- Track quality metrics over time to detect degradation
- Establish fallback procedures when quality thresholds aren’t met
Integration Patterns and Architecture
Scout integrates into enterprise architectures through several common patterns, each with different tradeoffs.
Direct inference pattern:
- Application sends complete document set directly to Scout
- Model processes and returns results synchronously
- Best for: Batch processing, scheduled analysis, non-interactive workflows
Hybrid RAG pattern:
- Initial retrieval narrows document set to relevant subset
- Scout processes the filtered documents with full context
- Best for: Large document collections where only portions are relevant
Progressive context pattern:
- Start with smaller context for initial analysis
- Expand context based on initial results
- Best for: Exploratory analysis where full context may not be necessary
Choose the direct inference pattern when you know the complete relevant document set in advance and it fits within Scout’s context window. The hybrid approach works better for massive document collections (100K+ documents) where retrieval narrows the scope before deep analysis.
Organizations building production AI systems should evaluate Scout alongside other long-context options using platforms like MULTIBLY, which enables side-by-side comparison of 300+ AI models on actual workloads before committing to infrastructure investment.
What Are the Cost Considerations for Scout Deployment?
Understanding the total cost of ownership for Scout deployment helps organizations make informed decisions between self-hosted and managed options.
Self-Hosted Infrastructure Costs
Self-hosted Scout deployment requires upfront hardware investment but eliminates ongoing per-token fees.
Hardware investment breakdown:
- Single H100 GPU: ~$20,000-$30,000 (int4 quantized deployment)
- H200 GPU: ~$35,000-$45,000 (improved performance)
- B200 GPU: ~$50,000-$70,000 (maximum performance)
- Supporting infrastructure: $10,000-$25,000 (servers, networking, cooling)
Add operational costs for power, cooling, and maintenance. A single H100 deployment typically consumes 700W under load, translating to ~$500-$1,000 monthly power costs depending on electricity rates and utilization.
Break-even analysis:
Assuming $0.50 per million tokens for comparable proprietary API services:
- 100M tokens/month: 20-month break-even on H100 investment
- 500M tokens/month: 4-month break-even
- 1B+ tokens/month: 2-month break-even
Organizations processing high volumes of long-context inference reach break-even quickly. Low-volume users should consider managed options.
Managed Platform Costs
Cloudflare Workers AI and AWS SageMaker offer managed Scout deployment with different pricing models.
Cloudflare Workers AI pricing:
- Pay-per-request model
- No infrastructure management overhead
- Costs scale linearly with usage
- Currently limited to 131K context window
AWS SageMaker pricing:
- Instance-hour based pricing
- Costs depend on instance type (GPU configuration)
- More predictable costs for steady workloads
- Full 10M context window support
Choose managed platforms if your monthly inference volume is below 50-100M tokens or if you lack in-house GPU infrastructure expertise. The convenience and reduced operational burden justify the higher per-token costs for many organizations.
Hidden Costs and Considerations
Several less obvious cost factors affect total ownership:
Data transfer and storage:
- Transferring large document sets to inference endpoints
- Storing processed results and intermediate outputs
- Egress fees for cloud deployments
Development and integration:
- Engineering time for initial integration
- Ongoing maintenance and optimization
- Testing and quality assurance infrastructure
Opportunity costs:
- Time to production for self-hosted vs managed
- Flexibility to switch providers or models
- Lock-in risks with proprietary infrastructure
For comprehensive cost analysis across open and proprietary models, organizations should review total cost of ownership comparisons that account for these hidden factors.
What’s Next for Long-Context Open-Source Models?
Llama 4 Scout’s 10M token context window establishes a new baseline for open-source long-context capabilities, but the competitive landscape continues evolving rapidly.
Emerging Alternatives and Competition
Several open-source projects are developing competing long-context models:
Notable developments:
- Kimi Linear: Moonshot AI’s efficient attention mechanism for 1M+ contexts with improved computational efficiency
- GLM-4.5: Z AI’s 355B MoE model with extended context capabilities
- DeepSeek R1: China’s reasoning-focused model with competitive long-context performance
These alternatives offer different tradeoffs in model size, efficiency, and specialized capabilities. Organizations should evaluate multiple options rather than assuming Scout is the default choice for all long-context applications.
For teams tracking the broader open-source AI landscape, the rapid pace of innovation means regular reassessment of model choices.
Future Optimization Opportunities
Several technical improvements could enhance Scout’s practical utility:
Likely near-term developments:
- Improved attention mechanisms that reduce recency bias
- Better instruction following across full context windows
- Optimized inference for reduced time-to-first-token
- Enhanced multimodal capabilities with more image formats
- Specialized fine-tuned versions for specific industries
Organizations planning long-term Scout deployments should architect systems with flexibility to incorporate these improvements as they become available.
Strategic Implications for Enterprise AI
Scout’s capabilities signal important shifts in enterprise AI strategy:
Key strategic considerations:
- Long-context processing is no longer a proprietary advantage – open-source models now match or exceed closed alternatives
- Infrastructure costs favor high-volume self-hosting – economics shift dramatically at scale
- Application architecture can simplify – many RAG systems can be replaced with direct long-context processing
- Data privacy and control become realistic – self-hosted deployment is now viable for sensitive workloads
Organizations building AI strategies for 2026 and beyond should account for continued rapid improvement in open-source capabilities. The gap between proprietary and open models continues narrowing across most dimensions.
Frequently Asked Questions
What is Llama 4 Scout’s maximum context window size?
Llama 4 Scout supports a 10 million token context window, approximately 7.5 million words or 15,000 pages of text. This represents a 78x increase from Llama 3’s 128K token limit and currently exceeds all proprietary alternatives including GPT-4 and Claude.
Can Scout run on a single GPU?
Yes, Scout can run on a single NVIDIA H100 GPU when quantized to int4 precision. Meta optimized the model specifically for this configuration, making deployment accessible at approximately $20,000-$30,000 in hardware costs. Performance is lower than multi-GPU or higher precision configurations but sufficient for many document analysis applications.
How does Scout’s performance compare to GPT-4 for document analysis?
Scout excels at processing massive document collections that exceed GPT-4’s context limits, but GPT-4 typically produces higher quality outputs for complex reasoning tasks within its 128K context window. Choose Scout when context size is the primary constraint and GPT-4 when output quality is paramount within smaller contexts.
What are the main limitations of the 10M context window?
The primary limitations include increased latency (30-90 seconds time-to-first-token for full contexts), attention bias toward recent content, variable instruction following across the full window, and significant computational costs. The model also struggles with tasks requiring equal attention to information distributed randomly across the entire context.
Is Scout suitable for real-time applications?
Scout works better for batch processing than real-time interactive applications when using large contexts (above 1M tokens). The time-to-first-token latency makes it impractical for conversational interfaces or applications requiring sub-second response times. Consider smaller context windows or alternative models for real-time use cases.
How much does it cost to run Scout compared to proprietary APIs?
Self-hosted Scout deployment has high upfront costs ($20,000-$70,000 for hardware) but zero per-token fees. Break-even versus proprietary APIs typically occurs at 50-100M tokens monthly. Below this threshold, managed services like Cloudflare Workers AI or AWS SageMaker offer better economics despite higher per-token costs.
What file formats and document types does Scout support?
Scout processes text and images natively, supporting documents in formats that can be converted to text and image representations. This includes PDFs, Word documents, code files, HTML, and scanned documents (via OCR preprocessing). The model handles embedded images, charts, diagrams, and tables within the 10M token context.
Can Scout be fine-tuned for specific industries or use cases?
Yes, Scout supports fine-tuning for domain-specific applications. Organizations can fine-tune on proprietary datasets for legal, medical, financial, or technical domains. The open-source nature enables complete customization, though fine-tuning requires significant computational resources and domain expertise.
How does Scout handle multiple languages within the same context?
Scout processes 12 languages natively and can handle multilingual documents within a single context window. The model maintains context across language boundaries, enabling applications like multilingual document analysis and cross-language information retrieval. Performance is strongest in English, Spanish, French, German, and Italian.
What monitoring and observability tools work with Scout deployments?
Scout integrates with standard ML monitoring tools including Prometheus, Grafana, and cloud-native observability platforms. Key metrics to monitor include GPU utilization, memory usage, time-to-first-token, throughput, and output quality scores. Organizations should implement custom quality checks specific to their use cases.
How frequently is Scout updated and how do updates affect deployments?
Meta releases Llama model updates periodically, typically every 6-12 months for major versions. Updates require redeploying model weights and may necessitate infrastructure changes. Organizations should plan for testing periods before production deployment of new versions and maintain rollback capabilities.
What are the data privacy implications of using Scout?
Self-hosted Scout deployments provide complete data privacy since inference occurs on organization-controlled infrastructure. Managed deployments (Cloudflare, AWS) follow the respective platform’s data handling policies. For sensitive workloads (legal, medical, financial), self-hosted deployment eliminates data sharing with third parties.
Conclusion
Llama 4 Scout’s 10M token context window represents a fundamental shift in open-source AI capabilities for massive document processing. Organizations can now handle entire document collections, codebases, and multi-year reports without the architectural complexity of chunking, embedding, and retrieval systems that previously defined enterprise AI deployments.
The model’s Mixture of Experts architecture with 109B total parameters and 17B active parameters delivers this capability efficiently enough to run on a single NVIDIA H100 GPU when quantized. This accessibility democratizes long-context AI for organizations that previously couldn’t justify the infrastructure investment for proprietary alternatives.
However, Scout is not a universal solution. The model shows clear limitations in instruction following across the full context window, exhibits attention bias toward recent content, and struggles with real-time interactive applications due to latency. Organizations should carefully evaluate whether their specific use cases align with Scout’s strengths in batch document analysis, codebase understanding, and comprehensive information extraction.
Key decision criteria for Scout adoption:
- Choose Scout if you process high volumes of long documents that exceed 128K tokens
- Choose Scout if data privacy requirements prevent cloud API usage
- Choose Scout if monthly inference volume exceeds 50-100M tokens (self-hosted economics favor high volume)
- Choose proprietary alternatives if you need the highest quality reasoning within smaller contexts
- Choose managed Scout deployment (Cloudflare, AWS) if you need rapid deployment without infrastructure investment
The competitive landscape for long-context models continues evolving rapidly. Organizations should architect AI systems with flexibility to incorporate improvements from Scout updates, competing open-source models like GLM-4.5 and Kimi Linear, and emerging proprietary options.
For teams evaluating multiple AI models across different use cases, platforms like MULTIBLY enable side-by-side comparison of Scout against 300+ alternatives on actual workloads before committing to infrastructure investment. This testing-first approach reduces deployment risk and ensures optimal model selection for specific enterprise requirements.
Scout’s release confirms that open-source models now compete effectively with proprietary alternatives on context window size—the next frontier is closing remaining gaps in output quality, reasoning capability, and specialized task performance across those extended contexts.
References
[1] Meta Llama 4 Is Now Available On Workers Ai – https://blog.cloudflare.com/meta-llama-4-is-now-available-on-workers-ai/
[2] Llama 4 Multimodal Intelligence – https://ai.meta.com/blog/llama-4-multimodal-intelligence/
[3] Nvidia Accelerates Inference On Meta Llama 4 Scout And Maverick – https://developer.nvidia.com/blog/nvidia-accelerates-inference-on-meta-llama-4-scout-and-maverick/
[4] Llama 4 Family Of Models From Meta Are Now Available In Sagemaker Jumpstart – https://aws.amazon.com/blogs/machine-learning/llama-4-family-of-models-from-meta-are-now-available-in-sagemaker-jumpstart/
[5] Llama 4 10m Context Coding Decent Follow Up 426n – https://dev.to/maximsaplin/llama-4-10m-context-coding-decent-follow-up-426n
Our Fact Checking Process
We prioritize accuracy and integrity in our content. Here's how we maintain high standards:
- Expert Review: All articles are reviewed by subject matter experts.
- Source Validation: Information is backed by credible, up-to-date sources.
- Transparency: We clearly cite references and disclose potential conflicts.
Our Review Board
Our content is carefully reviewed by experienced professionals to ensure accuracy and relevance.
- Qualified Experts: Each article is assessed by specialists with field-specific knowledge.
- Up-to-date Insights: We incorporate the latest research, trends, and standards.
- Commitment to Quality: Reviewers ensure clarity, correctness, and completeness.
Look for the expert-reviewed label to read content you can trust.



