
- Key Takeaways
- Quick Answer
- What Makes Kimi K2's 256K Context Window Different from Traditional Models?
- How Does Long-Context Processing Impact Legal Document Analysis?
- What Are the Technical Advantages of Kimi K2's Architecture for Document Processing?
- How Do Medical and Financial Institutions Benefit from 256K Context Windows?
- What Are the Cost and Performance Tradeoffs in Production Deployments?
- How Do Traditional Chunking Approaches Compare to Single-Pass Long-Context Processing?
- What Are the Deployment Considerations and Best Practices for Long-Context LLMs?
- FAQ
- Conclusion
- References
Key Takeaways
Kimi K2.5’s 256K context window processes approximately 190,000 words in a single session, eliminating document chunking for legal contracts (500+ pages), medical records (decades of history), and financial reports (complete annual filings with exhibits)
The model costs $0.60/$3.00 per 1K input/output tokens, making it 9x cheaper than Claude Opus 4.5 while maintaining superior performance on document-heavy tasks, saving enterprises $30,000-$350,000 annually on typical processing volumes
Native INT4 quantization delivers 2x inference speed improvements without accuracy loss, breaking the traditional speed-memory tradeoff that plagued earlier long-context models
Mixture-of-Experts architecture activates only 32 billion of 1 trillion total parameters per token, reducing computational costs by 10-30x compared to dense models while maintaining performance
The model sustains 50+ conversation rounds and 200-300 sequential tool calls, enabling autonomous document analysis workflows that traditional models cannot maintain without degradation
Native vision processing through 400M-parameter MoonViT encoder handles scanned documents, financial charts, medical imaging, and design mockups without converting visual content to text
Cross-reference preservation is the killer application for legal, medical, and financial document processing where traditional chunking destroys contextual relationships between distant sections
Production deployments require intelligent routing strategies that direct complex multi-document queries to K2.5 while using faster traditional models for simple single-document tasks
Security and compliance considerations remain critical for regulated industries, requiring evaluation of data residency, encryption, and audit logging capabilities before production deployment
The economic case for migration from traditional models is strongest when organizations process 10+ million tokens monthly on document-heavy workflows where context completeness prevents errors
Quick Answer

Long-Context LLMs in Production, particularly Kimi K2’s 256K window versus traditional models for document processing, represents a fundamental shift in how enterprises handle complex document analysis. Kimi K2.5’s 256K token capacity processes entire codebases (200,000 lines), legal contracts (500+ pages), or multi-document research collections in a single session without chunking—something traditional 32K-128K models cannot achieve. The practical advantage shows most clearly in legal contract analysis, medical record reviews, and financial due diligence where maintaining cross-document context prevents the fragmentation errors common in chunked approaches.
What Makes Kimi K2’s 256K Context Window Different from Traditional Models?
Kimi K2.5’s 256K context window fundamentally changes document processing by holding approximately 190,000 words in active memory simultaneously[1]. Traditional models with 32K-128K windows require document chunking, which breaks contextual relationships and forces applications to implement complex orchestration logic.
The key difference is architectural, not just numerical. While competitors like Claude Opus 4.5 offer 200K tokens and GPT-5.2 provides 128K, Kimi K2.5 combines its 256K capacity with a Mixture-of-Experts (MoE) design that activates only 32 billion of its 1 trillion total parameters per token[1]. This sparse activation pattern means the model processes long documents without the proportional computational cost increase that dense models face.
Practical capacity comparisons:
- Legal contracts: Process 500+ page merger agreements in one session versus 4-8 chunked sessions with traditional models
- Medical records: Analyze complete patient histories spanning decades without losing temporal context
- Financial reports: Review entire annual reports with footnotes, exhibits, and cross-references intact
- Codebase analysis: Load 200,000 lines of code for architectural reviews or refactoring tasks[2]
In practice, the 256K window is 28% larger than Claude Opus 4.5’s 200K tokens and exactly double GPT-5.2’s 128K capacity[2]. But the real advantage emerges in multi-document scenarios where traditional models lose cross-reference accuracy after chunking.
Common mistake: Teams often assume longer context windows automatically mean slower inference. Kimi K2.5’s native INT4 quantization through Quantization-Aware Training (QAT) actually achieves 2x inference speed improvements compared to traditional FP16 implementations[3], with reported latency of 8-25 seconds in Thinking Mode for complex reasoning tasks[4].
For most enterprise teams processing legal, medical, or financial documents, choose Kimi K2.5 when cross-document references, temporal context, or complete codebase understanding matters more than raw speed. Choose traditional shorter-window models when processing independent documents that don’t require cross-referencing.
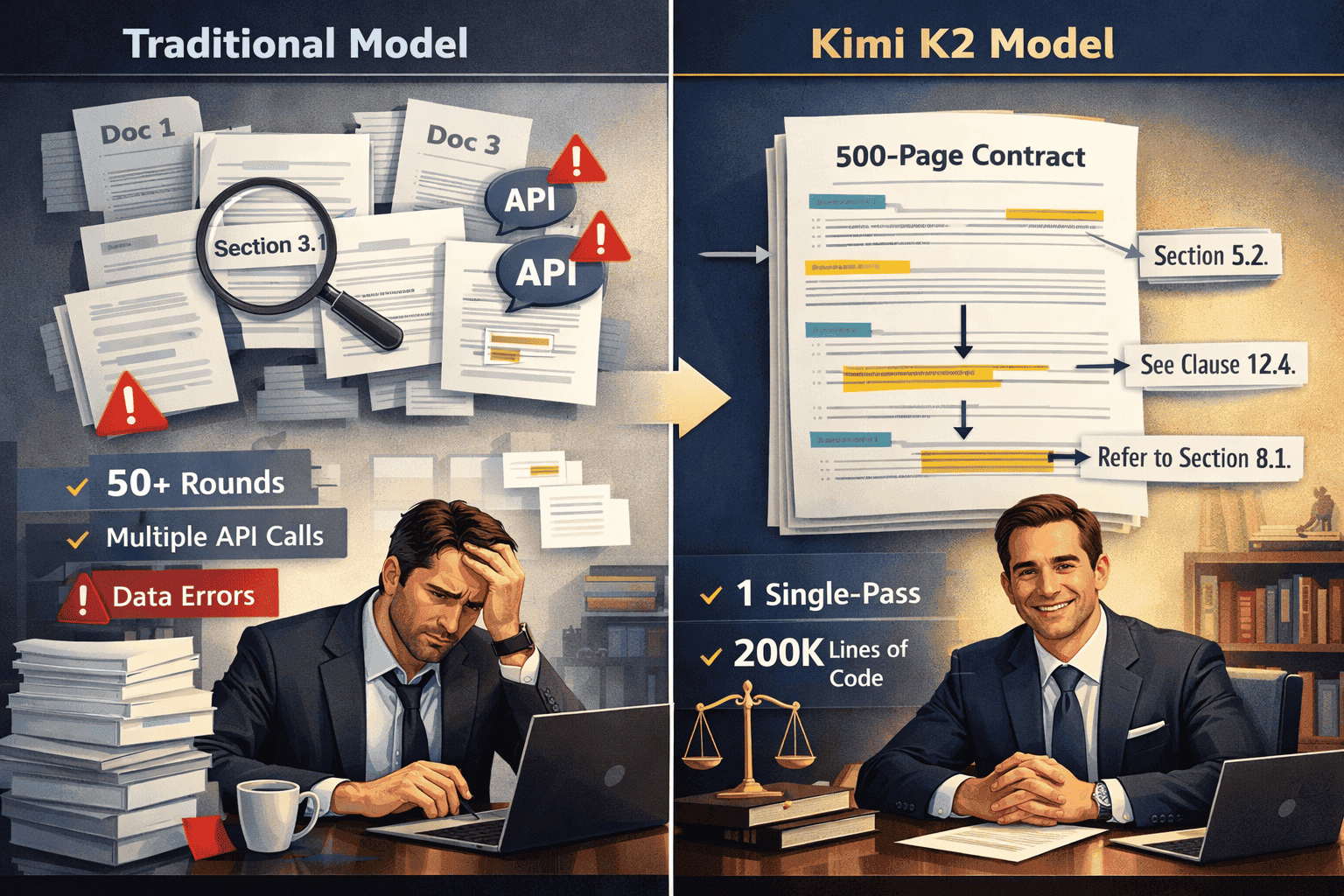
How Does Long-Context Processing Impact Legal Document Analysis?
Legal document analysis sees the most dramatic improvement from long-context LLMs because contracts, merger agreements, and regulatory filings contain extensive cross-references that traditional chunking destroys. A typical merger agreement spans 300-800 pages with hundreds of internal references to definitions, exhibits, and conditional clauses.
Traditional model workflow (32K-128K context):
- Split 500-page contract into 8-12 chunks
- Process each chunk independently
- Implement retrieval system to find referenced sections
- Manually verify cross-references weren’t missed
- Risk missing conditional dependencies between distant sections
Kimi K2.5 workflow (256K context):
- Load entire contract in single session
- Query any section with full document context
- Automatically trace cross-references across all pages
- Maintain 50+ rounds of deep discussion about specific clauses[2]
The 256K window holds approximately 190,000 words, sufficient for most legal documents short of massive regulatory compilations[1]. This means lawyers can ask questions like “What are all the termination conditions and how do they interact with the indemnification clauses?” without the model losing track of dependencies 400 pages apart.
Real-world legal applications:
- Due diligence reviews: Analyze 20-30 contracts simultaneously to identify inconsistent terms across vendor agreements
- Regulatory compliance: Cross-reference company policies against 200+ page regulatory frameworks
- Litigation support: Review discovery documents while maintaining temporal and contextual relationships
- Contract drafting: Reference entire precedent libraries when generating new agreements
Edge case consideration: Even 256K tokens have limits. For truly massive document sets (1,000+ page regulatory compilations), the best approach combines Kimi K2.5’s long context with strategic document selection rather than attempting to load everything simultaneously.
Choose Kimi K2.5 for legal work when cross-document consistency, clause interaction analysis, or multi-contract comparison matters. The 9x cost advantage over Claude Opus 4.5 ($0.60/$3.00 vs $5.00/$15.00 per 1K tokens)[2] makes it economically viable for routine contract reviews that would be prohibitively expensive with traditional models.
What Are the Technical Advantages of Kimi K2’s Architecture for Document Processing?
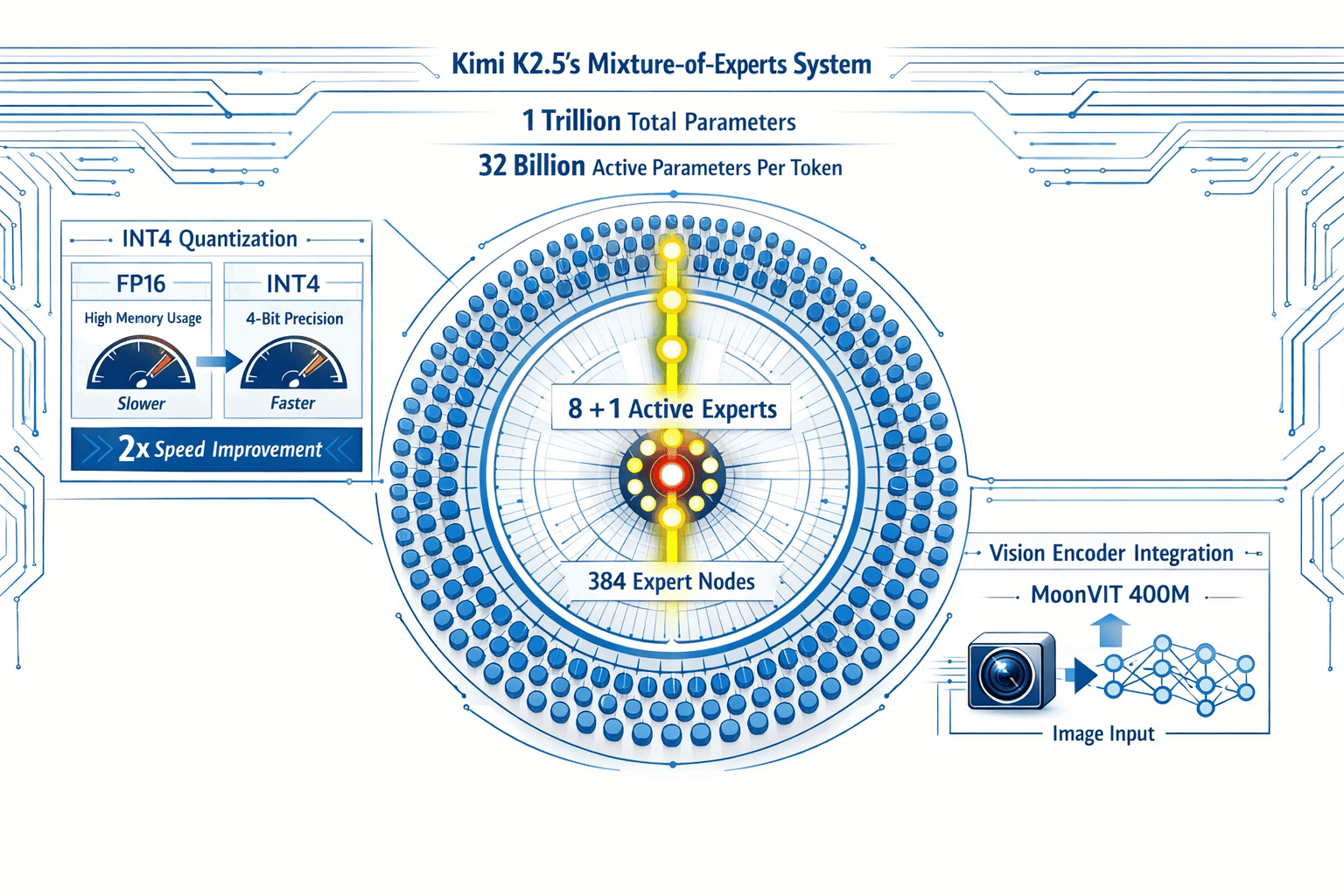
Kimi K2.5’s technical architecture solves three critical problems that plague traditional long-context models: computational cost, inference speed, and context degradation over extended sessions.
Mixture-of-Experts Efficiency
The model uses 384 total experts with an 8+1 selection mechanism per token[1]. This means only 32 billion parameters activate for each token despite the 1 trillion total parameter count. Traditional dense models must activate all parameters regardless of input complexity, making them computationally expensive for long documents.
Computational advantage: Processing a 100,000-token legal document with K2.5 activates the same 32 billion parameters throughout, while a comparable dense model activates 10-30x more parameters for the same task.
Native INT4 Quantization
K2.5 implements native INT4 quantization through Quantization-Aware Training rather than post-training quantization[3]. This approach trains the model to operate efficiently at lower precision from the start, avoiding the performance degradation common in retrofitted quantization.
Speed improvement: 2x inference speed compared to FP16 implementations without accuracy loss[3]. For document processing workflows running hundreds of queries daily, this doubles throughput without additional hardware.
Proprietary Vision Integration
The 400M-parameter MoonViT native vision encoder processes images and videos directly rather than converting them to text descriptions[4]. For document processing, this means K2.5 can analyze scanned contracts, financial charts, medical imaging, and architectural diagrams without losing visual information.
Practical vision applications:
- Scanned contracts: Process PDFs with embedded images, signatures, and formatting intact
- Financial reports: Analyze charts, tables, and graphs alongside text
- Medical records: Review imaging results in context with clinical notes
- UI/UX design: Convert design mockups to code with 86.6% accuracy on VideoMMMU benchmarks[4]
Extended Agentic Capability
K2.5 maintains stable tool-use across 200-300 sequential tool calls[1][3], enabling autonomous document analysis workflows. Traditional models degrade after 20-50 tool calls, requiring human intervention to reset context.
Agentic workflow example (financial due diligence):
- Load target company’s annual reports (years 1-5)
- Extract revenue figures and calculate growth rates
- Cross-reference footnotes for accounting policy changes
- Search external databases for industry comparisons
- Generate summary report with sourced citations
- Answer follow-up questions across all documents
The model achieved 78.4% on BrowseComp in swarm mode[3], demonstrating strong performance in complex multi-step reasoning with parallel information gathering.
Decision rule: Choose Kimi K2.5’s architecture when document processing requires sustained autonomous operation, visual element analysis, or cost-efficient scaling. Choose traditional models when single-document, text-only processing with human oversight is sufficient.
Platforms like MULTIBLY allow teams to compare Kimi K2.5’s performance against 300+ other models side-by-side, making it easier to validate these architectural advantages for specific document processing workflows.
How Do Medical and Financial Institutions Benefit from 256K Context Windows?
Medical and financial institutions handle documents where context loss creates compliance risks, diagnostic errors, or regulatory violations. The 256K context window addresses these risks by maintaining complete document context throughout analysis sessions.
Medical Record Analysis
Patient records accumulate over decades, creating complex temporal relationships between diagnoses, treatments, and outcomes. Traditional models chunk these records, losing the ability to trace how a medication prescribed 10 years ago interacts with current symptoms.
Medical use cases for long-context processing:
- Longitudinal patient analysis: Review complete medical histories (20+ years) to identify patterns in chronic disease progression
- Clinical trial matching: Cross-reference patient records against 100+ page trial protocols to identify eligible candidates
- Diagnostic support: Analyze symptoms, lab results, imaging reports, and family history simultaneously
- Treatment planning: Consider all contraindications, drug interactions, and prior treatment responses in context
Compliance advantage: Healthcare regulations like HIPAA require complete audit trails. Processing entire patient records in a single session reduces the risk of missing critical information that chunked processing might fragment.
Common mistake: Assuming longer context automatically improves diagnostic accuracy. The model’s reasoning capability matters as much as context length. Kimi K2.5’s Thinking Mode with 8-25 second latency[4] provides the deliberative reasoning medical applications require, but teams should validate outputs against established clinical protocols.
Financial Document Processing
Financial institutions process documents where cross-references, footnotes, and exhibits contain material information that traditional chunking obscures.
Financial use cases for 256K windows:
- Annual report analysis: Process complete 10-K filings (200+ pages) including footnotes, MD&A sections, and risk factors
- Credit risk assessment: Analyze borrower financials, industry reports, and economic indicators simultaneously
- Regulatory compliance: Cross-reference internal policies against evolving regulatory frameworks (Dodd-Frank, Basel III)
- M&A due diligence: Review target company documents while maintaining context across financial statements, contracts, and operational data
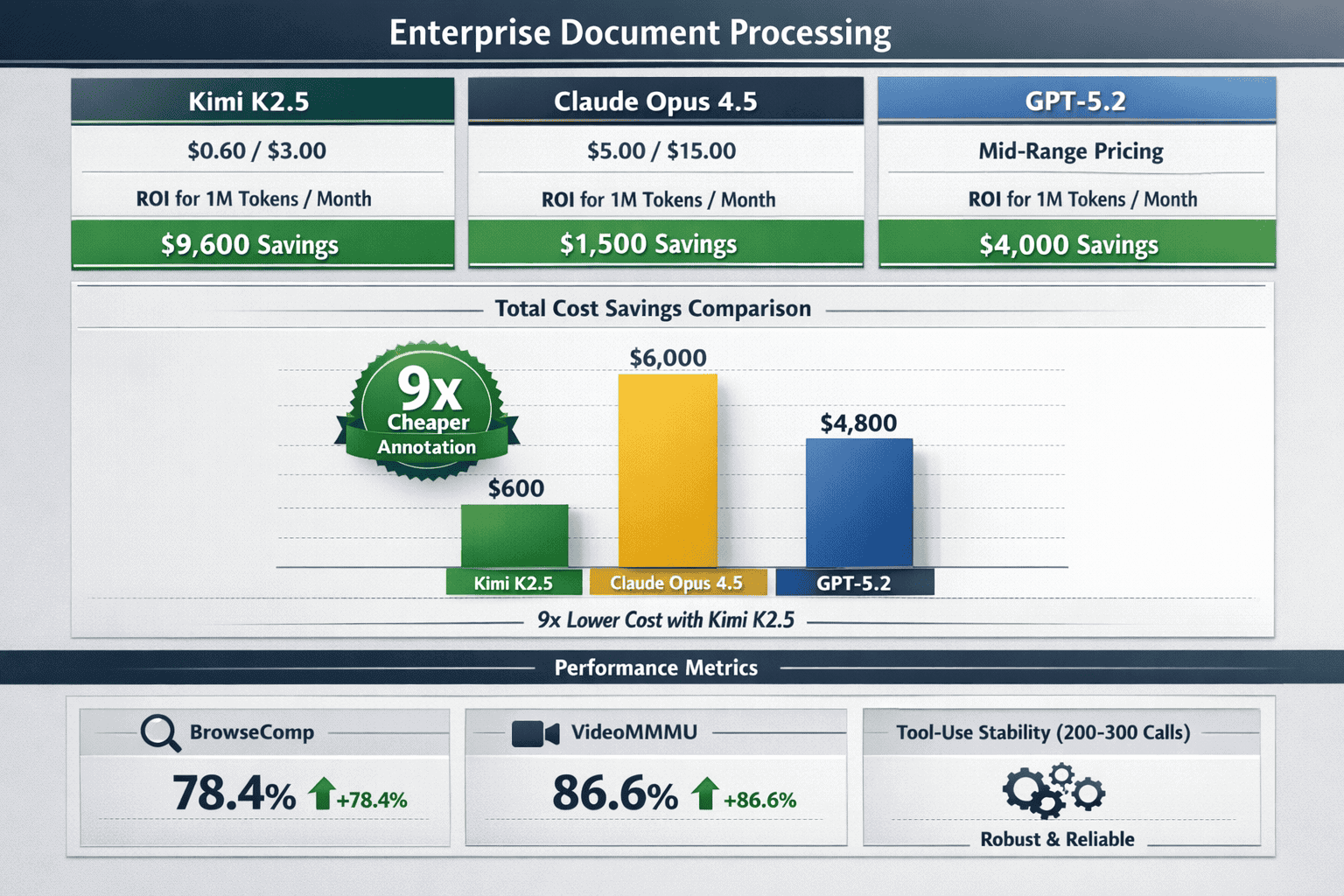
Cost advantage for financial institutions: At $0.60/$3.00 per 1K input/output tokens, processing 1 million tokens monthly costs $600-$3,000 with Kimi K2.5 versus $5,000-$15,000 with Claude Opus 4.5[2]. For institutions processing thousands of documents monthly, this 9x cost difference justifies migration from traditional models.
Regulatory and Compliance Applications
Both medical and financial institutions face regulatory requirements that demand complete document context. Missing a cross-reference in a 500-page compliance filing can trigger regulatory violations.
Regulatory processing advantages:
- Policy cross-referencing: Verify internal policies comply with external regulations across hundreds of pages
- Audit trail generation: Document how conclusions were reached with full source context
- Change impact analysis: Assess how regulatory updates affect existing procedures across entire policy libraries
- Risk identification: Spot inconsistencies between operational procedures and regulatory requirements
Edge case: Highly sensitive documents may require on-premise deployment. While Kimi K2.5 is primarily available via API, institutions should evaluate deployment options based on data residency requirements and regulatory constraints.
For most medical and financial teams, choose Kimi K2.5 when regulatory compliance, cross-document verification, or longitudinal analysis justifies the investment in long-context infrastructure. The model’s ability to sustain 50+ conversation rounds[2] means analysts can conduct deep investigations without losing context mid-session.
Organizations exploring context windows as a competitive advantage should evaluate how K2.5’s 256K capacity addresses specific compliance and analysis workflows in their industry.
What Are the Cost and Performance Tradeoffs in Production Deployments?
Production deployments of long-context LLMs require balancing three factors: token costs, inference latency, and accuracy requirements. Kimi K2.5’s economics fundamentally change this calculus compared to traditional models.
Token Cost Analysis
Kimi K2.5 pricing: $0.60 per 1K input tokens, $3.00 per 1K output tokens[2]
Competitor pricing comparisons:
- Claude Opus 4.5: $5.00/$15.00 per 1K tokens (9x more expensive)[2]
- GPT-5.2: Approximately $3.00/$8.00 per 1K tokens (5x more expensive)
- Traditional models (GPT-4 class): $2.50/$7.50 per 1K tokens (4x more expensive)
Monthly cost scenarios (1 million input tokens, 200K output tokens):
| Model | Input Cost | Output Cost | Total Monthly |
|---|---|---|---|
| Kimi K2.5 | $600 | $600 | $1,200 |
| Claude Opus 4.5 | $5,000 | $3,000 | $8,000 |
| GPT-5.2 | $3,000 | $1,600 | $4,600 |
| Traditional (GPT-4) | $2,500 | $1,500 | $4,000 |
For enterprise teams processing 10-50 million tokens monthly (typical for legal, medical, or financial document analysis), Kimi K2.5 saves $30,000-$350,000 annually compared to Claude Opus 4.5.
Inference Speed Considerations
Long-context models traditionally sacrifice speed for capacity. Kimi K2.5’s native INT4 quantization breaks this pattern, achieving 2x speed improvements over FP16 implementations[3].
Reported latency benchmarks:
- Standard queries: 2-5 seconds for typical document Q&A
- Thinking Mode: 8-25 seconds for complex reasoning tasks[4]
- Agentic workflows: Stable performance across 200-300 sequential tool calls[1][3]
Decision framework for speed vs. context tradeoffs:
- Choose Kimi K2.5 when document completeness matters more than sub-second response times (legal analysis, compliance reviews, research synthesis)
- Choose traditional faster models when processing independent documents with simple queries (customer support, basic classification, single-document summarization)
- Choose hybrid approaches when workflows mix simple and complex tasks (use faster models for routing, K2.5 for deep analysis)
Accuracy and Reliability Metrics
Production deployments require consistent performance across diverse document types. Kimi K2.5’s benchmark results demonstrate strong generalization:
Performance benchmarks:
- BrowseComp (swarm mode): 78.4% accuracy on complex multi-step reasoning[3]
- VideoMMMU: 86.6% accuracy on video reasoning tasks, surpassing GPT-5.2 and Claude Opus 4.5[4]
- Code understanding: Successfully processes 200,000 lines of code in single sessions[2]
- Sustained reasoning: Maintains accuracy across 50+ conversation rounds[2]
Common deployment mistake: Teams often over-provision context capacity. A 256K window doesn’t mean every task should use 256K tokens. For optimal cost-performance, use K2.5’s full capacity only when documents genuinely require it, and route simpler tasks to more economical models.
Scaling Considerations
Production deployments must account for concurrent users, peak load handling, and failover requirements.
Scaling best practices:
- Implement intelligent routing: Direct complex multi-document queries to K2.5, simple single-document tasks to faster models
- Cache common queries: Legal and financial institutions often process similar document types repeatedly
- Batch processing for non-urgent tasks: Overnight processing of due diligence documents reduces peak load costs
- Monitor token usage patterns: Track which workflows actually benefit from 256K context vs. those that could use shorter windows
Edge case: Teams processing extremely high volumes (100M+ tokens monthly) should negotiate enterprise pricing directly with Moonshot AI, as published API rates may not reflect volume discounts available for large-scale deployments.
For teams evaluating whether to deploy Kimi K2.5 in production, the decision typically hinges on whether document processing workflows justify the architectural investment. Organizations can use platforms like MULTIBLY to test K2.5 against traditional models on representative document sets before committing to production deployment.
The open-source AI surge has made models like Kimi K2.5 increasingly accessible, reducing the barrier to entry for enterprises that previously relied exclusively on proprietary solutions.
How Do Traditional Chunking Approaches Compare to Single-Pass Long-Context Processing?
Traditional chunking approaches dominated document processing before long-context models became viable. Understanding when chunking still makes sense versus when single-pass processing with Kimi K2.5 delivers better results helps teams make informed architecture decisions.
Traditional Chunking Workflow
Standard chunking process:
- Split document into overlapping segments (typically 2K-8K tokens per chunk with 10-20% overlap)
- Process each chunk independently or with limited context from adjacent chunks
- Implement retrieval system (vector database) to find relevant chunks for queries
- Aggregate results across chunks, attempting to reconstruct cross-references
- Handle edge cases where critical information spans chunk boundaries
Chunking advantages:
- Works with any model regardless of context window size
- Enables parallel processing of chunks for faster throughput
- Reduces memory requirements for model inference
- Allows selective processing of relevant sections only
Chunking disadvantages:
- Breaks contextual relationships between distant sections
- Requires complex orchestration logic to manage chunk dependencies
- Introduces retrieval accuracy as a failure point (missed chunks = incomplete answers)
- Struggles with queries requiring cross-document synthesis
- Adds latency from retrieval operations before LLM processing
Single-Pass Long-Context Processing
Kimi K2.5’s 256K window enables single-pass processing where the entire document loads into context once, eliminating retrieval orchestration.
Single-pass workflow:
- Load complete document (up to 190,000 words) in single API call
- Query any section with full document context available
- Maintain conversation history across 50+ rounds of questions[2]
- Automatically trace cross-references without explicit retrieval
Single-pass advantages:
- Preserves all contextual relationships across entire document
- Eliminates retrieval accuracy as failure point
- Simplifies application architecture (no vector database required)
- Enables queries that require cross-document synthesis
- Maintains context across extended conversation sessions
Single-pass disadvantages:
- Higher token costs when processing large documents (though K2.5’s pricing mitigates this)
- Requires documents fit within 256K token limit
- Cannot selectively process only relevant sections (processes entire document)
- May be overkill for simple queries on large documents
When to Use Each Approach
Choose traditional chunking when:
- Documents exceed 256K tokens (rare but occurs with massive regulatory compilations)
- Processing independent sections that don’t require cross-referencing (customer reviews, support tickets)
- Cost optimization matters more than context completeness for simple queries
- Infrastructure already invested in retrieval systems (RAG pipelines)
- Parallel processing speed matters more than contextual accuracy
Choose single-pass long-context (Kimi K2.5) when:
- Cross-document references are critical (legal contracts, medical records, financial reports)
- Queries require synthesis across entire document (compliance reviews, due diligence)
- Conversation depth matters (50+ rounds of iterative questioning)[2]
- Simplifying application architecture justifies slightly higher token costs
- Accuracy and completeness outweigh raw processing speed
Hybrid Approaches
Sophisticated production systems often combine both approaches, routing queries based on complexity.
Hybrid architecture example:
- Simple factual queries: Use chunking + retrieval for cost efficiency (“What is the contract termination date?”)
- Complex analytical queries: Use K2.5’s full context for accuracy (“How do the termination clauses interact with indemnification provisions across all exhibits?”)
- Exploratory analysis: Start with K2.5’s full context, then cache frequently accessed sections for follow-up queries
Implementation pattern:
<code>if query_requires_cross_references or query_complexity > threshold:
use_kimi_k2_full_context()
else:
use_traditional_chunking_retrieval()
</code>The decision framework should account for both technical requirements and economic factors. Kimi K2.5’s 9x cost advantage over Claude Opus 4.5[2] means single-pass processing is often more economical than teams expect, especially when factoring in the engineering complexity of maintaining retrieval systems.
Teams exploring alternatives to traditional chunking can compare approaches using MULTIBLY’s platform, which provides access to both long-context models like Kimi K2.5 and traditional models, enabling side-by-side evaluation on representative document sets.
What Are the Deployment Considerations and Best Practices for Long-Context LLMs?
Deploying long-context LLMs like Kimi K2.5 in production requires different architectural patterns than traditional models. Teams must account for token management, session handling, and cost optimization strategies specific to extended context windows.
Token Management Strategies
Pre-processing optimization:
- Remove unnecessary formatting: Strip excessive whitespace, redundant headers, and formatting artifacts that consume tokens without adding semantic value
- Intelligent section selection: For documents exceeding 256K tokens, prioritize sections most relevant to anticipated queries
- Document compression: Use extractive summarization for appendices and exhibits that provide context but aren’t query targets
Token counting accuracy: Always validate token counts before API calls. A 500-page PDF might contain 150,000-250,000 tokens depending on formatting, tables, and embedded content. Underestimating token counts leads to truncation errors; overestimating wastes preprocessing effort.
Monitoring and alerting:
- Track token usage per query to identify inefficient patterns
- Set alerts for queries approaching 256K limit
- Monitor cost per document type to optimize routing decisions
Session and State Management
Long-context models enable extended conversation sessions that traditional models cannot sustain. Kimi K2.5 maintains coherence across 50+ rounds of dialogue[2], but production systems must manage session state carefully.
Session best practices:
- Persist conversation history: Store full conversation context to enable session resumption after interruptions
- Implement conversation summarization: For sessions exceeding 50 rounds, periodically summarize earlier exchanges to free context space
- Handle context overflow gracefully: When adding new documents would exceed 256K, prompt users to start new session or remove earlier documents
- Track conversation depth: Monitor how many rounds typical workflows require to optimize session timeout settings
State management pattern:
<code>session_state = {
"documents_loaded": ["contract_v2.pdf", "exhibits_a_through_d.pdf"],
"total_tokens": 187000,
"conversation_rounds": 23,
"key_findings": ["termination_clause_analysis", "indemnification_scope"],
"remaining_capacity": 69000
}
</code>Error Handling and Fallback Strategies
Long-context processing introduces failure modes that don’t occur with traditional models.
Common failure scenarios:
- Token limit exceeded: Document + conversation history exceeds 256K
- Timeout on complex reasoning: Thinking Mode queries occasionally exceed typical latency windows
- Context degradation: Very long sessions may show reduced accuracy in later rounds
- API rate limits: High-volume deployments may hit concurrent request limits
Fallback strategies:
- Graceful degradation: If full document exceeds limit, automatically switch to chunking + retrieval
- Retry with reduced context: Remove older conversation rounds and retry failed queries
- Hybrid model routing: Fall back to faster traditional models for time-sensitive queries
- User notification: Clearly communicate when context limits require workflow changes
Cost Optimization Techniques
Even with K2.5’s favorable pricing, processing millions of tokens monthly requires cost optimization.
Cost reduction strategies:
- Intelligent caching: Cache processed documents and common queries to avoid reprocessing
- Batch processing: Group non-urgent queries to optimize API call efficiency
- Tiered routing: Use cheaper models for simple queries, K2.5 for complex analysis
- Token budgeting: Set per-user or per-project token limits to prevent runaway costs
- Compression techniques: Implement document compression for reference materials that don’t require full fidelity
ROI calculation framework:
<code>monthly_cost_savings = (traditional_model_cost - k2_cost) - engineering_overhead
time_savings_value = hours_saved_per_month * average_hourly_rate
accuracy_improvement_value = errors_prevented * cost_per_error
total_roi = monthly_cost_savings + time_savings_value + accuracy_improvement_value
</code>Security and Compliance Considerations
Document processing often involves sensitive information requiring security controls.
Security best practices:
- Data residency: Verify API endpoints comply with data residency requirements (GDPR, HIPAA)
- Encryption in transit: Ensure TLS 1.3 for all API communications
- Access controls: Implement role-based access to prevent unauthorized document processing
- Audit logging: Log all document processing activities for compliance audits
- Data retention: Establish clear policies for how long processed documents remain in conversation history
Compliance edge case: Highly regulated industries (healthcare, finance) may require on-premise deployment or private cloud instances. While Kimi K2.5 is primarily available via API, teams should discuss enterprise deployment options directly with Moonshot AI for sensitive use cases.
Integration Patterns
API integration best practices:
- Implement retry logic: Handle transient failures with exponential backoff
- Stream responses: Use streaming endpoints for long-form outputs to improve perceived latency
- Parallel processing: For multi-document workflows, process independent documents concurrently
- Health monitoring: Implement endpoint health checks and automatic failover
- Version pinning: Pin to specific model versions for production stability
Common integration mistake: Teams often implement synchronous processing for long-context queries, leading to timeout issues. For documents approaching 256K tokens, implement asynchronous processing with status polling or webhooks for completion notification.
Organizations can explore deployment patterns by testing Kimi K2.5 alongside other models on MULTIBLY’s platform, which provides unified access to 300+ AI models and enables side-by-side comparison before committing to production architecture decisions.
For teams evaluating how small models like Phi-4 and Mistral compare to long-context models for specific workflows, the key consideration is whether context completeness or inference speed matters more for the target application.
FAQ
What is the maximum document size Kimi K2.5 can process in a single session?
Kimi K2.5’s 256K token context window can process approximately 190,000 words or 200,000 lines of code in a single session[1][2]. This translates to roughly 500-800 pages of typical legal or financial documents, depending on formatting and embedded content.
How much does Kimi K2.5 cost compared to Claude Opus 4.5 and GPT-5.2?
Kimi K2.5 costs $0.60 per 1K input tokens and $3.00 per 1K output tokens, making it approximately 9x cheaper than Claude Opus 4.5 ($5.00/$15.00) and 5x cheaper than GPT-5.2[2]. For processing 1 million input tokens monthly, K2.5 costs $600 versus $5,000 for Claude Opus 4.5.
Can Kimi K2.5 process scanned documents and images?
Yes, Kimi K2.5 includes a native 400M-parameter MoonViT vision encoder that processes images and videos directly[4]. This enables analysis of scanned contracts, financial charts, medical imaging, and design mockups without converting visual content to text descriptions.
How many conversation rounds can Kimi K2.5 maintain before losing context?
Kimi K2.5 supports 50+ rounds of deep discussion while maintaining full conversation history and context[2]. This is significantly more than traditional models, which typically degrade after 10-20 rounds when processing long documents.
What happens if my document exceeds 256K tokens?
Documents exceeding 256K tokens require either document compression, selective section loading, or falling back to traditional chunking approaches. Teams should implement preprocessing to identify and prioritize the most relevant sections for queries, or split processing across multiple sessions for truly massive document sets.
How fast is Kimi K2.5 compared to traditional models?
Kimi K2.5’s native INT4 quantization achieves 2x inference speed improvements compared to traditional FP16 implementations[3]. Standard queries return in 2-5 seconds, while complex Thinking Mode queries take 8-25 seconds[4]. This is faster than most long-context models despite the extended window.
Is Kimi K2.5 suitable for real-time applications?
Kimi K2.5 works well for interactive document analysis where users expect thoughtful responses (legal research, medical record review, financial analysis). It’s not optimal for sub-second real-time applications like chatbots or customer support where speed matters more than deep context.
Can Kimi K2.5 handle autonomous workflows with tool use?
Yes, Kimi K2.5 maintains stable tool-use across 200-300 sequential tool calls[1][3], enabling autonomous workflows for research tasks, web searches, code execution, and iterative refinement. The model achieved 78.4% accuracy on BrowseComp in swarm mode[3], demonstrating strong agentic capabilities.
How does the Mixture-of-Experts architecture reduce costs?
Kimi K2.5’s MoE architecture activates only 32 billion of its 1 trillion total parameters per token[1]. This sparse activation pattern reduces computational requirements by 10-30x compared to dense models of similar capability, enabling the favorable pricing despite the large total parameter count.
What industries benefit most from Kimi K2.5’s long context window?
Legal, medical, and financial industries see the most significant benefits because their documents contain extensive cross-references, temporal relationships, and regulatory requirements that traditional chunking approaches fragment. Any industry processing complex multi-document workflows benefits from the extended context.
Can I deploy Kimi K2.5 on-premise for sensitive data?
Kimi K2.5 is primarily available via API, but organizations with strict data residency or compliance requirements should contact Moonshot AI directly about enterprise deployment options. Highly regulated industries may require private cloud or on-premise instances.
How does Kimi K2.5 compare to GPT-5 for document processing?
Kimi K2.5’s 256K context window is double GPT-5.2’s 128K capacity[2], making it superior for long-document processing. However, model choice should consider the specific task—GPT-5’s dual-model system may offer advantages for workflows mixing speed and reasoning requirements. Teams can compare both models side-by-side on MULTIBLY before committing.
Conclusion
Long-Context LLMs in Production, particularly Kimi K2’s 256K Window vs Traditional Models for Document Processing, represents a fundamental shift in how enterprises approach complex document analysis. The practical advantages extend beyond raw token capacity to encompass cost efficiency, architectural simplicity, and accuracy improvements that traditional chunking approaches cannot match.
For legal teams conducting due diligence, medical professionals reviewing patient histories, and financial analysts processing regulatory filings, the ability to maintain complete document context throughout extended analysis sessions eliminates the fragmentation errors that plague traditional approaches. The 9x cost advantage over Claude Opus 4.5 makes this capability economically viable for routine workflows that would be prohibitively expensive with proprietary alternatives.
Actionable next steps for teams evaluating long-context LLMs:
- Audit current document processing workflows to identify where cross-reference accuracy, temporal context, or multi-document synthesis creates value
- Calculate token volumes for representative document sets to estimate monthly costs and ROI compared to current solutions
- Test Kimi K2.5 on production-representative documents using platforms like MULTIBLY to validate performance claims before architectural commitment
- Design hybrid routing strategies that direct complex queries to K2.5 while using faster models for simple tasks
- Implement monitoring and cost controls to track token usage patterns and optimize spending as deployment scales
- Evaluate security and compliance requirements to determine whether API access suffices or enterprise deployment is necessary
The competitive landscape continues evolving as open-source models like GLM-4.5, Kimi K2, and DeepSeek challenge proprietary model dominance. Organizations that establish long-context processing capabilities now position themselves to handle increasingly complex document workflows as regulatory requirements and business complexity continue growing.
The key insight is that long-context models don’t just process more tokens—they enable fundamentally different application architectures that eliminate retrieval orchestration, preserve contextual relationships, and simplify production systems. For document-heavy industries, this architectural shift delivers measurable improvements in accuracy, cost efficiency, and operational simplicity that justify migration from traditional approaches.
References
[1] Kimi K2 – https://www.leanware.co/insights/kimi-k2
[2] Kimi K2 5 Coding Benchmark Context Window Cli Guide En – https://help.apiyi.com/en/kimi-k2-5-coding-benchmark-context-window-cli-guide-en.html
[3] Kimi K2 5 – https://www.together.ai/models/kimi-k2-5
[4] Kimi K2 5 Launch – https://llm-stats.com/blog/research/kimi-k2-5-launch
Our Fact Checking Process
We prioritize accuracy and integrity in our content. Here's how we maintain high standards:
- Expert Review: All articles are reviewed by subject matter experts.
- Source Validation: Information is backed by credible, up-to-date sources.
- Transparency: We clearly cite references and disclose potential conflicts.
Our Review Board
Our content is carefully reviewed by experienced professionals to ensure accuracy and relevance.
- Qualified Experts: Each article is assessed by specialists with field-specific knowledge.
- Up-to-date Insights: We incorporate the latest research, trends, and standards.
- Commitment to Quality: Reviewers ensure clarity, correctness, and completeness.
Look for the expert-reviewed label to read content you can trust.



