
- Key Takeaways
- Quick Answer
- What Makes Magistral Medium Different from Standard Language Models?
- How Does Magistral Medium Compare to Claude Opus 4.1 and GPT-4?
- What Are the Core Deployment Strategies for Magistral Medium?
- How to Integrate Magistral Medium via API: Step-by-Step Guide
- What Enterprise Use Cases Benefit Most from Magistral Medium's Reasoning Capabilities?
- What Are the Limitations and Considerations When Deploying Magistral Medium?
- How Does Mistral's Deployment Support Model Compare to Alternatives?
- What's Next for Magistral Medium and Mistral's Enterprise Strategy?
- Frequently Asked Questions
- Conclusion
- References
Key Takeaways
- Magistral Medium delivers enterprise-grade reasoning with transparent decision-making processes that satisfy audit and compliance requirements in regulated industries
- Cost efficiency through token optimization achieves 8X lower inference costs compared to premium alternatives while maintaining competitive performance on coding, safety, and multilingual benchmarks[3]
- Flexible deployment strategies including cloud API, hybrid with Koyeb integration, on-premises, and in-VPC configurations address data sovereignty and regulatory requirements
- Mistral’s quasi-consultancy approach provides forward-deployed engineering teams for customized solutions, differentiating it from API-only providers[2]
- Multilingual reasoning consistency across 100+ languages makes Magistral Medium suitable for global enterprise deployments without separate model configurations[3]
- Customization depth from fine-tuning to full pre-training allows enterprises to create domain-specific models optimized for their workflows[8]
- Integration with enterprise tools and support for function calling enables agentic workflows and complex automation tasks
- Ministral reasoning variants (14B, 8B, 3B parameters) provide cost-optimized alternatives for less complex tasks while maintaining reasoning capabilities[4]
- Strategic positioning between frontier models and lightweight alternatives creates sustainable competitive advantage as compute constraints increase in 2026[2]
- Testing through platforms like MULTIBLY allows side-by-side comparison of Magistral Medium against 80+ models to validate performance before deployment commitments
Quick Answer
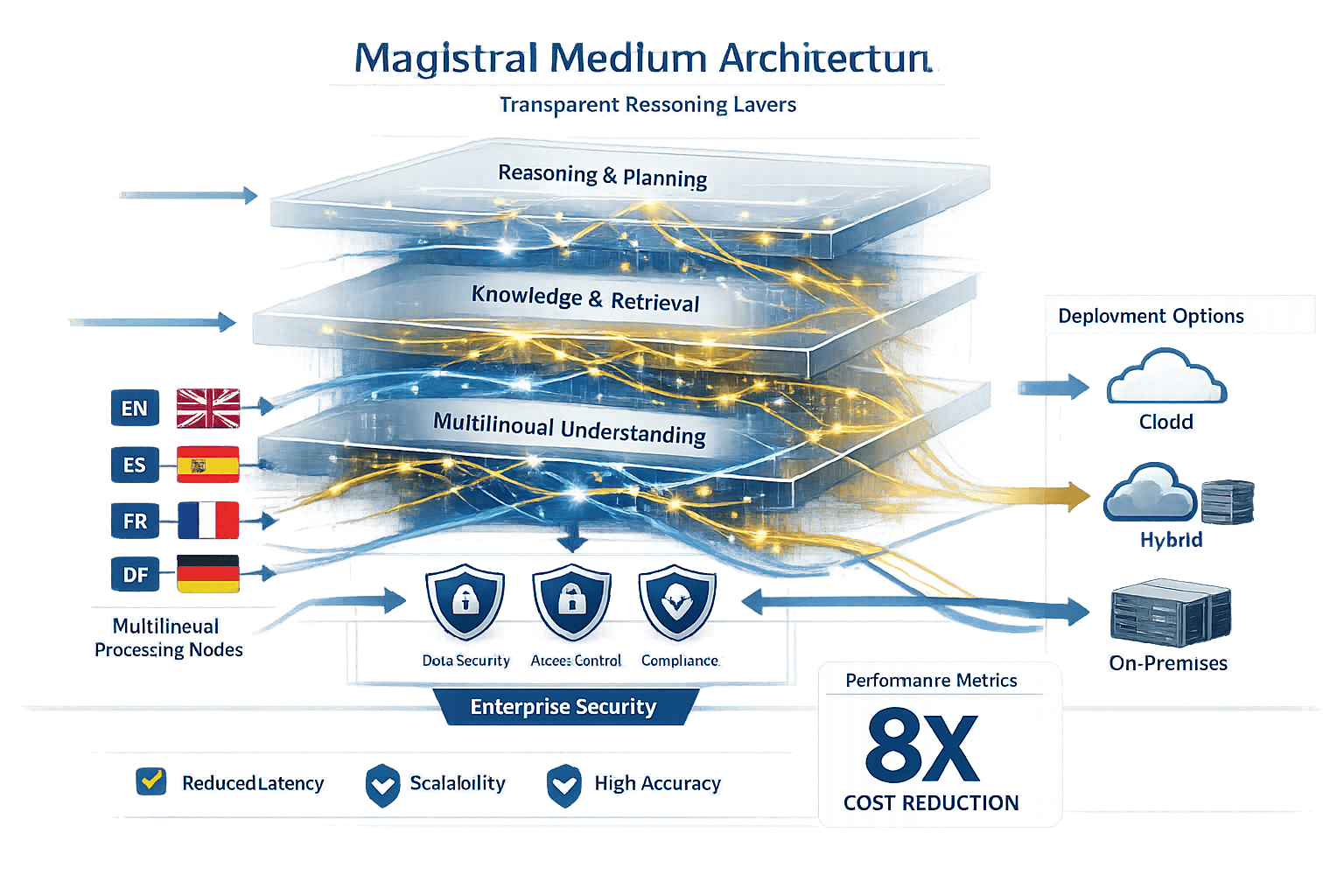
Magistral Medium represents Mistral’s specialized enterprise reasoning model that combines transparent decision-making processes with production-ready deployment flexibility. Released as part of the Mistral 3 lineup in December 2025, it delivers comparable performance to premium models like Claude Opus 4.1 at significantly lower inference costs through efficient token generation and optimized architecture[3]. The model excels in complex reasoning tasks, multilingual processing, and enterprise tool integration while offering deployment options that satisfy data sovereignty requirements for regulated industries.
What Makes Magistral Medium Different from Standard Language Models?
Magistral Medium is built specifically for transparent reasoning rather than simple text generation. The model exposes its thinking process, allowing enterprises to audit how it arrives at conclusions—a critical capability for regulated industries like finance, healthcare, and legal services[3].
The key architectural difference lies in how the model handles complex multi-step problems. Standard language models generate responses in a single pass, while Magistral Medium breaks down reasoning into discrete steps that can be examined individually. This approach mirrors how human experts document their decision-making process.
Core capabilities that set Magistral Medium apart:
- Reasoning transparency: Each inference step can be traced and validated
- Multilingual reasoning consistency: Maintains logical coherence even when switching languages mid-task[3]
- Enterprise tool integration: Native support for function calling, API interactions, and workflow automation
- Cost efficiency: Generates significantly fewer tokens than comparable models while maintaining performance[4]
- Flexible deployment: Supports cloud, hybrid, on-premises, and sovereign AI configurations[3]
In practice, this means a financial analyst can see exactly how Magistral Medium arrived at a risk assessment, or a legal team can audit the reasoning behind contract clause recommendations. The transparency isn’t just a feature—it’s fundamental to the model’s design.
For teams evaluating multiple AI models, MULTIBLY’s platform allows direct comparison of Magistral Medium’s reasoning outputs against other premium models to validate performance for specific enterprise workflows.
How Does Magistral Medium Compare to Claude Opus 4.1 and GPT-4?
Magistral Medium positions itself as a cost-effective alternative to premium models while maintaining competitive performance across key enterprise benchmarks. The comparison reveals distinct tradeoffs that matter for different deployment scenarios.
Performance Benchmarks
Coding and technical tasks: Magistral Medium demonstrates particularly strong performance in code generation, debugging, and technical documentation. The model’s reasoning transparency helps developers understand suggested solutions rather than treating the AI as a black box.
Safety and alignment: Mistral emphasizes that Medium 3 achieves strong safety scores without sacrificing capability, addressing a common enterprise concern about model reliability in production environments[3].
Multilingual capabilities: Unlike models primarily optimized for English, Magistral Medium maintains consistent reasoning quality across 100+ languages, making it suitable for global enterprise deployments[3].
Cost Comparison
The most significant differentiator is inference cost. Magistral Medium achieves approximately 8X lower cost per inference compared to premium alternatives[3]. This reduction comes from:
- Token efficiency: Generating fewer tokens for equivalent task completion[4]
- Optimized architecture: More efficient parameter usage without sacrificing quality
- Flexible deployment: Options to run on-premises or in-VPC reduce cloud API costs
Choose Magistral Medium if:
- Cost predictability matters for high-volume deployments
- Reasoning transparency is required for compliance
- Multilingual consistency is essential
- Data sovereignty requirements prevent cloud-only solutions
Choose Claude Opus 4.1 or GPT-4 if:
- Maximum performance on English-language tasks is non-negotiable
- Established ecosystem integrations are critical
- Budget constraints are less important than cutting-edge capabilities
The small model revolution demonstrates that specialized models like Magistral Medium often outperform larger general-purpose models on specific enterprise tasks while reducing operational costs.
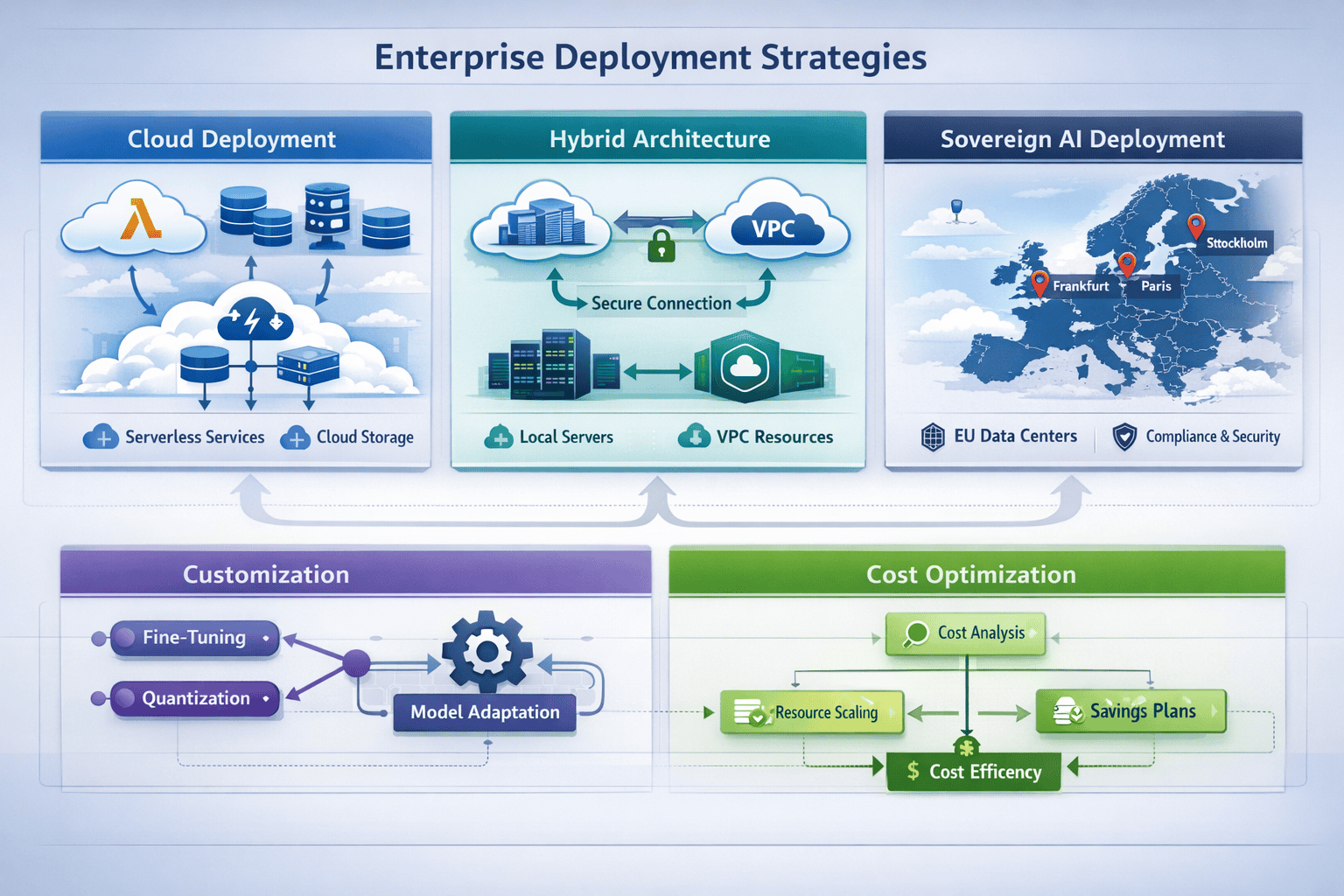
What Are the Core Deployment Strategies for Magistral Medium?

Mistral offers four primary deployment pathways designed to meet different enterprise requirements around data sovereignty, compliance, and operational control.
Cloud Deployment via Mistral API
The fastest path to production uses Mistral’s hosted API service. This approach requires minimal infrastructure setup and provides immediate access to Magistral Medium with standard enterprise SLAs.
Best for: Teams prioritizing speed to market, startups, and organizations without strict data residency requirements.
Implementation steps:
- Obtain API credentials from Mistral’s enterprise portal
- Configure authentication and rate limiting
- Integrate API calls into existing applications
- Monitor usage and performance metrics
Common mistake: Failing to implement proper retry logic and error handling. Magistral Medium’s reasoning outputs can be longer than standard responses, requiring adjusted timeout configurations.
Hybrid Deployment with Koyeb Integration
Following Mistral’s acquisition of Koyeb in 2025, enterprises can deploy Magistral Medium using serverless architecture with localized compute control[5]. This approach balances convenience with data sovereignty.
The hybrid model allows sensitive data processing on-premises while leveraging cloud infrastructure for non-sensitive workloads. Koyeb’s serverless platform automatically scales based on demand without requiring manual infrastructure management.
Best for: Organizations with mixed data sensitivity levels, regulated industries with specific compliance requirements, and teams seeking cost optimization through dynamic scaling.
On-Premises and In-VPC Deployment
For maximum control, Mistral supports fully on-premises or in-VPC deployment of Magistral Medium[3]. This option addresses strict data sovereignty requirements common in European enterprises and regulated industries.
Deployment considerations:
- Hardware requirements: Magistral Medium’s parameter count determines GPU/TPU specifications
- Quantization options: Mistral offers compressed versions maintaining reasoning integrity[8]
- Update management: Balancing model updates with stability requirements
- Monitoring infrastructure: Implementing observability for reasoning quality and performance
Edge case: Organizations in highly regulated industries may require air-gapped deployments. Mistral’s forward-deployed engineering teams work directly with customers on these specialized configurations[2].
Custom Post-Training and Fine-Tuning
Mistral’s deployment strategy includes customization from fine-tuning to full pre-training[8]. This approach allows enterprises to adapt Magistral Medium to domain-specific terminology, reasoning patterns, and compliance requirements.
Customization options:
- Fine-tuning: Adapting to industry-specific language and workflows
- Quantization: Reducing model size while maintaining reasoning quality
- Pruning: Removing unnecessary parameters for specific use cases
- Distillation: Creating smaller specialized versions of Magistral Medium
Mistral’s quasi-consultancy model means software engineers work directly with customers on customized solutions, similar to Palantir’s approach for large bureaucratic organizations[2]. This hands-on support differentiates Mistral from API-only providers.
For teams comparing deployment approaches across multiple models, MULTIBLY’s platform provides unified access to test Magistral Medium alongside alternatives before committing to infrastructure investments.
How to Integrate Magistral Medium via API: Step-by-Step Guide
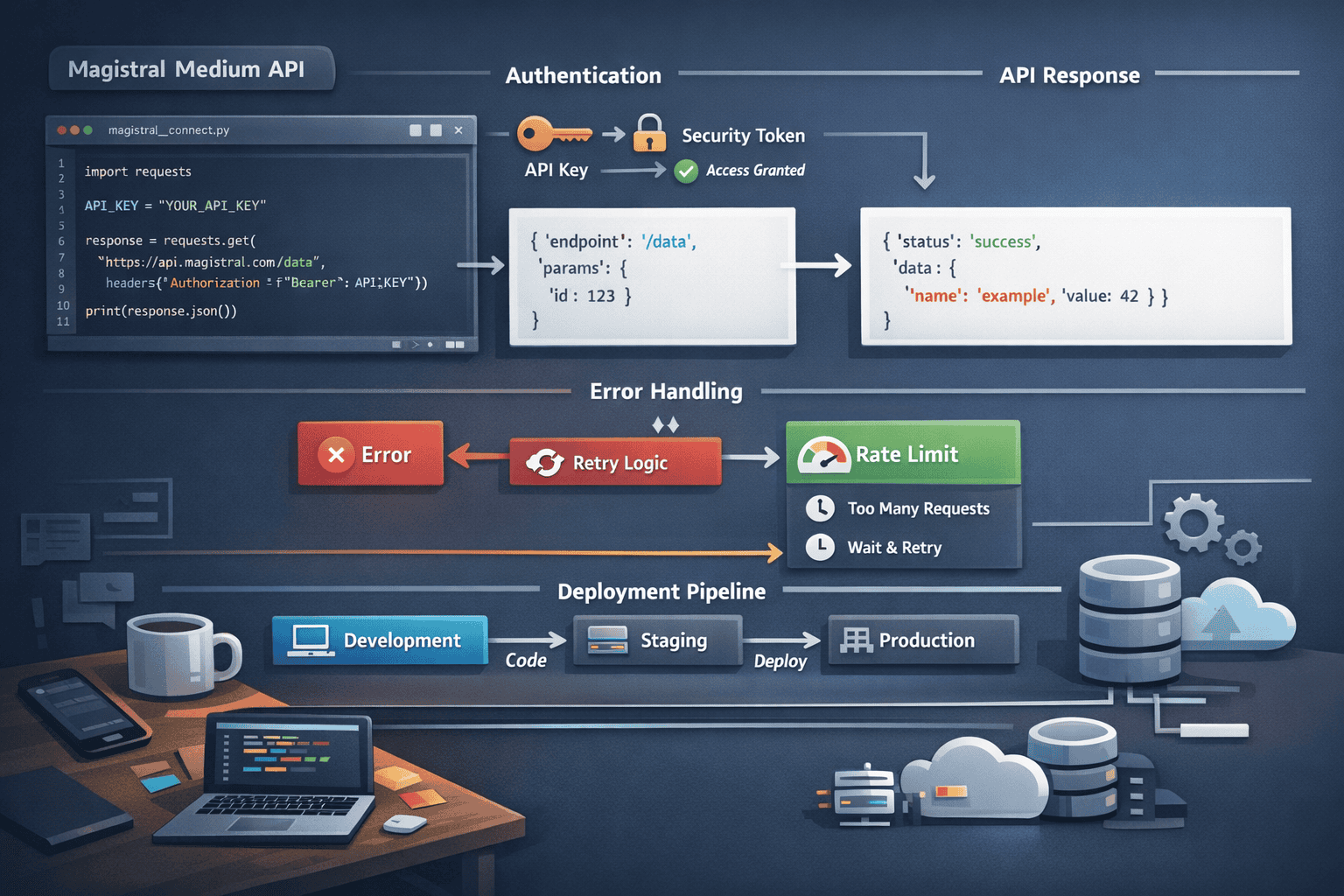
Implementing Magistral Medium through Mistral’s API requires proper authentication, request formatting, and response handling to leverage the model’s reasoning capabilities effectively.
Step 1: Authentication Setup
Obtain enterprise API credentials from Mistral’s portal. The authentication uses bearer token format with support for key rotation and usage tracking.
<code>Authorization: Bearer YOUR_API_KEY
Content-Type: application/json
</code>Security best practice: Store API keys in environment variables or secure credential management systems, never in source code repositories.
Step 2: Construct Reasoning Requests
Magistral Medium’s API accepts standard chat completion format with additional parameters for reasoning transparency.
Key request parameters:
- model: Specify “magistral-medium” or version identifier
- messages: Array of conversation history with role and content
- temperature: Controls randomness (0.0-1.0, lower for deterministic reasoning)
- max_tokens: Response length limit (account for reasoning steps)
- reasoning_detail: Optional parameter to control transparency level
Example request structure:
<code class="language-json">{
"model": "magistral-medium",
"messages": [
{"role": "system", "content": "You are a financial analyst providing detailed reasoning."},
{"role": "user", "content": "Analyze the risk profile of this portfolio."}
],
"temperature": 0.2,
"max_tokens": 2000,
"reasoning_detail": "verbose"
}
</code>Step 3: Handle Reasoning Responses
Magistral Medium returns responses with separated reasoning and final answer components when reasoning transparency is enabled. Parse these sections appropriately for your use case.
Response structure:
- reasoning_steps: Array of intermediate thinking processes
- final_answer: Synthesized conclusion
- confidence_scores: Optional metadata about certainty levels
- token_usage: Detailed breakdown for cost tracking
Implementation consideration: Applications requiring auditability should store reasoning_steps alongside final answers for compliance documentation.
Step 4: Error Handling and Retry Logic
Implement robust error handling for production deployments. Magistral Medium’s reasoning processes may occasionally require longer processing times than standard completions.
Common error scenarios:
- Rate limiting: Implement exponential backoff with jitter
- Timeout handling: Adjust based on task complexity
- Partial responses: Handle streaming mode for long reasoning chains
- Token limit exceeded: Break complex tasks into subtasks
Edge case: When reasoning tasks involve multilingual switching, ensure your application properly handles Unicode and maintains character encoding throughout the pipeline[3].
Step 5: Cost Optimization
Monitor token usage patterns to optimize costs. Magistral Medium’s efficiency comes from generating fewer tokens, but complex reasoning tasks still require budget management.
Optimization strategies:
- Cache reasoning for repeated similar queries
- Use temperature=0 for deterministic tasks to enable caching
- Implement request batching where appropriate
- Monitor reasoning_detail parameter impact on token consumption
The context window capabilities of Magistral Medium support 128,000-256,000 tokens, allowing complex document analysis without multiple API calls[1].
What Enterprise Use Cases Benefit Most from Magistral Medium’s Reasoning Capabilities?
Magistral Medium’s transparent reasoning architecture makes it particularly valuable for high-stakes decision support where explainability and auditability matter as much as accuracy.
Financial Analysis and Risk Assessment
Investment firms and banks use Magistral Medium for portfolio analysis, risk modeling, and regulatory compliance documentation. The model’s ability to show its reasoning process satisfies audit requirements that black-box models cannot meet.
Specific applications:
- Credit risk evaluation with documented decision factors
- Portfolio rebalancing recommendations with transparent rationale
- Regulatory filing assistance with traceable reasoning
- Fraud detection with explainable alert generation
Key advantage: Compliance teams can review reasoning steps to validate that AI recommendations align with regulatory requirements before implementation.
Legal Research and Contract Analysis
Law firms leverage Magistral Medium for contract review, legal research, and case analysis. The multilingual reasoning consistency supports international law practices working across jurisdictions[3].
Use cases:
- Contract clause comparison with reasoning about implications
- Legal precedent research with citation validation
- Due diligence document analysis with risk flagging
- Multilingual contract translation maintaining legal consistency
Common mistake: Treating AI legal analysis as final rather than decision support. Best practice involves using Magistral Medium’s reasoning as a starting point for attorney review.
Healthcare Decision Support
Medical organizations use Magistral Medium for clinical decision support, research analysis, and patient communication where transparent reasoning builds trust and satisfies regulatory requirements.
Applications:
- Diagnostic suggestion with symptom-to-conclusion reasoning
- Treatment protocol recommendations with evidence citations
- Medical literature synthesis with transparent methodology
- Patient education materials with clear explanation chains
Regulatory consideration: Healthcare deployments typically require on-premises or in-VPC configurations to satisfy HIPAA and similar data protection regulations[3].
Technical Documentation and Code Review
Engineering teams use Magistral Medium for code review, architecture decisions, and technical documentation where showing the reasoning process helps team alignment.
Engineering use cases:
- Code review with explained security and performance concerns
- Architecture decision records with transparent tradeoff analysis
- API documentation generation with usage reasoning
- Debugging assistance with step-by-step problem isolation
The model’s strong performance on coding benchmarks makes it competitive with specialized code models while adding reasoning transparency[3].
Multilingual Customer Support
Global enterprises leverage Magistral Medium’s consistent multilingual reasoning for customer support that maintains quality across languages without separate model deployments[3].
Support applications:
- Complex troubleshooting with step-by-step reasoning in customer’s language
- Policy explanation with transparent interpretation
- Escalation analysis with documented reasoning for human agents
- Knowledge base generation maintaining consistency across languages
For organizations evaluating whether Magistral Medium fits their specific use case, comparing responses across multiple models helps validate performance before full deployment.
What Are the Limitations and Considerations When Deploying Magistral Medium?
Understanding Magistral Medium’s constraints helps enterprises set appropriate expectations and design systems that account for model limitations.
Reasoning Overhead and Latency
Transparent reasoning requires additional computation compared to direct answer generation. Tasks requiring extensive reasoning chains take longer to complete than simpler queries.
Latency considerations:
- Simple queries may be faster with standard models
- Complex reasoning tasks justify the additional processing time
- Streaming responses can improve perceived performance
- Caching strategies reduce repeated reasoning overhead
Choose standard models instead if: Sub-second response times are critical and reasoning transparency isn’t required.
Token Generation Efficiency Tradeoffs
While Magistral Medium generates fewer tokens than comparable models for equivalent tasks[4], enabling detailed reasoning transparency increases token usage compared to answer-only mode.
Token management strategies:
- Adjust reasoning_detail parameter based on use case
- Use verbose reasoning only when auditability is required
- Implement tiered approaches (detailed reasoning for high-stakes, standard for routine)
- Monitor actual token usage patterns to optimize configurations
Multilingual Performance Variance
Although Magistral Medium maintains reasoning consistency across languages[3], performance on specialized terminology varies by language. English technical documentation remains more extensive than other languages.
Mitigation approaches:
- Fine-tune on domain-specific multilingual corpora
- Validate performance in target languages before production
- Implement human-in-the-loop for critical non-English tasks
- Maintain glossaries for consistent technical term handling
Model Update Management
Mistral’s rapid release cycle (Medium 3.1 in August 2025, Mistral 3 lineup in December 2025[1][2]) means enterprises must balance staying current with stability requirements.
Update strategy considerations:
- Pin specific model versions for production stability
- Maintain staging environments for testing updates
- Document performance baselines for regression testing
- Plan migration windows for version updates
Edge case: Regulated industries may require extended validation periods before adopting new model versions, creating tension with staying current on capabilities.
Cost Predictability for Variable Workloads
While Magistral Medium offers 8X cost reduction[3], variable reasoning complexity makes cost prediction challenging for new deployments.
Cost management approaches:
- Run pilot projects to establish baseline usage patterns
- Implement budget alerts and rate limiting
- Consider reserved capacity for predictable workloads
- Evaluate on-premises deployment for high-volume use cases
The DeepSeek models demonstrate similar cost-efficiency tradeoffs, where specialized architectures reduce costs but require careful workload analysis.
How Does Mistral’s Deployment Support Model Compare to Alternatives?
Mistral’s approach to enterprise deployment combines forward-deployed engineering teams with flexible infrastructure options, differentiating it from pure API providers and traditional software vendors.
The Quasi-Consultancy Model
Mistral deploys software engineers directly to customer sites for customized solutions, similar to Palantir’s approach for large bureaucratic organizations[2]. This hands-on model addresses complex deployment scenarios that standard API documentation cannot solve.
What this means in practice:
- Dedicated engineering support for custom post-training[8]
- Architecture consultation for hybrid deployments
- Performance optimization for specific workloads
- Compliance guidance for regulated industries
Best for: Large enterprises with complex requirements, regulated industries, and organizations requiring extensive customization.
Not suitable for: Small teams seeking self-service deployment or organizations preferring minimal vendor interaction.
Sovereign AI Positioning
Following the Koyeb acquisition, Mistral positions itself as the European sovereign AI alternative[5]. This strategy appeals to organizations concerned about data sovereignty and regulatory compliance.
Sovereign AI advantages:
- European data residency options
- Compliance with GDPR and industry-specific regulations
- Reduced dependency on US-based cloud providers
- Localized compute control through Koyeb integration
Regulatory consideration: Financial institutions and government agencies increasingly require AI deployments that satisfy data sovereignty requirements, making this a competitive advantage.
Customization Depth
Mistral offers customization from fine-tuning to full pre-training[8], a broader range than most competitors provide. This flexibility allows enterprises to create truly specialized models.
Customization options:
- Fine-tuning: Adapt to industry terminology and workflows
- Compression: Quantization, pruning, and distillation maintaining reasoning integrity[8]
- Custom pre-training: Build domain-specific models from foundation
- Hybrid approaches: Combine techniques for optimal performance-cost balance
Tradeoff: Deeper customization requires more time and expertise. Organizations without ML teams may prefer simpler fine-tuning options.
Comparison with Alternative Support Models
OpenAI/Anthropic approach: Primarily API-focused with enterprise support tiers but limited on-premises options and customization depth.
Google/Amazon approach: Strong cloud infrastructure integration but less specialized enterprise deployment consulting.
Open-source alternatives: Maximum flexibility but require internal expertise for deployment, optimization, and maintenance.
Mistral’s model sits between these extremes, offering managed services with extensive customization for enterprises willing to invest in tailored deployments.
For teams evaluating support requirements across providers, testing models through MULTIBLY’s unified platform helps assess whether specialized deployment support justifies the investment.
What’s Next for Magistral Medium and Mistral’s Enterprise Strategy?
Mistral’s rapid release cycle and strategic positioning suggest continued focus on enterprise reasoning capabilities and deployment flexibility through 2026.
Multimodal Reasoning Expansion
Medium 3.1 introduced multimodal capabilities in August 2025, achieving approximately 90% of Claude Sonnet 3.7 performance at lower costs[2]. Expect continued enhancement of vision, audio, and document understanding with maintained reasoning transparency.
Anticipated developments:
- Enhanced document analysis for complex layouts
- Video understanding with temporal reasoning
- Audio processing with contextual interpretation
- Cross-modal reasoning (combining text, image, and data)
Ministral Reasoning Variants Integration
The Ministral 3 lineup (14B, 8B, 3B parameters) achieved 85% accuracy on AIME ’25 with the 14B variant[4], demonstrating that reasoning capabilities can scale down to smaller, more cost-effective models.
Strategic implications:
- Edge deployment of reasoning models
- Cost optimization through right-sized model selection
- Specialized reasoning models for specific domains
- Hybrid architectures combining multiple Ministral variants
Organizations can deploy smaller Ministral variants for routine reasoning tasks and escalate to Magistral Medium for complex scenarios, optimizing cost without sacrificing capability.
Compute Infrastructure Expansion
Mistral’s Koyeb acquisition signals vertical integration into compute infrastructure[5]. This strategy reduces dependency on third-party cloud providers and enables more competitive pricing.
Expected infrastructure developments:
- Expanded geographic coverage for data residency
- Specialized hardware optimization for reasoning workloads
- Improved serverless scaling for variable demand
- Enhanced hybrid deployment tooling
Enterprise Tool Ecosystem
Mistral emphasizes native enterprise tool integration[3] as a differentiator. Expect expanded pre-built connectors for common enterprise systems.
Integration priorities:
- CRM and customer data platforms
- Enterprise resource planning systems
- Business intelligence and analytics tools
- Collaboration and workflow platforms
Competitive Positioning Against Frontier Models
As compute becomes more constrained in 2026, Mistral’s efficiency-focused approach positions it well against competitors facing scaling challenges[2]. The company’s strategy emphasizes practical enterprise value over benchmark maximization.
Competitive advantages:
- Cost efficiency through token optimization[4]
- Deployment flexibility addressing sovereignty requirements
- Reasoning transparency for regulated industries
- Multilingual consistency for global enterprises[3]
The ongoing competition from Chinese models and smaller specialized models suggests that Mistral’s positioning between frontier models and lightweight alternatives creates a sustainable market position.
Frequently Asked Questions
What is Magistral Medium and how does it differ from other Mistral models?
Magistral Medium is Mistral’s specialized transparent reasoning model designed for enterprise deployments requiring explainable decision-making. Unlike Mistral’s base models, it exposes reasoning steps for auditability, supports extensive multilingual consistency, and offers flexible deployment options including on-premises and hybrid configurations[3].
How much does Magistral Medium cost compared to Claude Opus 4.1?
Magistral Medium achieves approximately 8X lower inference cost compared to premium alternatives like Claude Opus 4.1[3]. The exact cost depends on deployment method (API, on-premises, or hybrid) and usage patterns, but the token efficiency and optimized architecture significantly reduce operational expenses for high-volume deployments.
Can Magistral Medium run on-premises for data sovereignty requirements?
Yes, Mistral supports fully on-premises and in-VPC deployment of Magistral Medium[3]. This option addresses strict data sovereignty requirements common in European enterprises and regulated industries like finance and healthcare. Mistral’s forward-deployed engineering teams assist with custom deployment configurations[2].
What programming languages and frameworks work with Magistral Medium’s API?
Magistral Medium’s API uses standard REST endpoints compatible with any programming language supporting HTTP requests. Mistral provides official SDKs for Python, JavaScript, and other common languages. The API follows OpenAI-compatible formatting, allowing easy migration from other providers.
How does Magistral Medium handle multilingual reasoning tasks?
Magistral Medium maintains reasoning consistency across 100+ languages, including the ability to switch languages mid-task without losing logical coherence[3]. This capability makes it suitable for global enterprises requiring consistent AI performance across geographic regions and language contexts.
What are the hardware requirements for on-premises Magistral Medium deployment?
Hardware requirements depend on deployment scale and whether you use quantized versions. Mistral offers compression techniques including quantization, pruning, and distillation that maintain reasoning integrity while reducing infrastructure needs[8]. Contact Mistral’s enterprise team for specific sizing based on your workload.
Does Magistral Medium support function calling and tool integration?
Yes, Magistral Medium includes native support for function calling, API interactions, and enterprise tool integration[3]. The model can interact with external systems, databases, and APIs as part of its reasoning process, making it suitable for agentic workflows and complex automation tasks.
How long does it take to fine-tune Magistral Medium for specific use cases?
Fine-tuning timeline varies based on customization depth, from basic fine-tuning (days to weeks) to full custom pre-training (months)[8]. Mistral’s quasi-consultancy model provides hands-on engineering support throughout the process[2]. Pilot projects typically run 4-8 weeks to validate performance before production deployment.
What context window size does Magistral Medium support?
Magistral Medium supports context windows ranging from 128,000 to 256,000 tokens depending on the specific variant[1]. This extensive context allows processing of large documents, extended conversations, and complex reasoning tasks without splitting inputs across multiple requests.
Can Magistral Medium be used for real-time applications?
Magistral Medium’s reasoning transparency adds computational overhead compared to direct answer generation, making it less suitable for sub-second response requirements. For real-time applications, consider using streaming responses or deploying smaller Ministral variants for routine tasks while reserving Magistral Medium for complex reasoning that justifies additional latency[4].
How does Mistral handle model updates and version management?
Mistral releases model updates regularly (Medium 3.1 in August 2025, Mistral 3 lineup in December 2025[1][2]). Enterprise deployments can pin specific model versions for production stability while testing updates in staging environments. Mistral provides migration guidance and backward compatibility support for version transitions.
What industries benefit most from Magistral Medium’s transparent reasoning?
Regulated industries requiring explainable AI decisions benefit most: financial services (risk assessment, compliance), healthcare (clinical decision support), legal (contract analysis, research), and government (policy analysis, procurement). Any use case where understanding how the AI reached a conclusion matters as much as the conclusion itself is a strong fit for Magistral Medium.
Conclusion
Magistral Medium represents Mistral’s strategic bet that enterprise AI adoption depends as much on transparency, deployment flexibility, and cost efficiency as on raw performance benchmarks. The model’s transparent reasoning architecture addresses genuine enterprise needs in regulated industries where explainability isn’t optional.
The deployment strategies Mistral offers—from simple API integration to fully customized on-premises installations with forward-deployed engineering support—recognize that enterprise AI requirements vary dramatically across organizations. A startup optimizing for speed to market has fundamentally different needs than a European bank navigating data sovereignty regulations.
For teams evaluating Magistral Medium in 2026, the key decision factors are:
Choose Magistral Medium when:
- Reasoning transparency and auditability are compliance requirements
- Cost predictability matters for high-volume deployments
- Multilingual consistency is essential for global operations
- Data sovereignty requirements necessitate on-premises or hybrid deployment
- Customization depth beyond simple fine-tuning provides competitive advantage
Consider alternatives when:
- Maximum performance on English-language tasks is non-negotiable
- Sub-second response times are critical for your use case
- Self-service deployment without vendor interaction is preferred
- Established ecosystem integrations outweigh cost considerations
The practical path forward involves testing before committing. Platforms like MULTIBLY allow side-by-side comparison of Magistral Medium’s reasoning outputs against Claude Opus 4.1, GPT-4, and dozens of other models on your actual use cases. This empirical validation matters more than benchmark claims when making production deployment decisions.
Start with pilot projects that leverage Magistral Medium’s strengths: complex reasoning tasks requiring explainability, multilingual workflows, or high-volume deployments where cost efficiency compounds. Monitor actual token usage, reasoning quality, and latency to validate that theoretical advantages translate to practical value for your specific context.
As the AI landscape continues fragmenting between frontier models, specialized reasoning models, and lightweight alternatives, the ability to compare and deploy the right model for each task becomes a competitive advantage. Magistral Medium’s positioning as a cost-effective, transparent, flexibly-deployed reasoning model fills a genuine gap in the enterprise AI ecosystem—but only for organizations whose requirements align with its specific strengths.
References
[1] Mistral Closes In On Big Ai Rivals With Mistral 3 Open Weight Frontier And Small Models – https://techcrunch.com/2025/12/02/mistral-closes-in-on-big-ai-rivals-with-mistral-3-open-weight-frontier-and-small-models/
[2] Ai 2026 Mistral Will Rise As Compute – https://brief.bismarckanalysis.com/p/ai-2026-mistral-will-rise-as-compute
[3] Models – https://mistral.ai/models
[4] Mistral 3 – https://mistral.ai/news/mistral-3
[5] Mistral Ai Deepens Compute Ambitions With Koyeb Acquisition – https://www.infoworld.com/article/4133757/mistral-ai-deepens-compute-ambitions-with-koyeb-acquisition.html
[8] Custom Model Training – https://mistral.ai/solutions/custom-model-training
Our Fact Checking Process
We prioritize accuracy and integrity in our content. Here's how we maintain high standards:
- Expert Review: All articles are reviewed by subject matter experts.
- Source Validation: Information is backed by credible, up-to-date sources.
- Transparency: We clearly cite references and disclose potential conflicts.
Our Review Board
Our content is carefully reviewed by experienced professionals to ensure accuracy and relevance.
- Qualified Experts: Each article is assessed by specialists with field-specific knowledge.
- Up-to-date Insights: We incorporate the latest research, trends, and standards.
- Commitment to Quality: Reviewers ensure clarity, correctness, and completeness.
Look for the expert-reviewed label to read content you can trust.



