
The conversation around Open vs Closed: The Total Cost of Ownership for DeepSeek R1, Qwen3, and Proprietary LLMs in 2026 extends far beyond simple per-token pricing. Organizations evaluating AI infrastructure face a complex financial equation that includes infrastructure costs, fine-tuning expenses, deployment complexity, licensing fees, and long-term maintenance requirements. While proprietary models like GPT-5 and Claude Opus 4.5 offer turnkey API access, open-source alternatives such as DeepSeek R1 and Qwen3 promise dramatic cost reductions for teams willing to manage their own infrastructure.
The financial stakes are substantial. Self-hosted open-source models can reduce inference costs by 80-90% compared to API-based alternatives[1], but this headline figure masks important nuances around upfront investment, technical expertise requirements, and hidden operational expenses. In 2026, the choice between open and closed LLMs represents one of the most consequential strategic decisions for AI-driven organizations.
This guide breaks down the true total cost of ownership for leading open-source models—DeepSeek R1 and Qwen3—against proprietary alternatives. You’ll learn how to calculate your actual costs, understand the infrastructure trade-offs, and identify which deployment model makes financial sense for your specific use case.
- Key Takeaways
- Quick Answer
- What Drives the True Cost of LLM Ownership in 2026?
- How Do DeepSeek R1 and Qwen3 Compare on Pure Performance?
- What Are the Infrastructure Costs for Self-Hosting vs API Access?
- How Do Fine-Tuning Costs Differ Between Open and Closed Models?
- What Hidden Costs Should You Factor Into Your TCO Calculation?
- How Does Deployment Complexity Impact Total Cost of Ownership?
- What Are the Licensing and Legal Considerations for TCO?
- How Do You Calculate Your Specific TCO for Open vs Closed LLMs?
- What Are Common Pitfalls When Choosing Between Open and Closed LLMs?
- FAQ
- Conclusion
- References
Key Takeaways
- Total cost of ownership extends far beyond per-token pricing, encompassing infrastructure, engineering labor, fine-tuning, monitoring, redundancy, and compliance costs that can multiply apparent costs by 2-3x
- Self-hosted open-source models like DeepSeek R1 and Qwen3 reduce inference costs by 80-90% compared to proprietary APIs[1], but require upfront infrastructure investment of $150,000-$400,000 and dedicated engineering resources
- Breakeven typically occurs at 15-40 million tokens monthly, with organizations below this threshold often finding API-based proprietary models more cost-effective when accounting for total ownership costs
- Qwen3 demonstrates superior performance efficiency, outperforming DeepSeek R1 on 17 of 23 benchmarks despite 35% fewer total parameters and 60% fewer active parameters[4], translating to better cost-per-quality ratios
- Fine-tuning economics heavily favor self-hosted models, with proprietary services charging 3-10x base inference rates while self-hosted options enable unlimited fine-tuning at compute cost
- Licensing differences create strategic flexibility: DeepSeek R1’s MIT License and Qwen3’s Apache 2.0 enable unrestricted commercial use without recurring fees[1], while proprietary terms-of-service create vendor dependencies
- Deployment complexity varies dramatically, with API services reaching production in 2-6 weeks versus 12-22 weeks for self-hosted solutions requiring ML infrastructure expertise
- Hidden costs include DevOps labor ($300,000-$600,000 annually), monitoring tools, redundancy infrastructure, and compliance requirements that organizations frequently underestimate by 50-200%
- Hybrid deployments optimize economics by using proprietary APIs for low-volume workloads while deploying self-hosted models for high-volume production use cases
- Model performance differences impact downstream costs: Qwen3’s 92.3% accuracy versus 80% for DeepSeek R1 on mathematics benchmarks[1] reduces error handling and human review expenses that can exceed infrastructure costs
Quick Answer
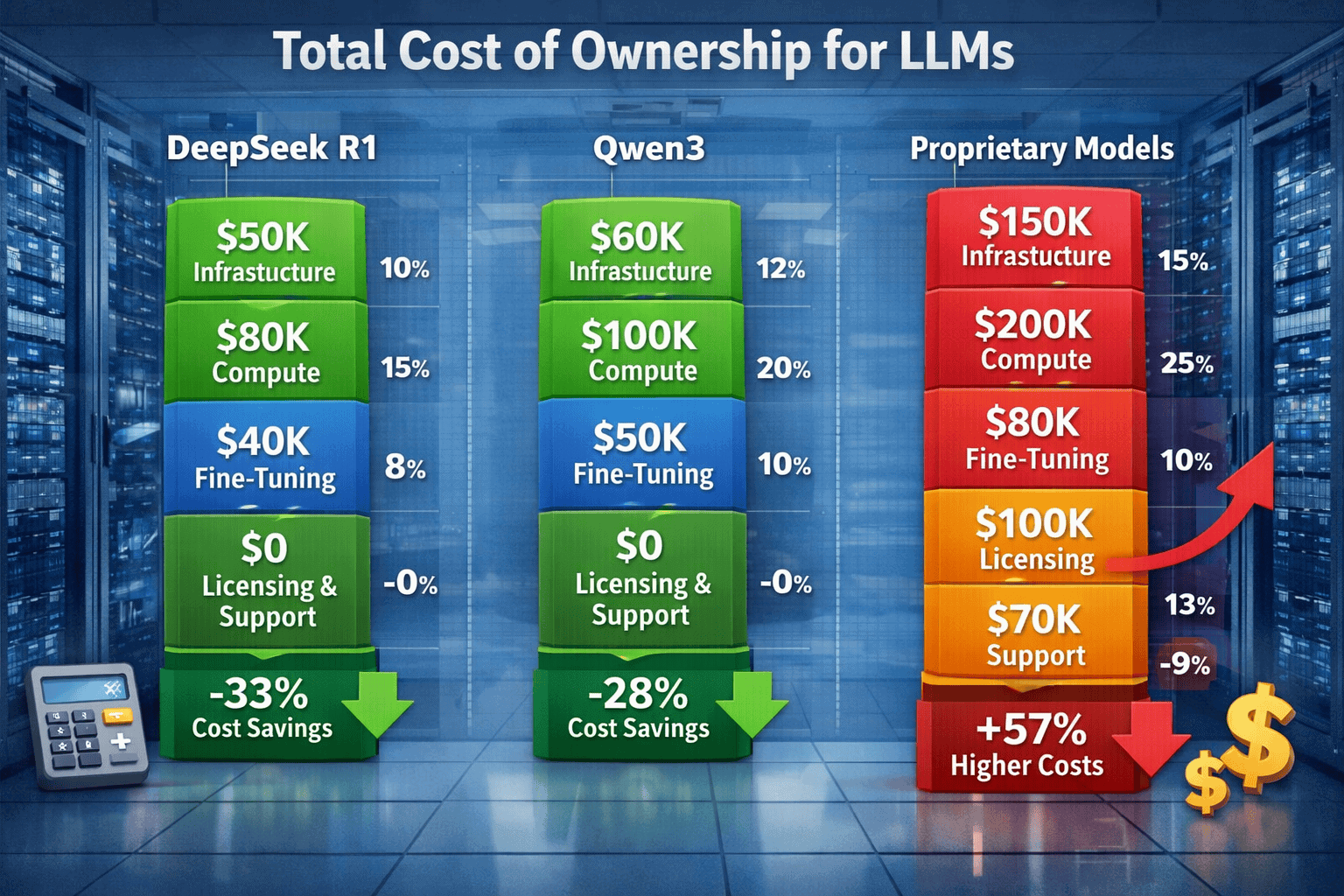
Open vs Closed: The Total Cost of Ownership for DeepSeek R1, Qwen3, and Proprietary LLMs in 2026 depends primarily on your deployment scale and technical capabilities. For organizations processing millions of tokens monthly, self-hosted open-source models like DeepSeek R1 and Qwen3 typically deliver 80-90% cost savings compared to proprietary API services[1]. However, these savings require upfront infrastructure investment ($10,000-$50,000+ for GPU servers), DevOps expertise, and ongoing maintenance costs that proprietary API services eliminate entirely.
The breakeven point typically occurs between 10-50 million tokens per month, depending on your infrastructure costs and internal labor rates. Below this threshold, API-based proprietary models often prove more cost-effective when accounting for total ownership costs.
What Drives the True Cost of LLM Ownership in 2026?
The total cost of ownership for LLMs encompasses seven distinct cost categories that vary dramatically between open and closed deployment models. Understanding these components helps organizations make informed financial decisions rather than reacting to headline pricing alone.
Infrastructure and compute costs represent the most visible expense category. Proprietary models charge per token consumed through API calls, while self-hosted models require GPU servers, storage, networking, and data center resources. A single NVIDIA H100 GPU costs approximately $30,000-$40,000, with most production deployments requiring multiple GPUs for acceptable performance and redundancy.
Licensing and subscription fees create ongoing obligations for proprietary models. Enterprise contracts for GPT-5 or Claude Opus 4.5 often include minimum spending commitments, support fees, and premium pricing tiers. Open-source models like DeepSeek R1 (MIT License) and Qwen3 (Apache 2.0) eliminate these recurring costs entirely[1], though organizations must still account for the opportunity cost of capital invested in infrastructure.
Fine-tuning and customization expenses vary significantly by deployment model. Proprietary services charge premium rates for fine-tuning—often 3-10x the base inference cost—while self-hosted models allow unlimited fine-tuning at the cost of compute time and engineering effort. For organizations requiring domain-specific customization, this difference can swing the economic equation dramatically.
The key cost drivers include:
- Compute infrastructure: GPU servers, cloud instances, or API credits
- Storage requirements: Model weights (37B-671B parameters), training data, fine-tuned versions
- Network bandwidth: Data transfer costs for API calls or distributed inference
- Engineering labor: DevOps, ML engineers, and infrastructure specialists
- Licensing fees: Subscription costs, enterprise contracts, or support agreements
- Fine-tuning costs: Custom model training and optimization
- Operational overhead: Monitoring, maintenance, security patches, and updates
Hidden costs often overlooked include the engineering time required to integrate models, build monitoring systems, implement failover mechanisms, and maintain security compliance. Proprietary API services bundle these capabilities, while self-hosted deployments require building them from scratch.
In practice, organizations with limited ML infrastructure experience often underestimate self-hosting costs by 2-3x when they fail to account for engineering time, redundancy requirements, and ongoing maintenance. Conversely, high-volume users frequently overestimate API costs by failing to negotiate volume discounts or explore reserved capacity pricing.
How Do DeepSeek R1 and Qwen3 Compare on Pure Performance?
Before evaluating costs, understanding performance differences between DeepSeek R1 and Qwen3 helps determine whether either model meets your quality requirements. Both models represent the cutting edge of open-source reasoning AI in 2026, but they take different architectural approaches that impact both capabilities and deployment economics.
DeepSeek R1 employs a massive 671B parameter model with a Mixture of Experts (MoE) architecture that activates only 37B parameters during inference—an efficiency ratio of 5.5%[4]. This design delivers strong reasoning performance while keeping inference costs manageable. On the AIME 2025 mathematics benchmark, DeepSeek R1 achieves approximately 80% accuracy[1], demonstrating robust problem-solving capabilities.
Qwen3 takes a more efficient approach with 235B total parameters and only 22B active during inference—a 9.4% efficiency ratio that indicates superior parameter utilization[4]. Despite having only 35% of DeepSeek R1’s total parameters and 60% of its active parameters, Qwen3 outperforms DeepSeek R1 on 17 of 23 thinking-mode benchmarks[4]. On AIME 2025, Qwen3 achieves 92.3% accuracy[1], significantly exceeding DeepSeek R1’s performance.
Benchmark performance comparison:
| Model | Total Parameters | Active Parameters | AIME 2025 Score | Benchmarks Won (vs competitor) | License Type |
|---|---|---|---|---|---|
| DeepSeek R1 | 671B | 37B (5.5%) | ~80% | 6 of 23 | MIT |
| Qwen3 | 235B | 22B (9.4%) | 92.3% | 17 of 23 | Apache 2.0 |
| Mistral Large | ~405B | Variable | ~75% | N/A | Proprietary |
The performance gap matters for TCO calculations because higher accuracy reduces the need for human review, retry logic, and error correction—all of which add hidden costs to production deployments. If Qwen3 delivers correct answers 92% of the time versus 80% for DeepSeek R1, the downstream cost savings from reduced error handling can offset higher infrastructure expenses.
A common mistake: Organizations often select models based solely on parameter count, assuming larger models deliver better performance. The Qwen3 vs DeepSeek R1 comparison demonstrates that architectural efficiency and training methodology often matter more than raw size. Qwen3’s superior benchmark performance with fewer active parameters translates directly to lower inference costs per query.
For teams comparing these models, DeepSeek R1 and V3.1 represent China’s challenge to global AI leaders, while Qwen3’s recent surge—overtaking Llama as the most downloaded open-source model family on HuggingFace in late 2025[1]—signals shifting adoption patterns worth monitoring.
What Are the Infrastructure Costs for Self-Hosting vs API Access?

Infrastructure costs represent the most dramatic difference between open and closed LLM deployment models. The choice between self-hosting and API access fundamentally changes your cost structure from operational expenses (OpEx) to capital expenses (CapEx), with significant implications for cash flow and financial planning.
Self-hosted deployment requires substantial upfront investment. A production-grade setup for DeepSeek R1 or Qwen3 typically requires:
- GPU infrastructure: 4-8 NVIDIA H100 or A100 GPUs ($30,000-$40,000 each)
- Server hardware: High-memory servers with PCIe lanes for GPU connectivity ($15,000-$25,000)
- Storage systems: NVMe storage for model weights and inference caching ($5,000-$15,000)
- Networking equipment: High-bandwidth switches and load balancers ($3,000-$10,000)
- Power and cooling: Adequate data center infrastructure or cloud equivalents
- Redundancy: Backup systems for production reliability (doubles costs)
Total upfront investment typically ranges from $150,000 to $400,000 for a production-ready self-hosted deployment with appropriate redundancy. Cloud-based alternatives reduce upfront costs but introduce ongoing instance charges that can exceed on-premises costs over 18-24 months.
API-based proprietary models eliminate infrastructure costs entirely but introduce per-token pricing that scales linearly with usage. In 2026, typical pricing for leading proprietary models ranges from:
- GPT-5 reasoning mode: $15-$30 per million input tokens, $60-$120 per million output tokens
- Claude Opus 4.5: $12-$25 per million input tokens, $50-$100 per million output tokens
- Gemini 3 Pro: $8-$18 per million input tokens, $35-$75 per million output tokens
The breakeven calculation depends on monthly token volume. For an organization processing 50 million tokens monthly at $20 per million tokens (blended rate), annual API costs reach $12 million. Self-hosted infrastructure costing $250,000 upfront plus $50,000 annual operating costs breaks even in just over 2 months at this scale.
However, most organizations operate at much lower volumes. At 5 million tokens monthly, annual API costs total $1.2 million, extending the breakeven period to approximately 20 months—assuming no engineering labor costs for self-hosting. When accounting for DevOps and ML engineering time ($150,000-$300,000 annually), the breakeven point shifts to 30-40 million tokens monthly for most organizations.
Choose self-hosting if:
- Monthly token volume consistently exceeds 20-30 million tokens
- You have existing ML infrastructure and DevOps expertise
- Data sovereignty or compliance requirements prevent API usage
- You require extensive fine-tuning and model customization
- Long-term (24+ month) deployment horizon justifies upfront investment
Choose API access if:
- Monthly volume stays below 10-20 million tokens
- You lack in-house ML infrastructure expertise
- Speed to deployment matters more than long-term cost optimization
- Variable workloads make capacity planning difficult
- Capital constraints limit upfront infrastructure investment
Platforms like MULTIBLY provide access to 300+ premium AI models including both open-source and proprietary options, allowing organizations to compare performance and costs before committing to infrastructure investments.
How Do Fine-Tuning Costs Differ Between Open and Closed Models?
Fine-tuning represents one of the most significant hidden cost differentiators between open and closed LLM deployments. The ability to customize models for domain-specific tasks often determines whether an LLM delivers acceptable business value, making fine-tuning economics a critical component of total cost of ownership.
Proprietary API providers charge premium rates for fine-tuning services. In 2026, typical fine-tuning costs include:
- Training costs: $50-$200 per million training tokens (3-10x base inference rates)
- Storage fees: $5-$15 per month per fine-tuned model version
- Inference premiums: 20-50% markup on fine-tuned model inference versus base models
- Minimum spending: Many providers require $10,000-$50,000 minimum commitments for custom fine-tuning
For an organization fine-tuning on 100 million tokens of domain-specific data, proprietary services typically charge $5,000-$20,000 for the initial training run. Each subsequent iteration adds similar costs, making rapid experimentation prohibitively expensive.
Self-hosted open-source models eliminate per-token fine-tuning charges but introduce compute time and engineering costs. Fine-tuning DeepSeek R1 or Qwen3 requires:
- Compute resources: 4-8 GPUs running for 12-72 hours depending on dataset size
- Engineering time: ML engineers configuring training runs, monitoring performance, and validating results
- Storage: Maintaining multiple model versions and training checkpoints
- Experimentation: Running multiple training iterations to optimize hyperparameters
The economics favor self-hosting for organizations requiring frequent fine-tuning. A single GPU-hour on NVIDIA H100 hardware costs approximately $2-$4 in cloud environments or $0.50-$1.50 for amortized on-premises infrastructure. A 24-hour fine-tuning run on 8 GPUs costs $384-$768 in cloud or $96-$288 on owned hardware—dramatically cheaper than proprietary alternatives.
However, engineering labor often dominates fine-tuning costs. An ML engineer spending 40 hours preparing data, configuring training runs, and validating results represents $4,000-$8,000 in labor costs at typical industry rates. This overhead applies equally to both open and closed models, but proprietary services often include managed fine-tuning options that reduce engineering time.
Fine-tuning frequency determines the cost impact:
- One-time customization: Proprietary managed services often prove cheaper when accounting for engineering time
- Monthly iterations: Self-hosted models begin showing cost advantages
- Weekly or continuous fine-tuning: Self-hosted models deliver 70-90% cost savings
- Experimentation-heavy workflows: Self-hosted models enable rapid iteration without per-run charges
A common edge case: Organizations with highly sensitive training data often cannot use proprietary fine-tuning services due to data governance requirements. This constraint forces self-hosting regardless of cost considerations, making the economic comparison moot.
The permissive licensing of DeepSeek R1 (MIT) and Qwen3 (Apache 2.0) enables unrestricted fine-tuning and model modification[1], while proprietary models often include terms-of-service restrictions on certain use cases or competitive applications.
What Hidden Costs Should You Factor Into Your TCO Calculation?
Beyond infrastructure and per-token pricing, several hidden cost categories significantly impact the true total cost of ownership for LLM deployments. Organizations that overlook these factors often experience budget overruns of 50-200% compared to initial projections.
DevOps and engineering labor represents the largest hidden cost for self-hosted deployments. A production LLM infrastructure requires:
- ML engineers: Model optimization, fine-tuning, and performance monitoring ($150,000-$250,000 annual salary)
- DevOps engineers: Infrastructure management, deployment automation, and scaling ($120,000-$200,000 annual salary)
- Security specialists: Compliance, access control, and vulnerability management ($130,000-$220,000 annual salary)
For a dedicated team of 2-3 engineers, annual labor costs range from $300,000 to $600,000. Proprietary API services eliminate most of this overhead, though organizations still need engineers to integrate and manage API usage.
Monitoring and observability tools add ongoing expenses. Production LLM deployments require:
- Performance monitoring: Latency tracking, throughput measurement, error rate analysis
- Cost tracking: Token usage monitoring, budget alerts, and cost allocation
- Quality monitoring: Output validation, hallucination detection, and accuracy measurement
- Security monitoring: Access logging, anomaly detection, and compliance reporting
Commercial observability platforms charge $500-$5,000 monthly for LLM-specific monitoring capabilities. Self-hosted solutions require engineering time to build and maintain.
Data pipeline costs often exceed model inference costs. Processing user queries requires:
- Preprocessing: Text cleaning, tokenization, and prompt engineering
- Embedding generation: Vector database operations for retrieval-augmented generation (RAG)
- Postprocessing: Output formatting, validation, and integration with downstream systems
- Storage: Conversation history, training data, and audit logs
These supporting systems can consume 30-50% of total compute resources, adding hidden costs to both self-hosted and API-based deployments.
Redundancy and disaster recovery requirements double infrastructure costs for production systems. Organizations need:
- Geographic redundancy: Multiple data centers or cloud regions
- Failover systems: Backup inference endpoints and automatic failover
- Data replication: Synchronized model weights and configuration across locations
- Testing infrastructure: Staging environments for validating updates before production deployment
Compliance and security costs vary by industry and jurisdiction:
- Data residency: Geographic restrictions may require specific infrastructure locations
- Audit requirements: Logging, retention, and reporting capabilities
- Certification costs: SOC 2, ISO 27001, HIPAA, or industry-specific compliance
- Legal review: Contract negotiation, terms-of-service analysis, and risk assessment
The hidden cost multiplier typically ranges from 1.5x to 3x the apparent infrastructure or API costs. A self-hosted deployment with $200,000 in hardware costs often requires $300,000-$600,000 in total annual spending when accounting for labor, monitoring, redundancy, and compliance. Similarly, $500,000 in annual API costs often grows to $750,000-$1,500,000 when including integration labor, monitoring tools, and supporting infrastructure.
Organizations frequently underestimate:
- Engineering time for initial deployment (3-6 months for production-ready systems)
- Ongoing maintenance burden (20-40% of one engineer’s time)
- Cost of experimentation and failed iterations
- Compliance and security requirements specific to their industry
Organizations frequently overestimate:
- Complexity of API integration (often simpler than anticipated)
- Difficulty of migrating between providers (standardized APIs reduce lock-in)
- Cost of scaling API usage (volume discounts often available)
Understanding the open-source AI surge and how models like DeepSeek are disrupting proprietary dominance helps contextualize these cost trade-offs within broader industry trends.
How Does Deployment Complexity Impact Total Cost of Ownership?
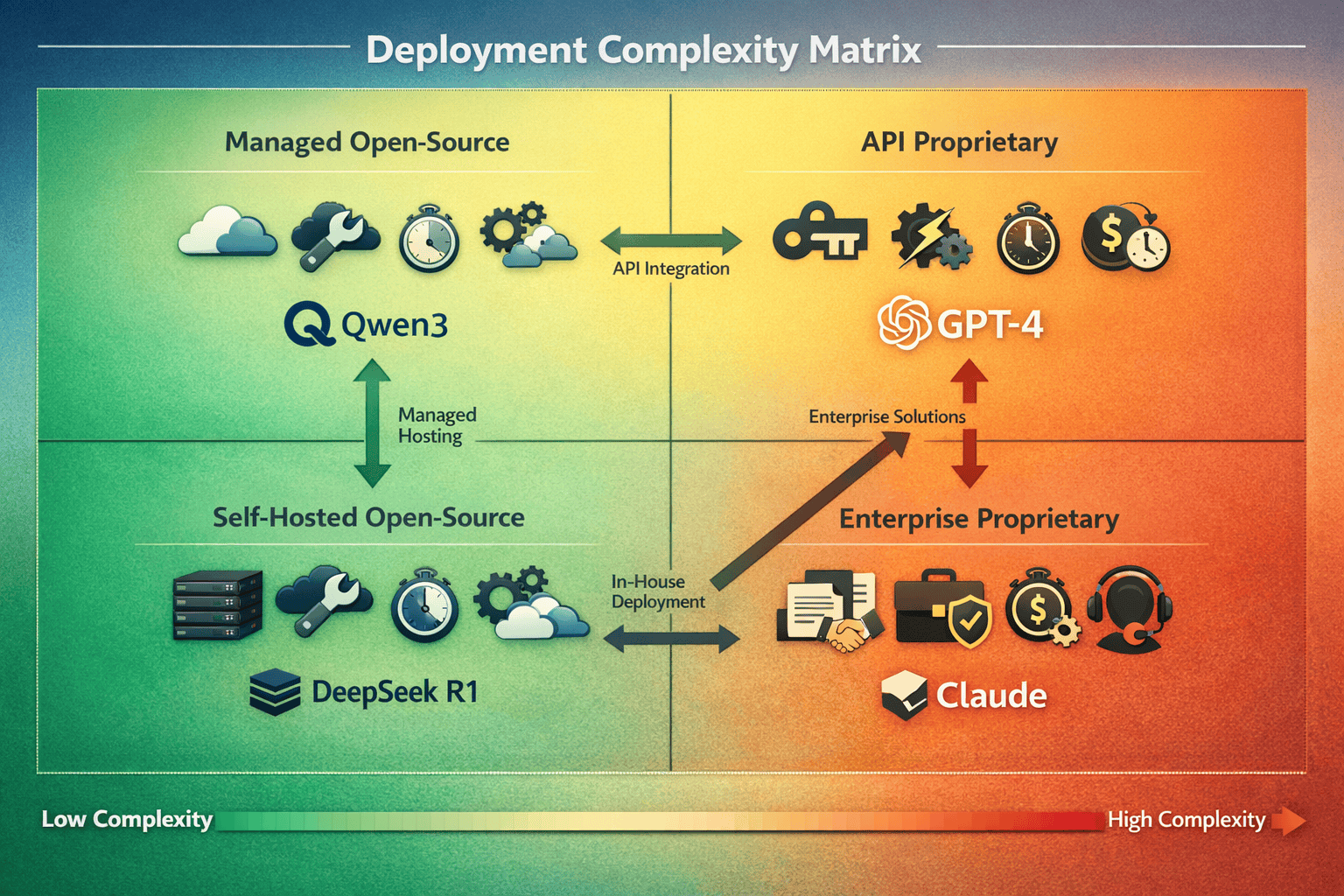
Deployment complexity directly influences total cost of ownership through engineering time, time-to-market delays, and ongoing maintenance requirements. The operational burden of managing LLM infrastructure varies dramatically between deployment models and significantly impacts the economic equation.
API-based proprietary models offer the simplest deployment path. Organizations can typically achieve production deployment in 2-6 weeks through:
- API key acquisition: Sign up for service and obtain authentication credentials (1 day)
- Integration development: Build application logic to call API endpoints (1-3 weeks)
- Testing and validation: Verify output quality and performance characteristics (1-2 weeks)
- Production deployment: Launch with monitoring and error handling (1 week)
This streamlined path requires minimal infrastructure expertise and allows small teams to deploy sophisticated AI capabilities quickly. The simplicity comes at the cost of less control over model behavior, limited customization options, and ongoing per-token charges.
Self-hosted open-source models require significantly more deployment effort:
- Infrastructure provisioning: Acquire hardware or cloud resources, configure networking (2-4 weeks)
- Model deployment: Download model weights, configure inference servers, optimize performance (2-3 weeks)
- Integration development: Build application interfaces and API layers (2-4 weeks)
- Load balancing and scaling: Implement request routing and auto-scaling (1-2 weeks)
- Monitoring and alerting: Deploy observability tools and configure dashboards (1-2 weeks)
- Security hardening: Implement access controls, audit logging, and compliance measures (2-3 weeks)
- Testing and validation: Performance testing, quality validation, and failure mode analysis (2-4 weeks)
Total deployment timeline for self-hosted solutions typically ranges from 12-22 weeks, requiring dedicated engineering resources with ML infrastructure expertise. This extended timeline delays time-to-market and increases opportunity costs.
Ongoing maintenance requirements differ substantially:
Proprietary API maintenance (low complexity):
- Monitor API usage and costs
- Handle API version updates and deprecations
- Manage authentication and access controls
- Track output quality and adjust prompts as needed
Self-hosted maintenance (high complexity):
- Apply security patches and system updates
- Monitor infrastructure health and performance
- Manage capacity planning and scaling
- Update model versions and migrate workloads
- Maintain redundancy and disaster recovery systems
- Optimize inference performance and cost efficiency
The complexity tax manifests as ongoing engineering allocation. Proprietary APIs typically require 5-15% of one engineer’s time for ongoing management, while self-hosted deployments consume 40-100% of a dedicated engineer’s capacity depending on scale and sophistication.
Choose simple API deployment if:
- Time-to-market is critical (weeks vs months matter)
- Engineering team lacks ML infrastructure experience
- Organization prefers operational expenses over capital investment
- Workload is unpredictable or highly variable
- Focus should remain on application logic rather than infrastructure
Choose complex self-hosted deployment if:
- Cost optimization justifies engineering investment
- Team has existing ML infrastructure expertise
- Data governance requires on-premises or private cloud deployment
- Customization needs exceed API provider capabilities
- Long-term strategic value justifies upfront complexity
For organizations seeking middle-ground options, managed cloud services offer pre-configured deployments of open-source models with simplified operations. Understanding the small model revolution and lightweight LLM deployment strategies can also reduce infrastructure complexity while maintaining cost advantages.
What Are the Licensing and Legal Considerations for TCO?
Licensing terms significantly impact total cost of ownership through usage restrictions, liability exposure, and long-term strategic flexibility. The legal framework governing LLM deployment often creates hidden costs or constraints that surface only after initial deployment.
Open-source models employ permissive licenses that maximize deployment flexibility:
DeepSeek R1 uses the MIT License, which provides:
- Unrestricted commercial use without licensing fees
- Permission to modify and redistribute the model
- Minimal liability for the model creators
- No patent grant protections
- Simple, well-understood legal framework[1]
Qwen3 employs Apache 2.0 with patent grant protection, offering:
- Unrestricted commercial use without licensing fees
- Explicit patent grants protecting users from patent claims
- Permission to modify and redistribute
- More comprehensive legal protections than MIT
- Industry-standard open-source framework[1]
These permissive licenses eliminate recurring licensing costs and enable unrestricted self-hosting, fine-tuning, and commercial deployment. Organizations can modify models, create derivatives, and deploy at any scale without additional fees or approval processes.
Proprietary models operate under restrictive terms-of-service that create ongoing obligations:
- Usage restrictions: Prohibited use cases, content policies, and acceptable use guidelines
- Competitive restrictions: Limitations on using outputs to train competing models
- Data rights: Provider claims to training data or usage telemetry
- Pricing changes: Unilateral right to modify pricing with limited notice
- Service termination: Provider can discontinue service or change terms
- Liability limitations: Extensive disclaimers limiting provider responsibility
The legal risk profile differs substantially. Open-source deployments place full liability on the deploying organization—if the model generates harmful outputs, the organization bears responsibility. Proprietary API services include liability limitations but may offer indemnification for certain use cases under enterprise contracts.
Enterprise contracts for proprietary models often include:
- Minimum spending commitments: $100,000-$1,000,000+ annual minimums
- Volume discounts: Tiered pricing based on usage levels
- Service level agreements: Uptime guarantees and performance commitments
- Support packages: Dedicated account management and technical support
- Custom terms: Negotiated usage rights, data handling, and compliance provisions
These contract terms create hidden costs through minimum commitments that may exceed actual usage, early termination fees, and legal review expenses. Organizations should budget $10,000-$50,000 for legal review of enterprise AI contracts.
Data governance and compliance requirements often determine deployment options:
- GDPR compliance: EU data residency and processing requirements may prohibit certain API services
- HIPAA requirements: Healthcare data restrictions often require self-hosted deployments
- Financial regulations: Banking and finance sectors face strict data handling rules
- Government contracts: Public sector deployments may require domestic infrastructure
- Export controls: Some jurisdictions restrict AI model deployment or transfer
The licensing choice impacts strategic flexibility. Organizations deploying open-source models can:
- Switch between deployment environments without renegotiating contracts
- Migrate to different infrastructure providers without vendor lock-in
- Create custom derivatives for specific use cases
- Deploy across multiple geographic regions without additional licensing
- Maintain operations even if the original model creator ceases support
Proprietary models create vendor dependencies that limit flexibility and create switching costs. Organizations deeply integrated with GPT-5 or Claude Opus 4.5 APIs face substantial re-engineering costs to migrate to alternatives.
A critical edge case: Organizations building AI products for resale must carefully review licensing terms. Some proprietary services prohibit using outputs in commercial products or training competing models, while open-source licenses enable unrestricted commercial applications.
For organizations navigating these choices, comparing enterprise AI adoption patterns between Claude Opus 4.5 and GPT-5 reveals how licensing terms influence corporate decision-making.
How Do You Calculate Your Specific TCO for Open vs Closed LLMs?
Calculating your organization’s specific total cost of ownership requires mapping your usage patterns, infrastructure capabilities, and strategic requirements to the cost models of different deployment options. A structured TCO calculation reveals the true economic trade-offs for your specific situation.
Step 1: Estimate your monthly token volume
Track or project your token consumption across:
- Input tokens: User queries, prompts, and context
- Output tokens: Model responses and generated content
- Fine-tuning tokens: Custom training data volume
- Experimentation tokens: Testing, validation, and development usage
Most organizations underestimate total volume by 30-50% when they fail to account for retries, error handling, and development/staging environments. Multiply production estimates by 1.5-2x for realistic total volume.
Step 2: Calculate API-based costs
For proprietary models, calculate:
- Base inference costs: (Input tokens × input price) + (Output tokens × output price)
- Fine-tuning costs: Training tokens × fine-tuning price + storage fees
- Support and contracts: Enterprise agreement fees, minimum commitments
- Integration costs: Engineering time to build and maintain API integration
- Monitoring costs: Observability tools and cost tracking systems
Example calculation for 25 million tokens monthly:
- Input tokens: 15 million × $0.020 per million = $300
- Output tokens: 10 million × $0.080 per million = $800
- Fine-tuning: 50 million tokens × $0.100 per million = $5,000 (one-time)
- Integration: 80 hours × $150/hour = $12,000 (one-time)
- Monitoring: $500/month
- Monthly cost: $1,600 + $500 = $2,100 (after initial setup)
- Annual cost: $25,200 + $17,000 (setup) = $42,200
Step 3: Calculate self-hosted costs
For open-source models, calculate:
- Infrastructure costs: Hardware purchase or cloud instance fees
- Engineering labor: DevOps, ML engineers, and security specialists
- Power and facilities: Data center costs or cloud overhead
- Fine-tuning costs: Compute time and engineering effort
- Monitoring and tools: Observability platforms and supporting software
- Redundancy: Backup systems and disaster recovery
Example calculation for 25 million tokens monthly:
- Infrastructure: $200,000 (upfront) or $8,000/month (cloud)
- Engineering: 0.5 FTE × $180,000 annual = $90,000 annual = $7,500/month
- Monitoring: $1,000/month
- Fine-tuning: 40 hours compute × $3/hour = $120/month
- Monthly cost (cloud): $8,000 + $7,500 + $1,000 + $120 = $16,620
- Monthly cost (owned): $7,500 + $1,000 + $120 + $8,333 (amortized over 24 months) = $16,953
- Annual cost: ~$200,000
Step 4: Identify the breakeven point
Plot total costs across different volume levels to find where self-hosted becomes cheaper:
| Monthly Tokens | API Cost | Self-Hosted (Cloud) | Self-Hosted (Owned) | Winner |
|---|---|---|---|---|
| 5 million | $8,400 | $16,620 | $16,953 | API |
| 25 million | $42,200 | $16,620 | $16,953 | Self-hosted |
| 50 million | $84,400 | $17,120 | $17,453 | Self-hosted |
| 100 million | $168,800 | $18,620 | $18,953 | Self-hosted |
In this example, breakeven occurs around 15-20 million tokens monthly, where API costs exceed self-hosted total costs.
Step 5: Account for strategic factors
Adjust calculations for qualitative factors:
- Data sovereignty: Does compliance require self-hosting? (Add 100% weight to self-hosted)
- Customization needs: Extensive fine-tuning favors self-hosted (Add 20-40% value)
- Engineering expertise: Lack of ML infrastructure skills increases self-hosted risk (Add 30-50% to labor costs)
- Time-to-market: Urgent deployment favors API (Quantify delay cost)
- Strategic flexibility: Vendor lock-in concerns favor open-source (Difficult to quantify)
Step 6: Build a 24-month projection
Model costs over time accounting for:
- Volume growth: Token consumption typically grows 20-50% annually
- Price changes: API providers may adjust pricing; hardware costs decline over time
- Efficiency improvements: Model optimization reduces compute requirements
- Team scaling: Engineering headcount changes as infrastructure matures
Common TCO calculation mistakes:
- Ignoring engineering time: Labor often exceeds infrastructure costs
- Underestimating volume: Production usage typically exceeds projections by 50-100%
- Overlooking redundancy: Production systems require backup infrastructure
- Forgetting fine-tuning: Custom training costs can exceed inference costs
- Assuming linear scaling: Volume discounts and efficiency improvements change economics at scale
Use a TCO calculator template:
<code>MONTHLY COSTS:
─────────────────────────────────────────
API-Based Deployment:
Input tokens: [volume] × [price] = $____
Output tokens: [volume] × [price] = $____
Fine-tuning: [volume] × [price] = $____
Integration labor: [hours] × [rate] = $____
Monitoring: $____
Total Monthly: $____
Self-Hosted Deployment:
Infrastructure: $____ (amortized or cloud)
Engineering: [FTE] × [salary/12] = $____
Fine-tuning compute: [hours] × [rate] = $____
Monitoring: $____
Total Monthly: $____
Breakeven Volume: _____ million tokens
</code>Organizations can test different scenarios using platforms like MULTIBLY to compare AI model responses and validate performance before committing to infrastructure investments.
What Are Common Pitfalls When Choosing Between Open and Closed LLMs?
Organizations frequently make costly mistakes when evaluating open versus closed LLM deployments, often discovering problems only after significant investment. Understanding these common pitfalls helps avoid expensive missteps and ensures informed decision-making.
Pitfall #1: Focusing exclusively on per-token pricing
Many organizations compare headline API pricing against inference costs without accounting for total ownership expenses. A model with 90% lower per-token costs may actually cost more when including infrastructure, engineering, and operational overhead. Always calculate total cost of ownership across all expense categories.
Pitfall #2: Underestimating deployment complexity
Teams without ML infrastructure experience often assume self-hosting open-source models is straightforward. In reality, production deployments require expertise in distributed systems, GPU optimization, load balancing, and monitoring. Organizations should honestly assess internal capabilities before committing to self-hosted infrastructure.
Pitfall #3: Ignoring model performance differences
Not all models with similar parameter counts deliver equivalent quality. Qwen3’s superior benchmark performance compared to DeepSeek R1 despite fewer parameters[4] demonstrates that architecture and training methodology matter more than size. Poor model performance creates downstream costs through error handling, human review, and customer dissatisfaction that can exceed infrastructure savings.
Pitfall #4: Overlooking licensing restrictions
Proprietary API terms-of-service may prohibit specific use cases, competitive applications, or data handling practices critical to your business model. Organizations should review legal terms carefully before building dependencies on proprietary services. Similarly, open-source licenses require compliance with attribution and redistribution requirements.
Pitfall #5: Failing to plan for scale
Initial deployments at low volume may favor API services, but rapid growth can make self-hosted options dramatically cheaper. Organizations should model costs at 2x, 5x, and 10x current volume to understand how economics change with scale. Migrating from API to self-hosted mid-project introduces substantial re-engineering costs.
Pitfall #6: Neglecting data governance requirements
Compliance and regulatory requirements often constrain deployment options regardless of cost considerations. Healthcare organizations subject to HIPAA, financial institutions under banking regulations, and government contractors with data residency requirements may have no choice but to self-host. Identify compliance constraints early to avoid investing in infeasible options.
Pitfall #7: Assuming vendor stability
API providers can change pricing, modify terms-of-service, deprecate models, or even cease operations. Organizations building critical systems on proprietary APIs should plan for vendor changes and maintain migration options. Open-source models provide more stability since model weights remain accessible even if the original creator stops support.
Pitfall #8: Undervaluing engineering time
The opportunity cost of engineering resources often exceeds direct infrastructure expenses. Engineers building and maintaining self-hosted LLM infrastructure cannot work on product features, customer-facing improvements, or other business priorities. Organizations should quantify this opportunity cost when comparing deployment options.
Pitfall #9: Ignoring hybrid approaches
Many organizations assume they must choose exclusively between open and closed models. In practice, hybrid deployments using proprietary APIs for low-volume use cases and self-hosted models for high-volume workloads often deliver optimal economics. Similarly, starting with APIs while building self-hosted capabilities reduces time-to-market risk.
Pitfall #10: Overlooking model ecosystem maturity
Proprietary services often include extensive tooling, documentation, and community support that reduces integration effort. Open-source models may lack comprehensive documentation, require custom tooling, and offer limited community resources. The maturity of the surrounding ecosystem significantly impacts deployment success.
Red flags indicating wrong deployment choice:
- API costs growing faster than revenue: Suggests self-hosted economics may be better
- Engineering team spending >50% time on infrastructure: Indicates self-hosting overhead is too high
- Frequent model switching due to performance issues: Points to inadequate model evaluation
- Compliance violations or audit findings: Reveals deployment model doesn’t meet regulatory requirements
- Vendor lock-in preventing business opportunities: Suggests proprietary dependencies are too deep
Organizations can reduce these risks by comparing multiple AI models side-by-side before committing to specific deployment architectures, validating both performance and integration complexity with real workloads.
FAQ
What is the typical breakeven point between API and self-hosted LLM costs?
The breakeven point typically occurs between 15-40 million tokens monthly, depending on infrastructure costs and engineering labor rates. Organizations with existing ML infrastructure and DevOps expertise break even at lower volumes (15-20 million tokens), while those building infrastructure from scratch may not break even until 30-40 million tokens monthly when accounting for engineering time.
Can you mix API-based and self-hosted models in the same application?
Yes, hybrid deployments are increasingly common in 2026. Organizations often use proprietary APIs for low-volume or experimental features while deploying self-hosted open-source models for high-volume production workloads. This approach optimizes costs while maintaining deployment flexibility, though it increases architectural complexity.
How much does fine-tuning actually cost for DeepSeek R1 vs Qwen3?
Self-hosted fine-tuning for both models costs primarily in compute time and engineering effort. A typical fine-tuning run on 100 million tokens requires 24-48 hours on 4-8 GPUs, costing $400-$1,500 in cloud compute or $100-$400 on owned infrastructure. Proprietary alternatives charge $5,000-$20,000 for similar fine-tuning volumes, making self-hosted options 80-95% cheaper for frequent fine-tuning.
Which license is better: DeepSeek R1’s MIT or Qwen3’s Apache 2.0?
Apache 2.0 provides stronger legal protections through explicit patent grants that protect users from patent claims[1]. MIT License is simpler and more permissive but lacks patent protections. For commercial deployments, Apache 2.0 offers better legal coverage, making Qwen3’s licensing slightly more favorable for enterprise use.
Do open-source models require less GPU memory than proprietary alternatives?
Not necessarily. GPU memory requirements depend on model architecture and quantization rather than open vs closed status. Qwen3’s MoE architecture with only 22B active parameters requires less memory than DeepSeek R1’s 37B active parameters[4], but both can run on similar hardware with appropriate quantization. Proprietary APIs eliminate GPU memory concerns entirely by handling infrastructure.
How quickly can you deploy self-hosted models vs API services?
API-based proprietary services typically reach production in 2-6 weeks with minimal infrastructure expertise. Self-hosted open-source deployments require 12-22 weeks for production-ready systems including infrastructure setup, model deployment, monitoring, and security hardening. Organizations with existing ML infrastructure can reduce self-hosted timelines to 6-10 weeks.
What happens if an API provider discontinues a model you depend on?
API providers typically offer 6-12 months notice before deprecating models, requiring migration to newer versions or alternative models. This creates re-engineering costs for prompt optimization, output validation, and integration updates. Self-hosted open-source models eliminate this risk since model weights remain accessible indefinitely, though organizations still need to manage security updates.
Can small teams realistically self-host models like DeepSeek R1 or Qwen3?
Teams of 2-3 engineers with ML infrastructure experience can successfully self-host these models, particularly using cloud-based GPU instances that reduce infrastructure complexity. However, teams lacking DevOps expertise or GPU optimization skills often underestimate operational burden. Small teams should start with managed services or API deployments until reaching sufficient scale to justify dedicated infrastructure.
How do data transfer costs impact self-hosted vs API economics?
API-based deployments incur data transfer costs for every request and response, typically $0.01-$0.10 per GB depending on provider. Self-hosted deployments eliminate external data transfer but may incur costs between application servers and GPU instances. For high-throughput applications, data transfer can add 10-30% to API costs, improving self-hosted economics.
What’s the cost difference for multi-region deployments?
API services charge identical per-token rates across regions, making global deployment simple but potentially expensive. Self-hosted deployments require duplicating infrastructure in each region, roughly doubling or tripling infrastructure costs for 2-3 region deployments. However, self-hosted multi-region costs remain fixed regardless of volume, while API costs scale linearly.
Do open-source models require more frequent updates than proprietary APIs?
Open-source models require manual updates when new versions release, while API services automatically deploy updates (sometimes introducing breaking changes). Organizations self-hosting typically update models every 3-6 months to incorporate improvements, requiring testing and validation. API services handle updates transparently but may force migrations to new versions on provider timelines.
How does Qwen3’s superior benchmark performance impact real-world TCO?
Qwen3’s 92.3% accuracy on AIME 2025 versus DeepSeek R1’s 80%[1] reduces downstream error handling costs by approximately 60%. For applications requiring high accuracy, this performance advantage reduces human review time, retry logic, and customer support costs that can exceed infrastructure expenses. Organizations should quantify error costs when comparing models.
Conclusion
The question of Open vs Closed: The Total Cost of Ownership for DeepSeek R1, Qwen3, and Proprietary LLMs in 2026 has no universal answer. The optimal choice depends on your specific token volume, engineering capabilities, compliance requirements, and strategic priorities. Organizations processing fewer than 20 million tokens monthly typically find API-based proprietary models more cost-effective when accounting for engineering time and infrastructure complexity. Above this threshold, self-hosted open-source alternatives like DeepSeek R1 and Qwen3 deliver substantial cost savings—often 80-90%—for teams with appropriate technical expertise.
The financial equation extends far beyond simple per-token pricing. Infrastructure costs, engineering labor, fine-tuning expenses, monitoring overhead, and compliance requirements create a complex total cost of ownership picture that demands careful analysis. Organizations that focus exclusively on headline pricing without accounting for hidden costs frequently experience budget overruns or deployment failures.
Performance differences matter as much as cost. Qwen3’s superior benchmark results despite smaller size demonstrate that architectural efficiency and training methodology often deliver better value than raw parameter counts. The downstream cost savings from higher accuracy—reduced error handling, less human review, fewer retries—can offset infrastructure expenses and shift the economic balance.
Actionable next steps:
- Calculate your specific TCO using the framework in this guide, accounting for all cost categories including hidden expenses
- Measure your actual token volume across development, staging, and production environments to understand true consumption patterns
- Assess your team’s ML infrastructure capabilities honestly to determine whether self-hosting is realistic
- Test model performance with your specific use cases before committing to deployment infrastructure
- Start with API services if time-to-market is critical, then evaluate self-hosted economics as volume grows
- Plan for hybrid deployments that optimize costs by matching deployment models to workload characteristics
- Review licensing terms carefully to ensure your deployment model aligns with compliance requirements and business objectives
Organizations can accelerate this evaluation process by using platforms like MULTIBLY to access and compare 300+ AI models including both open-source and proprietary options, validating performance and integration complexity before committing to specific deployment architectures.
The landscape continues evolving rapidly. The open-source AI surge demonstrates that models like DeepSeek R1 and Qwen3 increasingly match or exceed proprietary alternatives in capability while offering dramatically better economics at scale. Organizations that carefully analyze their specific requirements and calculate true total cost of ownership will make informed decisions that optimize both performance and financial outcomes.
References
[1] Deepseek R1 Vs Qwen 3 Vs Mistral Large Comparison – https://www.digitalapplied.com/blog/deepseek-r1-vs-qwen-3-vs-mistral-large-comparison
[2] Qwen3 Max Vs Deepseek R1 Distill Qwen 14b – https://artificialanalysis.ai/models/comparisons/qwen3-max-vs-deepseek-r1-distill-qwen-14b
[3] The Big Llm Architecture Comparison – https://magazine.sebastianraschka.com/p/the-big-llm-architecture-comparison
[4] Open Source Vs Closed Llms Choosing The Right Model In 2026 – https://www.letsdatascience.com/blog/open-source-vs-closed-llms-choosing-the-right-model-in-2026
[5] Top 10 Open Source Reasoning Models In 2026 – https://www.clarifai.com/blog/top-10-open-source-reasoning-models-in-2026
[6] Best Llm – https://zapier.com/blog/best-llm/
[7] Best Open Source Models February 2026 – https://whatllm.org/blog/best-open-source-models-february-2026
[8] Best Open Source Llms 2025 – https://www.siliconflow.com/articles/en/best-open-source-LLMs-2025
[9] Navigating The World Of Open Source Large Language Models – https://www.bentoml.com/blog/navigating-the-world-of-open-source-large-language-models
[10] Top 11 Llm Api Providers In 2026 – https://futureagi.substack.com/p/top-11-llm-api-providers-in-2026
Our Fact Checking Process
We prioritize accuracy and integrity in our content. Here's how we maintain high standards:
- Expert Review: All articles are reviewed by subject matter experts.
- Source Validation: Information is backed by credible, up-to-date sources.
- Transparency: We clearly cite references and disclose potential conflicts.
Our Review Board
Our content is carefully reviewed by experienced professionals to ensure accuracy and relevance.
- Qualified Experts: Each article is assessed by specialists with field-specific knowledge.
- Up-to-date Insights: We incorporate the latest research, trends, and standards.
- Commitment to Quality: Reviewers ensure clarity, correctness, and completeness.
Look for the expert-reviewed label to read content you can trust.



