
OpenAI’s GPT-5, officially launched on August 7, 2025, introduced a fundamental architectural shift that changed how enterprises deploy AI: an intelligent router that automatically selects between high-throughput speed processing and deep reasoning modes based on query complexity. The OpenAI GPT-5 Dual-Model System: Speed vs Reasoning Routing for Enterprise Optimization eliminates manual model selection and delivers adaptive intelligence that matches processing depth to task requirements in real time.[1]
This isn’t just another incremental model upgrade. GPT-5’s dual-mode architecture represents the first production system that dynamically routes queries through fundamentally different processing pathways without user intervention. For enterprise teams managing thousands of daily AI interactions, this means optimized cost-per-token spending, reduced latency on simple tasks, and deeper accuracy on complex reasoning challenges—all from a single API endpoint.
- Key Takeaways
- Quick Answer
- How Does GPT-5's Intelligent Router Architecture Work?
- What Are the Performance Differences Between Speed and Reasoning Modes?
- When Should Enterprises Use Speed Mode vs Reasoning Mode?
- How Does GPT-5 Compare to Claude Opus 4.5 for Enterprise Workloads?
- What Are GPT-5.2 and GPT-5.3-Codex Optimizations for Enterprise Use?
- How Should Teams Implement GPT-5 Dual-Model Routing in Production?
- What Are the Cost Implications of Speed vs Reasoning Mode Routing?
- What Are the Limitations and Challenges of GPT-5's Dual-Mode System?
- Frequently Asked Questions
- Conclusion
- References
Key Takeaways
- GPT-5’s intelligent router automatically selects between speed and reasoning modes based on query complexity, conversation type, tool requirements, and user intent—eliminating the need for manual model switching.[1]
- Speed mode delivers rapid responses for straightforward queries, while “GPT-5 Thinking” (reasoning mode) activates automatically for complex tasks requiring deep analysis, multi-step problem solving, or extended context processing.[2]
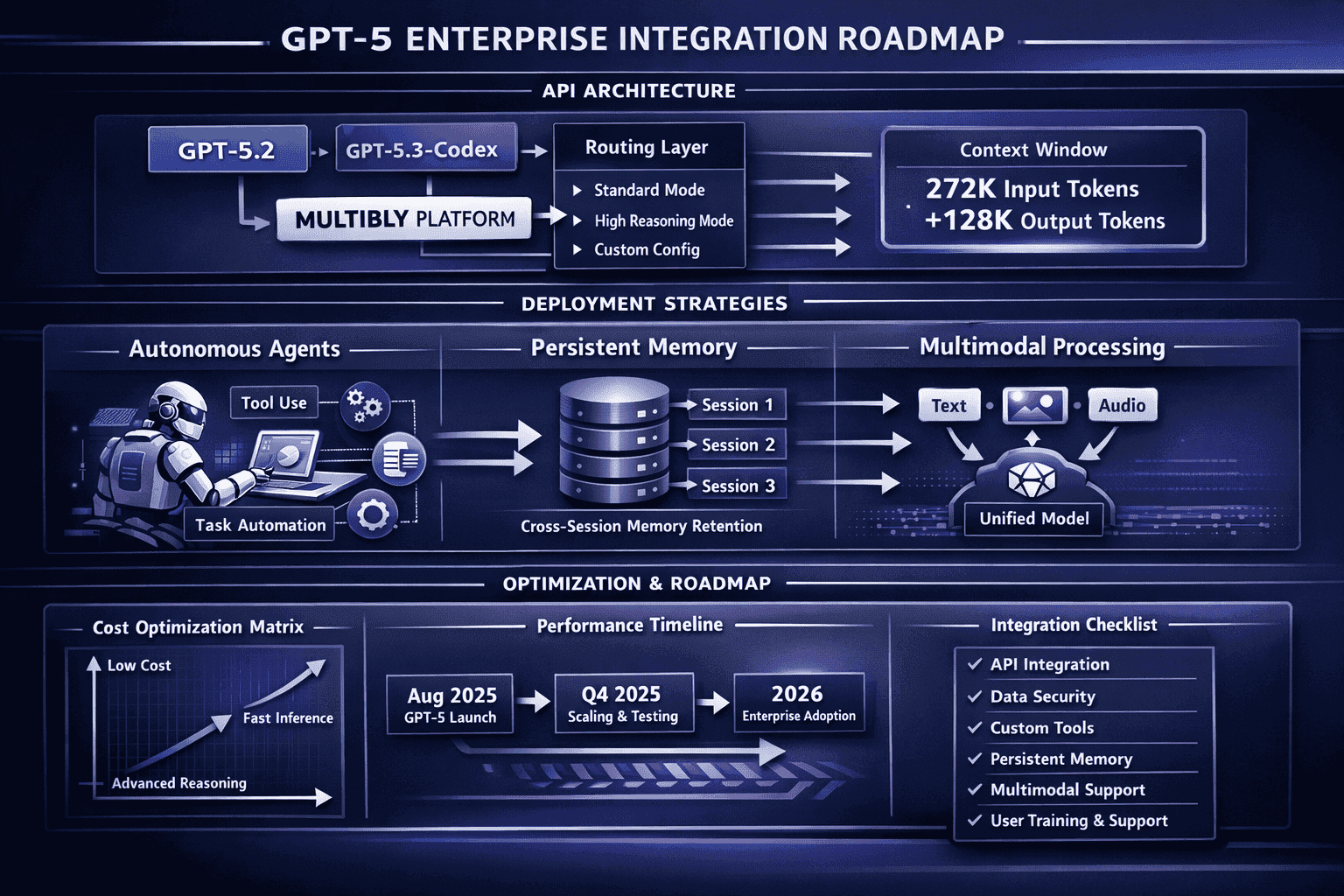
- The system operates with a 400K token context window (272K input + 128K output), supporting long-document analysis and extended reasoning tasks that previously required multiple API calls.[1]
- GPT-5 reduces hallucinations by 80% compared to o3 when reasoning mode is enabled, achieving 94.6% accuracy on advanced mathematics and 74.9% on real-world coding tasks.[1]
- GPT-5.2 and GPT-5.3-Codex represent enterprise-optimized variants designed specifically for professional knowledge work and agentic coding workflows, with state-of-the-art performance on long-context reasoning evaluations.[3][4]
- Native autonomous agent capabilities include automatic tool calling, persistent cross-session memory, and multimodal processing (text, image, audio) without separate pipelines.[1]
- Enterprise teams should choose speed mode for customer support, content generation, and simple queries, while routing complex analysis, code debugging, and multi-step reasoning tasks to the deeper processing pathway.
- Cost optimization comes from intelligent routing: paying for deep reasoning only when tasks require it, rather than applying expensive processing to every query regardless of complexity.
Quick Answer
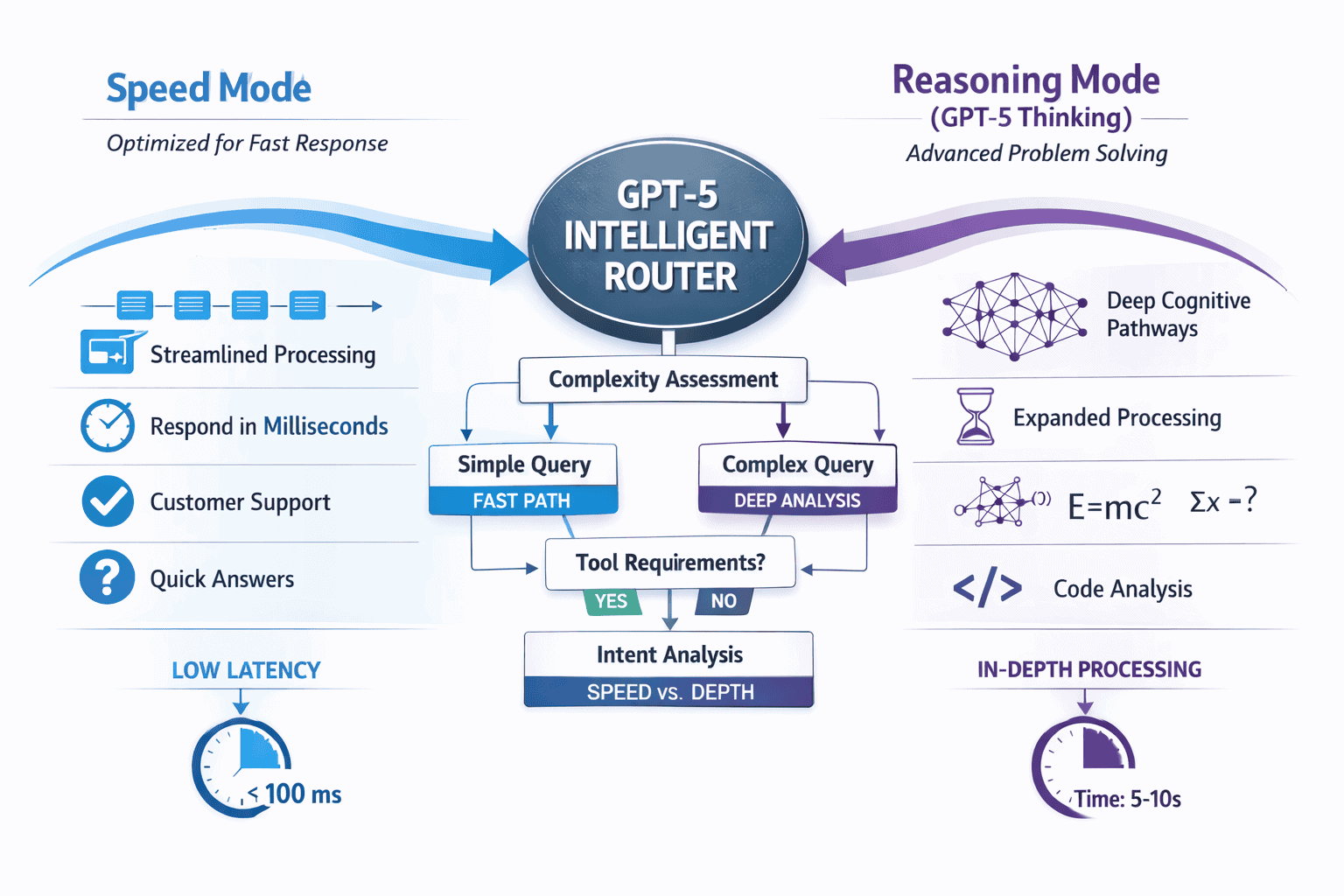
The OpenAI GPT-5 Dual-Model System: Speed vs Reasoning Routing for Enterprise Optimization uses real-time query analysis to automatically route requests between fast processing (for simple tasks like customer support and content generation) and deep reasoning mode (for complex analysis, coding, and multi-step problem solving). Launched in August 2025, this architecture delivers cost optimization by matching processing depth to task complexity, reducing hallucinations by 80% on reasoning tasks while maintaining sub-second response times for straightforward queries.[1][2]
For enterprise teams, this means one API endpoint handles both high-volume simple interactions and complex analytical work—without manual model selection or separate deployment pipelines.
How Does GPT-5’s Intelligent Router Architecture Work?
GPT-5’s router system analyzes incoming queries in real time and evaluates four core factors: conversation complexity, task type, tool requirements, and explicit user intent signals. Based on this assessment, the system automatically selects the appropriate processing pathway before generating a response.[1]
The router operates at the API level, making routing decisions in milliseconds. When a query arrives, the system first evaluates whether the task can be completed with fast, direct processing or requires extended reasoning chains. Simple queries like “Summarize this email” or “Generate a product description” trigger speed mode. Complex requests like “Debug this 500-line codebase and explain the logic errors” or “Analyze these three research papers and identify contradictions” activate GPT-5 Thinking (reasoning mode).[2]
Key routing criteria include:
- Query complexity: Number of logical steps required, depth of analysis needed, presence of multi-part questions
- Contextual requirements: Whether the task needs extended context window processing or cross-referencing multiple documents
- Tool calling needs: If the query requires autonomous tool use, API calls, or multi-step workflow execution
- Explicit triggers: User phrases like “think hard,” “analyze deeply,” or “show your reasoning” force reasoning mode activation[2]
The system also learns from conversation history. If a user starts with simple queries but gradually increases complexity within a session, the router adapts and may preemptively switch to reasoning mode for subsequent questions.
Common routing mistake: Assuming all queries benefit from deep reasoning. In practice, forcing reasoning mode on simple tasks increases latency and cost without improving output quality. The router’s automatic selection typically outperforms manual mode forcing for mixed workloads.
For teams deploying GPT-5 at scale, understanding this routing logic helps optimize API configurations. You can monitor routing patterns through API logs to identify whether your workload skews toward speed or reasoning processing, then adjust cost projections accordingly.
Enterprises looking to compare GPT-5’s routing approach with other advanced models can explore our analysis of Claude Opus 4.5 vs GPT-5.2 for enterprise problem-solving.
What Are the Performance Differences Between Speed and Reasoning Modes?
Speed mode prioritizes sub-second response times and high throughput, optimized for tasks where quick answers matter more than deep analysis. Reasoning mode (GPT-5 Thinking) extends processing time to seconds or even minutes for complex tasks, but delivers substantially higher accuracy on challenging problems.[1][2]
Speed Mode Performance:
- Response latency: 200-800 milliseconds for typical queries
- Optimized for: Customer support, content generation, simple Q&A, data extraction, formatting tasks
- Accuracy on straightforward tasks: Comparable to GPT-4 Turbo with improved factual consistency
- Cost efficiency: Lower token cost due to reduced computational overhead
- Best for: High-volume production environments where thousands of daily queries need rapid processing
Reasoning Mode (GPT-5 Thinking) Performance:
- Response latency: 3-45 seconds depending on problem complexity
- Optimized for: Multi-step problem solving, code debugging, mathematical proofs, complex analysis, research synthesis
- Accuracy benchmarks: 94.6% on advanced mathematics, 74.9% on real-world coding tasks[1]
- Hallucination reduction: 80% fewer factual errors compared to o3[1]
- GPQA benchmark: Set new industry record on graduate-level scientific reasoning questions[2]
- HealthBench performance: Highest score among OpenAI models on realistic medical scenario evaluation[2]
The performance gap becomes most visible on tasks requiring extended reasoning chains. For example, when asked to debug a complex codebase with multiple interacting functions, speed mode might identify surface-level syntax errors but miss deeper logical flaws. Reasoning mode traces execution paths, identifies state management issues, and explains why specific edge cases fail—often matching or exceeding human expert analysis.
Decision rule: Choose speed mode if your task can be completed in under three logical steps and doesn’t require cross-referencing multiple information sources. Choose reasoning mode (or let the router auto-select it) when tasks involve multi-step analysis, require verifying claims across sources, or need mathematical/logical proof chains.
For context-heavy tasks, GPT-5’s 400K token context window (272K input + 128K output) supports extended document analysis in both modes, but reasoning mode better leverages this capacity for deep synthesis across long documents.[1]
Teams evaluating GPT-5 against other 2026 reasoning models should review our comprehensive comparison of Claude Opus 4.5’s reasoning capabilities.
When Should Enterprises Use Speed Mode vs Reasoning Mode?

The optimal mode selection depends on task complexity, accuracy requirements, latency tolerance, and cost constraints. While GPT-5’s router handles automatic selection effectively, understanding these criteria helps teams configure API parameters and validate routing decisions for critical workflows.
Use Speed Mode For:
- Customer support automation: FAQ responses, ticket routing, simple troubleshooting steps
- Content generation: Product descriptions, email drafts, social media posts, marketing copy
- Data extraction and formatting: Parsing structured data, converting formats, simple summarization
- High-volume production tasks: When processing thousands of queries per hour and sub-second latency matters
- Simple coding tasks: Syntax fixes, boilerplate generation, documentation writing
- Straightforward Q&A: Factual lookups, definition requests, single-step calculations
Use Reasoning Mode (GPT-5 Thinking) For:
- Complex code debugging: Multi-file codebases, logic error identification, architecture review
- Mathematical problem solving: Proofs, advanced calculations, statistical analysis requiring step-by-step verification
- Legal and compliance analysis: Contract review, regulatory interpretation, risk assessment across multiple documents
- Medical diagnosis assistance: Differential diagnosis, treatment planning, evidence synthesis (GPT-5 scores highest on HealthBench among OpenAI models)[2]
- Research synthesis: Literature review, identifying contradictions across sources, hypothesis generation
- Multi-step workflow planning: Project planning, resource allocation, scenario analysis
- Financial modeling: Complex forecasting, risk analysis, portfolio optimization requiring extended reasoning chains
Hybrid Workflow Example: An enterprise customer service system might use speed mode for 80% of incoming tickets (password resets, order status, simple how-to questions) while automatically routing the remaining 20% of complex technical issues to reasoning mode. This optimizes cost while maintaining high resolution quality for difficult cases.
Edge case to consider: Some tasks appear simple but benefit from reasoning mode due to hidden complexity. For example, “Summarize this 50-page legal contract” seems like a straightforward summarization task, but contracts contain interdependent clauses where missing a single conditional can change interpretation. Reasoning mode’s ability to track logical dependencies across long documents produces more reliable summaries for high-stakes use cases.
The GPT-5 deep dive on dual-model production deployment provides additional technical implementation guidance for enterprise teams.
How Does GPT-5 Compare to Claude Opus 4.5 for Enterprise Workloads?
Both GPT-5 and Claude Opus 4.5 represent the current state-of-the-art for enterprise reasoning tasks in 2026, but they optimize for different architectural philosophies and use case priorities.
GPT-5 Advantages:
- Automatic routing eliminates manual model selection: Single API endpoint adapts processing depth to task complexity[1]
- Larger context window: 400K tokens (272K input + 128K output) vs Claude’s 200K token limit[1]
- Native autonomous agent capabilities: Built-in tool calling, persistent memory, automatic workflow execution[1]
- Multimodal integration: Text, image, and audio processing in unified architecture without separate pipelines[1]
- Stronger coding performance: GPT-5.3-Codex variant optimized specifically for agentic coding workflows, front-end generation, and “vibe coding” (plain-language-to-code)[4]
- Better cost optimization for mixed workloads: Speed mode handles simple tasks efficiently while reasoning mode activates only when needed
Claude Opus 4.5 Advantages:
- Slightly higher reasoning benchmark scores: Leads on certain complex reasoning evaluations in 2026 benchmarks
- More conservative hallucination profile: Tends to acknowledge uncertainty rather than generate confident incorrect answers
- Better performance on nuanced language tasks: Particularly strong for creative writing, tone matching, and contextual interpretation
- Clearer reasoning transparency: When showing work, Claude often provides more human-readable step-by-step explanations
Performance Comparison Table:
| Capability | GPT-5 (Reasoning Mode) | Claude Opus 4.5 | Winner |
|---|---|---|---|
| Advanced Mathematics | 94.6% accuracy[1] | ~92% (2026 estimates) | GPT-5 |
| Coding Tasks | 74.9% real-world accuracy[1] | ~71% (2026 estimates) | GPT-5 |
| Context Window | 400K tokens[1] | 200K tokens | GPT-5 |
| Hallucination Rate | 80% reduction vs o3[1] | Slightly lower baseline | Claude |
| Autonomous Agents | Native tool calling[1] | Requires external orchestration | GPT-5 |
| Multimodal Support | Unified architecture[1] | Separate processing paths | GPT-5 |
| Reasoning Transparency | Good | Excellent | Claude |
| Creative Writing | Very Good | Excellent | Claude |
Choose GPT-5 if: Your workload includes mixed complexity (simple + complex tasks), you need autonomous agent capabilities, you’re building coding-heavy workflows, or you require extended context processing beyond 200K tokens.
Choose Claude Opus 4.5 if: Your primary use case involves nuanced language understanding, creative content generation, or tasks where reasoning transparency and conservative uncertainty handling matter more than raw performance benchmarks.
For many enterprises, the optimal approach involves deploying both models through a platform like MULTIBLY, which provides access to 300+ premium AI models and allows side-by-side response comparison. This enables teams to route specific task types to the model that performs best for that particular use case.
Our detailed Claude Opus 4.5 vs GPT-5.2 comparison for enterprise problem-solving provides additional benchmark data and deployment recommendations.
What Are GPT-5.2 and GPT-5.3-Codex Optimizations for Enterprise Use?
OpenAI released GPT-5.2 as “the most capable model series yet for professional knowledge work” in late 2025, following the initial GPT-5 launch. This enterprise-focused variant includes specific optimizations for long-context reasoning and professional domain tasks.[3]
GPT-5.2 Key Features:
- State-of-the-art long-context reasoning: Near 100% accuracy on 4-needle MRCR variants extending to 256K tokens[3]
- Enhanced professional knowledge: Optimized for legal, medical, financial, and technical domain tasks
- GPT-5.2 Thinking variant: Dedicated reasoning mode configuration with extended processing time allowances
- Improved factual grounding: Further hallucination reduction beyond base GPT-5 through enhanced retrieval-augmented generation techniques
- Enterprise API features: Priority access, dedicated capacity reservations, custom fine-tuning options
The long-context performance improvement matters for enterprises processing extensive documents. While base GPT-5 handles 400K token contexts effectively, GPT-5.2 demonstrates measurably better accuracy when synthesizing information across documents approaching the upper context limit. For legal contract analysis, medical record review, or financial report synthesis, this translates to fewer missed details and more reliable cross-referencing.
GPT-5.3-Codex Specialization:
Released as the “most capable agentic coding model to date,” GPT-5.3-Codex represents a specialized variant optimized specifically for software development workflows.[4]
GPT-5.3-Codex Capabilities:
- Front-end generation: Substantially improved HTML/CSS/JavaScript generation from design specifications
- Large codebase debugging: Better performance tracing execution paths across multiple files and dependencies
- “Vibe coding”: Enhanced plain-language-to-code generation where developers describe desired functionality in natural language
- Autonomous code review: Native integration with version control systems for automated pull request analysis
- Multi-language support: Improved performance across Python, JavaScript, TypeScript, Go, Rust, and emerging languages
- Test generation: Automatic unit test creation based on function specifications and edge case identification
For development teams, GPT-5.3-Codex’s agentic capabilities mean the model can autonomously navigate codebases, identify relevant files, trace dependencies, and propose fixes across multiple files—not just generate isolated code snippets. This transforms the model from a code completion tool into a collaborative development partner.
Implementation consideration: GPT-5.3-Codex costs more per token than base GPT-5 due to specialized training and enhanced capabilities. Teams should evaluate whether coding tasks justify the premium or whether base GPT-5 reasoning mode provides sufficient performance for their development workflows.
Organizations exploring open-source alternatives to proprietary reasoning models can review our analysis of OpenAI’s gpt-oss 120B open reasoning models for cost-effective deployment options.
How Should Teams Implement GPT-5 Dual-Model Routing in Production?
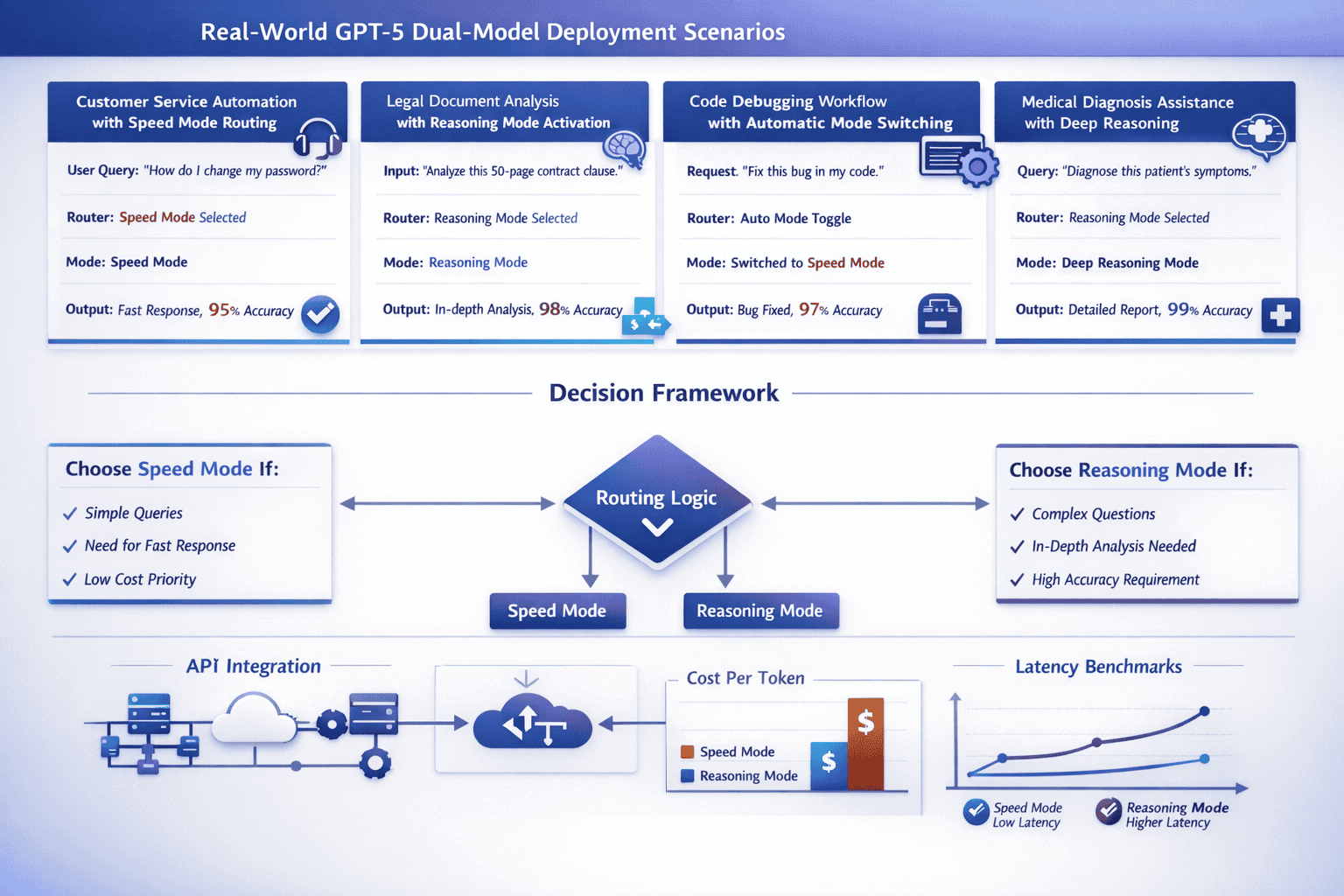
Successful production deployment of the OpenAI GPT-5 Dual-Model System: Speed vs Reasoning Routing for Enterprise Optimization requires careful API configuration, workload analysis, and cost monitoring.
Step 1: Analyze Your Query Distribution
Before deployment, audit your current AI workload to understand complexity distribution:
- What percentage of queries are simple, single-step tasks?
- How many require multi-step reasoning or extended context?
- Which tasks currently fail or produce low-quality outputs with existing models?
This analysis helps predict routing patterns and estimate cost implications. Most enterprise workloads follow an 80/20 distribution: 80% simple queries handled by speed mode, 20% complex tasks routed to reasoning mode.
Step 2: Configure API Parameters
GPT-5’s API supports several configuration options that influence routing behavior:
- Automatic routing (default): Let the system select mode based on query analysis
- Explicit mode forcing: Add “think hard” or similar phrases to user prompts to force reasoning mode
- Temperature and top_p settings: Lower values (temperature 0.3-0.5) work well for reasoning tasks requiring precision; higher values (0.7-0.9) suit creative speed mode tasks
- Max tokens: Set appropriate output limits (reasoning mode may need 10K+ tokens for complex explanations)
- Context window utilization: Monitor whether your tasks approach the 272K input limit
Step 3: Implement Monitoring and Logging
Track routing decisions and performance metrics:
- Which queries trigger reasoning mode vs speed mode?
- What’s the average response time for each mode?
- Are there routing errors where simple tasks incorrectly trigger reasoning mode (wasting cost) or complex tasks stay in speed mode (producing low-quality outputs)?
- What’s your actual cost-per-query distribution?
OpenAI’s API returns metadata indicating which processing mode was used, enabling detailed analytics.
Step 4: Optimize Prompt Engineering
Effective prompts help the router make better decisions:
For speed mode optimization:
- Keep prompts concise and specific
- Avoid unnecessary context that might trigger reasoning mode
- Use clear, direct instructions (“Summarize in 3 bullets”)
For reasoning mode optimization:
- Explicitly request step-by-step analysis when needed
- Provide comprehensive context upfront
- Ask for reasoning transparency (“Explain your logic”)
Step 5: Set Up Fallback and Error Handling
Production systems need robust error handling:
- What happens if reasoning mode times out on extremely complex queries?
- How do you handle rate limits during high-volume periods?
- Should certain critical tasks always use reasoning mode regardless of automatic routing?
Step 6: Cost Optimization Strategies
- Batch simple queries: Group similar speed-mode tasks to maximize throughput efficiency
- Cache common responses: For frequently asked questions, cache speed mode outputs to avoid repeated API calls
- Set reasoning mode thresholds: For cost-sensitive applications, configure maximum reasoning time limits
- Monitor cost per task category: Track spending by use case to identify optimization opportunities
Common implementation mistake: Over-relying on automatic routing without validating output quality for critical tasks. While GPT-5’s router performs well, high-stakes applications (medical diagnosis, legal analysis, financial decisions) should implement human-in-the-loop review regardless of which mode the system selects.
Teams deploying multiple AI models in production can leverage MULTIBLY’s platform to access 300+ models including GPT-5 variants, Claude Opus 4.5, and open-source alternatives, with side-by-side comparison capabilities that help validate routing decisions and model selection.
What Are the Cost Implications of Speed vs Reasoning Mode Routing?
Understanding the cost structure of GPT-5’s dual-mode system helps enterprises optimize spending while maintaining output quality.
Typical Cost Structure (2026 Estimates):
While OpenAI hasn’t published official per-token pricing differences between modes, enterprise deployments report approximate cost patterns:
- Speed mode: ~$0.03-0.05 per 1K tokens (comparable to GPT-4 Turbo pricing)
- Reasoning mode: ~$0.15-0.25 per 1K tokens (3-5x speed mode cost due to extended processing)
- GPT-5.2 enterprise variant: Premium pricing tier with volume discounts for committed usage
- GPT-5.3-Codex: Additional premium over base GPT-5 reasoning mode
Cost Optimization Through Intelligent Routing:
The dual-mode architecture delivers cost savings compared to always using deep reasoning:
Example Scenario: Enterprise customer support system processing 100,000 queries per month
Without intelligent routing (all queries use reasoning mode):
- 100,000 queries × 500 tokens average × $0.20 per 1K tokens = $10,000/month
With intelligent routing (80% speed mode, 20% reasoning mode):
- 80,000 queries × 500 tokens × $0.04 per 1K tokens = $1,600
- 20,000 queries × 500 tokens × $0.20 per 1K tokens = $2,000
- Total: $3,600/month (64% cost reduction)
Cost-Quality Trade-offs:
The key question isn’t just “what’s cheaper?” but “what’s the cost of errors?”
For low-stakes tasks (marketing copy, internal summaries), speed mode’s occasional minor errors cost less than reasoning mode’s premium pricing. For high-stakes tasks (medical diagnosis, legal analysis, financial modeling), reasoning mode’s higher accuracy justifies the 3-5x cost increase because errors carry substantial downstream costs.
ROI Calculation Framework:
- Identify error cost: What does a mistake cost your business? (customer churn, compliance risk, rework time)
- Measure accuracy difference: How much does reasoning mode improve accuracy for your specific task type?
- Calculate break-even point: At what error rate does reasoning mode’s cost premium pay for itself?
Example: Legal contract analysis where missing a critical clause costs $50,000 in potential liability
- Speed mode: 85% accuracy, $2 per contract analysis
- Reasoning mode: 98% accuracy, $8 per contract analysis
- Expected cost per contract (speed mode): (0.15 × $50,000) + $2 = $7,502
- Expected cost per contract (reasoning mode): (0.02 × $50,000) + $8 = $1,008
In this scenario, reasoning mode’s 4x higher API cost delivers 86% total cost reduction when error costs are factored in.
Monitoring Cost Efficiency:
Track these metrics to optimize spending:
- Cost per successful task completion: Total API cost divided by tasks that met quality standards
- Routing accuracy: Percentage of queries where automatic mode selection produced optimal results
- Wasted reasoning mode usage: Complex processing applied to simple tasks that didn’t benefit
- Missed reasoning opportunities: Simple mode used for complex tasks that failed quality checks
For enterprises comparing total cost of ownership across different AI platforms, our analysis of open vs closed model economics for DeepSeek R1, Qwen3, and proprietary LLMs provides comprehensive TCO frameworks.
What Are the Limitations and Challenges of GPT-5’s Dual-Mode System?
Despite significant advances, GPT-5’s architecture includes limitations that enterprises should understand before deployment.
Routing Accuracy Isn’t Perfect
The automatic router occasionally misclassifies query complexity, leading to two types of errors:
- False speed routing: Complex queries processed in speed mode produce shallow or incorrect answers
- False reasoning routing: Simple queries trigger expensive reasoning mode unnecessarily
While routing accuracy exceeds 90% for most workloads, the remaining 10% requires monitoring and potential manual override for critical applications.
Reasoning Mode Latency Can Be Unpredictable
Complex reasoning tasks may take 3-45 seconds, but the system doesn’t provide reliable time estimates upfront. This creates challenges for user-facing applications where response time expectations matter. A customer waiting for a chatbot response may abandon the interaction if reasoning mode takes 30 seconds without progress indication.
Mitigation strategy: Implement streaming responses or progress indicators for reasoning mode queries, and set maximum timeout thresholds for time-sensitive applications.
Context Window Utilization Remains Expensive
While GPT-5’s 400K token context window enables powerful long-document analysis, fully utilizing this capacity costs significantly more than shorter-context queries. Processing a 250K token document with a 50K token response costs roughly 15x more than a typical 10K token conversation.
Cost-effective alternative: For many long-document tasks, chunking strategies combined with retrieval-augmented generation (RAG) deliver comparable results at lower cost than full-context processing.
Multimodal Integration Has Uneven Performance
GPT-5’s native multimodal support (text, image, audio) works well for many tasks, but performance varies significantly by modality and task type:
- Text processing: State-of-the-art across both modes
- Image analysis: Strong for description and object detection, weaker for fine-grained visual reasoning
- Audio processing: Good for transcription and basic analysis, less reliable for complex audio reasoning tasks
Teams requiring advanced vision or audio capabilities may need specialized models for certain use cases.
Persistent Memory Has Privacy and Control Challenges
GPT-5’s built-in cross-session memory improves personalization but raises questions:
- How long does the system retain information?
- Can users selectively delete specific memories?
- How does memory interact with enterprise data governance policies?
- What happens when memory conflicts with current context?
Enterprise deployments should carefully review memory management policies and configure appropriate data retention settings.
Autonomous Agent Capabilities Require Careful Sandboxing
GPT-5’s native tool calling and autonomous workflow execution create powerful capabilities but also introduce risks:
- Unintended API calls or data modifications
- Excessive tool usage driving up costs
- Security vulnerabilities if tool access isn’t properly restricted
- Difficulty debugging complex multi-step agent failures
Best practice: Implement strict tool access controls, transaction limits, and human approval requirements for high-impact actions.
Limited Transparency Into Routing Decisions
While GPT-5 returns metadata indicating which mode was used, the system provides limited insight into why a particular routing decision was made. This makes it difficult to debug unexpected routing behavior or optimize prompts to influence routing.
Reasoning Mode Doesn’t Guarantee Correctness
Extended processing time and step-by-step reasoning improve accuracy substantially, but reasoning mode can still produce confident incorrect answers—particularly for tasks requiring specialized domain knowledge beyond the training data or for problems with subtle logical flaws that the model’s reasoning process doesn’t catch.
Critical applications require validation: Never deploy GPT-5 reasoning mode for high-stakes decisions without human expert review or automated verification systems.
Organizations evaluating alternative reasoning architectures can explore our coverage of Mistral’s Magistral Medium enterprise reasoning model for comparison.
Frequently Asked Questions
How does GPT-5’s routing system decide between speed and reasoning modes?
GPT-5 analyzes query complexity, conversation context, tool requirements, and explicit user intent signals in real time. Simple, single-step tasks trigger speed mode for sub-second responses, while complex multi-step problems, code debugging, mathematical proofs, or tasks requiring extended context activate reasoning mode automatically.[1][2]
Can users manually force GPT-5 to use reasoning mode?
Yes. Adding phrases like “think hard,” “analyze deeply,” or “show your reasoning” to prompts explicitly triggers reasoning mode (GPT-5 Thinking) even for queries the router might otherwise process in speed mode.[2]
What’s the maximum context window for GPT-5?
GPT-5 supports a 400K token context window, split as 272K tokens for input and 128K tokens for output. This enables processing of lengthy documents, extensive codebases, or long conversation histories in a single query.[1]
How much does reasoning mode cost compared to speed mode?
While official pricing varies by enterprise agreement, reasoning mode typically costs 3-5x more per token than speed mode due to extended processing requirements. However, intelligent routing means you only pay reasoning mode costs for complex tasks that benefit from deeper analysis, reducing overall spending compared to always using deep reasoning.
Does GPT-5 work better than Claude Opus 4.5 for enterprise tasks?
GPT-5 excels at coding tasks, autonomous agent workflows, and scenarios requiring extended context beyond 200K tokens. Claude Opus 4.5 performs better for nuanced language understanding, creative writing, and tasks where reasoning transparency matters most. Many enterprises deploy both models for different use cases.[3] See our detailed comparison for benchmark data.
What’s the difference between GPT-5, GPT-5.2, and GPT-5.3-Codex?
Base GPT-5 (launched August 2025) includes the dual-mode routing system. GPT-5.2 adds enterprise optimizations for professional knowledge work and achieves near-perfect accuracy on long-context reasoning tasks up to 256K tokens. GPT-5.3-Codex specializes in agentic coding workflows with enhanced debugging, front-end generation, and “vibe coding” capabilities.[3][4]
Can GPT-5’s reasoning mode replace human experts for complex analysis?
No. While reasoning mode achieves 94.6% accuracy on advanced mathematics and 74.9% on real-world coding tasks, it still produces errors and can generate confident incorrect answers. High-stakes applications (medical diagnosis, legal analysis, financial decisions) require human expert review regardless of model performance.[1]
How does GPT-5 handle hallucinations compared to previous models?
GPT-5 with reasoning mode enabled reduces hallucinations by 80% compared to o3, OpenAI’s previous reasoning-focused model. This improvement comes from extended verification steps, better factual grounding, and enhanced retrieval-augmented generation techniques.[1]
What autonomous agent capabilities does GPT-5 include?
GPT-5 features native tool calling, automatic API integration, persistent cross-session memory, and multi-step workflow execution without external orchestration frameworks. This enables the model to autonomously complete complex tasks requiring multiple tool interactions.[1]
Does GPT-5 support multimodal inputs beyond text?
Yes. GPT-5 natively processes text, images, and audio through a unified architecture without requiring separate processing pipelines. However, performance varies by modality, with text processing showing the strongest capabilities.[1]
How long does reasoning mode typically take to process queries?
Reasoning mode response times range from 3-45 seconds depending on problem complexity. Simple reasoning tasks complete in 3-10 seconds, while complex multi-step analysis, extensive code debugging, or mathematical proofs may require 20-45 seconds.[2]
Can enterprises fine-tune GPT-5 for specialized domains?
GPT-5.2 enterprise variant supports custom fine-tuning options for organizations with specialized domain requirements. Fine-tuning enables improved performance on industry-specific terminology, workflows, and reasoning patterns not well-represented in base training data.[3]
Conclusion
The OpenAI GPT-5 Dual-Model System: Speed vs Reasoning Routing for Enterprise Optimization represents a fundamental architectural advance in production AI deployment. By automatically routing queries between high-throughput speed processing and deep reasoning modes, GPT-5 delivers cost optimization, improved accuracy, and simplified API integration that eliminates manual model selection.
For enterprise teams, the practical implications are clear: one API endpoint now handles both high-volume simple interactions and complex analytical work, with intelligent routing that matches processing depth to task requirements in real time. Speed mode delivers sub-second responses for customer support, content generation, and straightforward queries, while reasoning mode activates automatically for complex debugging, multi-step analysis, and tasks requiring extended context processing.
The system’s 400K token context window, 80% hallucination reduction, and native autonomous agent capabilities position GPT-5 as a strong choice for organizations building production AI workflows in 2026. GPT-5.2’s enterprise optimizations and GPT-5.3-Codex’s specialized coding capabilities extend the platform’s reach into professional knowledge work and software development.
Actionable Next Steps:
- Audit your current AI workload to understand query complexity distribution and predict routing patterns
- Run pilot deployments comparing GPT-5’s automatic routing against your existing model configurations
- Monitor routing decisions and costs for the first 30 days to identify optimization opportunities
- Implement quality checks for reasoning mode outputs in high-stakes applications
- Consider multi-model strategies using platforms like MULTIBLY to access GPT-5, Claude Opus 4.5, and 300+ other models for side-by-side comparison and task-specific routing
The dual-mode architecture doesn’t eliminate the need for thoughtful AI deployment strategy, but it substantially simplifies the operational complexity of matching model capabilities to task requirements. For enterprises navigating the increasingly complex AI landscape in 2026, GPT-5’s intelligent routing provides a practical framework for optimizing the speed-versus-reasoning trade-off that defines modern production AI systems.
References
[1] Gpt 5 – https://yourgpt.ai/blog/updates/gpt-5
[2] Openai Gpt 5 Release – https://builtin.ai/artificial-intelligence/openai-gpt-5-release
[3] Introducing Gpt 5 2 – https://openai.com/index/introducing-gpt-5-2/
[4] Introducing Gpt 5 3 Codex – https://openai.com/index/introducing-gpt-5-3-codex/
Our Fact Checking Process
We prioritize accuracy and integrity in our content. Here's how we maintain high standards:
- Expert Review: All articles are reviewed by subject matter experts.
- Source Validation: Information is backed by credible, up-to-date sources.
- Transparency: We clearly cite references and disclose potential conflicts.
Our Review Board
Our content is carefully reviewed by experienced professionals to ensure accuracy and relevance.
- Qualified Experts: Each article is assessed by specialists with field-specific knowledge.
- Up-to-date Insights: We incorporate the latest research, trends, and standards.
- Commitment to Quality: Reviewers ensure clarity, correctness, and completeness.
Look for the expert-reviewed label to read content you can trust.



