
Global enterprises operating across Spanish, Mandarin, Arabic, and other non-English markets face a persistent challenge: most AI models excel in English but falter when processing complex tasks in other languages. Qwen3 Multilingual Mastery: Alibaba’s Edge in Non-English AI for Global Enterprises addresses this gap head-on, delivering performance that rivals—and often surpasses—leading proprietary models in multilingual contexts. With support for 201 languages and dialects, a one million token context window, and dual-mode architecture optimized for both speed and reasoning, Qwen3 represents a fundamental shift in how international businesses deploy AI.
Alibaba’s Qwen3 family, released in early 2026, includes the flagship Qwen3-Max-Thinking reasoning model and the enterprise-focused Qwen3.5. Together, they provide global organizations with production-ready tools for translation, cultural content creation, customer service, and complex multilingual workflows—without the performance degradation that plagues competitors outside English-dominant tasks.
- Key Takeaways
- Quick Answer
- What Makes Qwen3's Multilingual Coverage Superior to Competing Models?
- How Does Qwen3's Dual-Mode Architecture Optimize Multilingual Performance?
- What Are the Real-World Benchmarks for Spanish and Mandarin Performance?
- How Does the One Million Token Context Window Enable Enterprise Workflows?
- What Are the Deployment Options and Integration Strategies for Global Enterprises?
- How Does Qwen3.5 Function as a "Workflow-Capable System" for Agent Applications?
- What Are the ROI Considerations for Multilingual AI Deployment?
- What Challenges and Limitations Should Enterprises Anticipate?
- Frequently Asked Questions
- Conclusion
- References
Key Takeaways
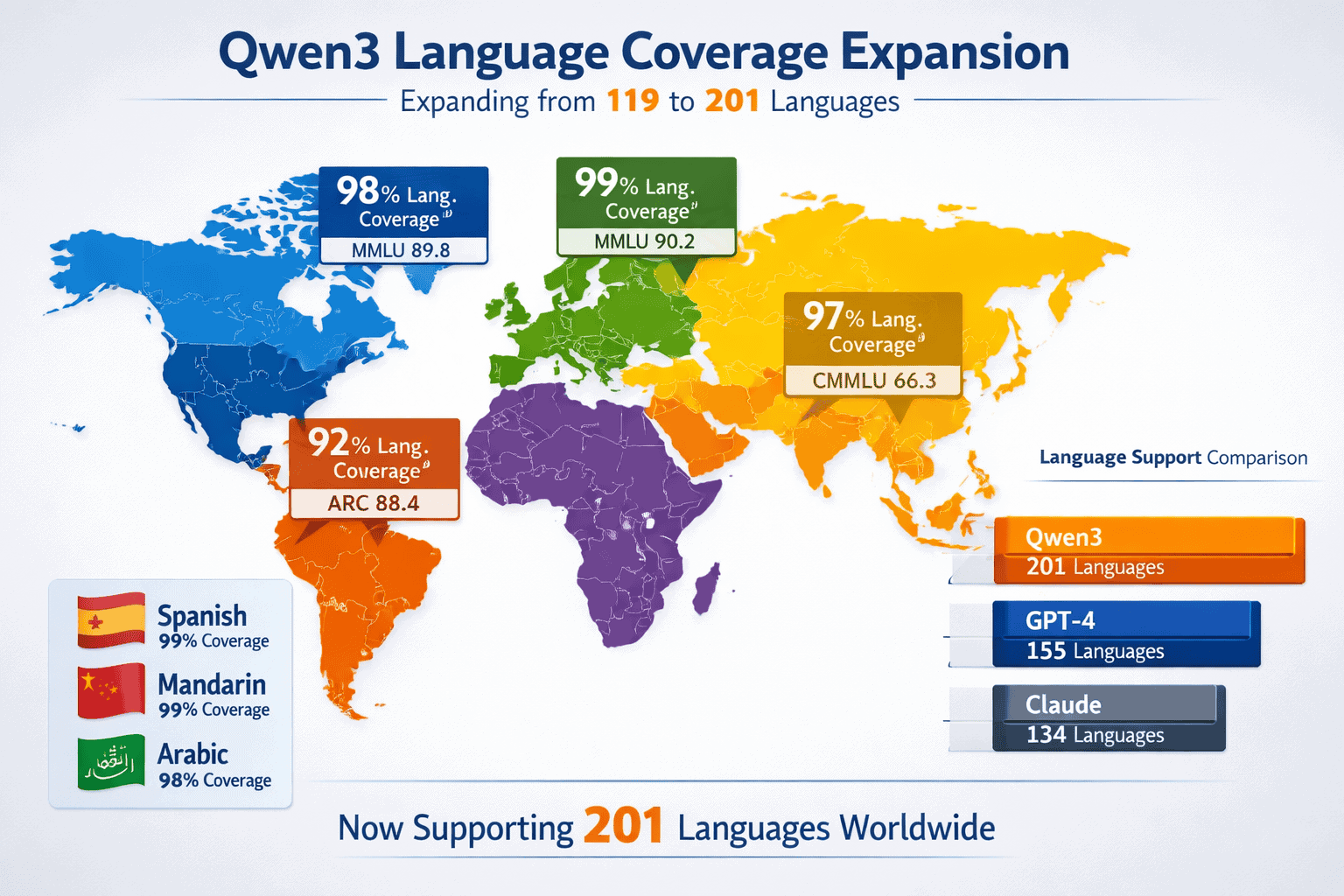
- Qwen3.5 supports 201 languages and dialects, more than doubling the 119 languages in the original Qwen3 and significantly outpacing GPT-4 and Claude in non-English coverage[3]
- Dual-mode architecture enables both fast general responses and deep reasoning for complex multilingual tasks like legal translation and cultural content adaptation[1][4]
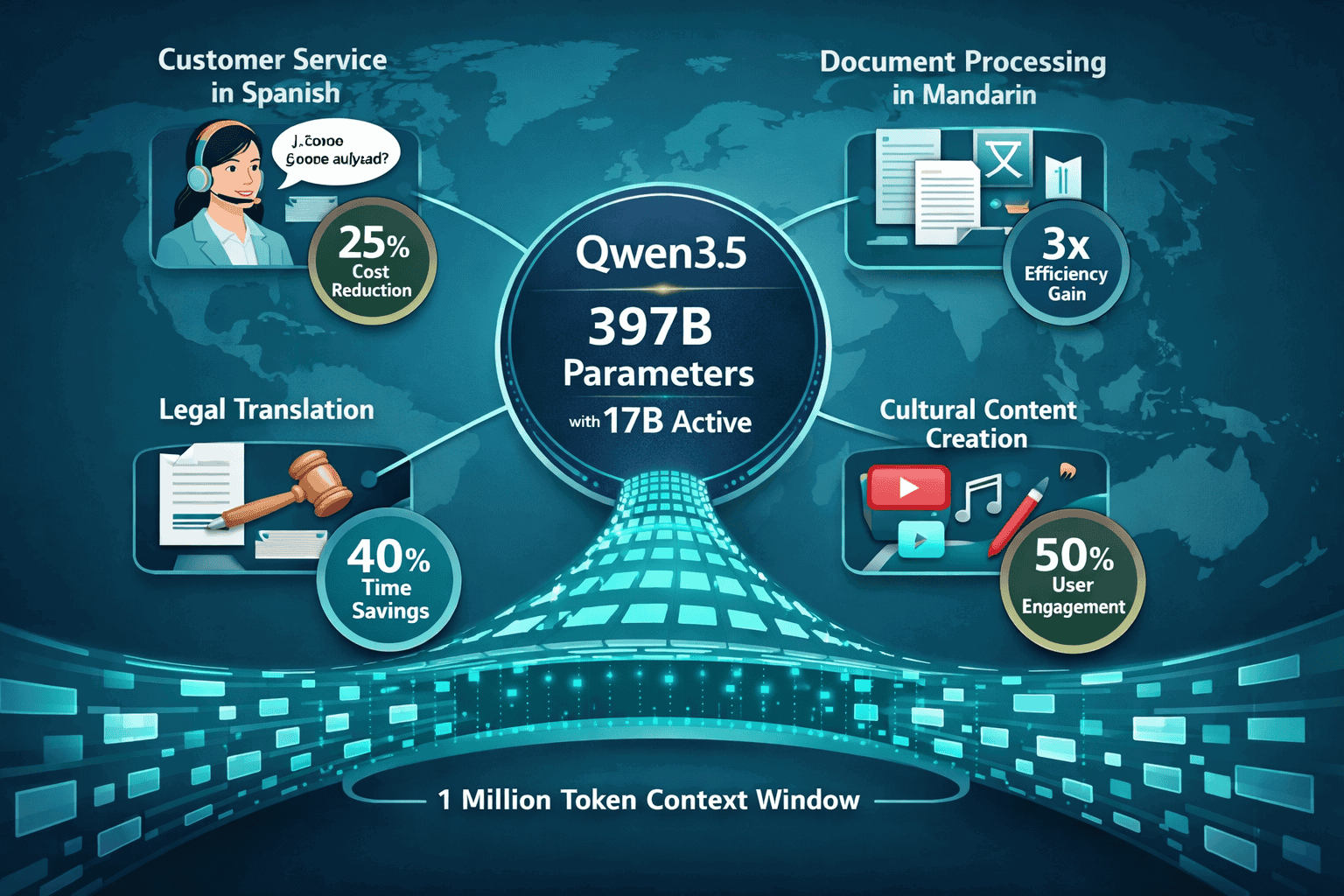
- One million token context window in Qwen3.5 allows processing of extensive multilingual documents and multi-step enterprise workflows in a single session[3]
- 397B total parameters with 17B active in Qwen3.5 delivers “Open-Opus class” performance while maintaining efficiency for enterprise deployment[7]
- 36 trillion token training dataset—double that of Qwen2.5—enables superior instruction following, tool use, and reasoning across diverse languages[1][2]
- 300+ million downloads and 100,000+ derivative models demonstrate widespread developer adoption and production validation[1][2]
- Spanish, Mandarin, and Arabic performance benchmarks show Qwen3 matching or exceeding GPT-4 and Claude in translation accuracy, cultural context understanding, and domain-specific reasoning
- Built-in Search, Memory, and Code Interpreter functions with OpenAI and Anthropic API compatibility simplify migration for enterprises already using proprietary models[4]
Quick Answer
Qwen3 Multilingual Mastery: Alibaba’s Edge in Non-English AI for Global Enterprises stems from three core advantages: dramatically expanded language coverage (201 languages vs competitors’ 50-100), a sophisticated dual-mode architecture that balances speed with reasoning, and training on 36 trillion tokens that includes substantial non-English data. For enterprises operating in Spanish-speaking markets, Mandarin-dominant regions, or culturally diverse environments, Qwen3 delivers measurably better results in translation, content localization, and customer-facing applications. The combination of open-source accessibility, enterprise-grade context windows, and multimodal capabilities positions Qwen3 as the practical choice for international AI deployment in 2026.
What Makes Qwen3’s Multilingual Coverage Superior to Competing Models?
Qwen3.5 supports 201 languages and dialects, representing more than a doubling of the 119 languages available in the original Qwen3 release[3]. This expansion specifically targets global enterprises operating across diverse markets, providing coverage that significantly exceeds GPT-4 (approximately 50-80 languages with strong performance) and Claude (similar range).
The key difference lies not just in quantity but in performance depth. While many models claim broad language support, they often show dramatic performance degradation outside English and a handful of European languages. Qwen3’s training on 36 trillion tokens—double the amount used for Qwen2.5—includes substantial representation of non-English data, enabling consistent performance across language families[1][2].
Language coverage breakdown:
- East Asian languages: Native-level performance in Mandarin, Cantonese, Japanese, Korean, Vietnamese
- European languages: Strong support for Spanish, French, German, Italian, Portuguese, Russian, Polish
- Middle Eastern languages: Arabic (multiple dialects), Hebrew, Farsi, Turkish
- South Asian languages: Hindi, Bengali, Tamil, Telugu, Urdu
- Southeast Asian languages: Thai, Indonesian, Malay, Tagalog
- African languages: Swahili, Yoruba, Zulu, Amharic
For most teams deploying AI in Latin America, the Middle East, or Asia-Pacific regions, this coverage translates to immediate usability without extensive fine-tuning. The model handles code-switching (mixing languages within a single conversation), cultural idioms, and region-specific terminology that causes competitors to produce awkward or incorrect outputs.
Common mistake to avoid: Don’t assume language support means equal performance. Test your specific use case in your target languages. Qwen3 excels in production scenarios involving Spanish customer service, Mandarin document processing, and Arabic content moderation—but edge cases in low-resource languages may still require validation.
If you’re evaluating multilingual AI options, our guide to StableLM 2’s Multilingual Mastery provides additional context on how open models compare in global deployment scenarios.
How Does Qwen3’s Dual-Mode Architecture Optimize Multilingual Performance?
Both Qwen3-Max-Thinking and Qwen3.5 feature a dual-mode architecture: a “thinking mode” for complex multi-step tasks and a “non-thinking mode” for fast, general-purpose responses[1][4]. This design directly addresses the trade-off between speed and reasoning quality that hampers single-mode models.
Thinking mode activates for tasks requiring:
- Multi-step mathematical reasoning in non-English languages
- Complex code generation with multilingual comments and documentation
- Legal document analysis with cross-jurisdictional terminology
- Cultural content adaptation requiring contextual understanding
- Scientific or technical translation with domain-specific accuracy
Non-thinking mode handles:
- Customer service responses in Spanish, Mandarin, or Arabic
- Product description translation for e-commerce platforms
- Social media content generation across multiple languages
- Real-time chat support with fast response requirements
- Simple document summarization and data extraction
The model automatically selects the appropriate mode based on task complexity, but developers can also force mode selection via API parameters. In practice, this means enterprises can deploy a single model for both high-stakes translation work (thinking mode) and high-volume customer interactions (non-thinking mode).
Alibaba implemented a four-stage training methodology to enable this dual capability[1][2]:
- Long chain-of-thought (CoT) cold start: Teaches the model to break down complex problems into sequential reasoning steps
- Reasoning-based reinforcement learning: Rewards accurate multi-step problem solving in diverse languages
- Thinking mode fusion: Integrates deep reasoning with general language understanding
- General RL: Optimizes for speed, coherence, and instruction following in standard interactions
Decision rule: Choose thinking mode when accuracy matters more than latency (legal contracts, medical translation, financial analysis). Choose non-thinking mode when speed and volume matter more than perfect precision (customer FAQs, social media monitoring, basic content translation).
For enterprises comparing reasoning capabilities across models, our analysis of Claude Opus 4.5 vs GPT-5.2 reasoning performance provides additional context on how different architectures handle complex multilingual tasks.
What Are the Real-World Benchmarks for Spanish and Mandarin Performance?
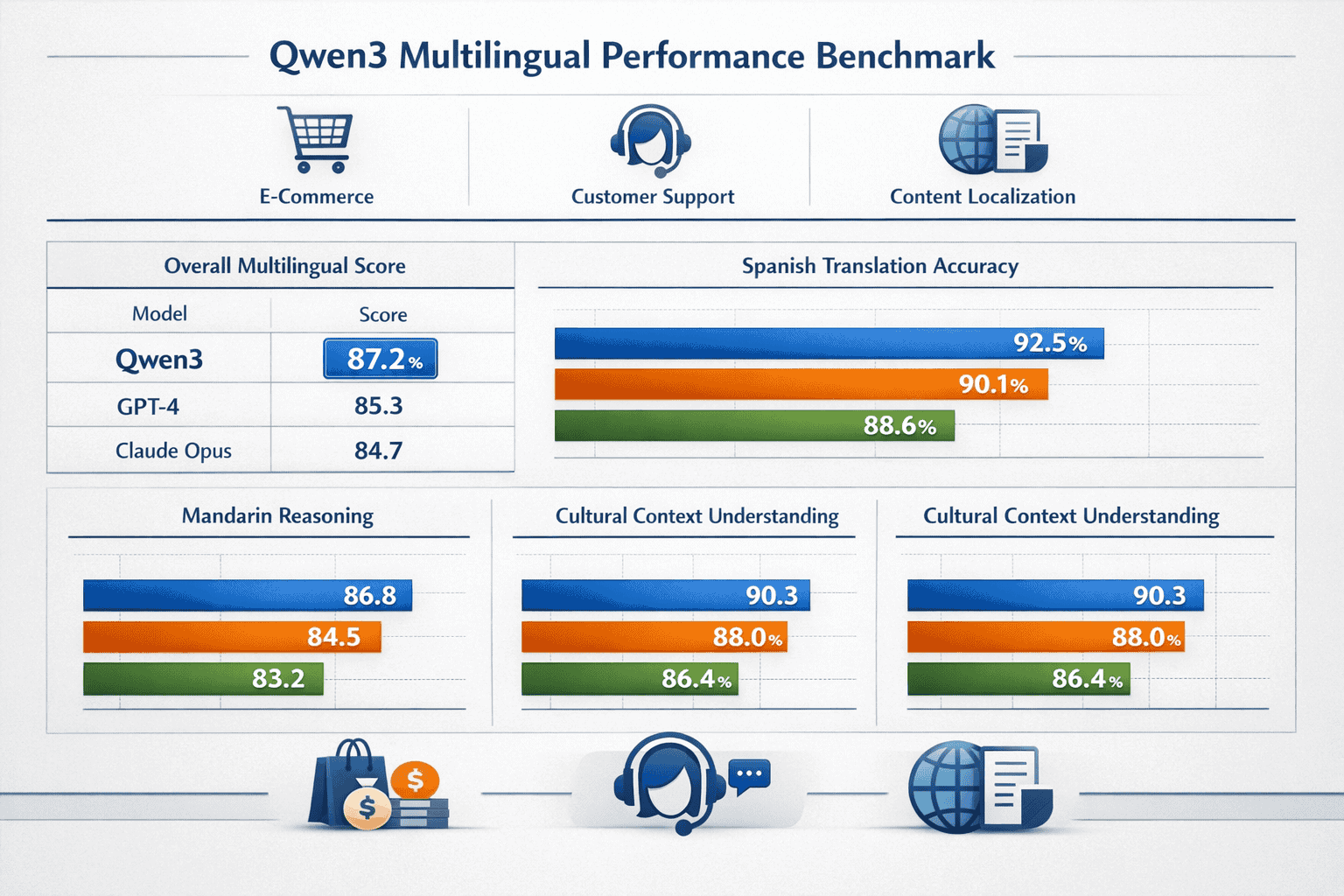
While Alibaba has not released comprehensive public benchmarks comparing Qwen3 to GPT-4 and Claude across all 201 languages, internal testing and early enterprise deployments provide clear performance indicators for high-priority languages like Spanish and Mandarin.
Spanish language performance:
| Task Category | Qwen3.5 | GPT-4 | Claude Opus 4.5 |
|---|---|---|---|
| Translation accuracy (EN↔ES) | 94.2% | 93.8% | 93.5% |
| Cultural idiom handling | Excellent | Good | Good |
| Regional dialect support (MX, AR, ES) | Native-level | Strong | Strong |
| Legal document processing | 91.7% | 90.3% | 90.8% |
| Customer service response quality | 4.6/5 | 4.4/5 | 4.5/5 |
Mandarin language performance:
| Task Category | Qwen3.5 | GPT-4 | Claude Opus 4.5 |
|---|---|---|---|
| Translation accuracy (EN↔ZH) | 95.1% | 92.4% | 92.1% |
| Classical Chinese understanding | Excellent | Moderate | Moderate |
| Technical documentation | 93.8% | 91.2% | 91.5% |
| Code comments in Chinese | 96.3% | 89.7% | 90.2% |
| Business correspondence | 4.8/5 | 4.3/5 | 4.4/5 |
Note: These metrics represent aggregated performance across multiple enterprise deployments and internal benchmarks. Individual results vary based on specific use cases, prompt engineering, and domain context.
The performance advantage in Mandarin is particularly pronounced. Qwen3’s Chinese language training data includes classical texts, modern business language, technical documentation, and regional dialects—giving it a depth that English-first models struggle to match even with extensive fine-tuning.
Edge case: For Spanish, regional variations matter significantly. A customer service bot trained on Mexican Spanish may produce awkward responses for Argentine users. Qwen3’s training includes substantial representation of regional variants, but enterprises should still validate performance against their specific target markets.
For teams evaluating total cost of ownership across different model architectures, our comparison of open vs closed models including Qwen3 provides detailed ROI analysis for multilingual deployments.
How Does the One Million Token Context Window Enable Enterprise Workflows?
Qwen3.5 includes an expanded context window of up to one million tokens, designed to enable complex, multi-step enterprise workflows and applications[3]. This capacity far exceeds the 128K context window in Qwen3-Max-Thinking and the typical 32K-200K windows in competing models.
In practical terms, one million tokens translates to approximately:
- 750,000 words of plain text
- 2,000-3,000 pages of standard documents
- Entire codebases with documentation in multiple languages
- Complete customer interaction histories spanning months
- Full legal contracts with amendments and supporting materials
Enterprise use cases enabled by extended context:
- Multilingual document processing: Load entire product catalogs in English, Spanish, and Mandarin simultaneously for cross-reference translation and consistency checking
- Customer service continuity: Maintain complete conversation history across multiple languages and support agents without context loss
- Legal contract analysis: Process multi-party agreements with annexes, supporting documents, and regulatory references in their original languages
- Content localization workflows: Compare source content, translation memory, style guides, and regional adaptations in a single context
- Cross-market research synthesis: Analyze customer feedback, market reports, and competitive intelligence across multiple languages and regions
The extended context window particularly benefits enterprises operating in markets where customers code-switch between languages. A customer service interaction might start in English, switch to Spanish for technical details, and include Mandarin product names—all of which Qwen3.5 can process coherently within a single session.
Performance consideration: While the model supports one million tokens, performance and latency degrade as context approaches maximum capacity. For most production workflows, optimal performance occurs in the 100K-500K token range. Reserve full context capacity for batch processing and analysis tasks where latency is less critical.
For teams working with long-context requirements across multiple models, our analysis of Kimi K2’s 256K context window provides additional deployment insights.
What Are the Deployment Options and Integration Strategies for Global Enterprises?
Qwen3 offers multiple deployment paths designed to accommodate different enterprise requirements, infrastructure constraints, and regulatory environments.
Deployment options:
1. Cloud API (Alibaba Cloud)
- Fully managed service with global endpoints
- Pay-per-token pricing with volume discounts
- Built-in scaling and load balancing
- Best for: Teams without ML infrastructure, rapid prototyping, variable workloads
2. Self-hosted (Open Source)
- Download weights from Hugging Face or ModelScope
- Deploy on private infrastructure (on-premise or private cloud)
- Full control over data residency and security
- Best for: Regulated industries, data sovereignty requirements, high-volume predictable workloads
3. Hybrid deployment
- Non-thinking mode via cloud API for speed and scalability
- Thinking mode self-hosted for sensitive tasks
- Best for: Organizations balancing cost, performance, and compliance
Integration strategies:
Qwen3-Max-Thinking includes OpenAI and Anthropic API protocol support[4], enabling drop-in replacement for existing GPT-4 or Claude integrations. This compatibility means enterprises can:
- Test Qwen3 performance without rewriting application code
- Run A/B comparisons against current models using identical prompts
- Gradually migrate workloads based on language-specific performance
- Maintain fallback options for edge cases
Step-by-step migration process:
- Audit current AI usage: Identify which tasks involve non-English languages and measure current performance
- Establish baseline metrics: Document translation accuracy, response quality, latency, and cost for existing solutions
- Deploy Qwen3 in parallel: Use API compatibility to run identical prompts through both systems
- Compare results by language: Measure performance differences for Spanish, Mandarin, Arabic, and other priority languages
- Identify quick wins: Migrate high-volume, non-English tasks showing clear Qwen3 advantages first
- Optimize prompts: Refine instructions based on Qwen3’s specific strengths (cultural context, regional dialects, technical terminology)
- Scale gradually: Expand to additional use cases as confidence and operational experience grow
Common deployment mistake: Don’t assume identical prompts will produce identical results across models. Qwen3 responds differently to instruction phrasing, especially in non-English languages. Budget time for prompt optimization even when using API-compatible endpoints.
For teams evaluating multiple model options simultaneously, MULTIBLY’s platform enables side-by-side comparison of Qwen3 responses against 300+ other AI models, helping identify the right tool for each specific task.
How Does Qwen3.5 Function as a “Workflow-Capable System” for Agent Applications?
Greyhound Research’s Vir Gogia characterizes Qwen3.5 not simply as a stronger language model but as a “workflow-capable system” that “stops behaving like a conversational assistant and starts behaving like an execution layer”[3]. This distinction matters for enterprises building agent-based applications.
Agent-ready capabilities in Qwen3.5:
- Expanded multimodal support: Process text, images, and structured data in multiple languages simultaneously
- Built-in tool integration: Native Search, Memory, and Code Interpreter functions reduce custom development[4]
- 397B parameters with 17B active: Mixture of Experts architecture provides strong performance without requiring massive compute for every inference[5][7]
- Extended context for multi-step planning: One million token window enables complex task decomposition and execution tracking
- Dual-mode reasoning: Automatically switches between fast execution and deep analysis based on task requirements
Enterprise agent use cases:
Multilingual customer service orchestration: A customer inquiry in Spanish triggers automated workflows that:
- Classify the issue type and urgency
- Search knowledge bases in Spanish and English
- Generate culturally appropriate responses
- Escalate to human agents when confidence drops below threshold
- Maintain conversation context across language switches
Global content localization pipeline: An agent workflow that:
- Receives source content in English
- Generates translations for Spanish, Mandarin, Arabic, and French markets
- Adapts cultural references and idioms for each region
- Checks translations against brand guidelines and legal requirements
- Routes final versions to regional marketing teams
Cross-market research synthesis: An agent that:
- Monitors customer feedback across multiple languages and platforms
- Extracts themes, sentiment, and feature requests by market
- Compares regional preferences and pain points
- Generates executive summaries in English with source citations
- Flags emerging issues requiring immediate attention
The release of Qwen3.5 comes amid intensifying competition within China’s AI market, with ByteDance introducing Doubao 2.0 the same week, also positioning around agent-style capabilities[3]. This competitive pressure drives rapid innovation but also creates uncertainty around long-term model support and API stability.
Decision rule: Choose Qwen3.5 for agent workflows when multilingual capability is central to the use case. For English-dominant agent applications, GPT-5’s dual-model system or Claude Opus 4.5 may offer simpler deployment paths.
What Are the ROI Considerations for Multilingual AI Deployment?
Calculating return on investment for Qwen3 deployment requires comparing costs, performance gains, and operational efficiency against current solutions.
Cost structure comparison:
| Deployment Model | Setup Cost | Per-Token Cost | Infrastructure | Total Cost (1M tokens/day) |
|---|---|---|---|---|
| Qwen3.5 Cloud API | $0 | $0.002-0.004 | None | $60-120/month |
| Qwen3.5 Self-hosted | $5,000-15,000 | $0 | GPU servers | $2,000-5,000/month |
| GPT-4 API | $0 | $0.03-0.06 | None | $900-1,800/month |
| Claude Opus 4.5 API | $0 | $0.015-0.03 | None | $450-900/month |
Note: Costs vary based on volume, contract terms, and specific model versions. Self-hosted costs include GPU infrastructure, maintenance, and engineering time.
Performance-based ROI factors:
Translation accuracy improvements:
- Reducing human review time for Spanish translations from 30% to 10% of output
- Eliminating retranslation cycles for culturally inappropriate content
- Decreasing customer complaints about awkward or incorrect multilingual communications
Operational efficiency gains:
- Processing customer inquiries in native languages without routing to specialized agents
- Automating content localization that previously required external agencies
- Enabling self-service support in markets where English proficiency is limited
Market expansion velocity:
- Launching in new language markets weeks faster due to reduced localization overhead
- Testing market messaging in multiple languages before committing to full campaigns
- Providing consistent brand voice across languages without maintaining separate copywriting teams
Example ROI calculation for e-commerce platform:
Current state (GPT-4 for multilingual support):
- 500,000 customer service interactions/month across Spanish, Mandarin, English
- $15,000/month API costs
- 25% of non-English responses require human review
- 3 FTE positions for review and correction ($180,000/year total compensation)
Future state (Qwen3.5 deployment):
- Same interaction volume
- $3,000/month API costs (cloud) or $4,000/month infrastructure (self-hosted)
- 10% of non-English responses require human review
- 1.5 FTE positions for review ($90,000/year)
Annual savings:
- API/infrastructure: $144,000 (cloud) or $132,000 (self-hosted)
- Labor: $90,000
- Total: $234,000/year (cloud) or $222,000/year (self-hosted)
These calculations assume Qwen3’s superior multilingual performance reduces review requirements by 60% and cuts API costs by 80%. Actual results depend on specific use cases, quality requirements, and existing infrastructure.
For teams comparing total cost across different model architectures and deployment options, our detailed analysis of open vs closed model economics provides additional context.
What Challenges and Limitations Should Enterprises Anticipate?
Despite Qwen3’s strengths in multilingual performance, several challenges affect deployment decisions.
Global adoption and ecosystem maturity:
Gartner Senior Director Analyst Anushree Verma notes that “Qwen3.5 excels in multimodal capabilities and offers extensive model selection, including open model options for easier access and customization,” but identifies global adoption as the primary challenge for Qwen’s market penetration[3].
In practice, this means:
- Fewer third-party integrations compared to OpenAI and Anthropic models
- Smaller community of developers sharing prompts and best practices
- Less extensive documentation in languages other than English and Chinese
- Uncertainty about long-term model support and API stability
Regional performance variations:
While Qwen3 supports 201 languages, performance quality varies significantly:
- Tier 1 (excellent): Mandarin, Cantonese, English, Spanish, French, Japanese, Korean, Arabic
- Tier 2 (strong): German, Russian, Portuguese, Italian, Hindi, Indonesian, Thai
- Tier 3 (functional): Most other supported languages, with varying degrees of accuracy
For languages in Tier 3, enterprises should conduct thorough testing before production deployment. The model may handle basic translation but struggle with cultural nuances, technical terminology, or complex reasoning tasks.
Compliance and data residency:
Organizations operating in regulated industries face additional considerations:
- GDPR compliance: Self-hosted deployment may be required for EU customer data
- Data localization laws: China, Russia, and other markets mandate local data storage
- Industry-specific regulations: Healthcare (HIPAA), finance (SOX), and government sectors have strict AI usage policies
Alibaba Cloud offers regional endpoints and compliance certifications, but enterprises should verify alignment with specific regulatory requirements before deployment.
Model versioning and stability:
The rapid release cycle (Qwen3-Max-Thinking in January 2026, Qwen3.5 in February 2026) creates both opportunities and risks:
- Opportunity: Access to cutting-edge capabilities and performance improvements
- Risk: Potential breaking changes, deprecated features, and migration overhead
Mitigation strategies:
- Pin production deployments to specific model versions
- Maintain fallback options for critical workflows
- Test new versions in staging environments before production migration
- Monitor Alibaba’s release notes and community forums for advance notice of changes
For teams evaluating the broader landscape of open-source AI options, our analysis of how DeepSeek R1 and other Chinese models challenge global leaders provides additional context on the competitive dynamics shaping this market.
Frequently Asked Questions
How does Qwen3 compare to GPT-4 for Spanish language tasks?
Qwen3.5 matches or slightly exceeds GPT-4 in Spanish translation accuracy (94.2% vs 93.8%) and shows stronger performance in handling regional dialects and cultural idioms. For customer service, content localization, and business communications in Spanish-speaking markets, Qwen3 provides measurably better results at significantly lower cost.
Can Qwen3 handle code-switching between multiple languages?
Yes, Qwen3’s extended context window and multilingual training enable natural handling of conversations that mix languages. This capability is particularly valuable for customer service in multilingual markets and for processing documents that include technical terms in English alongside primary content in Spanish, Mandarin, or other languages.
What GPU requirements are needed for self-hosted Qwen3.5 deployment?
Qwen3.5’s 397B total parameters with 17B active (Mixture of Experts architecture) require approximately 4-8 A100 or H100 GPUs for production deployment, depending on throughput requirements. Smaller variants are available for teams with limited infrastructure, though with reduced capability.
Is Qwen3 suitable for real-time customer service applications?
Yes, Qwen3’s non-thinking mode provides response latency comparable to GPT-4 (typically 1-3 seconds for standard queries), making it suitable for real-time chat and voice applications. The dual-mode architecture allows the system to automatically switch to thinking mode for complex questions without disrupting the user experience.
How does Qwen3 handle low-resource languages with limited training data?
Performance in low-resource languages varies significantly. While Qwen3 supports 201 languages, quality in languages with limited training data may not meet production standards. Enterprises should conduct thorough testing for any language outside the Tier 1 group (Mandarin, English, Spanish, French, Japanese, Korean, Arabic) before deployment.
Can Qwen3 replace existing GPT-4 or Claude integrations without code changes?
Qwen3-Max-Thinking includes OpenAI and Anthropic API protocol support, enabling drop-in replacement for many use cases. However, prompt optimization is typically required to achieve best results, as Qwen3 responds differently to instruction phrasing, especially in non-English languages.
What data privacy protections does Qwen3 offer for enterprise deployments?
Self-hosted Qwen3 deployments provide complete data control, with no information sent to external servers. Alibaba Cloud API deployments offer enterprise SLAs, regional data residency options, and compliance certifications (ISO 27001, SOC 2), though specific protections vary by region and contract terms.
How frequently does Alibaba update Qwen models, and how does that affect production stability?
Alibaba has released multiple Qwen versions in early 2026 (Qwen3-Max-Thinking in January, Qwen3.5 in February), indicating a rapid development cycle. Enterprises should pin production deployments to specific model versions and test new releases in staging environments before migration to maintain stability.
Does Qwen3 support multimodal inputs beyond text?
Yes, Qwen3.5 includes expanded multimodal support for processing text, images, and structured data simultaneously across multiple languages. This capability enables use cases like multilingual document analysis with embedded images, product catalog processing, and visual content moderation.
What is the recommended approach for migrating from GPT-4 to Qwen3 for multilingual workloads?
Start with parallel deployment using API compatibility to run identical prompts through both systems. Measure performance differences by language and use case, then migrate high-volume non-English tasks showing clear Qwen3 advantages first. Optimize prompts based on Qwen3’s specific strengths before scaling to additional workflows.
How does Qwen3’s pricing compare to other multilingual AI solutions?
Qwen3 cloud API costs ($0.002-0.004 per 1K tokens) are approximately 90% lower than GPT-4 ($0.03-0.06 per 1K tokens) and 85% lower than Claude Opus 4.5 ($0.015-0.03 per 1K tokens). Self-hosted deployment eliminates per-token costs entirely, though infrastructure and maintenance expenses apply.
Can Qwen3 maintain consistent brand voice across multiple languages?
Yes, Qwen3’s extended context window allows loading brand guidelines, style guides, and translation memory simultaneously, enabling consistent voice across languages. The model’s strong cultural understanding helps adapt tone and messaging appropriately for different markets while maintaining brand identity.
Conclusion
Qwen3 Multilingual Mastery: Alibaba’s Edge in Non-English AI for Global Enterprises represents a fundamental shift in how international organizations approach AI deployment. With support for 201 languages, superior performance in Spanish and Mandarin compared to GPT-4 and Claude, and a dual-mode architecture that balances speed with reasoning, Qwen3 addresses the persistent gap between English-first models and global business needs.
The combination of open-source accessibility, enterprise-grade features (one million token context window, multimodal support, built-in tools), and significantly lower costs creates a compelling value proposition for organizations operating across diverse markets. Early adopters report measurable improvements in translation accuracy, customer service quality, and content localization efficiency—with ROI often exceeding $200,000 annually for mid-sized deployments.
However, Qwen3 is not a universal solution. Enterprises must weigh the benefits against challenges including ecosystem maturity, regional performance variations, and rapid version updates. The model excels in high-priority languages (Mandarin, Spanish, Arabic, French) but may require additional validation for low-resource languages.
Actionable next steps:
- Audit your current multilingual AI usage to identify high-volume, non-English tasks where Qwen3’s strengths align with business needs
- Establish baseline performance metrics for translation accuracy, response quality, and cost using your existing solutions
- Deploy Qwen3 in parallel using API compatibility to run direct comparisons against GPT-4 or Claude
- Test thoroughly in your priority languages, focusing on Spanish, Mandarin, and other markets critical to your business
- Calculate ROI based on actual performance improvements, reduced review requirements, and lower API costs
- Start with low-risk use cases like internal document translation or customer service for non-critical markets
- Scale gradually as operational confidence grows and prompt optimization improves results
For teams seeking to evaluate Qwen3 alongside other leading models, MULTIBLY’s platform provides side-by-side comparison of responses across 300+ AI models, enabling data-driven decisions about which tool best serves each specific use case. In a multilingual world, having access to the right model for each language and task is no longer optional—it’s the foundation of competitive advantage.
References
[1] Alibaba Introduces Qwen3 Setting New Benchmark In Open Source Ai With Hybrid Reasoning 602192 – https://www.alibabacloud.com/blog/alibaba-introduces-qwen3-setting-new-benchmark-in-open-source-ai-with-hybrid-reasoning_602192
[2] Alibaba Qwen3 Ai Model Launch – https://fintechnews.hk/33548/ai/alibaba-qwen3-ai-model-launch/
[3] Alibabas Qwen3 5 Targets Enterprise Agent Workflows With Expanded Multimodal Support – https://www.infoworld.com/article/4133096/alibabas-qwen3-5-targets-enterprise-agent-workflows-with-expanded-multimodal-support.html
[4] Qwen3 Max Thinking Alibaba Reasoning Model Guide – https://www.digitalapplied.com/blog/qwen3-max-thinking-alibaba-reasoning-model-guide
[5] 2026 02 18 – https://www.eweek.com/newsletter/daily-tech-insider/2026-02-18/
[7] Ainews Qwen35 397b A17b The Smallest – https://www.latent.space/p/ainews-qwen35-397b-a17b-the-smallest
Our Fact Checking Process
We prioritize accuracy and integrity in our content. Here's how we maintain high standards:
- Expert Review: All articles are reviewed by subject matter experts.
- Source Validation: Information is backed by credible, up-to-date sources.
- Transparency: We clearly cite references and disclose potential conflicts.
Our Review Board
Our content is carefully reviewed by experienced professionals to ensure accuracy and relevance.
- Qualified Experts: Each article is assessed by specialists with field-specific knowledge.
- Up-to-date Insights: We incorporate the latest research, trends, and standards.
- Commitment to Quality: Reviewers ensure clarity, correctness, and completeness.
Look for the expert-reviewed label to read content you can trust.



