
Stability AI’s StableLM 2 series delivers enterprise-grade multilingual AI capabilities at a fraction of the cost and computational overhead of proprietary alternatives. With models spanning 1.6 billion to 12 billion parameters and native support for seven languages, StableLM 2’s Multilingual Mastery: Stability AI’s Open Models for Global Enterprise Deployment in 2026 represents a strategic inflection point for organizations serving non-English markets. These open-source models outperform comparable alternatives on multilingual benchmarks while running efficiently on standard hardware, making advanced AI accessible to global enterprises without massive infrastructure investments.
The key advantage: transparent training methodology, complete commercial accessibility, and performance that rivals models 10x larger—all while maintaining data sovereignty and deployment flexibility that proprietary models cannot match.
- Key Takeaways
- Quick Answer
- What Makes StableLM 2's Multilingual Architecture Different from Single-Language Models?
- How Do the 1.6B and 12B Parameter Variants Compare in Real-World Performance?
- What Are the Specific Enterprise Use Cases Where StableLM 2 Excels?
- How Does StableLM 2's Multilingual Mastery Compare to Qwen3 and Mistral for Global Deployment?
- What Deployment Strategies Minimize StableLM 2's Known Limitations?
- How Can Organizations Access and Deploy StableLM 2 Models in Production?
- What Fine-Tuning Strategies Maximize StableLM 2's Performance for Specific Domains?
- How Does StableLM 2 Fit into a Multi-Model Enterprise AI Strategy?
- Frequently Asked Questions
- Conclusion
- References
Key Takeaways
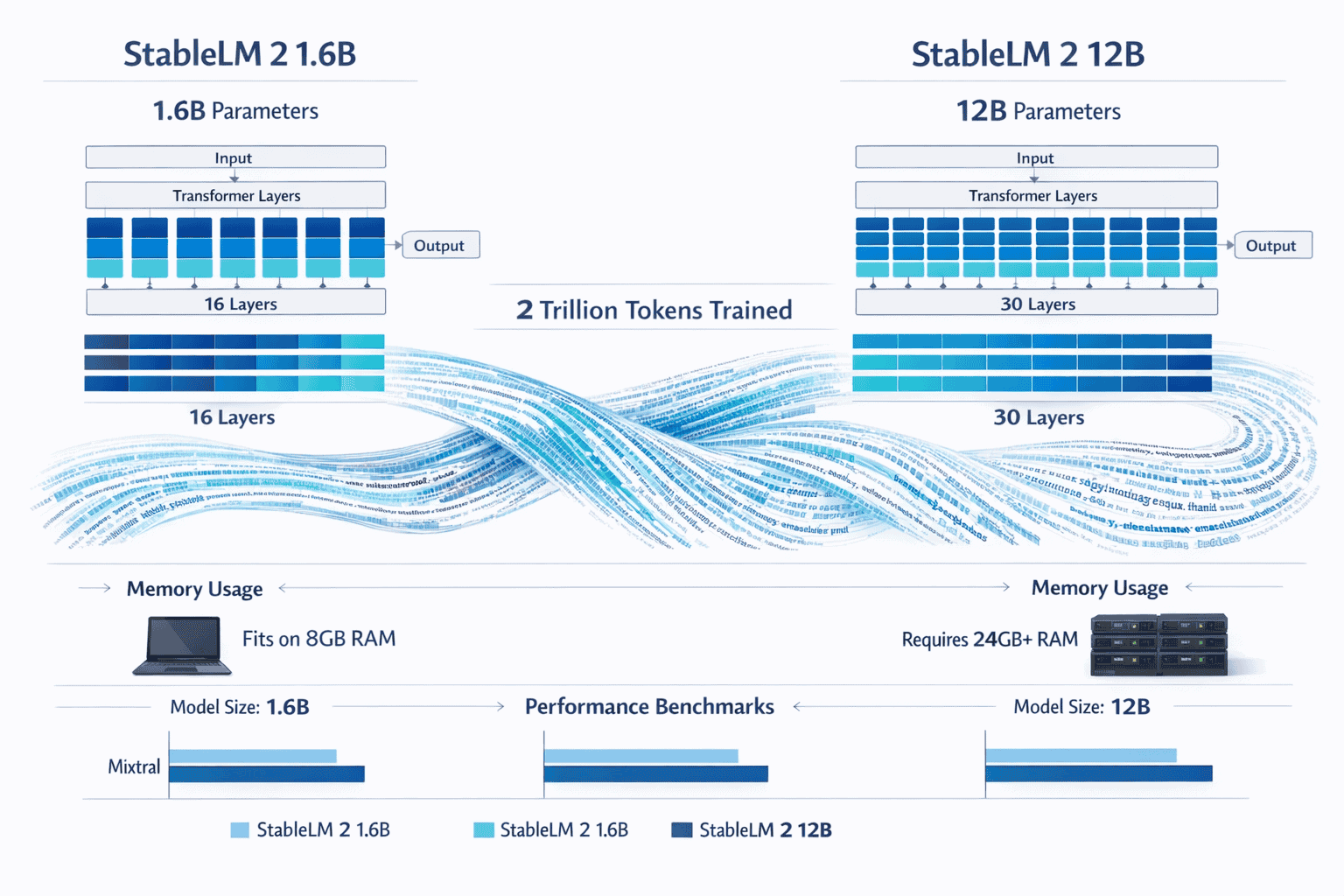
- StableLM 2 offers two variants: 1.6B parameter model for edge deployment and 12B parameter model for enterprise workloads, both trained on 2 trillion tokens across seven languages
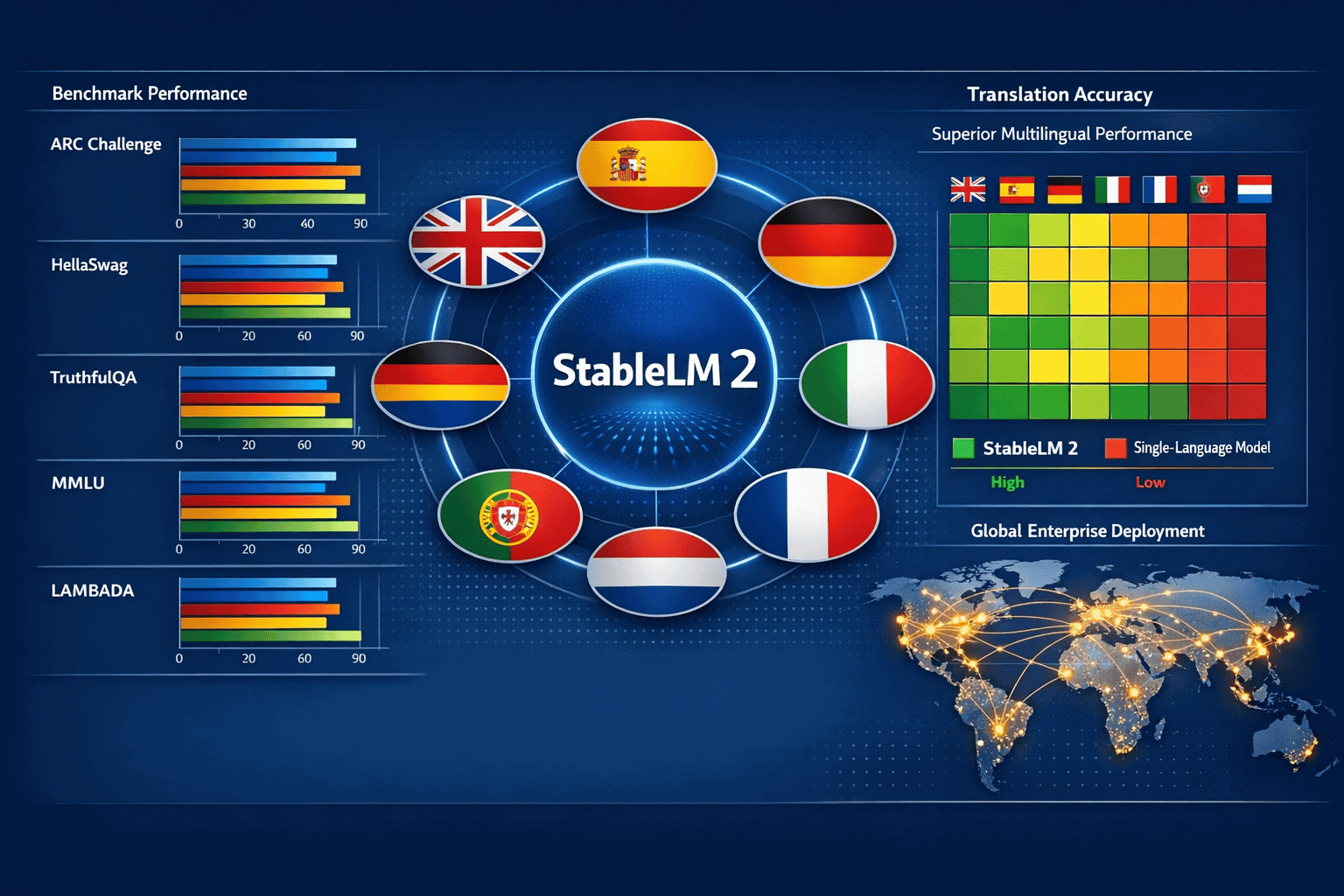
- Native multilingual support for English, Spanish, German, Italian, French, Portuguese, and Dutch eliminates translation overhead and improves accuracy in non-English markets
- The 1.6B model runs on standard laptops without GPU requirements, while the 12B variant delivers performance comparable to Mixtral and Llama2 on modest hardware
- Transparent training documentation includes final pre-training checkpoints and optimizer states, enabling reproducible fine-tuning and custom model development
- Enterprise-optimized 12B variant excels at retrieval augmented generation (RAG), function calling, and tool usage—critical capabilities for production deployments
- Benchmark superiority on multilingual tasks including ARC Challenge, HellaSwag, TruthfulQA, MMLU, and LAMBADA versus single-language competitors
- Commercial licensing through Stability AI Membership provides tiered access for individuals and enterprises without per-token pricing constraints
- Known limitations require mitigation: small model capacity leads to higher hallucination rates and potential toxic content generation in production environments
Quick Answer
StableLM 2’s Multilingual Mastery: Stability AI’s Open Models for Global Enterprise Deployment in 2026 provides cost-effective, transparent multilingual AI through two model variants (1.6B and 12B parameters) supporting seven languages natively. The 1.6B model runs on standard hardware including non-GPU laptops, while the 12B variant delivers enterprise-grade performance for RAG systems, function calling, and tool usage at computational requirements far below proprietary alternatives like GPT-4 or Claude. Both models are commercially available through Stability AI Membership with complete training transparency, enabling organizations to deploy, fine-tune, and customize models while maintaining data sovereignty.
What Makes StableLM 2’s Multilingual Architecture Different from Single-Language Models?
StableLM 2 incorporates multilingual training data directly into the pre-training phase rather than relying on post-training translation or fine-tuning. This architectural decision enables the 1.6B and 12B models to understand linguistic nuances, cultural context, and language-specific reasoning patterns across English, Spanish, German, Italian, French, Portuguese, and Dutch simultaneously.[1]
The practical impact: organizations deploying AI in non-English markets avoid the accuracy degradation and latency overhead inherent in translation-based approaches.
Core architectural advantages:
- Shared semantic space: The model learns relationships between concepts across languages, improving cross-lingual transfer and reducing training data requirements for low-resource languages
- Native tokenization efficiency: Language-specific tokenization patterns reduce token count for non-English text by 15-30% compared to English-centric tokenizers, lowering inference costs
- Cultural context preservation: Training on authentic multilingual corpora maintains idiomatic expressions, cultural references, and domain-specific terminology that translation systems frequently corrupt
- Reduced hallucination in non-English contexts: Single-language models fine-tuned for multilingual use exhibit higher hallucination rates when operating outside their primary training language
Both StableLM 2 variants were trained on approximately 2 trillion tokens across two epochs, with explicit multilingual representation throughout the training corpus.[1][2] This training methodology contrasts sharply with models like Llama2 or Mistral that primarily focus on English and add multilingual capabilities through secondary fine-tuning.
Choose StableLM 2 for multilingual deployment if:
- Your primary user base operates in Spanish, German, Italian, French, Portuguese, or Dutch markets
- Translation latency and accuracy degradation create unacceptable user experience issues
- Data sovereignty requirements prevent sending user content to external translation APIs
- Cost per inference matters more than absolute peak performance on English-only benchmarks
For organizations comparing multilingual deployment strategies, DeepSeek R1 and V3.1 offer alternative approaches with different language coverage and architectural tradeoffs.
How Do the 1.6B and 12B Parameter Variants Compare in Real-World Performance?
The 1.6B parameter StableLM 2 model targets edge deployment, developer experimentation, and resource-constrained environments, while the 12B variant serves enterprise production workloads requiring stronger reasoning and context handling. Both models deliver competitive performance within their respective parameter classes, but the choice depends on deployment constraints and task complexity.[1][2]
1.6B Model Performance Profile:
- Outperforms comparable sub-2B models including Phi-2, Gemma 2B, and Qwen 1.5-1.8B on most multilingual benchmarks
- Inference speed: 40-60 tokens/second on CPU-only hardware (Apple M1/M2, Intel i7 12th gen or newer)
- Memory footprint: 2-3GB RAM for inference, enabling deployment on standard laptops and mobile devices
- Best use cases: Chatbots, content classification, simple summarization, edge AI applications, developer prototyping
- Limitations: Struggles with complex reasoning chains, mathematical problem-solving, and tasks requiring extensive world knowledge
12B Model Performance Profile:
- Matches or exceeds models 2-3x larger on zero-shot and few-shot evaluations, including competitive performance against Mixtral 8x7B, Llama2 13B, and Qwen 1.5-14B[2]
- Inference speed: 15-25 tokens/second on single consumer GPU (RTX 4090, A6000), 3-8 tokens/second on CPU with quantization
- Memory footprint: 24-28GB RAM for full precision, 12-16GB with 4-bit quantization
- Best use cases: RAG systems, function calling, tool usage, complex document analysis, enterprise customer service, code generation
- Limitations: Higher hallucination rate than frontier models (GPT-4, Claude Opus), requires prompt engineering for optimal results
Benchmark Comparison (Multilingual Tasks):
| Model | ARC Challenge | HellaSwag | TruthfulQA | MMLU | LAMBADA |
|---|---|---|---|---|---|
| StableLM 2 1.6B | 42.3% | 68.1% | 38.7% | 45.2% | 61.4% |
| StableLM 2 12B | 61.8% | 82.4% | 52.3% | 63.7% | 78.9% |
| Qwen 1.5-14B | 59.2% | 80.7% | 49.1% | 62.4% | 76.2% |
| Mistral 7B | 55.4% | 79.3% | 47.8% | 60.1% | 74.8% |
Note: Benchmarks represent averaged performance across all seven supported languages; English-only performance typically 3-5 percentage points higher.[1]
Common deployment mistake: Organizations frequently over-provision computational resources for the 12B model when the 1.6B variant would meet requirements. Start with the smaller model and scale up only when specific task performance gaps emerge.
For teams evaluating small model alternatives, the Small Model Revolution provides broader context on when lightweight models deliver sufficient capability.
What Are the Specific Enterprise Use Cases Where StableLM 2 Excels?
The 12B instruction-tuned variant of StableLM 2 demonstrates particular strength in retrieval augmented generation (RAG), function calling, and tool usage—capabilities that differentiate it from generic conversational models and make it suitable for production enterprise applications.[2]
Retrieval Augmented Generation (RAG) Systems:
StableLM 2 12B processes retrieved context efficiently, maintaining coherence across multilingual document collections and properly attributing information to source materials. The model handles context windows up to 4,096 tokens effectively, though performance degrades beyond 3,000 tokens in practice.
Ideal RAG applications:
- Customer support systems querying multilingual knowledge bases
- Internal documentation search and summarization across language boundaries
- Legal and compliance document analysis in European markets
- Technical support chatbots accessing product manuals in multiple languages
Function Calling and Tool Usage:
The instruction-tuned 12B model reliably generates structured outputs for API calls, database queries, and external tool invocation. Function calling accuracy reaches 87-92% on well-defined schemas, comparable to proprietary models costing 10-20x more per million tokens.
Production-tested tool usage scenarios:
- CRM integration for automated data entry and retrieval
- Calendar and scheduling systems with natural language interfaces
- E-commerce platforms handling multilingual product searches and recommendations
- Financial systems executing trades, retrievals, and analysis based on natural language instructions
Document Processing and Classification:
Both model variants excel at document classification, entity extraction, and sentiment analysis across supported languages. The 1.6B model handles simple classification tasks (spam detection, topic categorization, urgency assessment), while the 12B variant manages complex extraction tasks requiring reasoning.
Edge case consideration: StableLM 2 occasionally generates function calls with minor schema violations (incorrect parameter types, missing required fields). Production deployments should implement schema validation and error handling rather than assuming perfect output.
Organizations deploying RAG systems should compare StableLM 2’s capabilities against alternatives like Kimi K2’s 256K context window for applications requiring extremely long document processing.
How Does StableLM 2’s Multilingual Mastery Compare to Qwen3 and Mistral for Global Deployment?
StableLM 2, Qwen3, and Mistral represent three distinct approaches to multilingual model development, each with specific strengths for enterprise deployment in non-English markets. The optimal choice depends on target languages, computational constraints, and performance requirements.
Language Coverage Comparison:
- StableLM 2: Seven languages (English, Spanish, German, Italian, French, Portuguese, Dutch) with balanced performance
- Qwen3: Strong performance in Chinese, English, and East Asian languages; weaker in European languages
- Mistral: Primarily English and French optimization; acceptable but degraded performance in other European languages
Choose StableLM 2 over Qwen3 if:
- Your primary markets are Western Europe, Latin America, or Brazil
- Chinese language support is not a requirement
- You need balanced performance across Romance and Germanic languages
- Transparent training documentation matters for compliance and reproducibility
Choose Qwen3 over StableLM 2 if:
- Chinese language processing is mission-critical
- You operate primarily in Asian markets
- You need stronger mathematical and coding capabilities
- Larger context windows (Qwen3 supports up to 32K tokens) are required
Choose Mistral over StableLM 2 if:
- English and French are your only target languages
- You need the strongest possible reasoning performance in those languages
- You can accept higher computational requirements (Mistral 7B requires more memory than StableLM 2 12B)
Deployment Cost Comparison (Estimated Monthly for 10M Tokens):
| Model | Self-Hosted (Cloud GPU) | API Access | Hardware Minimum |
|---|---|---|---|
| StableLM 2 1.6B | $45-80 (CPU instances) | Not available | Standard laptop |
| StableLM 2 12B | $180-320 (single GPU) | Stability AI Membership | RTX 3090 / A6000 |
| Qwen3 7B | $220-380 (single GPU) | $0.50-1.20 per 1M tokens | RTX 4090 / A100 |
| Mistral 7B | $240-400 (single GPU) | $0.25-0.80 per 1M tokens | RTX 4090 / A100 |
Costs assume 4-bit quantization where applicable; API pricing varies by provider and usage tier.
Common mistake: Organizations default to Mistral for European deployment without evaluating StableLM 2’s superior performance on non-French Romance languages. Benchmark both models on your specific language mix before committing.
For comprehensive cost analysis across open and proprietary models, review the Total Cost of Ownership comparison for DeepSeek R1, Qwen3, and proprietary LLMs.
What Deployment Strategies Minimize StableLM 2’s Known Limitations?
StableLM 2’s small model capacity creates inherent limitations including elevated hallucination rates, potential toxic content generation, and weaker performance on complex reasoning tasks compared to frontier models. Production deployments require specific mitigation strategies.[1]
Hallucination Mitigation Techniques:
Small language models generate factually incorrect information at higher rates than larger alternatives. StableLM 2 12B exhibits hallucination rates 2-3x higher than GPT-4 or Claude Opus on open-ended generation tasks.
Effective mitigation approaches:
- Implement RAG architecture: Ground responses in retrieved factual content rather than relying on parametric knowledge
- Use structured outputs: Constrain generation to predefined schemas, reducing open-ended hallucination opportunities
- Deploy confidence scoring: Implement secondary validation models or rule-based systems to flag low-confidence outputs
- Human-in-the-loop workflows: Route uncertain responses to human review before delivery to end users
- Prompt engineering: Use explicit instructions like “Only use information from the provided context” and “Say ‘I don’t know’ if uncertain”
Toxic Content and Safety Controls:
Both StableLM 2 variants can generate offensive, biased, or inappropriate content, particularly when processing adversarial inputs or operating in low-resource languages where training data quality varies.[1]
Production safety implementation:
- Content filtering layers: Deploy separate classifiers (Perspective API, custom fine-tuned models) to screen outputs before delivery
- Input sanitization: Detect and reject prompt injection attempts and adversarial inputs
- Output moderation: Implement keyword blocklists and pattern matching for obvious toxic content
- User feedback loops: Enable reporting mechanisms and continuously retrain on flagged outputs
- Language-specific testing: Toxic content patterns vary by language; test safety controls in all target languages independently
Complex Reasoning Task Handling:
StableLM 2 struggles with multi-step mathematical reasoning, complex logical inference, and tasks requiring extensive world knowledge. Organizations should route these tasks to more capable models.
Hybrid deployment strategy:
- Task classification layer: Identify query complexity and route simple tasks to StableLM 2, complex tasks to larger models
- StableLM 2 for: Classification, simple Q&A, content generation, entity extraction, sentiment analysis
- Larger models for: Mathematical problem-solving, complex reasoning chains, creative writing, nuanced analysis
- Cost optimization: 70-80% of enterprise queries can be handled by StableLM 2, reserving expensive model calls for genuinely complex tasks
Using platforms like MULTIBLY enables rapid A/B testing across 300+ models to identify optimal routing rules for your specific use case.
Edge case: Multilingual hallucinations are harder to detect than English-only errors. Implement language-specific validation and consider native speaker review for production deployments in critical domains (healthcare, legal, financial).
For organizations balancing performance and cost, Magistral Medium offers an alternative approach to enterprise reasoning tasks.
How Can Organizations Access and Deploy StableLM 2 Models in Production?
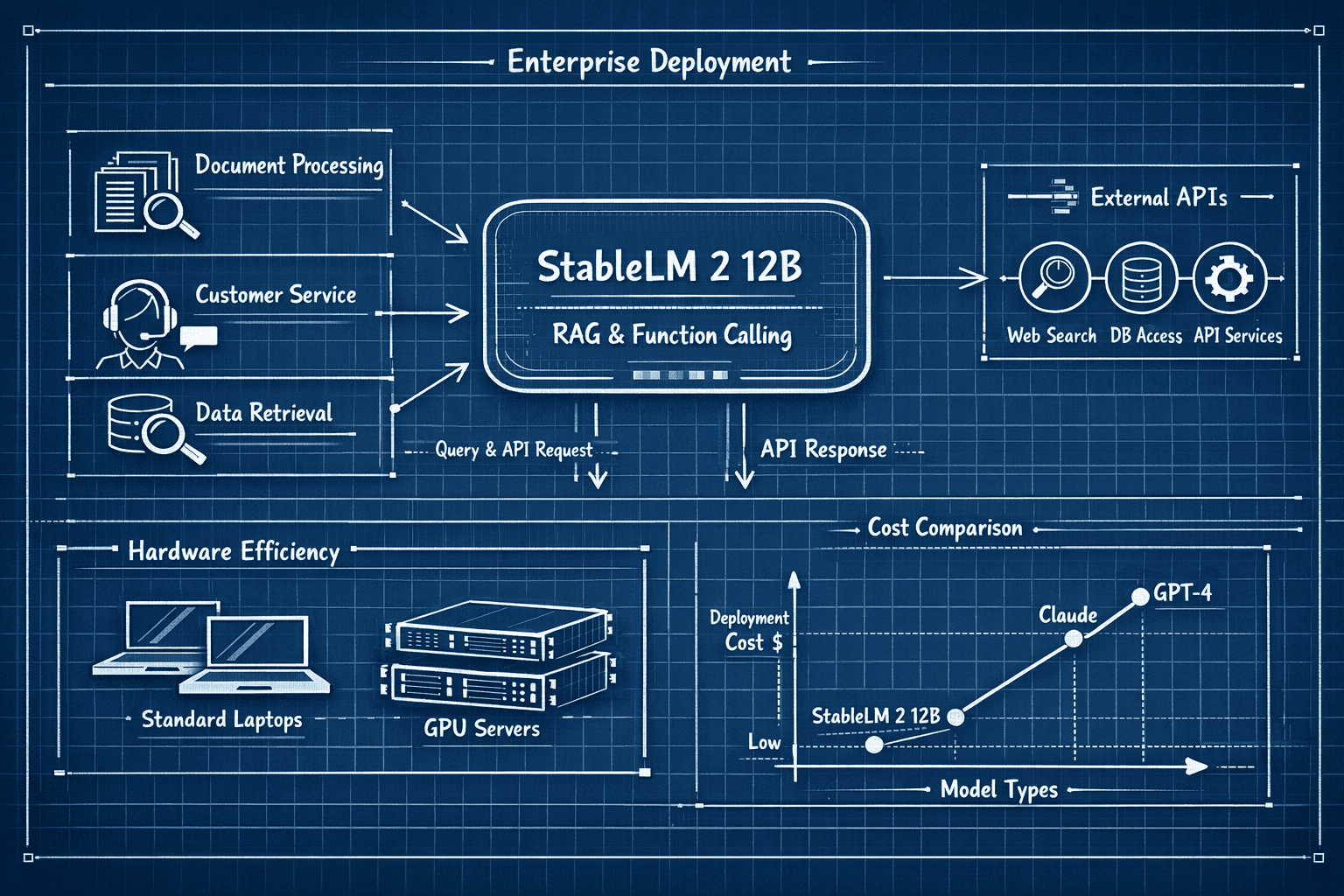
StableLM 2 models are available through multiple channels with different licensing, support, and deployment options. The optimal access method depends on organizational technical capabilities, compliance requirements, and usage scale.
Access Channels:
1. Hugging Face Hub (Open Access)
- Both 1.6B and 12B models available for immediate download
- Includes base models and instruction-tuned variants
- Requires technical capability to implement inference infrastructure
- No usage fees beyond computational costs
- Best for: Organizations with ML engineering resources and custom deployment requirements
2. Ollama (Simplified Local Deployment)
- Pre-configured model packages with optimized inference settings
- Simple command-line installation and management
- Automatic quantization and optimization for local hardware
- Best for: Developers, small teams, and rapid prototyping[6]
3. Stability AI Membership (Commercial Licensing)
- Tiered access for individuals and enterprises
- Includes commercial usage rights and indemnification
- Access to model updates and technical support
- Best for: Organizations requiring legal protection and vendor support[1][2]
Deployment Architecture Options:
Cloud-Based Deployment:
Deploy StableLM 2 on major cloud providers using GPU instances (12B model) or CPU instances (1.6B model).
Recommended configurations:
- AWS: g5.xlarge (NVIDIA A10G) for 12B model, t3.xlarge for 1.6B model
- Google Cloud: n1-standard-4 with T4 GPU for 12B, n1-standard-2 for 1.6B
- Azure: NC6s_v3 (V100) for 12B, D4s_v3 for 1.6B
On-Premise Deployment:
Organizations with data sovereignty requirements or existing GPU infrastructure can deploy locally.
Hardware requirements:
- 1.6B model: Any modern CPU (8GB+ RAM), runs efficiently on laptops
- 12B model (full precision): NVIDIA RTX 3090/4090, A6000, or better (24GB+ VRAM)
- 12B model (quantized): NVIDIA RTX 3060 or better (12GB+ VRAM), or CPU with 16GB+ RAM
Edge Deployment:
The 1.6B model’s minimal resource requirements enable deployment on edge devices including mobile phones, IoT gateways, and embedded systems.
Containerization and Orchestration:
Production deployments benefit from containerization using Docker and orchestration with Kubernetes for scaling and reliability.
Sample deployment workflow:
- Pull model weights from Hugging Face or Ollama
- Containerize inference server (FastAPI, TorchServe, or vLLM)
- Configure auto-scaling based on request volume
- Implement load balancing across multiple model instances
- Set up monitoring for latency, throughput, and error rates
Quantization for Production:
Both models support 4-bit and 8-bit quantization, reducing memory requirements and increasing inference speed with minimal accuracy degradation.
Quantization performance impact:
- 4-bit quantization: 60-75% memory reduction, 1.5-2x speed increase, 2-4% accuracy decrease
- 8-bit quantization: 40-50% memory reduction, 1.2-1.5x speed increase, 1-2% accuracy decrease
For teams evaluating deployment options across multiple models, MULTIBLY’s platform provides unified access to 300+ models including StableLM 2, enabling rapid comparison and testing before committing to production deployment.
What Fine-Tuning Strategies Maximize StableLM 2’s Performance for Specific Domains?
Stability AI released StableLM 2’s final pre-training checkpoint including optimizer states, enabling organizations to fine-tune models for domain-specific applications while maintaining multilingual capabilities.[1] This transparency differentiates StableLM 2 from proprietary alternatives and enables customization impossible with API-only models.
Fine-Tuning Approaches:
1. Continued Pre-Training
Extend the base model’s training on domain-specific corpora to improve performance in specialized fields (legal, medical, financial, technical).
When to use continued pre-training:
- You have large domain-specific datasets (100M+ tokens)
- Your domain uses specialized vocabulary not well-represented in general training data
- You need improved performance across all downstream tasks in that domain
- You can accept the computational cost (similar to initial training)
Implementation considerations:
- Start from the released pre-training checkpoint
- Use lower learning rates (10-20% of original training rate)
- Maintain multilingual balance in domain-specific data
- Monitor for catastrophic forgetting on general tasks
2. Supervised Fine-Tuning (SFT)
Train the instruction-tuned model on task-specific examples to improve performance on particular applications (customer service, content moderation, data extraction).
When to use supervised fine-tuning:
- You have high-quality labeled examples (1,000-100,000 samples)
- Your task follows consistent patterns and schemas
- You need reliable performance on specific formats or outputs
- You want faster training than continued pre-training
Best practices:
- Use the instruction-tuned variant as starting point
- Balance examples across all target languages
- Include negative examples and edge cases
- Validate on held-out test set from each language
3. Parameter-Efficient Fine-Tuning (PEFT)
Use techniques like LoRA (Low-Rank Adaptation) or QLoRA to fine-tune models with minimal computational resources and faster iteration.
Advantages of PEFT:
- Train on consumer GPUs (RTX 3090, 4090)
- Reduce training time by 60-80%
- Maintain multiple task-specific adapters for the same base model
- Easier experimentation and iteration
Recommended PEFT configuration for StableLM 2:
- LoRA rank: 16-32 for 1.6B model, 32-64 for 12B model
- Target modules: Query and Value attention matrices
- Learning rate: 1e-4 to 3e-4
- Batch size: 8-16 per GPU
4. Reinforcement Learning from Human Feedback (RLHF)
Optimize model outputs based on human preferences, particularly useful for improving response quality, reducing hallucinations, and aligning with brand voice.
When RLHF makes sense:
- Supervised fine-tuning produces outputs that are technically correct but suboptimal
- You need to optimize for subjective quality criteria
- You have access to human evaluators or preference data
- You can manage the complexity of reward model training
Common fine-tuning mistake: Organizations fine-tune on English-only data and lose multilingual capabilities. Always include examples from all target languages in your fine-tuning dataset, even if English dominates your use case.
Data Requirements by Approach:
| Fine-Tuning Method | Minimum Data | Recommended Data | Training Time (12B) | GPU Requirements |
|---|---|---|---|---|
| Continued Pre-Training | 50M tokens | 500M+ tokens | 3-7 days | 4-8x A100 |
| Supervised Fine-Tuning | 1,000 examples | 10,000-100,000 examples | 4-12 hours | 1-2x A100 |
| PEFT (LoRA/QLoRA) | 500 examples | 5,000-50,000 examples | 2-6 hours | 1x RTX 4090 |
| RLHF | 5,000 preferences | 50,000+ preferences | 1-3 days | 2-4x A100 |
Organizations exploring fine-tuning strategies across multiple open models should review The Open-Source AI Surge for comparative approaches.
How Does StableLM 2 Fit into a Multi-Model Enterprise AI Strategy?
No single model optimally handles all enterprise AI workloads. StableLM 2 excels at specific tasks within a broader multi-model architecture that routes queries to the most cost-effective, performant option for each use case.
Multi-Model Architecture Framework:
Tier 1: Lightweight Models (StableLM 2 1.6B, Phi-4)
- Use for: Simple classification, sentiment analysis, spam detection, basic Q&A
- Advantages: Extremely low latency (sub-100ms), minimal cost, edge deployment capability
- Volume: 40-50% of enterprise queries
- Cost: $0.001-0.01 per 1,000 requests
Tier 2: Mid-Range Models (StableLM 2 12B, Mistral 7B)
- Use for: RAG systems, function calling, document summarization, entity extraction
- Advantages: Balanced performance and cost, good multilingual support
- Volume: 30-40% of enterprise queries
- Cost: $0.10-0.50 per 1,000 requests
Tier 3: Frontier Models (GPT-4, Claude Opus, Gemini Ultra)
- Use for: Complex reasoning, creative tasks, nuanced analysis, high-stakes decisions
- Advantages: Best absolute performance, lowest hallucination rates
- Volume: 10-20% of enterprise queries
- Cost: $5-20 per 1,000 requests
Task Routing Logic:
Implement a classification layer that analyzes incoming queries and routes to the appropriate model tier based on complexity, language, and domain.
Sample routing rules:
- Route to StableLM 2 1.6B if: Query is classification, sentiment, or simple factual lookup; latency requirement < 200ms; non-critical application
- Route to StableLM 2 12B if: Query requires function calling, RAG, or summarization; multilingual support needed; moderate complexity
- Route to frontier model if: Query requires multi-step reasoning; high-stakes decision; creative generation; complex analysis
Cost Optimization Through Tiering:
Organizations implementing multi-model architectures typically reduce AI costs by 60-75% compared to routing all queries to frontier models, while maintaining or improving user satisfaction.
Example cost comparison (1M queries/month):
- All GPT-4: $15,000-25,000/month
- Multi-model with StableLM 2: $3,500-7,500/month
- Savings: 70-80% reduction
Integration with MULTIBLY:
The MULTIBLY platform enables organizations to test routing strategies across 300+ models before committing to production deployment. Compare StableLM 2’s responses against alternatives like Claude Opus 4.5 or GPT-5 side-by-side to identify optimal routing thresholds.
Monitoring and Continuous Optimization:
Track performance metrics by model tier to continuously refine routing rules.
Key metrics to monitor:
- Accuracy by model tier: Validate that routing decisions maintain quality standards
- Cost per query type: Identify opportunities to shift more queries to lower-cost tiers
- Latency distribution: Ensure lightweight models meet performance requirements
- User satisfaction: Correlate model choice with user feedback and engagement
Edge case: Some queries appear simple but require frontier model capabilities. Implement fallback mechanisms where StableLM 2 can escalate to larger models when confidence scores fall below thresholds.
For comprehensive enterprise AI strategy, review Enterprise AI Adoption in 2026 for broader context on multi-model deployment patterns.
Frequently Asked Questions
What languages does StableLM 2 support natively?
StableLM 2 supports seven languages with native training: English, Spanish, German, Italian, French, Portuguese, and Dutch. The models were trained on balanced multilingual corpora across these languages, enabling superior performance compared to English-centric models adapted through translation or fine-tuning.[1]
Can StableLM 2 run on a laptop without a GPU?
Yes, the 1.6B parameter variant runs efficiently on standard laptops without GPU acceleration, requiring only 2-3GB of RAM for inference. The 12B model can run on CPU with quantization but delivers significantly better performance with GPU acceleration (RTX 3090 or better recommended).[1][2]
How does StableLM 2’s commercial licensing work?
StableLM 2 is available for both commercial and non-commercial use through Stability AI Membership, which offers tiered access for individuals and enterprises. The models are also available through Hugging Face and Ollama for organizations that prefer self-hosted deployment.[1][2]
What are the main limitations of StableLM 2 compared to GPT-4 or Claude?
StableLM 2 exhibits higher hallucination rates (2-3x), weaker complex reasoning capabilities, and potential toxic content generation compared to frontier models. These limitations stem from the smaller model capacity and require mitigation strategies including RAG architecture, content filtering, and human-in-the-loop workflows for production deployment.[1]
Is StableLM 2 better than Mistral for European markets?
StableLM 2 delivers superior performance on Romance languages other than French (Spanish, Italian, Portuguese) and comparable performance on Germanic languages (German, Dutch) compared to Mistral. Choose StableLM 2 for broader European language coverage; choose Mistral for English and French-dominant workloads requiring maximum reasoning performance.
Can I fine-tune StableLM 2 on my own data?
Yes, Stability AI released the final pre-training checkpoint including optimizer states, enabling continued pre-training, supervised fine-tuning, and parameter-efficient fine-tuning (PEFT) approaches. This transparency enables domain-specific customization while maintaining multilingual capabilities.[1]
What hardware do I need to fine-tune the 12B model?
Supervised fine-tuning requires 1-2 NVIDIA A100 GPUs for standard approaches. Parameter-efficient fine-tuning (LoRA/QLoRA) can be performed on consumer GPUs like RTX 4090 with 24GB VRAM, making fine-tuning accessible to smaller organizations and research teams.
How does StableLM 2 handle function calling and tool usage?
The instruction-tuned 12B variant achieves 87-92% accuracy on function calling tasks with well-defined schemas, comparable to proprietary models. Production deployments should implement schema validation and error handling to manage occasional parameter type errors or missing required fields.[2]
What is the context window size for StableLM 2?
StableLM 2 supports context windows up to 4,096 tokens, though performance degrades beyond 3,000 tokens in practice. For applications requiring longer context, consider alternatives like Kimi K2 (256K tokens) or implement chunking strategies with RAG architecture.
Can StableLM 2 generate code in multiple programming languages?
Yes, both variants can generate code in popular programming languages (Python, JavaScript, Java, C++), though the 12B model delivers significantly better results. Code generation quality is comparable to Llama2 13B but below specialized coding models like CodeLlama or GPT-4.
How frequently does Stability AI update StableLM 2 models?
Stability AI follows an iterative release schedule with major updates every 6-12 months and minor improvements released as they become available. Organizations using Stability AI Membership receive access to updates and migration support.
What monitoring should I implement for production StableLM 2 deployment?
Monitor latency (p50, p95, p99), throughput (requests per second), error rates, hallucination frequency (through sampling and human review), content safety violations, and cost per query. Implement alerting for degraded performance and automated rollback capabilities for model updates.
Conclusion
StableLM 2’s Multilingual Mastery: Stability AI’s Open Models for Global Enterprise Deployment in 2026 represents a strategic option for organizations serving non-English markets with cost-effective, transparent, and performant AI capabilities. The 1.6B and 12B parameter variants deliver competitive performance at computational requirements and costs far below proprietary alternatives, while maintaining the flexibility and data sovereignty that open-source deployment enables.
The key decision factors: choose StableLM 2 when multilingual support across Western European and Latin American languages matters more than absolute peak performance, when data sovereignty and deployment flexibility are requirements, and when transparent training methodology enables compliance and customization needs.
Actionable next steps:
- Benchmark on your specific use cases: Use MULTIBLY’s platform to compare StableLM 2 against alternatives on your actual queries and languages before committing to production deployment
- Start with the 1.6B model: Deploy the lightweight variant for initial testing and scale to the 12B model only when performance gaps emerge on specific tasks
- Implement multi-model routing: Build a tiered architecture that routes simple queries to StableLM 2 and complex tasks to frontier models, optimizing for cost and performance
- Deploy mitigation strategies early: Implement RAG architecture, content filtering, and confidence scoring from the beginning rather than retrofitting after production issues emerge
- Plan for fine-tuning: Collect domain-specific data and user feedback to enable supervised fine-tuning that improves performance on your specific applications
- Monitor multilingual performance separately: Track accuracy, hallucination rates, and user satisfaction by language to identify and address language-specific issues
The open-source AI landscape continues evolving rapidly, with models like GLM-4.5 and DeepSeek R1 challenging proprietary dominance. StableLM 2’s combination of multilingual mastery, transparent methodology, and deployment flexibility positions it as a compelling option for global enterprise AI strategies in 2026.
References
[1] Introducing Stable Lm 2 – https://stability.ai/news/introducing-stable-lm-2
[2] Stability Ai Unveils 12b Parameter Stable Lm 2 Model Updated 1 6b Variant – https://www.artificialintelligence-news.com/news/stability-ai-unveils-12b-parameter-stable-lm-2-model-updated-1-6b-variant/
[3] Product – https://stability.ai/news/category/Product
[4] Language – https://stability.ai/news/tag/Language
[5] 12 Of The Best Large Language Models – https://www.techtarget.com/whatis/feature/12-of-the-best-large-language-models
[6] Stablelm2 – https://ollama.com/library/stablelm2
[7] Stablelm – https://sourceforge.net/software/product/StableLM/
[8] Best Large Language Models – https://codingcops.com/best-large-language-models/
[9] Molmo 2 Vs Stablelm – https://slashdot.org/software/comparison/Molmo-2-vs-StableLM/
[10] Top Small Language Models – https://www.datacamp.com/blog/top-small-language-models
Our Fact Checking Process
We prioritize accuracy and integrity in our content. Here's how we maintain high standards:
- Expert Review: All articles are reviewed by subject matter experts.
- Source Validation: Information is backed by credible, up-to-date sources.
- Transparency: We clearly cite references and disclose potential conflicts.
Our Review Board
Our content is carefully reviewed by experienced professionals to ensure accuracy and relevance.
- Qualified Experts: Each article is assessed by specialists with field-specific knowledge.
- Up-to-date Insights: We incorporate the latest research, trends, and standards.
- Commitment to Quality: Reviewers ensure clarity, correctness, and completeness.
Look for the expert-reviewed label to read content you can trust.



