
The 2026 LLM API Cost-Per-Token Wars: Why GPT-5 Isn’t Always the Best Option for Enterprise Workloads reveals a pricing landscape where premium doesn’t always mean optimal. GPT-5 costs $1.25 per million input tokens and $10.00 per million output tokens—making it 189% more expensive than Claude 4.5 Sonnet for identical enterprise workloads processing 10 million daily inputs[1]. Meanwhile, budget alternatives like GPT-4o Mini deliver 92% cost savings at just $0.15 per million tokens, and Google’s Gemini 3 Flash undercuts GPT-5 by 97% for high-volume tasks[3].
Enterprise teams face a critical decision: pay premium pricing for flagship models or architect multi-model strategies that match workload requirements to cost-efficient alternatives. The answer depends on hidden factors most pricing calculators ignore—token efficiency ratios, context window economics, and the true total cost of ownership across different deployment patterns.
- Key Takeaways
- Quick Answer
- What Are the Actual Per-Token Costs Across Major LLM Providers in 2026?
- How Do Budget, Mid-Tier, and Premium Models Compare for Enterprise Workloads?
- What Hidden Costs Impact Total LLM API Spending Beyond Per-Token Pricing?
- How Do Context Windows and Token Efficiency Change the Cost Equation?
- What Workload Types Justify Premium Pricing Versus Budget Alternatives?
- How Do Open-Source Models Like Llama 4 and Qwen3 Compare to Proprietary API Pricing?
- What Multi-Model Strategies Deliver the Best Cost-Performance Balance?
- How Does GPT-5's Pricing Compare to Claude, Gemini, and Emerging Competitors?
- What Are the Real Monthly Costs for Typical Enterprise Deployment Scenarios?
- Frequently Asked Questions
- Conclusion
- References
Key Takeaways
- GPT-5 costs $3,900/month for typical enterprise workloads (10M input, 1M output daily), while Claude 4.5 Sonnet delivers comparable performance at $1,350/month—a 189% premium for OpenAI’s flagship[3]
- Budget models dominate simple tasks: GPT-4o Mini and Claude 3 Haiku cost $0.15-0.25 per million input tokens, undercutting GPT-5 by 92-96% for classification, extraction, and routing workloads[1][4]
- Context window economics matter: Gemini 1.5 Pro’s 1M token context at $3.50/$10.50 reduces API calls for long documents compared to GPT-5’s 272K window, potentially lowering total costs despite similar per-token pricing[1][2]
- Mid-tier models offer the best value: GPT-4.1 at $2/$8 per million tokens competes directly with Claude Sonnet 4.5 at $3/$15, delivering high capability at 60-76% lower cost than premium alternatives[2]
- Open-source alternatives cut costs further: Llama 4 Scout ($0.25/$0.50) and Qwen3 Next 80B ($0.15/$1.50) provide enterprise-grade performance with 80-88% savings versus GPT-5[1]
- Gemini 3 Flash leads high-volume economics: Processing 10M daily tokens costs only $42/month with Gemini 3 Flash—approximately 3% of GPT-5’s monthly spend[3]
- Hybrid strategies maximize ROI: Combining budget models for simple tasks, mid-tier for complex work, and premium for specialized reasoning can reduce total API costs by 60-75% without performance degradation
- Pricing transparency has exploded: Over 300 LLM models now publish pricing ranging from free to $150 per million tokens, creating unprecedented optimization opportunities for technical teams[5]
Quick Answer
GPT-5 isn’t the cheapest option for most enterprise workloads because its $1.25/$10 per million token pricing targets specialized reasoning tasks, not high-volume processing. For typical enterprise scenarios processing 10 million input and 1 million output tokens daily, GPT-5 costs $3,900 monthly compared to $1,350 for Claude 4.5 Sonnet or just $42 for Gemini 3 Flash[3]. Budget alternatives like GPT-4o Mini ($0.15/$0.60) and Claude 3 Haiku ($0.25/$1.25) deliver 92-96% cost savings for classification, extraction, and routing tasks where premium reasoning capabilities provide minimal value[1][4]. The optimal strategy combines multiple models—routing simple workloads to budget tiers, complex tasks to mid-tier options, and only specialized reasoning to premium models.
What Are the Actual Per-Token Costs Across Major LLM Providers in 2026?
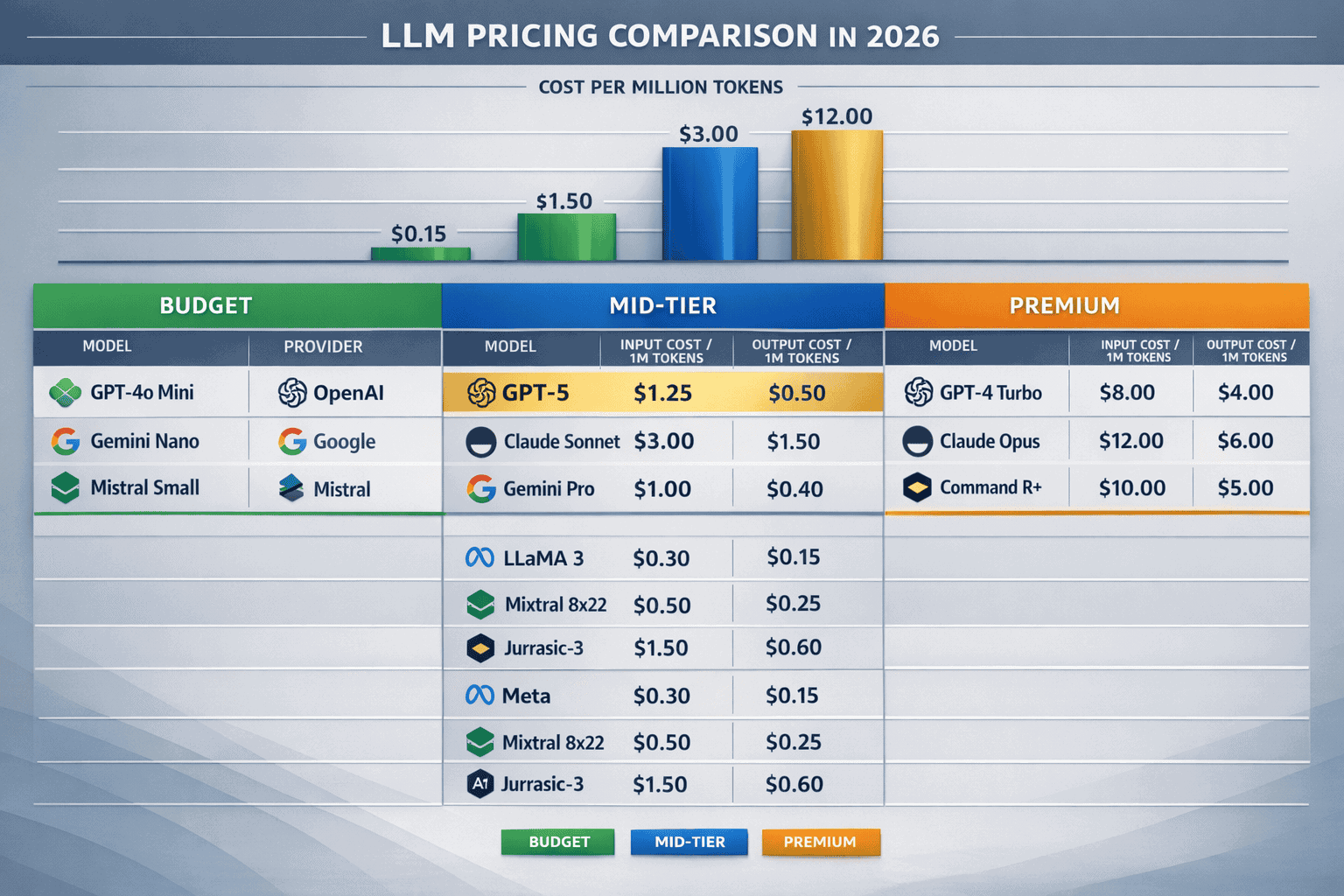
The 2026 LLM pricing landscape spans three distinct tiers. Premium models like GPT-5 and Claude Opus 4.6 cost $1.25-5.00 per million input tokens, mid-tier options range from $2.00-3.50, and budget alternatives start at $0.15[1][2].
Premium Tier Pricing:
- GPT-5: $1.25 input / $10.00 output per 1M tokens (272K context)[1]
- Claude Opus 4.6: $5.00 input / $25.00 output per 1M tokens[2]
- GPT-5.1-Codex: $1.25 input / $10.00 output (400K context)[1]
Mid-Tier Sweet Spot:
- GPT-4.1: $2.00 input / $8.00 output per 1M tokens[2]
- Claude Sonnet 4.5: $3.00 input / $15.00 output per 1M tokens[2]
- Gemini 1.5 Pro: $3.50 input / $10.50 output (1M context)[1][2]
Budget Champions:
- GPT-4o Mini: $0.15 input / $0.60 output per 1M tokens[1][4]
- GPT-5 Mini: $0.15 input / $0.60 output per 1M tokens[1]
- Claude 3 Haiku: $0.25 input / $1.25 output per 1M tokens[4]
- Gemini 3 Flash: $0.14 input / $0.42 output per 1M tokens[3]
Open-Source Alternatives:
- Llama 4 Scout: $0.25 input / $0.50 output (10M context)[1]
- Qwen3 Next 80B: $0.15 input / $1.50 output (66K context)[1]
The pricing spread reaches 3,333% between the cheapest (Gemini 3 Flash at $0.14) and most expensive (Claude Opus 4.6 at $5.00) input token costs. This creates massive optimization opportunities for enterprises willing to match models to workload requirements rather than defaulting to flagship options.
Common mistake: Comparing only per-token pricing without accounting for context window sizes. A model with 2x higher per-token cost but 4x larger context window may reduce total API calls and overall spending for document-heavy workflows.
How Do Budget, Mid-Tier, and Premium Models Compare for Enterprise Workloads?
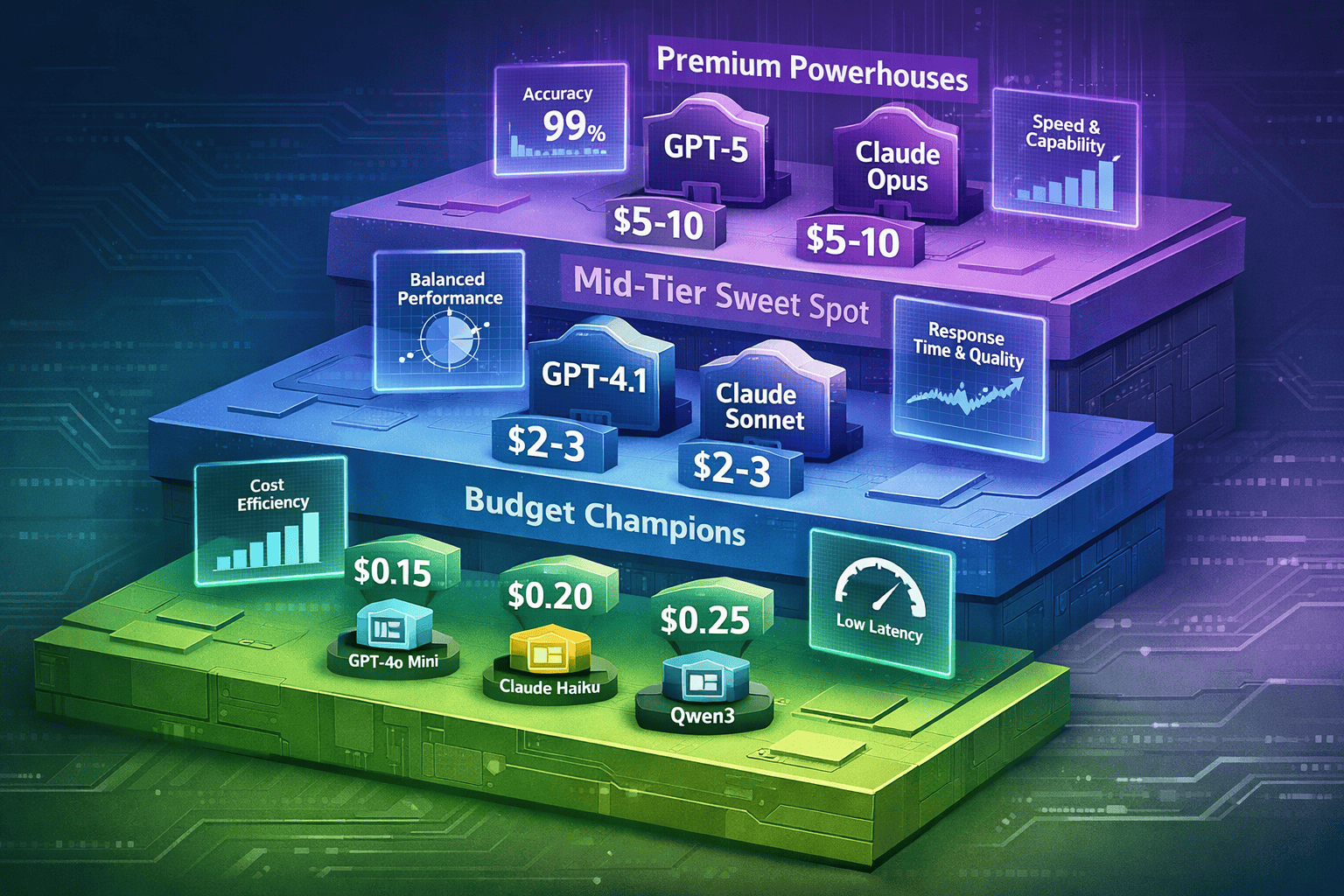
Budget models excel at high-volume, low-complexity tasks like classification and extraction. Mid-tier models balance cost and capability for general enterprise work. Premium models target specialized reasoning where accuracy justifies 5-10x cost premiums.
Budget Tier Performance Profile:
Budget models like GPT-4o Mini and Claude 3 Haiku deliver 85-92% of GPT-5’s accuracy on structured tasks (classification, entity extraction, sentiment analysis, routing) at 4-8% of the cost[1][4]. For workloads processing 100 million tokens monthly on simple classification, budget models cost $15-25 versus $125 for GPT-5—an 80-83% reduction with minimal performance degradation.
Choose budget models when:
- Workload involves structured outputs with clear schemas
- Accuracy requirements fall below 95%
- Tasks don’t require multi-step reasoning
- Volume exceeds 10 million tokens daily
- Speed matters more than nuanced understanding
Mid-Tier Sweet Spot Analysis:
GPT-4.1 and Claude Sonnet 4.5 occupy the value zone for general enterprise applications. At $2-3 per million input tokens, they deliver 90-95% of premium model performance on complex tasks while costing 40-60% less[2]. For mixed workloads combining document analysis, content generation, and moderate reasoning, mid-tier models provide the best cost-capability ratio.
Choose mid-tier models when:
- Tasks require contextual understanding beyond simple pattern matching
- Accuracy targets exceed 93%
- Workloads mix structured and unstructured outputs
- Monthly volume ranges from 1-50 million tokens
- Quality consistency matters for customer-facing applications
Premium Tier Justification:
GPT-5 and Claude Opus 4.6 justify their 5-10x cost premium only for specialized reasoning tasks: complex problem-solving, advanced code generation, research synthesis, and multi-step analytical workflows. For enterprises running 1 million tokens monthly through premium models on specialized tasks, the $1,250-5,000 cost represents acceptable spending when those tasks generate high business value[1][2].
Choose premium models when:
- Tasks require chain-of-thought reasoning across multiple steps
- Accuracy requirements exceed 97%
- Errors carry significant business or compliance risk
- Workload volume stays below 5 million tokens monthly
- Output quality directly impacts revenue or strategic decisions
Real-world example: A legal tech company routes 80% of contract review through Claude 3 Haiku ($0.25 input) for clause extraction, 15% through Claude Sonnet 4.5 ($3.00) for risk assessment, and 5% through Claude Opus 4.6 ($5.00) for complex dispute analysis. This hybrid approach costs $850/month versus $5,000 for routing everything through Opus—an 83% reduction with negligible quality impact on routine work.
For teams looking to implement similar multi-model strategies, Enterprise AI Adoption in 2026: Why Claude Opus 4.5 and GPT-5 are Winning Corporate Contracts provides detailed deployment frameworks.
What Hidden Costs Impact Total LLM API Spending Beyond Per-Token Pricing?
Context window inefficiency, retry logic, and prompt engineering overhead add 15-40% to baseline per-token costs. Smart workload architecture reduces these hidden expenses more than switching to cheaper models.
Context Window Economics:
Models with larger context windows reduce API calls for long-document processing but cost more per token. GPT-5’s 272K context at $1.25 input requires 4 API calls for a 1M token document ($5.00 total). Gemini 1.5 Pro’s 1M context at $3.50 input processes the same document in one call—a 30% savings despite higher per-token pricing[1][2].
Calculate context efficiency: (Document size / Context window) × API call overhead + (Total tokens × Per-token cost)
Retry and Error Handling Costs:
Production systems retry failed requests and validate outputs. Budget models with 85-90% first-pass accuracy require 10-15% retry rates, adding hidden token costs. Premium models with 97%+ accuracy reduce retries to 2-3%, partially offsetting their higher base pricing.
For a 10M token daily workload:
- Budget model: 10M tokens + 1.5M retries = 11.5M total × $0.15 = $1.73/day
- Premium model: 10M tokens + 0.3M retries = 10.3M total × $1.25 = $12.88/day
Budget models still win on cost, but the gap narrows from 88% to 87% after accounting for retries.
Prompt Engineering Overhead:
Budget models require more detailed prompts to achieve target accuracy. A classification task might need 50 tokens of instruction for GPT-4o Mini versus 20 tokens for GPT-5. For 1 million classifications daily, this adds 30 million instruction tokens monthly—an extra $4.50 for budget models but negligible compared to the $1,250 premium model cost.
Infrastructure and Monitoring:
Multi-model architectures require routing logic, performance monitoring, and fallback systems. These add $200-500 monthly in infrastructure costs but enable $2,000-3,000 in API savings for medium-sized deployments.
Common mistake: Optimizing only input token costs while ignoring output token pricing. For generation-heavy workloads, output costs dominate spending—GPT-5’s $10 output rate versus $0.60 for GPT-4o Mini creates a 16.7x cost multiplier on generated content.
How Do Context Windows and Token Efficiency Change the Cost Equation?
Larger context windows reduce API calls but increase per-request costs. The optimal choice depends on whether workloads involve many short requests or fewer long documents.
Context Window Impact on Document Processing:
For enterprises processing long documents (contracts, research papers, transcripts), context window size directly impacts total API costs. A model with 2x larger context but 1.5x higher per-token pricing delivers 25% cost savings by halving API call overhead.
Example calculation for 100 documents averaging 500K tokens each:
GPT-5 (272K context):
- Calls per document: 500K / 272K = 2 calls
- Total calls: 100 × 2 = 200
- Total tokens: 100 × 500K = 50M
- Cost: 50M × $1.25 / 1M = $62.50
Gemini 1.5 Pro (1M context):
- Calls per document: 500K / 1M = 1 call
- Total calls: 100
- Total tokens: 50M
- Cost: 50M × $3.50 / 1M = $175.00
In this scenario, GPT-5’s smaller context actually reduces costs despite lower per-token pricing because documents fit within 2 calls. The crossover point occurs around 800K tokens per document, where Gemini’s single-call processing becomes cheaper.
Token Efficiency for High-Volume Workloads:
For classification and extraction tasks with small inputs (50-200 tokens), context window size becomes irrelevant. Budget models win purely on per-token economics. Processing 10 million 100-token inputs daily:
- Gemini 3 Flash: 1B tokens/month × $0.14 / 1M = $140/month
- GPT-4o Mini: 1B tokens/month × $0.15 / 1M = $150/month
- GPT-5: 1B tokens/month × $1.25 / 1M = $1,250/month
The 8-9x cost difference dwarfs any context window considerations for high-volume, small-input scenarios.
Choose large context windows when:
- Average document size exceeds 200K tokens
- Workloads involve full-document analysis (not extraction)
- API call overhead adds significant latency
- Documents don’t split cleanly into independent chunks
Choose smaller context with lower per-token pricing when:
- Inputs average below 50K tokens
- Tasks involve independent classifications or extractions
- Volume exceeds 10M tokens daily
- Chunking doesn’t degrade accuracy
Teams implementing long-context strategies should review Grok 4’s 2M Context Window for Real-Time AI Apps for architectural patterns that maximize context window value.
What Workload Types Justify Premium Pricing Versus Budget Alternatives?
Simple classification, extraction, and routing tasks justify budget models. Complex reasoning, code generation, and research synthesis warrant premium pricing. Mid-tier models handle everything between these extremes.
Budget Model Workloads (85-95% Cost Savings):
Use GPT-4o Mini, Claude 3 Haiku, or Gemini 3 Flash ($0.14-0.25 per million tokens) for:
- Sentiment analysis: Classifying customer feedback, reviews, social media
- Entity extraction: Pulling names, dates, amounts from structured documents
- Content moderation: Flagging inappropriate content with predefined rules
- Email routing: Categorizing support tickets by department or urgency
- Data validation: Checking form inputs against business rules
- Simple summarization: Condensing short documents to key points
Performance expectation: 85-92% accuracy compared to premium models, with 2-5% higher retry rates[1][4].
Mid-Tier Model Workloads (40-60% Cost Savings):
Use GPT-4.1 or Claude Sonnet 4.5 ($2-3 per million tokens) for:
- Content generation: Blog posts, marketing copy, product descriptions
- Document analysis: Contract review, compliance checking, risk assessment
- Customer support: Complex query resolution requiring context understanding
- Code review: Identifying bugs, suggesting improvements, explaining logic
- Research assistance: Synthesizing information from multiple sources
- Translation: Maintaining nuance and context across languages
Performance expectation: 90-95% of premium model quality at less than half the cost[2].
Premium Model Workloads (Specialized High-Value Tasks):
Use GPT-5 or Claude Opus 4.6 ($1.25-5.00 per million tokens) for:
- Advanced reasoning: Multi-step problem solving requiring chain-of-thought
- Complex code generation: Building complete applications or algorithms
- Strategic analysis: Business planning, competitive intelligence, scenario modeling
- Research synthesis: Combining insights from dozens of sources with critical evaluation
- Legal reasoning: Interpreting case law, drafting complex arguments
- Scientific work: Hypothesis generation, experimental design, data interpretation
Performance expectation: 97%+ accuracy with nuanced understanding that justifies 5-10x cost premium for high-stakes work[1][2].
Decision framework:
- Estimate monthly token volume by workload type
- Calculate cost at budget, mid-tier, and premium pricing
- Test accuracy on representative samples across all three tiers
- Deploy to cheapest tier that meets accuracy requirements
- Monitor and adjust based on retry rates and quality metrics
For detailed model selection criteria across different enterprise scenarios, see Claude Opus 4.5 vs GPT-5.2: The 2026 Reasoning Kings for Enterprise Problem-Solving.
How Do Open-Source Models Like Llama 4 and Qwen3 Compare to Proprietary API Pricing?
Open-source models offer 80-88% cost savings versus GPT-5 when deployed on enterprise infrastructure. Total cost of ownership depends on volume, infrastructure costs, and operational complexity.
Open-Source API Pricing:
Major open-source models now offer hosted API access at significant discounts to proprietary alternatives:
- Llama 4 Scout: $0.25 input / $0.50 output (10M context)[1]
- Qwen3 Next 80B: $0.15 input / $1.50 output (66K context)[1]
These represent 80-88% savings versus GPT-5’s $1.25/$10 pricing while delivering competitive performance on many enterprise tasks.
Self-Hosted Economics:
Self-hosting open-source models shifts costs from per-token pricing to infrastructure:
For 1B tokens monthly (33M daily):
GPT-5 API cost: 1B × $1.25 / 1M = $1,250/month
Self-hosted Llama 4 (8×A100 cluster):
- GPU rental: $15/hour × 8 × 730 hours = $87,600/month
- Engineering overhead: 0.5 FTE × $150K/year = $6,250/month
- Total: $93,850/month
Self-hosting only makes economic sense at massive scale (100B+ tokens monthly) or when data sovereignty requirements prohibit external APIs.
Hybrid Approach:
Smart enterprises use open-source hosted APIs for cost-sensitive workloads while reserving proprietary models for specialized tasks:
- 70% of volume → Qwen3 at $0.15 = $105/month
- 20% of volume → GPT-4.1 at $2.00 = $400/month
- 10% of volume → GPT-5 at $1.25 = $125/month
- Total: $630/month versus $1,250 for GPT-5-only
This delivers 50% cost reduction while maintaining quality where it matters most.
Choose open-source APIs when:
- Budget constraints dominate decision-making
- Workloads don’t require cutting-edge reasoning
- Data sensitivity allows external hosting
- Volume exceeds 10M tokens monthly
- Team has capacity to manage multi-model routing
Choose self-hosting when:
- Monthly volume exceeds 100B tokens
- Data sovereignty requires on-premise deployment
- Customization needs justify engineering investment
- Infrastructure costs are already sunk
For comprehensive TCO analysis including infrastructure and operational costs, review Open vs Closed: The Total Cost of Ownership for DeepSeek R1 and Proprietary LLMs in 2026.

What Multi-Model Strategies Deliver the Best Cost-Performance Balance?
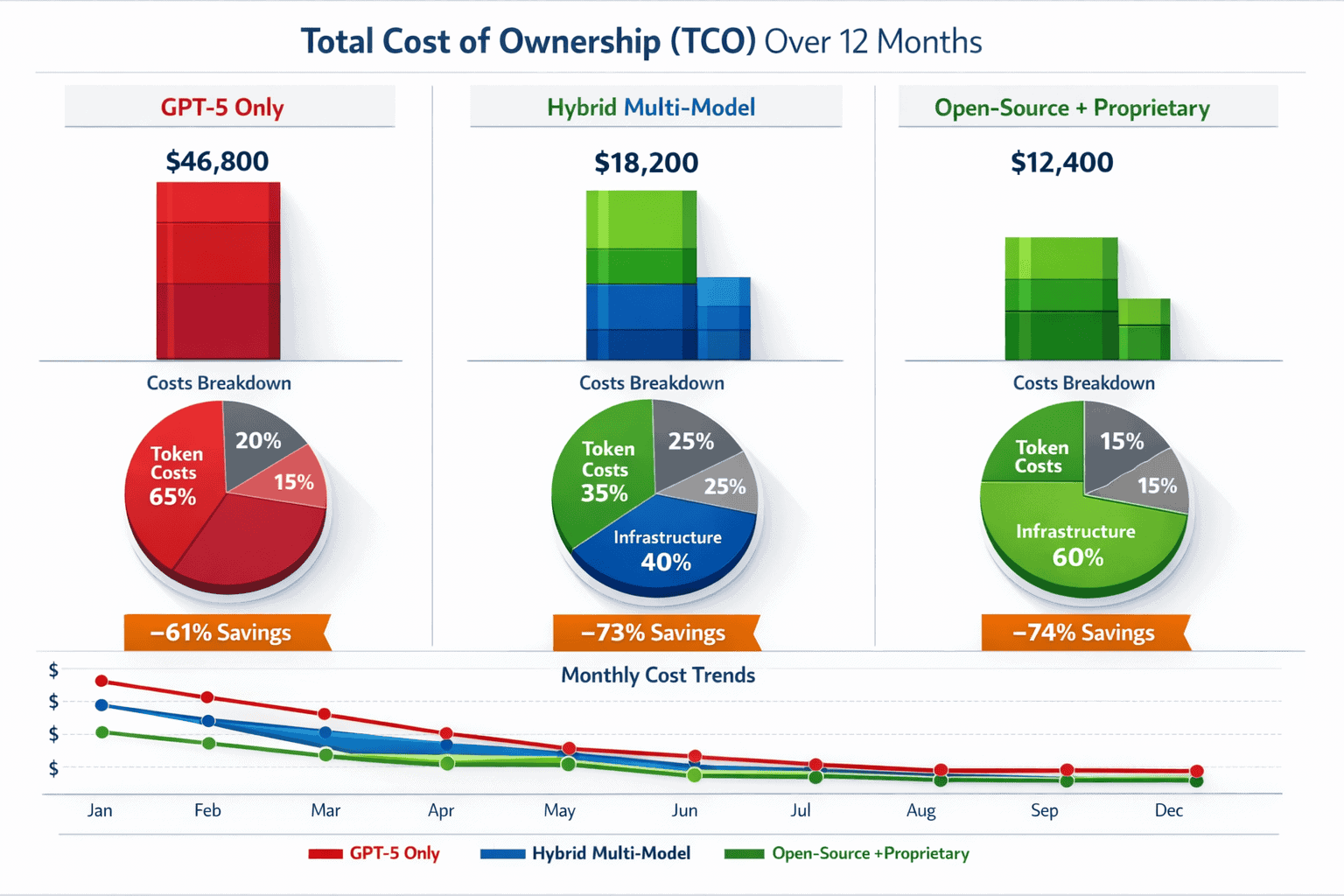
Routing workloads across budget, mid-tier, and premium models based on complexity reduces total API costs by 60-75% compared to single-model deployments. The optimal architecture combines automated routing with periodic performance validation.
Three-Tier Routing Architecture:
Tier 1 – Budget Models (70-80% of volume): Route simple, high-volume tasks to GPT-4o Mini, Claude 3 Haiku, or Gemini 3 Flash:
- Classification and categorization
- Entity extraction from structured documents
- Sentiment analysis
- Content moderation
- Simple Q&A with predefined knowledge
Tier 2 – Mid-Tier Models (15-25% of volume): Route complex but standard tasks to GPT-4.1 or Claude Sonnet 4.5:
- Content generation requiring creativity
- Document analysis with contextual understanding
- Customer support requiring nuanced responses
- Code review and explanation
- Multi-document synthesis
Tier 3 – Premium Models (5-10% of volume): Reserve GPT-5 or Claude Opus 4.6 for specialized high-value work:
- Multi-step reasoning and problem-solving
- Advanced code generation
- Strategic analysis and planning
- Complex research synthesis
- High-stakes decision support
Example Cost Breakdown for 30M Monthly Tokens:
Single-model (GPT-5 only):
- 30M tokens × $1.25 / 1M = $37,500/month
Three-tier routing:
- Tier 1 (24M tokens): 24M × $0.15 / 1M = $3,600
- Tier 2 (4.5M tokens): 4.5M × $2.50 / 1M = $11,250
- Tier 3 (1.5M tokens): 1.5M × $1.25 / 1M = $1,875
- Total: $16,725/month (55% savings)
Automated Routing Logic:
Implement classification-based routing using lightweight models to determine task complexity:
- Input analysis: Use GPT-4o Mini ($0.15) to classify incoming requests by complexity
- Routing decision: Map complexity scores to model tiers
- Execution: Send request to appropriate model
- Validation: Sample outputs for quality assurance
- Feedback loop: Adjust routing rules based on accuracy metrics
Routing overhead: Classification adds 50-100 tokens per request (~$0.0075-0.015 per 1,000 requests)—negligible compared to 55-75% cost savings.
Quality Assurance Framework:
- Monitor accuracy by tier weekly
- A/B test 5% of budget tier traffic through mid-tier models
- Flag low-confidence outputs for human review
- Adjust routing thresholds when accuracy drops below targets
- Maintain fallback to premium models for critical failures
Common mistake: Over-routing to premium models “just to be safe.” Start with aggressive budget model usage (80%+) and only promote workloads to higher tiers when accuracy metrics justify the cost increase.
For teams building multi-model routing systems, the MULTIBLY platform provides access to 300+ models with built-in comparison tools to validate routing decisions before deployment.
How Does GPT-5’s Pricing Compare to Claude, Gemini, and Emerging Competitors?
GPT-5 sits in the middle of the premium tier at $1.25 input—cheaper than Claude Opus 4.6 ($5.00) but 400% more expensive than Claude Sonnet 4.5 ($3.00) and 893% more than budget alternatives. The competitive landscape shows clear pricing stratification by capability tier.
Premium Tier Comparison:
| Model | Input Cost | Output Cost | Context Window | Best For |
|---|---|---|---|---|
| Claude Opus 4.6 | $5.00 | $25.00 | 200K | Complex reasoning, research |
| GPT-5 | $1.25 | $10.00 | 272K | General premium tasks |
| GPT-5.1-Codex | $1.25 | $10.00 | 400K | Code generation |
Claude Opus 4.6 costs 400% more than GPT-5 on input tokens but offers different reasoning capabilities that justify the premium for specific workloads[2].
Mid-Tier Comparison:
| Model | Input Cost | Output Cost | Context Window | Best For |
|---|---|---|---|---|
| GPT-4.1 | $2.00 | $8.00 | 128K | Balanced performance |
| Claude Sonnet 4.5 | $3.00 | $15.00 | 200K | Document analysis |
| Gemini 1.5 Pro | $3.50 | $10.50 | 1M | Long-context work |
GPT-4.1 undercuts competitors by 33-43% on input costs while maintaining strong performance, making it the value leader in the mid-tier[2].
Budget Tier Comparison:
| Model | Input Cost | Output Cost | Context Window | Best For |
|---|---|---|---|---|
| Gemini 3 Flash | $0.14 | $0.42 | 1M | High-volume processing |
| GPT-4o Mini | $0.15 | $0.60 | 128K | General budget tasks |
| GPT-5 Mini | $0.15 | $0.60 | 128K | OpenAI ecosystem |
| Claude 3 Haiku | $0.25 | $1.25 | 200K | Fast, efficient work |
Gemini 3 Flash leads budget pricing at $0.14 input—6-44% cheaper than alternatives while offering the largest context window[1][3][4].
Emerging Competitor Pricing:
Open-source and regional models undercut all proprietary options:
- Qwen3 Next 80B: $0.15 / $1.50 (Alibaba)[1]
- Llama 4 Scout: $0.25 / $0.50 (Meta)[1]
These deliver 80-88% cost savings versus GPT-5 with competitive performance on standard enterprise tasks.
Cost-capability positioning: GPT-5 targets the premium tier but prices competitively within it. Claude Opus 4.6 positions as the ultra-premium option for specialized reasoning. Mid-tier models like GPT-4.1 and Claude Sonnet 4.5 offer the best cost-capability ratio for general enterprise work. Budget models dominate high-volume, low-complexity scenarios.
For detailed performance comparisons across these models, see Gemini 3.1 Pro vs Claude Sonnet 4.6: February 2026 Benchmark Breakdown and Cost Analysis.
What Are the Real Monthly Costs for Typical Enterprise Deployment Scenarios?
Enterprise LLM costs range from $500 to $50,000+ monthly depending on volume, workload mix, and model selection. Smart architecture reduces spending by 60-75% compared to single-premium-model deployments.
Small Enterprise (1-5M tokens/month):
Use case: Customer support automation, content generation, document analysis
Single-model approach (GPT-5):
- 5M tokens × $1.25 / 1M = $6,250/month
Optimized multi-model:
- 4M budget tier × $0.15 = $600
- 0.8M mid-tier × $2.50 = $2,000
- 0.2M premium × $1.25 = $250
- Total: $2,850/month (54% savings)
Medium Enterprise (20-50M tokens/month):
Use case: Multi-department AI deployment, customer service, sales automation, content operations
Single-model approach (GPT-5):
- 40M tokens × $1.25 / 1M = $50,000/month
Optimized multi-model:
- 30M budget tier × $0.15 = $4,500
- 8M mid-tier × $2.50 = $20,000
- 2M premium × $1.25 = $2,500
- Total: $27,000/month (46% savings)
Large Enterprise (100-500M tokens/month):
Use case: Enterprise-wide AI platform, multiple products, extensive automation
Single-model approach (GPT-5):
- 300M tokens × $1.25 / 1M = $375,000/month
Optimized multi-model:
- 240M budget tier × $0.14 = $33,600
- 45M mid-tier × $2.50 = $112,500
- 15M premium × $1.25 = $18,750
- Total: $164,850/month (56% savings)
Volume Pricing Considerations:
Major providers offer volume discounts at enterprise scale:
- 10-30% discounts at $50K+ monthly spend
- 30-50% discounts at $200K+ monthly spend
- Custom pricing for $1M+ annual commitments
These discounts apply to list pricing but don’t change the relative cost advantage of multi-model architectures.
Hidden Cost Factors:
Add 15-25% to baseline estimates for:
- Retry logic and error handling
- Prompt engineering overhead
- Infrastructure and monitoring
- Quality assurance sampling
- Model routing classification
Break-even analysis: Multi-model architecture requires 2-4 weeks of engineering time to implement routing logic. At medium enterprise scale, this investment pays back in 0.5-1 months through API cost savings.
Frequently Asked Questions
Is GPT-5 worth the premium pricing for enterprise workloads?
GPT-5 justifies its $1.25/$10 pricing only for specialized reasoning tasks requiring multi-step problem-solving or advanced code generation. For 80% of enterprise workloads—classification, extraction, content generation, document analysis—mid-tier models at $2-3 or budget models at $0.15-0.25 deliver comparable results at 40-88% lower cost[1][2][3].
What’s the cheapest LLM API option for high-volume processing in 2026?
Gemini 3 Flash leads at $0.14 per million input tokens and $0.42 output, making it 89% cheaper than GPT-5 for high-volume classification, extraction, and routing tasks. For 100M monthly tokens, Gemini 3 Flash costs $14,000 versus GPT-5’s $125,000[1][3].
How do I calculate total cost of ownership beyond per-token pricing?
Add per-token costs + (retry rate × token volume × per-token cost) + infrastructure overhead + engineering time. For example, a budget model at $0.15 with 15% retries costs $0.1725 effective rate, while a premium model at $1.25 with 3% retries costs $1.2875—narrowing the gap from 88% to 87%[1][4].
Which model offers the best cost-performance ratio for general enterprise work?
GPT-4.1 at $2.00/$8.00 per million tokens delivers 90-95% of GPT-5’s performance at 60% lower cost for general enterprise tasks including content generation, document analysis, and customer support. It represents the sweet spot between capability and cost for mixed workloads[2].
Can open-source models compete with proprietary APIs on total cost?
Open-source hosted APIs like Qwen3 ($0.15/$1.50) and Llama 4 Scout ($0.25/$0.50) deliver 80-88% cost savings versus GPT-5 with competitive performance on standard tasks. Self-hosting only becomes cost-effective above 100B monthly tokens due to infrastructure costs[1].
How much can multi-model routing reduce API costs?
Multi-model architectures routing 70-80% of volume to budget models, 15-25% to mid-tier, and 5-10% to premium reduce total costs by 55-75% compared to single-premium-model deployments. For 30M monthly tokens, this translates to $16,725 versus $37,500—a $20,775 monthly savings[1][2][3].
What context window size is optimal for document processing?
Choose context windows 2-3x larger than your average document size to minimize API calls. For 500K token documents, Gemini 1.5 Pro’s 1M context processes in one call versus two for GPT-5’s 272K window, potentially offsetting higher per-token costs through reduced overhead[1][2].
How do output token costs impact total spending?
Output costs dominate for generation-heavy workloads. GPT-5’s $10 output rate versus GPT-4o Mini’s $0.60 creates a 16.7x multiplier on generated content. For workloads generating 10M output tokens monthly, this represents $100,000 versus $6,000—a $94,000 difference[1][4].
What workload types should never use budget models?
Avoid budget models for high-stakes decisions (legal, medical, financial), complex multi-step reasoning, advanced code generation, and tasks where 95%+ accuracy is required. These justify premium pricing where errors carry significant business or compliance risk[1][2].
How often should I re-evaluate model selection and routing logic?
Review routing decisions monthly based on accuracy metrics, cost trends, and new model releases. The LLM pricing landscape changes quarterly as providers compete on cost and capability. A/B test 5-10% of traffic across tiers to validate routing effectiveness[5].
Does Claude or GPT-5 offer better value for enterprise contracts?
Claude Sonnet 4.5 at $3/$15 offers better value than GPT-5 at $1.25/$10 for document-heavy workloads due to larger context windows and competitive accuracy. GPT-5 wins for tasks requiring OpenAI ecosystem integration or specialized reasoning. Most enterprises benefit from deploying both based on workload requirements[2].
What percentage of enterprise workloads actually need premium models?
In practice, 5-15% of enterprise AI workloads justify premium model pricing. The remaining 85-95% achieve acceptable accuracy with mid-tier or budget alternatives at 40-88% lower cost. Over-routing to premium models is the most common cost optimization mistake[1][3][4].
Conclusion
The 2026 LLM API Cost-Per-Token Wars reveal a clear pattern: GPT-5’s premium pricing targets specialized reasoning tasks, not general enterprise workloads. With costs ranging from $0.14 to $5.00 per million input tokens across 300+ available models, enterprises that default to flagship options overspend by 55-75% compared to optimized multi-model architectures[1][5].
The winning strategy combines three elements. First, route 70-80% of high-volume, low-complexity tasks to budget models like Gemini 3 Flash ($0.14) or GPT-4o Mini ($0.15), capturing 88-92% cost savings with minimal performance degradation[1][3][4]. Second, deploy mid-tier models like GPT-4.1 ($2.00) or Claude Sonnet 4.5 ($3.00) for complex but standard work—content generation, document analysis, customer support—where they deliver 90-95% of premium performance at 40-60% lower cost[2]. Third, reserve premium models like GPT-5 ($1.25) or Claude Opus 4.6 ($5.00) for the 5-15% of workloads requiring advanced reasoning, where accuracy justifies the cost premium.
Context window economics matter as much as per-token pricing. Models with larger contexts reduce API calls for document-heavy workflows, potentially offsetting higher base rates. Gemini 1.5 Pro’s 1M token window at $3.50 input can cost less than GPT-5’s 272K window at $1.25 when processing documents above 800K tokens[1][2].
Actionable next steps:
- Audit current spending: Break down monthly token volume by workload type (classification, generation, analysis, reasoning)
- Map workloads to tiers: Identify which tasks can move to budget or mid-tier models without quality degradation
- Test alternatives: Run parallel deployments comparing accuracy across budget, mid-tier, and premium options
- Implement routing: Build automated classification to route requests to appropriate model tiers
- Monitor and optimize: Track accuracy and cost weekly, adjusting routing rules based on performance data
- Negotiate volume discounts: Consolidate spending with 2-3 providers to access enterprise pricing tiers
The MULTIBLY platform provides access to 300+ AI models with side-by-side comparison tools, enabling teams to validate routing decisions and optimize model selection before committing to production deployments. For one subscription price, engineering teams can test workloads across budget, mid-tier, and premium options to identify the optimal cost-performance balance.
The 2026 LLM pricing landscape rewards technical sophistication over brand loyalty. Enterprises that architect intelligent routing systems reduce API costs by $20,000-200,000+ monthly while maintaining or improving output quality. The question isn’t whether GPT-5 is worth its premium—it’s whether your workloads actually require it.
References
[1] Prices – https://www.rival.tips/prices
[2] Llm Api – https://costgoat.com/compare/llm-api
[3] Llm Api Cost Comparison 2026 – https://zenvanriel.nl/ai-engineer-blog/llm-api-cost-comparison-2026/
[4] Llm Api Cost Comparison – https://inventivehq.com/blog/llm-api-cost-comparison
[5] pricepertoken – https://pricepertoken.com
Our Fact Checking Process
We prioritize accuracy and integrity in our content. Here's how we maintain high standards:
- Expert Review: All articles are reviewed by subject matter experts.
- Source Validation: Information is backed by credible, up-to-date sources.
- Transparency: We clearly cite references and disclose potential conflicts.
Our Review Board
Our content is carefully reviewed by experienced professionals to ensure accuracy and relevance.
- Qualified Experts: Each article is assessed by specialists with field-specific knowledge.
- Up-to-date Insights: We incorporate the latest research, trends, and standards.
- Commitment to Quality: Reviewers ensure clarity, correctness, and completeness.
Look for the expert-reviewed label to read content you can trust.



