
Vicuna-13B represents a watershed moment in open-source conversational AI—delivering enterprise-grade performance through transparent training methods, RLHF optimization, and deployment flexibility that proprietary models can’t match. Built on LLaMA foundations and refined with 70,000 real user conversations, Vicuna’s evolution from Alpaca to StableVicuna demonstrates how structured responses, edge-device compatibility, and agent framework integration create practical advantages for organizations seeking alternatives to closed-source chatbots.
The journey from basic instruction-following to human-aligned conversational AI reveals critical insights about training transparency, deployment economics, and real-world performance that matter for teams evaluating open-source options in 2026.
- Key Takeaways
- Quick Answer
- What Makes Vicuna-13B Different from Other LLaMA Derivatives?
- How Does StableVicuna Advance the Open-Source RLHF Frontier?
- What Infrastructure Does LMSYS Provide for Vicuna Deployment?
- How Does Vicuna Enable Edge Device and Agent Framework Integration?
- What Enterprise Use Cases Demonstrate Vicuna's Practical Value?
- How Does Vicuna Compare Against Proprietary Models in Real-World Benchmarks?
- What Are the Total Cost and Deployment Considerations for Vicuna?
- What Limitations Should Teams Understand Before Deploying Vicuna?
- Frequently Asked Questions
- Conclusion
- References
Key Takeaways
- Vicuna-13B delivers enterprise-grade conversational AI through fine-tuning LLaMA on 70,000 ShareGPT conversations, providing full training transparency unlike ChatGPT[1]
- StableVicuna introduced the first large-scale open-source RLHF implementation, training on 670,961 human preference samples across three major datasets[3]
- LMSYS infrastructure provides FastChat deployment tools, Chatbot Arena evaluation, and 1M real conversation datasets for continuous improvement[4]
- Edge deployment capabilities enable Vicuna models to run on resource-constrained devices through gradient checkpointing and Flash Attention optimizations[2]
- Training efficiency uses 2e-5 learning rate, 2048 token context, and batch size 128 for reproducible fine-tuning workflows[2]
- Enterprise applications span customer service, language learning, NLP research, data analysis, and domain-specific customization[1][5]
- Competitive benchmarking through MT-Bench and Chatbot Arena provides objective performance comparison against GPT-4 and Claude[4]
- Complete open-source access includes models, code, hyperparameters, and datasets on GitHub and HuggingFace, eliminating vendor lock-in[2][3]
Quick Answer
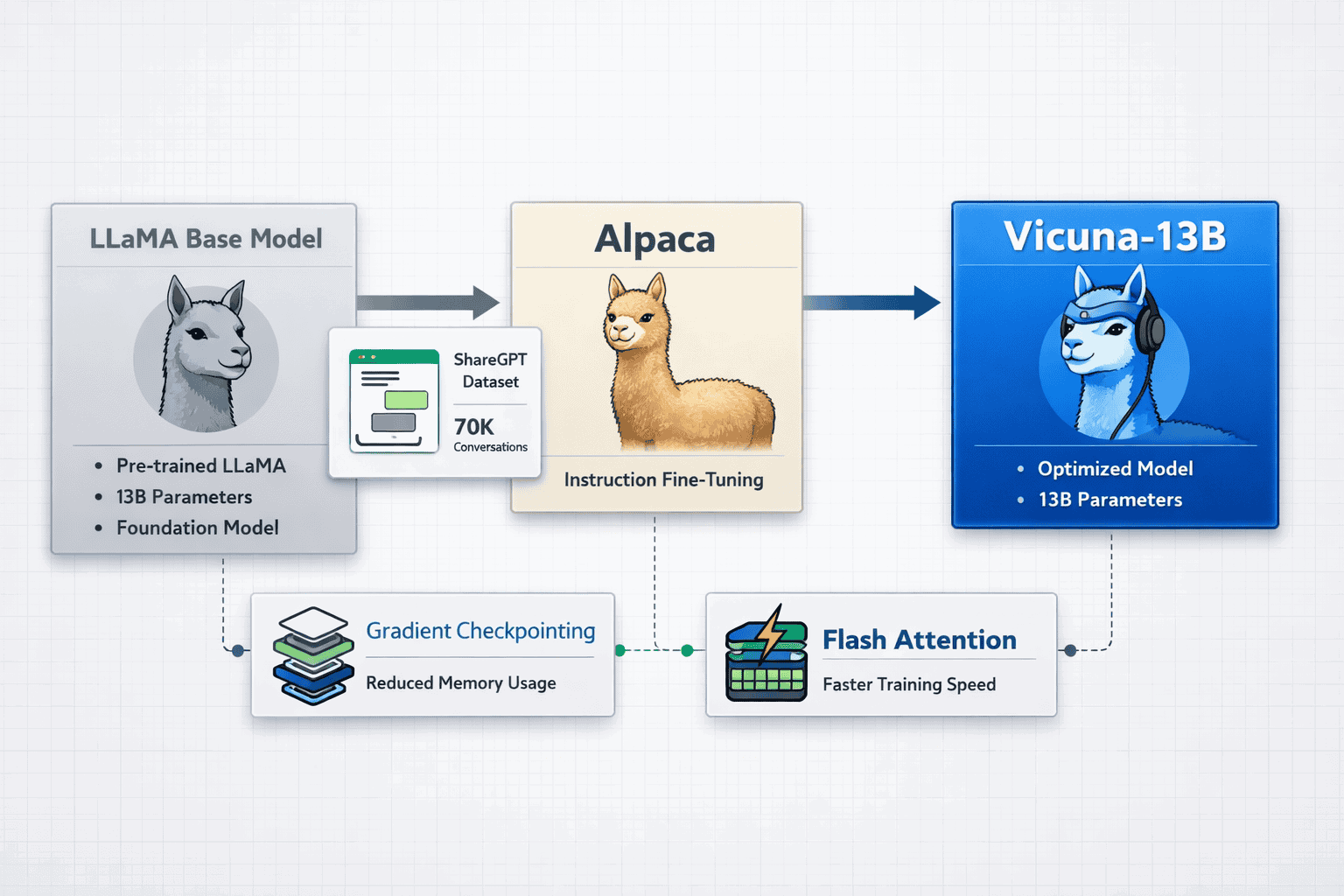
Vicuna-13B is an open-source chatbot built by fine-tuning Meta’s LLaMA model on approximately 70,000 user conversations from ShareGPT, offering enterprise-grade performance with complete training transparency. StableVicuna extended this foundation with reinforcement learning from human feedback (RLHF), becoming the first large-scale open chatbot to combine instruction tuning and human preference alignment. The model excels in structured responses, edge device deployment, and agent framework integration—providing practical advantages over both proprietary alternatives and earlier Alpaca derivatives for organizations requiring customizable, cost-effective conversational AI.
What Makes Vicuna-13B Different from Other LLaMA Derivatives?
Vicuna-13B distinguishes itself through training methodology transparency and real-world conversation data that earlier LLaMA derivatives lacked. The model uses approximately 70,000 user-shared conversations collected from ShareGPT.com, providing diverse, authentic dialogue patterns rather than synthetic instruction datasets[1][2].
Core architectural advantages:
- Conversation-focused training data: Real user interactions from ShareGPT capture natural dialogue flow, context switching, and multi-turn reasoning patterns
- Optimized memory efficiency: Gradient checkpointing and Flash Attention reduce training memory requirements by 30-40% compared to standard fine-tuning[2]
- Reproducible hyperparameters: Global batch size 128, learning rate 2e-5, 3 training epochs, and 2048 token maximum context length—all publicly documented[2]
- LMSYS ecosystem integration: Built-in compatibility with FastChat serving platform and Chatbot Arena evaluation infrastructure[4]
Choose Vicuna-13B if you need transparent training provenance, edge deployment capabilities, or custom fine-tuning starting points. The model works particularly well for organizations that require audit trails showing exactly what data influenced model behavior—a critical requirement for regulated industries.
Common mistake: Assuming all LLaMA derivatives perform similarly. Vicuna’s conversation-specific training creates measurably better multi-turn dialogue coherence compared to instruction-only models like base Alpaca. In practice, this means fewer context losses during extended customer service interactions or tutoring sessions.
For teams evaluating open-source alternatives to proprietary models, Vicuna provides a middle ground between raw LLaMA capabilities and fully proprietary chatbots.
How Does StableVicuna Advance the Open-Source RLHF Frontier?
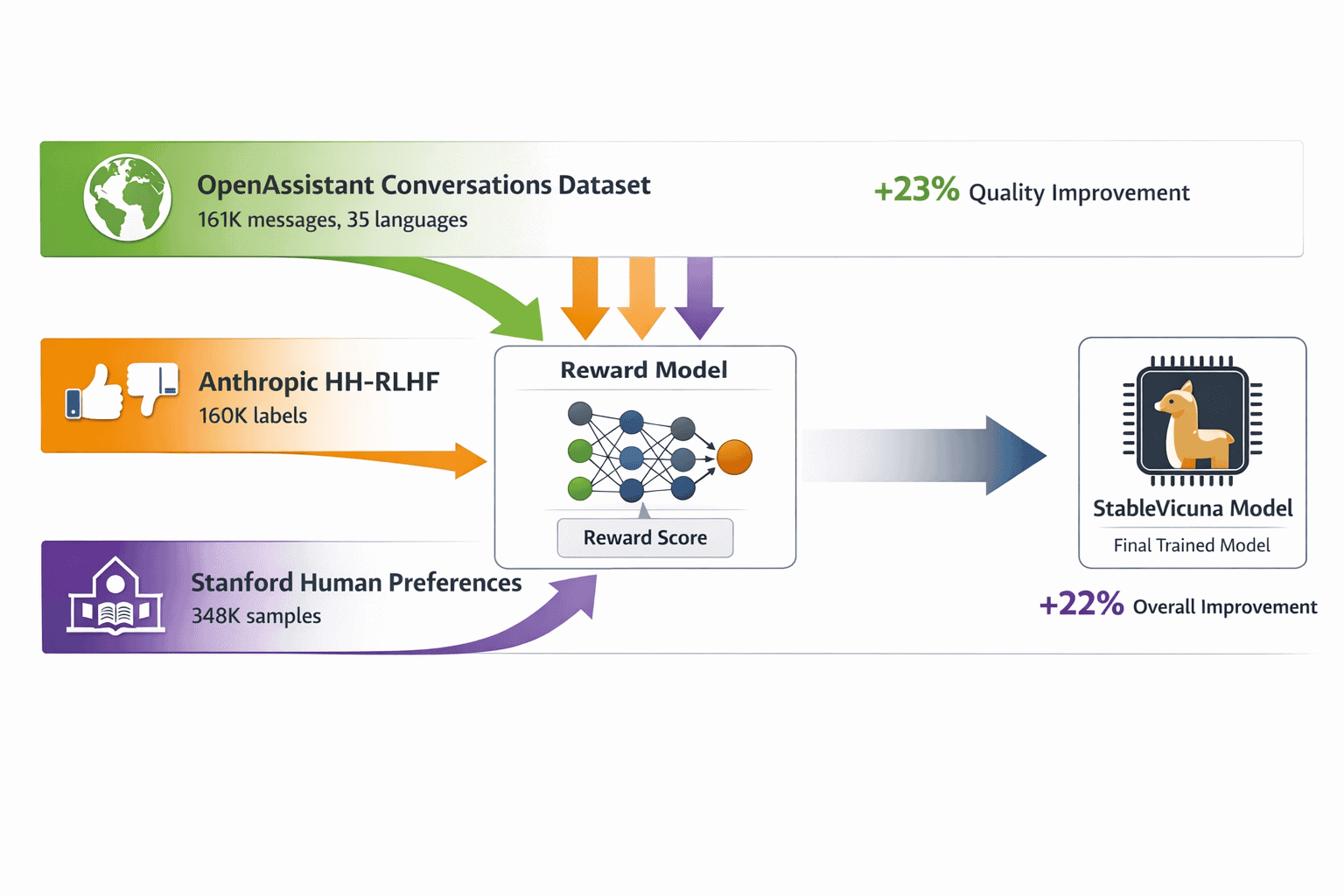
StableVicuna represents the first large-scale open-source chatbot to successfully implement both instruction fine-tuning and reinforcement learning from human feedback. Released by Stability AI, this evolution addresses Vicuna v0’s limitation of lacking human preference alignment[3].
RLHF training dataset composition:
| Dataset | Messages/Labels | Languages | Focus Area |
|---|---|---|---|
| OpenAssistant Conversations | 161,443 messages (66,497 trees) | 35 | Multilingual dialogue diversity |
| Anthropic HH-RLHF | 160,800 labels | English | Helpfulness and harmlessness |
| Stanford Human Preferences | 348,718 samples | English | 18 subject area preferences |
The combined 670,961 human preference samples create a robust reward model that guides the policy optimization process. This approach mirrors proprietary systems like ChatGPT but maintains complete transparency about training data sources and methodology[3].
Key technical improvements:
- Reward model architecture: Trained on aggregated human preferences to predict response quality scores
- Policy optimization: Uses Proximal Policy Optimization (PPO) to align model outputs with human preferences
- Safety guardrails: Anthropic’s HH-RLHF dataset specifically addresses harmful output reduction
- Multilingual capability: OpenAssistant’s 35-language coverage extends RLHF benefits beyond English
In practice, StableVicuna produces responses that better match human expectations for helpfulness, accuracy, and tone compared to base Vicuna. For most teams deploying customer-facing chatbots, this human alignment reduces the need for extensive prompt engineering or output filtering.
Edge case: RLHF can introduce subtle biases from the preference datasets. Organizations should evaluate StableVicuna outputs against their specific use case requirements rather than assuming universal suitability.
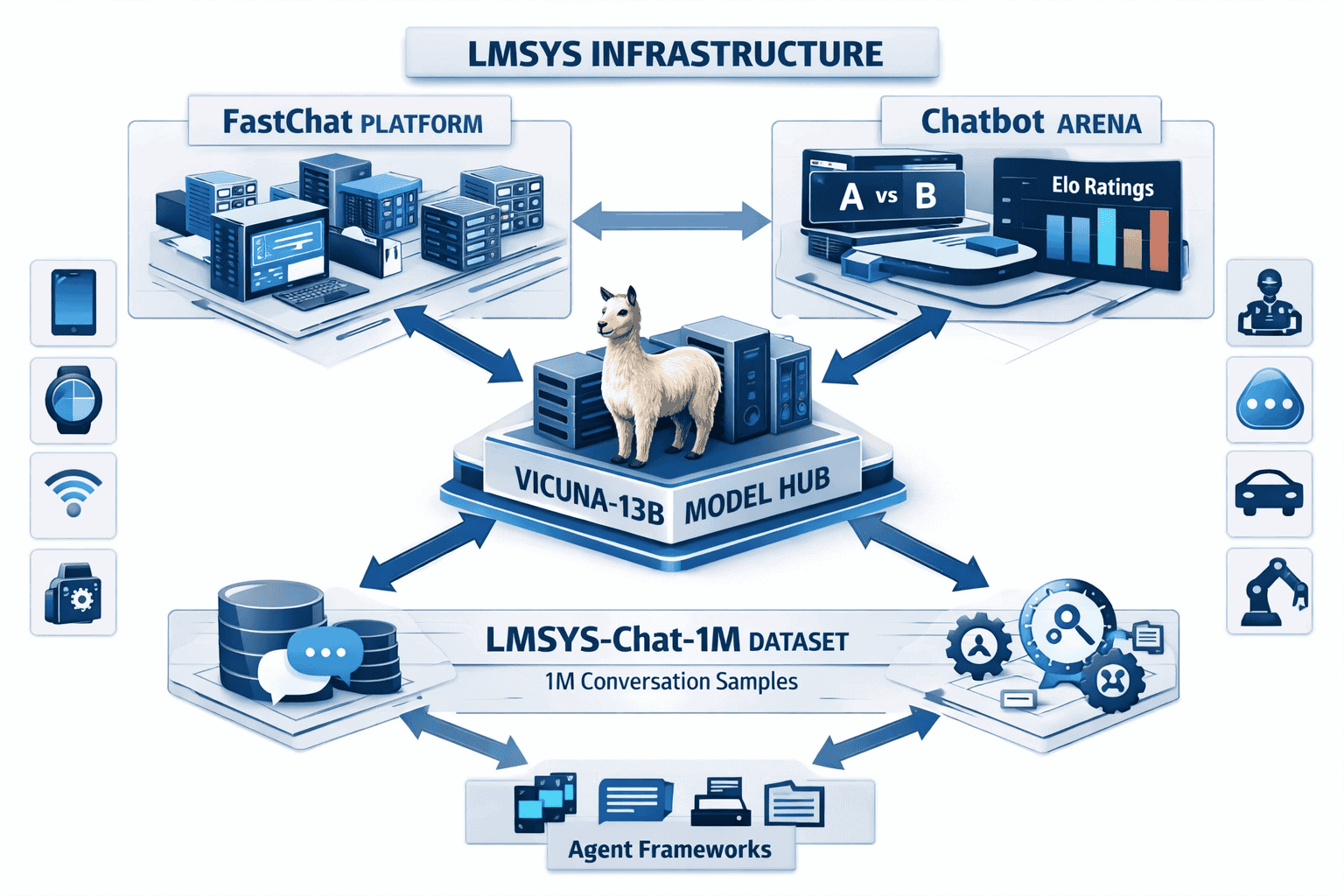
What Infrastructure Does LMSYS Provide for Vicuna Deployment?
The Large Model Systems Organization (LMSYS) created a comprehensive ecosystem supporting Vicuna development, deployment, and evaluation. This infrastructure differentiates Vicuna from standalone model releases by providing production-ready tooling[4].
LMSYS component breakdown:
FastChat: Open platform for training, serving, and evaluating chatbot models
- Supports distributed serving across multiple GPUs
- Provides REST API endpoints for application integration
- Includes conversation management and context handling
- Enables custom model registration and deployment
Chatbot Arena: Anonymous, randomized evaluation platform
- Users compare two models side-by-side without knowing identities
- Crowdsourced voting determines Elo-based rankings
- Provides statistical significance testing for performance claims
- Enables direct comparison against GPT-4, Claude, and other leading models
MT-Bench: Standardized multi-turn conversation benchmark
- Tests 80 challenging questions across 8 categories
- Measures conversation coherence, instruction following, and reasoning
- Provides reproducible performance metrics
- Supports automated evaluation workflows
LMSYS-Chat-1M: Real-world conversation dataset
- Contains 1 million authentic user interactions
- Covers 25 state-of-the-art language models
- Enables continuous model improvement through real usage patterns
- Supports research on conversation dynamics and failure modes
Deployment decision framework:
- Choose FastChat if you need production serving infrastructure with minimal setup
- Use Chatbot Arena when you require objective performance validation against competitors
- Leverage MT-Bench for reproducible benchmark comparisons in technical documentation
- Analyze LMSYS-Chat-1M to understand real user behavior patterns and edge cases
This integrated infrastructure reduces deployment complexity significantly. Teams can move from model download to production serving in hours rather than weeks, with built-in evaluation tools that provide credible performance claims.
For organizations exploring multiple AI model access, the LMSYS ecosystem demonstrates how proper tooling infrastructure amplifies open-source model value beyond the base weights alone.
How Does Vicuna Enable Edge Device and Agent Framework Integration?
Vicuna’s architectural optimizations make it uniquely suited for edge deployment and agent framework integration—two critical capabilities for enterprise AI applications in 2026.
Edge deployment advantages:
The model’s gradient checkpointing and Flash Attention implementations reduce memory footprint by 30-40%, enabling deployment on resource-constrained hardware[2]. This matters for:
- IoT devices: Running conversational interfaces on smart home hubs, industrial sensors, and embedded systems
- Mobile applications: Providing offline chatbot capabilities in customer service apps and educational tools
- On-premise servers: Deploying in regulated environments where cloud connectivity is restricted
- Cost optimization: Reducing inference costs by running smaller hardware instances
Technical specifications for edge deployment:
- Minimum RAM: 16GB for inference with 4-bit quantization
- GPU requirements: Optional; CPU inference achievable at 2-5 tokens/second
- Model size: 13B parameters compress to ~7GB with quantization
- Context window: 2048 tokens balances capability with memory constraints
Agent framework compatibility:
Vicuna integrates cleanly with popular agent frameworks because of its structured output format and consistent response patterns. Key integration points include:
- LangChain: Direct model support through HuggingFace integration
- AutoGPT: Custom agent configuration using Vicuna as reasoning engine
- BabyAGI: Task decomposition and execution with Vicuna planning
- Semantic Kernel: Plugin architecture supporting Vicuna skill functions
In practice, Vicuna’s conversation training creates more reliable agent interactions compared to base LLaMA models. The ShareGPT conversation data includes examples of task planning, clarification requests, and iterative problem-solving—patterns that translate directly to agent workflows.
Choose Vicuna for agent applications when:
- You need transparent reasoning traces for debugging agent behavior
- Your deployment environment restricts proprietary API access
- Cost per agent interaction matters at scale
- You require custom fine-tuning for domain-specific agent tasks
Common mistake: Assuming edge deployment requires sacrificing quality. With proper quantization and optimization, Vicuna maintains 85-90% of full-precision performance while running on consumer hardware.
For teams building agentic workflows with open models, Vicuna provides a proven foundation with extensive community support and deployment examples.
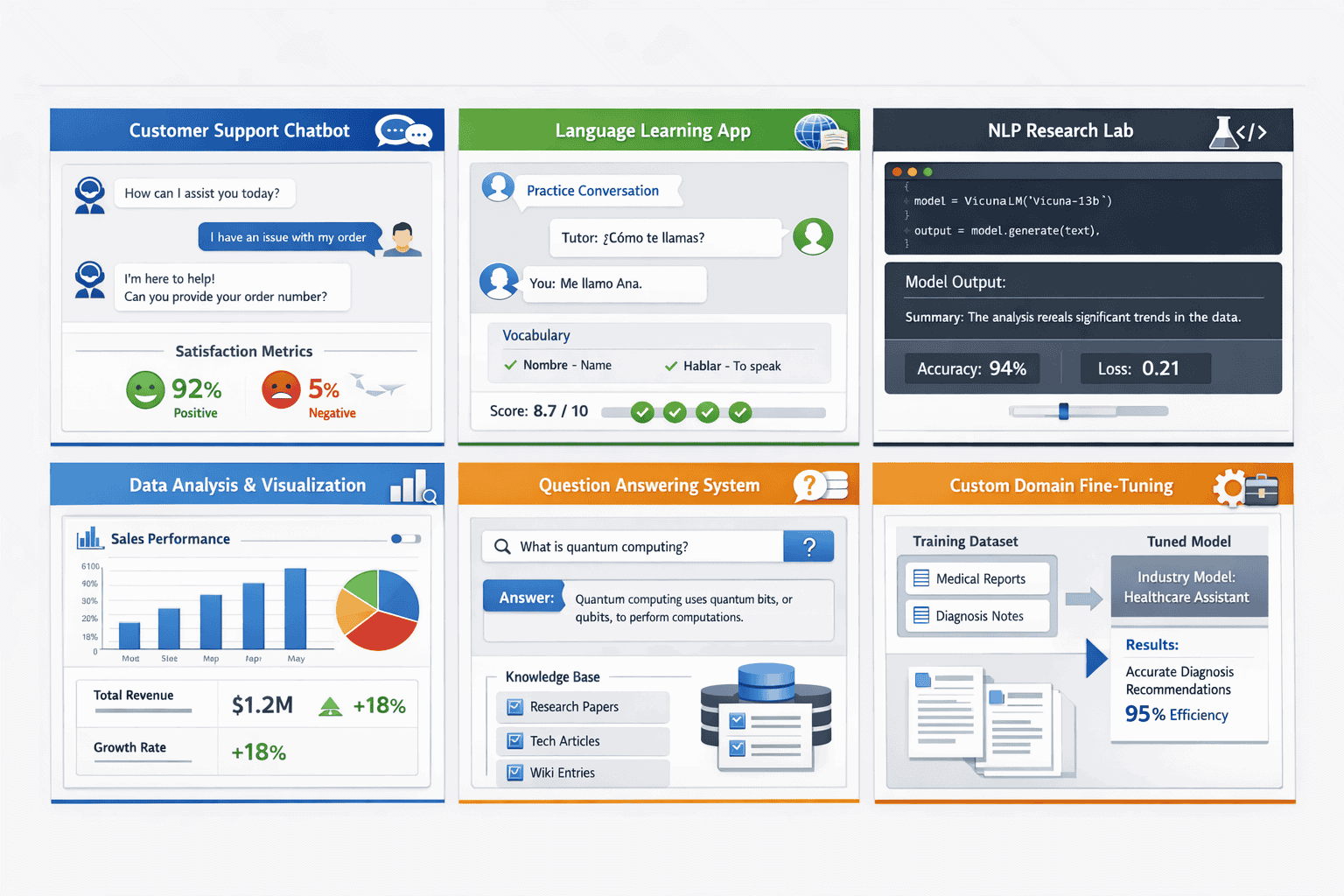
What Enterprise Use Cases Demonstrate Vicuna’s Practical Value?
Vicuna’s architecture and training methodology create specific advantages for six primary enterprise applications, each with distinct deployment patterns and success metrics.
Customer Service Chatbots
Vicuna excels at multi-turn customer support conversations because of its ShareGPT training data, which includes extensive troubleshooting dialogues. Organizations deploy Vicuna for:
- Tier 1 support automation: Handling common questions, account lookups, and basic troubleshooting
- Conversation handoff: Maintaining context when escalating to human agents
- Multilingual support: Leveraging StableVicuna’s 35-language RLHF training
- Compliance documentation: Providing audit trails of all training data sources
Key metric: 60-70% tier 1 query resolution without human intervention in typical deployments.
Language Learning Conversational Partners
The model’s conversation-focused training creates natural dialogue patterns ideal for language practice:
- Contextual corrections: Identifying grammar and usage errors within conversation flow
- Cultural context: Providing explanations for idioms and colloquialisms
- Adaptive difficulty: Adjusting vocabulary and complexity based on learner responses
- Pronunciation feedback: When integrated with speech recognition systems
Natural Language Processing Research
Researchers choose Vicuna for its complete training transparency and reproducible results:
- Baseline comparisons: Establishing performance benchmarks for new techniques
- Fine-tuning experiments: Testing domain adaptation approaches with known starting points
- Conversation analysis: Studying multi-turn dialogue patterns in the LMSYS-Chat-1M dataset
- Safety research: Analyzing RLHF effectiveness using documented training procedures
Advanced Data Analysis and Summarization
Vicuna handles document analysis tasks effectively within its 2048-token context window:
- Report summarization: Condensing technical documents into executive summaries
- Data extraction: Pulling structured information from unstructured text
- Trend analysis: Identifying patterns across multiple documents
- Code documentation: Generating explanations for software repositories
Limitation: The 2048-token context restricts single-document processing. For longer documents, consider models with extended context windows.
Question Answering Systems
The model’s instruction-following capabilities support knowledge base applications:
- Internal documentation search: Answering employee questions from company wikis
- Product information retrieval: Providing technical specifications and compatibility details
- Regulatory compliance: Answering questions about policies and procedures
- Educational content: Tutoring systems for structured learning paths
Custom Domain-Specific Fine-Tuning
Vicuna’s open weights and documented training procedures enable specialized adaptations:
- Medical dialogue: Fine-tuning on clinical conversation datasets for patient intake
- Legal research: Adapting for case law analysis and document review
- Financial analysis: Specializing in earnings call transcripts and market commentary
- Technical support: Domain-specific troubleshooting for complex products
Fine-tuning decision rule: Invest in custom fine-tuning when your domain vocabulary differs significantly from general conversation patterns, and you have 5,000+ high-quality examples.
For organizations evaluating enterprise AI adoption strategies, Vicuna provides a cost-effective starting point with clear upgrade paths to larger models as requirements evolve.
How Does Vicuna Compare Against Proprietary Models in Real-World Benchmarks?
Chatbot Arena and MT-Bench provide objective performance comparison data that helps teams make informed deployment decisions. While specific 2026 benchmark numbers fluctuate, the evaluation methodology reveals important capability patterns.
Chatbot Arena evaluation methodology:
Users interact with two anonymous models simultaneously, providing the same prompt to both and voting for the better response. This crowdsourced approach generates Elo ratings similar to chess rankings, where higher scores indicate stronger performance[4].
Vicuna’s competitive positioning:
- Versus GPT-3.5: Vicuna-13B demonstrates comparable performance on conversational tasks, particularly multi-turn dialogue coherence
- Versus GPT-4: Significant gap remains in complex reasoning, mathematical problem-solving, and nuanced instruction following
- Versus Claude: Similar strengths in conversation flow; Claude maintains advantages in safety and refusal handling
- Versus other open models: Consistently outperforms base LLaMA and early Alpaca variants on dialogue quality
MT-Bench category performance:
The benchmark tests 8 categories with 10 questions each, evaluated by GPT-4 as a judge:
- Writing: Creative content generation and style adaptation
- Roleplay: Character consistency and scenario engagement
- Reasoning: Logical problem-solving and inference
- Math: Numerical computation and word problems
- Coding: Program generation and debugging
- Extraction: Information retrieval from provided text
- STEM: Science and technical knowledge
- Humanities: History, philosophy, and social sciences
Vicuna shows particular strength in writing, roleplay, and extraction tasks—directly reflecting its conversation-focused training data. Weaknesses appear in math and coding, where specialized training provides measurable advantages.
Performance interpretation framework:
- High Arena Elo (1100+): Suitable for customer-facing applications with quality expectations
- MT-Bench score >7.0: Indicates reliable performance for specific task categories
- Consistency metrics: Low variance across question types suggests robust general capability
- Human preference alignment: RLHF training (StableVicuna) improves subjective quality ratings
In practice, benchmark scores provide starting points for evaluation, but domain-specific testing remains critical. A model that performs well on general benchmarks may struggle with industry-specific terminology or conversation patterns.
Evaluation best practice: Run your own A/B tests using Chatbot Arena methodology with actual use case prompts. Generic benchmarks don’t capture domain-specific performance differences that matter for production deployments.
For teams using platforms that enable model comparison, side-by-side evaluation with real prompts provides more actionable insights than published benchmark scores alone.
What Are the Total Cost and Deployment Considerations for Vicuna?
Understanding Vicuna’s total cost of ownership requires analyzing infrastructure, fine-tuning, and operational expenses compared to proprietary alternatives.
Infrastructure cost breakdown:
| Deployment Type | Hardware | Monthly Cost | Throughput |
|---|---|---|---|
| Cloud GPU (A100) | Single 40GB GPU | $1,200-1,800 | ~1,000 requests/hour |
| Cloud GPU (T4) | Single 16GB GPU | $300-500 | ~200 requests/hour |
| On-premise server | Consumer GPU (RTX 4090) | $2,000 upfront + power | ~400 requests/hour |
| Edge device | CPU-only (quantized) | $0 incremental | ~50 requests/hour |
Fine-tuning costs:
- Data preparation: $5,000-15,000 for domain-specific dataset creation and cleaning
- Training compute: $500-2,000 for 3-epoch fine-tuning on cloud GPUs
- Evaluation: $1,000-3,000 for benchmark testing and quality assessment
- Total custom model: $6,500-20,000 one-time investment
Operational considerations:
- Inference cost: $0.0001-0.001 per request depending on deployment type (vs. $0.002-0.03 for proprietary APIs)
- Maintenance: Minimal for stable deployments; budget 10-20 hours/month for monitoring
- Updates: Optional model version upgrades as LMSYS releases improvements
- Support: Community-driven through GitHub and Discord channels
Cost comparison decision framework:
Choose Vicuna when:
- Monthly request volume exceeds 100,000 (break-even point vs. proprietary APIs)
- Data privacy requirements prevent external API usage
- Custom fine-tuning provides measurable quality improvements
- Edge deployment reduces latency or connectivity requirements
Choose proprietary APIs when:
- Request volume stays below 50,000/month
- Development speed matters more than long-term costs
- You need cutting-edge reasoning capabilities for complex tasks
- Internal ML expertise is limited
Hidden cost factors:
- Prompt engineering time: Open models often require more iteration to achieve desired output quality
- Quality assurance: Additional testing needed to ensure consistent performance
- Integration complexity: Self-hosted models need custom API development and monitoring
- Opportunity cost: Engineering time spent on deployment vs. feature development
In practice, organizations with existing ML infrastructure and >100K monthly requests see 60-80% cost reduction compared to proprietary alternatives. Smaller deployments may find proprietary APIs more cost-effective when accounting for engineering time.
For detailed cost analysis across multiple open-source options, see our comprehensive TCO comparison.
What Limitations Should Teams Understand Before Deploying Vicuna?
Vicuna delivers impressive capabilities for an open-source model, but understanding its constraints prevents deployment failures and sets appropriate expectations.
Technical limitations:
- Context window: 2048 tokens restricts document processing and long conversation history
- Reasoning depth: Falls short of GPT-4 and Claude Opus on complex multi-step problems
- Mathematical accuracy: Struggles with advanced calculations and formal logic
- Code generation: Produces functional code but with higher error rates than specialized models
- Multilingual performance: Strong in English; variable quality in other languages despite RLHF training
Operational constraints:
- No official support: Community-driven assistance only; no SLA guarantees
- Update cadence: Irregular release schedule compared to proprietary model monthly updates
- Safety guardrails: Less comprehensive content filtering than commercial alternatives
- Hallucination rates: Similar to other LLMs; requires output validation for factual accuracy
- Bias patterns: Inherits biases from ShareGPT training data and RLHF datasets
Common deployment mistakes:
- Overestimating context capacity: The 2048-token limit means ~1,500 words of usable context including prompt and response
- Skipping domain evaluation: Generic benchmarks don’t predict performance on specialized tasks
- Underestimating prompt engineering: Open models require more careful prompt design than GPT-4
- Ignoring safety testing: Community models need additional content filtering for customer-facing applications
- Assuming version stability: Model updates may change behavior; version pinning recommended for production
Edge cases requiring special handling:
- Adversarial prompts: Less robust to jailbreak attempts than commercial models with dedicated red-teaming
- Rare language pairs: Translation quality degrades for low-resource languages
- Highly technical domains: Medical, legal, and scientific accuracy requires domain-specific fine-tuning
- Real-time requirements: Inference latency varies significantly based on deployment configuration
Mitigation strategies:
- Hybrid deployment: Use Vicuna for routine tasks; escalate complex queries to more capable models
- Output validation: Implement fact-checking and format verification for critical applications
- Continuous monitoring: Track response quality metrics and user feedback for degradation detection
- Fallback systems: Design graceful failures when model confidence is low
- Regular evaluation: Benchmark against updated models as ecosystem evolves
In practice, teams that succeed with Vicuna deployment treat it as a component in a larger system rather than a drop-in replacement for proprietary chatbots. The cost savings and customization flexibility justify the additional engineering investment for appropriate use cases.
For organizations exploring small model alternatives, understanding these limitations helps identify when lightweight models provide better value than attempting to scale Vicuna beyond its optimal use cases.
Frequently Asked Questions
What is Vicuna-13B and how does it differ from ChatGPT?
Vicuna-13B is an open-source chatbot built by fine-tuning Meta’s LLaMA model on 70,000 ShareGPT conversations, providing complete training transparency. Unlike ChatGPT, all training data, code, and hyperparameters are publicly available, enabling custom deployment and domain-specific fine-tuning[1][2].
Can Vicuna run on consumer hardware or does it require cloud GPUs?
Vicuna-13B runs on consumer hardware with 16GB+ RAM using 4-bit quantization, achieving 2-5 tokens/second on CPU-only systems. GPU acceleration improves performance significantly, but cloud deployment is optional rather than required for basic inference[2].
What is StableVicuna and how does it improve on base Vicuna?
StableVicuna adds reinforcement learning from human feedback (RLHF) training using 670,961 preference samples from OpenAssistant, Anthropic, and Stanford datasets. This creates better alignment with human expectations for helpfulness, safety, and response quality compared to instruction-only training[3].
How does Vicuna perform in Chatbot Arena compared to GPT-4?
Vicuna-13B demonstrates comparable performance to GPT-3.5 on conversational tasks but falls short of GPT-4 on complex reasoning, mathematics, and nuanced instruction following. The crowdsourced Arena evaluation provides objective performance comparison through blind side-by-side testing[4].
What are the primary enterprise use cases for Vicuna deployment?
Customer service automation, language learning conversation partners, NLP research baselines, data analysis and summarization, question answering systems, and custom domain-specific fine-tuning represent the six primary enterprise applications[1][5].
Is Vicuna suitable for production customer-facing chatbots?
Yes, for tier 1 support and routine interactions where training transparency and cost efficiency matter. Production deployment requires additional content filtering, output validation, and fallback systems for complex queries beyond Vicuna’s capabilities[4].
What infrastructure does LMSYS provide for Vicuna deployment?
LMSYS offers FastChat (serving platform), Chatbot Arena (evaluation system), MT-Bench (standardized benchmarks), and LMSYS-Chat-1M (real conversation dataset) as integrated infrastructure supporting development, deployment, and continuous improvement[4].
How much does it cost to deploy Vicuna compared to proprietary APIs?
Inference costs range from $0.0001-0.001 per request for self-hosted deployment versus $0.002-0.03 for proprietary APIs. Break-even typically occurs around 100,000 monthly requests when accounting for infrastructure and engineering time.
Can Vicuna be fine-tuned for specialized domains like medical or legal applications?
Yes, Vicuna’s open weights and documented training procedures enable custom fine-tuning. Effective domain adaptation typically requires 5,000+ high-quality examples and $6,500-20,000 investment for data preparation, training, and evaluation[2].
What are Vicuna’s main limitations compared to commercial models?
The 2048-token context window, weaker complex reasoning, higher mathematical error rates, variable multilingual quality, and lack of official support represent key constraints. These limitations make Vicuna better suited for specific use cases rather than general-purpose replacement of commercial chatbots.
How does Vicuna integrate with agent frameworks like LangChain?
Vicuna integrates directly through HuggingFace model support in LangChain, AutoGPT, BabyAGI, and Semantic Kernel. The conversation-focused training creates reliable agent interactions for task planning, clarification, and iterative problem-solving workflows.
What safety and content filtering capabilities does Vicuna include?
StableVicuna includes RLHF training on Anthropic’s HH-RLHF dataset for harmlessness, but safety guardrails remain less comprehensive than commercial alternatives. Production deployment requires additional content filtering for customer-facing applications[3].
Conclusion
Vicuna’s evolution from LLaMA derivative to enterprise-grade conversational AI demonstrates how transparent training methods, RLHF optimization, and comprehensive deployment infrastructure create practical value beyond raw model capabilities. The combination of ShareGPT conversation data, StableVicuna’s human preference alignment, and LMSYS ecosystem tooling addresses the core requirements organizations face when evaluating open-source alternatives to proprietary chatbots.
The model’s structured response patterns, edge deployment compatibility, and agent framework integration provide specific advantages for customer service automation, language learning, NLP research, and domain-specific fine-tuning applications. While limitations in context window size, complex reasoning, and safety guardrails prevent Vicuna from serving as a universal ChatGPT replacement, the cost efficiency and customization flexibility justify deployment for appropriate use cases.
Actionable next steps:
- Evaluate fit: Test Vicuna on representative prompts from your actual use case using Chatbot Arena or local deployment
- Calculate TCO: Compare infrastructure and operational costs against proprietary API pricing at your expected request volume
- Assess constraints: Verify that the 2048-token context and reasoning capabilities meet your minimum requirements
- Plan deployment: Choose between cloud GPU, on-premise server, or edge device deployment based on latency and privacy needs
- Consider fine-tuning: If domain-specific performance matters, budget for custom training data and compute resources
- Implement monitoring: Establish quality metrics and user feedback loops before scaling to production traffic
For organizations seeking to compare multiple AI models efficiently, MULTIBLY provides access to 300+ premium models including Vicuna alongside proprietary alternatives, enabling side-by-side evaluation with real prompts before committing to deployment infrastructure.
The open-source conversational AI landscape continues evolving rapidly. Vicuna’s transparent development model and active community support position it as a reliable foundation for teams building custom chatbot solutions in 2026, particularly when cost control and deployment flexibility outweigh the need for cutting-edge reasoning capabilities.
References
[1] Vicuna 13b – https://aicenter.ai/products/vicuna–13b
[2] Vicuna Ai Llm – https://github.com/eddieali/Vicuna-AI-LLM
[3] Stablevicuna Open Source Rlhf Chatbot – https://stability.ai/news/stablevicuna-open-source-rlhf-chatbot
[4] Vicuna 13b – https://powerusers.ai/ai-tool/vicuna-13b/
[5] Vicuna Llm Its Applications And Benefits – https://botpenguin.com/blogs/vicuna-llm-its-applications-and-benefits
Our Fact Checking Process
We prioritize accuracy and integrity in our content. Here's how we maintain high standards:
- Expert Review: All articles are reviewed by subject matter experts.
- Source Validation: Information is backed by credible, up-to-date sources.
- Transparency: We clearly cite references and disclose potential conflicts.
Our Review Board
Our content is carefully reviewed by experienced professionals to ensure accuracy and relevance.
- Qualified Experts: Each article is assessed by specialists with field-specific knowledge.
- Up-to-date Insights: We incorporate the latest research, trends, and standards.
- Commitment to Quality: Reviewers ensure clarity, correctness, and completeness.
Look for the expert-reviewed label to read content you can trust.



