
Grok 4’s 2M context window fundamentally reshapes what’s possible in real-time AI applications. Unlike traditional large language models that process static documents, Grok 4 combines massive context capacity with live data ingestion from X (Twitter), enabling dynamic analysis of streaming information at unprecedented scale. This architecture creates entirely new use cases—from live market analysis that actually profits in trading competitions to multi-agent reasoning systems that debate complex problems in real-time before responding.
The difference isn’t just about processing longer documents. It’s about maintaining coherent understanding across millions of tokens of constantly updating information while coordinating multiple AI agents that think in parallel. For teams building production AI systems in 2026, understanding why Grok 4’s 2M context window changes the game for real-time AI applications means recognizing when streaming data and extended memory create competitive advantages that static models simply can’t match.
- Key Takeaways
- Quick Answer
- What Makes Grok 4's Context Window Different from Traditional LLMs?
- How Does Real-Time X Data Integration Enable New AI Use Cases?
- Why Does the Multi-Agent Architecture Matter for Extended Context?
- What Real-Time AI Applications Benefit Most from 2M Token Context?
- How Does Grok 4's Performance Compare to GPT-5 and Claude Opus for Real-Time Tasks?
- What Are the Limitations and Trade-offs of Extended Context Windows?
- FAQ
- Conclusion
- References
Key Takeaways
- Grok 4 offers a 256K baseline context window expandable to 2M tokens, roughly 15 times larger than GPT-4’s standard capacity, enabling processing of entire codebases and ultra-long documents in a single pass[1][3]
- The model ingests 68 million English tweets daily via X’s data firehose, providing real-time world knowledge that updates continuously rather than relying on static training cutoffs[1]
- Grok 4.20’s four-agent collaborative architecture (Grok, Harper, Benjamin, Lucas) enables parallel reasoning and debate before generating responses, directly addressing hallucination and accuracy problems in extended-context scenarios[1]
- Proven financial performance in live trading: Grok 4.20 was the only AI to achieve profitability in the Alpha Arena stock trading competition, averaging 12.11% returns by combining real-time data with extended context analysis[1]
- 65% reduction in hallucinations (from ~12% to ~4.2%) makes the model reliable enough for production applications where accuracy directly impacts business outcomes[1]
- 2M tokens per minute throughput delivers industry-leading inference speed for processing large-scale real-time data streams[2]
- Native multimodal processing handles text, images, and video simultaneously, enabling comprehensive real-time analysis across multiple data types[1][3]
- Currently available to SuperGrok subscribers ($30/month) and X Premium+ users, with broader API access expected soon[1]
Quick Answer

Why Grok 4’s 2M context window changes the game for real-time AI applications comes down to three core capabilities working together: massive context capacity (up to 2M tokens), continuous real-time data ingestion (68 million tweets daily from X), and a multi-agent architecture that coordinates parallel reasoning. This combination enables applications that were previously impossible—like maintaining coherent analysis across streaming market data, live social sentiment, and historical context simultaneously, all while reducing hallucinations by 65% compared to earlier versions[1].
The practical impact shows up in measurable outcomes. Grok 4.20 achieved profitability in live stock trading competitions where other AI models failed, demonstrating that extended context plus real-time data creates genuine competitive advantage in time-sensitive applications[1].
What Makes Grok 4’s Context Window Different from Traditional LLMs?
Grok 4’s context architecture differs from traditional LLMs in both scale and application. The model provides a 256K baseline context window that expands to 2M tokens when needed, compared to GPT-4’s 128K or Claude’s 200K standard windows[1][3]. But the real differentiation isn’t just size—it’s how that capacity integrates with streaming data.
Traditional LLMs process static inputs: you provide a document or conversation, and the model responds based on fixed training data plus your prompt. Grok 4 continuously ingests live information from X’s data firehose, processing approximately 68 million English tweets daily[1]. This means the model’s “world knowledge” updates in real-time rather than being frozen at a training cutoff date.
Key architectural differences:
- Dynamic context refresh: Real-time social media streams update the model’s understanding of current events, sentiment, and emerging trends continuously
- Expandable capacity: The 256K baseline handles most tasks efficiently, but the system can scale to 2M tokens for complex scenarios without requiring different model versions
- Multi-agent coordination: Four AI agents (Grok, Harper, Benjamin, Lucas) collaborate within the extended context, enabling parallel analysis and cross-validation before generating responses[1]
- Multimodal integration: Text, images, and video process together within the same context window, rather than requiring separate processing pipelines[1][3]
Choose Grok 4’s extended context when:
- You need analysis that spans massive documents (entire codebases, legal case histories, research compilations)
- Real-time data integration matters for your application (market analysis, event monitoring, sentiment tracking)
- Accuracy in extended reasoning is critical (the 65% hallucination reduction matters most in long-context scenarios)[1]
For teams working with traditional document processing or static knowledge bases, models like Kimi K2’s 256K window may provide better cost-efficiency. But when streaming data and dynamic context combine, Grok 4’s architecture creates fundamentally different capabilities.
How Does Real-Time X Data Integration Enable New AI Use Cases?
Real-time X data integration transforms Grok 4 from a document processor into a live intelligence system. The model ingests roughly 68 million English tweets daily, providing continuous updates on breaking news, market sentiment, political developments, and cultural trends[1]. This creates use cases that simply don’t work with static LLMs.
Financial market analysis represents the most proven application. Grok 4.20 was the only AI model to achieve profitability in the Alpha Arena live stock trading competition, averaging 12.11% returns in December 2025[1]. The model combines:
- Real-time social sentiment about specific stocks and sectors
- Breaking news detection from verified accounts and journalists
- Historical price data and technical analysis
- Extended context to maintain coherent trading strategy across multiple positions
Event detection and crisis monitoring benefit from sub-second latency between tweet publication and model awareness. Organizations can:
- Track emerging crises (natural disasters, political events, security incidents) as they unfold
- Analyze sentiment shifts in real-time during product launches or PR events
- Monitor brand reputation across millions of conversations simultaneously
- Identify coordinated information campaigns or misinformation spread patterns
Dynamic content creation uses live trends to inform outputs:
- Marketing teams generate content that references current events and trending topics accurately
- Journalists get AI assistance that incorporates breaking developments into draft articles
- Social media managers receive suggestions based on real-time conversation patterns
Common mistake: Assuming real-time data always improves accuracy. In practice, Twitter data includes noise, misinformation, and coordinated manipulation. Grok 4’s multi-agent architecture helps filter these issues through collaborative reasoning, but applications still need validation layers for critical decisions.
Edge case consideration: The X data firehose focuses on English tweets. Applications requiring real-time intelligence in other languages may need supplementary data sources or should consider models like Qwen3 for multilingual scenarios.
The key differentiator is temporal coherence—Grok 4 maintains understanding across both historical context (via the 2M token window) and current events (via streaming data), enabling analysis that traditional LLMs can’t replicate.
Why Does the Multi-Agent Architecture Matter for Extended Context?
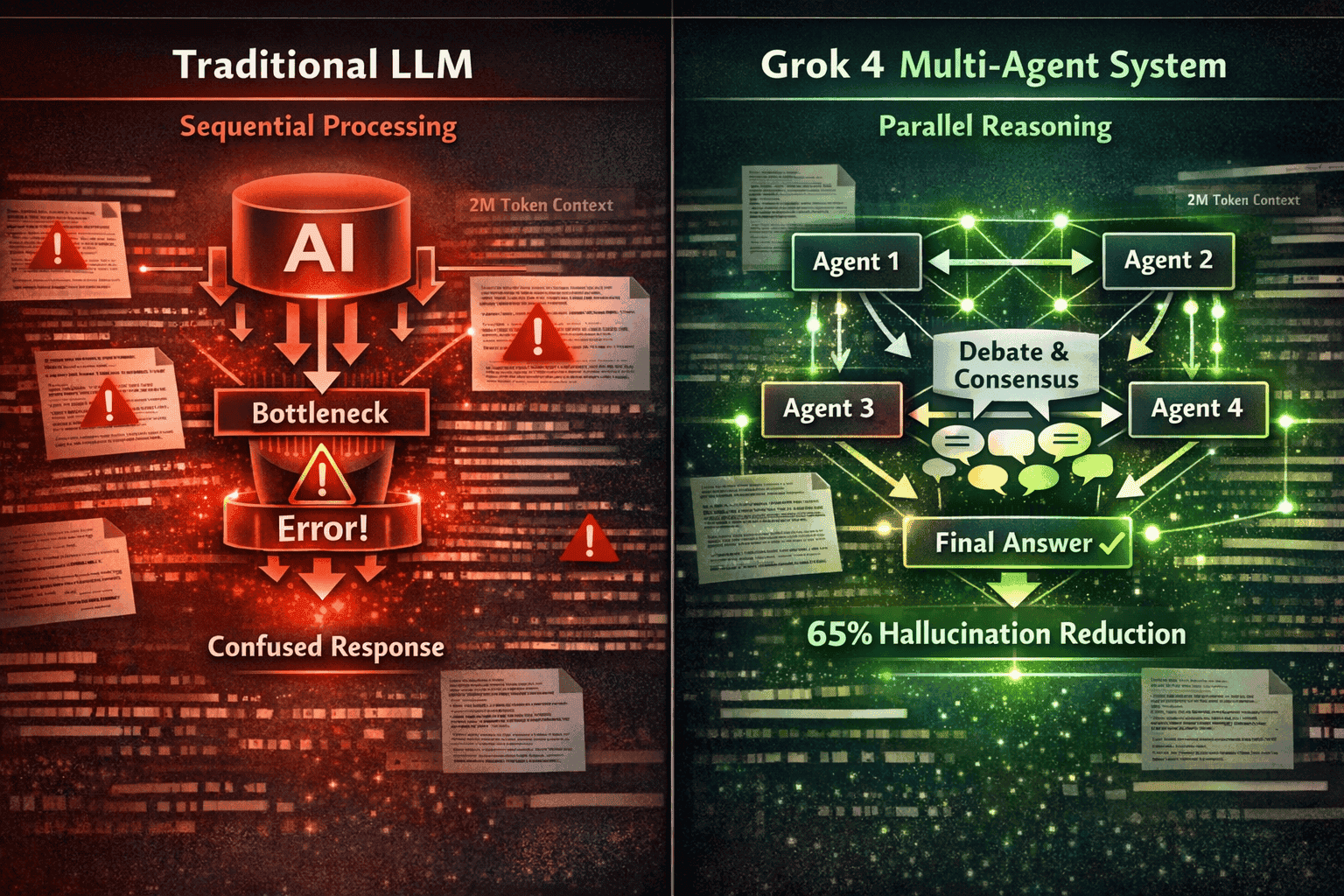
Grok 4.20’s four-agent collaborative system (Grok, Harper, Benjamin, and Lucas) directly addresses the core challenge of extended-context reasoning: maintaining accuracy and coherence across millions of tokens[1]. Traditional single-model architectures struggle with “lost in the middle” problems, where information buried in long contexts gets overlooked or misinterpreted.
How the multi-agent system works:
- Parallel processing: Each agent analyzes the extended context simultaneously from different analytical perspectives
- Collaborative debate: Agents share findings and challenge each other’s interpretations before reaching consensus
- Cross-validation: Multiple agents must agree on key facts and conclusions, reducing hallucination risk
- Specialized focus: Different agents can prioritize different aspects (factual accuracy, logical consistency, creative solutions, practical implementation)
This architecture delivered measurable improvements. Grok 4.20 achieved a 65% reduction in hallucinations, dropping from approximately 12% to 4.2%[1]. For production applications processing extended contexts, this reliability difference determines whether the system is usable or not.
Practical advantages in real-world scenarios:
| Application Type | Single-Model Challenge | Multi-Agent Solution |
|---|---|---|
| Codebase analysis | Missing dependencies across distant files | Agents track different modules simultaneously, validate cross-references |
| Legal document review | Contradictions between sections go unnoticed | Agents flag inconsistencies through collaborative review |
| Market analysis | Conflicting signals from different data sources | Agents debate interpretation before recommending action |
| Research synthesis | Key findings buried in middle of long papers | Agents specialize in different sections, combine insights |
Performance validation: In comparative benchmarks, Grok 4.20 achieved a 64.78% win rate versus prior production Grok versions[1]. Provisional LMArena Elo estimates place it at 1505-1535, with expectations of reaching #1 overall ranking once fully evaluated[1].
When multi-agent architecture creates the most value:
- Complex reasoning tasks where single-pass analysis often misses critical details
- High-stakes applications where hallucination costs are significant (financial decisions, medical analysis, legal review)
- Scenarios requiring synthesis across diverse information types (combining code, documentation, user feedback, market data)
Trade-off to consider: Multi-agent processing adds computational overhead compared to single-model inference. For simple queries or short contexts, the extra coordination may not justify the cost. But for extended-context scenarios where accuracy matters, the architecture fundamentally changes reliability.
The combination of extended context plus collaborative reasoning creates capabilities that neither feature delivers alone. Teams can explore how different AI architectures compare using platforms like MULTIBLY, which provides side-by-side access to 300+ models for direct performance evaluation.
What Real-Time AI Applications Benefit Most from 2M Token Context?
The 2M token context window creates the most value in applications where maintaining coherent understanding across massive, continuously updating information streams determines success. These aren’t theoretical use cases—they’re production scenarios where context limitations previously forced compromises.
Financial Trading and Market Intelligence
Why extended context matters: Successful trading requires synthesizing real-time price data, news flow, social sentiment, historical patterns, and portfolio positions simultaneously. Grok 4’s proven profitability in the Alpha Arena competition (12.11% average return) demonstrates practical value[1].
Specific applications:
- Algorithmic trading strategies that maintain coherent risk management across dozens of positions
- Sentiment-driven market timing combining millions of social media posts with technical indicators
- Event-driven trading that detects breaking news and analyzes implications within seconds
- Portfolio optimization considering real-time correlations across global markets
Enterprise Codebase Management
Why extended context matters: Modern enterprise applications span millions of lines of code across hundreds of repositories. Understanding dependencies, impacts, and refactoring opportunities requires processing entire codebases, not isolated files.
Specific applications:
- Automated code review that checks consistency across the entire project architecture
- Dependency analysis tracking how changes in one module affect distant components
- Migration planning for framework upgrades that impact thousands of files
- Security audits identifying vulnerability patterns across the complete codebase
Customer Intelligence and Support
Why extended context matters: Understanding customer issues requires context from previous interactions, product documentation, known bugs, and current system status—often exceeding 256K tokens for complex enterprise products.
Specific applications:
- Tier-3 technical support analyzing complete customer history plus product knowledge base
- Churn prediction synthesizing usage patterns, support tickets, and sentiment signals
- Product feedback analysis connecting feature requests across thousands of customer conversations
- Personalized onboarding tailoring guidance based on complete user journey and product state
Legal and Regulatory Compliance
Why extended context matters: Legal analysis requires cross-referencing current documents against precedents, regulations, and case history—often spanning millions of words.
Specific applications:
- Contract review checking consistency with company policies and legal requirements
- Regulatory compliance audits comparing practices against complete regulatory frameworks
- Due diligence analyzing target company documentation for M&A transactions
- Litigation support synthesizing evidence across thousands of documents
Research and Intelligence Analysis
Why extended context matters: Synthesizing insights from hundreds of research papers or intelligence reports requires maintaining coherent understanding across the complete corpus.
Specific applications:
- Literature reviews identifying patterns and gaps across entire research domains
- Competitive intelligence tracking competitor activities across news, patents, and public filings
- Threat assessment combining signals from diverse intelligence sources
- Trend analysis detecting emerging patterns in scientific or market research
Decision framework for choosing extended context:
Choose Grok 4’s 2M context when:
- Your application processes continuously updating streams (market data, social media, news feeds)
- Accuracy across the complete context is critical (hallucinations have significant costs)
- Information spans hundreds of documents or millions of lines of code
- Real-time responsiveness matters (2M tokens/minute throughput)[2]
Consider alternatives when:
- Static document processing without real-time updates (Kimi K2 offers cost-effective 256K windows)
- Reasoning depth matters more than context length (Claude Opus 4.5 excels at complex reasoning)
- Budget constraints are primary concern (open-source models like DeepSeek R1 offer strong value)
The practical test: if removing any significant portion of the context would degrade your application’s performance, you need extended context. If the application works well with selective retrieval of relevant chunks, traditional RAG (retrieval-augmented generation) with smaller context windows may be more cost-effective.
How Does Grok 4’s Performance Compare to GPT-5 and Claude Opus for Real-Time Tasks?
Grok 4’s real-time performance advantages stem from architecture choices that prioritize streaming data integration and throughput, while GPT-5 and Claude Opus optimize for different strengths. Understanding these trade-offs helps teams choose the right model for specific applications.
Throughput and Latency
Grok 4 delivers 2M tokens per minute throughput[2], industry-leading speed for processing large-scale real-time data streams. This matters most when:
- Processing continuous data feeds (market tickers, social media streams, sensor data)
- Analyzing large batches of documents with tight time constraints
- Supporting high-concurrency applications with many simultaneous users
GPT-5 (in its dual-model configuration) offers a speed-optimized variant for real-time tasks, though specific throughput benchmarks aren’t publicly disclosed. The model excels at:
- General-purpose real-time chat and customer service
- Balanced performance across diverse task types
- Integration with existing OpenAI ecosystem tools
Claude Opus 4.5 prioritizes reasoning depth over raw throughput, making it less optimal for high-volume real-time scenarios but superior when:
- Complex analysis matters more than speed
- Accuracy and nuance in reasoning justify longer processing times
- Tasks require deep logical chains rather than rapid response
Real-Time Data Integration
Grok 4’s unique advantage: Direct integration with X’s data firehose (68 million tweets daily)[1] provides continuously updating world knowledge. No other production model offers comparable real-time social intelligence.
GPT-5 and Claude Opus rely on:
- Static training data with periodic updates
- External API integrations for real-time data (requiring custom implementation)
- Retrieval-augmented generation (RAG) systems to inject current information
Practical implication: For applications requiring social sentiment, breaking news awareness, or trend detection, Grok 4 provides built-in capabilities that competitors require custom engineering to approximate.
Context Window Comparison
| Model | Context Window | Best Use Case | Real-Time Strength |
|---|---|---|---|
| Grok 4 | 256K–2M tokens | Streaming data + extended context | Real-time social intelligence, market analysis |
| GPT-5 | ~128K–200K (estimated) | General-purpose applications | Broad task coverage, ecosystem integration |
| Claude Opus 4.5 | ~200K | Deep reasoning tasks | Complex analysis requiring accuracy over speed |
Hallucination Rates in Extended Context
Grok 4.20: 4.2% hallucination rate after 65% reduction[1], achieved through multi-agent validation. This reliability matters most in:
- Financial applications where errors have direct monetary costs
- Legal and compliance scenarios requiring factual accuracy
- Enterprise deployments where trust determines adoption
GPT-5 and Claude Opus: Both models have strong accuracy, but specific hallucination metrics in extended-context scenarios aren’t publicly comparable. In practice:
- Claude Opus demonstrates exceptional accuracy in reasoning tasks
- GPT-5 shows strong general reliability across diverse applications
- Direct benchmarking on identical long-context tasks would be needed for definitive comparison
Cost and Availability
Grok 4 (as of February 2026):
- Available via SuperGrok subscription ($30/month) and X Premium+[1]
- API access expected soon but not yet publicly open[3]
- Pricing for API usage not yet disclosed
GPT-5:
- Available through OpenAI API with usage-based pricing
- Broad ecosystem support and integration options
- Mature tooling and documentation
Claude Opus 4.5:
- Available through Anthropic API
- Premium pricing reflecting advanced reasoning capabilities
- Strong enterprise adoption and support
Choosing between models for real-time applications:
Choose Grok 4 when:
- Social media intelligence and X data integration provide competitive advantage
- Extended context (approaching 2M tokens) is required
- Throughput and processing speed are critical performance metrics
- Multi-agent collaborative reasoning reduces hallucination risk for your use case
Choose GPT-5 when:
- General-purpose capabilities across diverse tasks matter most
- Ecosystem integration and tooling maturity are priorities
- Real-time data can be provided through external APIs
- Proven enterprise support and documentation are requirements
Choose Claude Opus 4.5 when:
- Reasoning depth and accuracy are paramount
- Extended context needs are moderate (under 200K tokens)
- Processing speed is less critical than output quality
- Complex analytical tasks justify premium pricing
For teams evaluating multiple models across real use cases, platforms like MULTIBLY provide side-by-side comparison capabilities across 300+ AI models, enabling direct performance testing with your specific data and requirements.
The practical reality: most production AI systems in 2026 use multiple models for different tasks. Grok 4’s real-time X data integration creates unique value for specific applications, while GPT-5 and Claude Opus excel in complementary scenarios. Understanding when each model’s strengths align with your requirements determines optimal architecture.
What Are the Limitations and Trade-offs of Extended Context Windows?
Extended context windows create powerful capabilities, but they also introduce trade-offs that affect performance, cost, and practical usability. Understanding these limitations helps teams architect systems that leverage Grok 4’s 2M context effectively without encountering unexpected problems.
Computational Cost and Latency
The challenge: Processing 2M tokens requires significantly more computation than standard 8K or 32K contexts. Even with Grok 4’s impressive 2M tokens/minute throughput[2], extended context increases:
- API costs (when pricing becomes public, expect higher rates for longer contexts)
- Latency (more tokens = longer processing time, even with optimized architecture)
- Memory requirements (maintaining 2M token context requires substantial RAM)
Practical implication: Not every query needs the full 2M context. Applications should dynamically adjust context size based on task requirements—use 256K baseline for most tasks, expand to 2M only when necessary.
Information Retrieval Challenges
The “lost in the middle” problem: Even with multi-agent architecture reducing this issue, finding specific information within 2M tokens remains challenging. Research shows LLMs often struggle to utilize information positioned in the middle of very long contexts.
Mitigation strategies:
- Structured context organization: Place critical information at the beginning and end of prompts
- Explicit references: Direct the model’s attention to specific sections when needed
- Hybrid approaches: Combine extended context with retrieval systems that pre-filter relevant information
- Multi-agent validation: Leverage Grok 4’s collaborative architecture to cross-check findings across the context
Real-Time Data Quality Issues
The challenge: Grok 4’s X data integration provides real-time intelligence, but Twitter data includes:
- Misinformation and rumors that spread faster than corrections
- Coordinated manipulation from bot networks and influence campaigns
- Noise and irrelevance in high-volume trending topics
- Language and cultural biases in the predominantly English dataset
Risk management approaches:
- Source verification: Weight information from verified accounts and established sources more heavily
- Temporal validation: Cross-check claims that appear across multiple time periods
- Multi-agent debate: Use collaborative reasoning to identify suspicious patterns
- Human oversight: Implement review processes for high-stakes decisions
API Availability and Access
Current limitations (as of February 2026):
- Grok 4.20 available only to SuperGrok subscribers ($30/month) and X Premium+ users[1]
- API access not yet publicly available[3]
- Broader rollout expected but timing uncertain
Practical implication: Teams building production systems can’t yet integrate Grok 4 via standard API workflows. This limits:
- Enterprise deployment at scale
- Integration with existing AI orchestration platforms
- Automated workflows requiring programmatic access
Workaround: For teams needing extended context capabilities now, Kimi K2’s 256K window offers API access with proven document processing performance.
Context Coherence vs. Precision Trade-offs
The challenge: As context expands, models face increasing difficulty maintaining precise factual accuracy across all details. Grok 4’s 65% hallucination reduction[1] is impressive, but 4.2% error rate still matters when:
- Processing thousands of documents (even 4% error rate compounds)
- Making financial decisions (small inaccuracies have monetary consequences)
- Legal or medical applications (accuracy requirements approach 100%)
Best practices:
- Validation layers: Implement fact-checking for critical claims
- Confidence scoring: Request the model to indicate certainty levels
- Source attribution: Require citations to specific context sections
- Human review: Maintain oversight for high-stakes applications
Comparison to Alternative Approaches
Extended context isn’t always the optimal solution. Consider alternatives when:
| Scenario | Extended Context | Alternative Approach |
|---|---|---|
| Static document analysis | Grok 4 (2M tokens) | RAG + smaller context model (more cost-effective) |
| Real-time social intelligence | Grok 4 (X integration) | No good alternative—unique capability |
| Code analysis | Grok 4 (entire codebase) | Specialized code models + targeted context |
| Deep reasoning | Grok 4 (multi-agent) | Claude Opus (superior reasoning, smaller context) |
Training and Inference Resource Requirements
Infrastructure reality: Grok 4 was trained on 200K GPUs via the Colossus supercluster[1][3]. This massive computational investment enables the extended context capabilities, but also means:
- Inference costs will likely be premium-priced when API access launches
- Environmental considerations for organizations with sustainability commitments
- Vendor dependency on xAI’s infrastructure (no self-hosting option for most enterprises)
Planning considerations: Budget for higher per-token costs compared to standard models. For applications processing millions of tokens daily, costs can scale significantly.
The key insight: extended context windows are powerful tools, not universal solutions. Teams should evaluate whether the specific benefits—real-time data integration, massive document processing, multi-agent reasoning—justify the trade-offs for their particular use cases. For many applications, hybrid architectures combining extended context for specific tasks with more efficient models for routine operations provide the best balance.
FAQ
What is Grok 4’s actual context window size?
Grok 4 offers a 256K token baseline context window that can expand up to 2M tokens when needed[1][3]. The expandable architecture allows the system to handle most tasks efficiently at 256K while scaling to the full 2M capacity for complex scenarios requiring massive context.
How does Grok 4 access real-time Twitter/X data?
Grok 4 connects directly to X’s data firehose, ingesting approximately 68 million English tweets daily[1]. This integration provides continuously updating information about current events, social sentiment, and trending topics, unlike traditional LLMs that rely on static training data with periodic updates.
Is Grok 4 available via API for developers?
As of February 2026, Grok 4.20 is available to SuperGrok subscribers ($30/month) and X Premium+ users, but the API is not yet publicly available[1][3]. Broader API access is expected soon, though specific timing hasn’t been announced.
How much does Grok 4 cost compared to GPT-5 or Claude?
Public API pricing for Grok 4 hasn’t been disclosed yet. Current access requires a SuperGrok subscription at $30/month[1]. When API pricing launches, expect premium rates for extended context usage given the computational requirements of processing up to 2M tokens.
What is the four-agent architecture in Grok 4.20?
Grok 4.20 uses four AI agents named Grok, Harper, Benjamin, and Lucas that collaborate on tasks[1]. These agents think in parallel, analyze the context from different perspectives, debate findings, and reach consensus before generating responses. This architecture reduces hallucinations by 65% compared to earlier versions[1].
Can Grok 4 process images and video in real-time?
Yes, Grok 4.20 supports native multimodal processing of text, images, and video simultaneously[1][3]. This enables comprehensive real-time analysis across multiple data types within the same context window, rather than requiring separate processing pipelines.
How fast is Grok 4’s inference speed?
Grok 4 achieves 2M tokens per minute throughput[2], providing industry-leading inference speed for processing large-scale data streams. This performance enables real-time applications that require rapid analysis of extended contexts.
What applications benefit most from Grok 4’s extended context?
Financial trading and market intelligence, enterprise codebase analysis, customer intelligence systems, legal document review, and research synthesis benefit most from Grok 4’s extended context[1]. Applications requiring both real-time data integration and massive context capacity see the greatest advantage.
How accurate is Grok 4 compared to other LLMs?
Grok 4.20 achieved a 65% reduction in hallucinations, dropping from approximately 12% to 4.2% error rate[1]. Provisional LMArena Elo estimates place it at 1505-1535, with expectations of reaching #1 overall ranking[1]. The multi-agent architecture provides particular accuracy advantages in extended-context scenarios.
Can Grok 4 replace traditional RAG systems?
For some use cases, yes—Grok 4’s 2M context can process entire document collections that would require RAG chunking in traditional systems. However, RAG remains more cost-effective for very large static knowledge bases where selective retrieval is sufficient. The choice depends on whether real-time coherence across the complete context justifies the computational cost.
Does Grok 4 work in languages other than English?
The X data firehose integration focuses primarily on English tweets (68 million daily)[1], which limits real-time intelligence capabilities in other languages. For multilingual applications without real-time social data requirements, models like Qwen3 may provide better performance.
What are the main limitations of Grok 4’s 2M context?
Key limitations include higher computational costs, current lack of public API access, potential information retrieval challenges in very long contexts, and data quality issues inherent in real-time social media streams[1][3]. Applications requiring near-perfect accuracy or working with non-English content should carefully evaluate these trade-offs.
Conclusion
Why Grok 4’s 2M context window changes the game for real-time AI applications comes down to a unique combination: massive context capacity, continuous real-time data integration, and multi-agent collaborative reasoning working together. This isn’t just about processing longer documents—it’s about maintaining coherent intelligence across streaming information that updates constantly, enabling applications that were previously impossible.
The proof shows up in measurable outcomes. Grok 4.20’s profitability in live trading competitions, 65% hallucination reduction, and 2M tokens/minute throughput demonstrate practical value beyond benchmark scores[1][2]. For teams building financial intelligence systems, enterprise code analysis tools, or customer intelligence platforms, these capabilities create genuine competitive advantages.
But extended context isn’t a universal solution. The trade-offs—computational cost, current API limitations, and data quality challenges—mean teams need to evaluate whether Grok 4’s specific strengths align with their requirements. For applications where real-time social intelligence and massive context combine to create value, Grok 4 offers capabilities no other production model matches. For other scenarios, alternatives like Claude Opus for deep reasoning or open-source models for cost efficiency may provide better fits.
Next steps for teams evaluating Grok 4:
- Identify use cases where real-time data plus extended context create competitive advantage
- Test with SuperGrok subscription ($30/month) to validate performance on your specific data[1]
- Plan for API integration when public access launches, budgeting for premium pricing
- Compare against alternatives using platforms like MULTIBLY to evaluate 300+ models side-by-side
- Design validation layers to address the 4.2% hallucination rate in production systems[1]
- Monitor xAI announcements for API availability and pricing details
The 2026 AI landscape increasingly rewards teams that match specific model strengths to particular use cases rather than defaulting to general-purpose solutions. Grok 4’s 2M context window represents a specialized capability—powerful when applied correctly, but not optimal for every scenario. Understanding when streaming data and extended memory create genuine value determines whether this technology transforms your applications or simply adds unnecessary complexity.
For production systems requiring the intersection of real-time intelligence and massive context, Grok 4 changes what’s possible. For everything else, the broader AI ecosystem offers alternatives worth evaluating.
References
[1] Xai Launches Grok 4 20 And It Has 4 Ai Agents Collaborating – https://www.nextbigfuture.com/2026/02/xai-launches-grok-4-20-and-it-has-4-ai-agents-collaborating.html
[2] Grok 4 Vs Gpt 5 2 – https://otomatic.ai/en/grok-4-vs-gpt-5-2
[3] Grok 4 20 Beta 4 Agents Guide En – https://help.apiyi.com/en/grok-4-20-beta-4-agents-guide-en.html
[5] Grok 4 2 Public Beta Live Xais Rapid Learning Ai Now Available – https://www.basenor.com/blogs/news/grok-4-2-public-beta-live-xais-rapid-learning-ai-now-available
Our Fact Checking Process
We prioritize accuracy and integrity in our content. Here's how we maintain high standards:
- Expert Review: All articles are reviewed by subject matter experts.
- Source Validation: Information is backed by credible, up-to-date sources.
- Transparency: We clearly cite references and disclose potential conflicts.
Our Review Board
Our content is carefully reviewed by experienced professionals to ensure accuracy and relevance.
- Qualified Experts: Each article is assessed by specialists with field-specific knowledge.
- Up-to-date Insights: We incorporate the latest research, trends, and standards.
- Commitment to Quality: Reviewers ensure clarity, correctness, and completeness.
Look for the expert-reviewed label to read content you can trust.



